
基于神经网络的VSLAM综述
2024-06-20 20:18尚光涛陈炜峰吉爱红周铖君王曦杨徐崇辉
南京信息工程大学学报 2024年3期
尚光涛 陈炜峰 吉爱红 周铖君 王曦杨 徐崇辉

摘要:传统的基于视觉的SLAM技术成果颇丰,但在具有挑战性的环境中难以取得想要的效果.深度学习推动了计算机视觉领域的快速发展,并在图像处理中展现出愈加突出的优势.将深度学习与基于视觉的SLAM结合是一个热门话题,诸多研究人员的努力使二者的广泛结合成为可能.本文从深度学习经典的神经网络入手,介绍了深度学习与传统基于视觉的SLAM算法的结合,概述了卷积神经网络(CNN)与循环神经网络(RNN)在深度估计、位姿估计、闭环检测等方面的成就,分析了神经网络在语义信息提取方面的优点,以期为未来自主移动机器人真正自主化提供帮助.最后,对未来VSLAM发展进行了展望.
关键词同时定位和地图构建(SLAM);深度学习;卷积神经网络(CNN);循环神经网络(RNN);位姿估计;闭环检测;语义
中图分类号TP242;TP391.41
文献标志码A
0引言
移动机器人执行任务的首要前提是确定自己在所在环境中的位置[1].室外空旷环境下,基于GPS的定位方法可以基本满足机器人的定位需求,但有时接收不到GPS信号[2].室内环境中,通常需要提前设立导航信标如二维码、磁条等,这大大限制了移动机器人的应用范围[3].大多数情况下,移动机器人需要自主完成某些任务,这就要求机器人可以适应足够陌生的环境.因此,能够在未知环境中进行定位和地图构建的SLAM(SimultaneousLocalizationandMapping)[4]技术成为自主移动机器人必备的能力.根据所使用的传感器不同,SLAM技术主要分为激光SLAM与视觉SLAM(VSLAM)[5].与激光SLAM相比,VSLAM与人眼类似,主要以图像作为环境感知信息源,更符合人类的认知.近年来,由于相机具有廉价、易安装、可以获得丰富的环境信息、易与其他传感器融合等优势[6],基于相机的VSLAM研究受到了科研人员的广泛关注,大量以视觉为基础的SLAM算法应运而生[7].
随着深度学习的快速发展,不少学者尝试采用深度学习的方法解决视觉SLAM所遇到的问题.深度学习可以根据具体问题学习更强大和有效的特征,并成功地展示了一些具有挑战性的认知和感知任务的良好能力.最近的工作尝试包括从单目图像中对场景进行深度估计,以及视觉里程计和语义映射生成等.权美香等[8]对传统的VSLAM进行了详细总结,并对比了不同方法的优缺点;胡凯等[9]从视觉里程计的角度,对VSLAM的发展做了概述,并介绍了深度学习在VSLAM中的应用;刘瑞军等[10]从里程计、闭环检测等方面介绍了深度学习与VSLAM的结合,并与传统方法进行了对比;李少朋等[11]将基于深度学习的VSLAM与传统的VSLAM进行了对比,并展望了未来发展方向.上述文献大多仅从深度学习角度讲述部分方法,未详细介绍典型神经网络与传统VSLAM的结合,也未将整个发展脉络完整展开.本文首先概述了VSLAM发展脉络,然后从深度学习的两个主要的神经网络,即卷积神经网络(ConvolutionalNeuralNetwork,CNN)与循环神经网络(RecurrentNeuralNetwork,RNN)入手,重点阐述了神经网络在VSLAM系统中深度估计、位姿估计、闭环检测,以及数据融合等方面的贡献,并介绍了神经网络在语义信息提取方面的优势,最后对VSLAM的发展做出总结和展望.CNN和RNN,并列举了部分优秀的VSLAM算法;第2节阐述了CNN与VSLAM的结合,并从单目深度估计、位姿估计、闭环检测3个方面详细总结了VSLAM的发展进程;第3节重点介绍了RNN与视觉惯性数据融合方面的优势,并给出了神经网络与传统VSLAM结合的部分优秀方案;第4节为总结,并对未来VSLAM的发展做出了展望.
1神经网络与VSLAM概述
传统的VSLAM研究已经取得了诸多令人惊叹的成就.2007年,Davidson等[12]提出了首个实时的单目VSLAM算法——MonoSLAM,该算法可实现实时无漂移的运动结构恢复.2011年,Newcombe等[13]提出了DTAM算法,该算法被认为是第一个实际意义上的直接法VSLAM.2015年,Mur-Artal等[14]提出了ORB-SLAM算法,创新地使用跟踪、局部建图和闭环检测3个线程同时进行,有效地降低了累计误差.闭环检测线程采用词袋模型BoW[15]进行闭环的检测和修正,在处理速度和构建地图的精度上都取得了很好的效果.随后几年,Mur-Artal团队相继推出了ORB-SLAM2[16]与ORB-SLAM3[17].ORB-SLAM系列是基于特征点提取方法中的佼佼者,它将传统VSLAM方法发展到了十分完善的程度.2018年,Engel等[18]提出了可以有效利用任何图像像素的DSO算法,它是直接法中的经典,其在无特征的区域中也具有良好的鲁棒性,并得到了广泛使用.2018年,香港科技大学团队推出了单目惯性紧耦合的VINS-Mono[19]算法,该算法是视觉惯性融合SLAM中最优秀的算法之一,它充分利用惯性测量单元(InertialMeasurementUnit,IMU)与单目相机的互补性,改善了具有挑战性环境中的定位精度.表1根据前端所用传感器不同,从视觉里程计(VisualOdometry,VO)及视觉惯性里程计(Visual-InertialOdometry,VIO)两方面列举了部分优秀的传统VSLAM方案,并给出了其开源地址.
