
基于深度学习的视频质量评价方法研究综述
2024-06-18 16:59:57杨文兵邱天张志鹏施博凯张明威
现代信息科技 2024年7期
杨文兵 邱天 张志鹏 施博凯 张明威


收稿日期:2023-08-31
基金项目:2021年江门市创新实践博士后课题研究资助项目(JMBSH2021B04);广东省重点领域研发计划(2020B0101030002)
DOI:10.19850/j.cnki.2096-4706.2024.07.017
摘 要:互联网时代充斥着海量的质量参差不齐的视频,低质量的视频极大地削弱人的视觉感官体验同时对储存设备造成极大压力,进行视频质量评价(VQA)势在必行。深度学习理论的发展为视频质量评价提供了新的思路,首先简单介绍视频质量评价理论知识和传统的评价方法,其次对基于深度学习的评价模型进行神经网络分类——2D-CNN和3D-CNN,并分析模型的优缺点,再次在公开数据集上分析经典模型的性能表现,最后对该领域存在的缺点和不足进行总结,并展望未来的发展趋势。研究表明:公开的数据集仍不充足;无参考的评价方法最具发展潜力,但其在公开数据集上的性能表现一般,仍有很大的提升空间。
关键词:深度学习;视频质量评价;2D-CNN;3D-CNN
中图分类号:TP391.4;TP18 文献标识码:A 文章编号:2096-4706(2024)07-0073-09
Literature Summary of Video Quality Assessment Methods Based on Deep Learning
YANG Wenbing, QIU Tian, ZHANG Zhipeng, SHI Bokai, ZHANG Mingwei
(Joint Laboratory of Digital Optical Chip of Wuyi University and Institute of Semiconductor Research, Chinese Academy of Sciences, Jiangmen 529020, China)
Abstract: The Internet era is full of a large number of videos with uneven quality. Low quality videos greatly weaken people's visual and sensory experience and cause great pressure on storage equipment. Therefore, Video Quality Assessment (VQA) is imperative. The development of Deep Learning theory provides a new idea for video quality evaluation, which is of great significance to video quality evaluation. Firstly, the theoretical knowledge of video quality evaluation and traditional evaluation methods are briefly introduced, and then the evaluation models based on Deep Learning are classified by neural network (2D-CNN and 3D-CNN), and the advantages and disadvantages of the models are analyzed. Then the performance of the classical models is analyzed on the open data set. Finally, the defects and deficiencies in this field are summarized, and the future development trend is forecasted. The research shows that the open data set is still insufficient, and the evaluation method without reference has the most potential for development, but its performance on the open data set is average, and there is still a lot of room for improvement.
Keywords: Deep Learning; VQA; 2D-CNN; 3D-CNN
0 引 言
