
抽象语义表示解析方法研究综述
2024-05-09 02:29卢懿亮季跃蕾吴梓浩彭亚男
中文信息学报 2024年3期
尹 华,卢懿亮,季跃蕾,吴梓浩,彭亚男
(1. 广东财经大学 信息学院,广东 广州 510320;2. 广东省智能商务工程技术研究中心,广东 广州 510320;3. 广州商学院 现代信息产业学院,广东 广州 511363)
0 引言
语义分析是自然语言处理领域亟待突破的瓶颈,精准把握自然语言语义需要准确且完备的语义表示方法。语义表示的目标是将人类理解的自然语言以一种语义等价的形式转化为计算机能够理解的表示,以获得更好的计算性。根据文本划分粒度,语义分析可以从词汇、句子和篇章三个层级展开,其中句子级语义分析通过句子中的句法信息和词语含义,推导出反映该句含义的某种形式表示[1]。语义角色标注(Semantic Role Labeling,SRL)[2]是研究句子级语义问题的一种简单直接的方法。SRL的理论基础来源于Filmore提出的格语法[3],以句子的谓词为中心,分析句子的谓词-论元结构,即句子中各成分与谓词之间的关系,用语义角色来描述它们之间的关系。SRL的表示方法不针对整句进行详细语义分析,忽视句子中的其他修饰信息,导致语义信息缺失,是一种浅层语义分析方法。为了尽可能完整地保留语义信息,需要对句子进行深层分析。语义依存分析方法(Semantic Dependency Parsing,SDP)[4]分析句子各个语言单位之间的语义关联,并将语义关联以依存结构呈现,是一种深层语义理解的表示方式。除此之外还有一些具有代表性的语义表示方式,例如,组合范畴文法(Combinatory Categorial Grammar,CCG)[5]和抽象语义表示(Abstract Meaning Representation,AMR)[6]。CCG的语义不依赖于语义词典,一般被认为是一种特定领域的语义表示方法[1]。Banarescu等提出的AMR则是一种领域无关的通用语义形式化表示,一定程度上缓解了跨领域整句标注的开销问题,并补充了整句层面的语义表示。AMR目前已经被有效应用在机器翻译[7]、文本摘要[8]、信息抽取[9]、对话系统[10]等场景。
2013年,美国宾夕法尼亚大学的语言数据联盟(Linguistic Data Consortium,LDC)、南加州大学、科罗拉多大学等科研机构的多名学者共同提出AMR定义、AMR标注规范体系以及英文《小王子》AMR标注语料库。AMR将句子抽象成由语义概念节点和语义关系标签弧构成的有向无环图,以此消除句法特质,并从句法事实中捕捉句子的核心语义。其在原有浅层语义分析(如SRL)的基础上,进一步以图的形式表征较为复杂的多谓词支配单名词的论元共享现象,并且支持对概念节点进行增删改操作,以补充隐含语义信息,进而能够完整且无损地表示深层句子语义。2014年,Flanigan等人[11]率先提出解析器JAMR。其后,有关AMR的相关研究引起了国内外学者的关注。围绕AMR标注、AMR解析、AMR生成以及AMR应用的研究相继展开。
我们采用CiteSpace对CNKI、Web of Science和 SCOPUS数据库中自2013年至2023年的文献统计发现,AMR研究主体呈现增长趋势,如图1所示。
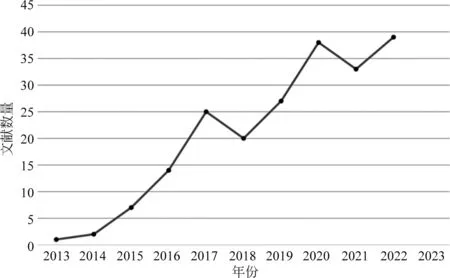
图1 AMR研究趋势图
通过设置时间切片为1,节点类型为“Institution”“Author”,选择研究AMR的英文文献,得到研究作者-机构共现图,共245个节点、551条边,网络密度为0.018 4,如图2所示。相关研究成果数量较为丰富, 其中以Brandeis大学和IBM Research等研究机构为主导。

图2 AMR英文文献作者-机构共现图
同时,选择研究AMR的中文文献,得到研究作者-机构共现图,共91个节点,201条边,网络密度为0. 049 1,如图3所示。

图3 AMR中文文献作者-机构共现图
聚焦于AMR研究领域的国内代表性研究机构有南京师范大学和苏州大学等,但是国内研究成果数量相对国外较少,尚有较大的发展空间。从AMR研究内容体量看,大部分集中于AMR解析,如图4所示,因此本文主要聚焦于AMR解析方法的研究。

图4 AMR相关研究类别文献统计柱状图
2017年,曲维光等[12]从AMR概念与规范、解析算法和相关应用的视角对AMR研究成果做了系统性的梳理。而由于时效性因素,亟需深入分析近年来涌现的AMR解析方法。本文梳理了自2013年至2023年以来有关AMR的国内外研究文献,首先阐述作为AMR研究基础的语料库研究现状与进展;然后从解析的角度分析研究中的难点问题;再根据AMR解析策略,将AMR解析算法分为四类: 基于图的、基于转移的、基于序列到序列(Seq2Seq)的和基于形式化的解析方法,并揭示了算法背后的核心思想及其面临的挑战。最后,对现有经典AMR解析算法性能进行归纳整理和比较,进一步展望AMR解析任务未来的研究方向。
1 AMR语料库
AMR图是一个单根有向无环图。节点表示语义概念,由句子中的实词抽象获得。边为带有语义关系标签的有向弧,由实词之间的关系抽象获得。Banarescu等[6]提出AMR时建立了统一的标注规范,涵盖约一百种概念关系及其逆关系。此外,每一种关系都可以具象化为概念节点[12],并基于该规范开发了英文《小王子》AMR标注语料库。
AMR标注体系和公开语料库的维护由LDC负责,该组织相继发布了LDC2017T10(AMR 2.0)、LDC2020T02(AMR 3.0)等语料库。AMR 3.0扩充了AMR 2.0的规模,共包含来自新闻、广播、论坛、网络文本等59 255条自然语言文本的语义树库。表1为常用AMR语料库信息,均可从LDC(1)https://www.ldc.upenn.edu/获取。

表1 AMR语料库
由于英文中的虚词相对实词而言意义不大,为了简化并加速标注流程,英文AMR的标注规范忽略了冠词、虚词、时态、单复数等语言现象。以句子“The boy wants to drink water.”为例,该句的AMR图及序列化表示如图5所示。解析过程中,首先对句子中概念进行实例化操作并生成对应的概念节点“boy”“want-01”“drink-01”“water”,分别根据单词的首字母对概念节点命名(如“boy”对应“b”)。当谓词存在不同义项时,可能会导致论元与谓词的语义关系不明确。因此,AMR图中标注有谓词的义项信息,如谓词“drink”被标注为“drink-01”,这表示采用“drink”的第一个义项。AMR图中有向弧标注“:ARG0”“:ARG1”分别代表了概念关系“施事对象”与“受事对象”,例如,根节点“want-01”和“boy”之间的有向弧标注“:ARG0”表示了“boy”为“want”的施事对象,而同理“drink”为“want”的“受事对象”。

