
基于改进Raft共识算法和PBFT共识算法的双层共识算法
2024-06-01 17:54:18袁昊天李飞
计算机应用研究 2024年5期
袁昊天 李飞

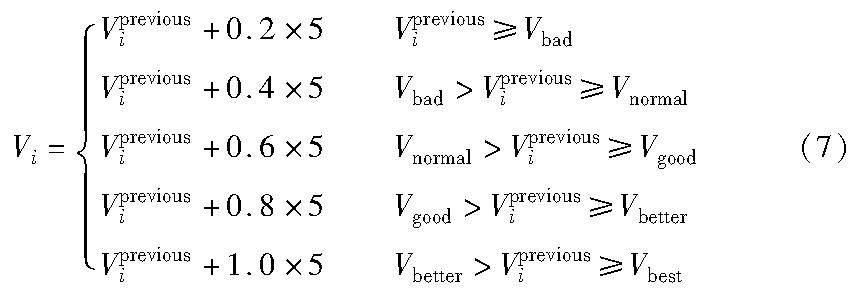

摘 要:针对目前应用于联盟链中的实用拜占庭(PBFT)共识算法可扩展性不足、通信开销增长过大、难以适用于大规模网络节点环境等问题,提出了一种基于改进Raft共识算法和PBFT共识算法的双层共识算法(DL_RBFT)。首先将区块链中的节点分成若干小组,组成下层共识网络,然后小组的组长再构成上层共识网络,形成一个双层共识网络结构;在下层共识网络的小组内部引入监督机制和声誉机制来改进Raft共识算法,在初始组长的选举流程引入了蚁群算法,使选举效率始终维持在较高水平;在上层共识网络中,使用PBFT共识算法进行共识。改进后的Raft共识算法具备了抗拜占庭节点攻击的能力,提升了算法的安全性。实验结果分析表明,相较于传统的PBFT共识算法,在100个节点的情况下,DL_RBFT将共识时延降低了两个数量级,吞吐量也提升了一个数量级,与其余改进算法相比也有着明显优势。因此DL_RBFT共识算法拥有良好的可扩展性,可以广泛应用于联盟链的各种场景中。
关键词:联盟链; 共识算法; Raft; PBFT; 区块链; 双层共识网络; 监督机制; 声誉机制
中图分类号:TP301 文献标志码:A 文章编号:1001-3695(2024)05-005-1314-07
doi:10.19734/j.issn.1001-3695.2023.08.0390
Double layer consensus algorithm based onimproved Raft consensus algorithm and PBFT
Abstract:This paper proposed a dual-layer consensus algorithm(DL_RBFT) based on the enhanced Raft and practical Byzantine fault tolerance(PBFT) consensus algorithms to address scalability issues, excessive communication overhead, and challenges in large-scale network node environments in use within consortium blockchains. Initially, it divided blockchain nodes into several groups to form a lower-layer consensus network. Then, leaders from these groups constituted an upper-layer consensus network, creating a dual-layer consensus structure. In the lower-layer consensus network, it improved Raft consensus algorithm by introducing supervision and reputation mechanisms, while the leader election process introduced ant colony optimization to maintain high efficiency. In the upper-layer consensus network, it utilized the PBFT consensus algorithm for consensus. The enhanced Raft consensus algorithm exhibited resistance to Byzantine node attacks, enhancing the algorithms security. Experimental results indicate that compared to traditional PBFT consensus algorithms, DL_RBFT reduces consensus latency by two orders of magnitude and improves throughput by one order of magnitude in a 100-node scenario. In comparison to other enhanced algorithms, DL_RBFT demonstrates significant advantages. Therefore, DL_RBFT consensus algorithm exhibits strong scalability and can be widely applied in various consortium blockchain scenarios.
