
基于STL-XGBoost-NBEATSx的小时天然气负荷预测
2024-06-24 10:39:46邵必林任萌田宁
中国石油大学学报(自然科学版) 2024年3期
邵必林 任萌 田宁


摘要:小时天然气负荷预测受外部特征因素与预测方法的影响,为提高其预测精度并解决其他深度学习类模型或组合模型可解释性差、训练时间过长的问题,在引入“小时影响度”这一新特征因素的同时提出一种基于极端梯度提升树(extreme gradient boosting tress,XGBoost)模型与可解释性神经网络模型NBEATSx组合预测的方法;以 XGBoost模型作为特征筛选器对特征集数据进行筛选,再将筛选降维后的数据集输入到NBEATSx中训练,提高NBEATSx的训练速度与预测精度;将负荷数据与特征数据经STL(seasonal and trend decomposition using Loess)算法分解为趋势分量、季节分量与残差分量,再分别输入到XGBoost中进行预测,减弱原始数据中的噪音影响;将优化后的NBEATSx与XGBoost模型通过方差倒数法进行组合,得出STL-XGBoost-NBEATSx组合模型的预测结果。结果表明:“小时影响度”这一新特征是小时负荷预测的重要影响因素,STL-XGBoost-NBEATSx模型训练速度有所提高,具有良好的可解释性与更高的预测准确性,模型预测结果的平均绝对百分比误差、均方误差、平均绝对误差分别比其余单一模型平均降低54.20%、63.97%、49.72%,比其余组合模型平均降低24.85%、34.39%、23.41%,模型的决定系数为0.935,能够很好地拟合观测数据。
关键词:天然气负荷预测; 小时影响因素; 极端梯度提升树; 可解释性; NBEATSx; 组合模型
中图分类号:TP 996; TP 183 文献标志码:A
文章编号:1673-5005(2024)03-0170-10 doi:10.3969/j.issn.1673-5005.2024.03.019
Hourly natural gas load forecast based on STL-XGBoost-NBEATSx
SHAO Bilin, REN Meng, TIAN Ning
(School of Management, Xian University of Architecture and Technology, Xian 710311, China)
Abstract: Hourly natural gas load forecasting was affected by external feature factors and forecasting methods. In order to improve the accuracy of natural gas hourly load forecasting and solve the problems of poor interpretability and long training time of other deep learning models or combination models, in this paper we introduce a new feature of "hourly influence" and propose a prediction method based on the combination of extreme gradient boosting tree (XGBoost) model and interpretable neural network model NBEATSx. The XGBoost model was used for feature screening, then the filtered and dimensionality-reduced dataset and load values were inputted into NBEATSx for training, which improves the training speed and prediction accuracy of NBEATSx. The load data and feature data were decomposed into the trend, seasonal, and residual components by the seasonal and trend decomposition using Loess (STL) algorithm, and then they were inputted into XGBoost for prediction, which reduces the influence of the noise in the original data. The two types of models mentioned above were combined by the inverse variance method to obtain the prediction results of the STL-XGBoost-NBEATSx model. The results show that the new feature of "hourly influence" is an essential factor in hourly load forecasting. The STL-XGBoost-NBEATSx not only improves the training speed, but also has good interpretability and higher prediction accuracy. The mean absolute percentage error, mean square error, and mean absolute error of the prediction results of the combined model are respectively 54.20%, 63.97%, and 49.72% lower than the rest of the single model on average, and 24.85%, 34.39%, and 23.41% lower than the rest of the combined model on average. The model has an R-squared of 0.935, which provides a good fit to the observed data.
