
融合时空图卷积网络与非自回归模型的三维人体运动预测
2024-05-24 03:32刘一松高含露蔡凯祥
计算机应用研究 2024年3期
刘一松 高含露 蔡凯祥


摘 要:
当前人体运动预测的方法大多采用基于图卷积网络的自回归模型,没有充分考虑关节间的特有关系和自回归网络性能的限制,从而产生平均姿态和误差累积等问题。为解决以上问题,提出融合时空图卷积网络和非自回归的模型对人体运动进行预测。一方面利用时空图卷积的网络提取人体运动序列的局部特征,可以有效减少三维人体运动预测场景中的平均姿态问题和过度堆叠图卷积层引起的过平滑问题的发生;另一方面将非自回归模型与时空图卷积网络进行结合,减少误差累计问题的发生。利用Human3.6M的数据集进行80 ms、160 ms、320 ms和400 ms的人体运动预测实验。结果表明,NAS-GCN模型与现有方法相比,能预测出更精确的结果。
关键词:人体运动预测;非自回归;图卷积网络
中图分类号:TP181 文献标志码:A 文章编号:1001-3695(2024)03-048-0956-05doi: 10.19734/j.issn.1001-3695.2023.07.0323
Three-dimensional human motion prediction combining spatiotemporal graph
convolutional networks and non-autoregressive models
Liu Yisong, Gao Hanlu, Cai Kaixiang
(School of Computer Science & Communication Engineering, Jiangsu University, Zhenjiang Jiangsu 212013, China)
Abstract:
The current methods for predicting human motion mostly use autoregressive models based on graph convolutional networks, without fully considering the unique relationships between joints and the limitations of autoregressive network performance, resulting in issues such as average posture and error accumulation. To address the above issues, this paper proposed a fusion of spatiotemporal graph convolutional networks and non autoregressive models for predicting human motion. On the one hand, using a network of spatiotemporal graph convolutions to extract local features of human motion sequences could effectively reduce the occurrence of average pose problems and oversmooth problems caused by excessive stacking of graph convolutions in 3D human motion prediction scenes. On the other hand, it combined non-autoregressive models with spatiotemporal graph convolutional networks to reduce the occurrence of error accumulation problems. Conduct human motion prediction experiments using a Human3.6M dataset for 80 ms, 160 ms, 320 ms, and 400 ms. The experimental results indicate that the NAS-GCN model predicts more accurate results compared to existing methods. Key words:human motion prediction; non-autoregressive; graph convolutional network
0 引言
三維人体运动预测目前主要用于人机交互、运动分析和体育预测等领域,该方向由人体姿态特征提取和运动预测两部分组成。由于深度学习的发展,近年来相关方法已经使得模型预测的精确度得到很大提升。
