
应用于人脸识别的多任务卷积神经网络性能优化
2024-05-09 11:16:54叶惠仙
中原工学院学报 2024年1期
叶惠仙
(福建农业职业技术学院 信息工程学院, 福建 福州 350007)
近年来,深度学习技术尤其是卷积神经网络(Convolutional Neural Network, CNN),逐步成为了人脸识别的主流工具,各种CNN模型在人脸检测、关键点定位和人脸识别等方面的应用已取得显著成效。目前,相关研究者正致力于通过新的技术手段,如增强学习、迁移学习等提高人脸识别系统在复杂场景中的应用表现[1]。多任务卷积神经网络(Multi-task Convolutional Neural Network, MTCNN)突破了CNN只能处理单一任务的局限性。它能针对人脸检测、关键点定位和人脸识别3种任务,通过共享底层卷积层的特征表示,实现对多个任务的同时学习[2]。这不仅能提高模型的泛化能力,还能够在处理光照变化、遮挡、姿态变化等问题时取得优异的效果。MTCNN的引入使得人脸识别系统能够更全面地理解和处理人脸图像数据,为提高准确性、鲁棒性和稳定性奠定理论基础[3]。通过训练处理人脸多方面任务的模型,能够让系统适应多变环境,更全面、准确地识别人脸。这在安全监控、人机交互等领域有着重要的意义。多任务学习可以更好地应对真实场景中的各种挑战,为人脸识别技术在工业、商业和人们生活中的广泛应用提供更加可靠的解决方案,也有望推动人脸识别技术在实际应用中的普及和进一步发展[4]。本文将从MTCNN的设计和优化着手,研究不同任务之间的关联性以及有效共享底层特征表示的方法,提高模型在人脸检测、关键点定位和人脸识别中的性能;分析MTCNN在复杂场景中的性能表现,包括在光照变化、遮挡、姿态变化时的鲁棒性;测试模型在真实场景中应用的性能。
1 多任务学习在人脸识别中的应用
传统的人脸识别方法包括基于特征的方法和基于模型的方法。其中:基于特征的方法需先将人脸图像表示为特征向量,再利用分类器对其进行分类;基于模型的方法需将人脸识别看作一个模型训练问题,是通过训练模型来实现人脸识别的。传统的人脸识别方法主要基于的是图像处理和模式识别技术,包括主成分分析法、线性判别分析法和模板匹配法等[5]。这些方法曾取得了一定的应用成果,但在处理复杂场景和变化多样的人脸图像时存在一些明显的缺点。例如,它们对光照变化、表情变化、姿势变化和遮挡等因素的鲁棒性较差,且对提取特征的表示能力有限,很难准确区分不同的人脸。
多任务学习能够通过模型训练,对人脸属性如性别、年龄、表情等进行识别,在面对不同光照条件、佩戴眼镜或口罩等复杂场景时依然能准确判断人脸属性,从而提高系统的适应能力。多任务学习能针对人脸检测和关键点定位任务,通过同一模型的学习提高人脸检测的准确性,并改善关键点定位的精度,使得人脸识别模型具有更强的鲁性棒,以便在各种情况下精确地定位人脸的位置和关键特征点。多任务学习更加敏感于人的情感状态,在人脸表情识别方面更具优势。它通过学习多个表情分类任务,能够更好地理解和识别人脸表情。多任务学习可用于增强人脸活体检测的能力,防止使用照片或视频等虚假信息的欺骗行为。多任务学习通过同时学习真实人脸和虚假攻击的任务,能够显著提高人脸识别系统的安全性和可靠性。这些应用不仅能使人脸识别系统更为全面,也能提高其实际应用的效果和可靠性。一些经典的神经网络模型如AlexNet、VGGNet、GoogLeNet和ResNet等[6],已经在人脸识别任务中取得了令人瞩目的成果。
2 MTCNN模型的确定
在多任务学习中,同一个模型可以同时学习多种任务,从而提高模型的泛化能力和学习效率。以人脸识别为例,多任务学习可以同时进行面部特征检测、性别识别、年龄估计等任务的学习,从而提高模型对人脸图像数据的理解和识别能力。MTCNN模型通过学习大规模数据集中的人脸图像,可以自动提取更具表征能力的特征,且具备较强的泛化能力。
MTCNN是一种通过堆叠多个卷积层和池化层来提取图像特征的神经网络结构。相比于传统的浅层网络结构,它具有更强的非线性建模能力和复杂特征提取能力。MTCNN能通过不同尺寸和深度的卷积核来捕捉不同层次的图像信息,并通过池化操作降低特征维度,减小空间尺寸,从而减少网络的参数量和计算复杂度。这种网络结构在人脸识别任务中具有广泛的应用,并在一些公开数据集上表现出了优异的识别性能。根据文献[7],MTCNN模型的卷积层结构如图1 所示。
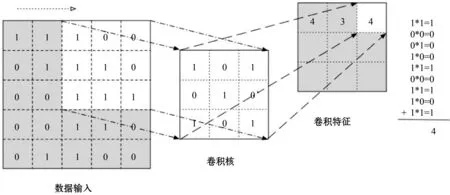
图1 MTCNN模型的卷积层结构
卷积层是MTCNN模型的核心组件之一。通过卷积层输入图像数据,与可学习的卷积核进行卷积运算,可提取图像中的局部特征(即卷积特征)。MTCNN模型的池化层在网络中起降低特征维度和减小空间尺寸的作用。通过池化操作能够提取图像中的主要特征并减少特征的冗余性,同时让指定特征具有一定的平移和尺度不变性。