传统方法多采用基于特征提取的间接法或者直接对像素进行操作的直接法.虽然在大多数环境中传统方法可以稳定运行,但是在光照强烈、相机快速旋转或是动态物体普遍存在等环境中鲁棒性会大大降低,甚至可能会失效.近年来,深度学习的快速发展吸引了诸多学者的目光,将深度学习的方法与传统VSLAM相结合成为广受关注的研究领域[20].
深度学习可以学习不同数据中的特征或者是数据之间的某种关联,学习得到的特征属性与关联关系都可以用于不同的任务中[29].深度学习通过层次化的处理方式,对视觉数据进行学习,得到数据的抽象表达,在图像识别、语义理解、图像匹配、三维重建[30]等任务中取得了显著的成果[31].作为深度学习中两个重要的神经网络,CNN与RNN在多个领域取得了很高的成就,图1为CNN和RNN的基本框图,表2中给出了两者主要特点的对比.CNN可以从图像中捕捉空间特征,准确地识别物体以及它与图像中其他物体的关系[32].RNN可以有效地处理图像或数值数据,并且由于网络本身具有记忆能力,因此可以学习具有前后相关的数据类型[33].此外,其他类型的神经网络如深度神经网络(DeepNeuralNetwork,DNN),在VSLAM领域也有一些尝试性的工作,但尚在起步阶段.如表3所示,结合深度学习进行VSLAM的研究已经有了许多突破性的进展.部分学者建议使用深度学习的方法替换传统SLAM的某些模块,如深度估计、闭环检测、位姿估计等,从而改善传统方法.这些方法都取得了一定效果,在不同程度上提高了传统方法的性能.后文将从CNN和RNN两个神经网络入手,重点讲述它们与传统VSLAM的结合.
2CNN与VSLAM
CNN以一定的模型对事物进行特征提取,而后根据特征对该事物进行分类、识别、预测或决策等,可以对VSLAM的不同模块提供帮助.
2.1单目深度估计
基于单目相机的VSLAM算法由于传感器成本低、简单实用,受到了诸多学者的喜爱.单目相机只能得到二维的平面图像,无法获得深度信息.简单地说,单目的局限性主要在于无法得到确定尺度[53].CNN在图像处理方面的优势已得到充分验证,使用CNN进行视觉深度估计,最大程度上解决了单目相机无法得到可靠的深度信息的问题[54].
2017年,Tateno等[34]在LSD-SLAM的框架上提出了基于CNN的实时SLAM算法CNN-SLAM.该算法用CNN做深度预测将其输入到后续的传统位姿估计等模块,用来提升定位和建图精度.此外,该算法利用CNN提取环境的语义信息,进行全局地图和语义标签的融合,提高了机器人的环境感知能力.类似利用CNN预测深度信息的工作还有Code-SLAM[36]以及DVSO[37]等.但上述方法只在某个方面利用了CNN的优势,Yang等[42]提出的D3VO则从3个层面利用了CNN,包括利用深度学习进行深度估计、位姿估计以及不确定度估计Σ.如图2所示,D3VO将预测深度(D)、位姿(Tt-1t)以及不确定度紧密结合到一个直接视觉里程计中,来同时提升前端追踪以及后端非线性优化的性能.所提出的单目深度估计网络的核心是自监督训练体制,这种自监督训练是通过最小化时间立体图像和静态立体图像之间的光度重投影误差来实现的,原理如下:
传统方法对极几何、PnP、ICP、LK光流几何特征只能为相机的姿势提供短期的限制,而且可能在有强烈的光和快速运动的环境中失败,且复杂特征的提取相当耗时
基于CNN的方法数据关联、高级信息提供帮助(如语义信息)无需提取环境特征,也无需进行特征匹配和复杂的几何运算,当光照强度、观测距离和角度变化时,语义信息保持不变
其中:V是图片It上面所有像素的集合,文中将It设置为双目相机中左侧摄像头所得帧;t′是所有源帧的索引(区别于时刻t的某一时刻,右上角的′表示将其与t区分开);It′为包含相邻时间的两帧以及右侧摄像头所得帧,即It′∈It-1,It+1,Its(It-1为t时刻前一时刻左侧相机所得帧,It+1为t时刻后一时刻左侧相机所得帧,Its为双目相机中右侧摄像头所得帧).
2.2位姿估计
传统的位姿估计方法,一般采用基于特征的方法或直接法,通过多视图几何来确定相机位姿.但基于特征的方法需要复杂的特征提取和运算[55],直接法则依赖于像素强度值,这使得传统方法在光照强烈或纹理稀疏等环境中很难取得想要的结果[56].基于深度学习的方法由于无需提取环境特征,也无需进行特征匹配和复杂的几何运算,因此更加直观简洁[57].Zhu等[58]通过利用CNN关注光流输入的不同象限来学习旋转和平移,在数据集中测试结果比传统SLAM效果更好.表4给出了在位姿估计方面传统方法与基于CNN方法的不同.由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显示的特征抽取,而隐式地从训练数据中进行学习,文献[32,59]在这方面做出了较为详细的总结.相比传统位姿估计方法,CNN无需传统方法复杂的公式计算,无需提取和匹配特征,因此在线运算速度较快[60].
2.3闭环检测
闭环检测可以消除累积轨迹误差和地图误差,决定着整个系统的精度,其本质是场景识别问题[61].在闭环检测方面,传统方法多以词袋模型为基础.如图3所示,首先需要从图像中提取出相互独立的视觉词汇,通常经过特征检测、特征表示以及单词本的生成3个步骤,然后再将新采集到的图像进行词典匹配并分类,过程复杂.而深度学习的强大识别能力,可以提取图像更高层次的稳健特征如语义信息,使得系统能对视角、光照等图像变化具备更强的适应能力,提高闭环图像识别能力[62].因此,基于深度学习的场景识别可以提高闭环检测准确率,CNN用于闭环检测也得到了诸多可靠的结果.
