
基于LightGBM模型的中国成人吸烟行为研究
2024-06-18 05:07:10刘忠华卢鑫梅文强赵旻胡彬彬张轲殷红慧
现代信息科技 2024年7期
刘忠华 卢鑫 梅文强 赵旻 胡彬彬 张轲 殷红慧
收稿日期:2023-07-13
基金项目:云南省烟草公司文山州公司科技计划一般项目(20235326002)
DOI:10.19850/j.cnki.2096-4706.2024.07.027
摘 要:采用2018年世界卫生组织在中国开展的成人烟草调查数据,对成人吸烟行为影响因素进行探究。首先对原始数据做数据清洗,包括剔除无关变量、组合新变量等步骤。其次结合卡方检验、方差分析以及最大互信息数对处理后的数据集进行特征选择。再次基于XGBoost、LightGBM算法进行建模,对影响成人吸烟行为的因素进行排序和分析。最后基于表现较好的LightGBM模型进行变量组合建模,进一步挖掘吸烟者特征。经建模分析,识别得出成人性别、烟草环境、增税态度、低焦油烟认知、学历、年龄重要性由强至弱对吸烟行为产生影响。
关键词:LightGBM;XGBoost;吸烟行为
中图分类号:TP399 文献标识码:A 文章编号:2096-4706(2024)07-0128-09
Study of Adult Smoking Behavior in China Based on the LightGBM Model
LIU Zhonghua1, LU Xin1, MEI Wenqiang4, ZHAO Min1, HU Binbin2, ZHANG Ke3, YIN Honghui4
(1.China National Tobacca Corporation Yunnan Company, Kunming 650011, China; 2.Yunnan Academy of Tobacco Agricultural Sciences, Kunming 650031, China; 3.Yunnan Tobacco Quality Inspection & Supervision Station, Kunming 650032, China;
4. Yunnan Tobacco Company Wenshan Prefecture Company, Wenshan 663099, China)
Abstract: Using the adult tobacco survey data conducted by the World Health Organization in China in 2018, this study explores the influencing factors of adult smoking behavior. Firstly, perform data cleaning on the original data, including removing irrelevant variables, combining new variables, and other steps. Secondly, feature selection