图5 英文句子“The boy wants to drink water.”的AMR图表示形式及其序列化表示形式
英文的特性并不适应于所有语种,不同语种引入AMR标注规范的过程可能会有所差异。近年来,AMR对非英文语种的研究陆续开展。根据语言的不同特点,研究者们分别建立了西班牙语[13]、韩语[14]、土耳其语[15]和巴西葡萄牙语[16]的AMR标注规范及标注语料库。
南京师范大学的李斌等[17]借鉴英文AMR的标注框架和理论,率先设计了中文AMR标注规范,并标注了对标英文《小王子》的中文《小王子》AMR标注语料库。随后,进一步针对汉语特性,在虚词表示、概念关系对齐和特殊语法现象等方面改进。一方面由于在汉语中虚词对连接上下文有较大的作用,一定程度上表征了上下文语义信息,故而其保留了虚词并进行标注;另一方面,英文AMR缺少概念对齐信息,这为AMR自动解析带来了不便,故而其通过在中文AMR标注中引入编号,实现了概念对齐信息的融合,构建了中文AMR标注体系[18]。
2019年,南京师范大学联合布兰迪斯大学基于中文谓词库(CPB)的谓词框架词典对中文宾州树库(Chinese Penn TreeBank 8.0,CTB)中的博客、论坛等文本标注,构建了首个较大规模的中文AMR标注语料库CAMR 1.0,并于2021年在CAMR 1.0的基础上进一步标注CTB 8.0中新闻网络等文本,发布了CAMR 2.0。
AMR标注规范和语料库为AMR解析、生成和应用等各项任务奠定了数据基础。AMR解析器性能强依赖于概念和关系的正确识别,需要完善的AMR概念关系集合和一定规模的多领域语料库。现有的AMR语料库一方面在规模上相对有限,难以满足主流的数据驱动的语言模型;另一方面所涉及领域有限,例如,在法律[19]、医疗[20]等特定领域中语料库的构建基本空缺。由于难以捕捉特定领域专用术语的概念和关系,导致AMR在跨领域下的解析性能相差较大。
2 AMR解析
AMR解析器将自然语言句子无损且准确地转换为AMR图的形式化表征。根据解析模型和解析策略的区别,曲维光等在2017年的综述[12]中将AMR解析算法分为四类: 基于图的方法、基于转移方法、基于组合范畴语法的解析方法和基于机器翻译的解析方法。随后,吴泰中等进一步从中英文AMR解析角度简述AMR解析的研究脉络[21]。对于英文AMR解析方法,根据特征提取方法的不同,将2017年综述中涉及的四种方法归类为人工提取特征的基于统计的模型,并将自动提取特征的基于神经网络的AMR解析模型分为组合特征提取模型、基于循环神经网络的特征提取模型和基于卷积神经网络的特征提取模型。由于该文侧重基于转移的解析方法创新,所以仅简单呈现英文AMR解析的研究进展,并探讨基于转移的中文AMR解析方法。无论哪一种AMR解析器,将句子转化为图的表示过程对于AMR解析任务来说是统一的,均涉及图中节点和边的获取任务。同时,AMR图中的节点和边是一种概念抽象,必然涉及将句子中的文本实例与生成的概念/关系对齐的任务。因此,本文认为AMR解析面临以下三个关键难点问题。
(1) 如何准确地抽取文本中的概念以及概念关系?文本中的单词是概念的具体实例,从实例中抽取抽象概念表示及概念关系表示,涉及传统自然语言任务,既可以分步设计,也可以采用端到端的方式获得。概念抽取的精度和粒度决定了解析效果。
(2) 如何捕捉AMR与对应文本之间复杂的对齐关系?自然语言表达的灵活性(主动、被动表示,英文时态等)增加了对齐任务的复杂度,图6中consider-01这个概念节点在不同句子中所对齐的文本片段可能是不相同的。另外,由于图结构数据的节点可重入性质,文本片段和图中节点的对齐并不是简单的唯一对应关系。所以,捕捉隐式对齐关系是AMR解析任务的一大挑战。

图6 对齐示例
(3) 如何建模并融合文本的结构信息用以指导AMR解析?文本的结构信息包括但不限于句法结构、语义角色标注、AMR本身的图结构等。这些结构信息获取虽然源自不同的研究视角,但是从形式和语义上存在着相通之处,相关早期任务也证明了依存句法结构信息有益于AMR解析任务[22-23]。如何有效地利用这些辅助信息,从多维度的特征中抽象出文本的准确语义,是AMR解析任务面临的一大难题。
3 AMR解析算法
为了AMR研究的传承性,我们综合考虑了文献[12,24]的划分思路,再结合AMR进展,按照解析模型本质以及问题驱动的方法,详细分析AMR解析算法研究脉络。由于中文具有与英文不同的语言特性,英文AMR解析算法不能直接应用于中文AMR解析,且中文AMR解析方法研究起步较晚,文献数量较少。因此,我们将中文AMR解析方法的研究单独分为一个类别。
3.1 基于图的方法
最早提出的JAMR[11]解析器将解析任务建模为图搜索问题: 从由概念关系集合所构成的有向完全图中搜索符合约束的最大生成连通子图。该解析器提供了一种串联式的两阶段通用解析框架: 第一阶段进行概念识别获得概念图片段序列;第二阶段进行关系识别,在满足局部性、简易性、连通性和确定性的约束下,以Smatch得分最高为优化目标,利用带标记的有向弧链接概念图片段获得AMR图,其核心解析思路如图7所示。JAMR为了训练解析器,根据启发式规则,利用基于贪心策略的搜索过程实现句子与AMR图的对齐,建立了自动对齐器。