Memon等[63]提出一种基于词典的深度学习方法,它不同于传统的BoW词典,创新地使用两个CNN网络一起工作,以加快闭环检测的速度,并忽略移动对象对闭环检测的影响.其核心如图4所示,该方法使用并行线程(标记为虚线框)使闭合检测可以达到更高的速度.将patch逐个送入移动对象识别层,从标记为静止的patch中提取CNN特征,由创新检测层进一步处理.所有不包含任何移动物体的patch再经过创新检测层处理来判断是否访问过该场景.在新的场景下,自动编码器在一个单独的线程上并行地训练这些特征.该方法可以鲁棒地执行循环闭环检测,比同类方法拥有更快的运行速度.Li等[64]使用CNN从每帧图像中提取局部特征和全局特征,然后将这些特征输入现代SLAM模块,用于姿势跟踪、局部映射和重新定位.与传统的基于BoW的方法相比,它的计算效率更高,并且计算成本更低.Qin等[65]采用CNN提取环境语义信息,并将视觉场景建模为语义子图.该方法只保留目标检测中的语义和几何信息,并在数据集中与传统方法进行了比较.结果表明,基于深度学习的特征表示方法,在不提取视觉特征的情况下,可以明显改善闭环检测的效果.
上述内容主要从单目深度估计、位姿估计、闭环检测3个方面列举了CNN与VSLAM的结合.表5给出了传统方法与结合深度学习方法的对比.CNN在取代传统的特征提取环节上取得了不错的效果,改善了传统特征提取环节消耗时间和计算资源的缺点.同时,CNN有效地提高了单目深度估计的精度.此外,文献[34,66]利用CNN提取环境的语义信息,以更高层次的特征来优化传统VSLAM的进程,使得传统VSLAM获得了更好的效果.采用神经网络提取语义信息,并与VSLAM结合将会是一个备受关注的领域,借助语义信息将数据关联从传统的像素级别提升到物体级别,将感知的几何环境信息赋以语义标签,进而得到高层次的语义地图,可帮助机器人进行自主环境理解和人机交互.
3RNN与VSLAM
循环神经网络RNN的研究从20世纪八九十年代开始,并在21世纪初发展为深度学习经典算法之一,其中长短期记忆网络(LongShort-TermMemory,LSTM)是最常见的循环神经网络之一.LSTM是RNN的一种变体,它记忆可控数量的前期训练数据,或是以更适当的方式遗忘[67].LSTM基本结构如图5所示,从左到右依次为遗忘门、输入门、输出门.采用了特殊隐式单元的LSTM可以长期保存输入,LSTM的这种结构继承了RNN模型的大部分特性,同时解决了梯度反传过程由于逐步缩减而产生的问题.此外GRU(GateRecurrentUnit)相比LSTM,更容易进行训练,能够很大程度上提高训练效率,因此很多时候会倾向于使用GRU,但在VSLAM领域还处于尝试阶段.
环节传统方法结合深度学习的方法
单目深度估计传统方法无法很好地解决单目尺度不确定性问题CNN可以在一些挑战性的环境中更有效地估计图像深度,如低纹理区域相机位姿估计通过特征提取与匹配,或是基于像素亮度变化,需要复杂的计算环节,并且在具有挑战性的环境中(低纹理区域、光照强烈、快速运动)无法得到可靠的效果可以取代传统方法复杂的公式计算、特征提取与匹配,速度更快闭环检测本质是场景识别问题,传统方法多采用词袋模型.在场景光照变化大、相机视野变化大等环境中,传统的DBoW方法能力有限闭环过程使用深度学习中的图像检索,能有效地减少由于环境光照、季节更替、视角变化引起的匹配问题语义信息传统的VSLAM算法中,基本不涉及高层次信息的提取,对于移动机器人的真正智能化没有帮助采用深度学习的方法可以有效地提取环境中的语义信息,高层次的语义信息可以给系统带来长期稳定的约束,并且使机器人更好地理解周围环境循环神经网络具有记忆性,参数共享,因此,在对序列的非线性特征进行学习时具有一定优势.RNN在帮助建立相邻帧之间的一致性方面具有很大的优势,高层特征具备更好的区分性,可以帮助机器人更好地完成数据关联.
3.1位姿估计
传统的位姿估计方法首先需要特征提取与匹配[68],或是基于像素亮度变化的复杂计算.其原理如图6所示,该问题的核心是求解旋转矩阵和平移向量,需要繁琐的计算过程.基于特征的方法(图6a)需要十分耗时地提取特征,计算描述子的操作丢失了除了特征点以外的很多信息(图6a中R,t分别为旋转矩阵和平移向量,红色点为空间中的特征点,黑色点为特征点在不同图像中的投影).直接法(图6b)不同于特征点法最小化重投影误差,而是通过最小化相邻帧之间的灰度误差估计相机运动,但是基于灰度不变假设:
如图6b,假设空间点P在相邻两帧图像上的投影分别为P1,P2两点(用不同颜色的点表示二者像素强度的差别).它们的像素强度分别为I1(P1,i)和I2(P2,i),其中,i表示当前图像中第i个点.则优化目标就是这两点的亮度误差ei的二范数.
其中,T和ξ分别是P1,P2之间的转换矩阵及其李代数.ξ右上角的∧表示把ξ转为一个四维矩阵,从而通过指数映射成为变换矩阵.