MTCNN模型是通过堆叠多个卷积层和池化层来构建深层网络结构的。这些网络结构能够增强网络模型的深度和非线性表达能力,从而进一步优化网络的特征提取和分类性能。网络性能优化的关键在于有效地进行网络参数训练和优化方法的选择。随机梯度下降(Stochastic Gradient Descent,SGD)法是通过计算损失函数每个参数的梯度[8],并根据学习率进行参数更新实现性能优化的。但其存在过程震荡和收敛缓慢的问题。动量优化方法则能克服SGD的缺陷。自适应学习率方法如Adam、RMSprop,可根据参数梯度实时调整学习率。批归一化方法能够对每个小批量数据进行归一化处理,以提升训练速度,增强网络的稳定性。数据增强方法能够对训练数据进行随机变换,以扩充训练集,增强模型的泛化能力。对这些方法的综合运用和适当调整,可取得较好的网络性能优化效果。
用于人脸识别时,MTCNN需要3个不同的任务网络,以分别用于人脸检测、关键点定位和人脸识别。每个任务网络都有自己的损失函数,用于评估其在相应任务上的表现。这些损失函数组合在一起,可构成总的损失函数。模型的训练可采用反向传播算法,同时应使用SGD优化器进行优化。根据文献[9],可用人脸检测器P-Net来检测图像中的人脸位置。该检测器的输出是一个边界盒(它表示检测到的人脸在图像中的位置和大小)。此外,人脸识别时需要一个基于CNN的关键点定位器K-Net,以定位人脸的5个关键点,包括两个眼睛、一个鼻子和两个嘴巴角;还需用一个基于CNN的人脸识别器R-Net,从人脸图像中提取特征,并将其映射到一个低维空间。该低维空间的向量可以用于识别人脸。为了使3个任务网络共享底层卷积层的特征表示,应在P-Net和K-Net的卷积层之间添加一个共享的卷积层,在K-Net和R-Net的卷积层之间也添加一个共享的卷积层[10]。这种共享卷积层可使得不同的任务网络共享相同的底层特征表示,从而提高模型的泛化能力和识别准确率。
MTCNN模型的训练采用的是多任务学习方法,需要同时优化3个任务网络的损失函数。具体来说,它需要定义3个不同的损失函数,分别用于评估人脸检测、关键点定位和人脸识别的表现。将这3个损失函数组合在一起,就构成了总的损失函数[11]。
总的损失函数可表示为:
Ltotal=wdet×Ldet+wkp×Lkp+wid×Lid
(1)
其中:Ldet、Lkp和Lid分别表示人脸检测、关键点定位和人脸识别任务的损失函数;wdet、wkp和wid分别表示它们的权重。
模型优化过程,对于人脸检测任务,采用的是交叉熵损失函数;对于关键点定位任务,采用的是均方误差损失函数;对于人脸识别任务,采用的是三元组损失函数。具体来说,首先针对每个训练样本,随机选择两个同类样本和一个异类样本,并计算它们在特征空间的距离;然后,使用三元组损失函数来约束同类样本之间的距离,尽可能使其变小,而让异类样本之间的距离尽可能地大[12]。
三元组损失函数可表示为:
Ltriplet=max(0,m+||f(xa)-f(xp)||-
||f(xa)-f(xn)||)
(2)
其中:xa、xp和xn分别表示一个训练三元组中的锚点样本、正样本和负样本;f(·)表示针对具体样本的人脸识别器的特征映射函数;m表示一个margin,用于控制同类样本之间距离和异类样本之间距离的差值。
3 数据集的选择和预处理
在人脸识别实验中,选择合适的数据集对于评估和比较算法性能至关重要。数据集需要划分为训练集、验证集和测试集。一般用70%的数据作为训练集,10%的数据作为验证集,剩余的20%作为测试集[13]。常用的人脸识别数据集有LFW(Labeled Faces in the Wild的缩写)、Casia-WebFace、CelebA等。MTCNN 由于采用级联方式进行检测,每层网络都在前一层的基础上对人脸进行更加准确的检测和定位,因此检测精度比单一网络要高。MTCNN 在检测人脸的姿态和关键点方面具有更好的效果。人脸分类损失是用于评估人脸检测模型中分类任务性能的损失函数。在MTCNN中,人脸分类损失函数通常采用的是交叉熵损失函数。MTCNN中的P-Net网络能够将输入图像划分为多个不同大小的候选框,而这些候选框需要被分成人脸和非人脸两类。人脸分类损失函数计算的是网络输出的分类概率与真实标签之间的差异。在MTCNN训练过程中,人脸分类损失函数通常要与人脸边框回归损失函数、人脸关键点回归损失函数一起使用,计算总损失,以优化模型参数。
数据预处理是确保数据集一致性和可比性的重要步骤。通常用人脸检测和对齐算法来确保图像中的人脸区域能够对齐且具有一致的尺寸。此外,数据预处理需要通过直方图均衡化、对比度增强以及图像旋转,对图像进行标准化处理和增强。
使用MTCNN进行人脸检测和对齐的程序代码如下:
import cv2
from mtcnn import MTCNN
