
深度学习在图书馆文本分类中的应用研究进展
2024-06-24 14:22:10孙祝丽
新世纪图书馆 2024年4期

摘 要文本分类是图书馆领域的重要研究方向之一。基于深度学习方法对用户生成的内容进行分类有助于图书馆更精准的了解用户行为并评估图书馆服务质量。通过对图书馆领域和使用图书馆数据的计算机科学领域使用深度学习方法进行文本分类的研究进行批判性审查,调查图书馆领域使用深度学习方法进行文本分类的研究现状,为未来研究提出建议。研究结果表明,目前的研究主要集中在文本特征分类、文本情感分类和文本评级分类上。大多数研究仍采用传统的深度学习方法如前馈神经网络和人工神经网络等。近年来在计算机科学领域提出的具有更好分类性能的深度学习算法尚未引入图书馆领域。研究建议引入深度学习算法的方法框架、构建和开发更深层次的算法、明晰文本分类的详细步骤、明确数据标注规范和标注步骤并积极使用结合各自优势的多模型分类方法。
关键词图书馆;文本分类;深度学习;批判性反思
分类号G251.2
A Review of Research on the Application of Deep Learning in Library Text Classification
Sun Zhuli
AbsrtactText categorization is a major research direction in the field of library. Classifying user-generated content based on deep learning methods can help libraries understand user behavior more accurately and evaluate the quality of library services. This paper makes recommendations for future research by investigating and critically reviewing research on the use of deep learning methods for text classification in the library field and in the computer science field using library data. The results show that the current research mainly focuses on text feature classification, text sentiment classification and text rating classification. Most research still uses traditional deep learning methods such as feedforward neural networks and artificial neural networks. Deep learning algorithms with better classification performance in computer science have not been introduced to the library domain. The study recommends introducing a methodological framework for deep learning algorithms, building and developing deeper algorithms, clarifying detailed steps for text classification, specifying data annotation specifications and annotation steps, and actively using multi-model classification methods that combine their respective strengths.
