
预指导的多阶段特征融合的图像语义分割网络
2024-05-24 03:32王燕范向辉王丽康
计算机应用研究 2024年3期
王燕 范向辉 王丽康


摘 要:
针对目前语义分割对图像边缘和小物体不能进行精确识别,以及简单融合多阶段特征会造成信息冗余、混杂不清等问题,提出了一个预指导的多阶段特征融合的网络(pre-guidanced multi-stage feature fusion network,PGMFFNet),PGMFFNet采用编解码器结构,编码阶段利用预指导模块对各阶段信息进行指导,增强各阶段特征之间的联系,解决各阶段特征在后续融合过程中产生的语义混杂问题。在解码阶段,利用多路径金字塔上采样模块融合高级语义特征,然后使用改进的密集空洞空间金字塔池化模块对融合后的特征进一步扩大感受野,最后将高低层次的特征信息融合,使得对小物体的分割效果更优。PGMFFNet在CityScapes公开数据集上进行了验证,得到了78.38%的平均交并比(mean intersection over union,MIoU),分割效果较好。
关键词:语义分割;编解码器;预指导;金字塔;特征融合
中图分类号:TP391.41 文献标志码:A 文章编号:1001-3695(2024)03-047-0951-05doi: 10.19734/j.issn.1001-3695.2023.07.0302
Image semantic segmentation network of pre-guidanced multi-stage feature fusion
Wang Yan, Fan Xianghui, Wang Likang
(School of Computer & Communication, Lanzhou University of Technology, Lanzhou 730050, China)
Abstract:
In view of the current semantic segmentation can not accurately identify image edges and small objects, and simple fusion of multi-stage features will cause information redundancy, confusion and other problems, this paper proposed a pre-guidanced multi-stage feature fusion network (PGMFFNet). PGMFFNet employed a encoder-decoder structure, at the encoder stage, which used a pre-guidance module to guide the information in each stage. Strengthened the relationship between the features of each stage, and solved the semantic confounding problems in the subsequent fusion process of the features of each stage. At the decoder stage, which used the multi-path up-pyramid sampling module to fuse high-level semantic features, and then used the improved dense void space pyramid pool module to further expand the sensory field of the fused features, and finally fused the feature information of high and low levels to make the segmentation effect of small objects better. This paper verified PGMFFNet on CityScapes open data set, and the mean intersection over union (MIoU) obtained to 78.38%, showing good segmentation effect. Key words:semantic segmentation; encoder-decoder; pre-guidance; pyramid; feature fusion
