
基于医学检验大数据的乳腺恶性肿瘤预测模型研究
2024-05-18 06:17王莹
电脑知识与技术 2024年8期
王莹
摘要:[目的] 基于医学检验大数据,通过机器学习构建乳腺恶性肿瘤预测模型。[方法] 收集某综合性三甲医院2016年至2021年所有门诊和住院乳腺恶性肿瘤患者的医学检验数据,并通过大数据技术处理形成机器学习数据源。采用逻辑回归二分类和支持向量机两种算法分别构建乳腺恶性肿瘤预测模型。[结果] 逻辑回归二分类预测模型的AUC为0.923,F1-Score为0.875;支持向量机预测模型的AUC为0.957,F1-Score为0.912。[结论] 综合评估结果显示,基于医学检验大数据构建的预测模型具有较高准确率,可以有效识别乳腺恶性肿瘤患者。因此,该模型有望成为乳腺恶性肿瘤的一种微创、低成本、快捷有效的筛查手段。
关键词:医学检验大数据;乳腺恶性肿瘤;逻辑回归二分类;支持向量机;预测模型
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)08-0035-04
开放科学(资源服务)标识码(OSID)
1 概述
乳腺恶性肿瘤(breast malignant tumor,BMT) 是女性患者中常见的恶性肿瘤,也是全球女性患者癌症相关死亡的一个主要因素[1]。由于乳腺癌是常见的乳腺恶性肿瘤,其中患者比例占乳腺恶性肿瘤的90%以上,通过普及乳腺癌筛查以及提高相应诊疗水平实现了乳腺癌患者生存率的显著提升。现阶段乳腺癌筛查的主要方法是乳腺X线检查和超声检查,这两种方法对早期病灶敏感性低,需要结合细胞学或病理学结果才能确诊[2]。近年来全球乳腺癌发病率急剧上升,早诊断、早治疗对患者生存率的提高有极其重要的意义。
临床方面需要寻找一种简单、便捷的检查方法对BMT实施早期诊断、监测病情、评价疗效以及预后。肿瘤标志物为恶性肿瘤细胞或宿主对肿瘤的刺激反应而产生的物质,涵盖蛋白质、酶类、激素、神经递质及癌基因产物等。肿瘤标志物存在于患者的血液、体液、细胞或组织中,可采用生物化学、免疫学及分子生物学等方法测定,肿瘤标志物的指标异常升高通常早于其影像学改变,而且其取材方便,创伤小,适用于对高危人群的筛查或肿瘤患者的疗效评估[3]。目前临床用于疗效评估的成熟生物靶向标志物相对有限,因而探索易获得标本(外周血、胸腹水等)中肿瘤标志物检测的方法,将会为患者带来较大的便利和益处[4]。患者就诊过程中产生了较多数量的医学检验数据。但临床医生通常只关注部分重要的异常参数,而忽视其他医学检验数据以及医学实验室参数间的相互关系,导致医学实验室数据的价值利用率较低[5]。由于异常增殖的肿瘤细胞随着血液进入人体各个组织、器官,在全身各部位会有不同的表现,分泌的细胞因子及各种功能蛋白均会导致相应医学检验数据产生变化,即使数据处于正常参考值范围内,但数据之间相互的关系也可能发生改变,普通人工筛查模式无法察觉数据之间的潜在关系。采用人工智能算法对医学检验数据进行数据挖掘,可以发现数据之间潜在的关联关系[6]。因此,基于医学检验数据对BMT进行预测不但可以实现早诊断、早治疗,提升患者的生存率,还可以大幅降低BMT筛查的门槛以减轻社会经济负担。
2 材料和方法
2.1 材料
从某综合性三甲医院的实验室信息管理系统(LIS) 和医院信息系统(HIS) 中提取了2016年10月1日至2021年09月30日的全量医学检验数据(140 616 701条记录)及诊断结果。数据库字段包括患者ID、年龄、性别、就诊类别(门诊或住院)、检验日期、检验项目编码、检验结果和诊断结果。
2.2 方法
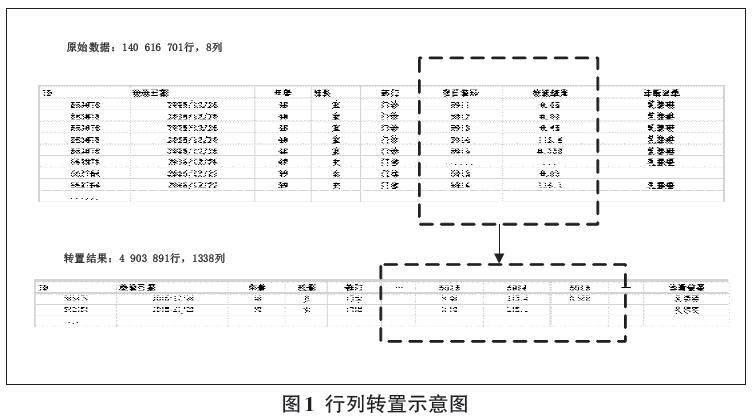