图7 JAMR核心解析思路
JAMR采用串联式(也称管道式)方式进行概念和关系识别,解析效果高度依赖于概念识别的准确性以及概念识别与关系识别之间的独立性。事实上,概念与关系之间具有强耦合特性,当时的概念识别方法并不能达到理想的准确率。为缓解串联式模型存在的误差传播问题,Zhou等人[25]提出一种增量式联合模型同步执行概念识别和关系识别这两个子任务,即将句子直接映射到AMR图,通过定义概念识别和关系识别的联合解码目标函数,设计搜索概念片段各连通分量之间的最优边集,实现增量式的关系识别。
由于句子中单词与AMR图的对齐并不是显式存在于数据标注中,针对这一问题,Lyu等人[26]考虑到概念、关系和对齐之间的紧密联系,对三者进行联合建模,将AMR解析联合概率模型定义为:
模型包含三个部分: 概念识别模块Pθ(c|a,w)、关系识别模块Pφ(R|a,w,c)以及对齐模块Qψ(a|c,R,w),其中,θ,φ,ψ均为模型中的参数。w是长度为n的句子,W=(w1,…,wn),wk∈V,k∈{1,…,n},其中V为词表;c是个数为m的概念序列c=(c1,…,cm),ci∈C,i∈{1,…,m},其中,C是概念集合;a是对齐序列a={a1,…,am}ai∈{1,…,n}表示第ai个单词对齐第i个概念。R为关系集合。
该联合概率模型将对齐信息视为隐变量,再用神经网络模型求解。由于难以使用深度学习方法求解离散隐变量,他们引入Gumbel-Sinkhorn架构[27]连续松弛化对齐问题,并基于变分自动编码(Variational Auto-Encoder,VAE)[28]架构使其得以采用计算可行的近似化方法对上述联合概率模型进行估算,最终取得了可观的解析性能提升。在该联合模型的基础上,Lyu等人[29]进一步发现,在训练对齐器前对概念子图的分割任务严重依赖现有规则定义,难以适配其他语种语料的分割规则,于是提出对图分割任务进行学习。他们将分割任务和对齐任务建模为一个“节点生成顺序选择”问题并将其作为VAE架构中的隐变量进行处理,最终达到了与基于人工分割规则的方法相当的性能表现。
Zhang等人[30]从图节点的可重入性质角度考虑,当节点有重入边时,复制此类具有多语义关系的节点并构造成树, 将AMR图转化为树结构。进而将标记索引节点的AMR树作为预测目标,把解析任务形式化为一个两阶段过程: 节点预测和边预测。使用扩展的指针生成网络[31]进行节点预测,解决有限AMR标注数据下的学习问题;采用深度双仿射分类器[32]进行边预测,在训练阶段联合学习。该模型不需要显式对齐器,而是通过注意力机制隐式学习源端的节点复制机制,如图8所示。

图8 节点预测的扩展指针生成器网络[32]
此外,有研究者尝试在AMR解析中引用外部结构信息。早期相关研究[22-23]已经证明了依存句法结构有益于AMR解析任务,但其是将结构信息显式地融入模型中。Zhou等人[23]通过实验发现,显式和隐式融入结构信息均可以提高AMR解析性能。他们将输入句子作为概率图生成器的先验来推断隐式的句法依存图结构,并利用图神经网络(Graph Neural Network,GNN)对上述结构信息进行编码,在无对齐器的模型框架下首次提出隐式地融入依存句法结构信息以降低概念识别等子任务的错误率,进而提升解析性能。
图搜索是从全图获得子图的过程,而逐步构造子图则是另一种AMR解析建模的思路,如图9所示。

图9 基于图生成的解析思路
Cai等人[33]提出一种自上而下的增量式图生成解析算法(Graph Spanning based Parsing,GSP)。受“先确定中心思想,再补充相关细节”启发,GSP从根节点开始进行迭代操作,每一步迭代将一个新的节点及其附属关系同步地加入图中,最终实验表明这种方法对于句子中核心语义的捕捉更有优势。在图生成的建模思路下,复杂场景的图生成可以转化为增量构建图的问题。针对长句子和蕴藏丰富语义的句子的复杂解析场景,Cai等人[34]提出了基于迭代推理的求解算法,将AMR解析视为输入序列与增量构建图之间的一系列决策问题,迭代求解互为因果的两个关键问题: ①应该对输入序列中的哪一部分进行抽象?②应该在增量构建图中的何处添加新的概念?迭代推理过程如图10所示。

图10 基于迭代推理的AMR解析算法[34]
3.2 基于转移的方法
基于转移的方法的本质思想来源于有限自动机,其将自然语言解析任务转变为预测一系列转移动作决策问题,根据预先定义的转移动作集合,分析当前转移状态,预测转移动作,如图11所示。通过一个动作序列,逐步建立起句子对应的树状或图状句法语义结构。其关键问题是如何定义转移系统,并根据预先定义的转移动作集合,通过当前转移状态对转移动作进行预测,搜索最优或近似最优的动作序列。