0 引言
图像语义分割是计算机视觉领域重要的任务之一[1],其主要目的是对输入的图像进行逐像素密度预测,然后为每一个像素分配一个语义标签[2]。图像语义分割在日常生活中应用广泛。例如,在自动驾驶[3]领域,汽车必须能够实时地对行驶过程中出现的各种事物作出具体的解析,然后根据不同場景,作出不同的反应。在医疗领域[4],图像语义分割能够辅助医生对患者进行治疗。近年来,卷积神经网络(CNN)发展迅速,在计算机视觉中取得了极大的成功[5]。随着2015年,Long等人[6]提出全卷积神经网络FCN,各种基于全卷积神经网络的架构广泛应用到语义分割领域当中。
目前,图像语义分割存在以下问题:a)对于体积较小、形状相似的物体分割效果不好,比如图像中存在的路灯灯杆以及远处的路灯,往往会被忽略,或者分割形状不完整,对于处在道路旁边,距离较远的人行道往往会被分割为道路;b)光照、以及其他物体的影子遮挡等也会对分割产生一定的影响,导致分割错误。
出现上述问题的原因主要有两个:a)未能提取丰富的特征信息;b)对提取的图像特征信息利用不够充分。针对以上问题,目前的语义分割有以下几种研究趋势:
a)采用基于编解码器架构的方法。编码阶段不断地加深卷积层次提取更多的特征信息,解码阶段对编码阶段的高级语义信息进行解码,并逐渐恢复边界信息。U-Net[7]采用U型结构、跳跃连接来恢复原图像信息。SPGNet[8]通过在多级编解码架构中加入语义预测,重新加权局部特征以提高分割精度。ESegNet[9]在编码阶段下采样到更深层次来获取更大的接收域和特征空间,在解码阶段采取更先进的BiFPN来聚合各阶段的特征信息。FFNet[10]极简的编解码结构上,通过对编码阶段进行微调,从而获得更大的感受野。
b)利用上下文来捕获长期依赖关系。Chen等人[11]提出了DeepLab,并在该网络中提出了空洞空间金字塔池化模块,该模块使用几个包含不同空洞率的并行分支和平均池化生成了不同尺度的特征信息。姚燕等人[12]基于改进 DeepLabV3+网络的轻量级语义分割算法,使用MobileNetv3降低模型复杂度,并引入注意力机制模块和组归一化方法,提升分割精度。Zhao等人[13]提出了PSPNet,该网络引入了金字塔池化模块,使用不同大小的池化模块生成不同区域的特征图,用于全局信息聚合。DenseASPP[14]采用密集连接的空洞卷积模块生成更为密集的多尺度特征信息。EncNet[15]将语义上下文编码到网络中,并强调类依赖。OCNet[16]提出新的对象上下文聚合方法来增强对象信息,以此获得更丰富的全局上下文信息。
c)利用注意力机制来增强通道或空间之间的联系。注意力机制的原理类似人眼机制,通过加强各特征通道之间或空间的联系,使得网络能够关注有用的信息,忽略无效信息,从而进一步提高网络的分割精度。SENet[17]中提出了挤压-激励模块,在挤压阶段顺着空间维度来进行通道压缩,在激励阶段通过参数来为每个通道生成权重,显示建模通道间的相关性。ECA-Net[18]是对SENet的一种改进,它避免了SENet中的降维操作,减少了降维会对通道注意力预测产生的消极影响,进一步提高了通道注意力的预测能力。郑鹏营等人[19]提出了一种基于空间特征提取和注意力机制的双路径语义分割算法,在引入空间特征提取模块的基础上,采用了一条结合双阶通道注意力的语义上下文进行特征提取,降低了精度损失。
上述各种方法虽然在一定程度上解决了语义分割的挑战,提高了分割精度,但有些方法只使用单一阶段的特征信息,未能充分利用其他各阶段的特征信息,有些方法虽然融合了多阶段特征,却对各阶段特征之间的联系处理不够,造成了后续融合阶段的信息冗余、混乱,使得有些像素信息会被抛弃,从而不能对图像的边缘以及小物体进行精确识别。因此,本文提出了预指导的多阶段特征融合网络PGMMFNet,以增强各阶段特征之间的联系和充分利用各阶段特征信息为原则,通过预指导模块对编码阶段产生的不同阶段特征进行指导,强化各阶段特征之间的联系,解决了后续融合过程中产生的信息冗余、混杂问题,并在解码过程中扩大感受野,利用多阶段的特征信息保留图像的边界以及深层次高级语义信息,可以更好地解决上述问题,实现精确分割。
本文的贡献如下:
a)提出预指导的多阶段特征融合网络PGMMFNet,通过PGM对编码阶段输出的不同层次的特征进行指导,强化各阶段特征之间的关联,更好地解决后续融合过程中产生的信息冗余、混杂问题;
