
基于数据挖掘算法的高校英语专业教学质量评估系统设计
2024-06-03 01:34韦珊杉宋瑞雪
无线互联科技 2024年8期
韦珊杉,单 珂,宋瑞雪
(吉林建筑科技学院,吉林 长春 130000)
0 引言
近年来,伴随着信息技术的飞速发展,大数据和人工智能技术在教育领域的应用成为教育改革和发展的新趋势。政府相继出台政策,推动教育信息化,鼓励运用先进的信息技术改善教学质量和提升管理效率。在此背景下,数据挖掘技术因其深刻的数据分析能力而成为改善教育质量的重要工具。特别是在高校英语专业教学中,通过数据挖掘技术分析学生学习行为、评价教学方法的有效性,对教学内容和策略进行优化,已成为提高教学质量的关键途径[1]。
本研究旨在设计一套基于SLIQ数据挖掘算法的高校英语专业教学质量评估系统,以实现对教学过程和结果的科学评价,进而指导教学改革,改善教学质量。本研究不仅回应了信息技术在教育领域应用的国策导向,还符合教育信息化发展的实际需求,具有重要的理论意义和应用价值。
1 数据挖掘系统结构
在基于数据挖掘的高校英语专业教学质量评估系统中,所设计的数据挖掘系统的结构框架如图1所示。该结构采用分层架构方法,由表示层、处理层和挖掘层组成。表示层负责提供用户交互界面和存储用户信息;处理层处理用户请求并调用相应的数据挖掘模块执行;挖掘层则是系统的核心,包含多组数据挖掘组件,每个组件实现一种数据挖掘算法[2]。所设计的数据挖掘系统结构框架能够提高系统的处理效率和数据挖掘的准确性,为高校英语专业教学质量评估提供科学、有效的技术支持。
2 SLIQ数据挖掘算法
2.1 SLIQ数据挖掘算法概述
SLIQ(Supervised Learning in Quest)数据挖掘算法是一种适用于大规模数据集的决策树构建算法。该算法通过引入预排序技术和分层数据存储结构,显著地提升了数据处理的效率和可扩展性。不同于传统算法在每个节点进行排序,SLIQ仅在预处理阶段对数据进行一次排序,降低了计算的复杂度。此外,该算法采用分裂点选择和剪枝机制,优化了决策树的生成过程,提高了分类的准确性[3]。在教育数据应用分析中,尤其是在高校英语专业教学质量评估中,SLIQ算法能够高效地处理和分析数据,为教学决策提供科学依据。
2.2 SLIQ算法流程
SLIQ算法首先引入属性列表(Attribute list)和类直方图(Class Histogram)2种数据结构,以便于快速、准确地找到各属性的最佳分裂点。SLIQ算法流程如图2所示。首先,所有记录按属性值预排序,以消除在决策树每个节点上进行排序的需要。其次,SLIQ算法采用广度优先搜索策略,对决策树中的所有叶节点进行同时分割,确保每次分裂均基于当前最优的分裂标准进行分割。在决策树的构建过程中,类直方图用于存储每个节点的类分布情况,以此来计算最佳分裂点。同时,该算法采用最小描述长度(Minimum Description Length,MDL)剪枝方法,避免了过拟合,确保了模型的泛化能力。针对高校英语专业教学质量评估的特点,该流程提高了大规模教学数据处理的高效性和准确性。
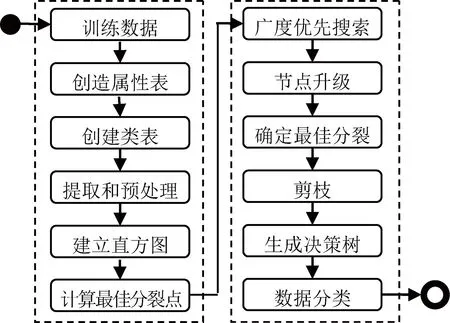
图2 SLIQ算法流程
2.3 计算最佳分裂点
SLIQ算法通过评估信息增益(Information Gain)或基尼指数(Gini Index)来确定最佳分裂点,从而在构建决策树时优化节点的分裂。具体而言,信息增益是根据属性分裂前后数据集不确定性的减少量来计算的。对于给定数据集D,其不确定性可用熵H(D)来表示,其计算公式为:
(1)
其中,m是类别数量,pi是第i个类别在数据集D中的相对频率。
在选择分裂属性和分裂点时,算法会计算每个可能的分裂所带来的信息增益,选择信息增益最大的分裂点作为最佳分裂点。信息增益IG(D,A)的计算公式为:
(2)
其中,A是候选分裂属性,Values(A)是属性A的所有可能值,Dv是属性A的值为v时的子集,|D|是数据集D的大小,|Dv|是数据集Dv的大小。
基尼指数是另一种评估分裂质量的方法,用于衡量数据集的纯度。节点的基尼指数越小,数据集的纯度越高。基尼指数Gini(D)的计算公式为:
(3)
对于每个属性,SLIQ算法都会计算分裂后子集的加权基尼指数,选择使加权基尼指数最小化的分裂点作为最佳分裂点。
在高校英语专业教学质量评估系统中,这一过程允许系统准确地识别出影响教学质量的关键因素,通过分析学生的学习数据,如成绩、参与度、反馈等,所提评估系统能够给出提升教学质量的有效路径。
2.4 DML剪枝算法
本文设计算法采用决策树剪枝技术,通过最小化决策树的复杂度来提高其泛化能力,从而避免过拟合现象。DML剪枝算法基于一种信息论的原理,即在给定数据集上,最佳模型是能够以最短描述长度(即最小的信息量)来描述数据的模型。DML剪枝过程可以表示为式(4)所示的优化问题,其优化目标是使成本最小。
(4)
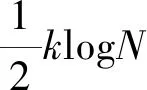
在高校英语专业教学质量评估系统中,DML剪枝算法的应用确保了决策树模型在保持足够大拟合度的同时,不会因模型过于复杂而失去对未知数据的预测能力。通过对决策树进行剪枝,系统能够剔除那些对教学质量评估贡献不大的属性,从而简化评估模型,提高评估的效率和准确性。这一过程对于识别和强化影响高校英语教学质量的关键因素至关重要,有助于教育管理者和教师基于数据驱动的洞察制定更加科学和有效的教学改进策略[4]。
