
基于多模态融合的深度神经网络图像复原方法
2024-05-15 01:44李伟伟王丽妍傅博王娟黄虹
吉林大学学报(理学版) 2024年2期
关键词:图像复原
李伟伟 王丽妍 傅博 王娟 黄虹


摘要: 针对水下图像成像环境复杂常受偏色等因素干扰而影响后续图像分析的问题, 提出一种基于多尺度特征与三重注意力多模态融合的深度卷积神经网络图像复原方法. 首先, 深度卷积神经网络在抽取图像空间特征的基础上, 引入图像多尺度变换特征; 其次, 通过通道注意力、 监督注意力和非局部注意力, 挖掘图像特征的尺度间相关性、 特征间相关性; 最后, 通过设计多模态特征融合机制, 将上述两类特征有效融合. 在公开的水下图像测试集上进行测试并与当前主流方法进行对比的实验结果表明, 该方法在峰值信噪比、 结构相似性等定量对比以及颜色、 细节等定性对比上都优于对比方法.
关键词: 多模态融合; 深度神经网络; 三重注意力; 图像复原
中图分类号: TP391文献标志码: A文章编号: 1671-5489(2024)02-0391-08
Deep Neural Network Image Restoration MethodBased on Multimodal Fusion
LI Weiwei1, WANG Liyan2, FU Bo2, WANG Juan1, HUANG Hong1
(1. School of Information Engineering, Shandong Youth University of Political Science, Jinan 250103, China;2. School of Computer and Artificial Intelligence, Liaoning Normal University,Dalian 116081, Liaoning Province, China)
Abstract: Aiming at the problems of the complicated underwater image imaging environment resulted in the subsequent image analysis often being affected by color bias and other factors, we proposed a deep convolutional neural network image restoration method based on multi-scale features and triple attention multimodal fusion. Firstly, the deep convolutional neural network introduced the image multi-scale transformation feature on the basis of extracting the image spatial feature. Secondly, by using channel attention, supervised attention and non-local attention, the scale correlation and feature correlation of image features were mined. Finally, by designing a multimodal feature fusion mechanism, the above two types of features could be effectively fused. The proposed method was tested on the open underwater image test set and compared with the current mainstream methods. The results show that this method is superior to the comparison method in quantitative comparison such as peak signal-to-noise ratio and structural similarity, as well as qualitative comparison such as color and details.
