
云计算环境下数据通信的智能路由算法研究
2024-05-09 09:52张光艳
通信电源技术 2024年5期
张光艳
(北京市委党校(北京行政学院),北京 100044)
1 智能路由算法设计
1.1 已有算法局限性
大规模、异构性和动态性是云计算环境的显著特点,这要求数据通信系统能够有效应对不断变化的网络状况、数据规模以及计算需求[1]。此外,安全性和隐私保护也成为云计算数据通信亟待解决的重要挑战之一。在应对云计算环境下的数据通信挑战时,研究者们提出了多种解决方案,其中包括基于传统路由协议的改进、软件定义网络(Software Defined Network,SDN)的应用以及各种负载均衡策略[2]。
由于云计算环境的动态性和异构性,传统的路由算法往往难以快速调整以适应不断变化的网络拓扑和流量负载[3]。这导致了在某些情况下路由决策的迟滞,影响了系统的实时性和性能表现。另一个制约的主要表现为在面对大量节点和复杂网络拓扑时,现有算法的计算和通信开销显著增加,限制了系统整体的可扩展性。在下一步的研究中,将重点关注设计一种具备更强适应性和可扩展性的智能路由算法。
1.2 算法设计
智能路由算法的核心思想基于强化学习,旨在全面优化自适应性、负载均衡和安全性。设计一个深度强化学习模型来实现智能路由算法需要定义状态表示、动作空间、奖励机制以及深度神经网络结构。以下介绍使用深度Q 网络(Deep Q Network,DQN)作为强化学习模型的算法。
第一,状态表示。定义一个状态,表示网络的当前状态。令St表示在时间步t的状态,包括网络拓扑信息、节点负载以及流量负载等。
第二,动作空间。定义一个动作空间,表示在给定状态下可选择的路由动作。令At表示在时间步t可选择的动作。
第三,奖励机制。设定一个奖励机制,以评估在给定状态和执行动作后的性能。令Rt+1表示在执行动作后获得的即时奖励。
第四,DQN 结构。DQN 用于映射学习状态和动作之间的关系,以实现在给定状态和动作下的累积奖励。其目标是学习最优Q函数,表示在最优策略下的累积奖励。在训练过程中,DQN 的目标是最小化预测Q值与实际Q值的差异,采用均方误差作为损失函数[4]。具体地,损失函数可表示为
式中:L(θ)表示损失函数;θ表示DQN 的参数;St表示当前状态;At表示当前动作;β表示即时奖励;St+1表示下一个状态;γ表示折扣因子;Q(St,At;θ)表示当前状态和动作下的预测Q值;Q(St+1,At+1;θ-)表示在下一个状态下选择最优动作的预测Q值;E表示对当前状态、动作、奖励及下一个状态的期望。目标Q网络的参数θ-用于稳定训练,通常通过固定周期或软更新的方式更新。
第五,训练过程。使用经验回放和目标网络来稳定DQN 的训练。在每个时间步t,执行以下步骤。一是选择动作At,其是由DQN 基于当前状态St给出的动作;二是执行动作,观察下一个状态St+1和即时奖励Rt+1;三是将经验(St,At,Rt+1,St+1)存储到经验回放缓冲区中;四是从经验回放缓冲区中随机抽样一批数据,更新DQN 的参数;五是更新目标网络的参数。
通过DQN 算法,实现一个能够学习并优化路由策略的智能算法,从而提升云计算环境下数据通信的性能。
2 算法实现
为了实现提出的智能路由算法,本文选择采用Python 编程语言,并使用深度学习框架TensorFlow 作为主要开发工具。
2.1 定义智能路由算法的DQN 模型与路由算法
要实现智能路由算法,需要先定义一个DQN模型,具体代码为

代码中,定义类“DQNNetwork”继承自TensorFlow的tf.keras.Model 类,表示DQN 的模型。在初始化方法中,定义了3 个全连接层,分别是具有128 个神经元和ReLU 激活函数的第一层,具有64 个神经元、ReLU 激活函数的第二层以及输出层。
在每一步训练中,先使用DQN 模型预测当前状态下的Q值,然后计算目标Q值,通过均方误差损失来更新DQN 的参数。同时,通过更新目标Q 网络的权重,确保目标Q 网络与DQN 保持一致。
2.2 主循环部分
在主循环中,根据num_episodes 的设定,执行一定数量的episodes。对于每个episode,使用初始状态initial_state,并在每个时间步中执行动作,更新状态、计算奖励,然后将经验存储到记忆中。algorithm.update_q_network() 和algorithm.update_target_network()表示更新Q 网络和目标网络,具体代码为

