
结合对抗训练和特征混合的孪生网络防御模型
2024-05-24 15:46张新君程雨晴
计算机应用研究 2024年3期
张新君 程雨晴

摘 要:
神經网络模型容易受到对抗样本攻击。针对当前防御方法侧重改进模型结构或模型仅使用对抗训练方法导致防御类型单一且损害模型分类能力、效率低下的问题,提出结合对抗训练和特征混合训练孪生神经网络模型(SS-ResNet18)的方法。该方法通过线性插值混合训练集样本数据,使用残差注意力模块搭建孪生网络模型,将PGD对抗样本和正常样本输入不同分支网络进行训练。在特征空间互换相邻样本部分输入特征以增强网络抗干扰能力,结合对抗损失和分类损失作为网络整体损失函数并对其进行标签平滑。在CIFAR-10和SVHN数据集上进行实验,该方法在白盒攻击下表现出优异的防御性能,黑盒攻击下模型对PGD、JSMA等对抗样本的防御成功率均在80%以上;同时,SS-ResNet18模型时间花销仅为子空间对抗训练方法的二分之一。实验结果表明,SS-ResNet18模型能防御多种对抗样本攻击,与现有防御方法相比,其鲁棒性强且训练耗时较短。
关键词:孪生神经网络;图像分类;对抗样本;对抗训练;注意力机制;特征混合
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)03-039-0905-06doi: 10.19734/j.issn.1001-3695.2023.07.0318
Combining adversarial training and feature mixing for siamese network defense models
Zhang Xinjun, Cheng Yuqing
(School of Electronic & Information Engineering, Liaoning Technical University, Huludao Liaoning 125105, China)
Abstract:
Neural network models are vulnerable to adversarial sample attacks. Aiming at the problem that current defense methods focus on improving the model structure or the model only uses the adversarial training method which leads to a single type of defense and impairs the models classification ability and inefficiency, this paper proposed the method of combining the adversarial training and the feature mixture to train the siamese neural network model (SS-ResNet18). The method mixed the training set sample data by linear interpolation, built a siamese network model using the residual attention module, and inputted PGD antagonistic samples and normal samples into different branches of the network for training. It interchanged the input features in the feature space between neighboring sample parts to enhance the networks immunity to interference, combining the adversarial loss and the classification loss as the overall loss function of the network and smoothing it with labels. Experimented on CIFAR-10 and SVHN datasets, the method shows excellent defense performance under white-box attack, and the success rate of