
科创项目信息提取系统设计
2024-06-18 06:58:06柏斌
现代信息科技 2024年7期

收稿日期:2023-08-31
DOI:10.19850/j.cnki.2096-4706.2024.07.005
摘 要:文章分析讨论了半结构化信息管理技术的发展状况和应用情况,在梳理和总结半结构化文本信息抽取载体类型、内容和技术方法的基础上,设计了科创项目信息提取系统。该系统数据源以科研院所/创业团队提供的商业策划书为主,采用B/S架构,以基础设置、数据层、应用层和用户层四层逻辑构架为基础,通过业务逻辑后台、文件解析模块、项目关键信息抽取服务三大功能模块,实现对科创项目策划书文本数据采集、关键信息提取、数据存储以及数据服务的高效管理。实践结果表明,该系统功能达到了预期设计目标,运行稳定、高效。
关键词:半结构化信息;科创项目;信息提取系统
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2024)07-0019-06
Design of Information Extraction System for Science and Technology Innovation Projects
BAI Bin
(Shanghai Yunju Shuchuang Network Technology Co., Ltd., Shanghai 201401, China)
Abstract: This paper analyzes and discusses the development and application of semi-structured information management technology. Based on sorting and summarizing the types, contents, and technical methods of semi-structured text information extraction carriers, an information extraction system for science and technology innovation project is designed. The data source of this system is mainly business proposals provided by research institutes/entrepreneurial teams, using a B/S architecture. It is based on a four layer logical framework of basic settings, data layer, application layer, and user layer. Through three functional modules: business logic backend, file parsing module, and project key information extraction service, it achieves efficient management of text data collection, key information extraction, data storage, and data services for science and technology innovation project proposals. The practical results show that the system function has achieved the expected design goals, it operates stably and efficiently.