is performed on the processed dataset by combining Chi-square test, analysis of variance, and Maximal Information Coefficient (MIC). Then, it conducts modeling based on XGBoost and LightGBM algorithms, sorting and analyzing the factors affecting adult smoking behavior. Finally, based on the well performing LightGBM model, variable combination modeling is performed to further explore the characteristics of smokers. Through modeling and analysis, it is identified that adult gender, tobacco environment, attitude towards value-added tax, low tar smoke awareness, educational background, and age importance have a varying impact from strong to weak on smoking behavior.
Keywords: LightGBM; XGBoost; smoking behavior
0 引 言
烟草作为一种嗜好品,长期吸食会对人体健康产生一定影响。烟草烟雾中含有数百种有毒有害物质,其中包括至少69种致癌物质。吸烟不仅对吸烟者自身健康有害,而且对周围不吸烟者也产生危害。在过去的50年里,越来越多无可争辩的科学证据表明,使用烟草制品或接触二手烟会导致死亡、疾病和残疾。根据《世界卫生报告》,在全球8个主要死因中,有6个与吸烟有关,而吸烟每年导致多达700万人死亡。为了遏制烟草流行,减少烟草对健康和经济的破坏性影响,世卫组织制定了烟草控制框架公约(FCTC),这是第一个国际公共卫生条约,也是最广泛接受和最迅速实施的条约之一。到目前为止,已有181个国家签署了《烟草控制框架公约》,中国是早期签署国之一。该公约要求签署国应建立烟草监测系统,提供准确的国家和全球烟草使用数据,以估算烟草使用对公共卫生和经济的影响,并进一步评估烟草控制政策的有效性。
根据国家卫生委员会的工作计划,在世界卫生组织的支持下,中国疾病预防控制中心在2018年7月至12月期间,按照全球成人烟草调查标准,在中国开展了2018年成人烟草调查。该调查是一项针对15岁及以上非集体中国居民的家庭调查,调查内容包括背景资料、烟草使用、电子烟使用、戒烟、二手烟、烟草价格、烟草控制运动、烟草广告、宣传和赞助、烟草使用知识、态度和看法等。本次调查采用分层多阶段整群随机抽样的方法,最终得到19 376份有效问卷。