the models defense against anta-gonistic samples, such as PGD, JSMA, etc., under black-box attack is more than 80%. At the same time, the SS-ResNet18 model time spent is only one-half of the one-half of the subspace antagonistic training method. The experimental results show that the SS-ResNet18 model can defend against a variety of adversarial sample attacks, and is robust and less time-consuming to train compared to existing defense methods. Key words:siamese neural network; image classification; adversarial examples; adversarial train; attention mechanism; feature blending
0 引言
深度神经网络在自动驾驶汽车[1]、自然语言处理[2]和图像识别[3]等方面获得大量关注并展现出巨大潜力,随着深度神经网络在重要领域的应用越来越深入,深度学习模型的安全问题逐渐受到重视。2014年,Szegedy等人[4]提出对抗样本的概念,对抗样本是指在原始样本添加微小的扰动,导致神经网络模型预测出错。虽然人眼无法察觉所添加的较小扰动,但这给深度学习的实际应用带来很大危害。例如,对交通标志图片添加对抗扰动[5],会使自动驾驶汽车将停车标志识别为限速,导致安全事故。因此,对抗样本防御方法的研究具有现实意义。
利用神经网络这一漏洞,许多对抗攻击算法被提出。Szegedy等人提出的拟牛顿攻击算法通过在输入的约束空间中找到一个不可察觉的最小输入扰动,成功攻击了当时最先进的图片分类模型AlexNet和QuocNet。Goodfellow等人[6]提出了快速梯度符号方法(fast gradient sign method,FGSM),利用神经网络的梯度求解扰动,优点是易于实现但攻击能力较弱。Kurakin等人[7]对FGSM攻击算法进行改进,提出基础迭代攻击算法(basic iterative method,BIM),它是FGSM多次迭代的攻击版本,利用损失函数的梯度多次更新对抗样本达到更强攻击效果。Madry等人[8]提出投影梯度下降攻击(project gradient descent,PGD),该攻击算法被用来作为测试模型防御性能好坏的基准攻击算法。
对抗攻击算法的发展威胁着神经网络模型的安全,因此提升分类神经网络模型防御对抗攻击的能力尤为重要。大部分防御方法已被文献[9]证明防御能力有限,同时证明了对抗训练是目前最为有效的防御方法之一。优化防御模型结构的防御方法如防御蒸馏[10]、对抗样本检测[11]和基于生成对抗网络的防御[12] 方法在面对某一类攻击样本时能达到很好的防御效果,一旦模型结构被攻击者已知,就失去了防御能力。对抗训练方法需要好的训练策略和更强的对抗样本,通常会使训练时间比标准训练增加一个或多个数量级,且容易发生灾难性过拟合故障[13]。其他防御方法通过处理输入数据[14~16]进行防御,模型整体防御性能提升不大。
本文提出一种融合残差注意力机制和孪生神经网络结构的对抗训练方法(SS-ResNet18 AT),通过无参注意力[17]机制中的能量函数增加重要神经元的权重占比,帮助网络学习图像底层特征,增强网络稳健性。首先,目标网络模型使用PGD算法生成对抗样本,再通过混合[18]和硬修补[19]策略混合样本特征,训练防御模型得到最优参数。实验结果证明,本文模型在防御对抗样本成功率方面较其他方法表现更好。
1 相关工作
1.1 威胁模型
对抗样本具有隐蔽性同时兼具攻击性的特点,决定了对抗样本生成方法必须添加一定的限制,不是使用任意图像替换给出的输入图像进行攻击就属于对抗攻击,这违背了对抗样本的定义。为此,将针对攻击目标网络生成对应对抗样本的模型定义为威胁模型。通过威胁模型生成对抗样本在现实世界进行应用会带来极大的安全隐患,例如,在非停车路段模拟停车标识使用自动驾驶汽车识别网络进行实验,自动驾驶汽车无法规避该问题。