Keywords:natural gas load forecasting; hourly influencing factors; extreme gradient boosting trees; interpretability; NBEATSx; combinatorial models
随着中国“碳达峰、碳中和”工作目标的推进,天然气作为一种低碳清洁能源,在供应端和消费端各领域具有独特的比较优势[1]。近年来,中国天然气产量不断提高,但仍难以满足高速增长的天然气消费需求,供需缺口持续扩大,甚至在一些地区出现了“气荒”[2]。负荷预测是保证天然气供需平衡的基础,相比于日负荷与年负荷等中低频数据,小时负荷更能反映出天然气的变化情况。准确的天然气负荷预测能够提高天然气供应的可靠性,改善天然气供不应求的情况。因此笔者使用XGBoost特征筛选优化NBEATSx,再使用STL(seasonal and trend decomposition using Loess)分解优化XGBoost,最后使用误差倒数法将优化后的两类模型组合,结合树模型训练速度快以及神经网络模型预测精度高的优势解决单一模型存在的不足。
1 国内外研究现状
天然气负荷数据具有非线性、非平稳性等特点,且受众多复杂因素的影响,现有预测模型主要分为传统模型与基于人工智能的模型两大类。传统预测模型主要有指数平滑法(ES)[3]、自回归差分移动平均法(ARIMA)等,这类模型原理简单,对非平稳、强非线性的数据预测精度较低。基于人工智能的预测模型主要有随机森林(RF)[4]、支持向量回归(SVR)[5]、梯度提升类算法与基于神经网络的算法等。梯度提升类基于树模型的算法具有良好的可解释性,可输出特征重要度来实现对高维特征的筛选,但模型缺乏对强波动时间段的感知能力,无法有效提取数据的长期信息;反向传播神经网络(BP)[6]、循环神经网络(RNN)[7]、长短期记忆网络(LSTM)[8]、门控递归单元(GRU)[9]等深度学习算法复杂,具有更好的长短期信息学习性能,适合对大数据集进行训练,非线性拟合能力强,但模型更像一个“黑盒”,可解释性差,而且参数过多、收敛速度慢。
由于负荷的波动性较强且受外部因素影响较大,单一的模型难以满足负荷预测高精度的实际需要,学者们提出了组合预测模型。谭海旺等[10]利用极端梯度提升树(extreme gradient boosting trees,XGBoost)对光伏发电功率进行初步预测并将预测值作为增加的特征值,再分别建立XGBoost模型和LSTM模型,利用误差倒数法整合两个模型的预测值,试验表明组合模型较单一模型预测性能更好;邵必林等[11]引入变分模态分解(VMD)算法将负荷数据分解为平稳数据,然后通过融合注意力机制的深度双向门控循环单元神经网络(IDBiGRU)对分解后的数据进行预测,降低了原始负荷数据中噪音的影响,提高了负荷预测的精度和训练速度,但VMD算法性能受K参数选取的影响较大;陈岚等[12] 利用 XGBoost 进行特征筛选,降低数据维度,再利用改进的 LSTNet 进行预测,预测准确性有所提高,但试验证明随着时间步增加,各个模型的预测误差都逐渐增大。
通过上述研究发现,对于影响天然气小时负荷的外部因素,通常仅关注时间、气象[13]等,忽略了同一天中不同时刻负荷的变化规律,因此本文中提出了“小时影响度”这一新特征衡量24个不同时刻对负荷变化的影响程度。此外,在负荷预测方面,存在单一树模型难以提取长期信息、预测精度受限于中小数据集,普通神经网络模型可解释性差、训练速度慢以及目前的预测模型往往在多步预测中表现不佳等不足。NBEATSx网络是在N-BEATS(neural basis expansion analysis for interpretable time series forecasting)基础上的扩展,它是一种仅通过全连接层实现时间序列预测的方法,其可解释性的结构可看作是模型自身实现对输入数据的分解处理,使得模型能够在负荷数据的单步与多步预测中具有更好的精度;XGBoost是一个强大的集成学习算法,它通过将多个弱分类器(决策树)组合起来,逐步减少预测误差,提高整体性能,并且具有出色的特征处理能力与可解释性。
2 基本原理
2.1 STL分解模型
STL分解算法是一种基于Loess局部加权回归平滑估计技术进行时间序列分解的算法,可以处理任何类型的时间序列数据,将其分为趋势分量、周期分量与残差分量。STL算法操作简单,参数少,计算速度快,分量具有可解释性,而且不需要困扰于对分量数量的选择,对异常值不敏感,鲁棒性好。STL通常利用加法原理对时序数据进行分解,表达式 [14]为
Yt=Tt+St+It.(1)
式中,Yt为t时刻的观测值;Tt、St、It分别为 t时刻的趋势分量值、周期分量值、残差分量值。
2.2 XGBoost树模型
XGBoost是一种梯度提升(gradient boosting)树模型,采用了前向加法思想,是对GBDT的改进,将GBDT的目标函数从一阶导数信息延伸到二阶导数,使得在提高精度的同时提高了模型的训练速度。XGBoost模型的集成预测值 [10]为
i=∑Kk=1fk(xi).(2)
式中,xi为第i个样本的特征向量;i为第i个样本的模型预测值;fk为第k棵树的预测函数;K为树的个数。
以第t步的模型(第t棵树)为例,第i个样本的目标函数O(t) [10]为
O(t)=L(t)+Ω(ft)=∑ni=1l(yi,(t-1)i+ft(xi))+γT+12λ∑Tj=1w2j. (3)
式中,(t-1)i为第i个样本第t-1棵树的预测值;yi为第i个样本的真实值;n为样本总数;γ为加入新叶子节点引入的复杂度代价;T为叶子数量;λ为加入新叶分数引入的复杂度代价;wj为叶分数的L2正则项。
将式(3)二阶泰勒展开,得到最优化目标函数为
O(t)≈∑ni=1l(yi,(t-1)i)+gift(xi)+12hif2t(xi)+γT+12λ∑Tj=1w2j≈∑ni=1giwq(xi)+12hiw2q(xi)+γT+12λ∑Tj=1w2j =∑Tj=1Gjwj+12(Hj+λ)w2j+γT. (4)
其中
Gj=∑i∈Ijgi, Hj=∑i∈Ijhi,gi=(t-1)l(yi,(t-1)),hi=2(t-1)l(yi,(t-1)).
