
基于静脉关键特征和AdaFace损失的轻量级指静脉识别算法
2024-05-24 02:52刘润基王一丁
计算机应用研究 2024年3期
刘润基 王一丁
摘 要:
基于深度学习的指静脉识别方法通常需要大量的计算资源,限制了其在嵌入设备上的推广和普及,采用轻量级网络又面臨模型参数减少导致准确率下降的问题,为此提出一种基于指静脉关键特征和AdaFace损失的轻量级识别算法。在MicroNet框架中,首先提出一种FMixconv卷积来替代原网络中的深度卷积,减少参数的同时可以获得静脉特征的多尺度信息;其次引入轻量级注意力模块CA模块,从空间和通道上聚焦于静脉特征的关键信息;最后在损失函数中加入AdaFace损失,通过特征范数对图像质量进行评价,以减少图像质量下降对训练的影响。该算法在SDUMLA-HMT、FV-USM和自建数据集上的识别准确率达到99.84%、99.39%和99.42%,而参数量仅有0.82 M。实验结果表明,该算法在准确率和参数量大小上均领先于其他方法。
关键词:指静脉识别;轻量级网络;MicroNet;AdaFace损失
中图分类号:TP391.41 文献标志码:A 文章编号:1001-3695(2024)03-044-0933-06doi: 10.19734/j.issn.1001-3695.2023.06.0304
Research on lightweight recognition algorithm based on key features of finger vein and AdaFace loss
Liu Runji, Wang Yiding
(School of Information, North China University of Technology, Beijing 100144, China)
Abstract:
Finger vein recognition methods based on deep learning usually require a large amount of computing resources, it limits their promotion and popularization on embedded devices. The adoption of lightweight network faces the problem of decreasing accuracy due to the reduction of model parameters. Therefore, this paper proposed a lightweight recognition algorithm based on key features of finger vein and AdaFace loss. In the MicroNet network framework, firstly, this paper proposed FMixconv convolution to replace the deep convolution in the original network, which could obtain multi-scale information of vein features while reducing parameters. Secondly, the method used a lightweight attention module, CA module, to focus on key information of venous characteristics from space and channel. Finally, the algorithm added AdaFace loss into the loss function, through the characteristics of the norm to evaluate image quality, to reduce the impact of image quality degradation on training. The recognition accuracy of the proposed algorithm on SDUMLA-HMT, FV-USM and self-built datasets reached 99.84%, 99.39% and 99.42%, while the number of parameters was only 0.82 M. Experimental results show that the proposed network is ahead of other methods in accuracy and parameter size. Key words:finger vein recognition; lightweight network; MicroNet; AdaFace loss
