
具有防撞安全约束的无人机集群智能协同控制
2024-05-08 09:47蔡云鹏周大鹏丁江川
航空学报 2024年5期
蔡云鹏,周大鹏,丁江川
航空工业沈阳飞机设计研究所,沈阳 110035
随着科学技术的发展进步,无人机(Unmanned Aerial Vehicle,UAV)已在军事和民用方面发挥着重要的作用。相比于单个无人机,由多架无人机组成的无人机集群具备更强的生存能力与环境适应能力,可以执行协同搜索、目标跟踪、目标围捕[1]、集群对抗等更加复杂的任务。无人机集群协同控制技术作为实现无人机集群协同能力的关键技术,已受到广泛的关注研究[2]。在无人机集群协同控制方法的研究中,已形成了传统协同控制方法、基于群体智能算法的协同控制方法以及基于深度强化学习的协同控制方法[3]等多种方法体系。
传统的无人机集群协同控制方法主要侧重于无人机集群的编队控制,比较成熟的方法包括基于领-从架构的编队控制方法[4]、基于虚拟结构的无人机编队轨迹跟踪控制方法,基于滑模编队控制方法[5]、基于一致性理论的编队控制方法[6]等。文献[7]基于领-从式架构提出一种四旋翼控制方法实现了从机的队形控制器,其基于积分反步法设计了领机的轨迹跟踪控制器,基于滑模控制方法实现了从机的队形控制器。文献[8]通过设计“长机层”和“僚机层”实现了对大规模无人机集群的协同控制,其中通过控制集群中各群组中的长机跟踪期望路径实现群组间的协同,群组内的协同通过控制群组内僚机跟随其长机实现。文献[9]基于虚拟结构法设计了无人机编队控制器,通过非线性模型预测控制方法实现了无人机的编队控制与安全避障。
基于群体智能算法的协同控制方法受到自然界中鸟群、鱼群等群居生物的启发,形成了更为灵活的集群协同控制方法[10-11]。文献[12]基于寒鸦群配对飞行行为机制提出一种无人机集群编队控制方法,通过设计无人机配对交互时的邻居选择机制,能有效解决无人机集群运动的一致性问题并且减小无人机集群的通信负载。文献[13]基于量子行为改进的鸽群优化算法实现了无人机集群的紧密编队控制器。文献[14]提出了一种复合的无人机集群控制方法,其基于人工势场法设计了3 种集群行为,并且建立了基于状态的集群行为模式切换逻辑,可有效解决无人机集群控制中面临的不完全约束、速度限制、机间避碰等问题。文献[15]通过考虑聚合、避碰等影响集群效果的序参数设计了无人机集群控制模型,并且采用进化算法对其进行了求解,获得的集群控制器可有效应用到实际的无人机集群控制中。
虽然以上传统协同控制方法和基于群体智能算法的协同控制方法可在较为简单的场景中对无人机集群进行有效的控制,但是受限于其规则化的控制策略,其难以应用于复杂的任务环境,还需进一步提升无人机集群控制策略的智能自主性。近年来,随着深度强化学习(Deep Reinforcement Learning,DRL)[16]在各个领域表现出一定的智能性及较好的应用效果[17],其在集群控制领域也备受关注。文献[18]结合领-从式架构和Q-学习(Q-Learning)方法提出一种固定翼无人机集群控制方法,构建的控制策略使得从机与主机保持一定的范围,并且满足分离、聚合以及对齐的集群规则。但是构建的控制策略并没有考虑机间避碰,无人机之间的避碰通过高度分层实现。文献[19]基于深度策略梯度算法构建了四旋翼无人机集群的控制策略,可使得无人机集群在大规模复杂环境中导航。文献[20]基于演员-评论家算法在连续空间下构建了无人机的集群控制策略,其可以将从机控制在主机的一定范围内。然而这种方法仅通过设计奖励函数的方式考虑机间避碰约束,是一种“软”约束,无人机之间仍然有较大的可能发生碰撞。