对于收集到的问卷,WHO研究人员进行统计分析后,用于了解该国总体烟草流行情况,以及城市和农村地区、性别的烟草流行情况等问题。近年来,基于梯度提升决策树(Light Gradient Boosting Machine, LightGBM)的算法快速发展[1,2],已被广泛用于交通[3,4]、医学[5,6]、金融[7-9]、防灾[10]、警务[11]等领域。本文基于WHO组织调查数据,借助集成机器学习模型XGBoost、LightGBM进行数据挖掘,探究影响中国成人吸烟行为的主要因素,并通过对部分因素进行组合,进一步刻画出吸烟者和非吸烟者画像。最终,借助研究结果,针对不同特征的人群,提出更为准确的控烟建议。同时,也可根据建立得出的最优模型对中国成人吸烟行为进行预测。
1 数据预处理
1.1 处理目的
在进行建模分析之前,为得到表现较好的模型,需要对数据进行预处理[12]。收集数据采用的抽样方法为WHO制定的多阶段随机整群抽样方法,得到的样本代表性良好。数据清洗的目的是让数据更加规整,主要包括剔除无关变量、组合新变量等步骤。特征选择则是帮助保留对模型结果有显著性影响的特征,化繁为简,增强模型的可解释性。
1.2 抽样方法
调查采用分层多阶段随机整群抽样方法[13]。在设计过程中,充分考虑了与以往调查数据进行纵向可比性的需要,以客观反映烟草使用和烟草控制政策的现状。抽样过程如下:首先,全国按地理区域(中北部、东北部、中东部、中南部、西南部和西北部)和城乡(区县)划分为12个地层。
第一阶段抽样:在2010年保留的100个监测点的基础上,再选择100个监测点。在12个地层中,主要采样级别为县/区级别。每个阶层的原始样本规模与该地区的总户数成正比。根据每个县/区的户籍数量,采用概率比例抽样法(PPS)选择每个阶层的县/区。在2018年的调查中,新选出了50个县和50个区;因此,最终选定的主要样本单元总数为200个。
第二阶段抽样:首先,在第一阶段选择的县/区中,采用PPS法选择了2个村或居委会。因此,全国共选出400个村或居委会。如果选定的村或居委会的户籍人口在1 000户至2 000户之间,则该村或居委会被视为第二阶段的最终样本单元;如果选定的村或居委会的户籍人口超过2 000人,则将村或居委会分成若干部分,每个部分约有1 000户。采用简单随机抽样法选择一个断面作为第二阶段的最终样本单元。
第三阶段抽样:采用简单随机抽样方法,从每个选定部门/村/居委会的住户名单中选择55户,全国共有22 000户。由于部分路段的空置住户相对较多,抽样时样本量有所扩大,全国共选择24 370户。
第四阶段抽样:根据选定的住户名单进行住户调查,根据调查问卷记录住户成员的信息,并从每户中随机选择一名成员作为受访者,最终,总共有19 376人完成了个人调查。
1.3 数据清洗
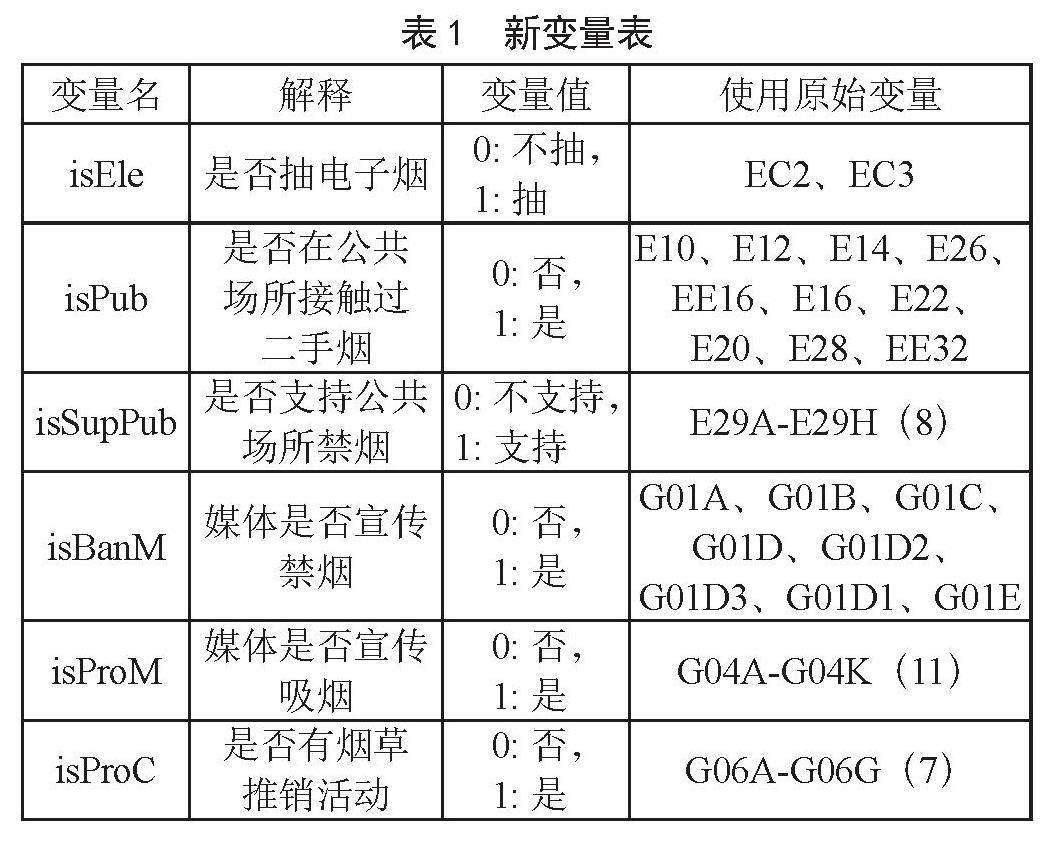
