
数据要素、数据劳动与中国制造业增长
2024-05-26 01:21于柳箐
统计与决策 2024年9期
于柳箐,高 煜,b
(西北大学a.经济管理学院;b.中国西部经济发展研究中心,西安 710127)
0 引言
在加快建设“数字中国”和加快发展数字经济的背景下,充分利用数据要素推动中国制造业增长以及数字化转型升级对现代化产业体系的建立尤为重要。数据不仅是信息技术制造业等新兴数字产业发展所必须依赖的要素,还在传统制造业数字化转型与变革过程中发挥着极其重要的作用。可以说,制造业变革或产业升级的路径就是土地、劳动力、资本、知识、数据等生产要素主导地位变化的过程。从而,研究数据要素对制造业增长的影响对于正在迈向制造强国的中国而言具有重要意义。当前文献着重考察了数据要素对制造业全要素生产率提升[1]、高质量发展[2]、绿色发展[3]等的影响,同时探究了企业增长和效率提升中数据要素与劳动力要素的结合效应[4,5]。然而,上述文献虽然在理论上明确了数据要素投入效应的发挥需要结合劳动力要素,但未进一步指明是何种劳动产生作用,且缺少经验证据。另外,在实证检验数据要素对制造业的影响时主要采用固定效应模型,虽然解决了部分不可观测因素对数据要素投入效应估计一致性的混淆,但是由于仅控制了少数变量,因此依然可能存在遗漏变量偏差。
作为数字经济时代具有关键作用的生产要素,数据要素与劳动力要素协同促进制造业增长的内在规律意义显著。鉴于此,本文旨在研究数据要素如何协同劳动力要素促进制造业增长。本文基于2012—2019年中国省级面板数据,利用因果森林这一机器学习异质性因果推断方法估计了数据要素影响制造业增长的效应,并进一步考察了数据要素投入效应在拥有不同数据劳动规模的地区制造业增长中是否存在异质性,以及如何呈现异质性。相比现有文献,本文以数据挖掘机制为核心深入分析了数据劳动对数据要素促进制造业增长的调节机制;补充了数据劳动如何发挥调节作用的经验证据;利用因果森林高维数据拟合和个体处理效应(Individual Treatment Effect,ITE)估计能力,在控制众多投入要素变量的同时进行基于个体的非线性异质性因果推断,不仅有效缓解了遗漏变量偏差问题,还使得考察数据劳动对数据要素促进制造业增长的非线性调节模式成为可能。
1 机制分析与研究假设
1.1 数据挖掘:数据要素促进制造业增长的核心机制
数据要素已经成为数字经济时代企业生产、经营管理、研发创新、营销等决策过程中的必要投入。但是原始数据的积累并不能自动转化为用于生产的数据资本,与劳动力、资本等实物(有形)生产要素通过直接投入产生经济物品不同,数据是虚拟(无形)的,无法依靠自身的消耗和形变创造价值,必须经过一定的转换、分析、处理才能成为促进企业增长的要素投入[6]。作为投入要素的数据,其本质是以0-1(二进制)编码的信息,具有非结构化和价值稀疏的特征,为了充分发挥数据价值,需要通过搜集、存储、清洗等步骤将低价值的非结构化形态转换为可供特定场景使用的高价值结构化形态,最后经过分析提取出有用的信息[5],这一过程即数据挖掘(Data Mining)。对产生于日常生产经营活动中数据资源①在产品生产、研发、销售中,或在人力资源、财务管理等活动中产生的原始数据。的挖掘将助推制造业企业形成数据-信息驱动决策范式,有利于优化生产技术、激励研发创新、提升管理能力等,进而实现制造业增长。