def detect_and_align_faces(image):
detector = MTCNN()
faces = detector.detect_faces(image)
aligned_faces = []
for face in faces:
x, y, w, h = face[‘box’]
keypoints = face[‘keypoints’]
# 对齐人脸
aligned_face = align_face(image, keypoints)
aligned_faces.append(aligned_face)
return aligned_faces
def align_face(image, keypoints):
left_eye = keypoints[‘left_eye’]
right_eye = keypoints[‘right_eye’]
nose = keypoints[‘nose’]
# 根据关键点进行人脸对齐
return aligned_face
# 加载图像
image=cv2.imread(‘face_image.jpg’)
# 进行人脸检测和对齐
aligned_faces = detect_and_align_faces(image)
# 对齐后的人脸图像可用于后续的特征提取和人脸识别实验。
在目标训练任务中,训练模型通常输出的是候选框的坐标和分类结果。然而,这些候选框通常不是精准的边框,因此需要利用框回归技术进行修正。框回归修正的目的是针对每个候选框,确定一个更为准确的边框。
4 MTCNN模型的训练
构建MTCNN模型,并利用训练集对MTCNN模型进行训练时,需要使用配置良好的计算机和服务器,并配备高性能的GPU加速器,以加速模型的训练和推理过程;同时,需安装必要的软件工具和框架,如TensorFlow、PyTorch等。通过评估训练集和验证集的性能表现,选择合适的参数和网络结构,才能完成网络模型的训练。
使用TensorFlow软件进行MTCNN模型训练的程序代码如下:
import tensorflow as tf
from tensorflow
.keras import layers
# 构建多卷积神经网络模型
model = tf.keras.Sequential() //创建一个tf.keras.Sequential模型
model.add(layers.Conv2D(32, (3, 3), activation=‘relu’, input_shape=(64, 64, 3)))
model.add(layers.MaxPooling2D((2, 2))) //添加第一个卷积层和最大池化层
model.add(layers.Conv2D(64, (3, 3), activation=‘relu’))
model.add(layers.MaxPooling2D((2, 2))) //添加第二个卷积层和最大池化层
model.add(layers.Conv2D(128, (3, 3), activation=‘relu’))
model.add(layers.MaxPooling2D((2, 2))) //添加第三个卷积层和最大池化层
model.add(layers.Flatten())
model.add(layers.Dense(256, activation=‘relu’))
model.add(layers.Dense(num_classes, activation=‘softmax’)) //添加输出层。
用上述代码对一个具有3个卷积层和1个最大池化层的MTCNN模型进行训练时,输入模型的是64像素×64像素的RGB图像,且是分为3个通道输入的。模型的每个卷积层后都有一个relu激活函数,用于引入非线性模型,并在每个卷积层操作后用最大池化层来减小特征图的尺寸。经过卷积和池化的特征图被展平成一维向量,可连接到全连接层和输出层。模型训练过程使模型能够从输入图像中提取关键特征,并在输出层进行相应的预测。
定义训练参数和优化器的程序代码如下:
model.compile(optimizer=‘adam’,loss=‘sparse_categorical_crossentropy’,metrics=[‘accuracy’])
# 数据增强
train_images= ImageDataGenerator(
rescale=1/255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode=‘nearest’
)
validation_images = ImageDataGenerator(rescale=1/255)
# 加载和预处理数据集
train_images,train_labels,fs_images,fs_labels = load_and_preprocess_dataset()