式中,wq(xi)为第t棵树的叶子节点值。
目标函数一阶导数为零时,解得最优值 [10]为
w*j=-GjHj+λ,O*=-12∑Tj=1G2jHj+λ+γT.(5)
此外,XGBoost的可解释性允许模型输出特征的全局重要度,在单个决策树中利用每个特征对分割点改进性能度量的量来计算特征重要度,由节点加权和记录次数[12],用特征在所有树中重要度的平均值来衡量全局重要度,输出重要度得分(Fscore)。重要度得分表明了特征因素对预测目标值的影响程度,可依据重要度得分对特征因素进行筛选。
2.3 NBEATSx神经网络模型
NBEATSx是一个基于后向和前向残差链路和一个非常深的全连接层堆栈的深度神经网络结构,用来解决单变量时间序列点预测问题[15]。一个完整的NBEATSx网络结构由多个堆栈(stack)组成,一个堆栈又由多个块(block)组成,每个块的基本构件是基于非线性激活函数的多层全连接网络(FCNN)。NBEATSx模型的整体结构如图1所示。
(1)块。以模型第s个堆栈里第m个块为例,由FCNN通过第s个堆栈里第m个块的输入窗口序列值
ybacks,m以及对应的外部变量矩阵Xm学习到线性适应于后向与前向预测扩张系数的隐藏层信息hs,m,得到扩张系数后,执行两种形式[15]的信息转换,输出后向与前向预测值backs,m、fors,m:
backs,m=Vback s,mθback s,m,fors,m=Vfors,mθfors,m,Vback s,m∈RL×Ns,Vfor s,m∈RH×Ns,θback s,m, θfor s,m∈RNs. (6)
式中,θback s,m、θfor s,m分别为后向、前向预测扩张系数;Ns为堆栈基维度;Vback s,m,Vfor s,m 分别为块中对应于后向预测、前向预测的基函数;H为预测窗口长度;L为输入窗口长度,L∈(2H~7H)。
(2)堆栈。使用双重残差连接原理将块堆叠成堆栈,第s个堆栈里的信息转换 [15]为
ybacks,m+1=ybacks,m-backs,m ,fors=∑Mm=1fors,m.(7)
式中,fors为第s个堆栈的未来预测值;M为第s个堆栈中块的数量。
(3)模型预测值。多个堆栈基于双重残差连接原理堆叠成完整的NBEATSx模型,模型最终预测值 [15]为
for=∑Ss=1fors. (8)
式中,S为一个完整NBEATSx结构中堆栈数量;for为NBEATSx模型预测值。
(4)可解释性结构。NBEATSx网络配置有可解释的结构,通过设置不同的表示趋势性(T)或季节性(S)的基函数来实现。不同堆栈预测的连接可以看作原始序列的顺序分解,能够很好地反映小时天然气负荷数据的趋势性与周期性,并可作为单独的可解释性输出。以块中的前向预测为例,后向预测中的函数处理过程与前向预测相同,趋势性、季节性、外部变量堆栈的预测原理[15]为
tT=[0,1,2,…,H-2,H-1]H ,trends,m=∑Npoli=0tiθtrend s,m,i≡Tθtrends,m,T∈RH×(Npol+1) .(9)
seass,m=∑H2-1i=0[cos(2πitNhr)θseass,m,i+sin2πitNhrθseass,m,i+H/2]≡Sθseass,m,S∈RH×(H-1).(10)
exogs,m=∑Nxi=0xiθexogs,m,i≡Xθexogs,m.(11)
式中,tT为时间向量t的转置; T为序列趋势性的多项式基函数;Npol为趋势多项式函数的最大次数;
θtrends,m、θseass,m、θexogs,m分别为与趋势性、季节性、外部变量相关的扩张系数;S为序列季节性的基函数; Nhr为超参数,控制谐波振幅;X为外部变量矩阵;Nx为外部变量个数;trends,m、seass,m、exogs,m分别为趋势性、季节性、考虑外部变量影响的预测值。
2.4 STL-XGBoost-NBEATSx组合预测模型