使用数据中的样本权重变量(gatsweight),经过计算调整样本数量,最终得到60 350条样本数据,代表中国15岁及以上的男性及女性的整体情况。数据中一共包含339个变量,包含个人背景资料、烟草使用、电子烟使用、戒烟、二手烟、烟草价格、烟草控制运动、烟草广告、宣传和赞助、烟草使用知识、态度和看法等方面内容。针对研究问题对数据做如下清洗:一是剔除无关变量。剔除与研究问题——是否抽烟无关的变量,以及只针对部分人群(如吸烟者)提问而产生的变量,保留82个变量做后续研究。二是组合部分变量,得到新变量。结合问卷信息,对类型一致或相似的变量进行组合,经过组合,得到6个新变量,如表1所示。
1.4 变量值的处理
问卷中变量值7、77含义为:Don't know,9、99含义为:Refuse to answer,将其用缺失值替换,由于集成机器学习模型对缺失值兼容,不需要进行缺失值填充;涉及是非问题的变量值1含义为:Yes,2含义为:No,将2替换为0,后续建模时即可将该类型变量作为0~1变量来处理;对于部分有序离散型变量,根据变量值含义调整数值大小;对于多分类的无序离散型变量(假设含有n个类别),结合其变量值分布,进行独热编码,最终处理为n个0~1变量。表2为多分类无序离散型变量处理表。
1.5 剔除类别分布不平衡变量
对于无序离散型变量,部分变量的类别分布过于极端,某类别样本达到总样本的90%以上,此变量很难对模型拟合效果的提升产生贡献,考虑将其进行剔除处理。经过上述清洗过程后得到29个变量,其中因变量为是否吸烟(isSmoke),自变量28个,包含连续型变量、有序离散型变量及无序离散型变量。相关变量说明如表3所示。
2 特征选择
2.1 离散型变量特征选择
对于本文研究的问题来说,如果一个离散型特征取值在吸烟组和不吸烟组占比是相同的,就认为这个变量对成人吸烟与否是没有影响的;如果该离散型特征取值在吸烟组和不吸烟组占比相差非常大,就认为该变量对成人吸烟与否影响非常大,即通过分析对比离散型变量不同取值在不同组之间分布有无显著差异,进行离散型变量的特征选择。由于考虑的是两个属性变量之间是否有联系,采用列联表分析的方法,列联表分析使用的是卡方统计量[14]。下面先介绍列联表分析的统计量卡方检验,以变量Male说明列联表筛选变量的原理与步骤。卡方检验方式如下:
若用f0表示观测值频数,用fe表示期望值频数,χ2统计量可写为:
如果在一定显著性水平下,χ2统计量大于所对应的χ2(n),那么我们认为拒绝原假设,我们就认为检测的两属性之间是不独立的,反之。下面以变量Male这一变量举例说明。表4是性别在不同组内的实际人数分布和期望人数分布,对应的卡方统计量计算为:
在α = 0.05的显著性水平下,,可见18 095 ? 3.84,作出拒绝原假设的判断,即认为性别与是否吸烟是显著相关的。
同样的,对其他的离散型变量依次进行卡方检验,进行变量筛选。
2.2 连续型变量特征选择
在这一节中,采用单因素方差分析方法进行变量选择。需要说明,将有序离散型变量烟草环境(TobaccoEnv)、低焦油烟认知(LowtarAware)当作连续型变量进行处理。方差分析的一般步骤如下:
1)提出原假设与备择假设。此问题原假设为是否吸烟对受访者特征没有影响。
2)构造检验统计量。计算组间平方和SSA、组内平方和SSE,构造F统计量:
其中,k为因素水平个数,n为样本总数。SSA与SSE定义为:
3)统计决策。根据计算出来的F统计量在一定显著性水平下判断是否拒绝原假设。下面以年龄这一变量举例说明方差分析的步骤,如表5所示。即这里分别计算不同组的组内、组间平方和。由于这里数据量过大,不展示详细的计算步骤。由上述计算得出拒绝原假设,保留年龄变量。同样的,对剩余的连续型变量依次进行方差分析,进行变量筛选。
2.3 依据变量相关性进行特征选择
在最后建模之前,我们考虑变量间可能会存在一定程度相关性,这会影响建模结果。用衡量两变量间相关关系的最大互信息数(MIC)作为判断标准,最大互信息数不局限于线性关系,也可以衡量变量间的非线性关系。MIC的计算公式为:
MIC计算的时候会a×b的网格划分数据空间。经计算得到两变量间MIC值结果,如表6所示。
本文对存在相关性的变量处理如下:若两变量之间MIC值大于0.7,结合卡方检验以方差分析结果进行判断,只将其中一个变量纳入建模的数据集中。经过上述特征选择,最终选取的16个变量用于后续建模,具体说明如表7所示。文中使用的模型XGBoost、LightGBM均是在梯度提升决策树模型(GBDT)的基础上改进而来,由于运算速度快、效果好的优点,在目前各个研究领域内被广泛使用。
3 模型方法
3.1 XGBoost模型
XGBoost(eXtreme Gradient Boosting)相较于传统GBDT在效率与准确率上有较大提升。它本质上是一种通过组合弱学习器来产生强学习的Boosting算法,相比于较早的Adaboost通过调整每一轮训练样本的权重,XGBoost是通过拟合上一轮学习器的残差来训练模型。
上式是XGBoost的目标函数,第一部分是训练误差,第二部分是每棵树的复杂度的和。主要有以下优点:一是高度灵活性。支持线性分类器,对代价函数进行二阶泰勒展开。二是正则化。在代价函数加入了正则项,用于控制模型复杂度,防止过拟合。三是自动缺失值处理。对于存在缺失值的特征,可以自动学习出它的分裂方向。四是列抽样。借鉴了Randomforest对列随机抽样的做法,不仅能降低过拟合,还能减少计算量。
3.2 LightGBM模型
LightGBM算法是2017年由微软团队提出的GBDT算法的改进版,是基于梯度的单面采样算法(GOSS)和特征捆绑算法(EFB)的结合。GOSS采样认为梯度大的样本点会贡献贡多的信息增益,因此GOSS进行下采样的时候保留大梯度的数据,按比例随机采样梯度小的样本点。EFB算法通过绑定互斥的特征来减少互斥特征的数量从而实现降维的目的。LighGBM采用了Histogram算法,将连续特征离散化固定到固定数量的bins上。主要有以下优点:一是时间复杂度低。采用直方图算法将遍历样本转变为遍历直方图;二是计算量小。采用了基于Leaf-wise算法的增长策略构建树;三是内存占用少。采用互斥特征捆绑算法减少了特征数量;四是支持并行学习。采用优化后的特征并行、数据并行方法加速计算,当数据量特别大的时候还可以采用投票并行的策略。
4 模型构建与评估
数据预处理完成后,分别建立XGBoost、LightGBM模型,用AUC值作为模型主要评价指标。依据模型绘制出决策树,并进行特征重要性排序,从而得出结论。
4.1 模型评价指标