0 引言
随着现代科技的不断发展,人们对身份安全信息愈发看重。生物特征识别作为身份认证技术的一种解决方案,典型代表有人脸识别、指纹识别、虹膜识别和静脉识别等。而指静脉识别作为新一代的生物特征识别技术,与人脸、指纹等其他生物特征相比,具有活体识别、皮下特征不可复制、特征唯一、识别稳定、无法造假等优势,是人工智能时代十分安全精确的生物识别技术之一。
日本科研者Kono在2000年首次成功地将指静脉识别用于身份认证[1]。自此,指静脉识别技术迅速发展,取得了大量的成果。对于指静脉识别来说,提取准确鲁棒的特征是指静脉识别的关键。2015年之前,指静脉识别的方法被称之为传统方法。传统方法主要以图像处理、统计学等方法来提取指静脉特征,并与分类方法相结合,进行识别。这些方法大多都存在着计算复杂、识别效率较低、识别不够鲁棒等问题。
2015年之后,随着深度学习的发展,以及其在计算机视觉领域取得的成果,大量学者开始将深度学习用于指静脉识别之中,依靠传统方法提取指静脉特征的方法被深度学习方法所取代。Yeh等人[2]使用Cutout方法进行数据增广,将处理后的图片送入ResNeXt-101中。Huang等人[3]在ResNet-50的基础上,与基于U-Net的空间注意机制相结合,改进设计了一种指静脉分类CNN模型。Li等人[4]为了让网络更加注重指静脉的纹理特征,先将指静脉图像分块,再送入ViT模型与胶囊网络相结合的网络之中。戴坤龙[5]在ResNet的基础上加入注意力机制,并与度量学习相结合,有效地提高了识别性能。
基于深度学习的方法基本都是以追求提升识别精确率为主要目的,采用的技术手段主要包括加深网络结构和增强卷积模块特征提取功能等,这通常需要复杂的网络模型结构,对硬件设备的计算能力要求较高,需要的内存也大大增加。为解决这个问题,许多学者提出了不同的轻量级网络。2016年,Iandola等人[6]提出了SqueezeNet,采用1×1卷积对上一层特征图进行降维,在准确度几乎与AlexNet一样的情况下,参数量少。2017年谷歌提出了MobileNet[7], 将普通卷积分解成Deepthwise(DW卷积)和Pointwise(PW),两者组合成深度可分离卷积,极大地减少了网络的参数量。同年,ShuffleNet[8]使用逐点组卷积降低逐点卷积的复杂度,同时通过channle shuffle改善跨通道卷积的信息流通。2020年,华为设计了Ghost模块,通过cheap operation以较小的计算量生成了更多的特征图,并以此为基础提出了GhostNet[9]。2021年,微软设计了micro-factorized convolution和dynamic shift max激活函数,并基于这两个操作,提出了MicroNet[10],以极低的计算成本解决了当参数极小时,网络性能大幅下降的问题。
受到上述工作的启发,许多工作者开始研究如何在保持较高指静脉识别准确率的前提下精简网络结构,使其能够部署到嵌入式开发板上。Shaheed等人[11]提出了一种基于深度可分离卷积的神经网络的预训练Xception模型用于指静脉识别。Ren等人[12]基于MobileNetV3,将深度可分离卷积、倒残差结构和网络搜索技术相结合,设计了一个轻量级的多模态特征融合网络 FPV-Net。牟家乐等人[13]在网络中引用教师-学生网络模式,对网络进行知识蒸馏,在保持较少参数量的情况下提高了识别的准确率。Zhao等人[14]提出了一个轻量级的CNN, 全连接层输出的特征向量长度为200,将softmax 损失与中心损失相结合。
以上方法大多都是结合指静脉数据集样本数量较少的特点,自己搭建小型网络或者对经典网络进行压缩,难以保证较高的识别准确率。因此,设计一种能够平衡识别准确率和网络大小的指静脉识别网络至关重要。为此,本文提出一种基于指静脉关键特征和AdaFace损失的轻量级识别算法,相关工作包括:a)指静脉感兴趣区域提取;b)以MicroNet-M0作为基础网络,使用低秩分解后的MixConv[15]代替深度卷积,使网络能够提取到静脉图像的多尺度特征;c)引入轻量级注意力模块CA模块[16],在几乎可以忽略参数量的情况下,提高网络在跨空间和跨通道上对指静脉纹理的注意力;d)采用AdaFace损失与SoftTargetCrossEntropy损失相结合的方法,在减少静脉缺失图像对训练影响的同时,减少类内距离,增大类间距离;e)将本文算法部署在嵌入式平台,并与其他模型相比较。
