
基于机器学习的碳基材料对水中四环素吸附预测研究
2024-06-13 04:00:21董晓冬陈丽红林芙李惠平黄慧
环境科学与管理 2024年2期
关键词:机器学习
董晓冬 陈丽红 林芙 李惠平 黄慧
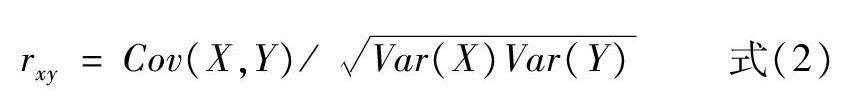
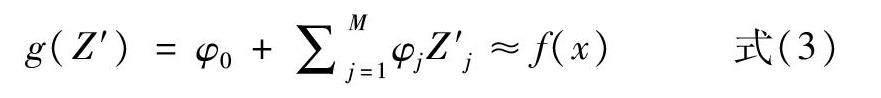
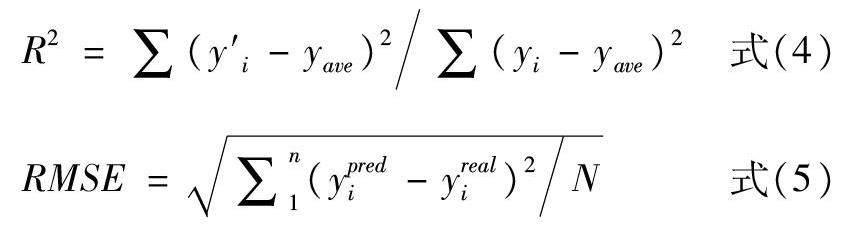
摘要:利用现有文献中的碳基材料对水中四环素的吸附量的数据,以机器学习为方法准确地预测了不同碳基材料在不同环境条件下对水中四环素的吸附量。其中梯度提升树(CBDT)对四环素的吸附量预测效果最好(R2>0.99)。比表面积和孔容积是决定碳基材料对四环素吸附量的最主要的特征。除pH与pHpzc对吸附量的贡献为负外,其余变量对吸附量均为正贡献,即特征重要性越明显时,对吸附量的提升越有利。整体而言,四环素在碳基材料上的吸附是一个物理过程,受吸附剂的物理特性和环境因素影响较大,而受碳基材料的化学特性的影响较小。
关键词:四环素吸附;机器学习;碳基材料;模型解释
中图分类号:X703 文献标志码:B
前言
长期暴露在一定浓度的四环素的刺激下会对人体的肾脏、眼球、胃肠道等器官造成伤害。由于四环素的滥用,天然水体中已有较高浓度的四环素检出,因此亟需去除水体中的四环素。利用碳基吸附剂可以高效地吸附水中四环素。各类碳基吸附剂被大量开发并应用于吸附水体中的四环素和其他污染物。然而评价碳基吸附剂对水体中四环素的去除效果则需要大量的实验投入才能获得较为准确的性能概览。因此,如何能高效快速地预测碳基吸附剂对水中四环素的吸附效果对于节省冗长枯燥的实验工作量有着至关重要的意义。
机器学习在以数据为基础的问题领域有着广泛的应用前景。并且机器学习目前在环境领域中的应用也有所开展。但以机器学习来预测吸附剂对水中污染物的去除目前仍处在初级阶段。因此,以机器学习来预测水中四环素在碳基吸附剂上的吸附可以有助于更好地理解影响吸附的关键变量,并为设计高效吸附剂提供合理指导或者思路。
研究中以现有文献数据为基础,通过整理现有数据作为机器学习的数据集进行模型训练。并对训练结果以及模型的可解释性进行了分析,讨论了决定四环素在碳基材料上的吸附效果的影响因素。
1 数据与方法
1.1 数据收集
研究所需文献来自Web of Science数据库,共计获得有效数据686条。数据集以四环素的吸附量(mmol/g)为因变量,并以10个物理化学特征和环境因素为自变量。其中物理特征包括比表面积(Surface area,m2/g)、孔容积(Volume,cm3/g)和孔径(Pore diameter,nm)。化学特征包括零电荷点(pHpzc)、C的质量百分比(C,wt%)和0的质量百分比(0,wt%)。环境因素包括投加量(Dosage,g/L)、初始浓度(C0,mmol/L)、溶液pH(pH)和溶液温度(T,K)。
1.2 数据预处理与模型选择
由于不同自变量之问的差异较大,如比表面积的范围为1-2000m2/g,而孔容积的范围为0.001-2cm3/g,为减小不同量纲对预测带来的影响以及节省算力,对原始数据进行标准化,即使得原始数据符合均值为0方差为1的分布,如式(1)所示:
xnew=(x-μ)/σ 式(1)
式(1)中,xnew和x分别为标准化后的数据和原始数据。μ为数据样本的均值,σ为数据样本的标准差。
对于标准化后的数据首先进行特征间的两两相瓦皮尔逊相关性分析(见式2),当皮尔逊相关系数的绝对值趋近于1时,表明两个特征之间的线性相关越强。研究中,若绝对值大于0.95,则这两个特征高度线性相关,应予以额外处理,包括数据降维或者删除一个特征。
式(2)中,rxy是皮尔逊相关系数,Cov(X,Y)为两个特征之间的协方差矩阵,Var(X)和Var(Y)是X和Y的方差。
