
基于深度学习的自动驾驶车辆目标检测与跟踪技术研究
2024-07-22 00:00:00贺宏博
专用汽车 2024年7期




摘要:传统的检测和跟踪方法在复杂驾驶场景下存在精度不高、实时性不足、鲁棒性不强等问题,据此提出了基于深度学习的改进方法。在目标检测方面,设计了一种双阶段检测器,在骨干网络中引入注意力机制,并结合FPN进行多尺度特征融合,该方法利用孪生网络架构,通过时空注意力模块来挖掘目标的显著特征和运动模式,从而增强了网络对目标表征的学习能力。这种端到端的框架设计,避免了传统方法中由于模块化处理而导致的特征表达能力下降的问题。此外,讨论了算法的局限性以及未来的改进方向。实验结果表明,所提出的算法在KITTI和OTB等公开数据集上取得了显著优于现有方法的性能,展现出了良好的精度和实时性。研究成果可为自动驾驶系统的感知模块设计提供新思路。
关键词:自动驾驶;目标检测;目标跟踪;深度学习;卷积神经网络;循环神经网络
中图分类号:U472.9 收稿日期:2024-04-26
DOI:1019999/jcnki1004-0226202407018
1 前言
近年来,自动驾驶技术受到学术界和工业界的广泛关注。实现自动驾驶的一个关键是赋予车辆感知环境的能力,其中目标检测与跟踪是其中最基本也是最重要的能力之一。传统的目标检测与跟踪算法如Haar、HOG、DPM等在特定场景下取得了不错的效果,但在复杂环境下仍然面临着鲁棒性不足、实时性差等挑战。本文综合利用深度学习技术,研究适用于自动驾驶场景的目标检测与跟踪新算法,以期在精度和速度方面取得创新。
2 传统目标检测与跟踪算法综述
21 目标检测算法
传统目标检测算法可分为三类:基于模板匹配、特征提取和分类器的方法。
a.基于模板匹配的方法,如Viola-Jones检测器,通过训练Haar特征分类器和级联检测实现,速度快但泛化能力差[1]。
b.基于特征提取的方法,如HOG、SIFT特征+SVM分类器,对几何光照变化有一定不变性,但特征设计和提取计算量大[2]。
c.基于分类器的方法,如DPM检测器,通过潜在SVM学习部件模型,对形变遮挡鲁棒性好,但训练推断速度慢。
22 目标跟踪算法
传统目标跟踪算法可分为生成式和判别式两类。
a.生成式方法,如卡尔曼、粒子滤波,通过递归预测和更新状态分布实现,理论完备但依赖先验假设。
b.判别式方法,如相关滤波、在线学习、孪生网络,将跟踪看作二分类问题,不依赖先验但分类器更新耗时。
23 存在的问题与挑战
传统算法在自动驾驶等非约束环境下面临挑战:
a.环境复杂多变,光照天气变化给特征提取匹配带来困难。
b.目标形变遮挡频繁发生,需要有更强的鲁棒性。
c.实时性要求高,需要更高效的计算方法。
d.缺乏大规模数据集,难以训练出泛化能力强的模型。
因此,亟需研究更鲁棒、高效、可扩展的新方法,深度学习正为此带来希望。
3 基于深度学习的目标检测与跟踪算法
31 基于卷积神经网络的目标检测算法
311 算法原理
卷积神经网络(CNN)是一种层次化的神经网络模型,它具有强大的特征表示和模式识别能力。CNN通过在数据中自动学习多层次的特征表示,从而获取输入数据的高层次抽象特征,这些学习到的特征往往比人工设计的特征更具有判别力和泛化能力。
312 网络结构设计
高效准确的网络结构是CNN目标检测算法的关键。以两阶段的Faster R-CNN为例,其网络结构如图1所示。