视频在拍摄、压缩及传输过程中,不可避免地会出现失真问题。这些失真问题极有可能会导致重要信息缺失从而造成难以估量的损失。比如人脸识别身份核验时,摄像头采集的图片像素过低导致采集图像错误从而识别失败;气象卫星拍摄的气象图传输过程中失真,导致气象预测不准。在监控系统中,视频质量评价(video quality assessment, VQA)可以预测设备状态,从而及时对存在问题的设备进行维修或更换,在网络直播过程中,通过视频质量评价,可以改善终端用户体验[1]。视频质量评价已经成为小红书、Soul、抖音等视频播放平台必不可少的一个环节,这些平台相继进行评价算法研究和系统开发。
基于人工特征的传统的VQA方法已经不适应规模庞大的视频数据质量评价,同时,种类繁多、场景复杂、来源多变的视频需要不同的模型进行视频质量评价,以确保结果的准确性。本文对近年来国内外富有影响力的VQA方法及模型进行剖析,总结其算法原理及优缺点,为VQA的研究提供一定的参考资料。
简言之,本文的贡献在于:1)系统总结了近年来基于深度学习的VQA经典模型,并分析其评价原理和算法性能。2)在典型的公开数据集上进行对比,在单一数据集上找到近年来性能最好的算法。3)深入研究经典模型的优缺点,对VQA的发展现状的和发展趋势进行展望。
1 评价方法概述
评价方法可分为主观评价和客观评价,主观评价主要依据一定条件下的人为打分,主观平均得分(mean opinion score, MOS)或主观平均得分差异(Differential Mean Opinion Score, DMOS)即为主观评价结果,客观评价主要依靠计算机算法进行计算,最后获得的质量分数即为评价结果。客观评价方法分三种类型:全参考(Full Reference, FR)、半参考(Reduced Reference, RR)和无参考(No Reference, NR)。FR需要获取完整参考视频;RR仅需部分参考视频;而NR则不需要,只需要待评价视频。
在实际情况中,获取原始视频再进行质量评价需要大量的经济和时间成本,而无参考的评价方法省去这一环节从而可以大大降低评价过程中的经济和时间成本,因而在VQA领域,无参考的评价方法具有很大潜力和优势。
1.1 主观评价
主观评价结果取决于观察者肉眼主观感受。因此评价结果不确定性较高,具体表现在:受试者对质量较好/差的视觉信号的评价一致性较高,而对于质量一般的视觉信号的评价一致性相对较低[2]。根据ITU-R BT.500 [3]的建议,通常使用如表1所示的方法进行主观评价。DSIS代表双刺激损伤标度法、DSCQS代表双刺激连续质量标度法、SSCQE代表单刺激连续质量评价法、SDSCE代表同时双刺激连续质量评价法。评价基本流程是让观察者在一定时间内连续观看多个测试序列,其中包括了原始参考视频和失真视频。然后让观察者对视频序列的质量进行评分,最后使用平MOS或DMOS来表示最终的质量得分,判断视频质量。
1.2 客观评价
视频质量主观评价方法由于其低效率和高成本已经不再适用于当前的众多视频质量评价场景,比如监控场景和网络视频播放场景。主观评价结果受多因素影响,如观测场地环境、观看时长、个人身体及情绪状况和视频播放顺序。同时时间掩蔽效应[4]极易影响人类视觉系统,从而使评价结果出现偏差。因此,在实际情况中需要一种客观的、易于实现的视频客观质量评价方法。如图1所示,在视频质量客观评价方法中,全参考评价方法高度依赖原视频(参考视频),需要在像素级上将待评价视频和其对应的原视频进行像素比对从而获得评价结果,评价结果极有可能和主观评价结果不同;半参考的视频质量评价方法部分依赖原始视频(参考视频),通过视频特征提取、特征比对进行评价;而无参考的评价方法,完全不需要原视频进行模型训练,直接调用训练好的模型就能得到评价结果。
2 传统的评价算法
传统客观评价方法是通过使用计算机算法对视频进行自动分析和评估,对同一段测试序列,主客观评价结果要一致。可以从预测的单调性、一致性、稳定性和准确性来衡量评价算法本身的优劣[5]。传统评价算法的原理、区别和经典模型如表2所示。
最初的全参考评估方法采用(PSNR)峰值信噪比-均方差(MSE)[10]和ST-MAD [7]方法,在像素级上进行像素比对,最后得出质量评价结果,一般直接使用参考视频和待评价视频同一帧相同坐标上的像素差的平方根作为依据,这能直接反应视频质量的波动情况。这类方法计算过程简单,能够一定程度反应图像质量状况,因此至今仍然被广泛应用。但其未充分考虑人眼视觉特性,评价结果往往与主观评价结果不相符。其后,部分学者充分考虑人眼视觉特性(human visual system, HVS)算法进行改进,仿人眼特性的算法在一定程度上提升了算法的准确性。文献[11]提出了支持向量机(Support Vector Machine, SVM)的算法,算法效果仍不理想。MOVIE [6]算法的提出使得基于全参考的评价方法在性能上提升了一大截,成为全参考评价的经典算法。但绝大多数情况下,参考视频很难获得,这大大降低了该算法的实用性。基于结构相似性(Structural Similarity, SSIM)IQA [8]方法是里程碑式的最经典方法之一,它极大提升了算法的准确性。该方法不再把图像中像素信息改变作为研究的重点,而是将评价重心转移到基于结构信息的主观感知上来,使得客观评价结果更贴近相同条件下的主观评价结果,极大地提高了评价算法准确度和一致性。最初的无参考方法主要用于评价压缩编码失真视频,其设计难度较大。针对H264压缩失真视频,Brandao等人[9]提出了一种无参考评价方法,利用最大似然估计和线性预测结合来进行参数估计,最后获得预测质量。