STL-XGBoost-NBEATSx组合模型的整体预测流程如下,模型结构如图2所示。
(1)收集天然气小时负荷实际观测数据与相关外部影响因素数据,将整体数据集进行预处理后划分为训练集与测试集;
(2)先将预处理后的负荷数据集与特征数据集一并输入到XGBoost中进行特征筛选,对模型输出的不同特征重要度得分进行排序,去除特征重要度得分较低的变量,以实现对特征数据集的降维,再将降维后的数据集输入到NBEATSx中训练,输出优化后的NBEATSx模型预测值1;
(3)将负荷数据集与特征数据集输入到STL模型中进行分解,降低数据的复杂度和噪音影响,再将分解后的趋势性分量、季节性分量与残差分量数据集分别输入到XGBoost进行预测,各分量的预测结果线性组合得出STL-XGBoost模型预测结果2;
(4)通过方差倒数法将预测结果1与预测结果2组合,得到最终的STL-XGBoost-NBEATSx组合模型预测结果,计算过程 [16]为
ωi=Q-1i∑mi=1Q-1i ,=ω11+ω22.(12)
式中,ωi为第i个模型的权重;m为组合模型数量;Qi为第i个模型的预测误差平方和。
3 模型构建与参数设置
3.1 小时天然气负荷影响因素
采集西安市灞桥区某天然气供应站2021年6月1日至2021年8月10日每小时的天然气负荷数据以及对应的气象数据、日期数据作为试验数据集,共71 d,每天采样24次,共计1 704个样本点,天然气采集点处的工况温度约为13 ℃,工况压力约为2.33 MPa。选取最后一周(7 d)的168条数据作为测试集,其余的1 536条数据作为训练集。
由于小时天然气负荷量会受到人们工作时间与休息时间的影响,例如白天对天然气的需求量大于晚上,休息时间的需求量大于工作时间,因此根据原始历史负荷数据构建了“小时影响度(hourly influence)”这一新特征,将训练集中天然气每一天同一个小时的负荷数据求和,取训练集中所有天各个小时天然气负荷总量在所有24小时天然气负荷总量中所占的比重为天然气负荷在相应时刻的小时影响度,计算式为
ωi=∑nj=1yij-min∑nj=1∑23i=0yijmax∑nj=1∑23i=0yij-min∑nj=1∑23i=0yij .(13)
式中,ωi为负荷数据在第i时刻的小时影响度;yij为第j天第i时刻的负荷数据;n为训练集中的总天数。
计算结果如图3所示,小时天然气负荷数据的“小时影响度”在每日0~6时刻小于0.1,但在10~21时刻却全部大于0.9。这符合人们夜晚休息时需求量小于白天工作时的实际情况。
因为历史负荷能够明显反映负荷的变化规律,因此把历史负荷值作为预测模型的输入特征,为了反映负荷数据的长期和短期关系,将每一负荷值的前24个小时的天然气历史负荷数据全部选取作为小时负荷预测的外部特征变量。
此外,选取气象数据:气温(℃)、湿度(%)、降水量(mm/h)、地面风速(m/s)。日期类型数据:工作日为0、周末与节假日为1,以及24个小时历史负荷值(-i 时刻/103 m3,i=1,2,…,24)共同构建一个含30个特征变量的天然气负荷数据初步特征集。
由于各特征值自身之间以及与负荷目标值之间的量纲不同,为了避免其对模型预测性能的影响,方便模型处理数据,提高模型收敛速度,将模型所有的输入数据进行归一化处理,在模型输出归一化预测值后再将其还原。归一化表达式为
i=xi-xminxmax-xmin .(14)
式中,i为第i个样本归一化后的值;xi为第i个样本真实值;xmax和xmin分别为样本中最大值和最小值。
3.2 基于XGBoost模型的特征筛选
特征变量多少以及自身的相关关系会影响模型的训练速度与精度,为了掌握不同特征因素对负荷的影响程度,有效提取和选择输入特征提高预测模型的性能,通过XGBoost模型的可解释模块输出每个特征的全局重要度,以实现特征分析与选择。
