
基于图像识别的建筑裂缝自动识别技术研究
2024-06-03 03:28:24李秀丽裴瑶瑶
信息系统工程 2024年5期
李秀丽?裴瑶瑶


摘要:针对建筑裂缝识别精度差和泛化性弱的问题,提出一种基于图像识别的建筑裂缝自动识别技术。该技术融合了注意力机制和U-Net架构,即AU-Net,能够有效学习不同尺度特征间的相互关系,从而显著提升裂缝识别的精度和泛化性。在三个建筑裂缝识别的数据集上进行测试,结果表明,相较于全卷积网络和标准的U-Net模型,AU-Net的平均F1分数提升9.4%,平均交并比提升7.2%。因此,本研究有助于及时预防建筑的结构性故障,提升建筑安全性。
关键词:建筑裂缝;自动识别;安全性
一、前言
随着城市化进程的推进,建筑物的安全性与耐久性成为重点问题之一。在建筑物的生命周期中,裂缝的出现往往预示着潜在的结构问题,及时检测建筑物对于预防灾害、保障人民生命财产安全具有至关重要的作用[1]。然而,传统的裂缝检测方法大多依赖于人工视觉检查,不仅效率低下,而且容易受到检测人员主观经验的影响,导致检测结果的精度较差。此外,人工检测通常伴随着高昂的劳动力成本和时间成本,在高空或危险环境中工作更增加了检测人员的安全风险。基于图像识别的建筑裂缝自动识别技术,以其高效、准确的特点,被视为提升建筑裂缝检测水平的有力工具。本研究以混凝土材质的居民建筑和道路为研究对象,提出了一种基于深度学习的建筑裂缝自动识别技术。该技术构建了一种融合注意力机制和U-Net架构的神经网络模型,即AU-Net,不仅能够捕捉图像的细微特征,还能处理分析不同尺寸和形态的裂缝。实验表明,AU-Net与现有的全卷积网络和U-Net模型相比,识别精度均有显著提升。因此,本研究可以有效提高裂缝检测的自动化水平,对于维护建筑的健康状态有重要意义。
二、裂缝识别技术的研究现状
(一)基于特征提取的方法
基于特征提取的方法应用传统的数字图像处理技术,对裂缝图像进行预处理和特征提取,通过分析处理后的结果以确定裂缝的位置和属性。传统的数字图像处理检测技术主要依赖于图像分割,包括基于阈值的方法、边缘检测算子(如Sobel,Canny等)、基于图论的分割方法,以及基于能量泛函的分割方法。例如,快速哈尔变换被验证了在裂缝识别的精确性上有着出色的表现。此外,数学形态学的方法也被用于图像增强,与阈值分割相结合,进一步提升对裂缝的识别能力[2]。
(二)基于深度学习的方法
与传统方法相比,基于深度学习的方法利用其深层神经网络结构自动提取图像中的复杂特征。这些深度特征提取器能够识别图像中难以直接捕捉的裂缝边缘、宽度、位置和亮度等细节[3]。计算机视觉领域的进步推动了基于深度神经网络的图像处理方案在实际应用中的发展。例如,深度学习算法被用于隧道衬砌裂缝的自动识别,多尺度深度卷积特征融合用于提升裂缝特征的提取效率,有监督的学习方法调整样本比例以处理数据不平衡问题。此外,通过在U-Net模型中加入残差连接,可以增强特征提取的能力,实验证明这种方法的准确率超过了传统的U-Net模型和其他深度学习模型[4]。
三、基于图像识别的建筑裂缝自动识别技术
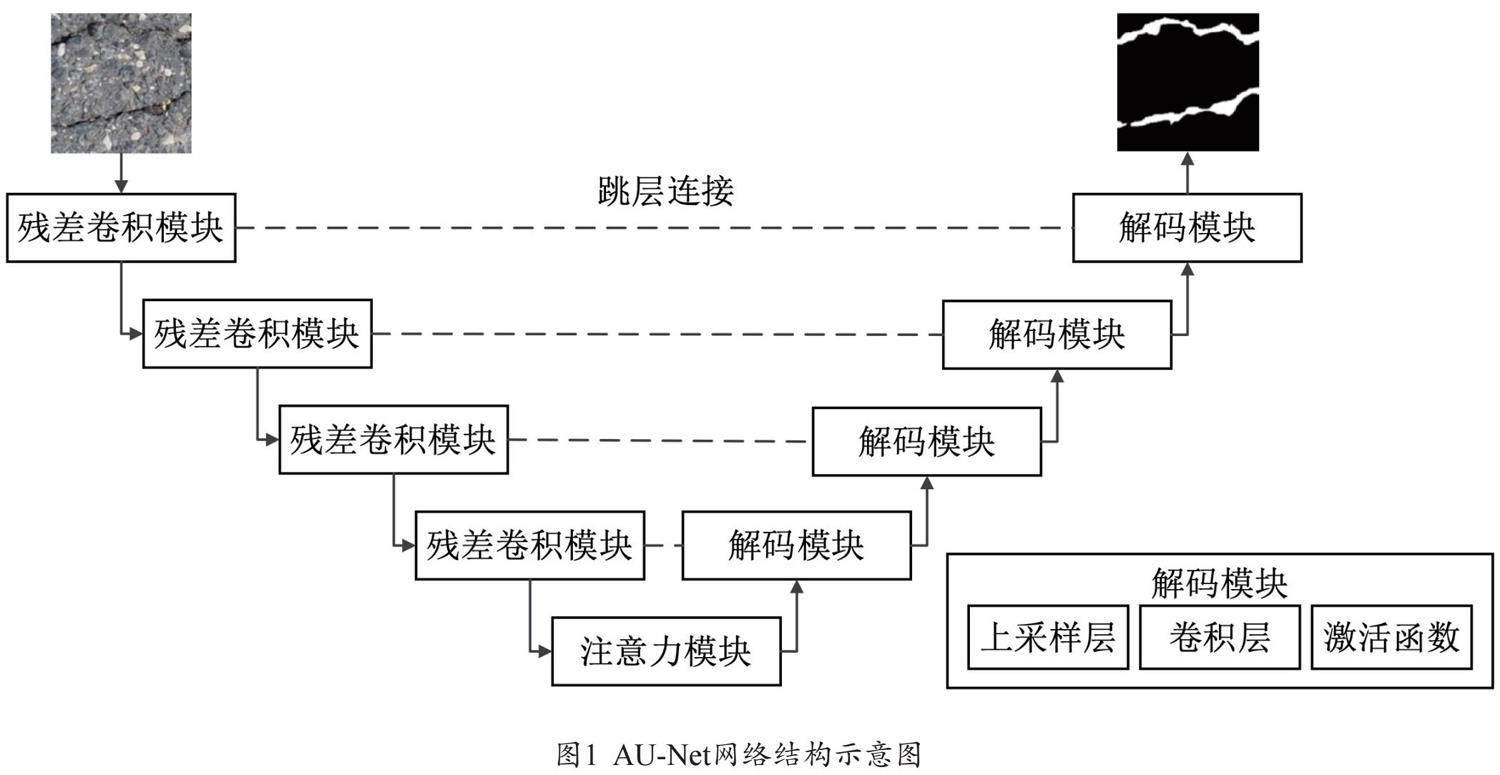
(一)AU-Net网络架构