3 基于深度学习的评价算法
视频是由多幅连续图像构成,包含了图像的运动信息。人眼识别的频率有限,单位时间内看到的图像数目超过25张/秒时会给人一种画面在运动的感觉,最初的视频质量评价方法大多源自图片质量评价方法。
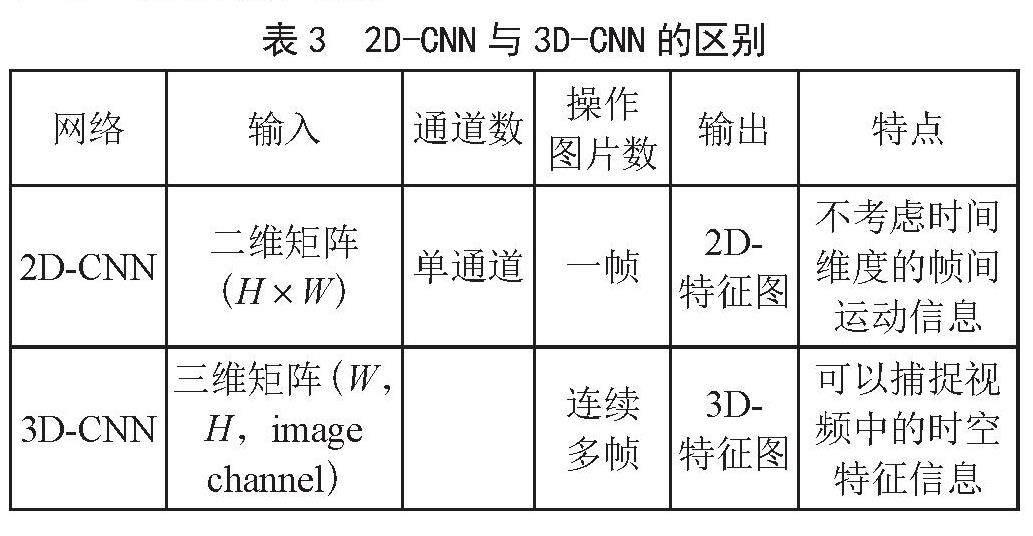
2006年发表的文献[12]开创性地将深度学习应用到客观评价上来,这是卷积神经网络和视频质量评价方法的首次结合,该方法有效解决了单刺激连续质量评估方法的预测问题。2014年,文献[13]提出了将CNN与无参考图像质量评价相结合,这些算法推动了图像视频质量评价算法进步。基于图像和视频之间的联系的2D-CNN(Two-Dimensional Convolutional Neural Network, 2D-CNN)主要是将视频的每一帧独立开来作为输入,这忽略各帧之间的关联信息,难以捕获时间信息[1]。3D-CNN以连续多帧作为输入,这些图片之间保持了连续性和连贯性,具有了时域信息,这能够提取到更具表达性的特征。表3是2D-CNN和3D-CNN的区别。
由表3可知,3D-CNN能够捕获视频中的空间和时间的特征信息,相比于2D-CNN,其更适合进行视频质量评价分析处理。
而2D-CNN由于其自身缺陷,需要人为引入迁移学习和其他时空特征提取技术才能使之适合视频质量评价。在基于深度学习的视频质量评价方面,根据有无参考视频,分为全参考和半参考,相比于传统客观评价方法缺少了半参考的类型;根据网络结构模型大致可分为采用基于2D-CNN的方法和基于3D-CNN的方法。
3.1 全参考评价方法
全参考视频评价方法要求必须获取完整的原始参考视频与失真视频,图2是FR-VQA流程图。评价过程依次为:预处理、特征提取、特征融合和回归模型。预处理即对输入的视频数据的分辨率和时长进行归一化处理,同时设定输入格式,2D-CNN以一帧图像作为输入,3D-CNN以连续几秒的视频块作为输入。特征提取过程则是利用卷积运算提取视频特征。特征融合时采用级联的方式将参考视频特征和失真视频特征进行融合;最后以融合后的时空特征和原始参考视频的MOS作为回归模型的输入,最后得到失真视频的质量分数。
客观评价得到的结果极易与主观打分不一致,因此在评价模型中很有必要引入人类视觉系统。如表4所示,Kim等人于2018年提出一种评估算法(Deep VQA)[14],该算法引入卷积神经聚合网络和注意力机制[15,16],一定程度上提高了模型评估的准确性。鉴于2D-CNN难以保留时域信息,Xu等人提出一种基于3D-CNN的评价方法C3DVQA [17],该方法使用3D卷积计算时空特征,模拟人类视觉系统,成功捕获了时域信息,提高了模型性能。在深度学习领域,充足数据集一直是进行模型训练的一个先决条件。为了解决参考视频样本不足这个问题,Zhang等人[18]于2020年提出一种基于特征迁移学习的全参考评价模型,该模型在一个特定特征空间中进行失真视频预处理转移,用特征迁移的方法丰富失真样本,有效解决了因训练样本不充足的问题,提升了预测的准确性。而Li [19]等人首次评估复杂场景下的人体运动质量的模型,该模型主要依靠参考视频和失真视频特征图的局部相似度进行评价。由于未充分考虑运动过程中的不确定性,该模型评估效果一般。
全参考的视频质量评价方法极度依赖参考视频,而参考视频的获取成本很高,同时用于训练模型的公开规范的数据集不充足,这些原因导致在真实场景下,基于深度学习的全参考视频质量评价方式不太适用于现实场景下的视频质量评价。
3.2 无参考评价方法
无参考方法不需要原始视频,通过失真视频的自身特征就能预测质量分数。无参考方法最具实用价值,有着非常广泛的应用范围。图3是基于深度学习的无参考方法的一般化流程图。
专家学者对无参考评价模型提出两点要求:一是普适于任意类型的失真,二是预测结果与人类主观视觉的感知一致。表5列举了无参考评价经典算法,这些算法建立在解决前面算法遇到的困境基础上,算法的性能逐步稳定提升。SACONVA [20]算法将视频分块之后提取特征,符合人类视觉感知习惯,但样本数据少、标签乱等问题影响了算法性能。文献[21-25]中提出的算法均旨在将视频时空特征融合使得评价结果更贴近现实,部分算法考虑人类视觉效应,但是基于2D-CNN的算法需要手动提取时间运动特征,在此过程中会丢失重要信息。LSTM [26]算法具有记忆功能,能保存评价预测结果,使得该算法在真实数据集上表现良好。
3.3 基于2D-CNN的方法