使用网格搜索和交叉验证(GridSearchCV)方法对XGBoost的主要超参数进行寻优,最终设置模型中树的数量为100,树的最大深度为3,树的学习率为0.05,这几个参数主要影响了模型的收敛速度与预测精度。
XGBoost模型输入特征变量为气温(℃)、湿度(%)、降水量(mm/h),地面风速(m/s),日期类型、小时影响度、-i时刻(103 m3,i=1,2,…,24)历史负荷值,其编号分别为f1、f2、f3、f4、f5、f6、f7~f30。
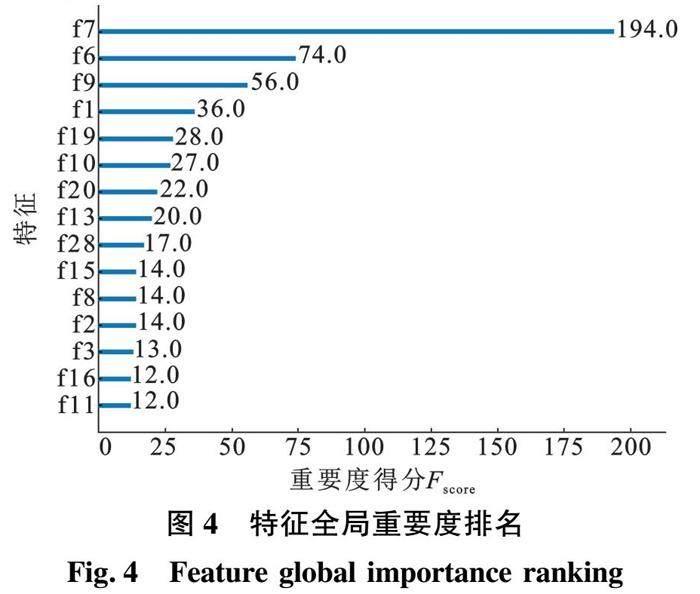
图4为模型最终输出的排名前15的特征全局重要度。
由图4可知,提出的新特征“小时影响度”对天然气小时负荷预测的重要度排第二,仅次于前1个时刻的历史负荷值对其的影响程度,表明了新特征对小时负荷预测的重要价值。前3个时刻的历史负荷值与气温等影响因素的重要度依次排名之后,为了降低输入数据维度,提高预测速度,去除重要度较低(重要度得分低于10)的特征,将图4中展现的剩余15个特征用作NBEATSx模型的外部变量输入数据。
3.3 基于NBEATSx模型的负荷预测
选择季节堆栈(seasonality)、趋势堆栈(trend)与外部变量堆栈(exogenous)作为NBEATSx神经网络基本结构,用来反映天然气小时负荷数据的趋势性与季节性以及外部特征变量对负荷的影响情况;由于小时天然气负荷数据呈现以日为周期的现象,将预测窗口步长H设置为24,同时为了更好地提取数据的长期信息,将输入窗口长度设置为7H,即168;采用SELU激活函数能够对神经网络进行自归一化,使得模型收敛速度更快且不会出现梯度消失与爆炸的问题,同时SELU激活函数必须配备lecun normal函数进行权重初始化。经过寻优,各堆栈中主要超参数设置:输入窗口长度L为168,预测窗口长度H为24,单个堆栈的块数为2,单个块中全连接网络层数为2,隐藏层神经元个数为64,采样频率为24,批处理大小为512,趋势性多项式次数为2,周期性傅里叶基数为1,迭代次数为25 000,优化器为Adam,学习率为0.002。
3.4 基于STL-XGBoost模型的负荷预测
先使用STL模型将天然气小时负荷数据同特征集数据一同分解为趋势分量、季节分量与残差分量,以小时负荷数据为例,经过STL分解后的结果如图5所示。将3个分量数据集分别输入到XGBoost模型进行预测,最后将预测结果线性相加得到STL-XGBoost负荷预测结果。对3种不同分量数据集预测任务的XGBoost超参数进行寻优,最优参数设置如表1所示。
4 实例仿真与对比分析
为了验证所提模型对小时天然气负荷预测的准确性与可靠性,将文中模型与当前一些经典单一模型和组合模型进行仿真对比分析,均采用滑动窗口的数据输入方式实现模型的多步预测。
4.1 评价指标
通过综合分析各模型的训练时间、均方误差(mean square error,Mse)、平均绝对误差(mean absolute error,Mae)、平均绝对百分比误差(mean absolute percentage error,Mape)以及决定系数(R2)来评价模型的整体预测性能。其中训练时间越短, Mse、Mae、Mape越小,模型的预测误差越小,性能越好。决定系数在0~1之间,该值越接近1,表明预测模型能够更好地解释观测数据的波动性,对真实数据的拟合程度更好。各评价指标计算式为
Mse=1n∑ni=1(i-yi)2, Mae=1n∑ni=1i-yi,Mape=1n∑ni=1i-yiyi,R2=1-∑ni=1(i-)2∑ni=1(yi-)2 .(15)
式中,n为测试样本数;yi和i分别为i时刻的负荷真实值和负荷预测值; 为测试集中负荷真实值的均值。
4.2 消融试验