威胁模型的设计对于防御对抗样本的研究极其重要,了解攻击原理才能更好地进行防御,针对对抗样本攻击的目标可以分为有目标攻击和无目标攻击。有目标攻击是将输入样本分类为给定的错误类,给定f(·)为分类器,输入样本x和预分类目标t, f(x)≠t,通过威胁模型寻找对抗样本x′,使得f(x′)=t且‖x-x′‖p≤δ(p=0,2,∞),δ为添加的对抗扰动,p表示对扰动添加的约束类型。无目标攻击是指将样本分类为任意一个非正确类,若f(x)=y,寻找一个对抗样本使f(x′)≠y。
根据攻击方式,将对抗攻击类型进行分类,可分为白盒攻击、灰盒攻击和黑盒攻击。白盒攻击是已知模型所有参数信息,所以攻击成功率更高,常见的白盒攻击算法有PGD、FGSM和Deep Fool[20]等。黑盒攻擊是攻击者无法获得目标网络的信息,仅能获得目标网络的输出,攻击者利用对抗样本的迁移性进行攻击。灰盒攻击则介于两者之间。
1.2 孪生神经网络与残差神经网络
孪生神经网络[21]由结构相同、权值共享的两个子网络组成。两个子网络各自接收一个输入,将其映射至高维特征空间,并输出对应的表征,输出作为孪生网络损失函数的输入。孪生网络子网络可以是卷积神经网络或循环神经网络,其权重由能量函数或分类损失优化。孪生网络一般用来评价两个输入的相似度或进行小样本学习,也有学者使用孪生网络进行图像分类等。
残差神经网络于2015年提出,在大数据集的分类任务上表现优秀,解决了随着网络深度不断增加,出现梯度爆炸或梯度消失的问题。残差网络主要是由一系列残差模块组成,每个残差模块内部都加入了跳跃连接。以ResNet18为例,共有四个残差单元,每个残差单元包含两个残差块,残差模块内部主要使用的卷积大小为1×1和3×3。针对残差网络的改进,主要分为加深网络深度和增加网络宽度两方面,随之而来的问题是网络复杂度上升,使用小样本训练网络时容易过拟合。图1显示了孪生网络基础结构和经典残差块结构。
1.3 对抗训练
对抗训练防御方法占据主流的理论是Madry等人从博弈的角度出发,在经验风险最小化的原理基础上,提出了对抗鲁棒性的优化观点。其中,将模型的优化问题定义为求解鞍点的优化问题,即最大—最小问题,为后续对抗训练防御方法的研究提供了理论基础。其求解公式如式(1)所示。
minθ ρ(θ),where ρ(θ)=E(x,y)~D[maxδ∈S L(θ,x+δ,y)](1)
其中:L(θ,x+δ,y)为损失函数;x为原始样本;y为原始样本的标签;δ为扰动信息;S为扰动信息的集合;D为数据(x,y)满足的分布;θ为深度神经网络的参数。此公式求解可理解为在内部找到对抗样本使损失最大,然后优化模型参数使其外部经验风险最小。
目前许多对抗训练方法不断改进,Goodfelllow等人使用目标网络生成FGSM对抗样本加入训练集去训练神经网络模型,证明了对抗训练能提高深度学习分类模型对对抗样本的鲁棒性,提高了模型对对抗样本的分类精度。但很快,BIM攻击通过采取多个更小的FGSM步骤改进了FGSM,最终使基于FGSM对抗样本训练的网络模型被击破。这种迭代的对抗攻击通过添加多次随机重启而得到进一步加强,并且使用该算法生成的对抗样本也被纳入对抗训练过程。
从Madry等人仅使用PGD算法生成的对抗样本训练网络模型到Zhang等人[22]提出TRADES方法,使用原始样本共同训练模型可以增加模型的准确率。自由对抗训练(Free AT)[23]方法在PGD对抗训练的基础上改进了梯度更新步骤,缩短了训练时间,但防御性能方面没有较大提升。快速对抗训练方法(Fast AT)[24]是在FGSM对抗训练方法基础上引入随机化,比自由对抗训练用时更短,但模型防御对抗样本攻击的成功率没有提升。还有利用各种技术增强对抗训练防御能力,如逻辑配对[25]、循环学习率[26]等。
2 本文方法
现有的对抗样本图像防御方法往往只侧重于提高对抗样本的鲁棒性,或者侧重于构建额外的模型检测对抗样本,而无法兼顾两者。为此,提出了结合对抗训练和特征混合训练孪生神经网络模型(SS-ResNet18),本文网络基础架构为加入注意力层的ResNet18,ResNet的残差结构能有效缓解梯度消失问题,且ResNet18相较于ResNet50和DenseNet,网络参数量更少,网络训练更易收敛,在达到较好防御性能的同时有效降低了网络计算复杂度。
训练网络时采用的MixUp方法不是从数据集中随机选取两个数据样本,而是从同一训练批次中抽取训练样本进行线性插值。然后,将对抗样本与原始样本分别输入孪生网络的子网络中,注意力层帮助网络更好地学习样本间的关联,硬修补融合相邻样本特征,减少对抗扰动对模型的干扰,从而提高网络稳定性和防御对抗样本的能力。图2为本文方法防御总体框架。
2.1 输入样本处理