综上所述,目前传统的无人机集群协同控制方法与基于群体智能算法的协同控制方法较为依赖无人机模型与环境模型,其规则化的集群控制策略缺乏较好的智能自主性,难以应用于复杂动态的任务环境。虽然以深度强化学习为代表的基于学习的无人机集群协同控制方法可不依赖模型构建较为灵活自主的集群控制策略,但其构建的基于深度神经网络的集群控制策略为一黑箱模型,缺乏安全性保证,无法应用于实际任务中。针对以上问题,本文将基于深度强化学习方法构建无人机集群的协同控制策略,通过强化学习[21]的交互式训练方法构建出较为灵活的协同控制策略。同时,基于固定规则设计无人机防撞策略实现无人机的机间避碰与环境障碍避碰能力,为无人机集群的安全性提供较为可靠的保障。通过这种方式,可构建出具有一定智能自主性且具有安全性保障的无人机集群控制策略。
1 问题描述
1.1 集群协同控制问题
本文针对固定翼无人机集群的协同控制问题展开研究,重点关注无人机集群协同控制过程中的智能性与安全性。具体地,考虑一个由N个无人机组成的无人机集群,在具有多个威胁区的环境中飞行,需要构建无人机集群控制策略,使得无人机集群在飞行过程中智能自主地形成紧密编队,并且躲避开环境中存在的威胁区以及避免发生机间避碰。该问题的主要难点在于如何在紧密编队与无人机集群的安全性之间达到平衡,并且设计一种分布式的方法,使得各无人机智能自主地形成一个紧密编队,在不需要额外指定队形的情况下使得无人机集群具备更好的鲁棒性与适应性。
1.2 无人机模型
本文考虑无人机集群在三维空间中的集群控制问题,由于不涉及无人机的内环控制过程,因此采用以下简化的无人机运动模型模拟无人机在三维空间中的运动过程:
式中:(x,y,z)表示无人机在三维直角坐标系O-XYZ下的位置;vH表示无人机在水平面O-XY上的投影速度,即水平速度;vz表示无人机在OZ轴上的分量速度;ψ表示速度vH与OX轴的夹角;表示无人机水平速度的控制指令;ψc表示无人机的航向控制指令;zc表示无人机的高度控制指令;表示与无人机动力学特性相关的时间常数。
2 集群协同控制方法
2.1 集群协同控制架构
针对第1 节提出的无人机集群协同控制问题,本文采用深度强化学习方法与基于规则的机间防撞策略构建无人机集群的协同控制策略。其中,基于深度强化学习的自学习自训练架构构建较为智能的无人机集群协同控制策略,基于规则的机间防撞策略为无人机集群的安全性提供较为可靠的保障。图1 为本文提出的集群协同控制架构。其中,采用深度神经网络构建无人机集群的协同控制策略,其输入为无人机观测到的环境状态s,输出为控制无人机运动的控制指令a,在每一步与环境的交互过程中,首先判断无人机是否处于安全状态,若无人机处于安全状态,则采用深度神经网络输出的控制指令控制无人机运动,反之则采取机间防撞策略给出的控制指令as控制无人机,避免无人机发生碰撞。这种方式一方面可在训练过程中为无人机集群控制策略的训练提供较高质量的交互经验,另一方面可在实际飞行过程中为无人机提供可靠的安全保障。

图1 无人机集群协同控制架构Fig.1 UAV swarm collaborative control architecture