Key words:consortium blockchains; consensus algorithm; Raft; PBFT; blockchain; dual-layer consensus network; supervision mechanism; reputation mechanism
0 引言
自2008年中本聰发布比特币白皮书[1],区块链[2]作为一种分布式、去中心化的技术,凭借其不可窜改、透明、安全性高等优势,受到各领域的关注。作为区块链核心技术之一的共识机制,其保证了节点集群的安全性、稳定性和一致性。随着区块链技术的快速发展,越来越多的人加入到区块链网络中,因而对区块链节点体量的要求越来越大,对共识机制的要求也越来越高,因此,共识机制的可扩展性、安全性和稳定性就成为了区块链领域的重点研究问题[3]。
现有的共识机制有工作量证明(proof of work,PoW)[4]、权益证明(proof of stake,PoS)[5]、权益证明+权益投票(delegated proof of stake,DPoS)[6] 、工作量证明+权益证明(proof of work with proof of stake,PoW/PoS)[7]、优先委托权益证明(preferential delegated proof of stake,PDPoS)[8]、Raft[9]、拜占庭容错共识(Byzantine fault tolerant consensus,BFT consensus)[10]、实用拜占庭容错共识(practical Byzantine fault tolerance,PBFT)[11]等。
根据节点准入类型的不同,可以将区块链划分为公有链(public blockchain)、联盟链(consortium blockchain)以及私有链(private blockchain)[12]三类。公有链是一种完全开放的区块链网络;在公有链中,任何人都可以参与该网络的节点,并且可以进行交易、添加新的区块以及参与共识机制。在联盟链中,参与的节点需要获得邀请或满足特定的准入条件才能加入网络;一般情况下,联盟链的节点由多个组织或实体共同管理;联盟链的共识机制可能不同于完全去中心化的公有链,联盟链通常更注重隐私性和可扩展性,因为参与者之间可能需要一定程度的信任;联盟链在特定行业或组织之间分享数据和交换价值的场景中被广泛使用。AntChain、Zhi Xin Chain、XuperChain、Ti Chain、星火链、长安链等,都是有名的联盟链。私有链是一种完全私有化的区块链网络,参与节点由单个实体或组织控制。私有链的访问权限通常受到严格限制,只有授权的节点才能参与网络的管理和交易活动。
联盟链相比于公链和私有链,更适合一些特定的企业和组织间合作的场景,因为其可以提供更高的隐私性、可控性和可扩展性。联盟链在物联网(IoT)[13]、供应链管理[14]、电子健康记录[15]、版权保护[16]、跨部门数据共享[17]、产品溯源[18]等领域有着广阔的应用前景。尽管联盟链在这些应用场景中表现出许多优势,但它们仍然面临一些挑战,比如扩展性差、安全性低、吞吐量小等问题。
目前在联盟链的许多应用中,使用最多的是PBFT共识算法,PBFT共识算法虽然不像PoW需要消耗大量的算力,但其时间复杂度为O(n2)[19],随着链上节点数的增加,PBFT的通信开销呈现平方级的增长,共识效率急剧降低,故只适用于节点数量在一定范围的场景。在供应链管理、物联网、跨部门数据共享、金融等领域,其对区块链的可扩展性和性能要求较高,节点的规模可能在数百上千,并且吞吐量要达到万级,PBFT共识算法难以适用于这些场景。作为区块链的核心技术之一,共识机制在很大程度上决定了区块链的吞吐量、可扩展性、安全性等,因此,改进现有的共识机制是切实解决这些问题的有效方法。
针对上述PBFT共识算法存在的问题,文献[20]引入了协调器技术对PBFT算法进行改进,首先将交易交给协调器进行分类,从中筛选出存在异常的交易,只对这部分交易执行完整的共识,使得共识延时缩短了79%;但是,该算法由于引入了协调器,会存在协调器单点故障导致整个系统失效的问题。文献[21]提出网络自聚类的分组方法,提升了PBFT扩展性不佳的問题,但是节点间频繁的通信导致通信复杂度增加,共识效率难以保证。文献[22]提出一种分组策略,利用K-medoids聚类算法对节点进行特征聚类和层次划分,使得单次共识耗时缩短了20%,通信次数最佳能够降低3个数量级;但是该算法的时间复杂度依然是O(n2),并且搭建公识网络的速度更慢,而且可能导致区块链网络所有节点的数据缺乏一致性。文献[23]在文献[22]的基础上,在分组策略中加入了仿生优化算法,提升了分组效率,又将组内共识改变为Raft共识机制,使得组内共识算法的时间复杂度优化为O(n),提升了共识效率;但仍然在一致性上存在问题,且文献[23]因为其通信流程设计,使得下层节点仅能知道上层节点的决定,不能作出干预,故下层节点的存在意义存疑。文献[24]提出一种基于一致性hash均匀分组的双层共识算法,解决了分组不均的问题,但是在分组时的多次hash增加了计算复杂度,降低了算法性能。
仅改进PBFT算法,不能解决其算法设计层面带来的时间复杂度高的问题,可扩展性差的问题也不能从根源上解决。Raft共识机制是一种强领导型的共识算法,时间复杂度仅为O(n),在节点规模庞大的情况下,也能使得共识效率处于较好的水平,但是Raft共识机制本身不存在抗拜占庭攻击的能力。因此,本文结合Raft共识机制的高效率特性和PBFT共识算法的抗拜占庭攻击的特性,构建一种基于Raft和PBFT算法的双层共识(DL_RBFT)算法,在保证可扩展性的同时,保证共识网络的抗拜占庭节点攻击能力。