混合(MixUp)是一种数据增广策略,以线性插值的方式来构建新的训练样本和标签。MixUp对标签空间进行了软化,通过模型输入与标签构建具有凸性质的运算,构造新的训练样本与对应的标签。与其他插值方法相比,线性插值能将任意层的特征以及对应的标签进行混合,提高模型的泛化能力和鲁棒性。
MixUp的过程是从训练数据中随机抽取两个特征目标向量(xi,yi)及(xj,yj),(,)为插值后的样本和对应标签,参数λ∈Beta(α,α)控制插值的强度,设置参数λ∈[0,1],α∈[0,∞],线性插值公式如式(2)所示。
=λxi+(1-λ)xj
=λyi+(1-λ)yj (2)
以CIFAR-10数据集为例,随机抽取500个数据样本进行可视化,直观显示MixUp操作前后的數据分布变化,右上角为数据标签信息。从图3中可观察到进行MixUp操作后,对比正常样本和对抗样本的数据分布,混合样本后能减轻噪声图像对网络训练过程的影响,增强模型的泛化能力。
硬修补(Hard PatchUp)方法最初提出目的是为了提高卷积神经网络模型对流形入侵问题的鲁棒性,即缓解对抗样本改变原始样本的数据分布,使原始样本特征偏离流形分布的问题。使用该方法在SS-ResNet18特征层进行多维度训练,对输入样本特征图进行处理,即选择卷积层k,创建二进制掩码M,将两个相邻样本中对应M大小的特征块进行互换。
该方法主要由三个超参数进行控制:patchup_prob为给定的小批量执行Hard PatchUp的概率,实验设置为1.0;块大小(block_size)和γ用于控制掩码生成,本文将block_size设置为7,γ设置为0.9。使用参数γ生成一个要屏蔽的块的中心点γadj,掩码中心γadj的计算为
γadj=γ×(feat_size2)(block_size2)×(feat_size-block_size+1)2(3)
对掩码中心进行伯努利采样,将掩码中的每个点扩展到块大小的方块区域,通过最大池化操作后取反,然后得到最终的掩码块。掩码块计算为
m←1-(max_pool2d(Bernoulli(γadj),kernel_size,stride,padding))(4)
假定输入的特征大小为(N,C,H,W),那么掩码中心的大小应该为(N,C,H-block_size-1,W-block_size-1),而掩码块的大小为(N,C,H,W),先对掩码中心进行填充,然后用一个卷积核大小的块进行最大池化来得到掩码块,最后将特征乘以掩码块即可。两个样本xi和xj在层k处的硬修补操作如式(5)所示。
hard(gk(xi),gk(xj))=M⊙gk(xi)+(1-M)⊙gk(xj)(5)
其中:⊙为点积运算;gk为输入图像在第k个卷积层隐藏表示的映射。应用PatchUp操作之后,分类网络模型从层k向前传递到模型中的最后一层,Hard PatchUp的特征块互换过程如图4所示。图4中x1=g(i)k(a)和x2=g(i)k(b)分别为两张图像卷积输出特征图,i为特征图索引,a、b为随机选择的两个样本关联的隐藏表示。在特征空间进行硬修补操作,使网络学习样本更深的特征而不易陷入过拟合。
2.2 对抗训练防御方法
本文对抗训练方法的实现分为以下四步:a)计算原始样本批次的损失;b)使用投影梯度下降(PGD)攻击算法生成一批对抗样本;c)使用原始标签对这些对抗样本进行训练,得到对抗样本的插值损失函数;d)从原始样本批次和对抗批次中获得损失的平均值,并使用该损失更新网络参数。PGD算法生成对抗样本如公式
xt+1=∏x+S(xt+ε sign(xJ(θ,x,y)))(6)
其中:xt为第k次迭代后的图像;y为真实标签;θ为目标模型参数;J(θ,x,y)为用来衡量分类误差的损失函数;ε为移动的步长;∏x+S为将扰动值限制在球面范围内。
生成对抗样本之后,与原始样本一起作为输入数据集输入分类模型,分类模型对输入样本进行计算得到输出,再同正确标签进行计算得到损失,损失反向传播来更新网络参数,重复进行直到损失达到预期效果或达到设置的训练批次。对抗训练的过程如图5所示。
2.3 子网络结构设计
实验以经典的残差网络模型ResNet18为基模型设计防御框架。考虑到训练深层网络过程中参与计算的参数量越大,模型结构越复杂的特点,为了提高网络对重要特征的提取能力,在ResNet18基础残差块中加入注意力模块SimAM,相比通道(1D)和空间(2D)注意力,其关注重点在于神经元重要性。该注意力可以有效生成真实三维权重。使用优化后的能量函数来发现每个神经元的重要性,式(7)用来计算能量函数。
et(wt,bt,y,xi)=
1M-1∑M-1i-1(-1-(wtxi+bt))2+(1-(wtt+bt))2+λw2t(7)