1 MicroNet
在指静脉图像采集时,由于手指错位、光线变换等影响,采取到的图片质量参差不齐,指静脉血管与背景噪声区分不明显,需要选择提取特征能力较强的神经网络。同时考虑到指静脉数据集图像数量较少的情况,采用复杂网络虽然提取特征能力较强,但是参数量较大,容易过拟合,而且后续的模型部署较为困难。MicroNet结构简单,特征提取能力较强,解决了当参数量极少时,网络性能大幅下降的问题,适合部署在嵌入式开发板上。因此,本文采用MicroNet作为基础网络。
MicroNet作为一种轻量级网络,其使用micro-factorized convolution(MF-Dconv),通过低秩分解将深度卷积分解成数个小卷积,在减少网络通道数的同时,使输入输出中特征图包含的信息损失较小,并使用dynamic shift-max(DY-Shift-Max)作为激活函数。DY-Shift-Max是一种动态激活函数,它可以在提升非线性表达的同时,使用动态的组间特征融合增加节点的连接性,尽量降低网络深度减少对性能产生的影响。
MicroNet是由多个micro-block组成的,里面均包含了DY-Shift-Max作为激活函数。micro-block又分为block-A、block-B、block-C,结构如图1所示。
MicroNet-M0的網络框架分为8个模块。第1个模块是stem层,用于缩小图片尺寸,由两个卷积层构成,其大小分别为3×1和1×3。第2和第3个模块是由block-A构成。第4个模块由block-B构成。第5~7个模块是由block-C构成。而第8个模块是由平均池化层和全连接层组成。MicroNet-M1~M3的网络结构是在三种micro-block的基础上设计,并修改特征层通道数、卷积分组数。由于MicroNet具有四种结构,为了选取最优结构作为指静脉识别的基础网络,将提取的ROI图像原图作为网络的输入图像进行实验。实验结果如表1所示。经过对比,M0参数量最小,而准确率最高,因此选择M0作为基础网络。
2 MicroNet-M0基础网络的改进
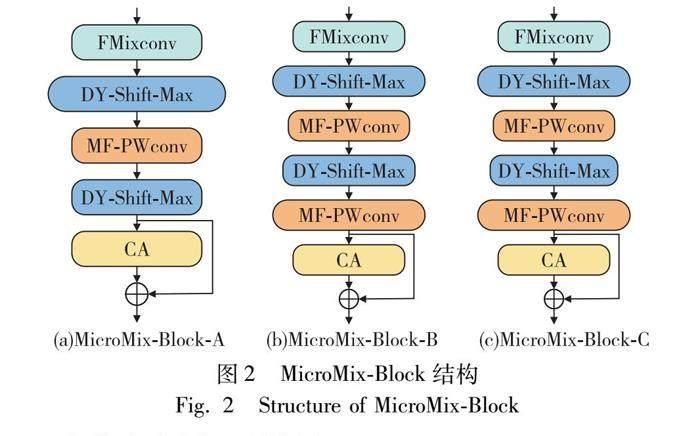
本文旨在保证网络模型轻量的前提下,加强网络对于指静脉特征的提取能力,保证指静脉识别的准确率。首先,将数据集图像经过感兴趣区域提取,分为训练集和测试集,并进行数据增强。然后,使用低秩分解后的MixConv卷积替代原网络中的深度卷积。同时,在每个block末端加入CA模块以提高网络在跨空间和跨通道上对指静脉纹理的注意力。两者均为获取指静脉的关键特征,并与MicroNet组成新的block,即MicroMix-Block,如图2所示。
以此为基础设计了一种改进的MicroNet-M0网络,即MicroMixNet,如图3所示。将训练集送入MicroMixNet中训练,得到512维的特征向量,将其送入AdaFace损失函数中优化特征向量之间的距离,最后计算特征向量之间的距离,进行分类匹配。区别于其他的目标识别,MicroMixnet在新增类别时,只需要采集新图像送入网络进行特征提取后存入库中,而不需要重新训练,极大满足了实际运用场景的需要。
2.1 指静脉感兴趣区域提取
指静脉图像蕴涵着大量的背景噪声,而且手指位置存在平移或旋转的情况。根据图3,第一部分需要完成指静脉感兴趣区域的提取,以保留指静脉血管特征较丰富的区域。a)得到手指轮廓,通过对原图4(a)进行Canny边缘检测实现,如图4(b)所示;b)计算出手指中线,将检测到的上下手指边缘作差,得到手指中线,如图4(c)所示;c)图像角度旋转,将指静脉图像根据手指中线进行旋转,旋转角度则是手指中线与水平方向的夹角,如图4(d)所示;d)图像剪裁,旋转后为了防止提取的区域混有背景噪声,采用最小内接矩形法对其进行裁切,得到图4(e)所示;e)图像增强,将得到的图片进行限制对比度自适应直方图均衡,使指静脉血管与非血管部分区别更加明显,并将图片尺寸归一化到224×224,同时对像素进行归一化。此时图4(f)即是所要的感兴趣区域。
3 实验与部署
3.1 实验环境和评价指标
实验平台为PC平台和嵌入式平台。
PC平台系统为Windows11,CPU型号为Intel i7-11700 @ 2.50 GHz,32 GB内存,GPU为NVIDIA GTX3080Ti显卡。开发环境配置为PyCharm、PyTorch1.11.0、CUDA11.3、 Python3.8。
嵌入式平台为NVIDIA Jetson Nano开发板,嵌入式平台环境配置设为Jetpack4.4、 PyTorch1.8.0、Python3.6。