本文的主要研究工作如下:a)针对联盟链实用拜占庭共识机制在大规模节点场景出现的时延爆炸问题,结合Raft共识算法提出了一种基于改进Raft共识算法和PBFT共识算法的双层共识算法(double layer consensus algorithm based on improved Raft consensus algorithm and PBFT,DL_RBFT);b)针对改进算法的安全性、一致性、活性进行讨论分析,论证了DL_RBFT算法的可行性;c)对DL_RBFT算法的共识延时、吞吐量和容错性进行仿真实验测试,验证其有效性和安全性;d)对下层改进的Raft算法中的选主策略进行仿真模拟,验证算法的有效性。
1 相关知识
1.1 PBFT算法
1999年,Castro等人[25]提出了实用拜占庭共识算法,改进了BFT算法的效率,使其时间复杂度从O(nf+1)降为O(n2),在满足网络中的总节点数N和拜占庭节点数f满足N≥3f+1关系的前提下,可以保证网络的正常运行。
三阶段共识流程和视图更换流程是实用拜占庭共识机制的两个主要流程[26]。
在三阶段共识流程中,分为请求(request)、预准备(pre-prepare)、准备(prepare)、确认(commit)、回复(reply)五个阶段。在request阶段,客户端会向主记账人(主节点)发送请求消息。主节点收到消息后,流程进入pre-prepare阶段,主节点会生成预准备消息广播给网络中所有的记账人节点(从节点)。在prepare阶段,所有的从节点接收到预准备消息并通过验证后,会将其余所有节点广播准备消息。commit阶段,当节点收到来自不同节点的准备消息的数量>2f(不包括自己),就会向网络中除自己以外的所有节点发送确认消息。当节点收到来自不同节点的确认消息的数量>2f+1,进入reply阶段,并向客户端发送回复消息。当客户端收到超过f+1个节点的有效回复消息后,会将这一次的共识判定为成功。其执行流程如图1所示。
当主节点出现异常,并且被从节点判定已失效,就会进入视图更换流程,切换主节点,进入新一轮共识,以保证共识的正常进行。
1.2 Raft共识算法
2014年,Ongaro等人[27]提出了Raft算法。Raft的两个核心部分是领导选举和日志复制。在Raft共识算法中,节点有领导者(leader)、追随者(follower)、候选人(candidate)三种状态,节点会在这三种状态之间有条件地切换。
系统在任一时刻,有且仅有一个leader,leader会周期性地和follower维持心跳联系。当follower超过时间阈值仍然没有收到来自leader的心跳,将会把自己的状态从follower转变为candidate,然后向其他节点广播竞选消息,邀请其余节点投票。如果candidate在竞选时间超时前收到超过半数的投票,将会把自己的状态转变为leader,否则将会广播下一轮竞选消息。节点状态的流程如图2所示。
在日志复制阶段,leader首先会将交易打包并广播给网络中所有节点,follower收到后,向leader反馈;在leader收到超过半数节点的回复信息后,会发送确认信息给follower,并且将该区块计入账本,follower在收到来自leader的确认信息后,也会将该区块计入本地账本。日志复制流程如图3所示。
1.3 集群智能算法
典型的集群智能系统是由若干个彼此间可相互通信且只能完成简单行为的代理组成,这个集群没有控制中心,行为简单,但可以通过彼此交互完成十分复杂的任务,从整体上表现出智能。典型的群体智能算法包括蚁群算法、粒子群算法、混合蛙跳算法、烟花算法等,这些算法普遍具有自组织、灵活性高、无中心控制、低能耗、高鲁棒性等特点;但不同的算法有着不同的优缺点,适用于不同的问题。
在本文研究的问题中,在双层共识网络的下层结构网络,节点群选择leader和监督节点时,Raft算法的随机性太强,在节点规模庞大时会陷入无解情况,故引入群体智能算法来解决该问题;同时还引入声誉值作为影响决策的重要因子,并且随着节点的不同操作,更新声誉值;因此需要一个自适应性强、鲁棒性强和全局搜索能力强的算法优化该流程。在上述的智能集群算法中,粒子群算法容易陷入局部最优解、对初始值敏感以及难以处理约束条件, 不适用于寻找最高声誉值的问题;混合蛙跳算法依赖于不同個体之间的交流,应用在本文研究的问题中,会严重降低选主效率,故也不适用于选主问题;烟花算法也容易陷入局部最优解,参数过多且对参数的敏感性太高,随机性太强,同样不适用于选主问题。
而蚁群算法凭借以下优势[28],更适用于解决该问题。
a)全局搜索能力强。通过蚂蚁之间的信息素交流和反馈来引导搜索过程,能够较好地探索问题空间,并具有全局搜索能力,使得算法在求解复杂优化问题时,能够找到较优的全局解。
b)自适应性和自组织性。蚁群算法具有自适应性和自组织性的特点,蚂蚁在搜索过程中不断调整行为策略,根据环境和信息素的变化进行适应性调整。该特性使得蚁群算法能够应对动态、复杂的问题,适应环境的变化。
c)分布式计算和并行性。蚁群算法的计算过程是分布式的,蚂蚁在搜索过程中独立执行,各个蚂蚁相互协作,通过信息素的交流和反馈来实现群体智能搜索。这种并行性使得蚁群算法在大规模问题和并行计算环境下能够具备较好的性能和效率。
d)鲁棒性和容错性强。蚁群算法具有一定的鲁棒性和容错性,即使在搜索过程中遭遇局部最优解,通过信息素的挥发和更新,也可以帮助蚂蚁摆脱陷入和跳出局部最优解,进一步搜索全局最优解。
1997年,Dorigo等人[29]提出了一种元启发式的蚁群算法,它是通过模拟蚂蚁在寻找食物过程中的行为而发展起来的一类群体智能优化算法。蚁群算法流程如图4所示,其基本思想是模拟蚂蚁在寻找食物时的行为。当一只蚂蚁找到一条路径后,它会释放一种化学物质(信息素)来标记这条路径,其他蚂蚁探测到这些信息素后,更有可能选择沿着被标记的路径行走。随着蚂蚁数量的增加,更多的蚂蚁选择相同的路径,导致该路径上的信息素浓度增加。这样,在信息素的引导下,蚂蚁群体逐渐集中于较优的路径上,从而找到问题的近似最优解。
2 DL_RBFT算法模型