Keywords: multimodal fusion; deep neural network; triple attention; image restoration
随着人工智能技术的不断发展, 深度学习中神经网络强大的自学习能力在图像处理领域具有至关重要的作用, 目前已将其应用于自然图像处理[1]中, 并取得了显著成果.在海洋能源勘探、 海洋环境保护以及海洋物种分析等领域, 水下图像包含了大量的海洋资源视觉信息, 是人们观察和探索海洋的重要载体. 但由于水下复杂的成像环境及光线吸收等各种干扰因素的影响, 真实水下图像的获取通常很困难. 在水下图像采集过程中, 图像视觉质量常会降低, 例如图像模糊、 偏色、 有噪声等, 无法获取有效且准确的图像视觉内容, 进而严重影响后续的图像分析任务. 因此, 通过水下图像复原方法, 提升图像清晰度、 丰富图像细节信息, 对海洋资源的探索利用和海洋生物的分类识别等具有重要意义. 目前, 水下图像复原方法已取得了许多研究成果. 早期传统的水下图像复原方法大多数是基于先验知识和物理模型的设计, 达到图像恢复的效果. Trucco等[2]设计了一种自调谐图像复原滤波器, 其基于简化的Jaffe-McGlamery水下成像模型设计, 对图像局部对比度质量判决函数进行优化, 进而估计出滤波器中的参数值; Fan等[3]对解决水下图像复原任务, 提出了新的点扩散函数(PSF)和调制解调函数(MFT), 图像先经过算数平均滤波后, 再用迭代盲反褶积方法得到去噪图像的初始点扩散函数的理想值, 最后得到图像复原的效果; He等[4]针对有雾图像提出了暗通道先验算法复原. 之后很多研究者都对暗通道进行了研究, 并应用于水下图像复原. Galdran等[5]合理地利用水下图像衰减与光波长的关系, 提出了一种R通道复原方法用于处理水下图像, 提高了图像的颜色校正和清晰度; Cheng等[6]利用R通道先驗, 通过分析PSF的物理特性, 提出了一种简单、 有效的低通滤波器复原水下图像, 从而提高水下图像的对比度和可见度; 张凯等[7]通过水下图像亮度通道下的多尺度Retinex(MSR)算法处理, 提出了一种基于多尺度的Retinex算法, 对水下彩色图像的全局视觉效果有很大提升; Sharanya等[8]分别使用了直方图均衡、 噪声降噪滤波器和基于二阶方向导数的重复插值方法提高水下图像质量, 增强细节信息. 尽管上述传统方法在一定程度上可以减少图像模糊程度、 增强边缘、 改善偏色, 但由于数据少导致模型的适用性较差, 并且模型中的参数需要手动设置, 因此只适用于退化程度较小的图像.
近年来, 基于深度学习的水下图像复原方法逐渐成为主流. 例如: Li等[9]利用水下图像及其深度学习数据训练一种可粗略地估计出水下场景深度的端到端网络; Fabbri等[10]提出了一种UGAN网络用于水下图像复原, 首先采用CycleGAN网络[11]将高质量的水下图像渲染为低质量的水下图像, 得到数据集后再通过网络训练改善水下视觉场景质量; Li等[12]提出了一种WaterNet网络用于水下图像, 构建水下增强基准以建立水下图像增强网络; Islam等[13]从图像内容、 颜色、 纹理细节等方面恢复水下图像, 通过对目标函数多方式调整提出了一种FUnIE-GAN网络. 但上述算法泛化能力较弱, 网络结构设计较浅, 网络本身无法学习到图像的全部特征.
无论是传统算法还是基于深度学习的方法, 大多数是提取出单一的数据特征进行处理, 从而达到图像复原的效果. 尽管深度学习方法在去噪和去除偏色问题等各方面都表现出了明显优势, 但单一的数据类型更多地限制了网络学习图像自身更多信息的能力, 无法关注到更多类型的数据特征. 因此, 本文提出一种新的水下图像复原模型框架基于多尺度特征与三重注意力多模态融合的深度神经网络水下图像复原方法. 该方法在深度学习框架下, 将图像数据特征和小波数据特征有效融合, 学习更多的高低频信息. 同时, 在网络框架中采用3种注意力模块, 可以同时去除噪声和恢复图像颜色, 挖掘图像更多的细节特征, 有效提升图像的视觉质量.