1.2 数据劳动:数据要素促进制造业增长的调节机制
数据要素的供给源于劳动创造,它不是原始的数据符号,而是经过挖掘后凝结了人类劳动的数据产品[7],形成数据要素的成本主要来自人力搜集、处理数据的成本[8]。换言之,涵盖数据搜集、存储、清洗与分析过程的数据挖掘的实现需要具备相关技能的劳动力全程参与,这反映了利用人力资本将数据“提纯”的逻辑思想[6]。Abis 和Veldkamp(2021)[9]构建了包含数据要素的两阶段知识生产模型,并指出在将原始的非结构化数据转换为结构化数据的过程中,需要数据管理人员的介入,随后结构化数据集与从事数据分析的劳动力将一同作为知识生产中的要素。具体来看,实现数据挖掘的劳动(即数据劳动)包括对数据的搜集、管理和分析,相应地,从事数据劳动的人员包括进行数据搜集与记录的数据搜集人员、进行数据清洗与存储的数据管理人员和进行数据分析的数据分析人员。对数据的挖掘能够促进制造业增长,而数据挖掘的实现又依赖于数据劳动。因此,在拥有不同数据劳动规模的地区,数据要素促进制造业增长的效应可能不同。数据劳动供给越充足的地区,数据挖掘的作用越能充分显现,数据资源中的信息越能被充分提取,从而数据要素促进制造业增长的效应越明显。据此,本文提出以下两个待检验的假设:
假设1:数据要素投入可以促进中国制造业增长。
假设2:数据要素对制造业增长的促进效应受到数据劳动的调节,数据要素能更好地促进拥有更大数据劳动规模地区的制造业增长。
2 研究设计
2.1 因果森林方法概述
传统回归模型无法有效拟合高维数据,可能造成遗漏变量偏差,同时还缺乏有效的异质性处理效应估计方法。Wager 和Athey(2018)[10]对经典随机森林(Random Forests)算法的节点分裂规则、数据拟合模式、处理效应估计等方面进行了改进,发展出因果森林(Causal Forests),不仅能用于高维数据因果推断,还能进行个体异质性处理效应估计。在非混淆假设下,基于半参数部分线性模型利用残差回归的推断,对于所有的x∈χ,结合随机森林方法可以得到固定的条件平均处理效应(τ^):
其中,Wi代表处理变量,Yi代表因变量,e(x)=P[Wi|Xi=x] 是由随机森林计算的倾向分数,m(x)=E[Yi|Xi=x]是由随机森林计算的边际结果(marginal outcomes),上标(-i) 表示执行随机森林的袋外(out-of-bag)预测①对于每个训练示例,所有在训练期间没有使用此示例的树都被识别出来,然后仅使用这些树对测试示例进行预测。。虽然式(1)对处理效应的估计是半参数有效的,但只能用于固定处理效应的估计,为此,Nie 和Wager(2021)[11]在式(1)的基础上生成了一个“R-learner”目标函数(objective function),用于异质性处理效应的估计:
其中,Λn(τ(·))是正则化项,用于控制学习到的函数^(·)的复杂性。不同于经典随机森林仅关注预测误差是否因节点分裂而降低,因果森林通过最大化节点分裂后处理效应的组间差异反映异质性处理效应。因此,在给定Xi并最小化式(2)后,可为每个个体提供一个相应的条件平均处理效应估计^(Xi)。具体来看,因果森林通过随机森林的袋外预测得到估计值^(·)和^(·),再利用式(3)可得到条件平均处理效应估计值:
其中,αi(x)为数据-自适应核(data-adaptive kernel),是利用随机森林测量的第i个训练示例与测试点x落入同一叶子的频率。将随机森林看作一种基于核的观点使得用式(1)和式(2)进行处理效应估计成为可能。式(3)实际上使用罗宾逊变换进行了正交化处理[11],即首先训练单独的随机森林和执行袋外预测计算倾向分数和边际结果的估计值,然后计算残差处理W-^(x)和残差结果Y-(x),最后在这些残差上训练一个因果森林。正交化估计量从Wi中剔除了Xi的影响,相当于执行了工具变量法,因此正交化对于在观测性研究中获得准确的处理效应估计必不可少。
因果森林不仅能在具有非混淆性假设的潜在结果框架下得到一致的处理效应估计量,还能够有效降低标准误,提高估计准确性。更为重要的是,因果森林具备高维数据拟合和个体处理效应估计能力,弥补了传统回归模型的不足[10]。
2.2 变量设定
2.2.1 处理变量
本文所关注的是数据要素投入与制造业产出的关系,因此处理变量是数据要素投入规模。虽然现行的统计和国民经济核算体系中仍然缺少有关数据要素规模、价值、存量等的记录,但是可以借鉴以往评估无形资产价值的经典方法,比如市场法、收入法和成本法对数据要素价值展开测度[5]。然而由于当前数据要素交易频率较低,且可参照的相关资产难以寻找,造成其未来收益、资产寿命、折旧率等难以准确衡量,使得市场法和收入法在数据要素价值测度实践中无法实现[8],因此只有成本法是目前最具可行性的测度数据要素价值的方法,即通过投入在数据生产活动中的劳动力和资本成本间接反映数据要素价值。鉴于此,徐翔等(2024)[8]基于从事数据搜集、处理的就业人员工资与数据资本投资数据测度了历年各省份的数据要素规模存量(datSca)。本文使用这一指标作为处理变量。
2.2.2 结果变量
本文的结果变量是制造业产出水平,采用主营业务收入(manIn)衡量。
2.2.3 调节变量
本文的调节变量是数据劳动规模。Nguyen和Paczos(2020)[12]指出,并非所有的行业都与数据生产活动相关,同时与数据生产相关的劳动力也不会将所有的工作时间都用于数据生产,因此各个行业或职业都存在一个“数据使用强度”。鉴于此,加拿大统计局对与数据生产相关的职业均分配了一个数据生产工作时间占全部工作时间的比例区间,随后与各职业人数相乘估算了数据劳动规模。然而这一做法具有较强的主观性,同时由于缺少中国省级层面的相关职业人员数据,因此本文以行业就业人员数据为基础构造地区数据劳动规模指标(datLab)。具体地,借鉴许宪春等(2022)[5]提出的“供给法”,本文基于数据生产活动中的劳动力与其数据生产工作时间占比估算地区数据劳动规模:第一步,根据《国民经济行业分类》(GB/T 4754-2017)选择与数据生产活动相关的国民经济二位数大类行业j,包括计算机、通信和其他电子设备制造业,仪器仪表制造业,软件和信息技术服务业,互联网和相关服务,电信、广播电视和卫星传输服务①根据徐翔等(2024)[8]的计算,以上行业中数据生产活动占其总生产活动的比例均接近或超过50%。