通过消融试验来验证XGBoost特征筛选对NBEATSx网络预测的有效性以及“小时影响度”对模型预测性能的重要影响。表2为消融试验结果。由表2可以看出,经过XGBoost模型进行特征筛选后,NBEATSx模型的整体训练速度都有所提高,经过特征筛选且加入“小时影响度”这一特征的NBEATSx模型的预测精度达到最高,其中Mape、Mse、Mae分别降低了6.05%、7.64%、4.32%,训练时间降低了74.51%,决定系数也有所提高,这意味着通过XGBoost进行特征筛选提高了NBEATSx模型的预测性能。
4.3 单一模型预测结果
分别选取ARIMA、SVR、树模型中的lightGBM、XGBoost以及神经网络模型中的RNN、LSTM、GRU与NBEATSx的预测结果进行比较。各模型均采用网格搜索与GridSearchCV进行参数寻优,并设置窗口滑动完成模型的168步预测。
图6(a)是将NBEATSx(有特征筛选,有“小时影响度”)模型与其他神经网络模型预测结果进行对比,图6(b)是将其与非神经网络模型预测结果进行对比,表3为各单一模型的预测误差评价指标对比。
分析图6(a)可知,NBEATSx能比其他神经网络更好地拟合负荷波动较大的波峰与波谷处;分析图6(b)可知,XGBoost模型在负荷曲线变化平稳阶段有着优秀的拟合能力,但对负荷数据波动部分的反映能力仍不如NBEATSx模型。
分析表3可知,在单一模型的对比中,基于GBDT框架的lightGBM与XGBoost模型发挥了树模型擅长处理多维特征变量的优势,整体预测性能优于经典的RNN、LSTM、GRU神经网络与SVR模型;此外,由于XGBoost采用预排序算法,能够更精确地找出数据分裂点,表现出比lightGBM更高的预测精度;兼具树模型的可解释性与神经网络模型的预测性能优势的NBEATSx模型在试验结果中表现最佳,与经典神经网络中表现最好的GRU相比,
Mape降低了45.37%,Mse降低了55.96%,Mae降低了42.14%,R2提高了14.02%;与树模型中表现最好的XGBoost相比,Mape降低了23.32%,Mse降低了35.39%,Mae降低了12.22%,R2提高了5.56%,说明NBEATSx模型能够更好地挖掘出时序负荷数据之间的复杂非线性关系以及负荷数据与外部特征变量之间的复杂相关性关系。
4.4 组合模型预测结果
合适的模型组合会提高单一模型的预测性能,为了证明所提模型组合的优势,将XGBoost预测结果直接与经过特征筛选后的NBEATSx预测结果通过方差倒数法进行组合;另外,将经由STL分解后的负荷数据分别输入到单一模型预测试验中表现较好的GRU与XGBoost中进行预测;将这4种组合模型与本文中所提出的STL-XGBoost-NBEATSx模型的预测结果进行对比,如图7和表4所示。
由图7可以看出,STL对输入数据的分解降噪改善了XGBoost在波动较大部分拟合效果不好的情况,提高了波动部分预测曲线的拟合度。而本文中提出的STL-XGBoost-NBEATSx模型的预测曲线与真实数据曲线的拟合效果最好,既发挥了XGBoost模型在数据变化平稳部分的优秀拟合能力,又结合了NBEATSx模型在数据波动性较大情况下的拟合优势。
分析表4可知,组合模型的预测性能整体优于单一模型。经STL分解后的GRU预测精度虽然高于单一GRU,但仍低于单一NBEATSx,这是因为NBEATSx模型不同功能的堆栈结构可以看作对输入数据进行分解与预测的结合,使得训练过程更简化,训练结果更精确。
单纯将XGBoost与NBEATSx组合后,由于单一XGBoost模型预测精度不足,与NBEATSx的学习能力差距较大,从而导致组合模型的Mape反倒比NBEATSx(特征筛选后)要高,预测效果不能达到预期。由表4可知,将原始数据经由STL分解,再输入到XGBoost中进行预测,减弱了输入数据中噪音对模型预测的影响,所得STL-XGBoost模型的预测误差比NBEATSx模型更低,有效提升了XGBoost模型的预测性能。