1 图像复原整体架构
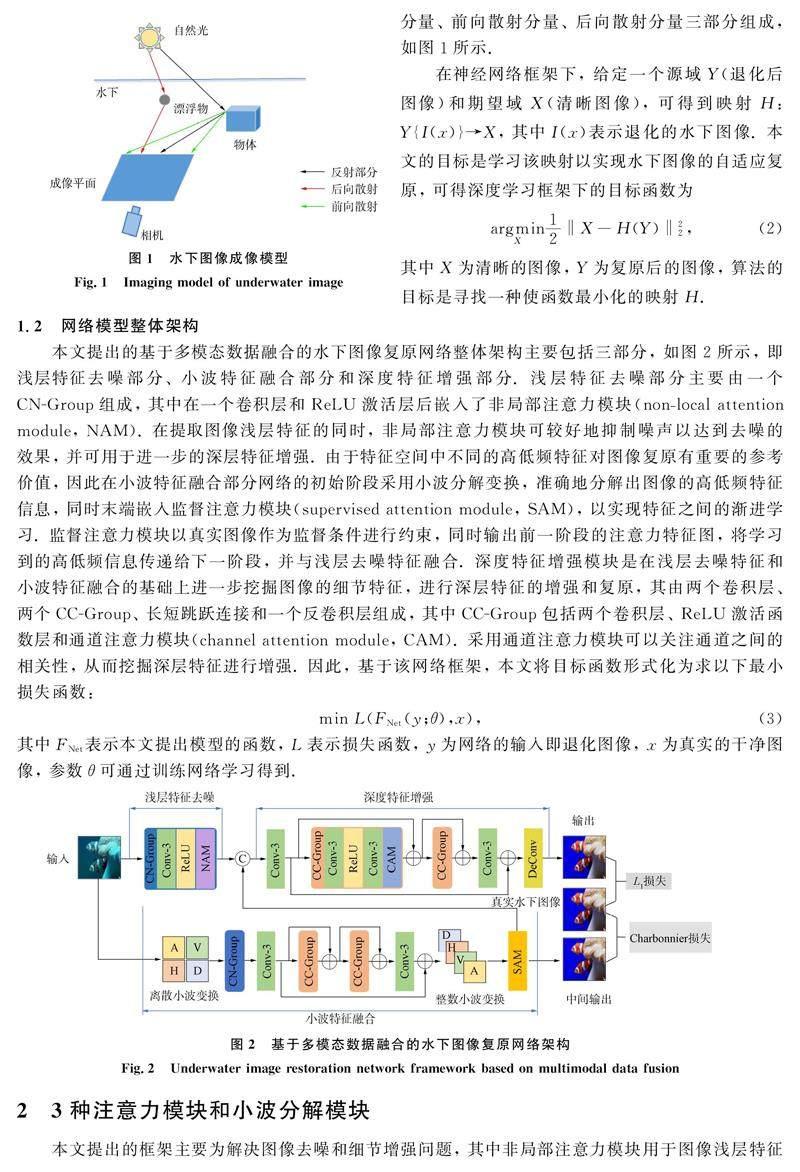
1.1 水下图像成像模型
水下圖像的生成通常遵循以下模型:
I(x)=J(x)t(x)+A(1-t(x)),(1)
其中x表示水下图像中第x个像素, I(x)表示退化后的原始图像, J(x)表示清晰图像, J(x)t(x)表示直接分量, A(1-t(x))表示背景散射分量, A表示水下环境光, t(x)表示场景光透射率.
式(1)根据Jaffe-MeGlamery[1]水下成像模型而得, 水下成像主要由相机接收到光线衰减后的直接分量、 前向散射分量、 后向散射分量三部分组成, 如图1所示.
在神经网络框架下, 给定一个源域[WTBX]Y(退化后图像)和期望域X(清晰图像), 可得到映射H: Y{I(x)}→X, 其中I(x)表示退化的水下图像. 本文的目标是学习该映射以实现水下图像的自适应复原, 可得深度学习框架下的目标函数为argminX 1/2‖X-H(Y)‖22,(2)其中X为清晰的图像, Y为复原后的图像, 算法的目标是寻找一种使函数最小化的映射H.