KeywordsLibrary. Text classification. Deep learning. Critical reflection.
0 引言
通过对用户信息或行为记录等内容进行分类可以获取文本特征,获取用户的情绪、感受、体验、偏好和评级等数据,从而有助于图书馆了解用户行为并评估图书馆的服务质量和满意度[1-2]。文本分类是根据一定的规则将文本分为不同类别的过程。分类规则可以人工构建,也可以使用算法从文本数据中自动总结。早期的文本分类是在知识工程的基础上构建人工定义规则,例如,通过编码采访文本和提取关键节点来构建研究维度。近年来,已有学者充分利用Twitter、Facebook、Google Maps、微博、大众点评网、微信公众平台等网站的大量用户生成的文本数据研究用户行为和图书馆服务质量[3-4]。文本分类不仅是数据挖掘与信息检索领域的研究热点,更是数字图书馆建设的技术基础[5]。同时,对用户生成的文本数据进行准确的分类还可以帮助图书馆把握用户的信息需求特征,组织和筛选用户感兴趣的内容,进而为用户提供智能和高效的个性化服务。另外,提取和计算用户生成文本中包含的情感信息和情感强度,关注用户的情感变化,还可以帮助图书馆不断改进服务的设计和提供方式。因此,文本大数据的分类需要引起图书馆领域的关注,而有关文本分类的研究已成为统计分析、维度构建、量表开发、预测建模的重要前提和基础。
作为自然语言处理领域的经典问题,文本分类的算法也在不断演进,当前的算法大致分为两类:一种是传统的分类算法(如基于规则的方法、社会网络分析方法等)、一种是基于机器学习的算法(如 特征工程、分类器等)[6]。受到算法本身的限制,传统的分类算法耗时耗力,成本较高,已逐渐被取代。与自然语言处理领域的发展同步,图书馆文本分类也逐渐从主要使用社会网络分析转变为机器学习和深度学习方法,从简单的用户生成文本的词频统计转变为挖掘文本中的深层语义关联,力求更精确地发现用户的感知和情感[7-8]。在大规模和非结构化的文本中寻找有效的隐含信息挖掘方法已成为自然语言处理(NLP)关注的焦点和大数据研究中的关键问题[9],而深度学习的出现可以有效解决以往机器学习方法(如朴素贝叶斯和支持向量机)存在的耗时、昂贵的浅层结构算法、表示复杂函数的能力有限以及难以处理高维数据和泛化能力差等问题[10]。基于深度学习的文本分类研究在各种自然语言处理任务中取得了显著的成效,为许多问题提供了有效的解决方案,因而正逐渐取代传统的机器学习方法成为文本分类领域的主流研究方向[11]。在图书馆领域,深度学习方法同样处于文本分类的最前沿,已有研究表明在预测评论可靠性、用户满意度、情感分类和预测评论评级等方面优于传统的机器学习模型[12]。
显然,深度学习方法对图书馆的文本分类具有重要意义。2023年7月30日,笔者通过“标题/主题”在SCOPUS、WOS、LISTA、LISS、知网等数据库进行了全面的文献检索。搜索策略包括系列搜索词:文本分类、深度学习和图书馆的组合搜索,除了关注于图书馆领域深度学习的文章外,还包括计算机科学领域的相关研究,这些研究涉及到了深度学习技术与图书馆数据的使用。在剔除重复与不相关的文献,并对相关文献的参考文献进行回溯检索后,共筛选出31篇文章作为本文综述的文献集。研究成果数量不多说明该领域尚未成熟,需要进一步的研究探索,为此,本文设计的研究问题是:深度学习在图书馆文本分类研究中的现状如何?研究的主题包含那些?未来研究应当从那些方面拓展?下文将梳理图书馆领域基于深度学习进行文本分类的相关研究内容,并探讨当前存在的问题及优化建议,以期为未来的相关研究提供参考。
1基于深度学习开展图书馆文本分类研究的主题分析
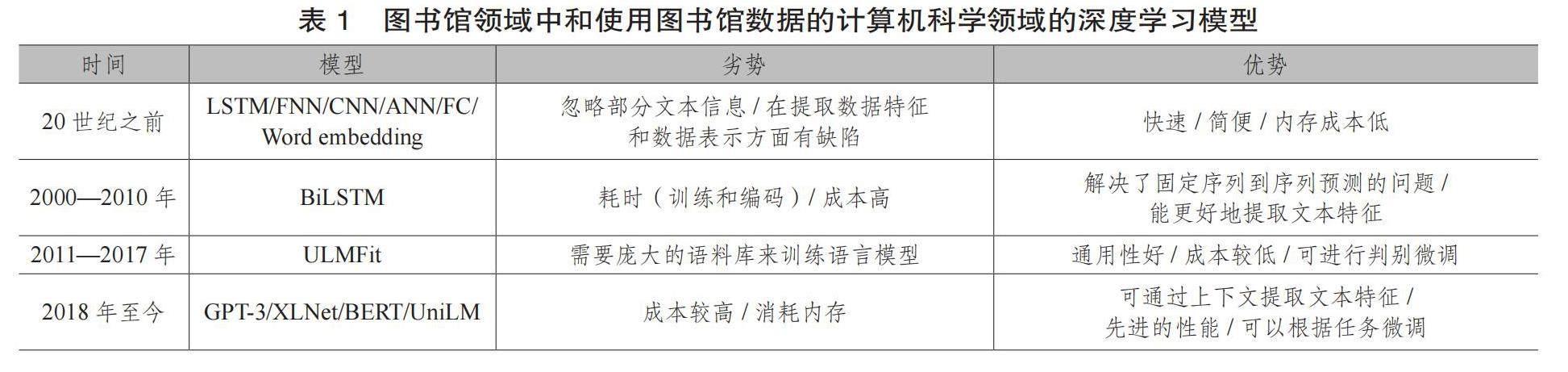
近年来,深度学习在图书馆领域的应用逐渐受到学者的关注。在这方面,计算机科学领域的学者有着特殊的贡献。通过对已有文献的调研梳理和系统分析,我们发现,当前深度学习在图书馆领域的应用主要包含以下几个方面:用户画像[13]、智慧服务[14-15]、文本识别[16]、知识库建设[17]、文本分类分析[18]等。然而,当前尚未有研究系统回顾深度学习方法在图书馆领域的使用情况。因此,我们归纳汇总了图书馆领域以及使用图书馆数据的计算机科学领域的深度学习文献,总结了图书馆领域及使用图书馆数据的计算机领域中使用深度学习模型的历史变迁、每种方法的优劣势(见表1),以及不同深度学习模型的应用场景和主要功能目标(见表2)。