本文结合PBFT共识算法的抗拜占庭节点的安全性和Raft共识算法的高效率的优点,提出了一种基于改进Raft共识算法和PBFT共识算法的双层共识算法。在下层小组网络中,设计了一种更高效、稳定的选主方式,同时在分组时,会争取每个小组的节点数尽可能相同。为了增强Raft算法的抗拜占庭节点的能力,在小组内引入了监督节点。
2.1 DL_RBFT网络结构
在DL_RBFT共识算法中,存在两层共识网络,下层共识网络是一个个相互独立的小组,每个小组都由1个组长节点、1个监督节点和若干个组员节点构成。每个小组的组长共同构成上层的共识网络。DL_RBFT的网络结构如图5所示。
2.2 下层网络主节点更新策略及监督机制
在Raft共识算法中,当节点数量规模达到一定程度后,会在一个时间点存在大量的candidate节点。由于每个节点处理事务的能力不同、网络延迟不同,可能会导致follower节点的选票分散在各candidate节点上,导致选举超时,所以可能会花费大量时间在选举leader上。为了解决这一问题,在初次选举leader时,本文引入声誉机制和蚁群寻路算法,将高声誉值节点模拟为蚁群搜寻目标。在后续重新选举leader时,如果是有节点声誉值达标,则采用声誉值评判机制来作出抉择,并且选择出监督节点;如果是leader出现故障,则由监督节点代替leader,follower中当前声誉值最高的担任监督节点。下面介绍小组内节点选主策略和声誉值机制。
在刚生成区块链网络时会随机指定一个临时组长,然后小组内的节点会先向所有人发送一条消息,消息中记录着本条消息发送时间的时间戳timestampsend。当节点收到其余节点发送的消息时,会记录收到该消息的时间戳timestampreceive,并计算时间差timedifferi=timestampreceive-timestampsend,并广播给其余节点该节点的通信时延。当节点收到来自其余节点的通信时延消息,并且超过2/3的节点所记录的数据差异不大时,会将自己收集到的时延信息发送给临时组长。临时组长会将消息整合,根据时延信息先进行标准化和归一化,然后对所有节点的声誉值进行初始化,如式(1)~(5)所示,其中n为节点数。
声誉值生成后,临时组长会将声誉值信息广播给所有节点,并告知节点开始进行leader竞选。
在首次leader竞选中,默认声誉值排第2的节点作为临时监督节点,声誉值排名前x(3≤x≤10)位的节点会成为candidate节点,然后根据声誉值和蚁群寻路算法进行leader选举。
算法中符号含义如表1所示。
算法1 蚁群选主算法
输入:value,random,α,i=0,β。
输出:leader和监督节点。
a)if i<n 转至步骤b),else i=0,并把票数全部归0,转至步骤b) //检测所有节点是否投票
b)if random<α+β,转至步骤c);else 转至步骤d) /*α和β视不同情況决定*/
c)votemax++,valuemax=valuemax×1.1,转至步骤e) /*声誉值最大的节点的票数和声誉值更新*/
d)随机选择一个不超过x的正整数,然后votem++,valuem=valuem×1.1,转至步骤e) //随机节点的票数和声誉值更新
e)if 不存在节点的选票超过半数i++, 转至步骤a), else选票超过半数的节点成为leader,声誉值第二大的节点成为监督节点,声誉值和票数清零,end //选择leader和监督节点,并对声誉值和票数进行归0操作
在leader产生后,会向follower节点定时发送心跳信息,如若有follower节点超时未收到心跳信息,则会向监督节点汇报leader异常,当监督节点收到超过半数的节点发来的leader节点异常信息,则会将自己的状态转换为leader,并广播给所有节点,同时会指派声誉值最高的follower节点成为监督节点来维持正常的共识功能。小组leader更新流程如图6所示。
在共识过程中,与传统Raft共识流程不同的是,follower节点的确认消息会同时发送给监督节点和leader,leader在记录区块后,也会将反馈信息发送给监督节点。如果监督节点发现消息异常,就会变成leader,然后指派声誉值最高的follower节点作为监督节点来维持正常的共识功能。
在声誉值机制中:
a)leader节点和监督节点不会参与声誉值更新;
b)在产生leader和监督节点后,所有节点的声誉值都会清0;
c)声誉值共分为Vbad、Vnormal、Vgood、Vbetter和Vbest五个等级,分别对应0~20、21~40、41~60、61~80、81~100;
d)节点声誉值到达100,就开始竞选leader。
节点声誉值更新公式如式(6)(7)所示。
a)惩罚公式:
b)奖励公式:
其中:Vi表示小组内第i个节点的声誉值,Vpreviousi表示第i个节点上一次的声誉值。
2.3 DL_RBFT共识流程
在对链上所有节点进行分组、组内leader选举形成双层共识结构后,各组长间进行PBFT共识,组内则采用改进的Raft算法进行共识。形成的双层共识算法在扩展性、安全性和共识效率上均取得了一定程度的提升。
DL_RBFT算法的共识流程如下:
定义小组数为G=3f+1,PBFT主节点编号为p,从节点编号为i,客户端编号为c,客户端请求消息的编号为reqID,请求消息为msg,请求消息的摘要为dig(msg),节点p对msg签名后记作〈msg〉σp,消息的时间戳记作timestamp,最终执行结果为reqs,本次共识的视图编号为Vid。
a)区块链按照2.1和2.2节中的方法分成G个小组,并选举leader,即组长。
b)客户端c发送msg到主节点p,开始进行上层共识,即组间共识。
c)PBFT主节点p向其余从节点发送预准备消息〈〈pre_prepare,reqID,msg〉σp,dig(msg)〉。