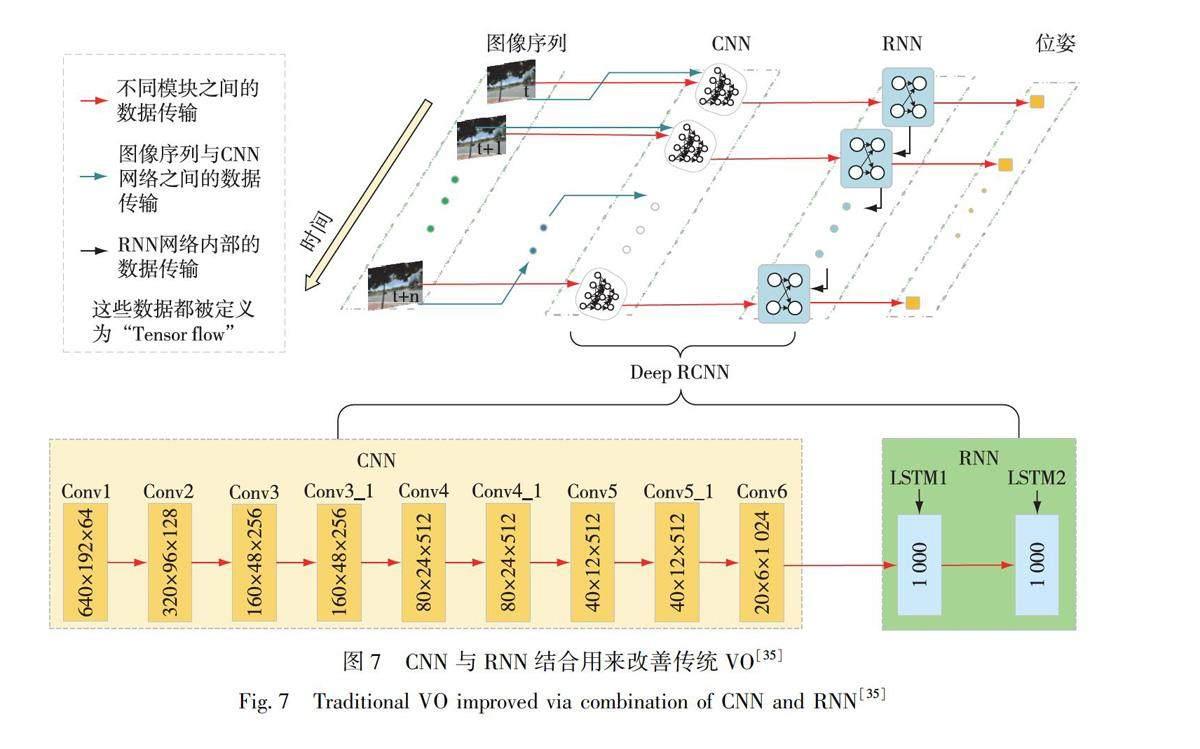
通过引入端对端的深度学习方法,使得视觉图像帧间的位姿参数解算无须特征匹配与复杂的几何运算,可快速得到帧间相对位姿参数[69].Xue等[70]基于RNN来实现位姿的估计.在位姿估计过程中,旋转和位移是分开进行训练的,相对于传统方法有更好的适应性.2017年,Wang等[35]使用深度递归卷积神经网络,提出一种新颖的端到端单目VO的框架.由于它是以端到端的方式进行训练和配置的,因此可以直接从一系列原始的RGB图像中计算得到姿态,而无需采用任何传统VO框架中的模块.该方法做到了视觉里程计的端到端实现,免去了帧间各种几何关系的约束计算,有良好的泛化能力.如图7所示,该方案使用CNN+RNN对相机的运动进行估计,直接从原始RGB图像序列推断姿态.它不仅通过卷积神经网络自动学习VO问题的有效特征表示,而且还利用深度回归神经网络隐式建模顺序动力学和关系.
3.2视觉惯性融合
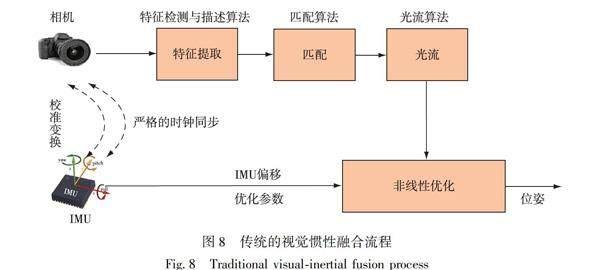
由于惯性测量元件IMU能够在短时间内高频地获得精准的估计,减轻动态物体对相机的影响,而相机数据也能有效地修正IMU的累积漂移,IMU被认为是与相机互补性最强的传感器之一[71].传统方法中,视觉惯性融合按照是否将图像特征信息加入到状态向量中可以分为松耦合和紧耦合[72].松耦合是指IMU和相机分别进行自身的运动估计,然后对其位姿估计输出结果进行融合[73].紧耦合是指把IMU的状态与相机的状态合并在一起,共同构建运动方程和观测方程,然后进行状态估计[74].图8为传统方法典型的视觉惯性融合流程,由于相机和IMU频率相差较大,需要先进行严格的同步校准.但是,不同传感器的数据融合,势必会带来计算资源消耗过多、实时性差等问题.
RNN是深度学习领域数据驱动的时序建模的常用方法,IMU输出的高帧率角速度、加速度等惯性数据,在时序上有着严格的依赖关系,特别适合使用RNN这类模型来优化.Clark等[47]使用一个常规的小型LSTM网络来处理IMU的原始数据,得到了IMU数据下的运动特征.如图9所示,在对相机数据和IMU数据结合后,送入一个核心的LSTM网络进行特征融合和位姿估计.该方法通过神经网络方法,避免了传统方法复杂的数据融合过程,使得运行效率大大提升.
相比于单纯用于位姿估计,RNN在视觉惯性数据融合方面做出的贡献更具吸引力.此类方法对视觉惯性数据进行了非常有效的融合,相比传统方法更便捷,类似的工作有文献[50-51]等.此外,一些工作利用神经网络提取环境中的语义信息,高层特征更具区分性,对于VSLAM数据关联有很好的帮助.2017年,Xiang等[75]使用RNN与KinectFusion相结合,对RGB-D相机采集图像进行语义标注,用来重建三维语义地图.通过在RNN中引入了一个新的循环单元,来解决GPU计算资源消耗过大的问题.该方法充分利用RNN的优点,实现了语义信息的标注,高层特征具备更好的区分性,同时帮助机器人更好地完成数据关联.