b)提出多路径金字塔上采样模块MPUM(multi-path pyramid upsample module)以减少高级阶段特征融合过程中的信息丢失,使用改进的密集连接空洞空间金字塔池化模块DCASPPM(dense connect atrous spatial pyramid pooling module)扩大感受野,最后将高低层次的特征信息融合,获取更丰富的全局上下文信息;
c)在公开的数据集CityScapes[20]上进行了大量的实验,验证了PGMFFNet的有效性,并且与经典网络以及近两年的先进模型进行了对比。
1 模型结构
PGMFFNet的整体架构如图1所示,整个架构采用编码器。编码阶段采用预训练的ResNet101作为骨干网络,为了对骨干网络最后一个阶段的输出同样使用PGM指导,本文在其后面使用了3层kernel为3,stride为2的卷积,将其称为Res-7。将骨干网络各相邻阶段的输出送入PGM,利用相邻阶段之间的关联性以及高层次特征包含更多的语义信息来进行指导,使包含边缘、轮廓的低级语义信息更加细化,语义之间关联性更强。解码部分由MPUM和DCASPPM组成。MPUM对高层次特征部分进行融合,并采用多路径的方式减少融合过程中造成的信息丢失,DCASPPM对融合的高层次特征扩大感受野,提取更多的图像特征信息。使用多阶段特征融合策略将不同层次的特征进行融合,并使用ECA(efficient channel attention)模块优化融合后通道之间的关系,最后通过双线性上采样恢复至原始分辨率。
2.2 实验环境及参数
本文实验采用RTX 3090、24 GB的运行环境,程序是在Python3.8的PyTorch 1.8框架下编写。CityScapes数据集上的实验所采用的基础学习率base_lr大小為0.004,具体大小根据lr=base_lr/16×batch_size进行计算。优化函数采用随机梯度下降法(stochastic gradient descent,SGD),其中momentum为0.9,权重衰减weight_decay为1E-4,损失函数使用交叉熵损失函数,学习率调整策略采用poly策略,具体计算为lr=lr0×(1-iter/max_iter)0.9,其中lr0为具体使用的初始学习率,iter为当前的迭代次数,max_iter为最大的迭代次数。数据的增强策略方面,在训练过程中本文采用随机裁剪、0.5~2.0的随机缩放以及随机水平翻转等策略。具体的参数配置如表1所示。
2.3 CityScapes数据集消融实验
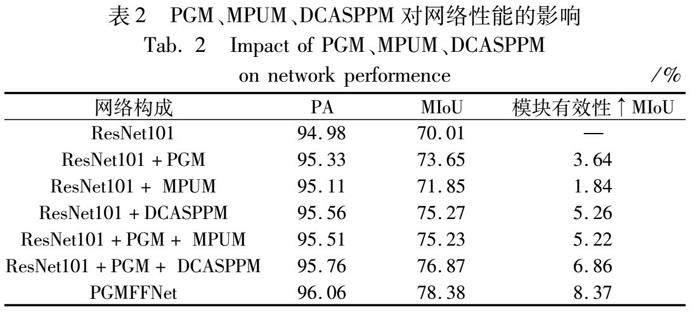
为了验证PGMFFNet中各模块的有效性,本文在CityScapes数据集上进行消融实验,各模块的消融实验结果如表2所示。PGMFFNet以预训练的ResNet101为基准网络,然后将各模块与ResNet101进行结合,设计一系列消融实验来验证各模块的有效性。↑MIoU表示与基准网络的MIoU值相比,所上升的值大小。
通过表2的结果可以看到,在只有ResNet101基准网络时MIoU值为70.01%,加入PGM对基准网络的输出进行指导优化后的MIoU值为73.65%,上升了3.64%,MIoU值的提高是PGM的指导增强了各阶段之间的联系,减少了信息冗余;加入MPUM时,MIoU上升了1.84%,加入DCASPPM时,MIoU上升了5.26%,较多的MIoU值的上升是因为DCASPPM采用了并联的递进式大空洞率,进一步扩大了高级语义特征的感受野,以此可以看出加入各模块后,对基准网络的性能有显著的提升。消融实验部分的可视化结果如图5所示,框选部分为重点关注区域。从框选中的人的轮廓等可以看出,在只有ResNet101的时候,人的轮廓很不明显,在加入PGM和DCASPPM以后,轮廓基本能够看清楚,但在某些躯干部位有些模糊,在各模块都加入以后,轮廓清晰,躯干部分也有改进,并且在远方景物还有道路与道路边草丛的细节处,都可以看到基准网络和加入各模块之后的对比效果,改进效果明显。
2.4 CityScapes数据集实验结果分析
CityScapes验证集上进行了ResNet50和ResNet101不同主干的对比,输入图像训练期间分辨率为768×768,验证采用2 048×1 024的大小,由对比结果选择了较优的ResNet101为主干,对比的结果如表3所示。
将PGMFFNet在CityScapes验证集上与经典的以及最近较先进的网络进行了对比实验,结果如表4所示。