STL-XGBoost-NBEATSx组合预测模型的子模型为优化后的NBEATSx与优化后的STL-XGBoost,满足差异化大、准确性高的条件,结合了两类子模型的优势,表现出最优的预测性能。与单一的XGBoost相比,Mape、Mse和Mae分别下降了38.85%、52.68%和29%;与单一的NBEATSx相比,Mape、Mse和Mae分别下降了25.07%、32.35%和22.62%,预测误差大大降低。模型的决定系数高达0.935,表明该模型能够很好地拟合原始负荷数据。图8为组合模型STL-XGBoost-NBEATSx与子模型的预测误差对比。由图8可以看出,组合模型的误差波动明显减小。在序列随机性与波动性较强的情况下,组合模型能够有效地提高模型的稳定性与预测精度。
5 结 论
(1)针对小时负荷预测引入“小时影响度”这一特征,可作为特征筛选后的重要外部变量,有效提高模型的预测效率。
(2)STL分解可以减小输入数据的复杂程度与噪声,解决XGBoost对数据敏感的问题,极大提高了XGBoost模型预测的稳定性与准确性。
(3)STL-XGBoost-NBEATSx组合模型结合了树模型与神经网络模型的优势,不仅有良好的可解释性,且相较于单一模型与其他组合模型,能更好地处理负荷时间序列中的线性与非线性特征,对负荷数据的平稳性与波动性具有更好的表征能力,能够有效减小负荷预测的误差,提高模型的预测精准性与预测速率,模型决定系数较高,预测性能可以满足天然气供输部门的精度需求。
(4)使用STL-XGBoost-NBEATSx预测模型进行短期预测可以提供更详细和精确的负荷信息,帮助制定准确的运营计划,进行实时预测可以支持实时能源调度和供应链管理。
参考文献:
[1] 刘合,梁坤,张国生,等.碳达峰、碳中和约束下我国天然气发展策略研究[J].中国工程科学,2021,23(6):33-42.
LIU He, LIANG Kun, ZHANG Guosheng, et al. Research on Chinas natural gas development strategy under the constraints of carbon peak and carbon neutrality[J]. Chinese Engineering Science,2021,23(6):33-42.
[2] 王坤,杨涛,梁坤,等.碳达峰碳中和战略下天然气的能源优势与发展建议[J].能源与节能,2023(3):27-31.
WANG Kun, YANG Tao, LIANG Kun, et al. Energy advantages and development suggestions of natural gas under the carbon peaking and carbon neutrality strategy[J]. Energy & Energy Conservation,2023(3):27-31.
[3] YOUSUF M U, AL-BAHADLY I, AVCI E. Wind speed prediction for small sample dataset using hybrid first-order accumulated generating operation-based double exponential smoothing model[J]. Energy Science Engineering,2022,10(3):726-739.
[4] 李焱,贾雅君,李磊,等.基于随机森林算法的短期电力负荷预测[J].电力系统保护与控制,2020,48(21):117-124.
LI Yan, JIA Yajun, LI Lei, et al. Short-term power load forecasting based on random forest algorithm[J]. Protection and Control of Modern Power Systems,2020,48(21):117-124.