1) 医学检验数据治理。通过在大数据平台上对医学检验数据进行行列转置,实现所有患者在同一日期的所有检验项目处于同一行,不同患者的同一检验项目结果处于同一列。将140 616 701條记录的全量医学检验数据转化为1 338列、4 903 891行的大数据宽表,转置模式如图1所示。
统计每一个检验项目对应的数据类型、数据量以及脏数据分布状况,并确定数据标准。根据数据标准进行数据类型转换或清理,删除各种错误数据和无效数据,采用零填充缺失数据。在对每个检验项目制定处理规则的基础上,形成计算机脚本实现自动化处理。
2) 医学检验数据开发。医学检验数据开发包括数据获取、数据归一化和特征抽象。
数据获取:从4 903 891条记录的诊断结果中检索获得26 102例BMT患者相关记录,形成BMT样本数据。从4 903 891条记录的诊断结果中检索获得19 841条普通体检人员相关记录作为BMT对照数据。
数据归一化:Y=(X-Fmin) /(Fmax-Fmin),式中,Fmax和Fmin分别为每一个数据库字段中的最大值和最小值,X是字段中待归一化的值,Y为X的归一化结果,实现数值数据压缩到[0,1]区间,从而去除字段的量纲,提高机器学习算法的收敛速度。
特征抽象:选择全部1 361个检验项目作为特征列,选择诊断结果为目标列,其中诊断结果为“乳腺癌”或“乳腺恶性肿瘤”置为“1”,其他诊断结果置为“0”,形成机器学习数据源。
3) 机器学习算法。本研究采用逻辑回归二分类(logistic regression,LR)和支持向量机(support vector machine,SVM) 两种机器学习算法。
由于LR算法产生的模型构造简单、结果简单易懂,在医学领域有着广泛的应用。LR模型可以用数学公式直观描述,假设 P 为某一事件发生的概率,其取值范围为[0, 1],则该事件不发生的概率为1-P,对P/(1–P) 取自然对数为 ln(P/(1–P)),记为 logitP, logitP 的取值范围为(–∞, +∞) 。以P 作为因变量,构建线性回归方程:
log itP =a+b1x1 + +bm xm (1)
对方程变换,进而得到:
P=exp(a+b1x1 + +bm xm) /(1+exp(a+b1x1 + +bm xm)) (2)
該模型即为LR模型,其中a 为常数,bi (i=1, …, m)为逻辑回归系数[7]。
SVM的基本思想是通过构建一个超平面,实现对正、负例的完全分开。由于客观上可能存在无数个能够实现对正、负例完全分开的超平面,需要利用间隔最大化求分离超平面得到唯一解[8]。
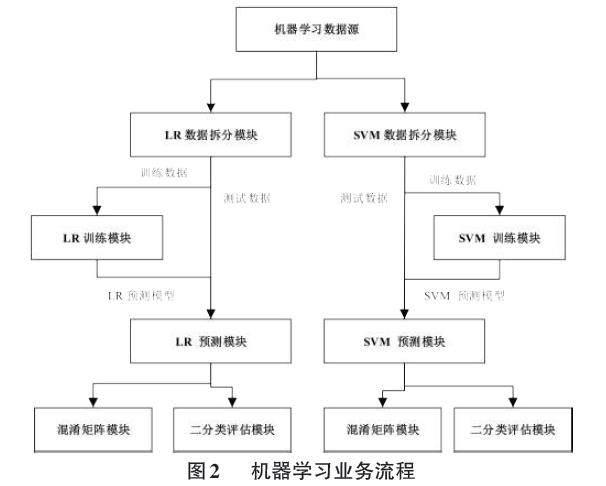
4) 机器学习业务流程。机器学习业务流程包括数据拆分、训练预测模型、预测测试数据以及预测结果评估。数据拆分模块按照预设比例将机器学习数据源随机拆分为训练数据和测试数据两部分。例如,并行采用LR和SVM两种算法对同一机器学习数据源分别训练。其中,LR数据拆分模块采用训练数据与测试数据7:3的比例随机拆分机器学习数据源,SVM数据拆分模块采用训练数据与测试数据8:2的比例随机拆分机器学习数据源。LR数据拆分模块拆出的训练数据导入LR训练模块经过计算生成LR预测模型。LR数据拆分模块拆出的测试数据和LR预测模型分别导入LR预测模块实现LR预测模型对测试数据的预测。基于并行的SVM算法的操作步骤与LR算法相同。LR预测模块和SVM预测模块的预测结果分别导入各自对应的混淆矩阵模块和二分类评估模块,评估LR预测模型和SVM预测模型的预测水平。业务流程如图2所示。
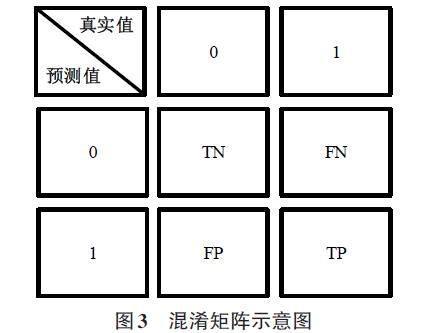