其中:wt和bt分别为权重和偏置变换;t和xi为输入特征的单个通道中目标神经元和其他神经元;M=H×W为该通道上的神经元数量。合理地假设单个通道中的所有像素遵循相同的分布。根据这一假设,可以计算所有神经元的平均值和方差,并重新用于该通道上的所有神经元,显著降低计算成本,避免重复计算。因此,最小能量可通过式(8)计算。
e*t=4(2+λ)(t-)+22+2λ(8)
其中:=1M∑Mi=1xi;2=1M∑Mi=1(xi-)2。式(8)表明,神经元t的能量e*t越低,与周围神经元越不同,对视觉处理越重要。因此,每个神经元的重要性可以通过1/e*t得出。相比通道(1D)和空间(2D)注意力,该注意力机制在改善本文网络的表征能力上更具灵活性和有效性。图6显示本文网络残差注意力模块结构。
2.4 损失函数
使用插值损失函数作为训练网络的损失函数。该损失函数由两部分组成,一部分为正常样本的插值损失函数Lnor。
Lnor=1n2∑ni, j=1Eλ~Dλl(fθ(i,j(λ)),i,j(λ))(9)
其中:i,j(λ)=λxi+(1-λ)xj,i,j(λ)=λyi+(1-λ)yj且λ∈[0,1];Dλ为Beta分布,Beta分布中超参数α,β>0;n为样本数;θ为网络参数;fθ(x)为神经网络输出;l为函数交叉熵损失。另一部分为对抗插值损失函数Ladv。
Ladv=1n2∑ni, j=1Eλ~Dλl(fθ(i,j(λ)),i,j(λ))(10)
其中:i=xi+δ,i,j(λ)=λi+(1-λ)j,對扰动δ使用L2范数约束;‖δ‖2≤C,C为大于零的常数,C越大,对抗样本攻击成功率越高,但对抗样本的隐蔽性会变弱,反之亦然。整体损失公式如式(11)所示。
Loss=Lnor+Ladv2(11)
3 实验
本章在CIFAR-10和SVHN数据集进行实验,验证本文方法训练的模型防御能力,主要使用FGSM、PGD、AA三种攻击算法进行无目标攻击测试,选用L∞范数作为攻击的距离度量,对抗扰动大小设置为8/255。对PGD攻击而言,迭代次数越多,攻击越强,步长均设置为2/255,使用PGD-7表示迭代七次生成对抗样本,PGD-20表示迭代二十次生成对抗样本。这三种攻击算法在模型不采取防御策略时均能使模型分类性能大幅下降,以此作为测试防御模型防御性能好坏的基准攻击。
3.1 实验设置
选用CIFAR-10和SVHN数据集作为本文实验所用数据集进行训练和测试。CIFAR-10数据集是用于识别普适物体的小型彩色数据集,每张图像大小为32×32,包含10个类别,有50 000张训练图像和10 000张测试图像。SVHN(street view house number)数据集来源于谷歌街景门牌号码,来自一个明显更难、未解决的现实世界问题(识别自然场景图像中的数字和数字)。数据集中每张图像大小都为32×32,每张图片中包含一组0~9的阿拉伯数字。训练集中包含73 257个数字,测试集中包含26 032个数字,另有531 131个附加数字。
a)硬件环境 本实验在Windows 10系统下进行,GeForce RTX 3060 6 GB的GPU辅助运行,机带RAM为16 GB。
b)软件环境 本实验采用Python 3.6编程语言,利用PyTorch深度学习框架,实验环境版本为CUDA 10.2,PyTorch 1.10,TorchVision 0.11.1。
主要使用FGSM、PGD(step=7和step=20)、AutoAttack三种对抗攻击算法制作对抗样本来测试模型的防御能力,测试所用对抗攻击算法来自Pytorch中的torchattacks库。在不防御的前提下,分类模型对各样本的分类结果如表1所示。
3.2 评价指标和对抗样本
实验采用两种评价指标评估防御方法,即评估训练模型所用时间和评估模型防御白盒攻击性能。在非目标攻击防御实验中,使用测试集的分类准确率对模型防御性能进行评估。分类准确率acc计算如式(12)所示。
acc=TP+TNTP+FP+TN+FN(12)
其中:TP表示把正类预测为正类;TN表示把负类预测为负类;FP表示把负类预测为正类;FN表示把正类预测为负类。本文用该指标来评估模型对输入图像的分类精度。
PyTorch自带的torchattacks库中对抗攻击算法生成的对抗样本图像如图7所示,其中原始样本来自SVHN数据集,对抗攻击算法对其添加的对抗扰动大小均设置为8/255。
3.3 实验结果
3.3.1 对比实验
为了更直观地观察本文防御模型性能,图8、9显示在FGSM、PGD及自动攻击(AutoAttack,AA)[27]下模型整体防御性能的提升,深灰色柱状区域表示模型不采取防御措施下对抗样本的防御成功率,浅灰色柱状区域则表示采取防御之后的防御成功率(参见电子版),可明显观察到本文模型防御对抗样本的能力大幅提升。