1.2 网络模型整体架构
本文提出的基于多模态数据融合的水下图像复原网络整体架构主要包括三部分, 如图2所示, 即浅层特征去噪部分、 小波特征融合部分和深度特征增强部分. 浅层特征去噪部分主要由一个[WTBZ]CN-Group组成, 其中在一个卷积层和ReLU激活层后嵌入了非局部注意力模块(non-local attention module, NAM). 在提取图像浅层特征的同时, 非局部注意力模块可较好地抑制噪声以达到去噪的效果, 并可用于进一步的深层特征增强. 由于特征空间中不同的高低频特征对图像复原有重要的参考价值, 因此在小波特征融合部分网络的初始阶段采用小波分解变换, 准确地分解出图像的高低频特征信息, 同时末端嵌入监督注意力模块(supervised attention module, SAM), 以实现特征之间的渐进学习. 监督注意力模块以真实图像作为监督条件进行约束, 同时输出前一阶段的注意力特征图, 将学习到的高低频信息传递给下一阶段, 并与浅层去噪特征融合. 深度特征增强模块是在浅层去噪特征和小波特征融合的基础上进一步挖掘图像的细节特征, 进行深层特征的增强和复原, 其由两个卷积层、 两个CC-Group、 长短跳跃连接和一个反卷积层组成, 其中CC-Group包括两个卷积层、 ReLU激活函数层和通道注意力模块(channel attention module, CAM). 采用通道注意力模块可以关注通道之间的相关性, 从而挖掘深层特征进行增强. 因此, 基于该网络框架, 本文将目标函数形式化为求以下最小损失函数:min L(FNet(y;θ),x),(3)其中FNet表示本文提出模型的函数, L表示损失函数, y为网络的输入即退化图像, x为真实的干净图像, 参数θ可通过训练网络学习得到.
2 3种注意力模块和小波分解模块
本文提出的框架主要为解决图像去噪和细节增强问题, 其中非局部注意力模块用于图像浅层特征去噪; 而通道注意力机制模块用于图像增强, 恢复更多图像细节; 小波分解变换下的特征融合, 在整个网络框架中具有核心的作用.
2.1 非局部注意力模块
对于图像去噪, 传统的非局部均值(non-local means, NLM)[14]算法通过采用非局部滤波器进行滤波操作, 计算所求像素值与图像中所有点的相似度, 加权平均得到新的像素值, 从而达到去噪的效果. 其计算公式为u(x)=∑y∈Iw(x,y)v(y),(4)其中: v表示噪声图像; u表示去噪后的图像; w表示加权平均的权重; x和y分别表示当前像素和相关性像素的位置, 通过计算两者相似程度赋以权重w(x,y), 通常采用欧氏距离计算二者的相似度.
由于注意力机制可帮助卷积神经网络重点关注图片的一些局部信息生成相应的序列, 因此, 借鉴非局部均值的思想, 本文将非局部算子模块化, 嵌入到CN-Group中, 形成非局部注意力模块NAM, 如图3所示. 在非局部注意力模块中, 采用卷积操作和残差连接实现该算法的思想, 可以随意插入到任何网络结构中. 首先, 采用3个1×1大小的卷积层, 提取到3个特征矩阵θ,,g; 其次, 为减少计算量, 对输出的特征进行降维, 然后计算其中两个输出的特征相似性, 并对其进行Softmax操作进行归一化; 最后, 将归一化后的系数对应乘回特征矩阵g中, 再经过一个1×1大小卷积层得到相应的通道数, 并与输入做残差连接, 从而得到与输入大小一致的非局部结果,
2.2 监督注意力模块
在小波特征融合部分的末端, 嵌入监督注意力模块. 在网络训练过程中, 中间特征的监督具有一定的参考价值. 监督注意力模块不仅提供真实图像作为监督形成约束条件, 还将小波变换后学习到的特征更好地融入到浅层去噪特征中, 主要表现在生成注意力特征图抑制当前信息较少的特征, 只允许有用的特征传递给下一阶段, 其结构如图4所示. 首先, 前一阶段的输入特征fin被一个3×3的卷积层卷积得到的特征叠加在退化图像Input上, 通过真实图像监督计算Charbonnier损失, 从而得到中间输出Inter_output. 然后, 中间输出被一个1×1卷积层和Sigmoid函数激活后, 并与输入特征fin经过一个3×3的卷积层后的特征点乘, 其结果与输入特征fin融合得到输出的注意力特征图fout, 并将其用于小波特征和浅层去噪特征的融合. 本文将此过程用网络的形式描述为
