
风力发电机组故障诊断与预测维护技术研究
2024-05-22 07:25中国华电科工集团有限公司王宝灵
电力设备管理 2024年6期
中国华电科工集团有限公司 王宝灵
1 风电机组常见运行故障
在风电机组运行过程中,容易出现多种故障,以笔者所在的电厂为例,其常见故障类型有如下几种。
馈电故障:此类故障的出现原因为电缆损坏或老化,具体为机组内部负责馈电的电缆发生异常,无法正常运行,导致机组稳定性受到影响;电源故障:风电机组内部存在诸多子系统,其在运行阶段均需要电力支持,若电源出现故障机组运行便会受到影响,严重时甚至会引发灾难性的后果;冷却故障:某电厂所采用的风电机组发电机主要是永磁式电机,为冷却温度,会通过风扇使内部热空气与外部空气相互交换。若风扇因故障无法正常运行,会导致机组内热量大幅度上升,致使电机绕组增加,不利于机组正常运行;励磁故障:导致此类故障的发生原因众多,通常以参数设置、控制信息被错误操作、下载位置不准确为主[1]。某电厂针对上述几种常见的故障,将CGAN-CNN 作为基础提出一种诊断风电机组故障的方法,具体内容如下所述。
1.1 构建故障判别模型
在风电机组运行阶段获取故障样本的难度极大,究其原因,主要是风电机组稳定性非常高,且在发生异常之初通常会立即停机,避免故障扩大造成严重的经济损失。再加上风电机组造价非常高昂,通常不会在做不可逆试验时将其作为试验对象,故正常样本和故障样本之间存在悬殊的比例,机组故障并不丰富。鉴于此,某电厂会对生成式对抗网络加以运用,完成模型的构建。究其原因,主要是此类网络无需在先验证假设的情况下生成样本。卷积神经网络的组成部分较多,分别为输入、池化、卷积、连接和输出层。各层的说明如下。
卷积层:该层组成部分为卷积单元,其数量众多,对输入数据各种特征予以提取,属于其主要作用。在实际运算阶段可利用下述公式表示运算过程,式中:卷积运算操作由conv表示;输出特征图由xI j表示;卷积由*表示;位置由bI j表示;所在网络层数由上标表示;激活函数由f(x)表示,通常为ReLU。
池化层:该层属于采样层,在运算阶段所选择的卷积核相对较多,在此基础上所产生的特征图数量会增加,相较于原始数据,在经过处理后数据量同样会增加。在经过池化层处理后数据冗余度会下降,有利于降低计算难度,同时还能对过拟合现象加以屏蔽。通常情况下该层所处位置是卷积层之后,输出相应的公式。
全连接层。该层可以整合特征,使其转化为特征向量,其所处位置是整个卷积网络的末端,若有需求还具有与分类器相同的作用,其模型如下:yI=f(Wkxk-1+bk);式中:特征向量由yI表示;权重由Wk表示;偏置由bk表示;激活函数由f(x)表示[2]。
1.2 以CGAN-CNN 为基础的风电机组故障判断技术
某电厂所提出的故障判断模型由两部分组成,分别为样本生成和故障诊断。第一步,需要完成对抗网络模型的构建,使原始数据增加,生成拟合度高的样本数据,满足故障诊断样本的要求;第二步,实现对卷积神经网络的构建,之后训练数据集获得相应的模型,为故障诊断提供数据支持。
1.2.1 对抗网络样本模型的构建
某电厂所构建的CGAN-CNN 模型,其内部存在生成器和判别器,二者的数量均为1,其中,前者结构为三层全连,这里所说的三层,分别为输入、输出和隐藏层。后者的结构为四层全连,拥有两个隐藏层。且各层还具有全连接、激活和dropout 层,其网络结构如表1所示。
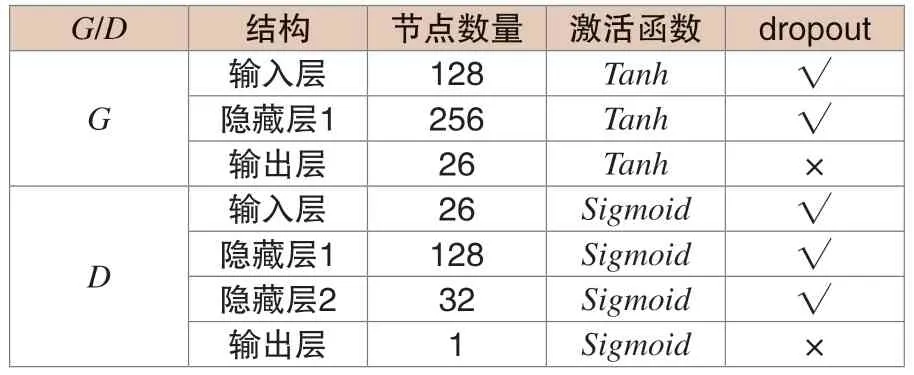
表1 对抗网络结构
1.2.2 以卷积神经网络为基础的风电机组故障诊断模型