Keywords: semi-structured information; science and technology innovation project; information extraction system
0 引 言
科技成果转化的关键在于“精准对接”,其核心在于识别科技成果的核心亮点,进而从海量数据中快速、准确的检索到匹配需要的资源。传统的做法主要依靠人力完成,效率低且效果不可靠。利用人工智能技术对项目文档中关键词信息抓取、整理、关联挖掘出有效信息,并以可视化的方式直观展示,可以大幅提高科技成果和企业需求匹配效率。
1 现状分析
从科创项目策划书文本数据构成上看,主要是以半结构化信息为主,结构化信息只占了其中很小的一部分,如何有效提取大量的以半结构化化信息为主的科创项目信息,在此基础上提炼出对项目决策有辅助作用的知识,已成为当前科创项目信息处理的一个热点。本文通过对前人在面向半结构化文本信息抽取载体类型、内容和技术方法方面的研究进展进行了梳理和总结,从而为更好地实现以半结构化文本为主的科创项目文本关键信息的提取提供思路。
在半结构化文本抽取载体类型研究方面,按半结构化文本资源的表达形式将信息抽取的载体类型划分为科技文献和网络文献[1]。其中,在科技文献方面,丁君军等人[2]对学术期刊中的属性描述进行了情感信息和数量关系的分析,并对学术概念属性抽取系统进行设计和实现。刘一宁等人[3]提出了一种学术定义抽取系统,通过使用语法规则和词频统计的方法实现信息抽取目的。在网络文献方面,Shah等人[4]设计了一种从包含自由文本和语义标记Web中检索文档的方法,并发现通过结合索引和语义标记提高检索效率的目的。Tang等人[5]讨论了在ArnetMiner系统中的关键问题,针对在学术社会网络中实现对专家信息的抽取并挖掘。
在半结构化文本抽取内容研究方面,Pollak等人[6]通过使用形态语法、自动术语识别和语义标注技术,提出了针对领域语料中抽取定义候选集的工作流,定义抽取工作能够被重复使用并可转化为其他语言类型。Ferneda等人[7]以法律文书为载体,研究了法律定义词汇特定的规范性规则,利用规模样本训练了SVM分类器,并在一个测试语料中对该方法进行了评价。王雪芬等人[8]针对专家信息库来源单一等问题,结合专家库中人物属性的特点,提出了基于社会网络的专家检索技术方案。
在半结构化文本抽取技术方法研究方面,Califf [9]提出采用一种模式匹配规则对文本信息进行抽取。Ciravegna等人[10]通过利用LearningPinocchio工具包对规则进行学习,实现了对以简历为样本的半结构化文本信息进行抽取。黎伟健等人[11]采用大数据思维研究了半结构化数据的文本挖掘方法,总结出针对较大规模文本量的分析过程,为海量文本的数据提取方法提供了参考。周法国等人[12]基于内在认知机理的知识发现理论,探讨了半结构化信息抽取中的关键技术,如机器学习技术、篇章分析与理解技术等,对非结构化信息实体识别、关系识别都有涉及。张博[13]对比各个统计模型后,采用一种优化后的方法对各类半结构化文本的关键信息进行抽取,结合领域知识库对抽取结果进行二次抽取,抽取结构准确性得到了有效提高。