基于图卷积网络(graphical convolutional network,GCN)的自回归模型是目前人体运动预测的主流方法,该方法利用图卷积网络的模型学习人体非欧几里德数据的特征和内部规律,模拟关节的空间相互作用。尽管现有研究使用了多种方法对其进行改进,如人工构造的时空图卷积网络和结构化预测层[1,2]、自适应学习空间特征[3~5]等,但依旧存在以下问题:a)预测长期运动时容易收敛到一个静止的姿态即平均姿态;b)模型预测误差随时间推移累计,最终崩溃到不可信的状态。
对于问题a)来说,由于当前图卷积网络在提取特征过程中大多只注重相邻关节之间的连接性,没有充分考虑几何分离关节之间的隐性关系,容易导致平均姿态问题的产生。为了解决这个问题,Cui等人[6]利用两个参数化图卷积网络学习关节之间的动态关系,捕获关节之间的隐式关系。Liu等人[7]在其基础上提出捕获几何分离关节之间隐藏联系的图卷积网络和自适应学习的图卷积网络,利用优化的GCN学习运动序列的空间特征,可以缓解部分平均姿态问题。但使用GCN构建全局关系时,过度堆叠图卷积层会导致过平滑问题的发生,同时基于自回归的模型本身具有一定的限制。
针对问题b),文献[8,9]表明,人体运动预测过程中误差累积产生的主要原因是当前预测往往依赖于之前的时间步数据。文献[10]进一步证实由于自回归模型自身网络性能的限制,不可避免地涉及误差累积问题。为解决该问题,Li等人比较人体运动序列预测与非自回归机器翻译模型,并验证非自回归模型用于减少人体运动序列误差累积问题的可行性,提出一种多任务非自回归运动预测模型[9]。文献[11]将基于骨架的活动分类与非自回归模型进行结合,提出精度优于自回归方法且计算量更低的非自回归模型,进一步验证了非自回归模型对于降低误差累积的有效性。但基于非自回归的方法研究重点大多集中于全局时间关系建模,对于关节之间的相关性即空间特征提取考虑得不够充分。
针对上述目前研究工作中存在的问题,本文提出融合时空图卷积网络和非自回归模型(non-autoregressive combines spatio-temporal graphical convolutional network,NAS-GCN)的三维人体运动预测。考虑到非自回归模型对于全局提取能力较好,而对于人体运动序列的局部特征提取能力较差,因此在特征提取时先利用改进GCN的局部特征编码器,再结合非自回归模型对数据集进行全局特征提取与预测,使得模型对于空间特征提取进一步优化的同时减少误差累积的发生。同时为了解决时间表示方面的问题,提出将最终序列编码后输入解码器的策略,相对于自回归模型准确率更高,效率更快。
本文主要包括如下改进:a)提出改进的时空特征图卷积网络提取局部特征,充分考虑骨骼解剖学运动定律以减少平均姿态的发生,同时添加初始残差和恒等映射解決过平滑问题;b)利用非自回归模型代替自回归模型,将改进图卷积网络和非自回归的模型融合,提取人体运动的局部和全局特征。在更全面地考虑人体运动序列时空关系的同时进一步提升了模型对局部和全局特征的提取能力,从而减少误差累积问题的发生。具体来说,一方面提出了多层残差半约束图(multilayer residual semi constrained graph, MRSG)提取人体空间特征,该模型通过模拟骨骼解剖学的运动定律提取人体运动的空间结构,以减少人体骨骼之间歧义,其中GCN提取人体运动序列特征时,过多堆叠会限制GCN,从而导致过平滑问题,因此在模型中添加初始残差和恒等映射对过平滑问题进行一定的缓解;另一方面针对误差累积问题引入了非自回归模型,该模型用并行预测人体运动序列的方法解决了自回归模型解码串行输出的问题。
1 本文方法
本文提出NAS-GCN模型,由局部特征编码器(local feature encoder,LFE)、局部特征解码器(local feature decoder,LFD)和基于Transformer的非自回归编-解码器组成。其中局部特征编码器LFE、局部特征解码器LFD用于提取人体运动序列的局部特征,基于Transformer的非自回归编-解码器用于全局的特征提取。整体模型如图1所示。
1.1 局部特征提取
文献[12]提出当模型对于空间特征提取不够准确时,预测往往会收敛到平均姿态,因此为了更好地获取人体运动时各个关节之间的隐藏关系,提取人体运动序列的空间结构特征。本文提出LFE和LFD学习人体骨骼的空间相关性,以减少平均姿态问题的发生。
1.1.1 局部特征编码器(LFE)
局部特征编码器LFE由MRSG和TCN组成,该模型将输入数据分别利用MRSG和TCN进行局部空间特征、时间特征的提取,最后将提取到的空间特征和时间特征结合,得到人体运动序列的局部特征。
1)局部空间特征提取MRSG
MRSG的主要模块为GCNadd,用来提取局部空间特征,减少由于过度堆叠GCNadd带来的过平滑问题,其中GCNadd为优化后的GCN。GCN可以提取人体骨骼之间的关系,学习骨骼关节对之间的连接,但是该方法对人体隐藏关系的提取能力较差,例如打电话时上半身的变化可能比下半身更加丰富,走路时更加注重腿部和手臂的协调性等。因此本文提出MRSG模型模拟骨骼解剖学的运动定律,提取人体运动的空间结构,减少人体骨骼之间歧义,以提高预测人体骨骼空间相关性。