3 实验及评估
3.1 实验环境搭建
实验具体目标是验证数据通信效率、负载均衡以及安全性。搭建实验环境采用多核心的Intel Xeon处理器、32 GB 大容量内存以及高性能的NVIDIA Tesla 系列图形处理单元(Graphics Processing Unit,GPU)。需要安装Ubuntu Server 操作系统,配置VMware虚拟化软件,以便模拟多个云计算节点。此外,配置深度学习框架(如TensorFlow)、网络模拟工具(GNS3)以及加密库(OpenSSL)。
实验数据集采用PlanetLab 数据集,涵盖了节点之间的实时通信数据、节点负载信息以及性能数据,具有丰富的网络通信和性能指标。对于云计算环境下数据通信的智能路由算法的实验设计,PlanetLab 数据集的全球范围覆盖使其适用于不同地域、网络拓扑以及负载情况的研究[5]。
3.2 对比实验
对比实验是要将本文设计的深度强化学习模型来实现智能路由算法,与传统路由协议路由信息协议(Routing Information Protocol,RIP)和开放最短路径优先协议(Open Shortest Path First,OSPF)进行对比实验。表1 ~表3 是3 种路由协议的实验配置。
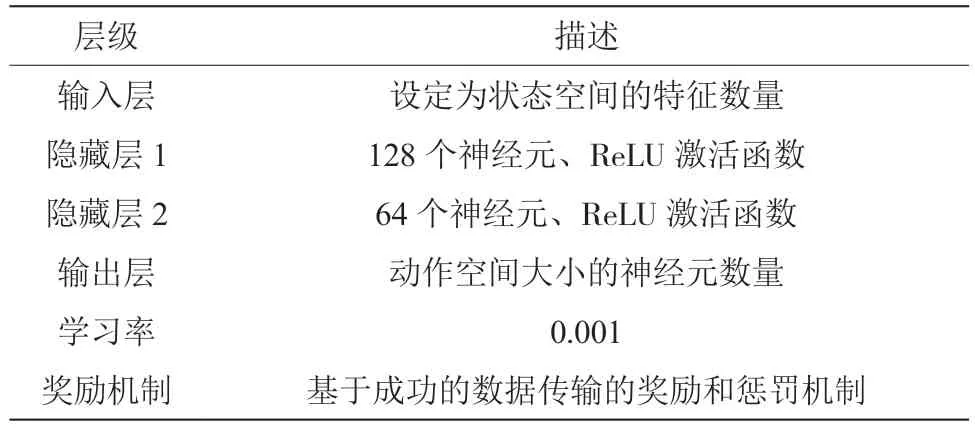
表1 深度强化学习框架的配置

表2 RIP 协议的配置

表3 OSPF 协议的配置
3.3 实验结果分析
经过对比实验、记录及整理数据,实验对比结果如表4 所示。

表4 实验结果
实验对比结果显示了深度强化学习模型在多个方面的性能优势。收敛时间方面,深度强化学习模型相较于传统的RIP协议表现更好,且略优于OSPF协议。在路由表更新频率方面,深度强化学习模型和OSPF协议表现相当,而RIP 协议的更新较为缓慢。负载均衡方面,深度强化学习模型表现优异,具有较高的负载均衡指标。相比之下,OSPF 协议也相对较好,而RIP 协议的负载均衡指标较低。
4 结 论
文章通过采用深度强化学习模型,提出了一种具有自适应性、高效通信、快速适应性以及良好负载均衡性能的智能路由算法。实验对比结果显示,相对于传统路由协议,文章设计的智能路由算法在收敛时间、数据传输效率、路由表更新频率及负载均衡性能等关键性能指标上均更具有优越性。在未来的研究方向上,可以进一步优化算法性能,使其适应更复杂的网络拓扑结构,推动智能路由算法的实际应用和发展。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
工程与建设(2019年3期)2019-10-10
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
网络安全和信息化(2018年3期)2018-11-07
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
铁道通信信号(2018年5期)2018-06-28
火控雷达技术(2016年2期)2016-02-06
电子设计工程(2015年3期)2015-02-27
电测与仪表(2014年16期)2014-04-22
