
基于机器学习的DDoS攻击网络流量识别方法
2024-05-31 00:26:46刘仲维
无线互联科技 2024年7期
刘仲维
(衡水学院,河北 衡水 053000)
0 引言
分布式拒绝服务(Distributed Denial of Service,DDoS)是网络安全领域的常见安全攻击问题,DDoS攻击通过利用大量受控的僵尸网络(Botnet)向目标系统发起集中请求,耗尽目标网络的带宽或资源,使合法用户无法获取服务。随着攻击手法的多样化与复杂化,传统的基于特征的侦测方法已难以应对新型、变种的DDoS攻击,近年来,机器学习技术以其卓越的数据挖掘能力,为网络流量的分析与异常检测提供了新的视角。本文旨在探讨和分析基于机器学习的DDoS攻击网络流量识别方法,研究机器学习算法在DDoS攻击检测中的应用。
1 DDoS攻击的安全威胁与有效识别
近年来,DDoS攻击已然成为一个严重的网络安全威胁。DDoS攻击通过利用大量受控制的僵尸网络(Botnet)向目标发起大量请求数据包,耗尽目标网络带宽或其他关键资源,严重干扰目标服务器的正常工作,使大量合法用户无法访问网络服务。仅2023年,全球就发生了将近1000万起DDoS攻击事件,造成的经济损失高达数十亿美元。DDoS攻击具有显著的分布式、突发性和隐蔽性特征,这给网络流量的分析带来了极大困难。DDoS攻击源地址经过伪造和代理,动用了成千上万台来自全球各地的“僵尸电脑”参与攻击,源地址分布广泛,难以回溯;攻击流量在极短时间内迅速增长,对网络造成冲击波[1];还利用各种手段伪装成看似正常的流量,隐蔽性非常强。这些特点使得DDoS攻击十分难以预防和检测。目前,各大互联网公司和云服务提供商每年投入巨资用于应对DDoS攻击的威胁。但是,依靠人工分析海量网络数据已难以满足实时检测的需求。许多企业采用了基于攻击签名的检测系统,这类方法依赖手工提取已知攻击的特征,对新型未知DDoS攻击效果不佳。如何从庞大、复杂的网络流量中快速准确识别DDoS攻击,实现流量的精细化分析和图形化展示,一直是网络安全领域亟待解决的问题。
2 DDoS攻击与网络流量分析技术
2.1 DDoS攻击的特点
DDoS攻击作为一种典型的网络拒绝服务攻击方式,具有非常明显的特点,这些特点给识别DDoS攻击流量带来了很大的挑战。主要特点可概括如下。
2.1.1 分布式参与
DDoS攻击可以动员数以万计的各种互联网设备参与攻击。这些设备既包括服务器、PC机,又包括各类物联网设备,都可以成为僵尸网络的一部分。攻击者通过病毒、后门程序等方式,将这些设备变为“僵尸”,远程控制它们发起DDoS攻击。由于攻击源分布在全球各地,十分难以追踪真实攻击发起者。
2.1.2 流量突发性
正常的网络流量通常相对平稳,而DDoS攻击通过同时动用大量节点,可以在极短时间内产生海量攻击流量,在1~2 min内达到峰值,流量骤增在流量图上非常明显,但若仅从短时数据看,很难分辨突发流量是否为DDoS,需要综合判断其他特征。
2.1.3 源地址伪造
由于源地址可以随意伪造,DDoS攻击通常采用随机源IP地址或者存活主机IP地址,因此无法通过简单的源地址过滤来实现防御。攻击者还会使用IP地址欺骗,伪装成知名可信服务的IP地址发动攻击。
2.1.4 协议类型复杂
DDoS攻击可以使用多种协议实现,既有ICMP、UDP洪水等基于量的攻击,又有SYN洪水、ACK洪水等数据包洪水,甚至可以伪装成HTTP、HTTPS等请求。不同协议载荷结构复杂,给流量分析带来难度。
2.1.5 流量模式隐蔽
为了缩小被识别的可能性,攻击者会注重伪装攻击流量,使其模式接近于正常业务流量,如调整发送速率,避免流量过于集中,或在数据包中填充实际业务负载等,导致从单个流或数据包很难检测到攻击。
2.2 传统基于签名的方法的局限性
对于DDoS攻击的检测,传统上广泛采用的是基于攻击签名的方法。该方法通过提取已知攻击的明显特征,构建签名规则库,根据预置规则对网络流量进行匹配和筛选,从而检测出攻击流量。这种方法在应对大量已知攻击时有一定效果,但随着DDoS攻击手段的不断变化,基于签名的检测方式体现出一些局限性:(1)基于签名的方法需要事先获取攻击实例,人工提取其特征构建签名。而新型DDoS攻击手段层出不穷,攻击者可以通过修改协议、调整流量规律等方式产生新的变种攻击,基于签名的系统由于缺乏对这些未知攻击的特征提取和学习,因此难以检测新的攻击变种。(2)依赖专业背景提取特征。攻击签名的生成需要安全专家针对具体攻击流量提取特征,这依赖于很强的专业背景知识和大量人工工作量。不同的攻击类型特征差异很大,提取过程缺乏统一规范,不利于签名库的共享应用。(3)效率难以应对高带宽流量。基于签名的方法需要将每个数据包或会话流与规则库逐一匹配,时间复杂度较高,DDoS攻击流量速率极快,对检测系统效率需求非常高,海量流量下签名匹配容易成为性能瓶颈,难以满足实时检测需求。