2 实验结果与分析
2.1 实验设置
实验使用RTX2080Ti GPU,Linux操作系统,PyTorch深度学习框架。训练学习率为10-4,批量大小为16。在预训练过程中,学习率从0逐渐增加到10-4,从而提高了训练的稳定性。模型采用50帧,输出25帧的1 s运动。实验设置epochs为400,steps_per_epoch为200,num_heads为8,dim_ffn为2 048。编码器输入前需要对数据进行归一化操作,使得数据更加稳定。
本文使用Human3.6 M的数据集进行人体运动预测。该数据集遵循了训练和测试的标准协议。该数据库采用三维的骨骼模型对人体运动序列进行表示,且一个三维姿态由32个三维坐标组成,相当于一个96维的矢量。其中训练集5用于测试,其他训练集用于训练。输入序列长为2 s,对预测序列的前1 000 ms进行测试。通过计算预测和真实值之间的欧拉角误差评估序列。在训练过程中,模型采用MRSG提取空间特征,TCN提取时间特征,将两者融合后,利用非自回归模型对全局特征进行提取,最后得出预测的人体运动序列。
为了验证NAS-GCN,本文根据式(12)计算损失函数,并与其他模型进行对比,预测平均角度误差MAE,MAE是角度空间产生的预测与真实值直接的平均距离损失,该值越低表示数据越好。
2.2 消融实验
本节在Human3.6M数据集中验证了不同类型LFE的效果。提出利用LFE和LFD进行人体运动序列的局部特征提取,用MRSG层、TCN层或MLP层对LFE、LFD进行实验。不同类型的局部特征提取的平均值如表1所示,后缀enc表示解码器LFD为MLP,后缀full表示解码器LFD为MRSG。
经过实验发现,利用gcntcn_full进行局部特征提取,即当LFE由MRSG与TCN组成时,MAE值更加精确。综上所述,局部空间编码器中利用MRSG可以有效避免出现过拟合的情况,进一步提高了数据精度。
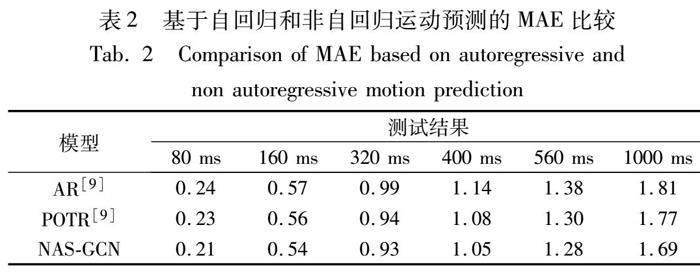
2.3 与自回归方法的比较
为了验证NAS-GCN非自回归模型在长期预测的效果,表2显示了本模型与自回归模型测试结果的对比。其中局部特征提取与POTR网络的实验参数同文献[9]。从表中数据可以观察到,MAE值有明显的降低,其中1 000 ms的长期预测比原模型[9]的MAE降低了约4.52%。自回归版本不使用查询姿态,而是根据前一次的结果预测一个运动向量。本文的非自回归方法在大多数时间间隔内显示出比同类方法更低的MAE,具体数据如表2所示。
2.4 与其他模型比较
表3比较了NAS-GCN模型与其他网络在H3.6M数据集中11个活动的误差。加粗表示最好数据,下画线其次。对于每个数据,从上到下分别展示了ZeroV[7]、Res-sup[7]、POTR[9]、ST-Transformer[11]、Skel-TNet[17]、DCT-GCN[18]等先进方法与当前NAS-GCN的预测,非自回归模型在短期内获得第一和第二个较低的MAE,并且在80 ms内最低,同时与从前的非自回归模型相比,在长期内误差有了很明显的降低。使用最后一个输入序列作为查询姿态减少误差累积,且该方法在长期预测方面也取得了较大的进步。
图5对预测动作MAE进行比较,主要包括directions、ea-ting、taking photo与greeting四個动作,其中灰色为ground truth,第三行为NAS-GCN的数据,在精确度上有了很大的提高。根据图片发现,POTR的eating动作没有充分考虑上半身的变化,左臂应该是平稳向下的,因此使用NAS-GCN效果更好;POTR的taking photo动作集中在左臂,与真实动作相反,而NAS-GCN集中于右臂的变化;POTR的greeting动作出现了平均姿态问题,而NAS-GCN注意到了左腿相应的变化并作出改变。综上,相比于POTR网络,NAS-GCN更加接近真实动作,网络改善效果比较明显。
3 结束语
NAS-GCN模型用于人体运动预测,首先通过人体运动序列局部特征提取的编码器LFE、LFD提取局部时空特征;然后,引入非自回归模型提取全局特征并进行人体运动序列的预测。其中LFE由MRSG和TCN组成,该方法可以降低人体骨骼特征提取不准确引起的平均姿态问题和过度堆叠引起的过平滑问题,提高预测精确度。非自回归模型有助于降低误差累积。虽然当前预测减少了平均姿态的出现频率,但在长期范围内序列依然存在平均姿态问题,下一步将研究优化查询序列的过程,同时针对多人和更复杂的环境进行人体运动预测,以提高研究的全面性。
参考文献:
[1]Jain A,Zamir A R,Savarese S,et al. Structural-RNN: deep learning on spatio-temporal graphs [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2016: 5308-5317.