2.2 基于深度强化学习的集群协同控制策略
在基于深度强化学习方法构建集群协同控制策略的过程中,首先将集群协同控制策略构建为参数为θ的深度神经网络πθ,其次通过强化学习的交互式训练方式训练网络参数θ,使得集群控制策略的能力满足需求。在交互式训练过程中,无人机首先从飞行环境中获得观测状态s,然后根据策略πθ选择执行动作a~πθ(s),执行动作a之后,无人机观测到改变之后的环境状态s′并且获得对其动作的奖励值r。在强化学习框架下,集群控制策略训练的目标是学习到最优策略a∼πθ∗(s),使得无人机在一个任务周期中获得的累积折扣奖励最大。其中,累积折扣奖励值计算公式为
式中:Gt表示t时刻无人机可获得的累积折扣奖励;rt+k+1表示在t+k+1 时刻无人机获得的奖励值;γ(0<γ<1)为折扣因子。
2.2.1 观测空间与动作空间
集群协同控制策略的网络结构与无人机的观测状态和动作指令密切相关,因此,在介绍集群协同控制策略的网络结构之前,先介绍无人机的观测空间与动作空间。
无人机的观测状态s主要包含3 个部分:无人机与目标点的相对位置关系sg;无人机与其邻近无人机之间的相对运动状态sn;以及无人机与环境中威胁区的相对位置关系so。
sg=其中表示无人机与目标点的水平距离;Δϕg表示无人机航向与无人机指向目标点的方向的夹角;Δzg表示无人机与目标点的高度差。
综上所述,无人机的观测状态s(s∈R24)为24 维的高维向量。
2.2.2 网络结构
集群协同控制策略网络πθ将无人机观察状态s映射为无人机的控制指令a,其网络结构如图2 所示。由图2(a)可知,网络πθ共有3 层网络,前两层网络为分别具有128 节点与256 个节点的全连接网络,激活函数均为线性整流函数(Rectified Linear Unit,ReLU)。第3 层网络具有2 路结构,第1 路具有3 个线性处理节点,这一路输出控制指令的平均值;第2 路具有3 个线性处理节点,输出控制指令的对数标准差alnstd。
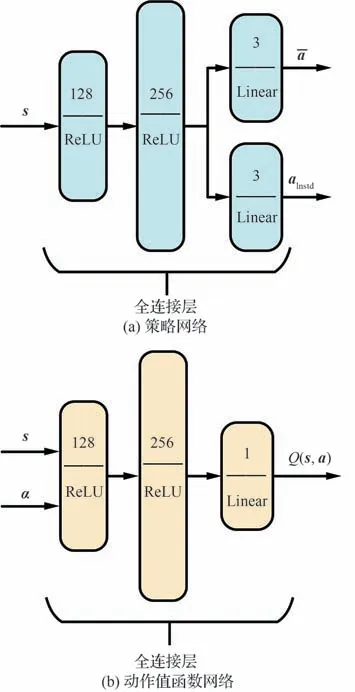
图2 网络结构Fig.2 Networks structure
式中:“⊙”表示向量对应元素相乘。
2.2.3 奖励函数
由式(2)可知,奖励函数对策略的训练过程至关重要,其决定着训练出的策略所具备的能力。考虑1.1 节描述的集群协同控制问题,本文据此建立的无人机集群协同控制策略的奖励函数为
2.2.4 训练算法
鉴于软演员-评论家(Soft Actor-Critic,SAC)[22]算法在一系列连续控制任务中具有很好的性能表现,本文采用SAC 算法训练无人机集群协同控制策略。SAC 算法是一种基于最大熵强化学习方法的算法,智能体在最大化累积奖励的同时在最大化策略熵,即通过最大化以下性能函数获得最优的策略:
式中:ρπ表示在策略π下的动作状态轨迹分布;H(π(⋅|st))表示策略π 的熵;α为调节参数;用于平衡奖励与策略熵之间的权重。
在SAC 架构下,t时刻的状态值函数计算式为
式中:Q(st,at)表示状态-动作对(st,at)的值函数,也称为Q 值函数,表示在状态为st时执行动作at之后可获得的回报值,计算式为
在本文的集群协同控制策略训练过程中,将Q 值函数通过参数为ϕ的深度神经网络表示为Qϕ(s,a),如图2(b)所示。