基于2D-CNN(二维卷积神经网络)的视频质量评价方法主要是利用卷积神经网络来学习视频内容的特征,并根据这些特征来评估视频的质量。其基本流程为:1)数据准备:收集包含不同质量的视频样本,包括原始高质量视频和压缩、降噪等处理后的低质量视频。2)数据预处理:对视频样本进行预处理,包括图像帧提取、尺寸调整等。3)特征提取:使用2D-CNN模型来学习视频的特征表示。4)特征融合:将提取的特征融合成一个视频级别的特征表示。5)质量评估:将视频的特征表示映射到对应的质量评分。6)模型训练和优化:使用训练集进行模型训练,并通过交叉验证等方法进行模型优化和参数调整。7)模型评估。
其网络结构的优点为:1)2D-CNN模型在学习视频特征表示方面表现出色。2)能够学习输入特征与视频质量之间的复杂非线性关系。3)支持无参考评价。4)模型可以利用帧序列的时空关系,捕捉到视频中的动作和运动信息,从而更好地反映视频质量的感知。
其缺陷在于其数据需求量大、训练复杂度高、光照和噪声敏感,光照变化和噪声可能会对评价结果产生一定影响。最大的问题是,在进行二维解算时会造成时域信息丢失。文献[25,27]用循环神经网络来解决时序问题,通过充分利用时间信息提取特征来提高模型性能,在自然失真视频数据集取得较好的预测效果。基于2D-CNN的评价方法主要有:1)V-BLIINDS [28](Video BLIINDS),该模型通过卷积和池化层来提取视频的特征表示,然后将这些特征传递给全连接层进行质量评分预测。2)VMAF [29](Video Multimethod Assessment Fusion),它使用多个基于2D-CNN的模型来预测视频的质量,然后将多个模型的评分进行融合得到最终的质量评分。
3)P-Net(Perceptual Net)[30],它通过学习来捕捉视频中的感知失真,并将其与主观质量评分进行关联。4)VGG-QA [31],其在训练阶段使用主观质量评分和视频帧之间的误差作为损失函数进行优化。目前通过手动提取时域特征能够有效改善2D卷积上时域信息丢失问题,但数据预处理很复杂,效率不高。
3.4 基于3D-CNN的方法
3D-CNN不需要手动加入时域特征就能效捕捉视频对象的时空信息,其更适合于视频质量评价。3D-CNN的输入多了一个时间维度,这个维度是视频上的连续帧或立体图像中的不同切片。
如表6所示,基于3D-CNN的评价方法主要有:视频多任务端到端优化的深度神经网络(Video Multi-Task End-to-End Optimized Neural Network, V-MEON)[32],
Hou等人提出的一种三维深度卷积神经网络[33],Yang等人提出的基于3D-CNN的立体视频质量评估(Stereoscopic Video Quality Assessment, SVQA)框架[34],Yang等人提出的针对VR视频的基于3D-CNN的端到端网络框架[35],R-C3D [36]等。
这些方法利用3D-CNN模型的时空建模和自动特征提取能力,并结合其他方法或技术,能够较好地评估视频质量。它们能够捕捉视频的动态特征、提供准确的评估结果,并具有较好的细粒度性能和鲁棒性。然而,具体选择哪种方法还需根据具体任务和数据情况进行综合考虑。
4 评价数据集
在基于传统评价方法的评价过程中,这些公开统一、失真类型多样的数据集用来验证算法的性能;在基于深度学习的评价模型中,这些数据集用来训练模型和验证算法的性能。这些数据集包括合成失真数据集LIVE VQA [37],CSIQ [38],VCD2014 [39],LIVE-Q [40],真实失真数据集KonIQ-1k [28],YouTube UGC [41]等。这些真实失真的数据库更加人性化,提供图像信息,方便科研人员统计分析。下文中提到的算法均采用表7所示的数据集来验证其算法的优越性和可靠程度。
5 算法评价指标
对于如何评价一个视频质量评价算法的性能,视频质量专家组(Video Quality Experts Group)建议[42]从单调性、准确性、一致性[43]三方面进行考虑。客观评价模型的指标是基于客观模型输出的预测质量分数与主观质量分数间的单调性、准确性和一致性。本文提到的算法也用这些指标评价算法优劣和准确性,常用的评价指标有以下几个。
5.1 皮尔森线性相关系数
皮尔森线性相关系数(Pearson Linear Correlation Coefficient, PLCC)[44],表示客观预测值和主观打分之间的线性相关性,如式(1):
(1)
其中,N表示失真视频的数量,Ci表示第i个视频的主观评价分数,Di表示第i个视频的质量预测分数; 表示主观打分值均值; 表示客观预测值均值。PLCC表示模型评价结果的准确性,PLCC值越趋近于1,预测结果越准确;反之则预测越不准确。
5.2 斯皮尔曼秩序相关系数
斯皮尔曼秩序相关系数(Spearman Rank Order Correlation Coefficient, SROCC)[45]是非线性指标,其根据原始数据的排序位置进行计算,如式(2):
(2)
其中,Di表示两个变量的秩次;N表示变量的数量。SROCC表示模型预测值与主观打分的靠近趋势,也能反映变量单调变化情况,SROCC取值[-1,1],值越接近于1说明预测分数与主观打分相关正相关性越高。