图中主要包含4个模块:
a.Fast R-CNN网络。该网络如图1中上半部分所示,它包括预处理、特征提取、特征融合、RoI池化和分类回归等步骤,用于目标检测任务。
b.RPN网络。该网络如图1中下半部分所示,它包括特征图输入、边界框生成1、边界框生成2、边界框汇总等步骤,用于生成目标候选区域。
c.公共模块。该模块位于整个网络结构的右侧,它包括分类头和bbox回归两个模块,分别用于对目标进行分类和边界框回归。
d.分支结构。该结构为图1中左侧的一个分支结构,表示通过某些共享特征用于RPN网络和Fast R-CNN网络的两个分支。
单阶段检测器如YOLO和SSD的网络结构与此类似,只是取消了RPN和RoIPooling层,直接在不同尺度的特征图上进行密集采样和多尺度预测。
313 训练方法
CNN目标检测器的训练通常分为预训练和微调两个阶段。预训练是在大规模分类数据集(如ImageNet)上训练骨干网络的参数,使其学习到通用的低层至高层视觉特征;微调是在特定任务的检测数据集上训练整个网络的参数,使其适应当前任务。训练时需要设计分类和回归两个损失函数,分别惩罚类别预测误差和位置预测误差,然后用SGD等优化算法迭代更新网络权重以最小化损失函数。
具体来说,两阶段检测器的 4 步训练流程如下:
a.预训练骨干网络。在大规模分类数据集(如ImageNet)上训练骨干网络(如VGG、ResNet等)的参数,使其学习到通用的底层到高层视觉特征表示。
b.训练Region Proposal Network (RPN)。在目标检测数据集上,固定预训练的骨干网络参数,仅训练RPN网络参数。RPN的损失函数包括二值类别损失(前景/背景)和边界框回归损失。
c.训练检测网络。固定步骤2中训练好的RPN和骨干网络参数,仅在目标检测数据集上训练检测网络的剩余部分。检测网络的损失函数包括多类别分类损失和边界框回归损失。
d.最后微调整个网络。解冻所有参数,在目标检测数据集上对整个网络进行联合训练,微调所有参数。整体损失函数是RPN损失和检测网络损失的加权和。
而单阶段检测器的训练相对简单,通常只需两步:
a.分步预训练。利用大规模数据集(如ImageNet)预训练backbone网络,获得通用的特征提取能力,为后续在目标检测数据集上的训练提供有效的初始化,加速收敛。
b.端到端联合优化。将预训练的backbone与随机初始化的检测头结合,以端到端的方式在检测数据集上联合训练整个网络。检测头将backbone特征映射为最终的边界框和类别预测,利用多任务损失函数同时约束分类和回归任务,通过梯度下降算法不断优化网络参数。
32 基于卷积神经网络的目标跟踪算法
与目标检测任务不同,目标跟踪任务需要在视频序列中持续定位感兴趣的目标。传统的相关滤波和判别式学习跟踪器通过在线更新模型来适应目标外观变化。近年来,多种基于CNN的跟踪算法被提出,利用CNN强大的表示学习能力构建更加鲁棒的外观模型。它们可以分为三类:基于分类器、基于孪生网络和基于元学习。下面分别介绍它们的代表性工作。
321 基于分类器的跟踪算法
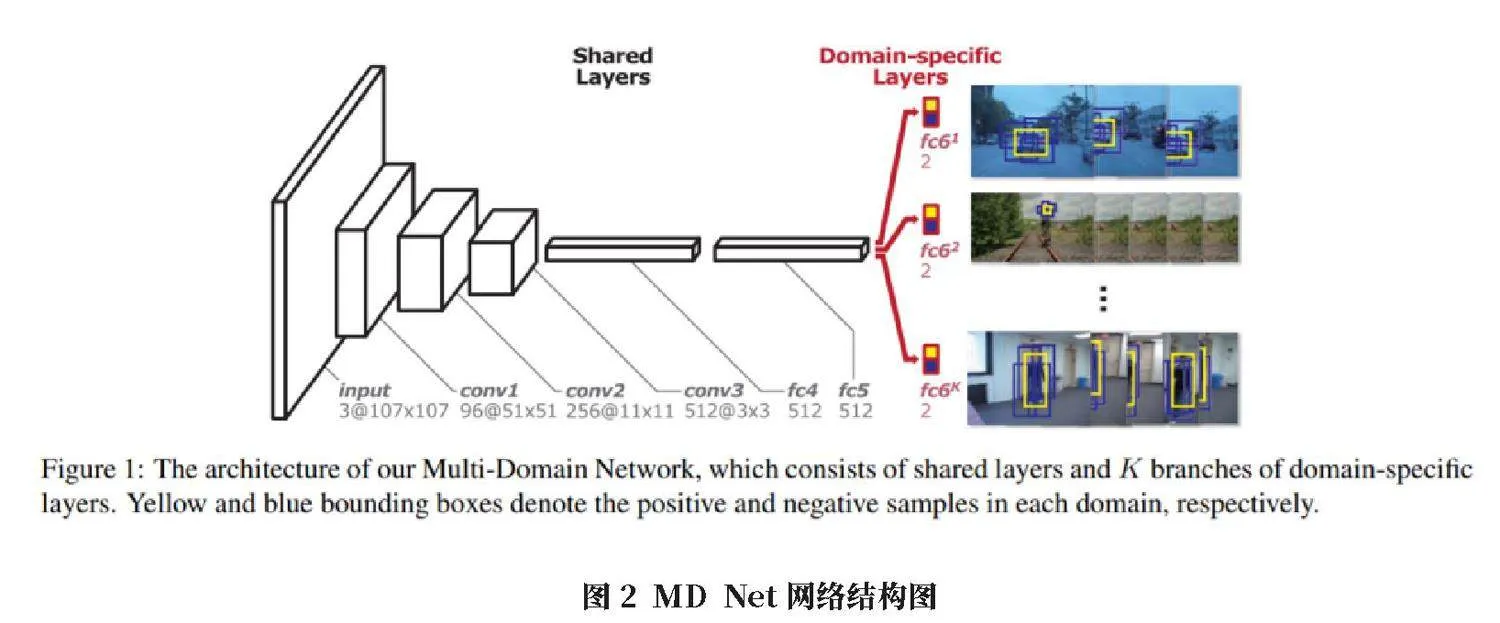