从表2可以看出,当前基于深度学习开展图书馆文本分类的研究主要分为三个主题:文本特征分类、文本情感分类和文本评价分类。
1.1文本特征分类
对于用户感知和体验的研究,重要的是识别在线评论中影响用户评分和行为的关键特征(如服务质量、真实性、环境等)。尽管对文本特征的分类很重要,但多数研究使用了相对更为简单的主题聚类方法,只有少数研究使用深度学习模型对其进行研究。例如,有研究者利用基于深度学习的自然语言处理技术,对12582 条人工标注的图书馆在线评论进行研究,通过文本特征分析服务质量。在该模型中,神经网络用于从非结构化文本中发现模式,并将前馈神经网络组合起来表示输入层和输出层之间的非线性关系(服务质量的类别概率)[19];有研究者使用深度学习模型对手动标记的数据进行文本分类,以确定用户体验的真实性维度。该研究中使用的人工神经网络(ANN)模型具有两层网络,可以将输入数据(句子)映射到期望值(每个维度的概率),从而表示更复杂的函数关系[20];还有研究者通过多标签文本降维、平衡化处理及组合多种深度学习算法构建文本分类器,实现了多标签文本特征分类[21]。这类型研究一般通过叠加累积卷积层和池化层来持续对层数进行加深,从而达到提取更高层文本特征的效果,使得基于文本特征的分类表达能力更强,文本特征更为明显。
1.2文本情感分类
尽管情感分析在图书馆服务质量的评估中很重要,但目前文本的情感分类主要是使用情感词典和机器学习进行的,使用深度学习对文本情感进行分类的研究并不多。一项研究从微博上抓取了112 412 条关于图书馆的评论,并应用双向 LSTM、简单嵌入及平均池化这两种深度学习模型,对在线评论的两种情绪(正面和负面)进行分类,结果表明,双向 LSTM 在情感分类上更有效,该研究旨在为文本情感挖掘任务提供合适的深度学习算法[22];另一项研究使用深度学习模型 BERT分析了包含4728 条评论的图书馆数据集,将标签分为四类(中性、正面、负面和冲突),研究结果表明该模型比其他基线模型具有更好的性能,为图书馆文本情感分类任务提供了一种新方法[23];还有学者通过Tensor Flow深度学习框架,利用Keras人工神经网络库,将卷积神经网络和双向长短时记忆网络结合,构建了基于CNN-BiLSTM-HAN混合神经网络的情感分析模型,对高校图书馆社交网络平台用户评论的21 091条数据进行分析[24]。这些研究的重要贡献在于关注了图书馆用户情绪变化,使用双向LSTM 解决了循环神经网络梯度消失和梯度爆炸问题,与LSTM相比,这不仅保留了过去的信息,还保留了未来的信息。
1.3文本评级分类
对在线评论中的服务质量进行综合评价,不仅要采用用户给出的评价,如图书馆的价值、服务、位置和整体功能方面的评价,还应考虑评论信息中隐含的含义。研究者一般通过查找句子中的情感词、连词和否定词来获得情感分级,而这需要随着新词的出现不断增加和更新情感词典,同时还要考虑到每个词在不同的位置或语境下有不同的应用和效果,会表达不同的情感。文本评级分类的深度学习研究主要是利用在线文本的评分作为标签,训练用于文本分类的深度学习模型。在这方面,深度学习模型在提取文本特征时考虑了句子中每个词的上下文,可以解决同一个词在不同上下文中可能具有不同含义的问题,但很少有研究在数据集上使用深度学习来解释这种不同的含义。例如,一项研究使用深度学习算法在公开可用的数据集上训练模型,该数据集包含6294条在线评论和评级信息,并使用经过训练的深度学习分类模型内核获得用户评级[25]。同时,不同算法的性能也有所不同。有学者使用深度学习算法对图书馆评论文本评分预测进行了比较分析,发现基于在线评论评分,简单嵌入和平均池化相比双向LSTM 表现出更好的预测性能,评估指标R2和F1-score的变化分别提高5.8%和0.3%。此外,为了获得更适合文本评级分类的深度学习模型,该研究对深度学习领域的文本分类算法进行了总结,并在包含3500000余条图书馆评论的公开数据集上使用八种深度学习算法进行了测试。结果表明,与其他基线深度学习模型相比,BERT、XLNet 和通用语言模型微调等算法的准确率提高了约10%。在这些最先进的文本分类方法中,XLNet 在数据集上产生了最好的五个分类结果,准确率为72.2%[26]。