图11 基于转移的方法示意图
Wang等人[35]在基于转移的依存句法解析器的基础上提出了CAMR解析器,将AMR解析转移系统定义为四元组S=(C,T,s0,Ct),其中:
(1)C是转移状态集合;
(2)T是转移动作集合,其中每个转移动作都是CAMR将输入句子和其对应的依存句法树映射为初始状态,而后再执行一系列转移动作,进而实现AMR解析。其后,研究者从提高基础自然语言处理任务准确率、优化转移动作集合、缩小搜索解空间等角度对这一基准模型进行改进[36-38]。
一个函数t:C→C;
(3)s0是一个初始化函数,将输入句子和其对应的依存句法树映射为初始状态。
(4)Ct⊆C是一组终端状态。
CAMR采用依存句法解析器构建了树这一中间表示,再将树转换为图。Damonte等人[39]则实现了直接由文本到图的解析模式,其受到ARC-EAGER转移系统[40]的启发,自左向右顺序读入文本中的词,并根据关系优先的原则,增量式地预测构造AMR图的转移动作序列。
Ballesteros等人[41]认为AMR解析需要解决多个自然语言处理任务,包括命名实体识别、词义消歧和语义角色标注等,而传统管道式方法依赖于前置任务的特征,这使得构建端到端的系统存在难度。他们采用Stack-LSTMs表示转移状态,在转移系统的基础上构造了一个直接由文本到图的端对端解析器。有别于采用外部工具完成依存分析、语义角色标注等任务的方法[39],该解析器利用了神经网络的向量表示将多个自然语言处理任务融于解析模型中,并将训练目标设定为极大化转移动作序列的似然。
Naseem等人[42]认为以上解析器的目标策略存在两个缺陷: 第一是由于转移动作序列的预测与对齐信息密切相关,文本片段与图节点间的对齐不准确/不完备会影响解析结果;第二是即便对齐准确,解析器所生成的转移动作序列也并非唯一的或者最优的转移动作序列,可能导致局部最优而非全局最优。通过组合对齐方法、预处理命名实体和概念、引入上下文向量和应用强化学习自批评序列训练算法(Self-Critical Sequence Training,SCST)[43],将Smatch评测指标作为策略学习中的奖励函数以松弛对齐约束,使得模型得以在更广泛的转移动作空间中寻得最优转移动作序列。同样从优化转移动作搜索空间的角度考虑,Guo等人[44]则关注目标端的AMR图表示,他们将概念分为Lexical和Non- Lexical两类,其中Lexical概念对应于输入句子中的具体词元,Non-Lexical概念则是由子概念产生。通过移除部分Non-Lexical概念、可重入节点关系,简化其中的概念和关系,并提出了紧凑AMR图,限制了转移动作搜索空间。
准确定义转移状态是基于转移的解析器取得良好表现的关键因素。Ballesteros等人[41]利用Stack-LSTMs编码转移状态,其优势在于对全局状态进行了建模。但是依旧存在两个问题: 一是忽略了局部状态的建模,如上下文单词表征;另一个是Stack-LSTMs处理长文本时,在预测转移动作的过程中,对于栈和缓冲区的调整不可避免地会重用之前步骤的隐状态,造成误差传播。为了兼顾全局和局部的状态信息,Astudillo等人[45]引入注意力机制,将Stack-LSTMs替换为Stack-Transformers编码转移状态。采用注意力机制计算任意两个转移状态之间的相关性以捕捉全局信息和局部信息。该解析器沿用了Ballesteros等人[41]的转移动作集合,如表2所示。尽管基于转移的解析器自左向右顺序处理的强约束提供了一种符合AMR特征的归纳偏置形式,但是上述解析器在处理例如可重入节点时需要频繁执行SWAP动作,导致最终所得到的转移动作序列是冗余的。
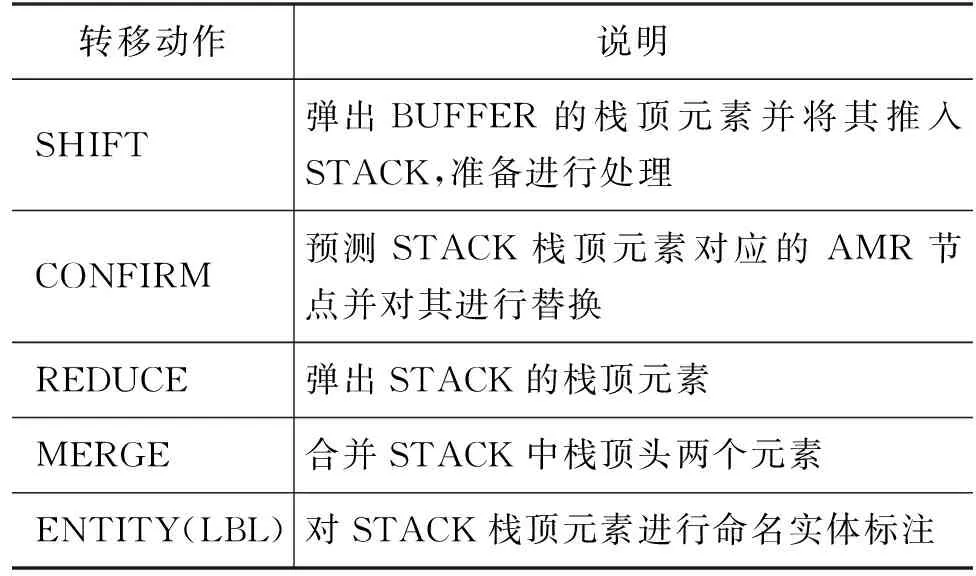
表2 转移动作集合
为了避免转移动作序列过长,Zhou等人[46]提出了一个Action-Pointer Transition(APT)系统以简化转移动作序列。APT系统融合了基于转移的方法和图构造方法的优势,核心思想是将目标转移动作序列既作为一种图构造过程,又作为一种图表征形式。其受到采用指针的解析器启发,使用自左向右移动的光标来替代传统的栈和缓冲区结构,所提出的转移动作集合如表3所示。APT通过引入指针网络并将其应用于目标端,根据过去的节点生成转移动作构造生成边,采用Transformer模型同时对转移动作序列生成任务和指针预测任务建模,利用交叉注意力机制的Mask操作将目标节点与原文本片段相关联。这种转移模式优化了可重入节点的处理过程,使得图构建过程更为简便自然,同时这也保证了准确且完备的对齐。

表3 转移动作集合
预训练模型的嵌入表示中蕴含了丰富的语义表征。Zhou等人[47]尝试将预训练语言模型BART集成到转移模型框架APT中。将转移动作集合中的保留预测动作(如Ballesteros等人[41]中的CONFIRM、Astudillo等人[45]中的PRED)替换为“
3.3 基于Seq2Seq的方法
文本解析为AMR图的过程也可以被视为一个机器翻译的过程,如图12所示,采用Seq2Seq模型构造端到端的解析器,在融合现有深度学习模型的同时,避免了其他解析方法烦琐的串联式解析步骤。此类方法主要面临三个问题: 第一,AMR解析预测的目标词汇表过大,这可能导致数据稀疏问题;第二,Seq2Seq模型基于数据驱动,而AMR可训练语料规模较小或者训练数据质量不高,导致模型学习效果不佳;第三,模型的语义表示能力有限,难以充分地表征,如文本的句法信息、浅层语义信息和图结构信息等。根据Seq2Seq模型的演化,此类AMR解析方法分为三个阶段。