# 进行模型训练
model.fit(train_images,train_labels,epochs=10,batch_size=32,validation_data=(fs_images, fs_labels))
# 在数据测试集上评估模型性能
fs_loss, fs_acc = model.evaluate(fs_images, fs_labels)
print(‘Fs accuracy:’, fs_acc)。
通过模型训练,可获得图2所示的数据集。

图2 模型训练所得数据集
在模型训练中,使用了ImageDataGenerator函数,通过对应训练数据的图像旋转、平移、剪切、缩放、水平翻转等进行数据扩增,生成更加多样和丰富的训练样本,从而增强了模型的泛化能力和鲁棒性。这种方法使得MTCNN模型能够更灵活地适应各种变化的复杂场景。它提高了模型在实际应用中的适应性。
5 MTCNN在人脸识别中的性能测试
测试集不仅能用于评估模型性能,还可通过比较测试集的预测结果与实际标签,计算各种评估指标如准确率、召回率、精确度和F值(F-Measure)等,了解MTCNN在不同数据集和实验设置下相对于传统方法(如支持向量机)的优点。
用MTCNN进行人脸识别的程序代码如下:
import numpy as np
from sklearn import svm
import tensorflow as tf
from tensorflow import keras
# 加载和预处理数据集
train_images,train_labels,fs_images,est_labels= load_and_preprocess_dataset()
# 构建多卷积神经网络模型
model = tf.keras.Sequential()
# 添加网络层
# 训练多卷积神经网络模型
model.fit(train_images,train_labels,epochs=10,batch_size=32, validation_data=(fs_images, fs_labels))
# 在测试集上评估多卷积神经网络模型
fs_loss, fs_acc = model.evaluate(fs_images, fs_labels)
print(‘多卷积神经网络的测试准确率:’, fs_acc)
# 使用传统方法(支持向量机)进行人脸识别
# 将图像数据转换为特征向量
train_features = extract_features(train_images)
fs_features = extract_features(fs_images)
# 使用支持向量机进行训练和预测
svm_classifier=svm.svc()
svm_classifier.fit(train_features, train_labels)
svm_accuracy = svm_classifier.score(fs_features, fs_labels)
print(‘支持向量机的测试准确率:’,svm_accuracy)。
图3所示为MTCNN的人脸识别测试结果。

图3 MTCNN的人脸识别测试结果
6 结语
本文通过人脸图像的数据集对MTCNN模型进行训练和预测,并对它在人脸识别任务中的性能表现进行了评估。MTCNN模型训练的总损失是通过3个损失函数的加权计算得出的。总损失越小则代表模型性能越优。在其训练过程中,通过总损失的最小化可实现模型的优化,使之能够在人脸识别任务中更好地进行特征学习和预测。
尽管MTCNN在人脸识别中展示出了巨大的潜力,并在实验中获得了令人满意的结果,但仍然存在一些挑战和改进的空间,包括模型的进一步优化、使用更大规模的人脸数据,以及在隐私保护和安全领域的拓展性研究。随着深度学习和人脸识别技术的不断发展,相信MTCNN在未来的人脸识别应用中将发挥更为重要的作用。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
作文中学版(2022年1期)2022-04-14 08:00:34
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
学生天地(2020年31期)2020-06-01 02:32:06
今日农业(2019年15期)2019-01-03 12:11:33
动漫星空(2018年9期)2018-10-26 01:17:14
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
计算机工程(2015年8期)2015-07-03 12:19:07
发明与创新(2015年33期)2015-02-27 10:40:09