2 系统功能需求分析
科创项目信息服务系统的数据源主要来自科研院所/创业团队提供的项目策划书文本信息,其系统功能需求主要从数据配置管理、项目文本数据采集、项目文本信息提取、项目数据存储、项目数据服务、系统维护以及用户管理几个方面进行分析:
1)数据配置管理。可实现对项目文本关键词字段参数增、删、改、查及导入导出功能。
2)项目文本数据采集。可实现对图片和文字性PDF格式的项目文件进行数据采集功能。
3)项目文本信息提取。根据配置字段内容,可实现对项目文本文件关键信息进行提取,并能对文本提取后的关键信息进行浏览、编辑、入库。
4)项目数据存储。包括数据库结构设计和实现,提取信息入库,数据增、删、改、查及数据的导入和导出功能。
5)项目数据服务。包括门户界面、项目检索、项目策划书内容详情查看、项目策划书关键信息提取后的文档查看、校订、检索与对比、批量导出、项目人员权限管理等模块。
6)系统维护(系统设置)。包括用户信息、系统日志、软件升级等。
7)用户管理。包括超级管理员、用户、数据维护人员等类型用户的注册、登录、密码和角色管理。
3 系统设计
3.1 系统设计概述
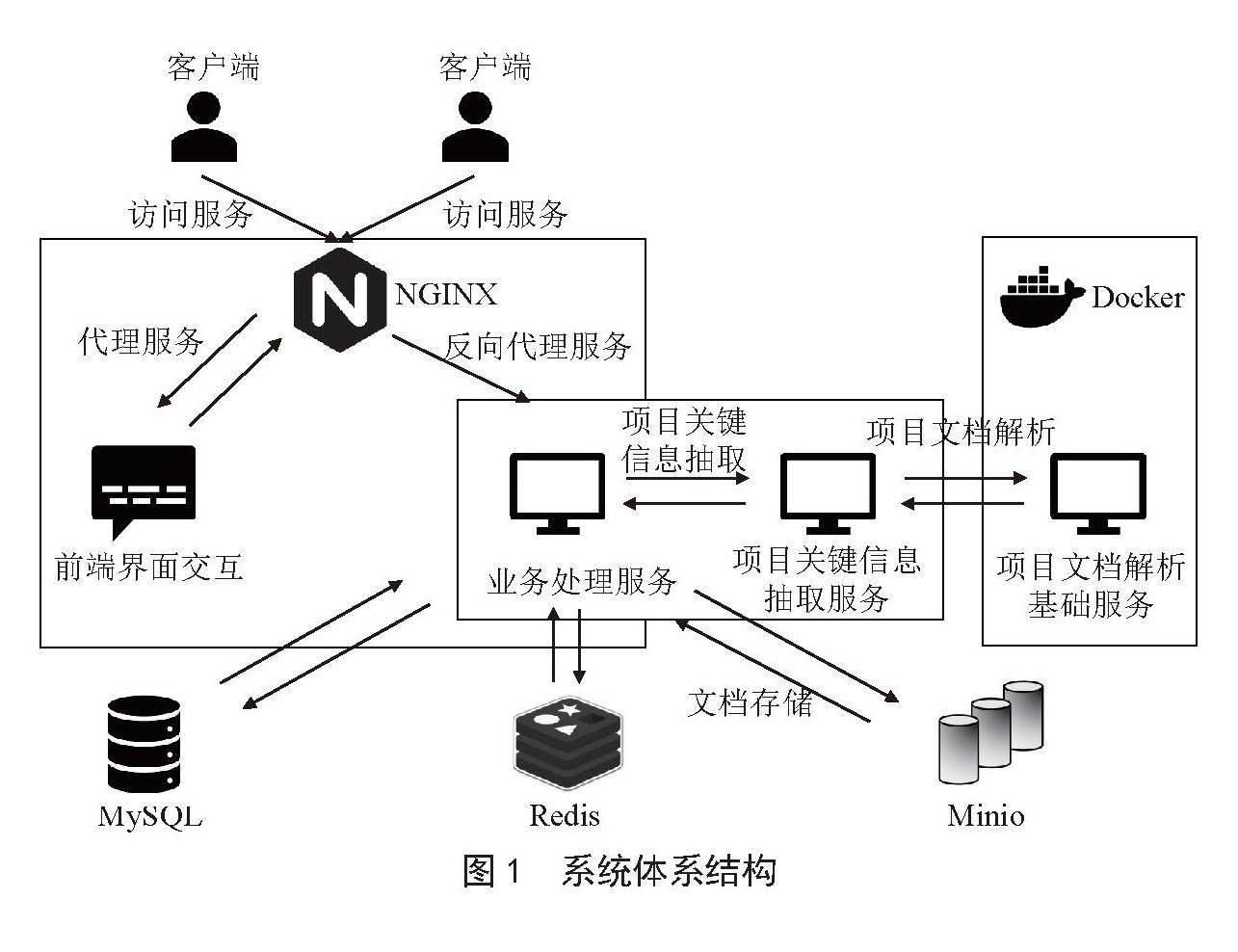
系统采用以浏览器和服务器架构模式的B/S架构,用户通过NGINX代理访问前端页面,同时所产生的数据请求交互通过NGINX反向代理后台业务服务完成对存储于MySQL、Redis、Minio等永久化数据进行交互。后台业务服务主要通过Java环境运行,其中项目抽取部分则依赖项目抽取服务,先将PPT和PPT形式的PDF文件转换为文本信息,在对文本信息进行处理。系统体系架构图如图1所示。
3.2 系统构架设计
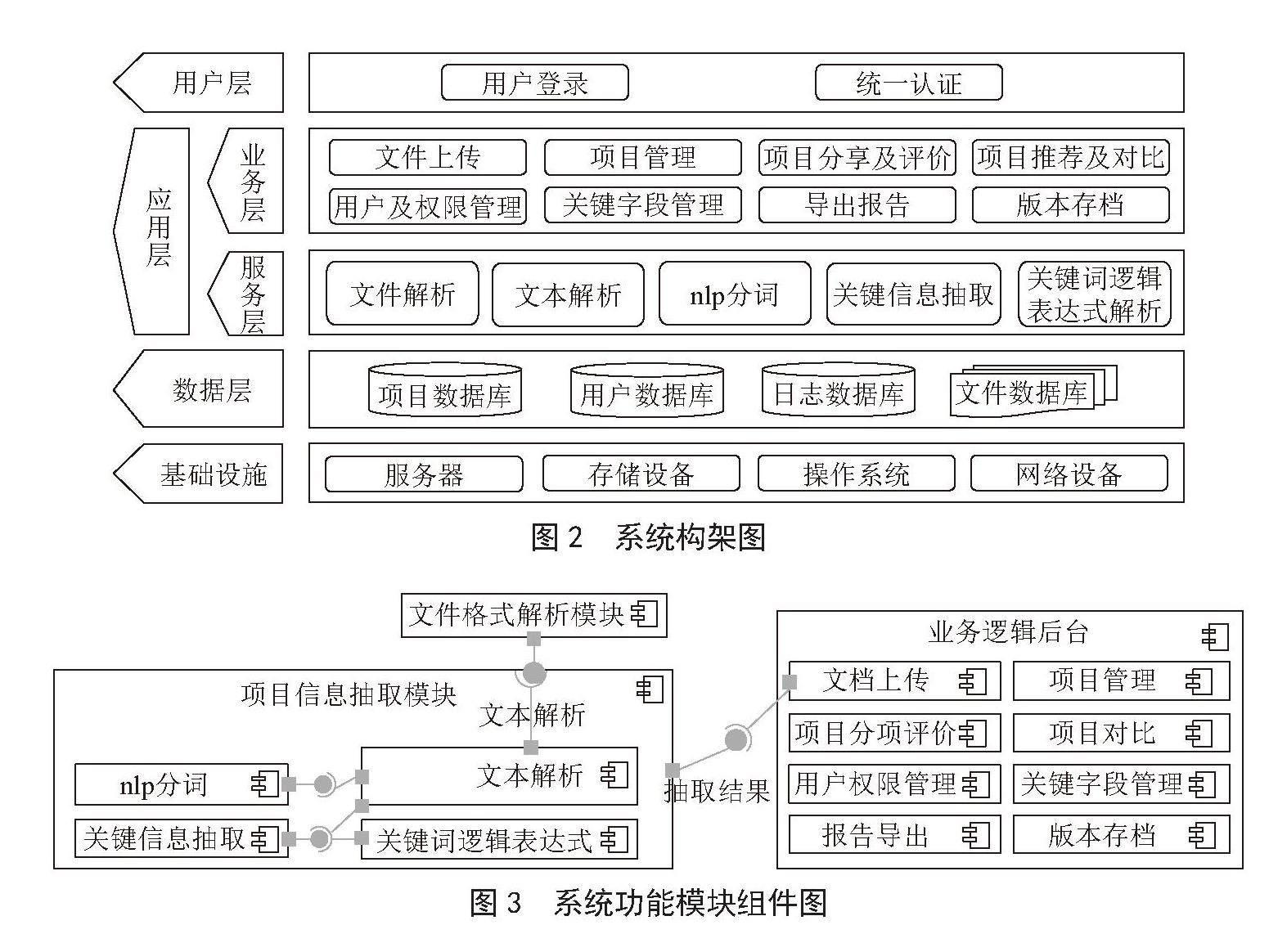
系统构架图如图2所示,从逻辑结构上系统结构主要分为基础设施、数据层、应用层和用户层,其中,基础设施层主要包括网络、服务器、存储、存储设备等硬件条件是系统运行的基础保证。数据层是用户存储系统的数据,系统数据有多种类型,包括项目数据库、用户数据库、日志数据库、文件数据库。其中文件数据库是用户存储项目原始文件。应用层根据系统需求可分为应用层和服务层。服务层介于数据层和业务应用层,为业务应用层提供支持,包括文件解析服务、文本解析服务、自然语言处理服务、关键信息抽取服务及关键词逻辑表达式解析服务,从物理结构上将服务层划分为PDF解析模块及项目信息抽取模块;业务应用层是指具体的业务应用系统功能模块,包括文件上传、项目管理、项目分享及评价、项目推荐及对比、用户权限管理、关键字段管理、导出报告、版本存档,该部分从物理结构划分到业务逻辑后台。用户层为用户提供使用系统的入口,主要通过浏览器进行访问,包括用户登录及统一认证服务。
3.3 主要功能模块
在上述系统构架设计基础上,将系统应用层从物理结构上划分为业务逻辑后台、文件解析模块、项目关键信息抽取服务模块,功能模块组件图如图3所示。
3.3.1 业务逻辑后台
业务逻辑后台模块主要包括文档上传、项目管理、项目分享及评价、项目推荐及对比、用户权限管理、关键字段管理、导出报告、版本存档等子模块,各个子模块之间相对独立。
业务逻辑后台基于Java语言进行开发,主要使用Spring Boot框架,搭配使用MyBatis Plus、Spring Data Redis框架对数据库进行操作。其中文档上传中的各文档数据主要存储在Minio文件存储系统中。
3.3.2 文档解析模块