在本研究中,提出了一种基于图像识别的建筑裂缝自动识别技术。该技术采用了融合注意力机制的改进U-Net网络架构,即 AU-Net。如图1所示,AU-Net的核心是编码器—解码器结构。编码器部分融合了残差卷积层和基于注意力机制的Transformer层,这种结合充分利用了卷积操作在提取丰富的细节和语义信息方面的能力。同时,通过Transformer层引入的全局自注意力机制,捕获特征间长距离的依赖关系,以实现全局特征信息的整合,为识别过程提供了更全面的上下文支持。
解码器部分通过级联的上采样操作将抽象的高级特征映射回原始的分辨率。这一过程包括四个阶段,每个阶段都包含一个2倍上采样操作、一个3×3卷积层以及一个ReLU激活层。此外,解码器在每个上采样步骤中都引入了长跳跃连接,将编码器各层提取的高分辨率特征图与相应上采样层的特征图进行精确融合。这种设计使得解码路径能够更加精细地恢复浅层细节特征,提高了裂缝识别的精确度。
(二)残差卷积模块
在本研究中,对U-Net模型的编码器部分进行了改进,即采用由兩个残差单元组成的残差卷积模块来替代每一步的下采样操作。第一个残差单元的设计旨在通过两次不同配置的卷积操作来增强特征的提取能力。首先使用步长为2的3×3卷积核实现下采样,并捕获更抽象的特征。随后采用步长为1的3×3卷积核,以保持特征图的细节信息。在建筑裂缝识别的应用中,这种设计有助于更有效地提取裂缝特征,并在下采样过程中减少细节的丢失,这对于复杂、细微的裂缝尤为重要。该过程可以表示为:
F=σ(conv3×3?(conv3×3?(X) )+conv1×1?(X) ) (1)
X为第一个残差单元的输入,conv3×3为3×3卷积核,conv1×1为1×1卷积核,σ为激活函数。第二个残差单元的目的是在不改变特征图分辨率和通道数的前提下进行特征融合。因此,采用两个步长均为1的3×3卷积核来维持特征图的空间分辨率,同时防止模型的过拟合,提高泛化能力。该过程可以表示为:
(F=σ(conv3×3(conv3×3(X) )+X) (2)
X为第二个残差单元的输入,conv3×3为3×3卷积核,σ为激活函数。
(三)注意力模块
为了在建筑裂缝识别中取得更好的效果,在编码器设计的最后引入了基于Transformer的注意力模块,以弥补传统卷积编码方式在提取空间细节时可能丢失上下文信息的问题。自注意力机制有助于捕捉图像中的长距离依赖,从而提高对建筑裂缝特征的识别能力,并减少分割图中裂缝的断裂或冗余情况。设输入的特征图X∈RH×W×C,注意力特征提取的过程如下:
第一,进行图像序列化。将输入设置为二维的小块,设每个块尺寸为P×P,得到序列化的块向量xp∈RN×(P2?C),N=H×W/P2为块的数量。
第二,执行嵌入操作。通过可训练的线性映射将图像块序列映射到潜在空间,该过程表示为:
z0=[xp1E;xp2E;…;xpNE] (3)
E∈R(P2?C)×D代表线性映射矩阵,xpi代表第i个块向量。
第三,添加位置信息,引入可学习的位置编码,该过程表示为:
z0=z0+Epos (4)
Epos∈RN×D代表位置编码。
最后,基于注意力机制提取特征,这里采用标准的Transformer结构,每个Transformer层由两个标准化块、一个多头自注意力模块和一个多层感知机模块构成。第l个Transformer层的计算表达为:
zl'=MSA (LN(zl-1) )+zl-1 (5)