d)PBFT从节点接受到预准备消息后,会对消息进行验证检查,若合法,则所有从节点向除自己以外的所有节点广播自己签名后的消息〈prepare,reqID,dig(msg),i〉σp。
e)当节点(组长)收到超过2f个节点的准备消息并验证确认后,会将消息带入小组内,进行组内共识。
(a)组长向监督节点和所有组员节点广播消息。
(b)组员节点收到消息,验证确认后向组长节点和监督节点发送确认信息,监督节点收到超过3n/4个节点发送的确认信息,组长节点收到超过n/2个节点发送的确认信息(n为小组组员节点总数),则进入下一阶段,否则认为本轮共识无效。
(c)监督节点对组长节点进行审查,审查通过,继续完成共识,组长节点将消息上链,并返回上层网络;审查不通过,进行组长更换,具体流程如2.2节所述。
f)组长节点向PBFT网络除自己以外的所有节点广播确认消息〈commit,reqID,dig(msg),i〉σp。
g)当节点收到超过2f+1个来自其他节点发来的确认消息,则认定该消息已确定,并向客户端c发送回复消息〈reply,Vid,timestamp,c,i,reqs〉σi。
DL_RBFT算法的完整共识流程如图7所示。
3 算法分析
本文的DL_RBFT共识算法是针对联盟链提出来的,本章对DL_RBFT共识算法的安全性、一致性、活性进行理论分析,对通信开销进行分析并与PBFT、 Raft算法进行对比。DL_RBFT共识算法是基于PBFT共识算法和Raft共识算法构建的,引入了监督机制、声誉机制和蚁群算法,也对Raft选主流程做了一定改进,使得算法的安全性和活性都有一定的提升。
3.1 安全性
在组长节点组成的上层共识网络中,共识的安全性由PBFT算法自身的抗拜占庭节点特性提供。拜占庭节点不超过组长节点总数的1/3时,系统安全性由PBFT共识流程中的三阶段共识流程保证;当主节点出现异常时,系统通过切换视图来更换主节点,以此来保证安全性。
在下层共识网络的小组中,在传统的Raft算法中引入了监督机制,使得Raft算法拥有了抗拜占庭攻击的能力。如果组长发送给监督节点的确认消息与监督节点自己从组员处收集到的消息不一致,将触发组长更新事件来保证共识的正常进行。
假设小组内节点数量为n,拜占庭节点数量为f。拜占庭节点收到来自组长的消息msg后,可能不处理消息,或者作出假消息msg′,但是会向监督节点发送正确的消息msg。那么监督节点收到的M条一致消息中,可能存在f个拜占庭节点的恶意消息。为了保证M中存在一半以上由诚实节点发送来的消息msg,应满足
因此,在下层共识网络中,引入监督节点可以保证拜占庭节点在不超过n/4的情况下,共识能正常运行。
小组内的组长和监督节点也会在组员声誉值达标或者自身出现异常时进行组长和监督节点的更新,以确保不会存在单点失效的问题。
3.2 一致性
由CAP定理[30]可知,在一个分布式系统中,最多同时满足一致性、可用性、分区容错性三个属性中的两个。但是为了保证系统的可用性,一般会根据BASE理论[31]来构建系统,达到最终一致性而非强一致性。
在组长构成的上层共识网络中,PBFT保证了在拜占庭节点数量不超过组长节点数量的1/3时的一致性。在小组内部,通过Raft算法的日志复制来保证一致性,即使有节点宕机,也可以在恢复后从组长处下载完整的日志记录,达成最终一致性。
3.3 活性
在上层网络中,活性由PBFT算法的视图切换协议来保证。当PBFT主节点出现异常,无法正常响应客户端时,通过p=v mod k确定新的主节点来推动共识流程正常进行,p为主节点编号,v为当前视图编号,k为参与PBFT共识的节点总数。
下层网络中follower会和leader保持心跳消息联系,倘若响应时间超时,则会触发leader更新协议,使监督节点暂代leader,直至下次leader选举;同时,新产生的leader会代替原leader履行其在上层网络中的职责,增强了PBFT算法的活性。
3.4 通信开销分析
在本节中,假设区块链的分组数为G,每个小组的节点数为n,且G≥4,n≥4,则整个链上的总节点数为N=G×n。
1)单次PBFT共识流程通信次数
若使用传统的PBFT共识算法进行一次共识,在request阶段,客户端向主节点发送请求,通信1次;在pre-prepare阶段,主节点向其余节点发送预准备消息,总共通信N-1次;在prepare阶段,每一个收到预准备消息的节点,向其余节点发送prepare消息,此過程通信次数为(N-1)2;在commit阶段,每个节点向其余节点发送确认消息,总共通信N×(N-1)次;在reply阶段,所有节点向客户端发送回复消息,一共通信N次。由此可知,单次PBFT共识流程的总通信次数为
CPBFT=1+(N-1)+(N-1)2+N(N-1)+N=2N2-N+1(10)
2)单次Raft共识流程通信次数
若使用传统的Raft共识算法进行一次共识,leader收到请求消息后,会向所有的follower发送消息,通信N-1次;然后follower会向leader返回处理消息,通信N-1次;日志复制会发生在下一次请求或者心跳中,故单独计算通信次数。由此可知,单次Raft共识流程的总通信次数为
CRaft=(N-1)+(N-1)=2N-2(11)
3)单次DL_RBFT共识流程通信次数
若本文DL_RBFT共识算法进行一次共识,在上层共识网络中,各组长进行PBFT共识,通信次数为2G2-G+1;在下层共识网络的小组内部,leader先向监督节点和follower广播消息,通信次数为N-1次;然后follower向leader和监督节点返回处理消息,通信2(N-2)次;最后监督节点对leader处理信息进行审查,通信次数为2。由此可知单次DL_RBFT共识流程的总通信次数为
CDL_RBFT=2G2-G+1+G[(N-1)+2(N-2)+2]=2G2+3N-4G+1(12)
由上述分析可得,DL_RBFT共识算法将PBFT的时间复杂度从O(N2)降为了O(N+G2)。图8为不同节点数,PBFT、Raft和DL_RBFT共识算法的单次共识次数对比结果,其中展示了DL_RBFT共识算法将节点分为4组和5组的情况。