2.3 通道注意力模块
在深层特征增强部分中的CC-Group中, 本文嵌入了通道注意力模块, 如图5所示, 它可以更多关注重要的通道特征, 对深层特征的提取和增强有极大的辨识能力, 从而进行网络深层次特征增强和细节纹理恢复. 将通道注意力模块嵌入到CC-Group中, 同时伴有残差连接, 即使在更深层次的网络中, 也能利用通道之间的相互依赖关系, 提取有用的特征信息. 通道注意力模块由一个平均池化层、 两个卷积层、 ReLU激活函数和Sigmoid激活函数以及残差连接组成. 首先, 输入特征经过一个池化层对其下采样得到压缩后的特征图; 然后, 经过两次卷积和ReLU激活函数先后使通道降维再升维, 从而学习了多个通道之间的非线性相互作用; 最后, 被Sigmoid函数激活后, 其输出与输入相乘得到等大的输出结果. 本文将此过程用网络形式描述为
2.4 小波分解模块
通过卷积得到的特征大多数存在显著性. 因此, 本文引入小波变换将图像分成低频和高频小波子带, 然后将它们输入到浅层去噪和深层增强部分进一步学习和挖掘深层特征信息, 如图2所示. 小波变换[15]有助于减少信息损失, 能较好地重构原始图像内容, 采用离散小波变换(DWT)和整数小波变换(IWT)可以更好地将小波特征和浅层去噪特征融合. 本文采用Haar小波核, 用4个卷积核提取不同频率分量, 分别表示直流、 横向、 纵向、 斜向上的能量, 用公式表示为[WTHX]f[WTBX]LL=1/1
经过DWT后, 大小为(B,C,H,W)的图像可以变成大小为(B,4C,H/2,W/2)的小波带, 其中B,H,W,C分别表示批次尺寸、 高度、 宽度和通道数. 这样可以降低计算成本, 有助于加快训练过程. 在网络训练过程中, DWT后输出的特征图通道为12, IWT后输出的特征图通道数变为16, 卷积层输出的特征图通道为64, 因此, 融合小波特征后的卷积层其输入通道数为80, 输出通道数为64. 特别地, 小波变换是双向的, 能适用于端到端的网络训练. 小波分解变化用公式表示为fout=DWT(Input).(8)
2.5 损失函数
基于多模态数据融合的水下图像复原网络框架的整体损失函数如下:L=L1(Output,GT)+LCharbonnir(Inter_output,GT),(9)其中L1和LCharbonnir分别表示L1损失和Charbonnier损失函数[16], GT表示真实水下图像, Output表示整体网络复原后的图像, Inter_output表示经过监督注意力模块得到的输出图像. Charbonnier损失进行约束在于利用真实图像监督提取有用的特征, 其损失函数形式如下:LCharbonnir=‖Inter_output″-GT‖2+ε2.(10)為防止网络梯度消失, 这里ε为常数, 经验设置为10-3.
3 实 验
3.1 实验设置
本文算法的实验操作基于Windows 10操作系统、 PyTorch深度学习框架和NVIDIA GeForce RTX 3090 GPU. 采用EUVP中的Underwater Dark水下图像数据集, 其中包括5 550对已配对的训练图像和570张验证图像. 在实验过程中, 本文选用5 550对已配对的训练图像中的5 022对配对图像对数据集进行训练, 528对配对图像对数据集进行测试, 另570张图像作为验证图像.
网络训练过程中, 参数batch_size设置为16, patch_size设置为48, 学习率设置为10-4, 采用Adam优化器, 迭代次数epoch为300时网络达到收敛, 同时采用最优模型进行测试. 此外, 为验证去噪效果, 在原有数据集上模拟高斯噪声进行训练和测试.
采用其他4种现有的深度学习图像复原算法作为对比算法, 分别是CycleGAN[17],FUnIE-GAN[11],Shallow-UWnet[18]和RCAN[19]. 为保证实验的公平性和可靠性, 所有算法均采用与本文相同的训练集与测试集. 在评价图像质量上, 除主观视觉观察外, 还采用峰值信噪比(PSNR)和结构化相似性(SSIM)两个客观评价指标.