zl=MLP (LN(zl' ))+zl' (6)
LN表示标准化层,“MSA”表示多头子注意力模块,“MLP”表示多层感知机模块,zl-1表示第l个Transformer层的输入,zl表示第l个Transformer层的特征输出。这种结构的设计特别适用于建筑裂缝识别任务,有助于增强模型对裂缝的连续性和整体性的理解,进而提高分割效果的准确性和一致性。
(四)损失函数
在建筑裂缝识别的应用中,裂缝像素通常与背景像素的数量差异巨大。针对这种不平衡的正负样本分布,使用Dice损失函数。Dice损失的计算公式如下:
DiceLoss=1----2∑i=1N pigi+?
∑i=1N pi2+∑i=1N gi2+? (7)
pi代表预测值,gi代表真实值,N是像素点的总数,?是平滑因子,用以防止分母为0。对于Dice损失函数相对于某个像素点pj的梯度计算,公式表示为:
(8)
可以观察到,当pj或gj的值很小时,由于分母中包含平方项,计算结果将会变得非常小,造成梯度异常放大,意味着Dice损失对于裂缝这类小尺寸目标的分类错误异常敏感,使得模型即使对裂缝的少量像素点预测错误也会产生较大损失。利用这一特性,Dice损失能够促使模型更精确地预测细小裂缝。
四、实验及结果分析
(一)实验环境
为了验证所提出的AU-Net建筑裂缝自动识别技术的有效性,本研究在多个数据集上进行了一系列对比实验。实验所用的操作系统为Ubuntu 18.04,深度学习框架为PyTorch。此外,使用NVIDIA Geforce RTX 3080显卡对所有模型进行训练和测试。
(二)数据集
实验数据主要来源于混凝土的居民建筑和道路裂缝场景[5],包括:1.自行采集的居民建筑裂缝数据集,该数据集由600张224×224分辨率的裂缝图像组成。2.CrackForestDataset(CFD)数据集,包含118张分辨率约为480×320像素的城市混凝土道路裂缝图片。3.CrackLS315数据集,采用线阵相机技术采集的315张道路裂缝图片。本实验将每个数据集随机分为训练集、验证集和测试集三部分,比例为70%、15%和15%。确保训练和评估阶段广泛覆盖各种情况,保证模型性能评估的公平性。
(三)基线模型
为了准确评估AU-Net建筑裂缝自动识别技术的性能,选取了FCN8和标准的U-Net模型作为基线模型。FCN8模型是全卷积网络的一种变体,将图像中的每个像素分类。具体地,FCN8是一种通过将预训练的卷积神经网络进行改造,移除全连接层,利用反卷积对多尺度特征进行上采样和融合,从而实现对每个像素进行像素级别的语义分割;标准的U-Net模型是一种为医学图像分割设计的网络结构,具备优秀的特征提取和上下文信息融合能力。U-Net则采用了对称的编码器-解码器结构,编码器逐层提取不同尺度的特征表示,解码器逐层对特征进行上采样和重建,同时通过大量的跳级连接融合不同尺度的特征信息,使其在医学图像分割等任务中表现出色。
(四)评价指标
F1分数和平均交并比(mean Intersection over Union,mIoU)是本实验的两个主要评价指标,用于综合评估模型性能。F1分数是精确率和召回率的调和平均数,提供了一个单一指标来评价模型对正样本的识别能力。mIoU衡量预测区域与真实区域的重叠程度,是分类正确的像素与分类错误及未分类的像素之间的比例,能够直观反映出模型的分割效果。