为更好地评估防御性能,使用白盒攻击和黑盒攻击两种方式进行测试,白盒测试模型的防御性能,黑盒测试模型的泛化性能。在两个数据集上训练本文模型,然后与其他防御方法进行对比。SVHN数据集上进行对比的方法包括基线方法、PGD AT、MixUp和插值对抗训练方法。对比结果如表2所示。
CIFAR-10数据集上对比方法有PGD AT、快速对抗训练(Fast AT)、自由对抗训练(Free AT)、插值对抗训练(Interpolation AT)[28]以及子空间对抗训练(Sub-AT)[29],对比实验结果如表3所示。
实验结果表明,基于SS-ResNet18进行对抗训练的防御策略不仅能保持较高的原始样本分类准确率,模型对对抗样本的分类能力也有了大幅提升。以PGD-7攻击为例,其分类准确率提升20%以上,防御其他攻击的能力也有了明显提高。
除了表2、3的白盒攻击测试结果对比外,本文还进行了对抗样本黑盒攻击测试,使用VGG16网络生成对抗样本图像攻击SS-ResNet18防御模型。在两个数据集上的黑盒测试结果如表4所示。
根据混淆矩阵分析SS-ResNet18模型对数据集中每类图像的分类能力,黑盒攻击实验测试结果的混淆矩阵如图10所示。
混淆矩阵中对角线数据指的是SS-ResNet18模型将每类样本分类正确的数量,对角线外为分类错误的样本数量。图中横轴表示分类正确样本标签,纵轴表示分类错误样本标签,模型分类对抗样本的准确率用鲁棒准确率表示。分析黑盒攻击下的测试结果可得,在未知目标模型结构情况下,对抗样本很难通过泛化性成功攻击SS-ResNet18模型。该模型具有良好的泛化性能。
3.3.2 消融实验
在CIFAR-10和SVHN数据集上对实验结果进行消融研究,验证模型结构的合理性。消融设置如下:模型1为ResNet18不采用任何防御策略进行标准训练的模型、模型2为ResNet18进行PGD对抗训练防御方法训练得到的模型、模型3为ResNet18进行插值对抗训练防御方法训练得到的模型、模型4采用加入注意力机制的ResNet18进行插值对抗训练得到的模型、模型5为使用对抗训练和特征混合方法训练得到的SS-ResNet18模型。
实验测试所用模型均训练200轮次,基本参数相同。测试数据为原始测试数据集和使用残差网络生成的步长为2/255、迭代七次且进行l∞范数约束的PGD算法生成的对抗样本,评价指标为分类精度和鲁棒精度,分别表示分类正常样本和PGD-7对抗样本的分类准确率。实验结果如表5所示,均取最佳测试结果。
3.3.3 训练时间花销和稳定性对比
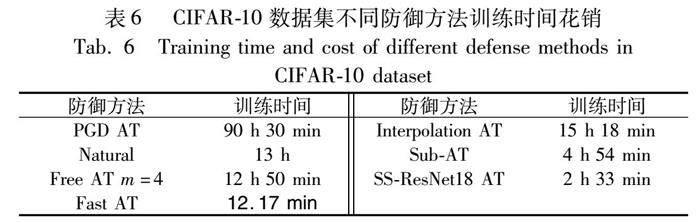
对抗训练需要生成对抗样本投入模型训练,因此较标准训练耗时更长,不易应用到大型网络。使用早期停止策略,当损失在20个周期不下降就停止网络训练,并使用ResNet18作为基模型进行训练。训练时间对比结果如表6所示。
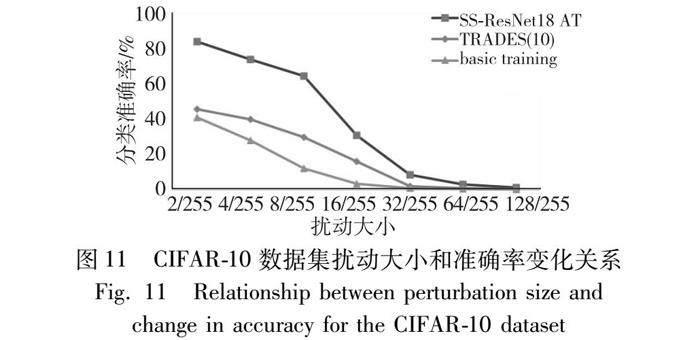
由表6数据可知,虽然训练模型时间相比快速训练方法仍有差距,但对比PGD对抗训练方法有着较大提升,且SS-ResNet18对抗训练所需训练时长低于最新提出的子空间对抗训练方法。从表6可知,SS-ResNet18对抗训练方法有效缩短了对抗训练时间,在时间成本上的花销低于大部分对抗训练防御方法。为了验证模型的稳定性,采取CIFAR-10数据集训练好的防御模型,在步长为2/255,迭代七次的PGD攻击扰动不断增大的情况下进行实验测试。与标准训练、TRADES方法进行对比,稳定性测试为白盒攻击测试结果,实验结果如图11所示。
众所周知,大扰动下分类模型更不易分类原始样本和对抗样本,扰动越大分类准确率越低,模型防御对抗样本的能力就越弱。图11可观察到SS-ResNet18对抗训练方法训练的模型在扰动不断增大的情况下下降趋势更为缓慢。综上可得,SS-ResNet18模型不仅具有高鲁棒性,也具有高稳定性。
4 结束语
本文通过添加注意力模块对残差网络结构进行改进,计算能量函数来增加重要神经元的权重。孪生网络结构很好地缓解了对抗训练过程中对抗样本对干净样本分类结果的干扰,加速网络训练过程,训练模型过程中融合样本间的特征以提高网络泛化性。在两个开源数据集上,使用多种攻击方式与不同防御方法训练的卷积神经网络分类模型进行对比,根据白盒攻击测试结果可得,本文模型鲁棒性最好,对比最新的子空间训练方法,模型训练时间更少。黑盒测试结果和稳定性对比实验进一步验证了该模型有着良好的泛化能力和防御性能。通过消融实验,保持參数一致的情况下证明SS-ResNet18模型所添加的策略是可行有效的。综合可得,SS-ResNet18模型提高了分类模型防御多种对抗样本攻击的能力。同时,模型降低了采用对抗训练方法对正常样本分类准确率的负面影响,且模型训练时间较短。