5.3 均方根误差
均方根误差(Root Mean Square Error, RMSE)表示模型预测分数与主观质量分数的差异大小,如式(3):
(3)
其中,Ci表示模型预测值,Di表示真实值(主观打分值均值),RMSE用来衡量预测可靠性、算法的稳定性,其值越小越好。
6 模型性能分析
6.1 传统模型性能分析
如前面章节所述,选用PLCC和SROCC分别衡量算法的相关性和单调性。表8中数据由各自论文提供。无固定名称算法以其第一作者名字代替,值保留小数点后三位,性能最好的算法数值用加粗标出。对于传统方法,公开的评价数据集中视频失真类型均为人为失真类型,故传统方法大多以人为失真数据集LIVE-VQA为实验标准数据集。表中,Wireless和IP等代表不同的失真类型的视频。
Wireless表示基于H.264压缩失真;IP表示无线网络传输错误失真;MPEG-2表示MPEG-2压缩失真类型;H.264表示H.264压缩失真类型;ALL表示在整个LIVE-VQA数据集上进行的实验,—表示数据缺失。
如表8所示,基于运动信息的全参考方法MOVIE和ST-MAD中,ST-MAD模型在失真类型为IP的数据集上表现较差,SROCC和PLCC均不到0.800;MOVIE模型仅在Wireless失真数据集上表现较好,两个指标均在0.800以上。在整个数据集上这两个算法SROCC和PLCC都达到0.780以上。这表明运动信息是有效的,但效果仍然不理想。而基于结构相似性的SSIM算法是半参考经典算法,其在整个数据集上性能优越,SROCC和PLCC分别达到了0.934和0.865。
6.2 基于深度学习的模型性能分析
自然失真的数据集更符合现实环境,而在此基础上进行质量评价更加具有挑战性。如表9所示,与传统的典型算法还有无参考的基于深度学习算法相比,加入3D卷积的全参考型C3DVQA算法在整体上有最好的评估效果,在LIVE和CSIQ数据库上的PLCC值和SROCC值都达到0.900以上的评估值,这是非常可观的;同时,全参考的评价方法整体上性能表现比无参考的评价方法优越,无参考的评价方法面临的最大的问题就是,在真实失真的数据集上性能表现较差。2D卷积的无参考型算法大都表现均匀良好,但是性能不算突出,这归功于2D-CNN优秀的特征提取能力,但评估效果都未有达到0.900以上的,远低于全参考型模型。而无参考的3D-CNN算法表现不尽如人意,PLCC仅有0.785,和全参考的3D-CNN相差较多。
6.3 近年来优秀的算法
表10分别为近5年来(2018—2023)VQA在典型的真实失真的数据集KoNViD-1K、LIVE-VQC、YouTube-UGC上最好的性能表现。
由表10可知,DOVER(end-to-end)算法在3个真实失真的数据集上均取得了最好的性能表现,PLCC值在0.900左右上下浮动。
7 结 论
基于深度学习的评价模型在训练过程中需要大量的训练和预测视频数据,然而目前规范性的公开视频数据集还不足以支撑模型训练。另一方面,自制视频数据集代价高昂,难以达到。样本数据集不充足导致评估效果不佳。大多模型采用迁移学习,通过特征迁移,以图像特征丰富视频特征,或以迁移模型提高评估能力。
实践证明,基于深度学习的视频质量评价方法比传统的方法更高效、精确,已经成为VQA研究人员的主要研究方向。对于视频分析而言,3D-CNN比2D-CNN更适合于视频质量分析。3D-CNN适用于复杂的立体视频、全方位视频以及VR视频,同时消耗资源较少。
VQA的研究还有许多问题,需要进一步解决,具体如下:1)工业界统一的需要评价标准和方法。视频质量评价是视频编解码领域一个至关重要的课题,同时具有极其重要的现实意义。随着深度学习的快速发展,越来越多的学者提出了各种算法模型进行视频质量评价,理论发展的目的是应用于实践。因此,提出一个学者们公认的统一的高效的、准确率高的算法;一些统一的合理的评价指标是视频质量评价算法研究的必然趋势。2)扩大现有公共数据库是必然趋势。就目前而言,现存的用于视频质量评价的统一的公共数据库数量稀少,并且每一个数据库中现存的视频数据量较少,完全不能满足深度学习数据集的要求,扩大公共数据库是必然趋势。3)NR-VQA是必然趋势。无参考的方法不需要原视频作为对照,这极大地简化了评价的过程,同时基于深度学习的视频质量评价方法能够完美契合无参考的评价方法,NR-VQA是必然趋势,提升无参考评价模型在真实失真的数据集上的性能是当务之急。4)音视频加字幕联合评价是重要方向。在一段高质量视频里面,音频、视频还有字幕是和谐地组合在一起的,声音和视频同步也是视频质量的基本要求。因此视频质量评价的过程中,除了评价视频每一帧的图像质量,音视频联合评价也是一个极其重要的方向。
参考文献:
[1] 程茹秋,余烨,石岱宗,等.图像与视频质量评价综述 [J].中国图象图形学报,2022,27(5):1410-1429.