文档解析模块基于Python语言进行开发,主要基于PDFPlumber提供对PPT形式的PDF进行解析。可查找PDF文本字符、矩阵、行的详细信息。该模块主要提供对PPT形式的PDF进行解析的API接口,将PDF中的文本解析提取进行返回,以便后续关键信息抽取模块的使用。
3.3.3 项目关键信息抽取模块
项目关键信息抽取模块主要包括对文件的文本解析、对解析后的文本进行分词处理、对预定义的关键字段及自定义的关键词逻辑表达式的关键字段信息进行抽取。
抽取模块主要采用NLP及其基础处理(分词、词性标记、命名实体识别)、文本分类(深度神经网络;简单关键字规则)、基于语义特征的文本抽取(语法、词性、命名识体识别结果)、基于规则的文本检索(双向关键字复合搜索算法)。
抽取过程中,首先对文本进行预处理包括分句、大小写转换,符号统一等,最终获取句子级别的文本。通过BERT-LSTM-CRF多任务自然语义处理(NLP)基础模型对句子进行分词、词性标记、命名实体识别。其次,通过设计触发词,基于词性标记、命名实体识别结果,并辅助以距离约束设计抽取模型分析句子中不同分词之间的潜在联系,对目标关键字进行抽取,获取词级别和句子级别结果。同时,为满足不同关键字搜索需求,借助基于双向关键字复合搜索算法、文本分类算法,识别特定目标关键字的句子级别结果。随后,基于文本分类对页面标题进行页面类型检测,对页面内抽取结果进行约束过滤,并对部分缺失字段结果使用页面级别结果进行填充。最后,进行抽取结果去重、清洗。
3.4 用户界面设计
3.4.1 项目管理页面设计
图4为项目管理列表页,表单中包括项目名称、创建人、创建时间及加入对比/详情/分享/删除操作。通过页面快速查找项目,并在页面中提供上传项目文件入口,支持对项目的导出、分享及对比,为查看项目详情提供入口。
3.4.2 项目关键字段管理页面
通过导航【关键字段管理】菜单,可以进入关键字段管理页面,如图5所示,可通过输入关键字段名称中的关键字对关键字段进行检索,并可通过选择关键字段类别进行过滤。
3.4.3 项目详情页面
图6为项目详情页,包括项目文件解析后的文本及抽取后的内容,可对项目进行详细操作,包括项目抽取后结果导出word版本文件、项目对比操作等,具体如图7和图8所示。
3.4.4 日志管理页面
图9为日志管理系统页面,统计报表为每日上传或解析项目文件数量的统计,包括账号、操作类型、操作对象、操作时间、操作状态。
4 结 论
本文根据项目策划书的文本特点,对信息抽取系统设计需求进行了简要分析,以基础设置、数据层、应用层和用户层四层逻辑构架为基础,设计了以业务逻辑后台、文件解析模块、项目关键信息抽取服务三大功能模块的科创项目信息抽取系统。该系统有效解决了传统依靠外部行业专家或通过密集的人力、且效率低且效果不可靠的做法。通过对项目文档中关键词信息抓取、整理、关联挖掘出有效信息,并以可视化的方式直观展示,大幅提高科技成果和企业需求匹配效率。
参考文献:
[1] 丁玉飞,王曰芬,刘卫江.面向半结构化文本的知识抽取研究 [J].情报理论与实践,2015,38(3):101-106.
[2] 丁君军,郑彦宁,化柏林.基于规则的学术概念属性抽取 [J].情报理论与实践,2011,34(12):10-14+33.
[3] 刘一宁,郑彦宁,化柏林.学术定义抽取系统实现及实验分析 [J].情报理论与实践,2011,34(12):15-19.