由MIoU值可以看出,经典网络DeepLabV3+,以及先进网络CCNet、SPFNet比PGMFFNet相差两到三个百分点。造成此差距的原因是上述三种网络重点处理的是骨干网络输出的最后一个阶段的特征,对包含图像边缘、轮廓等细节信息的第一阶段的特征处理不够,所以分割的图像边缘等细节信息不够清楚,也造成最后的分割MIoU值较低,而PGMFFNet使用PGM对骨干网络相邻阶段特征进行了指导,增强了各阶段特征之间的联系,弥补了细节处理不够的问题,并使用DCASPPM进一步扩大感受野,获得了丰富的语义特征信息,因此最后的分割效果较好,MIoU较高。PGMFFNet与部分对比网络在CityScapes数据集上的分割如图6所示,白色边框选中的是重点关注区域。
从图中可以看到,DeepLabV3+分割出的交通标志边缘形状不清晰,OCNet对路上行人的身体轮廓分割无法辨认,CCNet、SPFNet相较于DeepLabV3+、OCNet分割的交通标志边缘形状已大致清晰,但不够完整;在远处景物分割方面,OCNet无法识别远处的灯杆等小物体,SPFNet、CCNet虽然在一定程度上识别了灯杆,但破损处很多,而PGMFFNet对交通标志、行人轮廓,以及远处的灯杆等识别较为清晰、完整。造成此差距的原因是对比网络获取的上下文信息不完整、联系不够紧密,而PGMFFNet对基准网络的各个输出阶段进行了精细化处理,增强了不同层级之间的像素联系,并且使用MPUM减少了高级语义各阶段特征融合过程中的漏采,在融合之后,使用DCASPPM扩大了整体的感受野,使得分割出来的物体边缘形状较为完整,整体轮廓更为清晰,效果更好。
3 结束语
本文提出了预指导的多阶段特征融合的图像语义分割网络PGMFFNet,针对骨干网络各个阶段的输出,设计了PGM对各阶段输出进行指导,增强了不同阶段之间的像素语义关系,解决了后续融合阶段产生的语义冗余、混杂问题,使用MPUM将各高级阶段的语义特征进行融合,并且采用多路径金字塔上采样模块对融合后的特征尽可能地提取较多的语义信息,DCASPPM采用密集连接的空洞卷积扩大了感受野,获得了较为丰富的不同尺度的语义特征,最后融合了高层以及低层的语义信息,增强了分割效果。PGMFFNet在CityScapes公开数据集上的平均交并比达到了78.38%,分割的物体边缘完整,轮廓清晰,整體效果较好,与经典网络以及当前较为先进的网络进行对比,分割结果也占有明显的优势。在后续的工作中,将进一步优化模型结构,在减少参数量的基础上得到更好的分割精度。
参考文献:
[1]张鑫,姚庆安,赵健,等. 全卷积神经网络图像语义分割方法综述 [J]. 计算机工程与应用,2022,58(8): 45-57. (Zhang Xin,Yao Qingan,Zhao Jian,et al. A review of image semantic segmentation methods by full convolutional neural networks [J]. Computer Engineering and Applications,2022,58(8): 45-57.)
[2]Mo Yujian,Wu Yan,Yang Xinneng,et al. Review the state-of-the-art technologies of semantic segmentation based on deep learning [J]. Neurocomputing,2022,493: 626-646.
[3]Rizzoli G,Barbato F,Zanuttigh P. Multimodal semantic segmentation in autonomous driving: a review of current approaches and future perspectives [J]. Technologies,2022,10(4): 90-96.
[4]Jha D,Riegler M A,Johansen D,et al. DoubleU-Net: a deep convolutional neural network for medical image segmentation [C]// Proc of the 33rd IEEE International Symposium on Computer-Based Medical Systems. Piscataway,NJ: IEEE Press,2020: 558-564.
[5]Wang Wenhai,Xie Enze,Li Xiang,et al. Pyramid vision Transformer: a versatile backbone for dense prediction without convolutions [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2021: 568-578.