另外,根据《国民经济行业分类》(GB/T 4754-2017),(63)电信、广播电视和卫星传输服务,(64)互联网和相关服务,(65)软件和信息技术服务业是门类行业(I)信息传输、软件和信息技术服务业下所包含的二位数大类行业。,以及为工业互联网发展提供所需装备的通用设备制造业和专用设备制造业[2]。第二步,使用徐翔等(2024)[8]计算的上述行业j的数据生产活动占其总生产活动的比例αj乘以行业j在i地区t年份的就业人数Lijt,得到行业j在各地区不同年份的数据劳动投入αjLijt。第三步,加总t年份i地区内所有行业j的数据劳动投入得到历年各地区数据劳动规模指标,即datLabit=∑jαjLijt。
2.2.4 控制变量
由于因果森林具备高维数据拟合能力,因此可以通过控制更多的投入要素变量有效抑制潜在的混淆偏差,进而得到数据要素影响制造业增长的一致估计。本文在欧阳志刚和陈普(2020)[13]的研究基础上增加了数据要素类别,同时在物质资本中增加了衡量网络基础设施和数据资本的指标,在人力资本中增加了衡量数据劳动的指标。最终构建了包含7 个投入要素类别、18个一级指标、30 个二级指标的投入要素指标体系(如表1所示)。
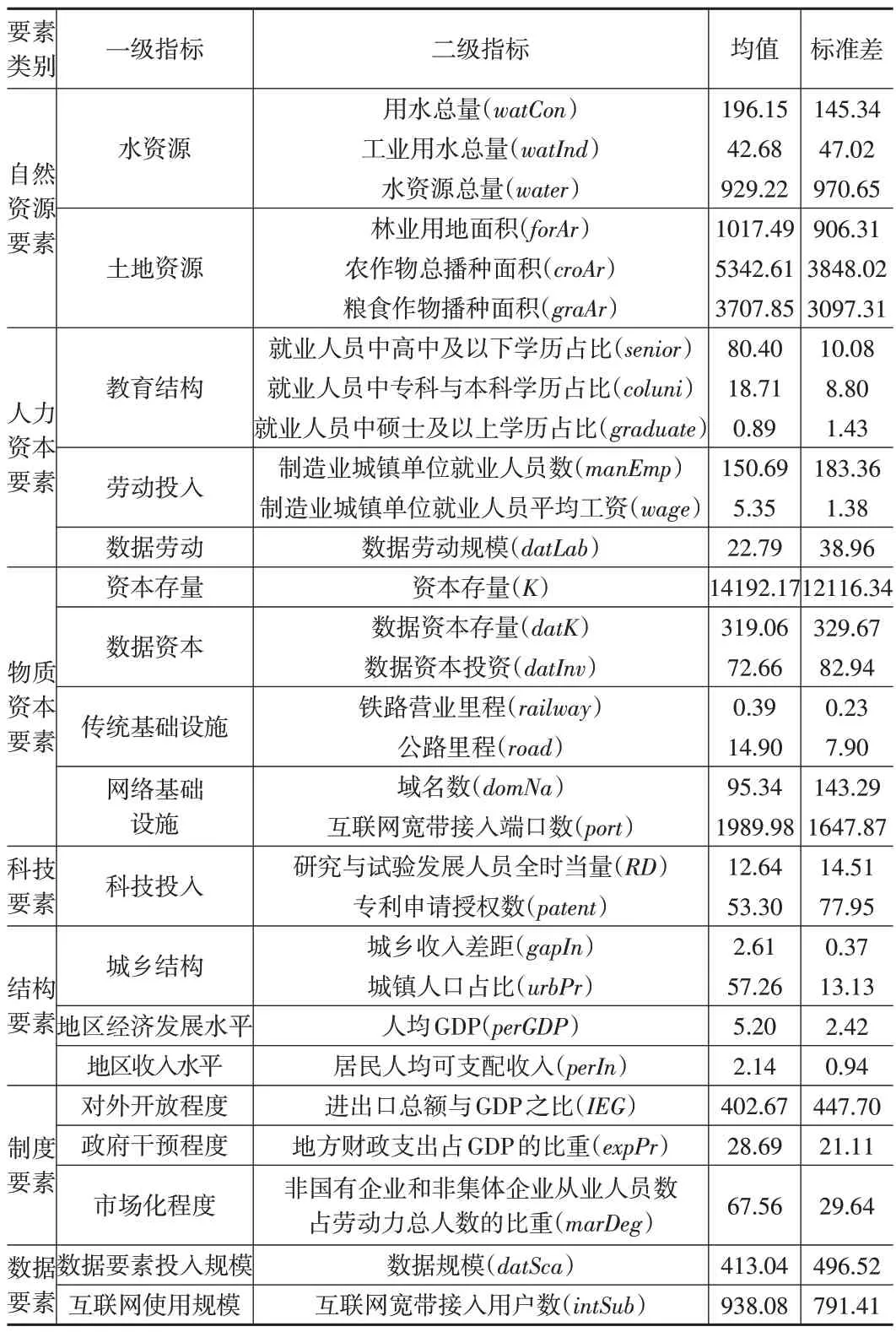
表1 投入要素指标体系与变量描述性统计
2.3 数据来源与说明
本文所用样本为2012—2019 年中国31 个省份(不含港澳台)的面板数据。投入要素变量数据主要来自中国研究数据服务平台(CNRDS)以及历年《中国统计年鉴》《中国科技统计年鉴》《中国劳动统计年鉴》《中国教育统计年鉴》《中国固定资产投资统计年鉴》等,制造业主营业务收入数据来自历年《中国工业统计年鉴》。需要说明的是,由于新冠肺炎疫情的影响,中国制造业在2020 年后的发展遭受重大冲击,可能波及数据要素对制造业增长的影响效应以及数据劳动的调节作用。与此同时,疫情期间大部分的经济统计指标均出现异常变动,不仅会影响因果森林等机器学习模型的估计效果[14],还会影响数据要素规模存量指标测度的精确性。因此,为了确保实证结果的可信度,参照近期文献的普遍做法[8,15],设定2019年为观察末期。
3 实证结果与分析
3.1 数据要素对制造业增长的影响
利用因果森林估计数据要素影响中国制造业增长的效应。为了得到更为稳健的结论,本文对因果森林模型参数(即超参数)进行了不同设置,结果如表2 所示。其中,列(1)使用R 语言grf 程序包中casual_forest 函数的默认超参数;列(2)、列(3)将基础决策树的数量分别设置为1000和4000 棵;列(4)进行聚类分析,将处理效应的估计聚类到省份层面,以控制不可观测的地区差异。不同省份具有不随时间改变的文化、区位、自然条件等特征,传统回归模型通过“固定效应”或“随机效应”模型来捕获聚类效应,但是线性可加性假设限制了非线性聚类效应的估计。为解决这一问题,本文使用因果森林聚类分析方法,在模型训练时所有的二次抽样过程、节点分裂、森林预测等均在整个集群上进行操作,而不是单个观测;列(5)使用交叉验证调参,即利用机器学习交叉验证法对因果森林超参数进行自动选择①具体做法是通过训练拥有不同超参数设置的因果森林,得到使式(2)“R-learner”目标函数袋外估计最小化时的超参数,并使用该超参数设置生成因果森林模型。;列(6)进行聚类分析的同时使用交叉验证调参。