4总结与展望
本文对深度学习中的两个典型神经网络CNN与RNN进行了介绍,并详细总结了神经网络在VSLAM中的贡献,从深度估计、位姿估计、闭环检测等方面将基于神经网络的方法与传统方法进行对比.从CNN与RNN各自的特点入手,列举出其对传统VSLAM不同模块的改善.神经网络一定程度上改善了传统VSLAM由于设计特征而带来的应用局限性,同时对高层语义快速准确生成以及机器人知识库构建也产生了重要影响,从而提高了机器人的学习能力和智能化水平.
综合他人所做研究,笔者认为未来VSLAM的发展趋势如下:
1)更高层次的环境感知.神经网络可以更加方便地提取环境中高层次的语义信息,可以促进机器人智能化的发展.传统的VSLAM算法只能满足机器人基本的定位导航需求,无法完成更高级别的任务,如“帮我把卧室门关上”、“去厨房帮我拿个苹果”等.借助语义信息将数据关联从传统的像素级别提升到物体级别,将感知的几何环境信息赋以语义标签,进而得到高层次的语义地图,可以帮助机器人进行自主环境理解和人机交互,实现真正自主化.
2)更完善的理论支撑体系.通过深度学习技术学习的信息特征还缺少直观的意义以及清晰的理论指导.目前深度学习多应用于SLAM局部的子模块,如深度估计、闭环检测等,而如何将深度学习应用贯穿于整个SLAM系统仍是一个巨大挑战.
3)更高效的数据融合.CNN可以与VLSAM的诸多环节进行结合,如特征提取与匹配、深度估计、位姿估计等,RNN的应用范围较小.但RNN在数据融合方面的优势,可以更好地融合多传感器的数据,快速推动传感器融合SLAM技术的发展.未来可能会更多地关注CNN与RNN的结合,来提升VSLAM的整体性能.
参考文献
References
[1]
任伟建,高强,康朝海,等.移动机器人同步定位与建图技术综述[J].计算机测量与控制,2022,30(2):1-10,37
RENWeijian,GAOQiang,KANGChaohai,etal.Overviewofsimultaneouslocalizationandmappingtechnologyofmobilerobots[J].ComputerMeasurement&Control,2022,30(2):1-10,37
[2]赵乐文,任嘉倩,丁杨.基于GNSS的空间环境参数反演平台及精度评估[J].南京信息工程大学学报(自然科学版),2021,13(2):204-210
ZHAOLewen,RENJiaqian,DINGYang.PlatformforGNSSreal-timespaceenvironmentparameterinversionanditsaccuracyevaluation[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2021,13(2):204-210
[3]尹姝,陈元橼,仇翔.基于RFID和自适应卡尔曼滤波的室内移动目标定位方法[J].南京信息工程大学学报(自然科学版),2018,10(6):749-753
YINShu,CHENYuanyuan,QIUXiang.Indoormoving-targetlocalizationusingRFIDandadaptiveKalmanfilter[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2018,10(6):749-753
[4]周韦,孙宪坤,吴飞.基于SLAM/UWB的室内融合定位算法研究[J].全球定位系统,2022,47(1):36-42,85
ZHOUWei,SUNXiankun,WUFei.ResearchonindoorfusionpositioningalgorithmbasedonSLAM/UWB[J].GNSSWorldofChina,2022,47(1):36-42,85
[5]BressonG,AlsayedZ,YuL,etal.Simultaneouslocalizationandmapping:asurveyofcurrenttrendsinautonomousdriving[J].IEEETransactionsonIntelligentVehicles,2017,2(3):194-220
[6]李晓飞,宋亚男,徐荣华,等.基于双目视觉的船舶跟踪与定位[J].南京信息工程大学学报(自然科学版),2015,7(1):46-52
LIXiaofei,SONGYanan,XURonghua,etal.Trackingandpositioningofshipbasedonbinocularvision[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2015,7(1):46-52
[7]刘明芹,张晓光,徐桂云,等.单机器人SLAM技术的发展及相关主流技术综述[J].计算机工程与应用,2020,56(18):25-35
LIUMingqin,ZHANGXiaoguang,XUGuiyun,etal.ReviewofdevelopmentofsinglerobotSLAMtechnologyandrelatedmainstreamtechnology[J].ComputerEngineeringandApplications,2020,56(18):25-35
[8]权美香,朴松昊,李国.视觉SLAM综述[J].智能系统学报,2016(6):768-776
QUANMeixiang,PIAOSonghao,LIGuo.AnoverviewofvisualSLAM[J].CAAITransactionsonIntelligentSystems,2016(6):768-776
[9]胡凯,吴佳胜,郑翡,等.视觉里程计研究综述[J].南京信息工程大学学报(自然科学版),2021,13(3):269-280
HUKai,WUJiasheng,ZHENGFei,etal.Asurveyofvisualodometry[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2021,13(3):269-280
[10]刘瑞军,王向上,张晨,等.基于深度学习的视觉SLAM综述[J].系统仿真学报,2020,32(7):1244-1256
LIURuijun,WANGXiangshang,ZHANGChen,etal.AsurveyonvisualSLAMbasedondeeplearning[J].JournalofSystemSimulation,2020,32(7):1244-1256
[11]李少朋,张涛.深度学习在视觉SLAM中应用综述[J].空间控制技术与应用,2019,45(2):1-10
LIShaopeng,ZHANGTao.AsurveyofdeeplearningapplicationinvisualSLAM[J].AerospaceControlandApplication,2019,45(2):1-10
[12]DavisonAJ,ReidID,MoltonND,etal.MonoSLAM:real-timesinglecameraSLAM[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2007,29(6):1052-1067
[13]NewcombeRA,LovegroveSJ,DavisonAJ.DTAM:densetrackingandmappinginreal-time[C]//2011InternationalConferenceonComputerVision.November6-13,2011,Barcelona,Spain.IEEE,2011:2320-2327
[14]Mur-ArtalR,MontielJMM,TardosJD.ORB-SLAM:aversatileandaccuratemonocularSLAMsystem[J].IEEETransactionsonRobotics,2015,31(5):1147-1163
[15]Galvez-LopezD,TardosJD.Bagsofbinarywordsforfastplacerecognitioninimagesequences[J].IEEETransactionsonRobotics,2012,28(5):1188-1197
[16]Mur-ArtalR,TardosJD.ORB-SLAM2:anopen-sourceSLAMsystemformonocular,stereo,andRGB-Dcameras[J].IEEETransactionsonRobotics,2017,33(5):1255-1262
[17]CamposC,ElviraR,RodriguezJJG,etal.ORB-SLAM3:anaccurateopen-sourcelibraryforvisual,visual-inertial,andmultimapSLAM[J].IEEETransactionsonRobotics,2021,37(6):1874-1890