图12 基于Seq2Seq的方法示意图
3.3.1 神经机器翻译模型
早期相关工作采用神经机器翻译模型实现AMR解析,沿用了经典的Seq2Seq模型[48-50]。Barzdins 和Gosko[51]率先在语义评测竞赛中使用带注意力机制的神经机器翻译模型实现AMR解析,采用单层GRU作为编码器和解码器。在PENMAN标记方式的AMR序列化表示中,变量名作为实例的别名并不具有语义信息,因此,他们执行了数据预处理操作,将变量名、wiki链接和实例化标签“/”视为噪声删除,以排除对模型语义表征的负面影响。但是由于受到数据稀疏问题的影响,当时的模型实验结果相较于主流的算法存在一定差距。
Peng等人[52]指出,造成数据稀疏问题的本质在于模型所要预测的目标词汇表规模太大。目标词汇表中包含构成概念和关系标签的数万个符号,而可训练数据规模又相对有限。因此针对较小规模的训练数据,他们在基于Seq2Seq的成分句法分析模型[53]的基础上提出了只采用单层LSTM作为编码器/解码器的解析模型。同时,对数据进行分类(2)也被称为重新分类(Re-Categorization),将数据集源端和目标端中出现的低频概念和部分实体子图,映射至新的类别,大幅缩减了目标词汇表的规模。
此外,他们提出新的线性化策略进行AMR序列表示,该策略将关系弧视为其概念头节点的一部分,以标识概念与关系之间的联系。将左/右括号和关系标签进行组合,将其记为关系范围的开始符号和结束符号,此类显式的划定方式使得模型能够较为顺利地预测出结构合法的AMR图。有别于传统的概念和关系独立区分的处理方式,在上述策略下模型得以更好地捕捉到概念与关系之间的关联。
随后,Konstas等人[54]采用堆叠双向LSTM作为编码器,自左向右逐个单词地建模输入序列。解码器则采用了堆叠LSTM进行预测,同时引入了全局注意力机制在预测阶段感知当前输出和输入序列的关联信息。为了缓解训练语料不足的问题,采用自学习策略对模型进行训练,通过预测无标签数据获得高置信度数据,以扩充训练样本,所提出的模型在AMR解析和AMR生成任务中都取得了很大程度上的性能提升。
受到Barzdins 和Gosko[51]启发,Van Noord等人[55]将字符作为基本处理单元并尝试进一步提升其性能,他们采用开源的机器翻译工具OpenNMT[56]构造了神经网络机器翻译模型,其中编码器与解码器均采用堆叠LSTM,同时在解码阶段引入局部注意力机制,用以感知输入序列与当前输出的相关性程度以指导预测。其分别从数据预处理、数据扩充和优化训练过程的角度尝试并验证了5种有效的技术,最终取得了当时的最优性能。与Konstas等人[54]采用自学习策略扩充训练数据不同,他们利用现有的AMR解析器生成训练数据,筛选后获得银数据(Silver Data)以确保训练数据高质量,避免噪声对模型的影响。由于当以字符为基本处理单元时待处理序列较长,会导致数据稀疏问题,且对于长距离关联的学习效果较差,后续的研究者大都还是将单词作为输入序列的基本处理单元。
3.3.2 Transformer模型
机器翻译模型的性能因Transformer模型的提出得到了大幅提升[57]。利用自注意力机制让模型能够学习到输入序列中不同部分之间的关系,其通过计算各部分之间的注意力分数,从而能够更全局地捕捉上下文信息。
为了提升解析模型的语义表示能力,许多研究者关注于建模和捕捉文本和图数据中所蕴含的结构信息。Ge等人[58]尝试将语法和语义信息融合到解析器中,采用一种可结构感知的AMR解析器隐式地建模上述信息。Transformer模型对整句层面的上下文信息学习更为充分,得以将元素间对齐、句法路径、句法距离和语义关系等信息融入编码之中。
机器翻译、句法解析和AMR解析3个任务是从不同的视角捕捉文本中的语言学知识。Xu等人[59]在微调阶段通过联合学习上述3个预训练任务,初始化构建AMR解析器模型。此外,他们还尝试引入预训练模型BERT[60]对源句子中的语言学知识进行表征,结果显示BERT的引入显著提升了模型的解析性能。
BERT本身并非生成式模型,其源端和目标端词汇表不共享的特性会给AMR解析任务带来困难。Bevilacqua等人[61]提出了一种基于BART的Seq2Seq模型SPRING(Symmetric PaRsIng aNd Generation)实现AMR解析和AMR生成任务。BART[62]是一种基于Transformer架构,结合了BERT双向编码和自回归模型GPT自左向右解码特点的编码器-解码器模型。BART通过降噪自监督任务还原乱序、带掩码以及存在损坏的文本,执行上述预训练任务以增强模型泛化能力。其源端和目标端的词汇表在很大程度上相交,以及生成式模型的特点可以满足AMR解析任务的条件。
前述工作中数据预处理是对诸如变量名、wiki关系等信息进行删减后以启发式的方法进行还原,这将不可避免地导致信息丢失和非法标注的问题。SPRING提出了一种无损的同构图线性化技术,引入特定标记
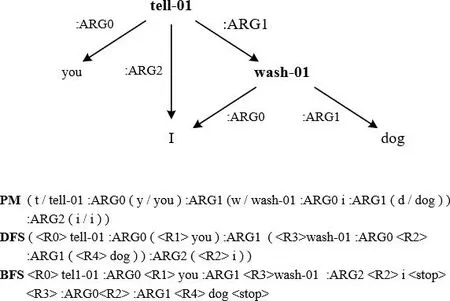
图13 AMR的三种线性化表示示例
其后,许多研究者通过引入额外结构信息进一步提升模型解析性能。引入额外结构信息的本质是为了提升模型的文本语义表征能力。Chen等人[63]在SPRING解析器中引入中间任务学习(Intermediate-Task-Learning,ITL)作为辅助任务训练,选择语义角色标注和依存解析作为中间任务,将其输出的数据转换为伪AMR数据(PseudoAMR),然后利用这些数据构建训练任务以满足模型对额外结构信息的学习。Yu等人[64]在SPRING的基础上设计多种策略将AMR图节点的祖先信息添加到解码器中以指导AMR图的生成,即引入了图结构信息。Cheng等人[65]则是在BART模型的基础上对文本和其对应的AMR图序列联合学习,提出双向贝叶斯学习(Bidirectional Bayesian Learning,BiBL)方法,对上述两种数据形式的联合概率分布进行单阶段多任务学习,通过辅助生成和重构这两项辅助任务,模型得以有效捕捉到概率分布中的潜在信息。
由于先前工作中的预训练语言模型大都是基于文本数据进行的,这导致模型对AMR这种图结构数据的学习和结构信息捕捉并不充分。Bai等人[66]尝试在BART模型的基础上,引入基于图结构模型中的图预训练策略,类比BART中的降噪自监督预训练策略,通过节点/边重构和子图重构两种操作实现图预训练任务的降噪。他们进一步提出一种文本-图联合预训练框架,将文本和AMR图同时作为输入进行联合学习,并输出期望的文本或图。这种预训练框架通过消除预训练和微调之间的输入和输出格式差异,来使模型在微调阶段中充分利用预训练知识,对于模型而言能够同时利用文本和图的信息,以捕捉更丰富的结构信息。
3.3.3 大语言模型
大语言模型出现后,Lee等人[67]尝试采用FLAN-T5大语言模型实现AMR解析,为了适配模型输入,首先对训练数据做了一系列AMR预处理操作,如删除wiki标签、线性化AMR等。然后对模型采用全参数微调、LoRA微调以及先全参数微调后再LoRA微调三种方式,以实现英文AMR解析。在AMR 2.0和AMR 3.0数据集上,加入银数据后,经过全参数微调再加LoRA微调的FLAN-T5-XL模型的性能优于采用BART预训练语言模型的性能,达到了目前AMR解析任务的SOTA。
3.4 基于形式化的方法
除上述类别外,还有一类解析方法,通过引入不同的文法、代数方法对图结构数据进行形式化建模,并生成对应的中间形式,进而将AMR解析任务转换为基于新形式下的相关问题求解,其示意图如图14 所示。