2当前研究存在的问题及优化建议
2.1存在的问题
2.1.1缺乏引入深度学习算法的方法框架
从整体上看,当前图书馆领域使用深度学习算法进行文本分类的研究仍然处于起步阶段,研究成果的数量不多,研究者对深度学习算法的认识和运用还有不足,存在盲目使用和跟风等问题,尤其是缺乏使用深度学习算法的方法框架,很多研究对算法的优劣势和适用性了解不够,致使研究结论的准确性受到影响。
2.1.2缺乏更先进的深度学习算法
已有研究来对多个深度学习模型文本分类方法的有效性进行了比较 (如fully connected,dense layers,2D convolution neural network,CNN,long short-term memory, LSTM),这些算法在提取文本信息方面的局限性较大:如FC对空间结构的表达能力较差、CNN会丢失相关信息导致误分类、LSTM在训练过程中只能保留单一信息等[27]。现有的许多研究并没有尝试使用更先进的深度学习方法来对评论进行科学分类,也缺乏对单个分类模型有效性的关注。这类型的研究往往依赖于公开可用的数据集,这些数据集中的每条评论都有用户给出的评分。然而,由于用户评级过程中可能存在服务补偿[28],因此后者不一定总是与评论文本所表达的信息相匹配,因此最好将评论和评分综合分析。
2.1.3文本特征分类的精度和效率有待提升
当前图书馆领域的文本特征分类主要使用前馈神经网络和ANN这两种深度学习算法。尽管前馈神经网络是经典的深度学习算法之一,也基本能够完成文本分类任务,但这种算法将文本视为一个词袋,并使用文本的向量或平均值来表示文本信息,而忽略了文本中的上下文信息,因而会影响分类的精度和效率。
2.1.4缺乏对文本分类过程的详细描述
现有的研究虽然或多或少涉及到文本分类的一些步骤,但很少系统地总结和说明了文本分类的整个过程(如文本预处理、多个文本分类模型的比较等),而只有详细描述文本分类的整个过程,才能提高研究的透明度,进而评价研究的质量、研究方法的严谨性和局限性,从而更好的完成文本分类任务。
2.1.5数据规模、数据预处理和数据标注等方面仍然存在局限性
在文本情感分类方面,当前的研究仅通过两种或三种情感分类很难衡量和捕捉用户复杂多样的情感。同时,许多研究的数据量不够大或不充分,导致对深度学习文本分类模型训练过程特征提取的要求变得非常高。虽然有研究者通过计算用户给出的价值、满意度等评分的平均值来标记情感标签,通过划分分数段来进行标注[29],但显然该研究的数据标注过程也需要改进。一是研究者未给出分数段分类的解释和依据,二是三级分类的粗粒度度量会导致有价值信息的丢失。
2.2优化建议
2.2.1明确引入深度学习算法的方法框架
计算机信息科学是探索文本分类深度学习的专业领域,因此我们可以在批评性比较和分析的基础上,结合图书馆的特征,为图书馆的文本分类任务引入一个方法框架。本研究认为,该方法至少应包括如下三个步骤:(1)方法选择:对于特定场景下的分类任务,不仅要根据方法的原理和已有的研究成果进行初步筛选,还要对多种方法进行比较,以获得最适合的方法;(2)数据选择:与图书馆领域的分类任务大多只在单个数据集上进行不同,计算机信息科学领域的研究是在多个数据集上进行测试,这也要求我们进行多数据集对比以获得更可靠的调查结果;(3)性能测试:对深度学习模型分类性能的评估是必不可少的步骤,每种方法的性能都可以通过完善的指标进行客观的测量。
2.2.2构建和开发更深层次的算法
双隐层神经网络比单层神经网络能表达更复杂的关系,分类效果更好。因此,图书馆领域需要不断加强对深度学习算法的理解,并尝试构建和开发更深层次的算法。与经典深度学习算法和基线方法(如情感词典和机器学习)相比,已经有几种深度学习算法具有更好的性能,可以用于文本特征分类任务。例如,2018年谷歌提出的自然语言模型(NLP) 基于Transformer的双向编码器表征(Bidirectional Encoder Representations from Transformers, BERT), 具有标记嵌入、片段嵌入和位置嵌入的输入特征,该模型使用掩码语言模型(随机屏蔽句子中的标记)进行训练,并通过双向转换器获得文本的矢量化表示。