[6]Long J,Shelhamer E,Darrell T. Fully convolutional networks for semantic segmentation [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2015:3431-3440.
[7]Ronneberger O,Fischer P,Brox T. U-Net: convolutional networks for biomedical image segmentation [C]// Proc of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer,2015: 234-241.
[8]Cheng Bowen,Chen L C,Wei Yunchao,et al. SPGNet: semantic prediction guidance for scene parsing [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2019: 5218-5228.
[9]Meng Tianjian,Ghiasi G,Mahjorian R,et al. Revisiting multi-scale feature fusion for semantic segmentation [EB/OL].
(2022-03-23). https://arxiv.org/abs/2203.12683.
[10]Mehta D,Skliar A,Ben Y H,et al. Simple and efficient architectures for semantic segmentation [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2022: 2628-2636.
[11]Chen L C,Zhu Yukun,Papandreou G,et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// Proc of European Conference on Computer Vision. Cham: Springer,2018: 801-818.
[12]姚燕,胡立坤,郭軍. 基于改进 DeepLabV3+网络的轻量级语义分割算法 [J]. 激光与光电子学进展,2022,59(4): 100-107. (Yao Yan,Hu Likun,Guo Jun. Lightweight semantic segmentation algorithm based on improved DeepLabV3+ network [J]. Advances in Laser and Optoelectronics,2022,59(4): 100-107.)
[13]Zhao Hengshuang,Shi Jianping,Qi Xiaojuan,et al. Pyramid scene parsing network [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2017:2881-2890.
[14]Yang Maoke,Yu Kun,Zhang Chi,et al. DenseASPP for semantic segmentation in street scenes [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2018: 3684-3692.
[15]Zhang Hang,Dana K,Shi Jianping,et al. Context encoding for semantic segmentation [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2018:7151-7160.
[16]Yuan Yuhui,Huang Lang,Guo Jianyuan,et al. OCNet: object context for semantic segmentation [J]. International Journal of Computer Vision,2021,129(8): 2375-2398.
[17]Hu Jie,Shen Li,Sun Gang. Squeeze-and-excitation networks [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2018: 7132-7141.
[18]Wang Qilong,Wu Banggu,Zhu Pengfei,et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2020: 11534-11542.
[19]鄭鹏营,陈玮,尹钟. 基于空间特征提取和注意力机制双路径语义分割算法 [J]. 计算机应用研究,2022,39(2): 613-617. (Zheng Pengying,Chen Wei,Yin Zhong. Dual path semantic segmentation algorithm based on spatial feature extraction and attention mecha-nism[J].Application Research of Computers,2022,39(2):613-617.)
[20]Cordts M,Omran M,Ramos S,et al. The CityScapes dataset for semantic urban scene understanding [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2016: 3213-3223.
[21]Huang Zilong,Wang Xinggang,Huang Lichao,et al. CCNet: criss-cross attention for semantic segmentation [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2019: 603-612.
[22]Zhao Hengshuang,Qi Xiaojuan,Shen Xiaoyong,et al. ICNet for real-time semantic segmentation on high-resolution images[C]// Proc of European Conference on Computer Vision.Berlin:Springer,2018:405-420.
[23]Yu Changqian,Wang Jingbo,Peng Chao,et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation [C]// Proc of European Conference on Computer Vision.Berlin:Springer,2018:325-341.
[24]Elhassan M A M,Yang Chunming,Huang Chenxi,et al. SPFNet: subspace pyramid fusion network for semantic segmentation [EB/OL].(2022-04-04). https://arxiv.org/abs/2204.01278.
猜你喜欢
数学小灵通(1-2年级)(2024年4期)2024-05-14
环球时报(2022-09-19)2022-09-19
Contemporary Social Sciences(2021年5期)2021-11-22
小猕猴智力画刊(2020年5期)2020-06-01
少儿美术(快乐历史地理)(2019年2期)2019-06-12
软件导刊(2017年7期)2017-09-05
无线互联科技(2017年12期)2017-07-18
科技资讯(2017年11期)2017-06-09
童话世界(2017年11期)2017-05-17
电子技术与软件工程(2017年5期)2017-04-23