本文指静脉图像采集装置为微盾WDH-1101指静脉采集仪。图10右侧为WDH-1101指静脉采集仪,左侧为NVIDIA Jetson Nano开发板。指静脉采集界面如图11所示。
本文采用识别准确率(accuracy)和ROC曲线作为评价指标。
accuracy 代表所有测试样本中,能够正确识别的样本所占的百分比。
ROC曲线是误识率false accept rate (FAR)、拒识率false reject rate (FRR)和阈值之间的一种关系,反映了识别算法在不同阈值上,FRR和FAR的平衡关系。ROC曲线的横坐标为误识率FAR,纵坐标为拒识率FRR。当曲线越靠近右下角坐标原点时,识别性能越好。
3.2 数据集和实验设置
本文采用山东大学机器学习与数据挖掘实验指静脉数据集SDUMLA-HMT(SDU)[20]、马来西亚理工大学手指静脉数据集FV-USM(FVM)[21]和自建数据集(SF)。
SDU中的指静脉图像为320×240 像素的灰度图像,共3 816张,没有提供ROI图像,都为原始图像。其来自106个志愿者,共636类,每人采集了左右手的食指、中指和小拇指共6个手指,每个手指采集了6幅图像。
FVM中的指静脉图像为640×480像素的灰度图像,共采集了5 904幅图像,提供了每幅图像的ROI图像。其来自123个志愿者,共492类,每个人采集了4个手指,分别是左手和右手的食指和中指。采集分为两个阶段,每个阶段每个手指采集6幅图像。在两个数据集上每类都随机选取5张作为训练集,1张作为验证集。
SF数据集来自微盾WDH-1101采集仪采集的35位志愿者右手的食指,共35类,每类20张图片,一共采集了700张图片。每类选择10张作为训练集,10张作为验证集。
本文在训练前将提取的ROI图像尺寸统一到224×224,并将像素归一化到0~1,然后对训练集的图片进行随机剪裁、-45°~45°的随机角度旋转、随机翻转、仿射变换。在训练时每个epoch随机对10%的图片进行MixUp、Cutmix处理。梯度优化器使用Adam优化器,初始学习率设为0.001,学习率的更新采用余弦退火方法,每20个epoch为一个周期。每一个批次训练32张图片,损失函数在训练集上使用AdaFace损失与SoftTargetCrossEntropy损失函数相结合的方法,验证集上使用AdaFace与CrossEntropy损失函数相结合的方法。
3.3 網络实验及分析
由于注意力模块放置位置不同,对网络的性能会有影响,本文为了探究注意力模块的最佳位置,只在原网络中加入FMixconv和通道压缩比系数r=16的情况下,对比了三种不同位置的准确率,如表2所示。top代表放置在block的最前端,mid代表放置在MixConv后,bot代表放置在block外,将输出结果进行残差连接。实验结果表明,把CA模块放置在bot处准确率达到99.69%,效果最好。
同时,为了探究CA模块中通道压缩比系数r的最佳值,本文在bot位置对r=8、r=16、r=32三种情况进行对比实验,如表3所示,最后发现r=16时准确率达到99.69%,识别准确率最高。因此本文将CA模块置于bot位置,取r=16。
最后为了验证本文方法的有效性,与原网络进行对比实验,本文方法相比MicroNet-M0网络的准确率提高了2.51%,如表4所示。
3.4 与轻量级网络在嵌入式平台的对比实验及分析
3.4.1 识别性能对比
将其他轻量级网络和本文方法在不同阈值下得到的FRR和FAR绘制ROC曲线,如图12所示。
可以看到,本文方法的曲线在三个数据集上都更加靠近左下角,且在SDU数据集上表现最好,当FAR为0时,FRR不到0.04,领先于其他网络超过0.08。因此,本文方法具有较高的通过率和安全性,识别性能在三个训练集上均领先于其他网络。
3.4.2 识别准确率与模型参数对比
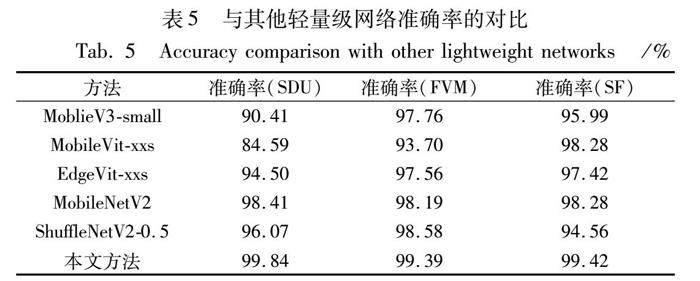
为了验证本文方法的有效性,将训练好的模型在Jetson Nano开发板上进行对比实验。在上述三个数据集上,将本文方法与近年来常用的轻量级分类模型进行对比实验,输入均为经过预处理的ROI图像,模型训练方法均与3.2节所描述的相同,实验结果如表5所示。
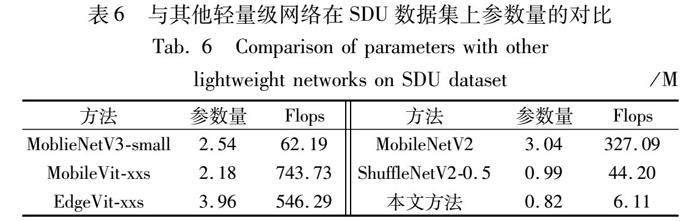
在SDU数据集上,本文方法相比准确率第2的MobileNetV2有1.43%的提高,在FVM数据集上比准确率第2的ShuffleNetV2-0.5有1.20%的提高,在SF数据集上比准确率第2的MobileVit-xxs和MobileNetV2有1.14%的提高。而在SDU數据集上,本文方法的网络参数仅有0.82 M,Flops为6.11 M。本文方法在参数量最少的情况下,识别准确率仍然领先于其他网络,证明了本文方法的有效性,如表6所示。