从图8可以看出,随着节点个数的增加,PBFT的通信次数急剧上升,当节点数为50时,需要近5 000次通信才能完成一次共识;而DL_RBFT和Raft共识算法的通信次数非常接近,且增长速度也非常缓慢。
因此,DL_RBFT共识算法显著地降低了单次共识中的通信次数,并且随着节点数增加,这种优势相比于传统PBFT算法更为显著。
4 实验及结果分析
本文实验通过在一个设备上监听多个不同的TCP端口,对PBFT共识算法、基于网络自聚类PBFT算法(NAC-PBFT)[21]、基于主节点随机选取的改进PBFT算法(RPBFT)[32]、基于节点分组信誉模型的改进PBFT算法(GR-PBFT)[33]以及本文DL_RBFT共识算法在共识延时和吞吐量进行对比分析,还对Raft的leader选举效率和本文改进的选举方案进行对比分析,实验配置如表2所示。
4.1 共识时延测试
在区块链中,共识时延指的是从客户端提交交易请求开始,一直到完成确认所花费的时间,是评价共识算法性能的重要指标之一。在实验中,共识时延的计算公式为
DT=timereq-timereply(13)
其中:timereply是客户端发起请求的时间,timereq是客户端收到足够数量的节点回复的时间。将节点分成不同的组数,多次实验求平均值作为共识时延,并且与PBFT共识算法和文献[21,31,32]改进算法的时延作对比,结果如图9、10所示。
从图9可以看出,随着节点数的增加,共识时延有不同程度的上升,其中PBFT系算法上升得格外迅速,但DL_RBFT算法的增长较为缓慢。当节点数为120时,PBFT的时延已经超过20 000 ms,三个改进PBFT算法均超过15 000 ms,而DL_RBFT算法的时延均不到3 000 ms,与PBFT算法相比,时延降低了近85%,与文献[21,31,32]的改进算法相比,在大规模节点的环境下,DL_RBFT算法共识时延也降低了80%左右。因此DL_RBFT算法因其双层共识网络的特性,能在大规模节点网络中保持较低的共识时延。
从图10可以看出,在DL_RBFT算法中,将节点分成不同组数,共识时延会有细微差别,组数越少,时延起点越低,但增长速率越快,反之起点越高,但增长速率低;总体来说,时间复杂度都是O(n),算法的效率不会有太大差异,证明了DL_RBFT算法具有较强的健壮性和稳定性。
4.2 吞吐量测试
吞吐量是指系统在单位时间内处理的事务数量,在区块链领域中常用每秒完成交易数(transactions per second,TPS)来衡量,假设在Δt的出块时间内完成的交易数量为TransactionΔt,则吞吐量计算公式为
将节点分成不同的组数,多次实验求平均值作为共识时延,并且与PBFT共识算法和文献[21,31,32]的改进算法的吞吐量进行对比。对比结果如图11、12所示。
从图11可以看出,随着节点数增加,几种算法的TPS都呈现下降趋势,但是PBFT算法的下降趋势最快,在很短时间就趋近为0,而DL_RBFT算法的吞吐量下降速度很缓慢,尽管在节点数很少的情况下稍低于文献[21,31,32]的改进算法的吞吐量,但是在本文研究的大规模节点的网络中,仍有较好的吞吐量,这是PBFT算法与其余三种改进算法不具备的特性。因此,DL_RBFT算法适用于对吞吐量有着较高要求的联盟链环境。
从图12可以看出,将节点分成不同组数,组数不同,DL_RBFT算法的TPS也不同,但变化并不大,在大规模节点的使用环境中,仍然能保有一定的吞吐量,再次证明了DL_RBFT算法具有较强的健壮性和稳定性。
4.3 初始leader选择效率
初始leader选择效率是指在刚组成小组时,对正式组长选举的效率。 在引入了声誉机制和蚁群算法的选举算法中,设置信息素和过往决策共占20%、40%和50%的权重,并与Raft中的传统选择机制进行对比,对比结果如图13和14所示。
从图13可以看出,随着节点数增加,Raft原始的选举机制所消耗的輪数增长得非常快,而引入了声誉机制和蚁群算法的改进选举机制则维持在一个小区间内,并且十分稳定。
从图14也可以看出,改进后的选举机制所消耗的时间与原来相比急剧下降,在120个节点的情况下,三种权重下的改进机制的耗时相比于原始机制都下降了50%左右,并且权重占比越高,所消耗时间越少。因此改进后的初始组长选举机制更适用于大规模节点的情况,使得双层共识网络的构建更加迅速。
5 结束语
本文提出了一种基于改进Raft共识算法和PBFT共识算法的双层共识算法——DL_RBFT。该算法很好地结合了PBFT抗拜占庭节点攻击和Raft共识效率高的优点,并且引入监督机制、声誉机制和蚁群算法改进选主流程,提高了算法效率,为共识过程中的安全性提供了保证。实验结果证明,DL_RBFT通信次数、通信时延均优于PBFT算法,并且可扩展性更高,吞吐量更大,更适用于大规模网络节点的环境,有效地突破了现有联盟链的性能瓶颈。
未来将进一步完善算法的细节,提升性能,考虑结合跨链技术,进一步解决联盟链中存在的问题。
参考文献:
[1]Nakamoto S. Bitcoin: a peer-to-peer electronic cash system[EB/OL]. (2008). https://bitcoin.org/en/bitcoin-paper.
[2]Xu Min, Chen Xingtong, Kou Gang. A systematic review of blockchain[J]. Financial Innovation, 2019,5(1): 1-14.
[3]Monrat A A, Schelén O, Andersson K. A survey of blockchain from the perspectives of applications, challenges, and opportunities[J]. IEEE Access, 2019,7: 117134-117151.