2.3 基于机器学习的网络流量分析技术
机器学习作为一种自主学习和模式识别的技术,具有很强的数据建模和泛化能力。基于机器学习算法训练的网络流量分析模型,可以自动从大规模的正常流量和攻击流量数据集中学习提取流量统计特征和行为特征,形成网络异常流量和已知攻击类型的检测模型,智能化、自动化检测网络威胁。机器学习模型通过学习获得流量特征的敏感性和泛化能力,可以泛化检测训练数据集中没有出现的新型网络攻击。基于流量分布的建模,机器学习模型可以检测训练数据中没有出现过的新型DDoS攻击。模型通过学习对流量时间统计规律、协议结构等的敏感性,对未知攻击具有很强的检测能力。机器学习模型经过训练后,可以利用高度优化的并行算法对流量进行模式识别与分类,时间复杂度低。基于GPU并行处理,可以实现每秒钟处理百万级数据包的超高速分析。
3 基于机器学习的DDoS攻击流量识别模型构建
3.1 数据采集与预处理
在构建基于机器学习的DDoS攻击流量识别模型之前,需要预处理采集得到的网络流量数据,以消除数据噪声,提取合适的特征,并将特征标准化到同一量纲。本研究使用UNSW-NB15数据集作为实验数据源,该数据集包含了正常流量和多种DDoS攻击流量。使用Python的Pandas库读取数据集,并进行数据清洗处理,提取了包括源IP、目的IP、源端口、目的端口、协议类型等在内的多种网络流量特征,组成特征矩阵:
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X=scaler.fit_transform(X)
对提取出的各个特征xi作标准化处理,以消除不同特征尺度带来的影响。标准化转换公式为:
其中,μi和σi分别是特征xi的均值和标准差。经过上述步骤,获得了干净、标准化的特征数据和标签,以供后续DDoS攻击流量识别模型的训练和测试。
3.2 特征工程
特征工程是构建高效机器学习模型的关键环节之一。为了从复杂的网络流量数据中提炼出有利于DDoS攻击识别的特征表示,先计算网络流量时间窗口内的基础统计量特征,如平均数据包大小、平均到达时间间隔等,反映流量的统计分布。然后,应用主成分分析(PCA)算法对原始网络流量特征矩阵进行正交转换降维,提取主要成分作为特征,以过滤冗余信息压缩特征空间。PCA的目标函数为最大化投影方差:
from sklearn.decomposition import PCA
pca = PCA(n_components=10)
pca_features = pca.fit_transform(X)
其中,PCA优化目标函数为:
研究还构建了基于深度神经网络的流量数据自编码器模型,通过训练自编码器使其在低维空间中重构流量数据,从而学习高阶的非线性流量特征表达:
from keras.layers import Input,Dense
from keras.models import Model
# 自编码器模型
input_layer = Input(shape=(28,))
encoded = Dense(14,activation='relu')(input_layer)
decoded = Dense(28,activation='sigmoid')(encoded)
autoencoder = Model(input_layer,decoded)
autoencoder.compile(optimizer='adam',loss='binary_crossentropy')
# 提取编码层作为特征
encoder = Model(input_layer,encoded)
encoded_features = encoder.predict(X)
3.3 机器学习模型选择与训练
在获取经过预处理的网络流量数据集后,研究选择了支持向量机(SVM)和随机森林2种机器学习算法进行建模,以实现DDoS攻击流量的自动识别。SVM是一种广泛采用的监督学习方法,其基本模型定义为f(x)=sign(wTx+b),通过学习最大间隔超平面实现分类分隔,从而可应用于不同的模式识别与分类问题。SVM的学习可形式化为一个凸二次规划问题:
这里C是正则化参数。通过引入核函数,SVM可以学习复杂的非线性决策边界,然后使用Python的scikit-learn库构建SVM模型:
from sklearn import svm
svm_clf = svm.SVC()
svm_clf.fit(X_train,y_train)
y_pred = svm_clf.predict(X_test)
随机森林是一个包含多个决策树的集成模型,通过在训练过程中引入随机抽样和特征采样,可以有效降低模型的方差,增强模型的泛化性。使用信息熵作为分裂criterion,并选择最佳的树数n_estimators:
rfc = RandomForestClassifier()