[2] ZHANG W X,MA K D,ZHAI G T,et al. Uncertainty-Aware Blind Image Quality Assessment in the Laboratory and Wild [J].IEEE Transactions on Image Processing,2021,30:3474-3486.
[3] 国家广播电影电视总局标准化规划研究所.数字电视图像质量主观评价方法:GY/T 134-1998 [S].北京:国家广播电影电视总局标准化规划研究所,1998.
[4] SUCHOW J W,ALVAREZ G A. Motion Silences Awareness of Visual Change [J].Current Biology,2011,21(2):140-143.
[5] 谭娅娅,孔广黔.基于深度学习的视频质量评价研究综述 [J].计算机科学与探索,2021,15(3):423-437.
[6] SESHADRINATHAN K,BOVIK A C. Motion Tuned Spatio-Temporal Quality Assessment of Natural Videos [J].IEEE Transactions on Image Processing,2010,19(2):335-350.
[7] VU P V,VU C T,CHANDLER D M. A Spatiotemporal Most-Apparent-Distortion Model for Video Quality Assessment [C]//2011 18th IEEE International Conference on Image Processing.Brussels:IEEE,2011:2505-2508.
[8] TAGLIASACCHI M,VALENZISE G,NACCARI M,et al. A Reduced-Reference Structural Similarity Approximation for Videos Corrupted by Channel Errors [J].Multimedia Tools and Applications,2010,48(3):471-492.
[9] BRAND?O T,QUELUZ T R M P. No-Reference Quality Assessment of H.264/AVC Encoded Video [J].IEEE Transactions on Circuits and Systems for Video Technology,2010,20(11):1437-1447.
[10] QIAN J S,WU D,LI L D,et al. Image Quality Assessment Based on Multi-Scale Representation of Structure [J].Digital Signal Processing,2014,33:125-133.
[11] MOORTHY A K,BOVIK A C. A Two-Step Framework for Constructing Blind Image Quality Indices [J].IEEE Signal Processing Letters,2010,17(5):513-516.
[12] CALLET P L,VIARD-GAUDIN C,BARBA D. A Convolutional Neural Network Approach for Objective Video Quality Assessment [J].IEEE Transactions on Neural Networks,2006,17(5):1316-1327.
[13] KANG L,YE P,LI Y,et al. Convolutional Neural Networks for No-Reference Image Quality Assessment [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:1733-1740.
[14] KIM W,KIM J,AHN S,et al. Deep Video Quality Assessor: From Spatio-Temporal Visual Sensitivity to a Convolutional Neural Aggregation Network [C]//Computer Vision – ECCV 2018: 15th European Conference.Munich:Springer-Verlag,2018:224-241.
[15] VINYALS O,BENGIO S,KUDLUR M. Order Matters: Sequence to Sequence for Sets [J/OL]. arXiv:1511.06391 [stat.ML].(2016-02-23)[2023-08-20].https://arxiv.org/abs/1511.06391.