[4]Feng Tao, Liu Yufeng. Research on PoW protocol security under optimized long delay attack[J]. Cryptography, 2023,7(2): 32.
[5]Cao Bin, Zhang Zhenghui, Feng Daquan, et al. Performance analysis and comparison of PoW, PoS and DAG based blockchains[J]. Digi-tal Communications and Networks, 2020,6(4): 480-485.
[6]Platt M, McBurney P. Sybil in the haystack: a comprehensive review of blockchain consensus mechanisms in search of strong sybil attack resistance[J]. Algorithms, 2023,16(1): 34.
[7]Zhang Rong, Chan W K V. Evaluation of energy consumption in block-chains with proof of work and proof of stake[J]. Journal of Physics: Conference Series, 2020,1584(1): 012023.
[8]Bachani V, Bhattacharjya A. Preferential delegated proof of stake (PDPoS) —modified DPoS with two layers towards scalability and higher TPS[J]. Symmetry, 2022,15(1): 4.
[9]Surjandari I, Yusuf H, Laoh E, et al. Designing a permissioned blockchain network for the Halal Industry using Hyperledger Fabric with multiple channels and the Raft consensus mechanism[J]. Journal of Big Data, 2021,8(1): 1-16.
[10]Buchman E. Tendermint: Byzantine fault tolerance in the age of blockchains[D].[S.l.]:University of Guelph, 2016.
[11]Zheng Xiandong, Feng Wenlong. Research on practical Byzantine fault tolerant consensus algorithm based on blockchain[J]. Journal of Physics: Conference Series, 2021,1802(3): 032022.
[12]Gorkhali A, Li Ling, Shrestha A. Blockchain: a literature review[J]. Journal of Management Analytics, 2020,7(3): 321-343.
[13]韋可欣, 李雷孝, 高昊昱,等. 区块链访问控制技术在车联网中的应用研究综述与展望[J]. 计算机工程与应用, 2023,59(24):26-45. (Wei Kexin, Li Leixiao, Gao Haoyu, et al. Review and prospect of application research on blockchain access control technology in the Internet of Vehicles[J]. Computer Engineering and Applications, 2023,59(24):26-45.
[14]Xu Xinhan, Chen Xiangfeng, Jia Fu, et al. Supply chain finance: a systematic literature review and bibliometric analysis[J]. International Journal of Production Economics, 2018,204: 160-173.
[15]Agbo C C, Mahmoud Q H, Eklund J M. Blockchain technology in healthcare: a systematic review[J]. Healthcare, 2019,7(2):56.
[16]Jing Nan, Liu Qi, Sugumaran V. A blockchain-based code copyright management system[J]. Information Processing & Management, 2021,58(3): 102518.
[17]Gai Keke, She Yufeng, Zhu Liehuang, et al. A blockchain-based access control scheme for zero trust cross-organizational data sharing[J]. ACM Trans on Internet Technology, 2022,23(3): article No.38.