某电厂所构建的网络模型结构层数较多,多达6层,各层的作用和参数如下所述。
一维卷积层:为使提取特征的数量增加,对卷积核的大小进行定义,本次定义的数量为2,在此基础上完成对滤波器的定义,其数量为100个;池化层:通常情况下该层与卷积层相连,为卷积后池化创造有利的条件,同时该层还具有筛选功能,能够提取特征鲜明的特征值;第二个一维卷积层,为获取更高层次的特征需要继续利用卷积层学习,其中2×100的矩阵是该层的输出;平坦层:对多维输入加以处理,具体处理方式是一维化。
随机层:在加入dropout 层后,对上层输入的神经元做赋值处理,但值得注意的是,赋值神经元数量为上层全部数量的50%,以此保证结果的准确性,同时还能使部分神经元之间的依赖作用被弱化;全连接层:借助softmax 函数对该层进行激活。之所以对此类函数加以使用,主要目的是做归一化处理,在处理完成后输出结果就会变为发生概率,这里所说的发生概率,主要对象为与输出结果相对应的情况,为后续准确率和损失率计算提供数据方面的支持。
1.3 风电机组故障诊断技术应用实例
数据预处理。某电厂将10台容量为1.5MW 的风电机组作为样本,所选择的机组在型号和批次上相同,且均处于相同的运行环境。在故障类型选择方面,将常见的齿轮、主轴承和发电机故障作为对象,同时将正常样本加入其中,故确定的运行模式为四种。调查数据显示,齿轮箱故障的总数为450、发电机组故障数量为600,主轴承故障发生次数为1600,合计2650组,同时还选择正常运行下的3500组数据,其中机组运行情况样本分类标签如下:常规状态1、主轴承故障2、齿轮箱故障3、发电机故障4,运行状态1~4的样本数据分布情况分别为:3500、1600、450、600,总计6150。
以CNN 为基础的机组故障诊断。在诊断故障的过程中,分别取该运行状态的数据800组,将其作为训练集,在此基础上另取400组作为测试集,二者之间的比重为2:1,其输出结果如下所述:在数据不平衡时,数据量偏少的3类和4类故障,其故障诊断效果非常差,而SMOTE-CNN 模型在预测时所取得的效果较为显著,好于输入不平衡样本集的CNN模型、但差于SMOTE-CNN 模型,由此可以看出,相较于SMOTE 算法使用生成的样本,采用本文所研究的CGNN 模型所生成的样本具有更高的真实性,能够被准确识别[3]。
2 风电机组故障预测方法
2.1 算法流程
风电机组故障预测过程由下述阶段组成:第一,采集运行数据;第二,训练故障预测模型;第三,提取故障特征;第四,演化过程分析。将DBN 模型作为基础,预测故障的步骤如下所述:
以机组在正常运行状态下的某个时间段的SCADA 数据为对象,将其作为训练数据集,在经过归一化处理后,得到下述公式:x=(x-xmin)/(xmax-xmin),式中:输入数据的最大值由xmax表示;最小值由xmin表示;通过滑动窗口的方式对所选择的数据集做处理,在比较散度算法后对网络参数予以更新,等到第一个RBM 训练完成后,确定隐含层节点数据,并将其作为后续RBM 的输入,在重复上述步骤后即可完成DBN 模型的获取,最后对风电机组标签样本加以使用,并利用BP 网络调整参数。值得注意的是,参数调整所遵循的原则为自上而下。
2.2 模型分析和实例验证
某电厂将自有的风电机组作为研究对象,结合上文可知该机组的容量为1.5MVA,在选择训练样本时,将正常运行状态下机组数据作为选择,对于机组内各部件所采取的监测方式并非集中监测,某电厂在验证过程中所选择的部件为主轴承。