在策略训练过程中,策略网络参数θ通过最小化以下损失函数更新:
式中:D表示收集到的无人机与环境的交互数据集。
Q 值函数的参数ϕ可通过最小化以下损失函数更新:
2.3 防撞策略
在以上深度强化学习架构下训练无人机集群控制策略以及实际使用训练好的无人机集群控制策略时,由于无人机集群控制策略的计算过程包含深度神经网络计算过程以及式(4)所示的采样过程,其计算出的集群控制指令具有一定的不确定性。因此在策略训练以及实际应用策略的过程中无法可靠地保障无人机的安全性。不具备安全性保障是严重制约深度强化学习方法实际应用的一个主要原因[23-24]。为此,本文在以上基于深度强化学习架构的基础上增加基于规则的防撞策略,如算法1 所示,为无人机集群控制策略的实际应用提供可靠保障。
首先,考虑无人机之间的防撞策略。不失一般性地,以当前无人机的位置为原点O,飞行速度v所在方向为x轴,与速度v所在的水平面垂直且指向上的方向为z轴,由右手坐标系构建y轴,以此构建当前无人机的速度坐标系,如图3 所示。在当前无人机速度坐标系O-xyz下使用pi和vi表示无人机i相对当前无人机的位置与速度矢量,则无人机i对应的避碰指令计算式为
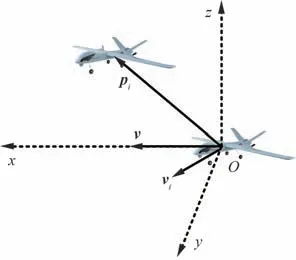
图3 无人机相对运动状态示意图Fig.3 Schematic diagram of relative motion states of UAVs
由式(18)可知,当机间有相互靠近的趋势时,kvr为<0 的数值,反之为0,这样可以避免在机间没有相互靠近趋势时计算由机间相对速度引起的避碰指令。
其次,对于环境中的威胁区,可以将无人机距离其边界最近的点视为一个假想无人机,这样可通过式(17)将无人机之间的防撞与无人机和威胁区的防撞进行统一。此外,考虑到无人机躲避威胁区时需要提前进行规避,因此设定的对于威胁区的安全距离一般要大于机间安全距离因此,同时考虑无人机集群与环境中存在的各威胁区时,当前无人机的防撞指令为
式中:i和j分别表示在设定的安全范围之内的无人机下标与威胁区对应的假想无人机下标。
最后,通过下式将无人机防撞指令Δc映射到控制无人机的速度、航向以及高度指令:
式中:Δcx、Δcy、Δcz分别表示防撞指令Δc在无人机速度坐标系O-xyz下各轴的分量分别表示控制无人机防撞的水平速度、航向与高度幅值大小。
综上所述,本文构建的具有防撞策略的无人机集群控制器结构如图4 所示。在每一步控制过程中,首先对无人机的状态进行安全监督,若无人机处于安全状态,则采用基于深度神经网络的集群控制策略输出的控制指令构建无人机的控制指令,反之则采取防撞策略给出的控制指令构建无人机的控制指令。

图4 无人机集群控制器结构Fig.4 Structure of the UAV swarm controller
3 仿真与分析
3.1 仿真场景及参数设置
本文通过仿真的方式验证提出的无人机集群控制策略的控制效果。
在构建的仿真场景中,无人机集群的飞行范围大小为1 000 m×1 000 m×130 m,其中分布着大小不同的圆柱形威胁区,每个威胁区的高度均为130 m,因此,无人机只能通过调整航向躲避这些威胁区。此外,无人机的最大飞行速度为20 m/s,最小飞行速度为12 m/s,动力学常数分别设置为:τvH=1.0 s,τψ=0.75 s,τz=1.0 s,τvz=0.3 s。集群控制方法中涉及的参数取值如表1 所示。