图14 基于形式化的方法示意图
3.4.1 超边替换文法
超边替换文法HRG[68]是上下文无关文法(Context-Free Grammar,CFG)在图结构上的一种表示,而派生的同步超边替换文法(Synchronous Hyperedge Replacement Grammar,SHRG)能够被用来实现图结构与其他结构(线性结构或者树结构)的双向转换。每一条SHRG规则由一对相互映射的CFG规则和HRG规则组成,根据SHRG规则可以并行地生成文本和对应的AMR图。Peng等人[69]首先将文本转换为超图,其中节点、超边分别为单词或短语,及其之间的关系,并同时构建初始SHRG规则集,每条规则将一条超边替换为一个子图。然后,根据文本与超图的对齐信息构建片段分解森林[70],片段分解森林是一个包含所有与输入文本和AMR图对齐的可能规则的集合。再采用马尔科夫链蒙特卡洛算法对片段分解森林进行采样学习,根据规则得分和采样策略选择得到最佳的SHRG规则。对测试数据应用所得的规则,最终实现AMR解析。
3.4.2 组合范畴文法
从计算语言学的角度看,CCG[68,71]是1类上下文有关文法,其通过一阶逻辑实现从语法到语义的自动推理,较其他语法形式相比更擅长于增量式的句子处理方式。Artz等人[22]率先提出了一个基于CCG的AMR解析算法,其采用CCG的句法分析过程生成组合性的AMR结构,再采用因子图对非组合性语言现象(如指代关系等)建模求解。具体来说,首先,将文本转换为CCG树,CCG树是一种能够将句子的句法结构和语义表示相互关联起来的树形结构,其中,树中每一个节点都包含一个表示该节点语法类型的范畴。然后,根据CCG树中的范畴信息生成对应的逻辑形式,逻辑形式是一种表示句子语义的形式,通常使用Lambda演算表示。最后,在逻辑形式中,每个AMR概念对应一个Lambda项,每个AMR关系对应一个应用于这些变量的二元谓词,以此实现AMR解析。
3.4.3 HR代数
HR代数是由Courcelle[72]于1993年提出的一种用以研究图性质的代数系统,HR代数是一种细粒度的代数,可以灵活地组合语法规则。Groschwitz等人[73]从代数图论的角度进行研究,他们认为AMR由多个原子图所组成,其中每个原子图对应单词及其在句子中的语义关系。通过对各原子图使用HR代数的通用图融合操作来实现AMR解析,这导致语法推理的计算量巨大。因此,他们提出AM代数,通过使用将谓词与补语或修饰语相结合的操作来进行原子图(又称为AM项)融合操作,这不但显著地减少了候选组合的数量,而且可以直接对控制、提升和并列等句法现象进行建模。
基于上述研究,Groschwitz等人[74]进一步提出使用AM代数实现AMR解析,其初衷是提供一种准确、可控和可扩展的方法以更好地捕捉句子的语义信息,巧妙地将AMR解析任务转化为计算给定文本的最佳AM依存树问题。具体来说,首先,利用AM代数将文本转换为as-graphs的中间形式,as-graph是带有节点和边标签的有向图,每个 as-graph 对应文本中的一个单词或短语;然后,采用超标记方法为每个as-graph分配类型信息;再使用依存句法解析器将as-graphs组合成一个依存句法树,并通过定义apply(APP)和modify(MOD)这一组操作来组合依存句法树中的as-graphs,APP操作将一个参数添加到谓词中,MOD操作将一个修饰语添加到图中,最终得到表征整个句子的as-graph,并将其转换为对应AMR解析结果。
3.5 中文AMR解析方法
中文AMR在英文AMR体系的基础上进行了较大的调整和改进,包括新增了概念关系和原句词语的对齐,对汉语离合词、重叠式等特殊语言现象的改进标注,对虚词的标注等,以更好地表示中文句子的语义结构[75]。由于中文AMR语料库2019年才构建,其研究起步较晚,因此,我们按照发展时间线论述中文AMR解析方法的研究成果。
吴泰中等人[76]受依存分析中基于Shift/Reduce的依存分析算法启发,在依存图分析基础上,采用基于双栈的扩展Shift/Reduce转移解码算法,解决交叉边和可重入边问题,设计了一个基于转移神经网络的增量式中文AMR解析模型。该模型在LA、RA、SHIFT、REDUCE四种转移动作的基础上,增加将主栈中的栈顶元素压入到次栈中的动作MEM,以处理交叉边或多个父节点等特殊情况,然后通过 LSTM模型学习语义关系表示和上下文相关词语义表示,并在此基础上,引入深度双向LSTM-CRF模型进行概念识别和消歧以对中文AMR进行解析。
Huang等人[77]基于Transformer模型实现了一个适用于中文的序列到序列AMR语义解析系统。该解析系统参考英文AMR解析中的预处理方法处理中文AMR图,删除了共指关系、对齐信息等,在不改变句子语义的情况下获得中文AMR的线性化序列,比较了BERT、BERT-wwm、NEZHA等五个预训练语言模型应用于中文AMR解析的性能,发现在模型中融合BERT-wwm的上下文表征的性能最好。
在2022年第二届中文AMR解析评测中[78],Chen等人[79]提出了概念预测和关系预测双阶段预测方法,实现中文AMR解析。在概念预测阶段,设计了直接对齐、标准化对齐、连续多字对齐、不连续多字对齐、分割对齐和空对齐6种不同的对齐规则,将输入的单词与抽象概念相对应,在关系预测阶段,利用RoBERTa和BiLSTM对预测的概念进行编码,然后输入到深度双仿射分类器(Biaffine)中预测两个概念之间的关系。
在同年竞赛中,周仕林等人(3)https://github.com/zsLin177/camr使用Chinese-RoBERTa预训练模型对输入数据进行编码,并通过BiLSTM将词性信息和句法依存信息与编码信息相结合,解码器再对编码器生成的节点进行动作预测、对齐预测、关系预测、属性判断和根节点预测处理。为了使输出的AMR符合中文规范,还设计了节点对齐、恢复共指信息等后处理,最后对AMR解析的结果采用多图聚合的操作,该模型在此次竞赛中取得了最好的成绩。
2023年,Gu等人[80]借鉴SPRING的框架结构,迁移至中文AMR解析。线性化AMR图得到AMR序列后,全参数微调Chinese-BART-large预训练语言模型,并将额外的词性与句法依存信息通过BiLSTM与BART Encoder的输出相结合,输入到BART Decoder中,随后通过对齐等后处理使得模型生成的AMR序列符合中文AMR的标注规范,最后将该模型输出的结果与上一模型输出的结果进行多图聚合操作。他们提出的方法在2023年第三届中文AMR解析评测中[81]取得了5项第一的成绩。
Yang等人[82]利用大型对话语言模型ChatGPT进行零样本学习(Zero-shot)和少样本学习(Few-shot),对ChatGLM-6B进行全参数微调和LoRA微调实现中文AMR解析。由于大模型在Zero-shot和Few-shot的设定下,长文本输入导致生成效果不理想,并且无法生成未见过的AMR关系,这使得解析性能欠佳。实验结果表明,经过全参数微调的ChatGLM-6B虽然具备一定的AMR解析能力,但是会损伤模型的泛化性,而LoRA微调尚不足以让模型实现AMR解析。Gao等人[83]选择对Baichuan-7B模型进行全参数微调来实现中文AMR解析,首先线性化AMR图,然后构造数据对大模型进行微调。构造的输入数据包含任务指令、原始句子以及带有词编号的分词后的句子,标签则是线性化后的AMR序列,最后基于规则匹配等方式对模型输出的AMR序列进行后处理,以使其符合中文AMR规范。
大型语言模型的出现及“预训练-微调”的范式不断地提升着AMR解析的性能,但如何将AMR的解析任务和大型语言模型的预训练任务结合起来是提升大语言模型进行AMR解析性能的关键。
4 实验对比
4.1 评测指标
评测AMR解析器性能可以通过将AMR解析图和人工标注AMR图进行相似度匹配来度量。Smatch[84]用于衡量两个AMR图的匹配程度,是目前最主流的AMR解析评测指标。Smatch评测中,首先将AMR图转换为三元组集合的形式,然后采用启发式的爬山算法(Hill-climbing Method)进行贪心搜索,以获取两个集合在最优匹配下的三元组匹配个数,最终返回准确率P、召回率R和Fβ值等度量指标。Smatch三元组集合包含节点、节点属性和有向弧三个子类别,表4给出图5示例的三元组表示形式。