BERT结合单词的上下文信息,从句子中提取信息,实现了文本的双向表征,即使在数据量很小的情况下也能训练参数,因而可以更好地提取句子的语义关系,进而很好的完成文本分类任务。已有研究表明BERT在特征提取方面优于用于词表示的全局向量(Glove)和用于特征提取的词到向量(word2vec),并且还优于诸如多注意力网络(MAN)和交互式多头注意力网络(IMAN)等其他模型[30]。值得注意的是,使用BERT模型进行训练和测试所花费的时间与硬件密切相关,如使用张量处理器(TPU)比使用图形处理器(GPU)更为省时[31]。而BERT优化后的变体ALBERT可以更快地训练并且消耗更少的内存,这意味着使用ALBERT模型进行分类更为高效且成本更低。
2.2.3明晰文本分类的详细步骤
为提高文本分类任务中详细步骤的透明度,需要在收集数据并确定文本分类需求之后,进行以下两个关键步骤:数据预处理和模型训练。第一步是数据预处理,对于不同的语言,处理手段略有不同。以中文为例,其中标记化的过程如下:(1)删除数据中重复的文本;(2)将所有文本数据进行格式化;(3)删除网站链接、数字、符号和特殊字符,如&、*和#等;(4)分词——根据文本分类任务的需要将文本分解成词,然后进行处理;(5)删除标点符号和停用词;(6)归一化,如词形还原、词干提取、去除性别/时间/等级差异等。第二步是深度学习文本分类模型的训练,这是文本分类任务的重点。在这一步中,首先是数据集的划分,计算机领域中一般将数据集分为训练集(训练模型)、验证集(优化模型)和测试集(评估模型)。在图书馆领域,数据集一般分为训练集和测试集。划分训练集和测试集的一般原则是,当数据集足够大(几十万或几百万)时,测试集所占比例较小,反之亦然。其次,使用预训练的语言模型将数据集(训练集和测试集)转化为向量,即计算机可以理解的形式将分类模型应用到训练集和测试集上。最后,评估分类模型的性能。文本分类有多种评估指标,包括精度Accuracy、准确率Precision、召回率Recall和F1 score(包括准确率和召回率)、Cohen′s Kappa(k)和Gwet的一致性系数(AC1)等。其中,使用最广泛的评估指标是精度。
2.2.4明确数据标注规范和标注步骤
由于数据是文本情感分类任务的基础,一般而言,文本数据量越大,文本分类的效果越好。因此,图书馆领域的文本分类研究有必要进一步扩大研究的数据量,并明确标注规范和数据标注步骤。本文认为,文本数据的标准规范包括以下几个方面:(1)明确标注的范围和实体类型;(2)标签和类别要简洁明晰,并与文本数据所表示的概念相符;(3)明确标注规则,避免概念混淆和错误;(4)按照特定的格式和结构来标注数据,使其适配标注工具或平台;(5)完善关系和实体间的一体性,便于之后的关系抽取和分析;(6)确保标注数据的复用性和开放性,以便后续对模型进行评估、优化和升级。另外,对于文本数据的标注大致可以分为两个步骤,每一个文本(如评论)需要由至少三位相关领域人士进行标注并达成共识:第1步,随机抽取少量评论由相关专家对其进行标注,通过讨论达成共识,并构建分类协议。第2步,由至少3人组成的小组根据分类协议对文本数据进行标注,结果相同的3个标注可以直接使用,结果不同的标注可以考虑拒绝或讨论同意后保留。
2.2.5使用结合各自优势的多模型分类方法
通过文献梳理表明,XLNet能更好的完成文本评级分类任务,它集成了自回归和自编码预训练语言模型的思想,允许上下文同时包含左右标记(每个位置从所有位置学习上下文信息,即捕获双向上下文),使其成为通用的顺序感知自回归语言模型。它还引入了双流自注意模型,以实现位置感知的单词预测。同时,开放生成式预训练(OpenGPT)和统一语言模型(UniLM)也适用于图书馆领域的文本分类。OpenGPT是一个单向(从左到右或从右到左)逐词预测文本序列模型,其中每个单词包含有关前一个单词的信息。文本分类任务可以通过将OpenGPT微调到特定任务并将其与特定于任务的分类器相结合来完成。而OpenGPT的第4版,即OpenGPT-4已被证实可以大大提高模型在文本分类任务上的性能[32]。UniLM使用来自单向、双向和序列到序列方法的三种不同类型的语言建模任务进行预训练。 因此,UniLM-2在文本分类任务上达到了一个新的水平,它可以在文本文档的每个单词中包含更多的上下文信息。在图书馆领域,研究者可以通过多模型的组合运用和比较来进行探索和分析。