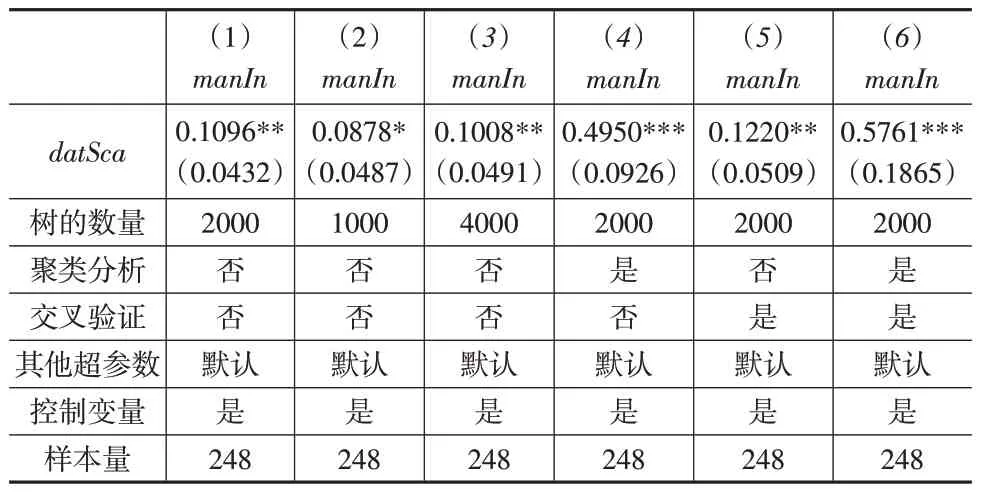
表2 数据要素影响制造业增长的效应估计
从表2可以看出,在基于不同超参数设置的因果森林模型中,datSca 系数均显著为正,因此说明数据要素对中国制造业增长具有显著的促进作用,假设1得到证实。需要说明的是,由于因果森林进行聚类分析以及使用交叉验证调参时避免了不可观测因素的干扰和人为主观设定超参数的弊端,因此后文对数据劳动调节作用的考察以及稳健性检验均以列(6)为基准。
3.2 数据劳动的调节作用
3.2.1 异质性检验
据前文可知,因果森林通过式(2)在给定Xi时可以为每个个体提供一个相应的条件平均处理效应(CATE)估计τ^(Xi)。基于此,本文使用表2 列(6)计算得到各省份数据要素影响制造业增长效应的估计值,并使用核密度分布进行拟合。拟合图(略)结果显示,CATE估计值的分布并不集中,分散于0.1~0.55,这说明数据要素对制造业增长的促进效应在不同省份之间存在差异。
为确定样本中是否存在异质性处理效应,本文使用最佳线性预测方法进行更正式的检验。将条件平均处理效应的袋外因果森林估计值划分为两个部分,分别为其中是袋外处理效应估计的平均值,随后将对Ci和Di进行回归,即设定如下回归模型:。Di的系数β2可解释为对处理效应异质性估计质量的度量,如果显著为正,那么表明和τ(Xi)之间存在联系,换言之,因果森林能够发现数据中存在异质性处理效应的假设得到了支持。从表3可知,当进行聚类分析后,Di的系数β2显著为正,说明数据要素影响制造业增长的效应的确存在地区差异,同时也体现了聚类分析的有效性。

表3 最佳线性预测检验结果
3.2.2 调节效应估计
为揭示数据要素影响制造业增长的效应是如何随着数据劳动规模的变化而变化的,本文利用由表2 列(6)得到的各省份数据要素影响制造业增长效应的估计值(CATE)以及相应省份的数据劳动规模生成散点图,并使用线性回归法与局部多项式回归法(LOESS)进行拟合,如图1所示。直线拟合显示,数据要素对制造业增长的促进效应随着数据劳动规模的扩大而增强。这说明数据要素能更好地促进拥有更大数据劳动规模地区的制造业增长,假设2得证。
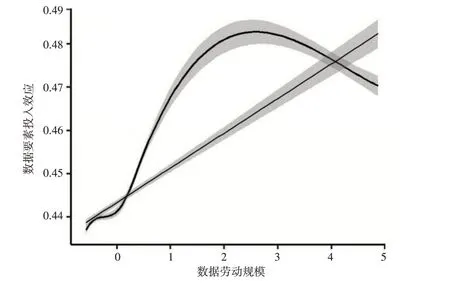
图1 数据劳动对数据要素促进制造业增长效应的调节作用
进一步地,曲线拟合展现了数据劳动边际处理效应(Marginal Treatment Effect,MTE)的变化,可以看到,数据劳动对数据要素促进制造业增长效应的调节呈现“倒U”型态势,即随着数据劳动规模的扩大,数据要素投入效应的增长幅度越来越小。这可能是因为,数据要素促进制造业增长效应的大小取决于从单位数据要素内挖掘的有用信息的多寡,而从单位数据要素内挖掘的有用信息的数量不仅取决于进行数据搜集、管理和分析的数据劳动人员数量,还依赖于他们所应用的数据抓取、编码、整合以及机器学习等数据挖掘技术。因而在数据挖掘技术水平的约束下,随着数据劳动规模的持续扩大,从单位数据要素内挖掘的有用信息的数量逐渐到达上限,进而新增数据劳动挖掘的有用信息的数量逐渐下降至零,从而导致新增数据劳动对数据要素投入效应的提升作用越来越小。