表4 Smatch三元组表示形式
Smatch评测指标基于英文AMR而设计,无法较好地兼容中文AMR解析评测。一方面是由于英文AMR只关注实词,而其所忽略的虚词以及部分语言现象在汉语中往往蕴藏着语义信息;另一方面是因为英文AMR缺乏对齐信息,中文AMR的概念、关系对齐结果并不能由Smatch所体现。为了弥补中文AMR解析评测在对齐信息上的空缺,肖力铭等人[85]在Smatch的基础上添加了描述概念对齐和关系对齐的信息,提出Align-Smatch用以评测中文AMR解析器。
Align-Smatch将中文AMR图转换为一个多元组,每个多元组包含3个或者4个元素。具体而言,对Smatch的三元组集合作了下列修改: ①在原节点属性类别中,对其三元组新增了表示概念对齐的三元组; ②在原有向弧三元组类别中,新增了表示关系对齐的四元组; ③使用有向弧多元组来表示位于根节点的词, 而不再使用节点属性三元组表示。Align-Smatch评测公式同Smatch评测公式,其中的准确率P为黄金AMR的多元组集合和解析生成的AMR多元组集合间的最大匹配个数与解析生成的 AMR多元组总个数之比; 召回率R为黄金AMR的多元组集合和解析生成的AMR多元组集合之间的最大匹配个数与黄金AMR的多元组总个数之比;Fβ值同Smtach。
4.2 实验比较分析
英文AMR解析器性能评估主要在AMR 2.0、AMR 3.0上进行,中文AMR解析器性能评估则是在CAMR 1.0、CAMR 2.0上进行。为验证跨领域泛化能力,部分解析模型也会在分布外(Out-of-distribution)设定下,在如The Little Prince 3(TLP)(4)3https://amr.isi.edu/download.html、BIO[86]等特定数据集上进行实验。评估实验结果基于Smatch或Align-Smatch评测指标去衡量黄金AMR图和解析结果的匹配程度,同时如表5所示的子指标也在一定程度上反映了AMR解析器在某项子任务中的表现。整理归纳现有中英文AMR解析器实验结果,表6为AMR 2.0上的评测结果,表7为AMR 3.0上的评测结果,表8为CAMR 1.0和CAMR 2.0上的评测结果。

表5 评测指标含义

表6 英文AMR解析器在AMR 2.0上的实验结果 (单位:%)
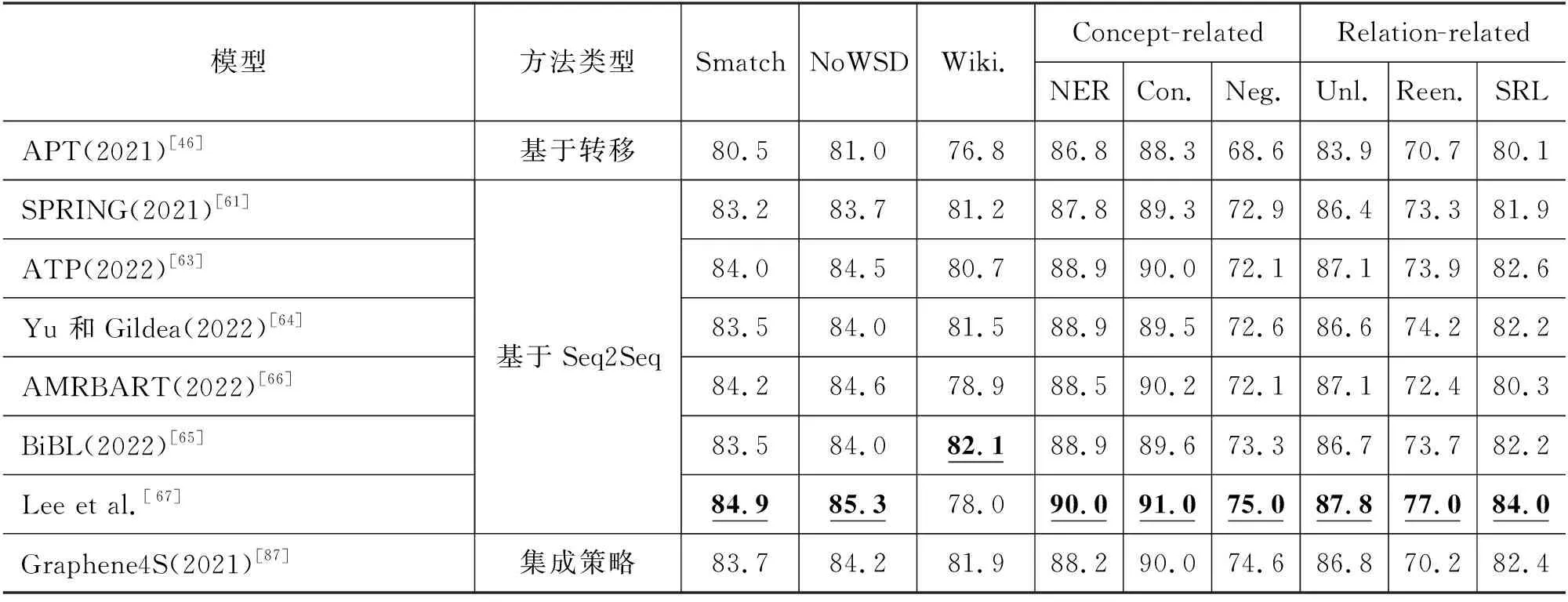
表7 英文AMR解析器在AMR 3.0上的实验结果 (单位:%)