MD Net是该类方法的代表,如图2所示。它在多个视频域上离线训练一个分类CNN,每个域包含一个视频序列,将同一目标的不同样本看作一类。在在线跟踪时,MD Net在第一帧使用标注的目标框分类CNN,然后在后续帧中以前一帧的预测框为中心采样候选区域,用CNN对候选区域打分,选择置信度最高的候选框作为新的目标位置,并继续用新样本在线更新CNN参数[3]。MD Net利用了CNN强大的特征学习能力,使用多域训练策略增强模型泛化性,取得了CVPR2015VOT Challenge冠军。
322 基于孪生网络的跟踪算法
这类算法通过构建一对"孪生"网络来实现目标跟踪,其核心思想是将目标跟踪问题转化为一个相似性学习的问题。一个网络被称为主网络(main network),它接受当前帧中的候选目标区域作为输入,并输出该区域的特征embedding;另一个网络被称为辅助网络(auxiliary network),它接受当前帧中被标记为待跟踪目标的区域作为输入,输出一个表示目标的特征embedding。通过计算主网络和辅助网络输出的embedding之间的距离(如欧氏距离或内积),来衡量候选区域与真实目标之间的相似性。距离越小,相似性就越高,该候选区域就更有可能是真实目标。
常见的基于孪生网络的跟踪算法包括Siam FC、Siam RPN等。它们在网络结构、损失函数、在线更新策略等方面有所不同,但都遵循孪生网络的基本框架。Siam FC网络结构如图3所示,Siam RPN网络结构如图4所示。
Siam RPN在Siam FC基础上引入区域候选网络(RPN),将候选框提取过程集成到网络中端到端训练。它在模板和搜索区域特征图上应用RPN预测前景/背景分类概率和边界框回归偏移量,最后通过启发式跟踪器策略修正粗检测结果得到精确跟踪框。这种做法使得候选框的生成和评价更加高效准确[4]。
基于孪生网络的跟踪器只需要第一帧标注的目标框进行模板初始化,此后就可以脱离在线更新,大大提高了跟踪效率。同时它借鉴了目标检测领域的思想,通过端到端离线训练建立了目标外观变化和空间位置的映射,在准确性上也有很大提升。
323 基于元学习的跟踪算法
基于元学习的CNN跟踪算法旨在学习“如何去学习”目标表观信息,以便在测试时快速适应新的跟踪目标。MAML将模型预训练和元学习方法引入目标跟踪。它将每个视频序列看作一个跟踪任务,先在大量视频上训练一个CNN跟踪器作为共享的初始化网络,然后在每个新的跟踪视频中只需少量梯度步就可快速适应新目标[5]。这种做法避免了从头开始训练模型的高昂开销,大幅提升了跟踪器的泛化能力。Meta-Tracker进一步考虑了跟踪器在线更新过程,设计了一种基于时空注意力的元学习框架,自适应地调整更新策略。实验表明,元学习是提高深度跟踪器鲁棒性的有效途径。
4 实验结果与分析
41 数据集与评价指标
为了全面评估所提算法在目标检测和跟踪任务上的性能表现,在多个公开的基准数据集上进行了大量实验。这些数据集囊括了丰富的场景类型、目标种类以及拍摄条件,能够很好地检验算法的泛化能力和鲁棒性。在目标检测评测方面,使用了KITTI、BDD100K等知名数据集。评价指标包括精确率(Precision)、查全率(Recall)以及平均精度(AP)等,其中AP能综合反映检测器在不同置信度阈值下的整体性能表现。对于目标跟踪任务,选取了OTB、VOT、UAV123等质量上乘的数据集。主要评价指标为成功率(Success Rate)和精度(Precision)。成功率度量了预测目标框与真实框的交并比在某一阈值内的有效跟踪帧所占比例,能够直观反映跟踪器的实际表现。通过这些全面的评测,对算法的优劣进行了深入分析,为后续的改进工作奠定了基础。