(五)结果及分析
经测试,实验结果如表1所示。结果表明,在自采集居民建筑数据集上,AU-Net模型相比FCN8和U-Net分别在F1分数上提高了大约15.2%和6.5%,在mIoU上提高了大约11.1%和2.9%。对于CFD数据集,AU-Net分别比FCN8和U-Net在F1分数上提升了约6.2%和3.6%,在mIoU上提高了约5.9%和4.1%。在CrackLS315数据集上,AU-Net相较于FCN8和U-Net的F1分数分别提升了6.7%和3.3%,mIoU分别提升了4.7%和2.0%。总体而言,AU-Net在三个数据集上的平均F1分數提升为9.4%,平均mIoU提升为7.2%。因此,AU-Net能够更有效地融合多尺度特征并准确捕捉裂缝的细微结构,从而提高裂缝检测的精度和鲁棒性。
五、结语
本研究提出了一种融合记忆力机制与U-Net架构的深度学习模型以自动化识别建筑裂缝。该模型能够有效捕捉和分析不同尺寸、形态的裂缝细微特征,实验结果显示出显著的精度提升。本研究提升了建筑裂缝检测自动化水平、检测的准确性和操作的安全性,对于确保建筑物的耐久性和预防潜在灾害具有重要意义。未来工作将着力于模型的进一步优化,拓展其在实际应用中的泛化能力,为建筑物的长期安全监测提供强有力的技术支持。因此, AU-Net 的编码器融合残差卷积和Transformer自注意力层,能够更好地捕获局部细节和全局长范围依赖关系,有助于更准确地识别出曲折、断裂的裂缝结构;解码器采用级联上采样操作,能够逐步恢复高分辨率的特征图,使预测结果与原始图像分辨率一致,从而保留更多细节信息,从而提高裂缝检测的精度和鲁棒性。
参考文献
[1]陈红彬,李华北.土木结构物裂缝识别检测的自动化研究[J].中州建设,2011(18):68-69.
[2]张娟,沙爱民,高怀钢,等.基于数字图像处理的路面裂缝自动识别与评价系统[J].长安大学学报:自然科学版,2004,24(02):18-22.
[3]李良福,马卫飞,李丽,等.基于深度学习的桥梁裂缝检测算法研究[J].自动化学报,2019,45(09):1727-1742.
[4]惠冰,李远见.基于改进U型神经网络的路面裂缝检测方法[J].交通信息与安全,2023,41(01):105-114.
[5]苗翔宇,刘华军.基于金字塔特征和级联注意力的路面裂缝检测[J].计算机与数字工程,2023,51(03):629-634.
作者单位:河南测绘职业学院
责任编辑:张津平、尚丹
猜你喜欢
中国自动识别技术(2023年6期)2024-01-12 08:13:22
现代仪器与医疗(2022年2期)2022-08-11 09:51:40
建材发展导向(2021年14期)2021-08-23 00:57:04
建材发展导向(2021年23期)2021-03-08 01:05:44
中华养生保健(2020年5期)2020-11-16 01:44:32
水上消防(2019年3期)2019-08-20 05:46:08
特别健康(2018年3期)2018-07-04 00:40:18
信息安全与通信保密(2016年3期)2016-08-23 01:23:46
发明与创新(2016年26期)2016-08-22 03:23:28
电测与仪表(2016年6期)2016-04-11 12:06:38