3.4.3 推理时间对比
为了证明本文方法的实时性,在没有预热的情况下,选取20张图片进行测试,实验结果如表7所示。
本文方法的运行时间仅有706.25 ms,低于其他方法,比位于第2的MobileNetV2网络的运行时间少47.64 ms,同时模型大小不到其1/3,证明本文方法更适合部署于嵌入式开发板上。
3.4.4 类激活热力图对比
为了观察网络是否注意到指静脉的关键特征,本文对网络提取的特征进行了可视化,类激活热力图如图13所示。可以看到,本文方法所关注的静脉区域更加全面,更加注重边缘的静脉纹理,并减少关注因外部条件影响而出现的阴影区域,因此本文方法能在与其他方法的对比实验中取得更好的效果。
3.5 与其他方法的对比实验及分析
本文还与其他方法在SDU和FVM两个公共数据集上进行比较,如表8与9所示。在SDU数据集上,相比准确率第2的Merge CNN,本文方法准确率提高了0.36%。在FVM数据集上,本文方法准确率领先于轻量级CNN 0.81%。进一步证明了本文方法相比于其他方法更具有优势。
4 结束语
针对指静脉识别网络部署在移动端和嵌入式平台困难的问题,本文提出了一种基于静脉关键特征和AdaFace损失的轻量级指静脉识别算法。首先在MicroNet-M0的基础上进行改进,对MixConv进行低秩分解,替代原网络中的深度卷积,获得静脉图像不同尺度的信息。其次,使用CA模块提高网络在跨空间和跨通道上对指静脉纹理的注意力,最后加入AdaFace损失减少低质量图像对训练的影响,并增大类间距离,减少类内距离。经实验证明,本文方法在SDUMLA-HMT、FV-USM和SF数据集上的识别准确率达到99.84%、99.39%和99.42%,而参数量只有0.82 M,同时推理时间也仅有706.25 ms,更容易部署在嵌入式平台上。
参考文献:
[1]谭营,王军. 手指静脉身份识别技术最新进展 [J]. 智能系统学报,2011,6(6): 471-482. (Tan Ying,Wang Jun. The latest deve-lopment of finger vein identification technology [J]. CAAI Trans on Intelligent Systems,2011,6(6): 471-482.)
[2]Yeh J,Chan H T,Hsia C H. ResNext with cutout for finger vein ana-lysis [C]// Proc of International Symposium on Intelligent Signal Processing and Communication Systems. Piscataway,NJ:IEEE Press,2021: 1-2.
[3]Huang Zhe,Guo Chengan. Robust finger vein recognition based on deep CNN with spatial attention and bias field correction [J]. International Journal on Artificial Intelligence Tools,2021,30(1): 2140005.
[4]Li Yupeng,Lu Huimin,Wang Yifan,et al. ViT-Cap: a novel vision transformer-based capsule network model for finger vein recognition [J]. Applied Sciences,2022,12(20): 10364.
[5]戴坤龙. 基于深度度量学习的指静脉识别研究及应用 [D]. 成都: 电子科技大学,2022. (Dai Kunlong. Research and application of finger vein recognition based on deep metric learning[D]. Chengdu: University of Electronic Science and Technology of China,2022.)
[6]Iandola F N,Han S,Moskewicz M W,et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and<0.5 MB model size [EB/OL].(2016).https://doi.org/10.48550/arXiv.1602.07360.