[16] YANG J L,REN P R,ZHANG D Q,et al. Neural Aggregation Network for Video Face Recognition [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:5216-5225.
[17] XU M N,CHEN J M,WANG H Q,et al. C3DVQA: Full-Reference Video Quality Assessment with 3D Convolutional Neural Network [C]//2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).Barcelona:IEEE,2020:4447-4451.
[18] ZHANG Y,GAO X B,HE L H,et al. Objective Video Quality Assessment Combining Transfer Learning With CNN [J].IEEE Transactions on Neural Networks and Learning Systems,2020,31(8):2716-2730.
[19] LI Y D,HE H M,ZHANG Z X. Human Motion Quality Assessment Toward Sophisticated Sports Scenes Based on Deeply-Learned 3D CNN Model [J/OL].Journal of Visual Communication and Image Representation,2020,71:102702[2023-08-20].https://doi.org/10.1016/j.jvcir.2019.102702.
[20] LI Y M,PO L M,CHEUNG C H,et al. No-Reference Video Quality Assessment With 3D Shearlet Transform and Convolutional Neural Networks [J].lEEE Transactions on Circuits and Systems for Video Technology,2016,26(6):1044-1057.
[21] WANG C F,SU L,HUANG Q M. CNN-MR for No Reference Video Quality Assessment [C]//2017 4th International Conference on Information Science and Control Engineering (ICISCE).Changsha:IEEE,2017:224-228.
[22] AHN S,LEE S. Deep Blind Video Quality Assessment Based on Temporal Human Perception [C]//2018 25th IEEE International Conference on Image Processing (ICIP).Athens:IEEE,2018:619-623.
[23] VARGA D. No-Reference Video Quality Assessment Based on the Temporal Pooling of Deep Features [J].Neural Processing Letters,2019,50(3):2595-2608.
[24] LOMOTIN K,MAKAROV I. Automated Image and Video Quality Assessment for Computational Video Editing [C]//International Conference on Analysis of Images,Social Networks and Texts.[S.I.]:Springer,2020:243-256.
[25] LI D Q,JIANG T T,JIANG M. Quality Assessment of In-the-Wild Videos [C]//Proceedings of the 27th ACM International Conference on Multimedia.Nice:ACM,2019:2351-2359.
[26] VARGA D,SZIR?NYI T. No-Reference Video Quality Assessment Via Pretrained CNN and LSTM Networks [J].Signal,Image and Video Processing,2019,13:1569-1576.
[27] HOSU V,HAHN F,JENADELEH M,et al. The Konstanz Natural Video Database (KoNViD-1k) [C]//2017 Ninth International Conference on Quality of Multimedia Experience (QoMEX).Erfurt:IEEE,2017:1-6.
[28] SAAD M A,BOVIK A C,CHARRIER C. Blind Prediction of Natural Video Quality [J].IEEE Transactions on Image Processing,2014,23(3):1352-1365.
[29] DASGUPTA I,SHANNIGRAHI S,ZINK M. A Hybrid NDN-IP Architecture for Live Video Streaming: From Host-Based toContent-Based Delivery to Improve QoE [J].International journal of semantic computing,2022,16(2):163-187.
[30] CHRYSOS G G,MOSCHOGLOU S,BOURITSAS G,et al. P–nets: Deep Polynomial Neural Networks [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle:IEEE,2020:7323-7333.
[31] HU X L,AN Z L,YANG C G,et al. DRNet: Dissect and Reconstruct the Convolutional Neural Network via Interpretable Manners [J/OL]. arXiv:1911.08691 [cs.CV].(2020-02-26)[2023-08-20].https://arxiv.org/abs/1911.08691.
[32] LIU W T,DUAN M Z F,WANG Z. End-to-End Blind Quality Assessment of Compressed Videos Using Deep Neural Networks [C]//Proceedings of the 26th ACM international conference on Multimedia.Seoul:ACM,2018:546-554.
[33] HOU R,ZHAO Y H,HU Y,et al. No-Reference Video Quality Evaluation by a Deep Transfer CNN Architecture [J/OL].Image Communication,2020,83(C):115782[2023-07-26].https://doi.org/10.1016/j.image.2020.115782.
[34] YANG J C,ZHU Y H,MA C F,et al. Stereoscopic Video Quality Assessment Based on 3D Convolutional Neural Networks [J].Neurocomputing,2018,309:83-93.
[35] YANG J C,LIU T L,JIANG B,et al. 3D Panoramic Virtual Reality Video Quality Assessment Based on 3D Convolutional Neural Networks [J].IEEE Access,2018,6:38669-38682.
[36] 桑农,张士伟,马百腾,等.一种基于R-C3D网络的端到端视频时序行为检测方法:CN110738129A [P].2022-08-05.