3.3 稳健性检验
(1)更换处理变量。为避免数据规模存量指标测度误差对估计结果的影响,借鉴徐翔和赵墨非(2020)[6]在研究数据资本与经济增长路径时的做法,选取省际移动互联网接入流量作为反映地区数据要素规模的指标,并将其转换为制造业层面数据。
(2)小样本调参。由于本文使用的是省级层面的数据,为避免基于小样本进行因果森林估计时可能存在的偏差,采用两种方案进一步优化超参数设置,以增强结果的稳健性。一是增加用于调参的树的数量;二是增加基础决策树的数量以及诚实分割部分,同时禁止诚实树剪枝。
(3)更换机器学习模型。为避免不同机器学习方法对因果森林估计的影响,分别使用广义回归森林和广义提升森林模型计算得到倾向分数^(x)、边际结果(x),随后将其作为超参数传递至因果森林模型。
结果(略)显示,在更换处理变量、使用适用于小样本的超参数、更换计算倾向分数和边际结果的机器学习模型后,因果森林模型对数据要素影响制造业增长效应的估计均显著为正,同时数据劳动对数据要素促进制造业增长效应的调节模式也与前文一致,说明本文的结论稳健。
4 结论与启示
本文主要研究了数据要素能否促进制造业增长以及数据劳动如何发挥调节作用的问题。以2012—2019年中国省级面板数据为研究样本,使用因果森林方法展开异质性因果推断,不仅估计了数据要素对制造业增长的影响效应,还考察了数据劳动对数据要素促进制造业增长效应的调节模式。据此,得到如下结论:第一,数据要素对中国制造业增长具有显著的促进作用;第二,数据要素能更好地促进拥有更大数据劳动规模地区的制造业增长;第三,随着数据劳动规模的持续扩大,数据要素投入效应的增长幅度越来越小。
由以上结论得出如下启示:首先,政府需要通过加快数据开放、数据交易基础设施建设、数据要素市场化改革等举措,努力提高数据要素供给数量与质量,而制造业企业则需要重视数据要素在生产经营活动中的作用,加强数据要素投入,并积极融入制造业的数字化转型升级;其次,政府需要加强数据搜集人员、数据管理人员、数据分析人员等数据劳动力的培育,而制造业企业则需要加快数据劳动人员的引进,充分发挥数据挖掘的作用,以提升数据要素对制造业增长的促进效应;最后,制造业企业在加强数据要素投入时,不仅应注意数据劳动人员数量的增加,还要关注数据劳动人员的数据搜集、管理、分析等技术应用能力的提高,以进一步激发数据挖掘的效用,充分挖掘数据资源中的有用信息,从而推动数据要素促进制造业增长效应的不断提升。
猜你喜欢
走向世界(2022年3期)2022-04-19
现代企业(2021年2期)2021-07-20
当代水产(2020年4期)2020-06-16
华人时刊(2019年15期)2019-11-26
现代园艺(2017年22期)2018-01-19
河北书画研究(2017年1期)2017-08-22
山东青年(2016年2期)2016-02-28
邯郸职业技术学院学报(2016年2期)2016-02-27
上海企业(2014年9期)2014-09-22
上海企业(2014年9期)2014-09-22