对于二分类模型,其阈值可能设定的高或低,通过设定不同的阈值得到不同的假正类率(FPR)和真正类率(TPR),ROC曲线就是将同一模型每个阈值的FPR作为横坐标,TPR作为纵坐标所形成的曲线。
由于ROC曲线的形状不好量化比较,因此需要结合ROC曲线与坐标系所围成的面积(AUC)来评价模型的预测性能。AUC评价指标相对于其他指标而言,更能衡量模型对于不平衡数据的预测能力,不关注具体得分,只关注排序结果,不需要设定阈值,评估效果更好。因此,本文选用AUC值作为模型评价指标。
4.2 模型建立——XGBoost
建模过程分为以下步骤:
1)训练集与测试集划分。按照8:2的比例划分训练集与测试集,在训练集进行模型训练,在测试集上用AUC值进行模型评价。
2)网格搜索调参。网格搜索算法是一种最简单也是最常用的超参数搜索算法,给定参数搜索范围,输出最优化的参数,如表8所示。
3)最优模型训练。给定最优化的参数,在训练集上进行训练,在测试集上的AUC值为0.872,模型泛化能力强,图1为ROC曲线。
4)获得模型结果。依据建立出的模型,可以绘制出决策树,如图2所示。
由图2可得出以下结论:
用特征分裂后带来的平均增益作为特征重要性评估标准,得到如图3所示的排序,其中,性别、烟草环境、是否支持增税为判断吸烟者的主要特征。可见,改善烟草环境能够有效降低成人的吸烟率,国家可出台相关政策进行管控。
重要性排前5的特征对AUC值的提升如表9所示。
4.3 模型建立——LightGBM
建模过程分为以下步骤:
1)训练集与测试集划分。按照8:2的比例划分训练集与测试集,在训练集进行模型训练,在测试集上用AUC值进行模型评价。
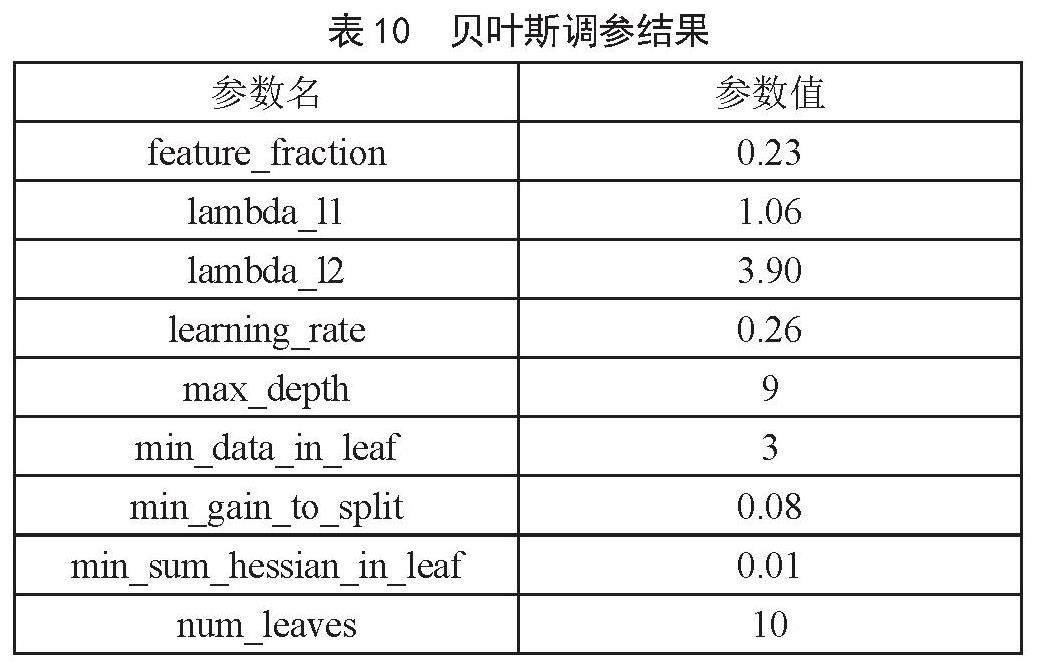
2)贝叶斯全局优化调参。贝叶斯优化是一个很有效的全局优化算法,目标是为了找到全局最优解。模型主要参数的选择如表10所示。
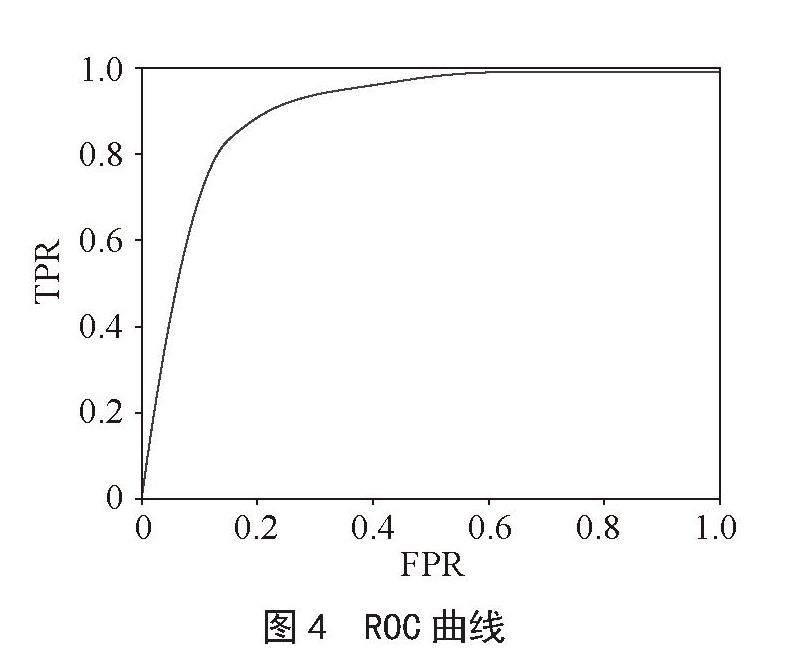
3)最优模型训练。给定最优化的参数,在训练集上进行训练,在测试集上的AUC值为0.874,模型泛化能力强,图4为ROC曲线。
4)获得模型结果。用全部变量进行建模,绘制出决策树,如图5所示。
依据该图的不同分支,可得出结论:
1)吸烟者画像:高中以下学历、在媒体上见过吸烟场景的男性。
2)不吸烟者画像:高中以上学历、未在媒体上见过吸烟场景的男性。
用特征分裂后带来的平均增益作为特征重要性评估标准,得到如图6所示的排序。
由图6可知,与XGBoost模型相同,性别、烟草环境、是否支持增税为判断吸烟者的主要特征。重要性排前5的特征对AUC值的提升如表11所示。
为进一步刻画出吸烟者画像,详细了解其特征,对部分变量进行组合建模,对绘制出的决策树图像进行分析,得出结论。
依据图7,可得出吸烟者画像为:支持增税、不认同低焦油烟危害以及吸烟引起心脏病;不支持增税、认同低焦油烟危害、18.5岁以上;在公共场所接触过二手烟、初中学历以下、18.5岁以上;未在公共场所接触过二手烟、年龄37.5岁以下;家里7口人以上、高中以下学历、农民工;家里6口人以下、小学以下学历、非农民工。