5) 预测模型评估指标。预测模型评估采用混淆矩阵和二分类评估两种方法。混淆矩阵为可视化预测工具,包括真阳性(true positive, TP) 、假阳性(false positive, FP) 、假阴性(false negative, FN) 、真阴性(true negative, TN) 等4项。其中,混淆矩阵的每一列代表一个类的预测情况,每一行表示一个类的实际样本情况,如图3所示。评估项包括准确率、精确率、召回率、F1-Score,相应的计算公式如下:
准确率=[TP+TNTP+TN+FP+FN]
精确率=[TPTP+FP]
召回率=[TPTP+FN]
F1-Score=[2*TP2*TP+FP+FN]
二分类评估采用F1-Score和受试者工作特征曲线下面积(Area Under Curve, AUC) 两项评估指标。其中,AUC数值处于[0, 1]之间,大于0.5则表示预测模型具有一定的区分能力,越接近1则预测模型的区分能力越强。
3 结果
3.1 LR二分类预测模型及预测水平评估
1) LR二分类预测模型。LR二分类预测模型包括1 361项特征列(检验项目)的权重,其中权重前15项如表1所示。
其中,项目编码为检验项目的唯一标识,权重表示检验项目在LR预测模型中的系数,权重数值越大,该检验项目与对应诊断结果的相关性越大。
2) LR二分类预测模型混淆矩阵评估。混淆矩阵对LR二分类预测模型的预测结果进行统计分析,评估结果如表2所示。其中,阳性样本预测的准确率、精确率、召回率、F1-Score评估结果均高于75%,表明LR二分类预测模型的预测准确性高,具有较好的可用性。
3) LR二分类预测模型二分类评估结果。二分类评估对LR二分类预测模型的预测结果进行统计分析,如表3所示,AUC和F1-Score的结果均高于0.800。这表明LR二分类预测模型的预测准确性高,具有较好的可用性。
3.2 SVM预测模型预测水平评估
1) SVM预测模型混淆矩阵评估。混淆矩阵对SVM预测模型的预测结果进行统计分析,评估结果如表4所示。其中,阳性样本的准确率、精确率、召回率、F1-Score评估结果均高于80%,表明SVM预测模型具有较高的预测准确性。
2) SVM预测模型二分类评估结果。二分类评估对SVM预测模型的预测结果进行统计分析,评估结果如表5所示。其中,AUC和F1-Score的结果均高于0.900,表明模型的预测准确性高,具有较好的可用性。
通过LR二分类和SVM两种机器学习算法对同一机器学习数据源进行并行训练、预测以及预测结果评估,经过这2种不同机器学习算法的相互验证,验证了基于医学检验数据构建的BMT预测模型具有较高的预测水平。
4 讨论
限于篇幅,仅以红细胞体积分布宽度(red cell distribution width,RDW) 、嗜碱性粒细胞(basophilic granulocyte ratio,BASO) 等部分检验项目为例进行分析。研究发现,权重排名第1的RDW,张璐璐等人[9]的研究发现乳腺癌组的RDW高于健康对照组,说明RDW与乳腺癌存在一定的相关性。而排名第4的BASO,高鹰等人[10]的研究发现BASO升高可增加女性良性乳腺结节的发病风险,而良性乳腺疾病又会增加乳腺癌的发病风险。权重排名第6的平均红细胞体积(erythrocyte mean corpuscular volume,MCV) ,谢晓琳等人[11]的研究发现乳腺癌组患者的MCV明显高于对照组,其差异具有统计学意义。权重排名第10的乙型肝炎病毒核心抗体(HBcAb) ,Lin-Jie Lu等人[12]的研究表明乳腺癌患者的HBcAb阳性率明显高于对照组,因此,暴露于乙型肝炎病毒感染可能是乳腺癌的一个危险因素,可能与中国女性乳腺癌发病高峰年龄较早有关。权重排名第十五的尿糖(glucose in urine,GLU) ,李军涛等人[13]发现伴有糖尿病的乳腺癌患者的肿瘤复发、转移率相对高于血糖正常的乳腺癌患者,研究表明糖尿病可能是增加乳腺癌复发、转移的一个危险因素。