3 教学质量评估系统功能设计
教学质量评估系统的功能设计核心在于对高校英语专业教学活动进行全面、细致的分析与评估,从而为教育决策提供数据支持。教学质量评估系统的设计旨在整合数据挖掘技术,特别是利用SLIQ算法高效、准确地处理和分析大量教学数据。下面介绍教学质量评估系统的主要功能模块。
3.1 数据收集与预处理
数据收集模块负责收集教学过程中产生的各类数据,包括但不限于学生的基本信息、成绩记录、课堂参与情况、作业提交情况及教师的教学反馈等。预处理环节将对收集的数据进行清洗、转换,以满足后续数据挖掘过程的需求。
3.2 特征选择与数据挖掘
基于SLIQ算法,特征选择模块对预处理后的数据进行特征选择,筛选出对教学质量评估最具影响力的特征。随后,通过SLIQ算法对选定特征进行数据挖掘,以识别影响教学质量的关键因素[5]。
3.3 教学质量评估模型构建
该模块利用数据挖掘结果,构建教学质量评估模型。该模型能够对教学质量进行量化评估,识别提升教学质量的潜在途径。
3.4 评估结果可视化展示
该模块设计一个直观的用户界面,通过图表、报表等形式展示教学质量评估的结果,包括教学质量的综合评分、关键影响因素的分析结果等,便于教育管理者和教师快速理解和应用评估结果。
3.5 教学改进建议生成
基于教学质量评估模型的输出,系统将提供针对性的教学改进建议,包括课程内容的调整、教学方法的创新、学生学习支持的加强等。
3.6 反馈与迭代优化
系统设计包含反馈机制,允许用户(教育管理者、教师、学生)对评估结果和改进建议提供反馈。系统将根据反馈内容进行迭代优化,以不断提高教学质量评估的准确性和实用性。
4 系统测试
4.1 测试环境
测试环境包括硬件和软件2个方面,硬件环境配置为Intel Core i7处理器、16 GB RAM、512 GB SSD存储,以保证数据处理和分析的高效性。软件环境包括Windows 10操作系统、MySQL 8.0数据库管理系统、Python 3.8数据处理和分析软件以及NumPy、Pandas科学计算库和Scikit-learn数据挖掘工具。此外,测试环境还设定了网络条件,模拟不同的网络带宽和延迟,以评估系统在不同网络状态下的表现。
4.2 参数设置
在高校英语专业教学质量评估系统的测试过程中,本研究对关键参数进行了细致的设定,以确保测试结果的有效性和可靠性。首先,SLIQ算法将最小分裂节点样本数设置为10,以避免过度拟合;最大树深度设置为5,以控制模型复杂度并保证计算效率。在数据预处理阶段,文本数据的向量化处理采用TF-IDF方法,n-gram范围设置为[1,3],旨在捕捉文本数据中的局部上下文信息。对于分类阈值的设置,SLIQ算法采用基于交叉验证的方法自动调整,以达到最优的分类性能。此外,系统性能测试参数包括响应时间、系统吞吐量(每秒查询数)和用户并发数(模拟100、200、500个用户并发访问系统)。通过对上述参数进行精确设置,本研究旨在全面评估教学质量评估系统在处理大规模教育数据时的性能表现,确保系统在实际部署中的高效性和准确性。
4.3 结果与分析
测试结果显示,系统在处理大规模教学数据集时展现了良好的性能和高准确度。关键测试结果如表1所示。

表1 测试结果
由表可知:随着用户并发数的增加,系统响应时间略有增长,但整体仍保持在合理范围内,说明系统具备良好的并发处理能力;系统吞吐量随用户并发数的增加略有下降,但下降幅度有限,表明系统能够有效处理高并发请求;教学质量评估准确率达到92%,说明SLIQ算法能够有效识别影响教学质量的关键因素,为提升教学质量提供了强有力的数据支持;决策树的平均深度为4.3,低于设定的最大深度,这表明DML剪枝算法有效地减少了模型过拟合,保证了模型的泛化能力。
5 结语
在本研究的探索和实践过程中,基于数据挖掘算法的高校英语专业教学质量评估系统设计不仅展示了数据科学在教育领域应用的巨大潜力,也为教育质量的评估与提升开辟了新的路径。通过精准分析教学数据,本文揭示了影响教学质量的关键因素,为教育管理者、教师提供了科学、实时的决策支持,从而推动教学方法的创新和教育质量的持续提升。此外,本研究也为数据挖掘技术在其他教育领域的应用提供了参考和借鉴,展现了信息技术与教育深度融合的广阔前景。未来,随着数据挖掘和人工智能技术的不断进步,该系统在教育评估与改进中的作用将更加凸显,为实现个性化教学、优化教育资源配置、提高教育质量提供更加强大的技术支撑。
猜你喜欢
保健医苑(2022年5期)2022-06-10
成都信息工程大学学报(2021年6期)2021-02-12
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
天津诗人(2017年2期)2017-03-16
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
疯狂英语(双语世界)(2016年4期)2016-06-05
疯狂英语(双语世界)(2016年2期)2016-02-27
郑州大学学报(医学版)(2015年1期)2015-02-27
计算机工程(2014年6期)2014-02-28