3.2 实验结果分析
本文对所有算法均在统一测试集上进行测试, 并且分别模拟了高斯噪声强度为5,10和15的测试集, 对PSNR和SSIM分别进行对比, 其量化结果列于表1. 由表1可见, 本文算法测试结果在PSNR和SSIM分数上明显突出. 为进一步展示视觉效果, 在噪声强度为10的情况下, 选择测试集中6张不同的图像进行对比, 其复原结果如图6所示.
由图6可见, 相比于其他水下复原算法, 本文算法无论在去噪还是恢复图像细节纹理上都有很大优势, 尤其是在解决偏色问题上更突出. 在6张对比图像中, 前3张和后3张图像处于不同颜色范围, 前3张图像均处于偏蓝绿色, 而后3张图像颜色更丰富, 本文提出的算法都能较好地解决偏色问题. 因此, 本文提出的基于多模态数据融合的水下图像复原算法可较好地复原退化的水下图像.
3.3 消融实验
为进一步验证本文算法融合小波特征和3种注意力模块的有效性, 对增加的不同模块做消融实验. 在噪声强度为10的情况下, 增加不同模块的量化结果列于表2.
具体实验内容如下: 1) 有小波分解模块情况下, 只带有通道注意力模块; 2) 有小波分解模块情况下, 只带有非局部注意力模块; 3) 有小波分解模块情况下, 只带有通道注意力模块和非局部注意力模块; 4) 无小波分解模块情况下, 带有通道注意力模块、 非局部注意力模块和监督注意力模块; 5) 有小波分解模块情况下, 带有通道注意力模块、 非局部注意力模块和监督注意力模块. 消融实验视觉效果如图7所示.
由表2和图7可见, 方法1)~4)考虑了累加不同注意力模块的表现情况, 而方法4)和5)验证了小波分解模块的优势. 因此, 无论是从视觉效果还是客观评价结果都可得出结论: 本文算法在水下图像的恢复方面与其他算法相比有一定的优势.
综上所述, 针对水下图像偏色失真问题, 本文提出了一种基于多尺度特征与三重注意力多模态融合的深度卷积神经网络水下图像复原方法, 突破了单模态对神经网络学习的限制. 在使用深度卷积神经网络提取图像空间特征时, 引入了图像多尺度变换特征. 通过通道注意力、 监督注意力和非局部注意力挖掘图像特征的尺度间相关性和特征间相关性. 在公开的水下图像测试集进行测试, 并与其他方法进行对比的实验结果证明了本文方法的优越性.
参考文献
[1]DONG C, LOY C C, HE K M, et al. Learning a Deep Convolutional Network for Image Super-resolution [C]//European Conference on Computer Vision. Berlin: Springer, 2014: 184-199.
[2]TRUCCO E, OLMOS-ANTILLON A T. Self-tuning Underwater Image Restoration [J]. IEEE Journal of Oceanic Engineering, 2006, 31: 511-519.
[3]FAN F, YANG K C, MIN X, et al. Underwater Image Restoration by Means of Blind Deconvolution Approach [J]. Frontiers of Optoelectronics in China, 2010, 3: 169-178.
[4]HE K M, SUN J, TANG X O, et al. Single Image Haze Removal Using Dark Channel Prior [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2011, 33(12): 2341-2353.
[5]GALDRAN A, PARDO D, PICN A, et al. Automatic Red-Channel Underwater Image Restoration [J]. Journal of Visual Communication & Image Representation, 2015, 26: 132-145.
[6]CHENG C Y, SUNG C C, CHANG H H. Underwater Image Restoration by Red-Dark Channel Prior and Point Spread Function Deconvolution [C]//2015 IEEE International Conference on Signal and Image Processing Applications (ICSIPA). Piscataway, NJ: IEEE, 2015: 110-115.