对于数据集进一步划分为训练集和测试集,其中样本数量占比为4:1。训练集用于模型训练,测试集则用于验证模型泛化能力。研究中,共选择了K近邻算法(KNN)、支持向量机(SVM)和梯度提升树(CBDT)三种算法来预测。对于算法中的超参的选择则利用网格搜索模式寻找最佳超参。
1.3 模型可解释性
利用Shapley方法可求得每个具体特征在所有特征组合的集合中的边际贡献的加权平均值,作为该特征对于整体模型的贡献程度的解读,该方法有效地避免了分配的平均主义。Shapley值的计算如式(3)所示:
其中,g(Z')是解释模型,f(x)是原机器学习模型,Z'j={0,1}M表示相应特征是否被观察到,M是输入特征的数目,φj是每个特征的归因值,φ0是解释模型的常数。
此外,利用个体条件期望图(Individual Condi-tional Expectation Plot,ICE)对每一个个体是如何受到单一特征影响做出解释。而ICE的平均值则为部分依赖图(Partial Dependence Plot,PDP)可以从全局的角度解读单一变量对输出结果的影响。
1.4 模型运行与评价
研究中所有数据预处理和模型构建均在Py-thon3.10上运行,并调用Scikit-Leam、Numpy、Pan-das、Shap、Matplotlib和Seahom包对数据进行运算以及图像呈现。决定系数(R2)和均方根误差(RMSE)作为评价模型预测效果的指标。R2越接近于1表明模型预测效果越好,RMSE的值越小表明模型预测效果越好。
其中,y'i是预测值,yi为对应真值,yave为样本平均值。ypredi是预测值,yreali为对应真值,N为样本数量。
2 结果与讨论
2.1 数据分布
碳基材料的孔隙结构较为符合正态分布,比表面积主要集中在100-500m2/g,孔容积主要集中在0.01-0.5cm3/g,而孔径主要集中在5nm左右。环境变量中,初始浓度和pH较为符合正态分布,而温度与投加量则出现不规则分布。化学因素中,pHpzc类似两个正态分布的叠加,中心值分别在3和7。这主要与碳基材料的制备方式有关,目前的在制备碳基材料时为了使得表面多孔,通常会使用强酸强碱来对碳基材料进行活化,因此pHpzc会由于活化药品的不同表面呈现出偏酸性或偏碱性的特点,造成零电荷点在3和7这两个值附近集中。C和O的分布则表现为不规则的数据分布,说明碳基材料表面官能团的种类与占比变化大,表面化学性状丰富。(见图1)
皮尔逊相关系数矩阵热图(如图2所示),所有特征之间均没有表现出会影响结果的强相关性,即绝对数值均小于0.95。因此不需要对特征进行删减或者对特征进行降维处理。仅比表面积和孔容积之间的相关系数较大,为0.86,但是仍在可控范围之内。由图2(b)可知,孔容积与比表面积呈现出一定的n线性正相关,即比表面积越大,孔容积越大。
2.2 模型预测效果和模型可解释性
KNN、SVM和GBDT算法不论是在训练集还是在测试集对于四环素的吸附量均能达到很好的预测效果(如表1所示),说明模型的准确度与泛化性都能够得到有效的保证。KNN模型是一种精准度高,对异常值不敏感的算法,非常适用于数值型和标称型的回归。SVM则擅长于解决高维特征的分类问题和回归问题,在特征维度大于样本数时依然有很好的效果。GBDT算法则是一种强力的集成算法,虽然以弱学习器为基础学习器,但是通过梯度提升对每次迭代的残差进行消除,使得最终的学习器成为强学习器。再结合决策树的优势,使得GBDT能够在多数分类和同归预测中表现出极佳的准确度。可知GBDT模型的预测精度为最高,因此后续分析所用的模型以GBDT模型为基准。如图3所示直观地展现了实际值与测试值之间的关系,从中可以看出二者高度线性相关。此外,训练集与测试集的分布也表现出相似的分布特点,因此,数据集划分合理,模型验证效果有效。