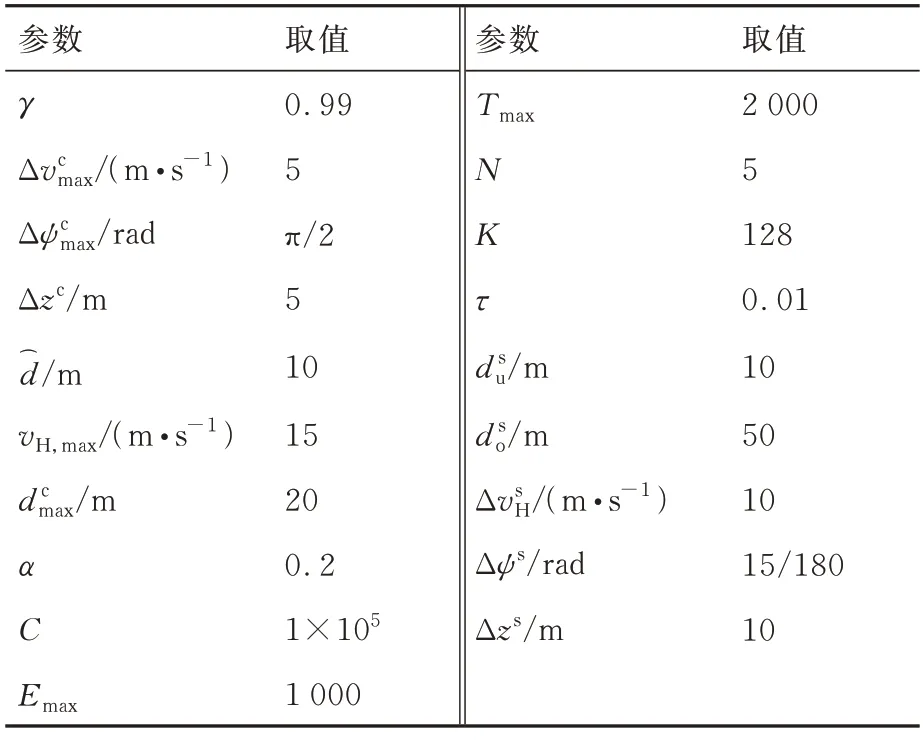
表1 集群控制方法参数取值Table 1 Parameter values of swarm control method
3.2 训练结果
无人机集群协同控制策略的训练过程持续了1 000 个训练周期,为了对比,本文同时训练了没有防撞策略与具有防撞策略两种集群控制策略。在没有防撞策略时,集群控制策略在训练过程中不会进行安全性判断,并且仅执行集群控制策略网络输出的动作指令。图5 所示为训练过程中2 种策略在一个训练周期内获得的累积奖励值随训练周期变化的曲线,图中曲线在原值基础上经过了2 阶指数平滑,平滑参数为0.01。
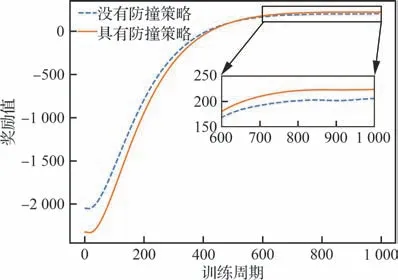
图5 奖励值变化曲线Fig.5 Curves of reward
如图5 可知,在训练前期,没有防撞策略的无人机集群控制策略反而可以获得更多的奖励,产生这个现象的主要原因是在训练前期集群控制策略与防撞策略相互冲突,没有达到平衡。因此,防撞策略会影响无人机集群的紧密一致性并且带来控制指令的抖动,从而会减小无人机获得的奖励值。随着训练周期的增加,在训练后期,无人机集群控制策略对防撞策略的工作机制已经熟悉,并且适应了在防撞策略下的集群控制过程,防撞策略会避免无人机发生碰撞,从而避免了无人机获得碰撞惩罚奖励。因此,在训练后期,具有防撞策略的无人机集群控制策略可以获得更多的奖励。
3.3 集群控制效果对比分析
由图5 的结果可知,最后训练出来的具有防撞策略的无人机集群控制策略应具有更好的集群控制效果。下面对图5 中训练出的2 种集群控制策略的控制效果做进一步的对比分析,同时,与文献[15,20]中的集群控制策略进行对比。文献[15]考虑了聚合、避碰等影响集群控制效果的序参数设计了无人机集群控制策略,文献[20]基于深度强化学习在连续空间下构建了无人机的集群控制策略,但没有设置防撞策略。
图6[15,20]所示为4 种集群控制策略控制5 架无人机组成的集群所产生的飞行轨迹。由图6(a)可以看出,在没有防撞策略时,无人机集群在飞行过程中虽然可以躲避环境中的威胁区,但是集群较为分散,在飞行过程中没有始终保持紧密的集群。相比之下,由图6(b)可以看出,在具有防撞策略时,无人机集群在整个飞行过程中可以保持紧密的集群,并且飞行时间更短。此外,由图6(c)可知,在考虑聚合、避碰等影响因素时,参考文献[15]中构建的集群控制策略控制的无人机集群队形保持的相对较好且飞行时间相对较短。与图6(b)相比,图6(d)所示的没有考虑防撞的无人机集群飞行轨迹相对较为松散。
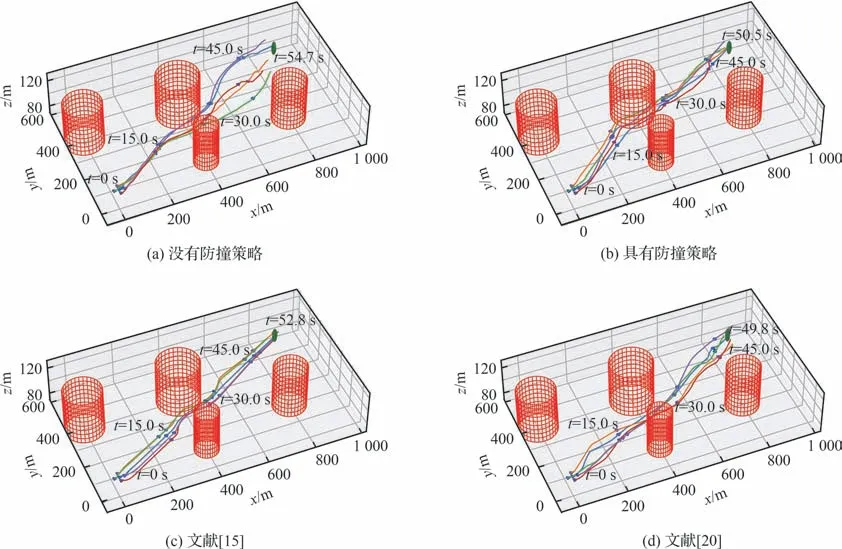
图6 无人机集群飞行轨迹Fig.6 Flight trajectories of UAV swarm
为了深入分析4 种集群控制策略的控制效果,从安全性与集群紧密一致性两方面出发,以机间最小距离无人机集群中各无人机飞行速度大小与集群平均飞行速度大小的偏差平均值verror,无人机集群中各无人机的飞行方向与集群中心飞行方向的偏差平均值ψerror,无人机集群中各无人机距离集群中心的平均距离dc这4 个指标对图6 所示的集群飞行过程进行分析,结果如图7[15,20]所示。