5 结 论
本文基于WHO组织2018年在中国开展的成人烟草调查数据,采用多阶段随机整群抽样方法,对其进行数据清洗、特征选择后,将XGBoost、LightGBM算法运用到成人吸烟行为预测模型中。研究表明,在算法上,LightGBM运行速度和模型分类能力均优于XGBoost;影响因素分析上,XGBoost和LightGBM算法均给出了影响因素重要性排序图,主要因素有:性别、烟草环境、增税态度、低焦油烟认知、学历、年龄等。通过对组合变量进行建模,由绘制出的决策树可以进一步刻画出吸烟者画,便于相关管理部门和控烟组织针对不同特征人群制定个性化控烟政策提供决策依据。
参考文献:
[1] 尹超英,邵春福,黄兆国,等.基于梯度提升决策树的多尺度建成环境对小汽车拥有的影响 [J].吉林大学学报:工学版,2022,52(3):572-577.
[2] 生红莹,赵伟国,陈扬,等.基于深度数据挖掘的电力系统短期负荷预测 [J].吉林大学学报:信息科学版,2023,41(1):131-137.
[3] 常硕,张彦春.基于袋外预测和扩展空间的随机森林改进算法 [J].计算机工程,2022,48(3):1-9.
[4] 甘红楠,张凯.参数自适应下基于近邻图的近似最近邻搜索 [J].计算机工程,2022,48(9):28-36.
[5] 彭俊,项薇,谢勇,等.基于LightGBM多阶段医疗服务等待时间的预测研究 [J].计算机应用与软件,2022,39(12):119-124.
[6] 闫瑞平,王习亮,姚粉霞,等.决策树模型与Logistic回归分析模型识别高血压危险因素的效果比较 [J].中华疾病控制杂志,2022,26(2):218-222.
[7] 胡嘉麟.基于LightGBM模型的车辆保险购买兴趣预测研究 [D].大连:大连理工大学,2021.
[8] 张汉平.基于LightGBM模型的个人贷款违约预测的研究 [D].武汉:华中师范大学,2021.
[9] 郭长东.基于XGBoost模型的股票预测研究 [D].延吉:延边大学,2021.
[10] 范桂英,汤军,高贤君,等.基于LightGBM的南阳市西部地区山洪灾害风险评价 [J].中国农村水利水电,2023(8):135-141+156.
[11] 钱芳慧,蔡竞.基于LightGBM的犯罪类型预测模型研究 [J].计算机仿真,2023,40(1):25-30.
[12] 吴照明,胡西川.基于LightGBM信贷风控模型的算法优化 [J].计算机应用与软件,2022,39(6):342-349.
[13] 郭长帅,卓建伟.基于数据挖掘算法的流动人口定居意愿研究 [J].管理现代化,2019,39(3):81-86.
[14] 冯斌,张又文,唐昕,等.基于BiLSTM-Attention神经网络的电力设备缺陷文本挖掘 [J].中国电机工程学报,2020,40(S1):1-10.
作者简介:刘忠华(1982—),男,汉族,云南楚雄人,统计师,农艺师,硕士研究生,主要研究方向:应用统计和数字农业;通讯作者:殷红慧(1977—),女,汉族,云南玉溪人,高级农艺师,硕士,主要研究方向:烟草农业研究。