表8 中文AMR解析器实验结果 (单位:%)
借鉴集成思想,Hoang等人[87]提出使用图聚合操作来提升解析性能。图聚合的核心思想是在多个解析器所得到AMR图集合中,求解最大公共子图作为最终的聚合图。Lee等人[88]则进一步提出了极大贝叶斯Smatch集成决策(Maximum Bayes Smatch Ensemble, MBSE)。其受到图聚合[87]和知识蒸馏[89]启发,通过集成Smatch-based模型和多种解析器的集成蒸馏模型来生成高质量的银数据以达到数据增强的目的。最终不仅进一步提高了在公开数据集上的AMR解析器性能表现,还在特定领域语料和跨语言的场景下均取得了较大的性能提升。因此,我们将此类研究实验结果作为四类方法的一种补充。
4.2.1 研究趋势分析
从时间发展维度分析发现,如图15、图16所示,AMR 2.0发布早,时间跨度大,其上的解析器性能反映了英文AMR发展的历程。前期工作主要以基于图和基于转移的方法为代表,2021年之后,基于Seq2Seq的方法占据了主导地位,综合解析性能超过其他方法。AMR 3.0发布时间较新,可以反映AMR解析器的前沿研究进展。AMR解析器自动解析性能已经达到较好水平,Transformer架构和预训练语言模型的引入使得基于Seq2Seq的AMR解析器性能取得了较大进步,但是近期研究中AMR解析器性能提升趋势渐缓。
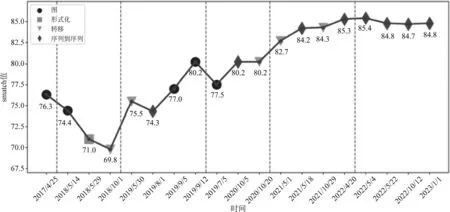
图15 英文AMR解析器在AMR 2.0上的Smatch值

图16 英文AMR解析器在AMR 3.0上的Smatch值
4.2.2 英文AMR解析方法对比分析
分析表6、表7发现,早期基于转移的方法以及基于形式化的方法性能较差,且缺少分项指标度量。实验显示,无论在AMR 2.0上还是AMR 3.0上,基于Seq2Seq的方法均是当前的SOTA。
删除缺少分项指标的数据后,构造折线图,如图17、图18所示。针对否定义项(Neg.)和可重入关系(Reen.)的识别还有着较大的提升空间,这意味着现有模型对于复杂的多语义关系的捕捉亟待加强。Lee等人的解析器在AMR 2.0和AMR 3.0上的Smatch值分别达到了86.4%和84.9%,虽然预训练技术乃至大模型的引入显著提升了解析性能,但是依旧还有不小的上升空间。如何在可承受的计算复杂度范围内进一步提升预训练模型的语义表征能力,是一个亟待解决的问题。
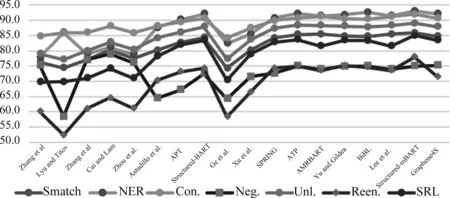
图17 英文AMR解析器在AMR 2.0上的指标折线图
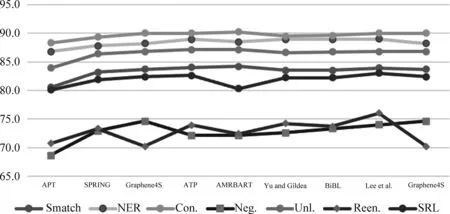
图18 英文AMR解析器在AMR 3.0上的指标折线图
4.2.3 中文AMR解析方法对比分析
分析表8发现,中文AMR解析方法研究较晚,早期中文AMR解析方法由于缺少对齐信息,仍然采用英文AMR评测指标Smatch。中文AMR语料库引入对齐信息后,主要采用基于图的方法以及基于Seq2Seq的方法,在CAMR 2.0数据集上构造指标折线图, 如图19所示。可以发现,不同于英文AMR解析中基于Seq2Seq的方法优于其他方法,在中文AMR解析器中,基于图的方法评测效果优于基于Seq2Seq的方法。

图19 中文AMR解析器在CAMR 2.0上的指标折线图
5 结束语
AMR以图的形式,突破浅层局限实现领域无关的整句通用语义表示,解析是AMR应用的关键步骤。通过CiteSpace工具分析发现,AMR解析方法是当前的研究热点,积累了较多研究成果,但尚缺乏与时俱进的文献综述。本文以问题驱动聚焦AMR解析方法的演化历程。结合文献理解,分析AMR 解析面临的关键难点问题,包括语料稀疏、对齐缺失、结构信息学习等。根据其解析策略,将AMR解析方法分为四类: 基于图的解析方法、基于转移的解析方法、基于Seq2Seq的解析方法和基于形式化的解析方法。以方法发展及问题解决为思路,重点阐述经典英文AMR解析方法、中文AMR最新解析方法,最后从评测和经典算法实验结果分析角度,分析了AMR解析方法的研究趋势,以及不同方法类型在中英文AMR解析上的性能。
研究发现,AMR解析的早期成果大都延续依存句法分析的相关方法进行迁移,而近三年来AMR解析性能的大幅提升主要受益于深度学习和预训练技术的引入。由于AMR评测语料库的规模较小,解析器性能依旧受限于多领域样本标注及数量,导致对于特定领域数据以及复杂语义现象的学习不够全面。未来AMR研究可以从以下方面展开: 第一,构建高质量AMR标注语料库。语料库开发是AMR解析的基石,尤其在特定领域、其他语种下的语料库标注工作意义重大。第二,英文AMR对齐信息的错误和缺失在一定程度上会影响自动解析的效果。可以考虑借鉴中文AMR标注规范,将对齐信息显式地加入到英文AMR标注中以缓解对齐问题。第三,尽管中文AMR标注有显式对齐信息,但是在解析器中正确获取对齐信息是解析的难点,可以重点研究AMR后处理方法或采用隐式学习对齐信息的方式,解决中文AMR对齐问题。第四,基于图的学习具有捕捉图结构信息的天然优势,图神经网络等相关算法有望在未来更好地实现AMR解析。
猜你喜欢
数据与计算发展前沿(2021年3期)2021-07-23
中学生数理化·高一版(2021年4期)2021-07-19
铁道通信信号(2020年6期)2020-09-21
开放教育研究(2020年2期)2020-03-31
电脑知识与技术·经验技巧(2018年8期)2018-10-16
电子世界(2018年14期)2018-04-15
语文世界(小学版)(2018年3期)2018-03-22
商周刊(2017年12期)2017-06-22
摄影之友(影像视觉)(2016年2期)2016-08-16
现代语文(2016年21期)2016-05-25