[18]EngelJ,KoltunV,CremersD.Directsparseodometry[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2018,40(3):611-625
[19]QinT,LiPL,ShenSJ.VINS-mono:arobustandversatilemonocularvisual-inertialstateestimator[J].IEEETransactionsonRobotics,2018,34(4):1004-1020
[20]邓晨,李宏伟,张斌,等.基于深度学习的语义SLAM关键帧图像处理[J].测绘学报,2021,50(11):1605-1616
DENGChen,LIHongwei,ZHANGBin,etal.ResearchonkeyframeimageprocessingofsemanticSLAMbasedondeeplearning[J].ActaGeodaeticaetCartographicaSinica,2021,50(11):1605-1616
[21]KleinG,MurrayD.ParalleltrackingandmappingforsmallARworkspaces[C]//20076thIEEEandACMInternationalSymposiumonMixedandAugmentedReality.November13-16,2017,Nara,Japan.IEEE,2007:225-234
[22]Gomez-OjedaR,BrialesJ,Gonzalez-JimenezJ.PL-SVO:semi-directmonocularvisualodometrybycombiningpointsandlinesegments[C]//2016IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).October9-14,2016,Daejeon,Korea(South).IEEE,2016:4211-4216
[23]PumarolaA,VakhitovA,AgudoA,etal.PL-SLAM:real-timemonocularvisualSLAMwithpointsandlines[C]//2017IEEEInternationalConferenceonRoboticsandAutomation.May29-June3,2017,Singapore.IEEE,2017:4503-4508
[24]ForsterC,PizzoliM,ScaramuzzaD.SVO:fastsemi-directmonocularvisualodometry[C]//2014IEEEInternationalConferenceonRoboticsandAutomation.May31-June7,2014,HongKong,China.IEEE,2014:15-22
[25]EngelJ,SchpsT,CremersD.LSD-SLAM:large-scaledirectmonocularSLAM[C]//EuropeanConferenceonComputerVision.Springer,Cham,2014:834-849
[26]MourikisAI,RoumeliotisSI.Amulti-stateconstraintKalmanfilterforvision-aidedinertialnavigation[C]//Proceedings2007IEEEInternationalConferenceonRoboticsandAutomation.April10-14,2007,Rome,Italy.IEEE,2007:3565-3572
[27]LeuteneggerS,LynenS,BosseM,etal.Keyframe-basedvisual-inertialodometryusingnonlinearoptimization[J].TheInternationalJournalofRoboticsResearch,2015,34(3):314-334
[28]BloeschM,OmariS,HutterM,etal.RobustvisualinertialodometryusingadirectEKF-basedapproach[C]//2015IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).September28-October2,2015,Hamburg,Germany.IEEE,2015:298-304
[29]XuD,VedaldiA,HenriquesJF.MovingSLAM:fullyunsuperviseddeeplearninginnon-rigidscenes[C]//2021IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).September27-October1,2021,Prague,CzechRepublic.IEEE,2021:4611-4617
[30]张彦雯,胡凯,王鹏盛.三维重建算法研究综述[J].南京信息工程大学学报(自然科学版),2020,12(5):591-602
ZHANGYanwen,HUKai,WANGPengsheng.Reviewof3Dreconstructionalgorithms[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2020,12(5):591-602
[31]LiJL,LiZJ,FengY,etal.Developmentofahuman-robothybridintelligentsystembasedonbrainteleoperationanddeeplearningSLAM[J].IEEETransactionsonAutomationScienceandEngineering,2019,16(4):1664-1674
[32]MumuniA,MumuniF.CNNarchitecturesforgeometrictransformation-invariantfeaturerepresentationincomputervision:areview[J].SNComputerScience,2021,2(5):1-23
[33]MaRB,WangR,ZhangYB,etal.RNNSLAM:reconstructingthe3Dcolontovisualizemissingregionsduringacolonoscopy[J].MedicalImageAnalysis,2021,72:102100
[34]TatenoK,TombariF,LainaI,etal.CNN-SLAM:real-timedensemonocularSLAMwithlearneddepthprediction[C]//2017IEEEConferenceonComputerVisionandPatternRecognition(CVPR).July21-26,2017,Honolulu,HI,USA.IEEE,2017:6565-6574
[35]WangS,ClarkR,WenHK,etal.DeepVO:towardsend-to-endvisualodometrywithdeeprecurrentconvolutionalneuralnetworks[C]//2017IEEEInternationalConferenceonRoboticsandAutomation.May29-June3,2017,Singapore.IEEE,2017:2043-2050
[36]BloeschM,CzarnowskiJ,ClarkR,etal.CodeSLAM:learningacompact,optimisablerepresentationfordensevisualSLAM[C]//2018IEEE/CVFConferenceonComputerVisionandPatternRecognition.June18-23,2018,SaltLakeCity,UT,USA.IEEE,2018:2560-2568
[37]YangN,WangR,StucklerJ,etal.Deepvirtualstereoodometry:leveragingdeepdepthpredictionformonoculardirectsparseodometry[C]//EuropeanConferenceonComputerVision(ECCV).September8-12,2018,Munich,Germany.2018.DOI:10.48550/arXiv.1807.02570
[38]LiRH,WangS,LongZQ,etal.UnDeepVO:monocularvisualodometrythroughunsuperviseddeeplearning[C]//2018IEEEInternationalConferenceonRoboticsandAutomation.May21-25,2018,Brisbane,QLD,Australia.IEEE,2018:7286-7291