3总结与展望
3.1 结论
本研究首次回顾和梳理了图书馆领域使用深度学习方法进行文本分类的研究,指出了当前图书馆文本分类任务中各种方法和数据的不足,有助于推进相关研究。目前图书馆领域使用深度学习算法进行文本分类的研究可以大致分为文本特征分类、文本情感分类和文本评级分类三个主题。在研究方法方面,主要使用的是前馈神经网络和人工神经网络,而计算机科学领域中更先进的方法尚未引起重视。除研究方法外,现有研究中使用的数据还涉及在不同背景下的适用性问题。目前采用的公开数据集主要以用户评论为主,缺乏直接采用用户评分作为标签的研究。另外,研究发现目前图书馆领域对文本的分类还比较粗放(主要分为两类或三类),缺乏更细粒度的文本分割维度。回顾现有的研究,本文建议采用可以从海量大数据中更快、更准确地进行细粒度文本分类的前沿深度学习方法,并提出了数据集标注的具体方法,为未来研究的方法选择和创新提供了路径。此外,本文再次强调了对文本情感进行准确分类的重要理论基础以及基于文本特征的维度构建,指出引入新的文本分类算法可以实现更准确的文本分类。这也有助于在特定图书馆环境中开发带标签的图书馆数据集和分类维度,为进一步研究用户评论对其使用行为的情感影响(如维度构建、量表开发等)奠定基础。同时,本文对计算机领域新方法的引入,有助于弥合图书馆领域研究方法的差距。
本文的研究结果对图书馆的管理实践也有一定启示。由于当前在线文本呈指数级增长,手动处理可能既昂贵又耗时,而使用深度学习技术可以从文本数据中更快、更准确、成本更低的提取上下文信息。例如,图书馆可以使用基于文本特征的深度学习方法来根据服务质量(响应性、可靠性和同理心)对用户评论进行分类,并使用情感分类器将评论分类为更细粒度的情感(愤怒、喜悦和厌恶等)。这些方法有助于客观、快速地了解全面的信息和其中的细节,帮助图书馆及时响应用户需求,为图书馆的管理和决策提供依据。
此外,这项研究还为第三方机构全面评价图书馆的服务质量提供了有效途径,用户也可以通过参考第三方机构在分析文本内容的基础上给出的综合评价来评估图书馆服务的质量。由于服务补偿和心理补偿因素的存在,总体评价信息并不能完全反映用户对图书馆的评价。政府相关部门或第三方机构可以使用深度学习算法对文本进行分类,不仅可以单独使用评分信息,还可以综合文本分类结果,更便捷的评估图书馆服务质量,指导图书馆的建设和发展。
3.2 局限性和未来研究
首先,尽管一些先进的深度学习方法在文本分类任务中表现出出色的分类性能,但它们在图书馆领域的表现尚未得到证实。例如,当前最新的深度学习算法,如OpenGPT-3、BERT、XLNET和UniLM等,已经在文本分类任务中实现了新的进展,但尚未有在图书馆领域中的应用。因此笔者建议学者们对这些算法进行实验。由于训练这些模型的成本并不高,因此可以微调现有模型或使用它们的变体,特别是对于图书馆领域来说,建议使用和测试集成多种深度学习算法的模型。此外,由于基于单一模型的分类对于不同的语料库、分类和标签可能表现的不够稳定,因此本研究建议在同一数据集上使用多个深度学习模型,并通过比较找到最适合的深度学习文本分类模型。
其次,虽然在图书馆领域有一些大规模的数据集,但这些数据集直接或间接地将用户的评分作为标签,这种做法忽略了用户在线评分时的服务补偿和心理补偿,同时,图书馆领域的相关数据集共享程度不够,因此,本研究建议学界和业界重视数据集的标注,严格按照完善的步骤对文本数据集进行手工标注[33],并共享更多的结构化标注数据,促进图书馆领域文本分类的发展。
再次,由于图书馆用户情绪的复杂性,将其划分为两类或三类情感维度,其实践和理论意义有限,后续研究有必要测试不同的方法,开发不同的数据,并在图书馆的不同场景下进行不同层次的工作。因此,本研究建议未来的研究构建更细粒度的文本数据分类。例如,基于深度学习模型用来研究用户情感(喜悦、爱、惊讶、愤怒、信任和悲伤)、服务质量(有形的、可靠的、响应性、保证和同理心)和其他更细化的维度。