[7]Howard A G,Zhu Menglong,Chen Bo,et al. MobileNets: efficient convolutional neural networks for mobile vision applications [EB/OL]. (2017). https://do iorg/10. 48550/arXiv. 1704. 04861.
[8]Zhang Xiangyu,Zhou Xinyu,Lin Mengxiao,et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2018: 6848-6856.
[9]Han Kai,Wang Yunhe,Tian Qi,et al. GhostNet: more features from cheap operations [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2020:1577-1586.
[10]Li Yunsheng,Chen Yinpeng,Dai Xiyang,et al. MicroNet: improving image recognition with extremely low flops [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2021: 458-467.
[11]Shaheed K,Mao Aihua,Qureshi I,et al. DS-CNN: a pre-trained Xception model based on depth-wise separable convolutional neural network for finger vein recognition [J]. Expert Systems with Applications,2022,191: 116288.
[12]Ren Hengyi,Sun Lijuan,Guo Jian,et al. A dataset and benchmark for multimodal biometric recognition based on fingerprint and finger vein [J]. IEEE Trans on Information Forensics and Security,2022,17: 2030-2043.
[13]牟家樂,沈雷,刘浩,等. 基于深度残差网络的轻量级指静脉识别算法 [J]. 杭州电子科技大学学报:自然科学版,2023,43(2): 35-40,46. (Mu Jiale,Shen Lei,Liu Hao,et al. Lightweight finger vein recognition algorithm based on deep residual network [J]. Journal of Hangzhou Dianzi University:Natural Sciences,2023,43(2): 35-40,46.)
[14]Zhao Dongdong,Ma Hui,Yang Zedong,et al. Finger vein recognition based on lightweight CNN combining center loss and dynamic regularization [J]. Infrared Physics & Technology,2020,105: 103221.
[15]Tan Mingxing,Le Q V. MixConv: mixed depthwise convolutional kernels [EB/OL].(2019).https://doi.org/10.48550/arXiv.1907.09595.
[16]Hou Qibin,Zhou Daquan,Feng Jiashi. Coordinate attention for efficient mobile network design [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2021: 13708-13717.
[17]Hu Jie,Shen Li,Sun Gang. Squeeze-and-excitation networks [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2018: 7132-7141.
[18]Park J,Woo S,Lee J Y,et al. BAM: bottleneck attention module [EB/OL].(2018).https://doi.org/10.48550/arXiv.1807.06514.
[19]Woo S,Park J,Lee J Y,et al. CBAM: convolutional block attention module [C]// Proc of European Conference on Computer Vision. 2018: 3-19.
[20]Yin Yilong,Liu Lili,Sun Xiwei. SDUMLA-HMT: a multimodal biometric database [C]// Proc of the 6th Chinese Conference on Biometric Recognition. Berlin: Springer,2011: 260-268.
[21]Asaari M S M,Suandi S A,Rosdi B A. Fusion of band limited phase only correlation and width centroid contour distance for finger based biometrics [J]. Expert Systems with Applications,2014,41(7): 3367-3382.
[22]Zhong Yiqi,Li Jiahui,Chai Tingting,et al. Different dimension issues in deep feature space for finger-vein recognition [C]// Proc of the 15th Chinese Conference on Biometric Recognition. Berlin: Springer,2021: 295-303.
[23]Hou Borui,Yan Ruqiang. ArcVein-arccosine center loss for finger vein verification [J]. IEEE Trans on Instrumentation and Mea-surement,2021,70: 1-11.
[24]Tao Zhiyong,Wang Haotong,Hu Yalei,et al. DGLFV: deep genera-lized label algorithm for finger-vein recognition [J]. IEEE Access,2021,9: 78594-78
[25]Li Shuyi,Ma Ruijun,Fei Lunke,et al. Learning compact multi-representation feature descriptor for finger-vein recognition [J]. IEEE Trans on Information Forensics and Security,2022,17:1946-1958.
[26]Boucherit I,Zmirli M O,Hentabli H,et al. Finger vein identification using deeply-fused convolutional neural network [J]. Journal of King Saud University-Computer and Information Sciences,2022,34(3): 646-656.
[27]Li Jun,Yang Luokun,Ye Mingquan,et al. Finger vein verification on different datasets based on deep learning with triplet loss [J]. Computational and Mathematical Methods in Medicine,2022,2022: article ID 4868435.