通过对比模型中各个特征Shapley值对预测结果的贡献程度可以发现,比表面积是最主要的特征,且呈现出明显的正贡献,即比表面积越大,四环素的吸附量也会越高。孔容积是另一个重要的特征,总体而言也是较为明显的正贡献,但是有部分样品表现出负贡献。初始浓度的重要性排在第三位,也表现出正贡献。pH的贡献度位于第四位,但是其对吸附量的贡献表现出负贡献,即pH越大,吸附量越小。温度则位于第五位,也是正贡献为主。其余因素对于四环素的吸附贡献相对较小。与部分研究结果有所不同的是,Shapley的结果表明碳基材料的化学特征对于四环素的吸附贡献程度非常有限,如图4所示,pHpzc为第7位,C含量为第9位,0含量为第10位。这说明四环素在碳基材料上的吸附并非是一个化学作用力主导的过程。同时也解释了大多数碳基材料对四环素的吸附都会包含大量的物理吸附的特性。
ICE和PDP图可以看出四环素吸附量对于大部分的因素依赖并未展现出单一的依赖性,说明四环素的吸附是多个特征综合作用的过程。这其中,比表面积在小于100m2/g时,对四环素的吸附量促进作用较大,但超过100m2/g时,吸附量提高的边际效益大幅减弱。因此在设计碳基吸附剂时,比表面积设置在100m2/g时即可,无需过多追求更大的比表面积。此外,四环素吸附量对初始浓度的变化表现出高度依赖,尤其是在初始浓度未0.5-0.75mmol/L之间时,依赖程度极其明显。
整体而言,碳基吸附剂的物理特性以及环境变量对四环素的吸附具有更大的影响,而化学因素对于四环素的吸附的影响则较弱,这也是为什么绝大多数报导的碳基吸附剂对于四环素的吸附偏向于物理吸附为主的原因。而所有特征中比表面积和孔容积为最重要的贡献特征,这说明孔隙填充是碳基材料吸附四环素的主要机制。为了探究化学因素是否对预测起到的作用较小,对于输入的10个特征剔除pHpzc、C含量和O含量,并再次进行模型训练。由表1可知在没有任何化学特征输入的情况下,虽然KNN、SVM和GBDT模型对四环素吸附的预测精确度有所下降,但是下降十分有限。因此仅碳基材料的物理特性和环境因素的输入就可以十分精确的预测四环素的吸附量。同时也再次证明四环素在碳基材料上的吸附是一个纯粹的物理吸附行为,碳基材料表面化学官能团以及等电点的分布对于四环素的吸附极其有限。此外,无需化学特征的采集即可获得非常精确的预测效果对于缩减数据采集时间具有重要意义,这一点在需要紧急预测的状况下极为重要。(见图5)
3 结论
研究通过对现有数据进行采集与整理,建立了碳基材料对水中四环素的吸附量的精准预测。在KNN、SVM、GBDT算法中,GBDT算法无论是在训练集还是在测试集都表现极佳,R2都大于0.98,RMSE都小于0.1。通过对Shapley值分析发现,特征重要性按照如下顺序排列:比表面积>孔容积>初始浓度>pH>温度>投加量>pHpzc>C含量>孔径>0含量。且pH和pHpzc对四环素吸附量表现出负贡献,其余特征表现为正贡献。整体而言,四环素在碳基吸附剂上的吸附主要受到物理特性和环境因素的影响较大,是一个物理吸附占据主导地位的过程。在紧急状况下,仅输入碳基材料的物理特征和环境因素即可实现精确的四环素吸附的预测,无需化学特征的输入,有效缩短了数据采集时间。
基金项目:国家重点研发项目(No.202IYFC3200805):甘肃省科技计划项目自然科学资助(20JR10RA441);甘肃省科技厅软科学专项(20CX9ZA026)
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科学与财富(2016年28期)2016-10-14 21:19:17
电脑知识与技术(2016年20期)2016-08-19 18:49:49
电脑知识与技术(2016年12期)2016-06-14 00:45:31
科教导刊·电子版(2016年10期)2016-06-02 19:17:03
科教导刊·电子版(2016年10期)2016-06-02 18:04:11