[2]Aksan E,Kaufmann M,Hilliges O. Structured prediction helps 3D human motion modelling [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2019: 7144-7153.
[3]Mao Wei,Liu Miaomiao,Salzmann M,et al. Learning trajectory dependencies for human motion prediction [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2019: 9489-9497.
[4]Li Maosen,Chen Siheng,Zhao Yangheng,et al. Dynamic multiscale graph neural networks for 3D skeleton based human motion prediction [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2020: 214-223.
[5]Li Maosen,Chen Siheng,Zhao Yangheng,et al. Multiscale spatio-temporal graph neural networks for 3D skeleton-based motion prediction[J]. IEEE Trans on Image Processing,2021,30(23): 7760-7775.
[6]Cui Qiongjie,Sun Huaijiang,Yang Fei. Learning dynamic relationships for 3D human motion prediction [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2020: 6519-6527.
[7]Liu Zhenguang,Su Pengxiang,Wu Shuang,et al. Motion prediction using trajectory cues [C]// Proc of IEEE/CVF International Confe-rence on Computer Vision. Piscataway,NJ: IEEE Press,2021: 13299-13308.
[8]Martinez J,Black M J,Romero J. On human motion prediction using recurrent neural networks [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2017: 2891-2900.
[9]Martínez-González A,Villamizar M,Odobez J M. Pose Transformers (POTR):human motion prediction with non-autoregressive Transfor-mers [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2021: 2276-2284.
[10]Li Bin,Tian Jian,Zhang Zhongfei,et al. Multitask non-autoregressive model for human motion prediction [J]. IEEE Trans on Image Processing,2020,30(8): 2562-2574.
[11]Aksan E,Kaufmann M,Cao Peng,et al. A spatio-temporal Transfor-mer for 3D human motion prediction [C]// Proc of International Con-ference on 3D Vision. Piscataway,NJ: IEEE Press,2021: 565-574.
[12]Wang He,Ho E S L,Shum H P H,et al. Spatio-temporal manifold learning for human motions via long-horizon modeling[J].IEEE Trans on Visualization and Computer Graphics,2019,27(1): 216-227.
[13]Chen Ming,Wei Zhewei,Huang Zengfeng,et al. Simple and deep graph convolutional networks [C]// Proc of International Conference on Machine Learning. [S.l.]:PMLR,2020: 1725-1735.
[14]何冰倩,魏维,张斌. 基于深度学习的轻量型人体动作识别模型 [J]. 计算机应用研究,2020,37(8): 2547-2551. (He Bingqian,Wei Wei,Zhang Bin. Lightweight human action recognition model based on deep learning [J]. Application Research of Computers,2020,37(8): 2547-2551.)
[15]Bai Shaojie,Kolter J Z,Koltun V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling [EB/OL]. (2018-04-19). https://arxiv. org/abs/1803. 01271.
[16]戴俊明,曹陽,沈琴琴,等. 基于多时空图卷积网络的交通流预测 [J]. 计算机应用研究,2022,39(3): 780-784. (Dai Junming,Cao Yang,Shen Qinqin,et al. Traffic flow prediction based on multi-temporal graph convolutional networks [J]. Application Research of Computers,2022,39(3): 780-784.)
[17]Guo Xiao,Choi J. Human motion prediction via learning local structure representations and temporal dependencies [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2019: 2580-2587.
[18]Mao Wei,Liu Miaomiao,Salzmann M. History repeats itself: human motion prediction via motion attention [C]// Proc of the 16th European Conference on Computer Vision.Berlin:Springer,2020:474-489.