最后,这项研究是对现有期刊论文中相关主题的梳理和总结,不包括会议论文、书籍等其他来源的文献,因而具有一定的局限性。未来的研究可以对多种方法、多种来源的文献进行比较分析,从而获得更可靠的研究结果。
参考文献:
[1]王芳,夏晓慧,宋家梅.基于文本分析的高校图书馆服务创新研究[J].图书馆学研究,2019(21):2-9.
[2]ZHENG X, CHEN W, ZHOU H, et al. Emoji-integrated polyseme probabilistic analysis model: sentiment analysis of short review texts on library service quality[J]. Traitement du signal, 2022, 39(1):313-322.
[3]金武刚,钟静涵.技术时代公共图书馆“场所”价值的社会公众认知研究:基于公共平台网络评论文本分析[J].图书馆杂志,2022,41(1):17-28.
[4]NGUYEN M. Use of social media by academic libraries in australia: review and a case study[J]. Journal of the australian library and information association,2023,72(1):75-99.
[5]李社蕾,周波,杨博雄.图马尔可夫卷积神经网络半监督文本分类研究[J].计算机仿真,2022,39(9):288-292.
[6]林鹤,曹磊,夏翠娟. 图情大数据[M].上海:上海科学技术出版社,2020:50.
[7]徐彤阳,尹凯.基于深度学习的数字图书馆文本分类研究[J].情报科学,2019,37(10):13-19.
[8]LIU C. Research on library book information resource management based on artificial intelligence and sensors[J]. Journal of sensors,2022: 3720811.
[9]ELNAGGAR A, HEINZINGER M, DALLAGO C, et al. Prottrans: Toward understanding the language of life through self-supervised learning[J]. IEEE transactions on pattern analysis and machine intelligence,2021,44(10):7112-7127.
[10]MINAEE S, KALCHBRENNER N, CAMBRIA E, et al. Deep learning--based text classification: a comprehensive review[J]. ACM computing surveys(CSUR),2021,54(3):1-40.
[11]OTTER D W, MEDINA J R, KALITA J K. A survey of the usages of deep learning for natural language processing[J]. IEEE transactions on neural networks and learning systems,2020,32(2):604-624.
[12]RAGAB M, ALMUHAMMADI A, MANSOUR R F, et al. Natural language processing with deep learning enabled hybrid content retrieval model for digital library management[J]. Expert systems,2022: e13135.
[13]刘海鸥,黄文娜,姚苏梅等.基于深度学习的移动图书馆用户画像情境化推荐[J].图书馆学研究,2019(21):57-64.
[14]李默.基于深度学习的智慧图书馆移动视觉搜索服务模式研究[J].现代情报,2019,39(5):89-96.