[5] KIHAN K, JIN H. A study on the development of the short-term photovoltaic power forecasting system using support vector regression (SVR)[J]. Journal of the Korean Institute of Illuminating and Electrical Installation Engineers,2019,33(6):42-48.
[6] 窦益华,张佳强,李国亮,等.基于优化BP神经网络的连续管疲劳寿命预测[J].石油机械,2023,51(10):144-149.
DOU Yihua, ZHANG Jiaqiang, LI Guoliang, et al. Fatigue life prediction of coiled tubing based on optimized BP neural network[J].China Petroleum Machinery,2023,51(10):144-149.
[7] AHN H K, PARK N. DeepRNN-based photovoltaic power short-term forecast using power IoT sensors[J]. Energies,2021,14(2):436.
[8] 宋先知,朱硕,李根生,等.基于BP-LSTM双输入网络的大钩载荷与转盘扭矩预测[J].中国石油大学学报(自然科学版),2022,46(2):76-84.
SONG Xianzhi, ZHU Shuo, LI Gensheng, et al. Prediction of hook load and rotary drive torque during well-drilling using a BP-LSTM network[J]. Journal of China University of Petroleum (Edition of Natural Science), 2022,46(2):76-84.
[9] JUNG S, MOON J, PARK S, et al. An attention-based multilayer GRU model for multistep-ahead short-term load forecasting[J]. Sensors,2021,21(5):1639.
[10] 谭海旺,杨启亮,邢建春,等.基于XGBoost-LSTM组合模型的光伏发电功率预测[J].太阳能学报, 2022,43(8):75-81.
TAN Haiwang, YANG Qiliang, XING Jianchun, et al. PV output prediction based on XGBoost-LSTM combination model[J]. Acta Energiae Solaris Sinica,2022,43(8):75-81.
[11] 邵必林,严义川,曾卉玢.注意力机制下的VMD-IDBiGRU负荷预测模型[J].电力系统及其自动化学报,2022,34(10):120-128.
SHAO Bilin, YAN Yichuan, ZENG Huibin. VMD-IDBiGRU load forecasting model under attention mechanism[J]. Proceedings of the CSU-EPSA,2022,34(10):120-128.
[12] 陈岚,张华琳,汪波,等.基于XGBoost和改进LSTNet的气温预测设计[J].无线电工程,2023,53(3):591-600.
CHEN Lan, ZHANG Hualin, WANG Bo, et al. Temperature prediction design based on XGBoost and improved LSTNet[J]. Radio Engineering,2023,53(3):591-600.
[13] 范豆,范锦涛.城市燃气负荷影响因素及预测方法分析[J].云南化工,2018,45(11):113-114.
FAN Dou, FAN Jintao. Analysis of influencing factors and forecasting methods of city gas load[J].Yunnan Chemical Technology,2018,45(11):113-114.
[14] QIN L, LI W D, LI S J, et al. Effective passenger flow forecasting using STL and ESN based on two improvement strategies[J]. Neurocomputing,2019,356:244-256.
[15] OLIVARES K G, CHALLU C, MARCJASZ G, et al. Neural basis expansion analysis with exogenous variables: forecasting electricity prices with NBEATSx[J]. International Journal of Forecasting,2023,39(2):884-900.
[16] 詹英.组合预测方法在我国人均 GDP 预测中的应用[D]. 武汉:华中师范大学,2014.
ZHAN Ying. Application of combined forecasting method in Chinas per capita GDP forecast[D]. Wuhan:Central China Normal University,2014.
(编辑 沈玉英)
基金项目:国家自然科学基金项目(62072363)
第一作者:邵必林(1965-),男,教授,硕士,博士生导师,研究方向为大数据、人工智能、数据信息与管理、能源可持续发展。E-mail: sblin0462@sina.com。
通信作者:任萌(1999-),女,硕士研究生,研究方向为能源预测、机器学习、数据信息与管理。E-mail: rmeng0123@163.com。
引用格式:邵必林,任萌,田宁.基于STL-XGBoost-NBEATSx的小时天然气负荷预测[J].中国石油大学学报(自然科学版),2024,48(3):170-179.
SHAO Bilin, REN Meng, TIAN Ning. Hourly natural gas load forecast based on STL-XGBoost-NBEATSx[J]. Journal of China University of Petroleum (Edition of Natural Science),2024,48(3):170-179.