[7]張凯, 金伟其, 裘溯, 等. 水下彩色图像的亮度通道多尺度Retinex增强算法 [J]. 红外技术, 2011(11): 14-18. (ZHANG K, JIN W Q, QIU S, et al. Multi-scale Retinex Enhancement Algorithm on Luminance Channel of Color Underwater Image [J]. Infrared Technology, 2011(11): 14-18.)
[8]SHARANYA R S, RAMESH R. Haze-Free Underwater Image Enhancement [J]. International Journal of Innovative Research and Development, 2013, 2(3): 533-543.
[9]LI J, SKINNER K A, EUSTICE R M, et al. WaterGAN: Unsupervised Generative Network to Enable Real-Time Color Correction of Monocular Underwater Images [J]. IEEE Robotics and Automation Letters, 2017, 3(1): 387-394.
[10]FABBRI C, ISLAM M J, SATTAR J. Enhancing Underwater Imagery Using Generative Adversarial Networks [C]//2018 IEEE International Conference on Robotics and Automation (ICRA). Piscataway, NJ: IEEE, 2018: 7159-7165.
[11]ZHU J Y, PARK T, ISOLA P, et al. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks [C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2017: 2223-2232.
[12]LI C Y, GUO C L, REN W Q, et al. An Underwater Image Enhancement Benchmark Dataset and Beyond [J]. IEEE Transactions on Image Processing, 2019, 29: 4376-4389.
[13]ISLAM M J, XIA Y, SATTAR J. Fast Underwater Image Enhancement for Improved Visual Perception [J]. IEEE Robotics and Automation Letters, 2020, 5(2): 3227-3234.
[14]BUADES A, COLL B, MOREL J. A Non-local Algorithm for Image Denoising [C]//Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2005: 60-65.
[15]LIU P J, ZHANG H Z, LIAN W, et al. Multi-level Wavelet Convolutional Neural Networks [J]. IEEE Access, 2019, 7: 74973-74985.
[16]CHARBONNIER P, BLANC-FRAUD L, AUBERT G, et al. Two Deterministic Half-Quadratic Regularization Algorithms for Computed Imaging [C]//Proceedings of 1st International Conference on Image Processing. Piscataway, NJ: IEEE, 1994: 168-172.
[17]ISLAM M J, XIA Y, SATTAR J. Fast Underwater Image Enhancement for Improved Visual Perception [J]. IEEE Robotics and Automation Letters, 2020, 5(2): 3227-3234.
[18]NAIK A, SWARNAKAR A, MITTAL K. Shallow-UWnet: Compressed Model for Underwater Image Enhancement [C]//Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 15853-15854.
[19]ZHANG Y L, LI K P, LI K, et al. Image Super-resolution Using Very Deep Residual Channel Attention Networks [C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 294-310.
(責任编辑: 韩 啸)
收稿日期: 2022-08-07.
第一作者简介: 李伟伟(1981—), 女, 汉族, 硕士, 副教授, 从事图形图像与深度学习的研究, E-mail: lww@sdyu.edu.cn.
通信作者简介: 傅 博(1983—), 男, 汉族, 博士, 副教授, 从事图像处理与计算机视觉的研究, E-mail: fubo@lnnu.edu.cn.
基金项目: 国家自然科学基金(批准号: 61702246)和山东青年政治学院博士科研启动基金(批准号: XXPY21025).
猜你喜欢
农业工程学报(2022年14期)2022-10-19
石家庄铁路职业技术学院学报(2019年3期)2019-10-30
数码世界(2017年12期)2017-12-28
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20
科技资讯(2016年27期)2017-03-01
计算机应用(2016年12期)2017-01-13
光学精密工程(2016年2期)2016-11-07
中国高新技术企业(2015年36期)2016-03-03
航天返回与遥感(2014年4期)2014-07-31
长江大学学报(自科版)(2014年7期)2014-03-20