图7 无人机集群安全性与集群紧密一致性指标变化曲线Fig.7 Curves of indicators of safety,tightness and consistency of UAV swarm
在verror指标上,文献[20]中的方法表现最好,其具有最小的verror指标,其他3 种方法的表现相当,并没有明显的区别。产生这一结果的主要原因是文献[20]中的集群控制策略是一种确定性策略,并且没有考虑防撞机制,这样引起的集群控制指令的抖动较小。这一现象同样可在ψerror指标上体现出来,即相对于其他3 种方法,文献[20]中方法控制的无人机集群的ψerror指标抖动较小。
在dc指标上,在无人机集群的后期飞行过程中,在本文提出的没有防撞策略的集群控制策略下以及文献[15]中的控制策略下,无人机距离集群中心的平均距离超过了30 m,表明无人机集群非常分散,无法形成紧密集群。相比之下,在本文提出的具有防撞策略的集群控制策略下,可以使得无人机距离集群中心的平均距离保持在20 m 以下,使得无人机集群形成紧密集群,而文献[20]中的方法控制下的无人机集群的dc指标相对较大,其控制的无人机集群相对较为分散。
由以上结果可知,相比于传统基于深度强化学习的集群控制策略以及基于群体智能算法的集群控制策略,本文在传统深度强化学习方法基础上增加防撞策略之后,构建的集群控制策略可紧密控制无人机集群,并且具有较高的安全性保障。
最后,对本文提出的具有防撞策略的集群控制策略的单步运行耗时进行测试,分析其在实际应用中的可行性。采用的测试平台与目前市面上的机载计算机的性能基本相当,CPU 为i5-1240P,内存为16GB DDR4 内存,没有独立显卡。对集群控制策略运行500 步,记录单步的运行时长,结果如图8 所示。可知,集群控制策略的单步运行时间均在2 ms 以下,可以满足实时运行的需求。因此,在采用与本文测试平台性能相当的机载计算机时,本文提出的具有防撞策略的集群控制策略可以在无人机的机载计算机上运行,实时解算出无人机的集群控制指令。

图8 集群控制策略运行耗时测试结果Fig.8 Test results of running time of the UAV swarm control strategy
4 结论
本文针对无人机集群协同控制问题展开了研究,提出了一种结合深度强化学习方法与防撞策略的无人机集群协同控制方法,可在保障无人机集群安全性的同时控制无人机集群形成紧密集群。具体结论如下所示:
1)在深度强化学习方法基础上引入防撞策略可以避免无人机之间发生碰撞的风险,提高无人机集群的安全性,并且可以使得无人机集群形成紧密的集群。
2)本文提出的具有防撞策略的集群控制策略单步运行耗时较短,可在无人机的机载计算机上实时运行。
猜你喜欢
装备维修技术(2021年37期)2021-11-03
现代电子技术(2019年15期)2019-08-12
山东冶金(2019年3期)2019-07-10
小哥白尼(趣味科学)(2018年12期)2018-12-18
消费导刊(2018年10期)2018-08-20
汽车工程师(2018年1期)2018-07-13
中国公路(2017年13期)2017-02-06
科技视界(2016年13期)2016-06-13
通信电源技术(2016年1期)2016-04-16
电测与仪表(2016年20期)2016-04-11