[39]LooSY,AmiriAJ,MashohorS,etal.CNN-SVO:improvingthemappinginsemi-directvisualodometryusingsingle-imagedepthprediction[C]//2019InternationalConferenceonRoboticsandAutomation(ICRA).May20-24,2019,Montreal,QC,Canada.IEEE,2019:5218-5223
[40]AlmaliogluY,SaputraMRU,deGusmoPPB,etal.GANVO:unsuperviseddeepmonocularvisualodometryanddepthestimationwithgenerativeadversarialnetworks[C]//2019InternationalConferenceonRoboticsandAutomation(ICRA).May20-24,2019,Montreal,QC,Canada.IEEE,2019:5474-5480
[41]LiY,UshikuY,HaradaT.Posegraphoptimizationforunsupervisedmonocularvisualodometry[C]//2019InternationalConferenceonRoboticsandAutomation(ICRA).May20-24,2019,Montreal,QC,Canada.IEEE,2019:5439-5445
[42]YangN,vonStumbergL,WangR,etal.D3VO:deepdepth,deepposeanddeepuncertaintyformonocularvisualodometry[C]//2020IEEE/CVFConferenceonComputerVisionandPatternRecognition(CVPR).June13-19,2020,Seattle,WA,USA.IEEE,2020:1278-1289
[43]ChancánM,MilfordM.DeepSeqSLAM:atrainableCNN+RNNforjointglobaldescriptionandsequence-basedplacerecognition[J].arXive-print,2020,arXiv:2011.08518
[44]LiRH,WangS,GuDB.DeepSLAM:arobustmonocularSLAMsystemwithunsuperviseddeeplearning[J].IEEETransactionsonIndustrialElectronics,2021,68(4):3577-3587
[45]BrunoHMS,ColombiniEL.LIFT-SLAM:adeep-learningfeature-basedmonocularvisualSLAMmethod[J].Neurocomputing,2021,455:97-110
[46]ZhangSM,LuSY,HeR,etal.Stereovisualodometryposecorrectionthroughunsuperviseddeeplearning[J].Sensors(Basel,Switzerland),2021,21(14):4735
[47]ClarkR,WangS,WenH,etal.VINet:visual-inertialodometryasasequence-to-sequencelearningproblem[C]//Proceedingsofthe31stAAAIConferenceonArtificialIntelligence.February4-9,2017,SanFrancisco,CA,USA.2017:3995-4001
[48]ShamwellEJ,LindgrenK,LeungS,etal.Unsuperviseddeepvisual-inertialodometrywithonlineerrorcorrectionforRGB-Dimagery[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2020,42(10):2478-2493
[49]HanLM,LinYM,DuGG,etal.DeepVIO:self-superviseddeeplearningofmonocularvisualinertialodometryusing3Dgeometricconstraints[C]//2019IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).November3-8,2019,Macao,China.IEEE,2019:6906-6913
[50]ChenCH,RosaS,MiaoYS,etal.Selectivesensorfusionforneuralvisual-inertialodometry[C]//2019IEEE/CVFConferenceonComputerVisionandPatternRecognition(CVPR).June15-20,2019,LongBeach,CA,USA.IEEE,2019:10534-10543
[51]KimY,YoonS,KimS,etal.Unsupervisedbalancedcovariancelearningforvisual-inertialsensorfusion[J].IEEERoboticsandAutomationLetters,2021,6(2):819-826
[52]GurturkM,YusefiA,AslanMF,etal.TheYTUdatasetandrecurrentneuralnetworkbasedvisual-inertialodometry[J].Measurement,2021,184:109878
[53]傅杰,徐常胜.关于单目标跟踪方法的研究综述[J].南京信息工程大学学报(自然科学版),2019,11(6):638-650
FUJie,XUChangsheng.Asurveyofsingleobjecttrackingmethods[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2019,11(6):638-650
[54]SteenbeekA,NexF.CNN-baseddensemonocularvisualSLAMforreal-timeUAVexplorationinemergencyconditions[J].Drones,2022,6(3):79
[55]唐灿,唐亮贵,刘波.图像特征检测与匹配方法研究综述[J].南京信息工程大学学报(自然科学版),2020,12(3):261-273
TANGCan,TANGLianggui,LIUBo.Asurveyofimagefeaturedetectionandmatchingmethods[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2020,12(3):261-273
[56]LiL,KongX,ZhaoXR,etal.Semanticscancontext:anovelsemantic-basedloop-closuremethodforLiDARSLAM[J].AutonomousRobots,2022,46(4):535-551
[57]SakkariM,HamdiM,ElmannaiH,etal.Featureextraction-baseddeepself-organizingmap[J].Circuits,Systems,andSignalProcessing,2022,41(5):2802-2824
[58]ZhuR,YangMK,LiuW,etal.DeepAVO:efficientposerefiningwithfeaturedistillingfordeepvisualodometry[J].Neurocomputing,2022,467:22-35
[59]KimJJY,UrschlerM,RiddlePJ,etal.SymbioLCD:ensemble-basedloopclosuredetectionusingCNN-extractedobjectsandvisualbag-of-words[C]//2021IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).September27-October1,2021,Prague,CzechRepublic.IEEE,2021:5425
[60]AiYB,RuiT,LuM,etal.DDL-SLAM:arobustRGB-DSLAMindynamicenvironmentscombinedwithdeeplearning[J].IEEEAccess,8:162335-162342