参考文献:
[1]Spielberg N A,Brown M,Gerdes J C. Neural network model predictive motion control applied to automated driving with unknown friction [J]. IEEE Trans on Control Systems Technology,2021,30(5): 1934-1945.
[2]桂韬,奚志恒,郑锐,等. 基于深度学习的自然语言处理鲁棒性研究综述 [J]. 计算机学报,2024,47(1): 90-112. (Gui Tao,Xi Zhiheng,Zhen Rui,et al. A review of deep learning-based natural language processing robustness research [J]. Chinese Journal of Computers,2024,47(1): 90-112.)
[3]Li Yinglong. Research and application of deep learning in image recog-nition [C]// Proc of the 2nd IEEE International Conference on Power,Electronics and Computer Applications. Piscataway,NJ: IEEE Press,2022: 994-999.
[4]Szegedy C,Zaremba W,Sutskever I,et al. Intriguing properties of neural networks [EB/OL]. (2014-02-19). https://arxiv.org/abs/1312.6199.
[5]Eykholt K,Evtimov I,Fernandes E,et al. Robust physical-world attacks on deep learning visual classification [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2018: 1625-1634.
[6]Goodfellow I J,Shlens J,Szegedy C. Explaining and harnessing adversarial examples [EB/OL]. (2015-03-20). https://arxiv.org/abs/1412.6572.
[7]Kurakin A,Goodfellow I J,Bengio S. Adversarial examples in the physical world [M]// Artificial Intelligence Safety and Security. Boca Raton,FL: Chapman and Hall/CRC,2018: 99-112.
[8]Madry A,Makelov A,Schmidt L,et al. Towards deep learning models resistant to adversarial attacks [EB/OL]. (2019-09-04). https://arxiv.org/abs/1706.06083.
[9]Athalye A,Carlini N,Wagner D. Obfuscated gradients give a false sense of security: circumventing defenses to adversarial examples [C]// Proc of International Conference on Machine Learning. [S.l.]:PMLR,2018: 274-283.
[10]Papernot N,McDaniel P,Wu Xi,et al. Distillation as a defense to adversarial perturbations against deep neural networks [C]// Proc of IEEE Symposium on Security and Privacy. Piscataway,NJ: IEEE Press,2016: 582-597.