本研究基于医学检验大数据采用LR二分类和SVM两种ML算法构建BMT预测模型,实验结果表明预测水平较高,具有可行性。通过LR二分类预测模型可以直观地展示医学检验项目与BMT诊断结果的关联关系,不仅印证了国内外相关研究结果,而且为进一步研究提供了潜在的方向。考虑到BMT的复杂性,本研究用机器学习算法对既往医学检验数据进行计算建模,还需要更多的医学检验数据来优化。未来将持续治理数据、优化算法,提升模型的预测能力,使其成为一种方便、快捷、简单的BMT预测手段,真正能够大规模用于临床筛查。
参考文献:
[1] YU Z P,TANG S L,MA H B,et al.Association of serum adiponectin with breast cancer[J].Medicine,2019,98(6):e14359.
[2] 黎立喜,马飞.乳腺癌筛查和早期诊断的血液生物学标志物[J].国际肿瘤学杂志,2021,48(2):109-112.
[3] 李林海.常见肿瘤标志物的临床应用及进展[J].中华检验医学杂志,2016,39(12):995-998.
[4] 沈胤晨,韩晓红.外周血肿瘤标志物的筛选策略及临床应用[J].中华检验医学杂志,2013,36(11):961-964.
[5] 郭杰,劉海东,韦琴,等.基于检验大数据的结直肠癌风险预测模型建立与验证[J]. 中华检验医学杂志, 2021(10): 914-920.
[6] 王正,王金申,刘志,等.基于人体血液学检测的机器学习辅助泌尿系肿瘤筛查[J]. 泌尿外科杂志(电子版), 2017(04): 9-14.
[7] 牟冬梅,任珂.三种数据挖掘算法在电子病历知识发现中的比较[J].现代图书情报技术,2016(6):102-109.
[8] 任丽,刘洋洋,童莹,曹雪虹,等.乳腺肿瘤超声图像的多特征提取及分类研究[J].中国医疗器械杂志, 2020(4): 294-301.
[9] 张璐璐,刘芸,段文冰,等.乳腺癌患者部分外周血指标的变化及肿瘤标志物的诊断价值[J].中国医药,2018,13(3):421-425.
[10] 高鹰,魏玮,樊娜,等.外周血嗜碱性粒细胞水平升高与女性良性乳腺结节发病风险的关联:基于乳腺超声队列研究[J].现代肿瘤医学,2021,29(21):3755-3760.
[11] 谢晓琳,阳小群,李梦璐,等.乳腺癌患者血液学指标和临床特征分析[J].海南医学,2019,30(2):186-188.
[12] LU L J,ADHIKARI V P,ZHAO C X,et al.Clinical study on the relationship between hepatitis B virus infection and risk of breast cancer:a large sized case-control and single center study in southwest of China[J].Oncotarget,2017,8(42):72044-72053.
[13] 李军涛,张恒伟,郭旭辉,等.高糖对人乳腺癌细胞体外侵袭能力的影响[J].中华医学杂志,2013,93(2):89-92.
【通联编辑:唐一东】
猜你喜欢
东方教育(2016年9期)2017-01-17
中国经贸(2016年21期)2017-01-10
中国水运(2016年11期)2017-01-04
商情(2016年43期)2016-12-23
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
经济师(2016年10期)2016-12-03
价值工程(2016年29期)2016-11-14
科学与财富(2016年28期)2016-10-14