[37] SESHADRINATHAN K,SOUNDARARAJAN R,BOVIK A C,et al. Study of Subjective and Objective Quality Assessment of Video [J].IEEE Transactions on Image Processing,2010,19(6):1427-1441.
[38] VU P V,CHANDLER D M. ViS3: An Algorithm for Video Quality Assessment Via Analysis of Spatial and Spatiotemporal Slices [J/OL].Journal of Electronic Imaging,2014,23(1):013016[2023-06-28].https://doi.org/10.1117/1.JEI.23.1.013016.
[39] NUUTINEN M,VIRTANEN T,VAAHTERANOKSA M,et al. CVD2014—A Database for Evaluating No-Reference Video Quality Assessment Algorithms [J].IEEE Transactions on Image Processing,2016,25(7):3073-3086.
[40] GHADIYARAM D,PAN J,BOVIK A C,et al. In-Capture Mobile Video Distortions: A Study of Subjective Behavior and Objective Algorithms [J].IEEE Transactions on Circuits and Systems for Video Technology,2018,28(9):2061-2077.
[41] WANG Y L,INGUVA S,ADSUMILLI B. YouTube UGC Dataset for Video Compression Research [C]//2019 IEEE 21st International Workshop on Multimedia Signal Processing (MMSP).Kuala Lumpur:IEEE,2019:1-5.
[42] 郭继昌,李重仪,郭春乐,等. 水下图像增强和复原方法研究进展 [J].中国图象图形学报,2017,22(3):273-287.
[43] 肖毅.基于多特征的水下视频客观质量评价方法研究 [D].上海:上海海洋大学,2022.
[44] PEARSON K. VII. Note on Regression and Inheritance in the Case of Two Parents [J].Proceedings of the Royal Society of London,1895,58:240-242.
[45] YANG J C,LIN Y C,GAO Z Q,et al. Quality Index for Stereoscopic Images by Separately Evaluating Adding and Subtracting [J/OL]. PLOS ONE,2015,10(12):e0145800[2024-09-26].https://europepmc.org/backend/ptpmcrender.fcgi?accid=PMC4699220&blobtype=pdf.
[46] XU J T,YE P,LIU Y,et al. No-Reference Video Quality Assessment Via Feature Learning [C]//2014 IEEE International Conference on Image Processing (ICIP).Paris:IEEE,2014:491-495.
[47] ZHANG Y,GAO X B,HE L H,et al. Blind Video Quality Assessment With Weakly Supervised Learning and Resampling Strategy [J].IEEE Transactions on Circuits and Systems for Video Technology,2019,29(8):2244-2255.
[48] TU Z Z,YU X X,WANG Y L,et al. RAPIQUE: Rapid and Accurate Video Quality Prediction of User Generated Content [J].IEEE Open Journal of Signal Processing,2021:425-440.
[49] LI B W,ZHANG W X,TIAN M,et al. Blindly Assess Quality of In-the-Wild Videos via Quality-Aware Pre-Training and Motion Perception [J].IEEE Transactions on Circuits and Systems for Video Technology,2022,32(9):5944-5958.
[50] SUN W,MIN X K,LU W,et al. A Deep Learning based No-reference Quality Assessment Model for UGC Videos [C]//Proceedings of the 30th ACM International Conference on Multimedia.Lisboa Portugal:ACM,2022:856-865.
[51] WU H N,CHEN C F,HOU J W,et al. FAST-VQA: Efficient End-to-End Video Quality Assessment with Fragment Sampling [J/OL].ArXiv:2207.02595 [cs.CV].(2022-07-06)[2023-07-12].https://doi.org/10.48550/arXiv.2207.02595.
[52] WU H N,ZHANG E,LIAO L,et al. Exploring Video Quality Assessment on User Generated Contents from Aesthetic and Technical Perspectives 2023 IEEE/CVF International Conference on Computer Vision (ICCV) [C]//2023 IEEE/CVF International Conference on Computer Vision(ICCV).Paris:IEEE,2023:20087-20097.
作者简介:杨文兵(1993—),男,汉族,江苏扬州人,硕士研究生,主要研究方向:视频质量评价和视频编解码;通讯作者:邱天(1977—),男,汉族,河南周口人,副教授,博士,主要研究方向:图像处理、集成电路设计及智能设备等。
猜你喜欢
中共云南省委党校学报(2022年1期)2022-04-26 13:55:44
小学生优秀作文(低年级)(2020年4期)2020-07-24 08:31:16
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
当代陕西(2019年10期)2019-06-03 10:12:04
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
法律方法(2018年2期)2018-07-13 03:22:06
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
现代防御技术(2016年1期)2016-06-01 12:13:27