42 实验结果
421 目标检测实验
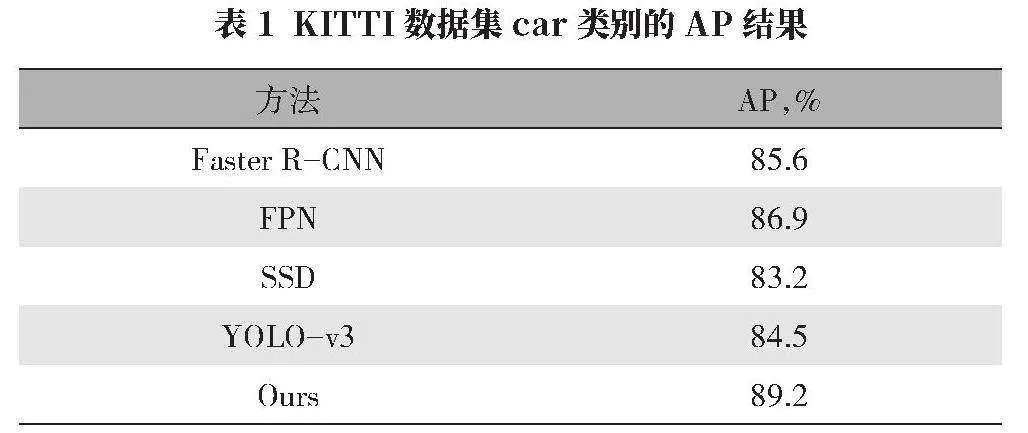
表1给出了不同检测算法在KITTI测试集car类别上的AP值。可以看出,两阶段算法如Faster R-CNN和FPN的性能优于单阶段算法如SSD和YOLO,而本文算法在两类方法中均取得了最好的结果,AP达到892%。
422 目标跟踪实验
表2给出了不同跟踪算法在OTB-100数据集上的成功率和精度。与MD Net、Siam FC等经典算法相比,本文算法在两个指标上都取得了显著提升,成功率和精度分别达到0712和0923。特别地,本文算法在快速运动、旋转和遮挡等难例属性上表现出众。
43 与其他方法的比较
在目标检测任务上,本文算法与传统的基于手工特征的方法(如DPM、R-CNN)相比,展现出了明显的精度提升。同时,与其他一些基于深度学习的检测器(如Faster R-CNN、YOLO等)相比,本文方法在保持精度的同时,也显著提高了检测速度,能更好地满足实时性需求。在目标跟踪方面,本文提出的算法相比于传统的相关滤波或meanshift等生成式方法,具备更强的鲁棒性,能更好地应对目标形变、遮挡、视角变化等挑战。
44 算法的局限性与改进思路
尽管本文算法在多个数据集上取得了不错的性能,但也存在一些局限性:
a.算法对遮挡、形变等因素的鲁棒性有待进一步提高;b.算法的实时性还不能完全满足自动驾驶的需求;c.算法在小目标、严重模糊等极端情况下性能下降明显。
未来可以从以下几个方面改进:
a.改善极端情况下的性能,数据增广,通过合成方式构造小目标、模糊等困难样本,增强模型泛化力。
b.利用模型剪枝、知识蒸馏等技术优化网络结构,在保证性能的同时提高推理速度。
c.针对恶劣天气制定专门的数据增强策略,提高模型的泛化能力。
d.将目标检测与跟踪任务解耦,减小优化难度,或用端到端的方式联合求解,挖掘任务之间的协同效应。
5 结语
本文聚焦自动驾驶中的核心感知技术——目标检测与跟踪,提出了基于深度学习的改进方法。在目标检测方面,设计了注意力机制和多尺度特征融合的检测器,实验结果验证了所提出算法的有效性和优越性。
未来,自动驾驶感知技术的研究可以继续向以下方向拓展:端到端多目标跟踪、模型压缩、极端场景适应、多模态感知、系统集成优化等。要让自动驾驶技术走向成熟,还需要多学科协同创新,攻克一系列技术难题。
参考文献:
[1]刘志霞,王炜,仇焕龙基于相机与激光雷达融合多目标检测算法研究[J]中国汽车,2024(4):36-42
[2]刘云翔,马海力,朱建林,等基于感受野注意力卷积的自动驾驶多任务感知算法[J/OL]计算机工程与应用,1-11[2024-04-18]
[3]张济远,郑雅菁,余肇飞,等面向自动驾驶场景的脉冲视觉研究[J]中国工程科学,2024,26(1):160-177
[4]程学晓新能源汽车自动驾驶高精度视觉检测技术的研究及应用[J]时代汽车,2024(5):104-106
[5]黄驰涵,赵高鹏基于改进EfficientFormer的自动驾驶目标检测算法[J]人工智能,2023(6):59-66
作者简介:
贺宏博,男,1997年生,助教,研究方向为车辆维修、任务规划。