某电厂所使用的模型为CGAN,其由两个部分组成,分别为判别器和生成器,两种设备的连接结构均为四层,分别为隐含层两个、输入和输出层各一个。针对函数损失和训练效果不佳的问题,所采取的方式为重置生成器设置梯度,从而保证训练质量。所谓的梯度重置,主要是指在发现梯度消失后重新设置梯度,并将零值覆盖,保证生成器能够正常学习,一直持续到判别器无法对生成样本简单分辨为止。在生成器损失保持平衡后,表示模型达到整体平衡[4]。
以某电厂某风电机组作为数据来源,该机组运行时间为5天10小时20分钟20秒,每次采样间隔20秒的时间,总共获得22000组数据,使其成为输入样本。为降低难度且保证不失一般性,本次测试并没有选择全部监测点的数据,最终确定了如下所述的输出向量数据:风速(m/s),变量符号为V1;轴承转子侧的温度℃,变量符号为T1;齿轮箱温度℃,变量符号为T2;电网电压V,变量符号为UL1;电网电流A,变量符号为IL1;电网功率(kW),变量符号为P1;变流器有功功率(kW),变量符号为P2。
2.3 机组运行正常时预测模型验证
某电厂在训练数据选择过程中所选的训练数据数量为30000组,在正常运行状态下某电厂风电机组主轴承重构误差如表2所示,可知其中固定阈值设定原理为EWMA,而基于自适应原理设定的阈值如表3所示,可知在机组正常运行状态下因不同时刻风速存在差异,故重构误差同样存在波动,但不会超出阈值。
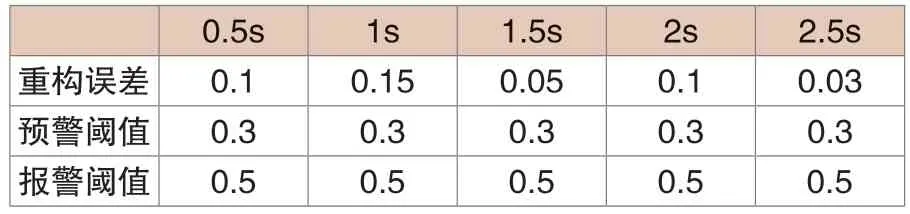
表2 固定阈值重构误差变化趋势
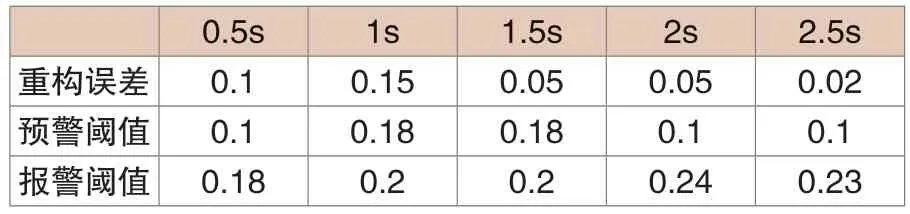
表3 自适应阈值重构误差变化趋势
2.4 主轴承故障状态下预测模型
输入故障状态数据,在经过计算后可以获得Re的变化情况,之后对上文所介绍的阈值设定方法予以应用,用于校检故障预测方法,最后对相关参数残差曲线加以分析,在此基础上预测故障类型,同时完成对故障标签的准确核对。本电场将EWMA控制原理作为依据,实现对阈值的设置,其中报警阈值的设定参数为0.505,而预警阈值设定参数低于报警阈值,具体数值为0.326。之后以故障发生的前三天为时间范围,发现在预警阈值范围内重构误差的变化波动较小,表明风电机组在这个时间段未发生故障。在重构误差产生后,风电机组在运行第四天开始发出故障预警,第五天故障报警触发。自此之后重构误差的上升速度加快。
预测结果表明,故障预测模型的构建可以起到监测风电机组运行状态的作用,有利于准确预测机组故障发生的概率,能够为后续机组维护创造有利的条件[5-6]。
3 结语
综上所述,为实现碳中和的目标,我国高度重视新能源发电产业的发展,以太阳能和风力发电为代表的新能源发电方式所占的比重逐渐增加。为使风力发电机组运行稳定性和安全性得到保证,某电厂基于CGAN-CNN 提出一种故障诊断和预测方法,结果表明本文所提出的诊断和预测方法可以取得良好的应用效果,能够为机组故障维护提供可靠的数据支持。
猜你喜欢
军事文摘(2018年24期)2018-12-26
能源(2018年6期)2018-08-01
能源(2018年6期)2018-08-01
能源(2018年6期)2018-08-01
能源(2018年6期)2018-08-01
通信电源技术(2018年3期)2018-06-26
能源(2018年8期)2018-01-15
风能(2016年12期)2016-02-25
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
振动、测试与诊断(2014年5期)2014-03-01