[4] SHAH U,FININ T,JOSHI A,et al. Information Retrieval on the Semantic web [C]//Proceedings of the Eleventh International Conference on Information and Knowledge Management,2002:461-468.https://dl.acm.org/doi/10.1145/584792.584868.
[5] TANG J,ZHANG J,YAO L M,et al. Arne Miner: Extraction and Mining of Academic Social Networks [C]//Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(SIGKDD),2008:990-998.https://dl.acm.org/doi/10.1145/1401890.1402008.
[6] POLLAK S,VAVPETIC A,LAVRAC N,et al. NLP Workflow for On-line Definition Extraction from English and Slovene Text Corpora [EB/OL].[2023-08-06].http://www.oegai.at/konvens2012/proceedings/10_pollak12o/10_pollak12o.pdf.
[7] FERNEDA E,DOPRADO H A,BATISTA A H,et al. Extracting definitions from Brazilian legal texts [C]//International Conference on Computational Science and Its Applications,2012(4):631-646.
[8] 王雪芬,王曰芬.专家库中的专家检索技术研究 [J].情报理论与实践,2011,34(2):96-99.
[9] CALIFF M E. Relational Learning Techniques for Natural Language Information Extraction [C]//Relational learning techniques for natural language information extraction.ACM Digital Library:The University of Texas at Austin,1997:1-200.
[10] CIRAVEGNA F,LAVELLI A. Learning Pinocchio: Adaptive Information Extraction for Real world Applications [J].Natural Language Engineering,2004,10(2):145-165.
[11] 黎伟健,胡斌,李威,等.大数据视角下的非结构化文本挖掘分析方法 [J].新媒体研究,2021,7(8):8-10+52.
[12] 周法国,王映龙,杨炳儒,等.非结构化信息抽取关键技术研究探讨 [J].计算机工程与应用,2009,45(14)1-6+21.
[13] 张博.基于领域知识库的简历信息抽取系统的设计与实现 [D].北京:北京邮电大学,2018.
作者简介:柏斌(1990—),男,汉族,湖南永州人,项目总监,研究方向:信息系统软件开发与应用。