[11]魏忠誠,冯浩,张新秋,等. 基于注意力机制的物理对抗样本检测方法研究 [J]. 计算机应用研究,2022,39(1): 254-258. (Wei Zhongcheng,Feng Hao,Zhang Xinqiu,et al. Research on physical adversarial sample detection methods based on attention mechanisms [J]. Application Research of Computers,2022,39(1): 254-258.)
[12]Esmaeilpour M,Cardinal P,Koerich A L. Cyclic defense GAN against speech adversarial attacks [J]. IEEE Signal Processing Letters,2021,28: 1769-1773.
[13]Kim H,Lee W,Lee J. Understanding catastrophic overfitting in single-step adversarial training [C]// Proc of the AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2021: 8119-8127.
[14]Jia Xiaojun,Wei Xingxing,Cao Xiaochun,et al. ComDefend: an efficient image compression model to defend adversarial examples [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recog-nition. Piscataway,NJ: IEEE Press,2019: 6077-6085.
[15]Wu Dongxian,Wang Yisen. Adversarial neuron pruning purifies backdoored deep models [J]. Advances in Neural Information Processing Systems,2021,34: 16913-16925.
[16]王佳,張扬眉,苏武强,等. 基于压缩感知的神经网络实时综合防御策略 [J]. 计算机学报,2023,46(1): 1-16. (Wang Jia,Zhang Yangmei,Su Wuqiang,et al. Compression-aware neural network-based real-time integrated defense strategy [J]. Chinese Journal of Computers,2023,46(1): 1-16.)
[17]Yang Lingxiao,Zhang Ruyuan,Li Lida,et al. SimAM: a simple,parameter-free attention module for convolutional neural networks [C]// Proc of International Conference on Machine Learning. [S.l.]: PMLR,2021: 11863-11874.
[18]Zhang Linjun,Deng Zhun. How does mixup help with robustness and generalization? [C]// Proc of the 9th International Conference on Learning Representations. 2021.
[19]Faramarzi M,Amini M,Badrinaaraayanan A, et al. PatchUp: a feature-space block-level regularization technique for convolutional neural networks [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2022: 589-597.
[20]Moosavi-Dezfooli S M,Fawzi A,Frossard P. DeepFool: a simple and accurate method to fool deep neural networks [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2016: 2574-2582.
[21]Koch G,Zemel R,Salakhutdinov R. Siamese neural networks for one-shot image recognition [C]// Proc of ICML Deep Learning Workshop. 2015.
[22]Zhang Hongyang,Yu Yaodong,Jiao Jiantao,et al. Theoretically principled trade-off between robustness and accuracy [C]// Proc of International Conference on Machine Learning. [S.l.]: PMLR,2019: 7472-7482.
[23]Shafahi A,Najibi M,Ghiasi M A,et al. Adversarial training for free! [EB/OL]. (2019-11-20). https://arxiv.org/abs/1904.12843.
[24]Wong E,Rice L,Kolter J Z. Fast is better than free: revisiting adversarial training [EB/OL]. (2020-01-12). https://arxiv.org/abs/2001.03994.
[25]Li Xingjian,Goodman D,Liu Ji,et al. Improving adversarial robustness via attention and adversarial logit pairing [J]. Frontiers in Artificial Intelligence,2022,4: 752831.
[26]Smith L N. Cyclical learning rates for training neural networks [C]// Proc of IEEE Winter Conference on Applications of Computer Vision. Piscataway,NJ: IEEE Press,2017: 464-472.
[27]Croce F,Hein M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks [C]// Proc of International Conference on Machine Learning.[S.l.]:PMLR,2020:2206-2216.
[28]Lamb A,Verma V,Kannala J,et al. Interpolated adversarial training: achieving robust neural networks without sacrificing too much accuracy [C]// Proc of the 12th ACM Workshop on Artificial Intelligence and Security. New York:ACM Press,2019: 95-103.
[29]Li Tao,Wu Yingwen,Chen Sizhe,et al. Subspace adversarial training [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2022: 13399-13408.
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
现代电子技术(2017年3期)2017-03-04
现代电子技术(2017年1期)2017-02-16
现代电子技术(2016年22期)2016-12-26
软件导刊(2016年9期)2016-11-07