n_estimators=[10,50,100,200,500]
grid_rfc=GridSearchCV(rfc,param_grid={'n_estimators':n_estimators})
grid_rfc.fit(X_train,y_train)
best_n = grid_rfc.best_params_['n_estimators']
训练完成的SVM和随机森林模型在测试集上进行性能评估,选择最优模型用于DDoS攻击识别。
3.4 实验与结果分析
3.4.1 实验数据集和环境
在DDoS攻击流量识别模型的训练和测试中,使用了公开的UNSW-NB15数据集。UNSW-NB15数据集包含了约175000条网络流量记录,特征包括流量基本属性、内容特征等。从该数据集中提取出只包含正常流量和DDoS攻击流量的子集,做了流聚合和特征提取,最终构建了一个规模为3万条样本、130维特征的实验数据集,按比例分为训练集和测试集。
考虑到机器学习模型对特征值范围较为敏感,采用Z-Score方法对流量特征进行标准化处理[2]。实验环境基于Python语言和TensorFlow框架,主要依赖库包括NumPy、Pandas、Scapy、Sklearn、Keras等,模型训练和评估在具备Tesla V100 GPU的工作站上完成,使用GPU加速了训练过程,软硬件配置充分。
3.4.2 关键参数设置
在训练 SVM 和随机森林模型时,通过Grid Search方法遍历不同参数组合,分析了模型在验证集上的性能,调优了一些关键超参数,具体设置如表1—2所示。

表1 SVM模型参数
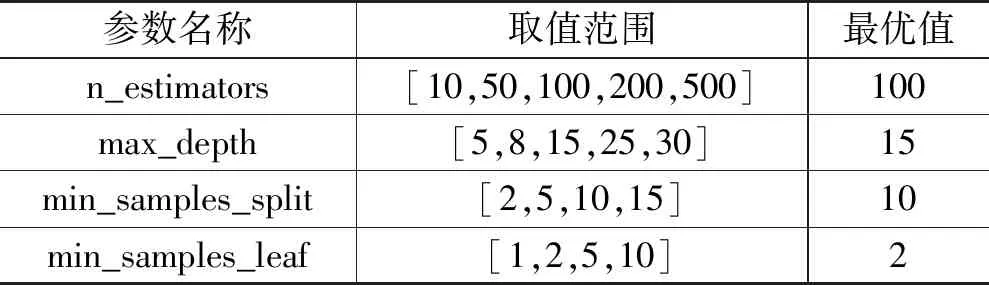
表2 随机森林模型参数
其中,SVM的正则化参数C用于控制分类误差与模型复杂度之间的权衡;核函数kernel选择RBF以核拟合复杂决策边界;gamma参数影响RBF核的解析能力。随机森林中,n_estimators表示森林中决策树的数量;max_depth控制单棵树的最大深度;min_samples_split和min_samples_leaf表示节点分裂所需的最小样本数。
3.4.3 实验结果及性能评估
为全面评估所构建的支持向量机模型和随机森林模型在DDoS攻击流量检测应用上的效果,采用多项关键指标对两种模型在测试集上的性能进行比较分析。主要考量了精确率、召回率、F1指标以及ROC曲线下方面积AUC 4个指标[3],这些指标从不同角度反映了模型的准确性和泛化性能,如表3所示。

表3 SVM和随机森林在测试集上的性能
从定量结果可以看出,随机森林模型的整体表现要略优于支持向量机模型,其中随机森林在测试集上取得了92.6%的高精确率,召回率也达到90.7%,F1得分为91.6%,AUC指标达到0.97,支持向量机的各项指标也均在89%以上的较优水平。若从识别不同类型DDoS攻击的角度进行分析,随机森林同样显示了更好地多类泛化能力,如表4所示。

表4 模型在不同攻击类型上的检测率
在SYN洪水攻击、UDP洪水攻击和ACK洪水攻击3种典型DDoS攻击场景上的检测率也都高于支持向量机模型,尤其在UDP洪水攻击上的识别率最高,可达92.3%。综合以上定量结果可以发现,所构建的集成随机森林模型不仅整体DDoS攻击流量检测精确率和召回率超过90%,不同类别的具体攻击检测率也在86%以上,已经达到了较高的性能水平。
4 结语
机器学习技术在网络安全领域具有广阔的应用前景。实验结果显示,经过调参优化的集成随机森林模型达到了90%以上的总体检测精确率,不同DDoS攻击类型的识别率也均在86%以上。当然,模型对新增未知攻击类型的泛化能力还有待提高,后续工作的一个重点方向是继续扩充训练集样本量和种类,以涵盖更多DDoS攻击模式,并研究模型集成的方式来增强检测的鲁棒性,实际应用中还需要考虑算法的训练效率和检测速度等方面的优化,以及不同网络环境的适配问题。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22 09:52:26
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
微型电脑应用(2021年3期)2021-03-31 08:56:46
网络安全和信息化(2018年4期)2018-11-09 12:01:54
电影(2018年8期)2018-09-21 08:00:06
北京航空航天大学学报(2017年7期)2017-11-24 05:27:28
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
中国新通信(2014年11期)2014-09-11 19:27:52
河南科技(2014年23期)2014-02-27 14:18:43