[61]JavedZ,KimGW.PanoVILD:achallengingpanoramicvision,inertialandLiDARdatasetforsimultaneouslocalizationandmapping[J].TheJournalofSupercomputing,2022,78(6):8247-8267
[62]DuanR,FengYR,WenCY.Deepposegraph-matching-basedloopclosuredetectionforsemanticvisualSLAM[J].Sustainability,2022,14(19):11864
[63]MemonAR,WangHS,HussainA.LoopclosuredetectionusingsupervisedandunsuperviseddeepneuralnetworksformonocularSLAMsystems[J].RoboticsandAutonomousSystems,2020,126:103470
[64]LiDJ,ShiXS,LongQW,etal.DXSLAM:arobustandefficientvisualSLAMsystemwithdeepfeatures[C]//2020IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).October24,2020-January24,2021,LasVegas,NV,USA.IEEE,2020:4958-4965
[65]QinC,ZhangYZ,LiuYD,etal.Semanticloopclosuredetectionbasedongraphmatchinginmulti-objectsscenes[J].JournalofVisualCommunicationandImageRepresentation,2021,76:103072
[66]GodardC,AodhaOM,BrostowGJ.Unsupervisedmonoculardepthestimationwithleft-rightconsistency[C]//2017IEEEConferenceonComputerVisionandPatternRecognition.July21-26,2017,Honolulu,HI,USA.IEEE,2017:6602-6611
[67]SangHR,JiangR,WangZP,etal.Anovelneuralmulti-storememorynetworkforautonomousvisualnavigationinunknownenvironment[J].IEEERoboticsandAutomationLetters,2022,7(2):2039-2046
[68]LiGH,ChenSL.Visualslamindynamicscenesbasedonobjecttrackingandstaticpointsdetection[J].JournalofIntelligent&RoboticSystems,2022,104(2):1-10
[69]LiuL,TangTH,ChenJ,etal.Real-time3Dreconstructionusingpoint-dependentposegraphoptimizationframework[J].MachineVisionandApplications,2022,33(2):1-11
[70]XueF,WangQ,WangX,etal.Guidedfeatureselectionfordeepvisualodometry[C]//14thAsianConferenceonComputerVision.December2-6,2018,Perth,Australia.IEEE,2018:293-308
[71]TangYF,WeiCC,ChengSL,etal.Stereovisual-inertialodometryusingstructurallinesforlocalizingindoorwheeledrobots[J].MeasurementScienceandTechnology,2022,33(5):055114
[72]BucciA,ZacchiniL,FranchiM,etal.Comparisonoffeaturedetectionandoutlierremovalstrategiesinamonovisualodometryalgorithmforunderwaternavigation[J].AppliedOceanResearch,2022,118:102961
[73]WuJF,XiongJ,GuoH.ImprovingrobustnessoflinefeaturesforVIOindynamicscene[J].MeasurementScienceandTechnology,2022,33(6):065204
[74]HuangWB,WanWW,LiuH.Optimization-basedonlineinitializationandcalibrationofmonocularvisual-inertialodometryconsideringspatial-temporalconstraints[J].Sensors(Basel,Switzerland),2021,21(8):2673
[75]XiangY,FoxD.DA-RNN:semanticmappingwithdataassociatedrecurrentneuralnetworks[J].arXive-print,2017,arXiv:1703.03098
AreviewofvisualSLAMbasedonneuralnetworks
SHANGGuangtao1CHENWeifeng1JIAihong2ZHOUChengjun1WANGXiyang1XUChonghui1
1SchoolofAutomation,NanjingUniversityofInformationScience&Technology,Nanjing210044,China
2CollegeofMechanical&ElectricalEngineering/LabofLocomotionBioinspirationand
IntelligentRobots,NanjingUniversityofAeronauticsandAstronautics,Nanjing210016,China
Abstract
Althoughtraditionalvision-basedSLAM(VSLAM)technologieshaveachievedimpressiveresults,theyarelesssatisfactoryinchallengingenvironments.Deeplearningpromotestherapiddevelopmentofcomputervisionandshowsprominentadvantagesinimageprocessing.ItsahotspottocombinedeeplearningwithVSLAM,whichispromisingthroughtheeffortsofmanyresearchers.Here,weintroducethecombinationofdeeplearningandtraditionalVSLAMalgorithm,startingfromtheclassicalneuralnetworksofdeeplearning.TheachievementsofConvolutionalNeuralNetwork(CNN)andRecurrentNeuralNetwork(RNN)indepthestimation,poseestimationandclosed-loopdetectionaresummarized.Theadvantagesofneuralnetworkinsemanticinformationextractionareelaborated,andthefuturedevelopmentofVSLAMisalsoprospected.
Keywordssimultaneouslocalizationandmapping(SLAM);deeplearning;convolutionalneuralnetwork(CNN);recurrentneuralnetwork(RNN);poseestimation;closed-loopdetection;semantic
猜你喜欢
开放教育研究(2020年2期)2020-03-31
黑龙江电力(2017年1期)2017-05-17
环境科技(2016年5期)2016-11-10
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
现代语文(2016年21期)2016-05-25
湖北工业大学学报(2016年5期)2016-02-27
系统工程学报(2015年2期)2015-02-28
电网与清洁能源(2015年2期)2015-02-28
大连民族大学学报(2015年2期)2015-02-27