[18]Ni Shiying, Bai Xiwen, Liang Yuchen, et al. Blockchain-based traceability system for supply chain: potentials, gaps, applicability and adoption game[J]. Enterprise Information Systems, 2022,16(12): 2086021.
[19]王謹东, 李强. 基于Raft算法改进的实用拜占庭容错共识算法[J]. 计算机应用, 2023,43(1): 122-129. (Wang Jindong, Li Qiang. A practical Byzantine fault tolerant consensus algorithm improved by Raft algorithm[J]. Journal of Computer Applications, 2023,43(1): 122-129.)
[20]Seo J, Ko D, Kim S, et al. A coordination technique for improving scalability of Byzantine fault-tolerant consensus[J]. Applied Sciences, 2020,10(21): 7609.
[21]高娜, 周创明, 杨春晓,等. 基于网络自聚类的PBFT算法改进[J]. 计算机应用研究, 2021,38(11): 3236-3242. (Gao Na, Zhou Chuangming, Yang Chunxiao, et al. Improvement of PBFT algorithm based on network self-clustering[J]. Application Research of Computers, 2021,38(11): 3236-3242.)
[22]陈子豪, 李强. 基于K-medoids的改进PBFT共识机制[J]. 计算机科学, 2019,46(12): 101-107. (Chen Zihao, Li Qiang. The improved PBFT consensus mechanism based on K-medoids[J]. Computer Science, 2019,46(12): 101-107.)
[23]翟社平, 廉佳颖, 杨锐,等. 基于Raft分组的实用拜占庭共识算法[J]. 计算机应用研究, 2023,40(11): 3218-3224,3234. (Zhai Sheping, Lian Jiaying, Yang Rui, et al. Practical Byzantine consensus algorithm based on Raft clustering[J]. Application Research of Computers, 2023,40(11): 3218-3224,3234.)
[24]黄冬艳, 李浪, 陈斌,等. RBFT: 基于Raft集群的拜占庭容错共识机制[J]. 通信学报, 2021,42(3): 209-219. (Huang Dongyan, Li Lang, Chen Bin, et al.RBFT: Byzantine fault-tolerant consensus mechanism based on Raft clustering[J]. Journal on Communications, 2021,42(3): 209-219.)
[25]Castro M, Liskov B. Practical Byzantine fault tolerance[C]//Proc of the 3rd Symposium on Operating Systems Design and Implementation.New York:ACM Press, 1999: 173-186.
[26]Li Wenyu, Feng Chenglin, Zhang Lei, et al. A scalable multi-layer PBFT consensus for blockchain[J]. IEEE Trans on Parallel and Distributed Systems, 2020,32(5): 1146-1160.
[27]Ongaro D, Ousterhout J. In search of an understandable consensus algorithm[C]//Proc of USENIX Annual Technical Conference. 2014: 305-319.
[28]秦小林, 罗刚, 李文博,等. 集群智能算法综述[J]. 无人系统技术, 2021,4(3): 1-10. (Qin Xiaolin, Luo Gang, Li Wenbo, et al. An overview of cluster intelligence algorithms[J]. Unmanned Systems Technology, 2021,4(3): 1-10.)
[29]Dorigo M, Gambardella L M. Ant colony system: a cooperative lear-ning approach to the traveling salesman problem[J]. IEEE Trans on Evolutionary Computation, 1997,1(1): 53-66.
[30]Fox A, Brewer E A. Harvest, yield, and scalable tolerant systems[C]//Proc of the 7th Workshop on Hot Topics in Operating Systems. Piscataway,NJ:IEEE Press, 1999: 174-178.
[31]Pritchett D. BASE: an acid alternative: in partitioned databases, trading some consistency for availability can lead to dramatic improvements in scalability[J]. Queue, 2008,6(3): 48-55.
[32]王森, 李志淮, 賈志鹏. 主节点随机选取的改进PBFT共识算法[J]. 计算机应用与软件, 2022,39(10): 299-306. (Wang Sen, Li Zhihuai, Jia Zhipeng. Improved PBFT consensus algorithm with random primary node selection[J]. Computer Applications and Software, 2022,39(10): 299-306.)
[33]陈苏明, 王冰, 陈玉全,等. 基于节点分组信誉模型的改进PBFT共识算法[J]. 计算机应用研究, 2023, 40(10): 2916-2921. (Chen Suming, Wang Bing, Chen Yuquan, et al. Byzantine fault-tolerant consensus mechanism based on Raft clustering[J]. Application Research of Computers, 2023,40(10): 2916-2921.)
猜你喜欢
小学生学习指导(当代教科研)(2021年6期)2021-05-23 13:24:38
马克思主义哲学研究(2020年1期)2020-11-26 07:25:48
内蒙古民族大学学报(社会科学版)(2020年1期)2020-11-03 09:09:48
考试与评价·高二版(2020年3期)2020-09-10 07:22:44
人大建设(2019年12期)2019-11-18 12:11:06
中学历史教学(2018年1期)2018-04-04 05:20:24
古代文明(2016年1期)2016-10-21 19:35:20
中国科技信息(2016年16期)2016-09-10 03:12:33
凤凰生活(2016年2期)2016-02-01 12:41:05
发明与创新(2015年17期)2015-02-27 10:38:59