[15]SHI X, HAO C, YUE D, et al. Library book recommendation with CNN-FM deep learning approach[J]. Library hi tech,2023(1):48-56.
[16] LIU Z, ZHAO W. Comparative research on structure function recognition based on deep learning[J]. Library hi tech,2022(6):1-16.
[17]张凌云.基于深度学习的《资本论》汉英术语知识库建设与应用研究[J].图书馆工作与研究,2023(2):20-27+50.
[18]WU Y, WANG X, YU P, et al. ALBERT-BPF: a book purchase forecast model for university library by using ALBERT for text feature extraction[J]. Aslib journal of information management,2022,74(4):673-687.
[19]JOO S , LU K , LEE T. Analysis of content topics, user engagement and library factors in public library social media based on text mining[J].Online information review,2020,44(1):258-277.
[20]WU P , LI X , SHEN S ,et al.Social media opinion summarization using emotion cognition and convolutional neural networks[J].International journal of information management,2020(51):101978.
[21]程雅倩,黄玮,金晓祥,等.5G环境下高校图书馆自媒体平台多标签文本分类方法研究[J].情报科学,2022,40(2):155-161.
[22]ZHENG X, CHEN W, ZHOU H J, et al. Emoji-Integrated polyseme probabilistic analysis model: sentiment analysis of short review texts on library service quality[J].Traitement du signal,2022(39):313-322.
[23]SCIASCIO C D, STROHMAIER D, ERRECALDE M, et al. Interactive quality analytics of user-generated content: an integrated toolkit for the case of wikipedia[J]. ACM transactions on interactive intelligent systems(TiiS),2019,9(2-3):155-196.
[24]李博,李洪莲,关青等.基于CNN-BiLSTM-HAN混合神经网络的高校图书馆社交网络平台细粒度情感分析[J].农业图书情报学报,2022,34(4):63-73.
[25]马佳滢,金武刚.国外公共图书馆“场所”价值的公众认知研究——基于Google Maps在线评论文本分析[J].图书与情报,2022(3):6-19.
[26]BORREGO ?, COMALAT N M. What users say about public libraries: an analysis of google maps reviews[J]. Online information review,2021,45(1):84-98.
[27]MINAEE S, KALCHBRENNER N, CAMBRIA E, et al. Deep learning: based text classification: a comprehensive review[J]. ACM computing surveys(CSUR),2021,54(3):1-40.
[28]ROSCHK H, GELBRICH K. Identifying appropriate compensation types for service failures: a meta-analytic and experimental analysis[J]. Journal of service research,2014,17(2):195-211.
[29]陈信.基于媒介传播效果框架的图书馆短视频评论文本分析[J].图书馆学研究,2023(2):76-81.
[30]?Z?IFT A, AKARSU K, YUMUK F, et al. Advancing natural language processing(NLP) applications of morphologically rich languages with bidirectional encoder representations from transformers(BERT):an empirical case study for Turkish[J]. Automatika: ?asopis za automatiku, mjerenje, elektroniku, ra?unarstvo i komunikacije,2021,62(2):226-238.
[31]LI X, FU X, XU G, et al. Enhancing BERT representation with context-aware embedding for aspect-based sentiment analysis[J]. IEEE access,2020(8):46868-46876.
[32]王静静,叶鹰,王婉茹. GPT类技术应用开启智能信息处理之颠覆性变革[J]. 图书馆杂志,2023,42(5):9-13.
[33]RAVE J I P, ?LVAREZ G P J, MORALES J C C.Multi-criteria decision-making leveraged by text analytics and interviews with strategists[J]. Journal of marketing analytics,2022(10):30-49.
孙祝丽 绍兴图书馆馆员。浙江绍兴,312000。
(收稿日期:2023-10-20 编校:谢艳秋)
猜你喜欢
小太阳画报(2018年1期)2018-05-14 17:19:25
计算机应用(2016年12期)2017-01-13 01:24:36
电子技术与软件工程(2016年22期)2016-12-26 12:56:34
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
少年博览·小学低年级(2016年10期)2016-11-24 06:48:23
数字技术与应用(2016年9期)2016-11-09 23:23:56
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
科技视界(2016年24期)2016-10-11 09:36:57
