
大模型技术行业研究与应用进展
2024-05-07 07:44:08中国铁道学会智能铁路委员会,中国铁道科学研究院集团有限公司科学技术信息研究所
铁路计算机应用 2024年4期
大模型是指在机器学习和深度学习领域中,利用大规模数据和复杂网络结构构建的庞大神经网络模型。大模型往往由数以亿计甚至更多的可训练参数组成,通过学习海量数据中的模式和规律来实现各种智能任务,具有更强的泛化能力和表达能力。大规模预训练模型的发展历程可以追溯到2017年,当时谷歌提出Transformer架构,奠定了当前大模型领域主流的算法架构基础。到2022年年底,OpenAI推出的ChatGPT掀起了一场人工智能领域的“大火”,使得大模型成为人工智能新基建领域新兴并快速发展的热点方向之一。
随着生成式人工智能大模型技术的不断创新和发展,大模型在自然语言处理、图像识别等领域展现出强大的应用潜力,能源、航空、汽车、通信、金融、医疗等垂直行业也基于领域人工智能技术和数据积累等能力,在通用基础大模型的底座上,推出行业大模型,深度赋能各行业人工智能应用场景。如表1所示。

表1 大模型技术行业应用进展
1 基础大模型研究进展
随着数据量的爆炸性增长,硬件算力设备以及算法模型的标准化,大模型技术开启人工智能新时代。国内外科技巨头积极布局,纷纷推出自己的通用基础大模型,积极抢占人工智能大模型领域的战略高地。如图1所示。
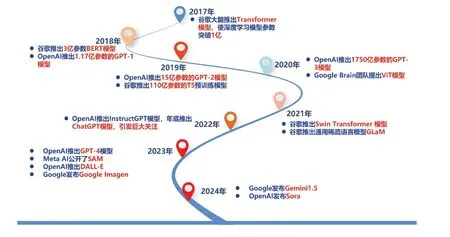
图1 人工智能大模型技术发展历程
1.1 语言大模型
自2017年Transformer架构推出后,语言大模型技术发展迅速。2018年,OpenAI推出了具有1.17亿参数的GPT-1模型,极大地推动了自然语言处理领域的发展。此后,大量新式预训练语言模型不断涌现,预训练技术在自然语言处理领域蓬勃发展。到2020年,OpenAI的GPT-3模型参数规模达到了1 750亿,实现了模型规模从亿级到上千亿级的突破,标志着深度学习和自然语言处理领域的一个新高度。2022年11月,OpenAI公司基于GPT-3.5推出了ChatGPT,掀起了人工智能领域新一轮的浪潮。ChatGPT发布后,用户数持续暴涨,2个月实现月活用户过亿,成为史上增速最快的消费级应用。之后,OpenAI的GPT-4、Meta的LLaMA、谷歌PaLM-2等大模型被相继推出,并在多样化和高难度的任务中表现出色。
在ChatGPT被推出后,中国本土厂商积极跟进,百度的“文心一言”、阿里云的“通义千问”、科大讯飞的“讯飞星火认知大模型”、百川智能的“Baichuan系列大模型”以及清华大学的“GLM系列大模型”等相继被推出,并取得了出色表现。
1.2 计算机视觉大模型
继语言模态之后,视觉大模型的研究也逐步受到重视。2020年,谷歌提出ViT模型证明了Transformer架构在计算机视觉领域的可行性,拉开了视觉大模型的序幕。之后,微软亚洲研究院的研究团队提出Swin Transformer视觉大模型,该模型是基于Transformer架构的一种变体,在图像分类、目标检测和语义分割等计算机视觉任务中展示了出色的性能。2023年4月,Meta开源了图像分割模型—Segment Anything Model,简称SAM,SAM是一个提示型模型,其在1 100万张图像上训练了超过10亿个掩码,实现了强大的零样本泛化。2023年,谷歌宣布了他们最先进的图像生成模型Imagen2,该模型不仅在参考图片和文本的基础上生成新图片,而且在局部编辑和细节处理方面表现出强大的效果,Imagen2的推出进一步证明了AI技术在模拟和增强人类视觉能力方面的巨大潜力,标志着人工智能在视觉创造和理解方面又迈出了一大步。
国内方面,华为推出了盘古CV大模型,盘古CV大模型是基于海量图像、视频数据和盘古独特技术构筑的视觉基础模型,利用少量场景数据对模型微调即可实现特定场景任务,极大提升了AI开发效率。商汤科技与上海人工智能实验室联合发布书生2.5大模型,其中大规模视觉基础模型InternImage是一种新的基于 CNN的大规模基础模型,可以为图像分类、对象检测和语义分割等多功能视觉任务提供强大的表示。
1.3 多模态大模型
继语言模态和视觉模态的大模型研究之后,进一步地,单模态的大模型被统一整合起来,模拟人脑多模态感知的大模型出现。OpenAI的DALL-E、Google的Gemini1.5、OpenAI的Sora以及国内中科院的“紫东太初”等多模态大模型不仅在理论上具有创新性,而且在面对多模态或跨模态任务时,具有更强的灵活性和适应性,在实际应用中显示出巨大的潜力和价值。
2 行业大模型应用进展
大模型具备良好的泛化能力,可支撑多种碎片化应用场景,大幅降低了人工智能的应用门槛。当前,大模型在各行业的应用边界正在不断拓展,相关技术和应用在多个行业领域初具成效。
2.1 能源行业大模型应用
(1) 南方电网“大瓦特CV大模型”
南方电网广西电网公司输电人工智能大模型(大瓦特CV)的发布标志着全国首个全栈自主可控电力生产应用场景大模型在广西落地。该大模型致力于解决在生产运行、工程建设、客户服务中面临的智能化不足、人力资源紧缺、作业流程繁琐、实时响应难等技术问题,通过持续夯实人工智能平台算力能力,以人工智能技术解放生产力,赋能电网公司高质量发展。在输电线路运行维护方面,算力、框架、算法全栈国产化适配的广西输电人工智能大模型,相比传统小模型,在准确率、泛化能力、识别效率等方面都有更优越的表现。如图2所示。

图2 输电线路运行维护
此外,大瓦特CV大模型,能够更加精准地识别输电线路缺陷类型和位置,相比传统小模型,大模型的识别效率提升了5倍,准确率提升了15%,能够更加精准地表述缺陷隐患类型和位置,解决模型碎片化问题,更好地处理未见过的电力业务场景缺陷。
(2) 山东能源“盘古矿山大模型”
盘古矿山大模型由山东能源集团、华为、云鼎科技联手研发,该模型涵盖采煤、掘进、主运、辅运、提升、安监、防冲、洗选、焦化9大专业场景应用。目前,山东能源集团已经实现AI大模型在人员误入危险区域及关键岗位行为状态监护、变电所巡检合规性监测、采煤转载装运异常AI智能控制、防冲卸压工程打钻深度监管、介质桶跑粗智能监测、智慧配煤、煤仓运行异常状态监控等场景的落地,在兴隆庄煤矿、李楼煤业、济二煤矿、鑫泰能源等煤矿完成试点建设。利用该模型,实现煤炭智能开采产量占比超过80%,减少井下作业人员1.2万人,为煤矿行业乃至整个能源行业高质量发展注入了新动能。如图3所示。

图3 AI智能监控
2.2 民航领域大模型应用
(1)中国航信“千穰大模型”
中国航信旗下航旅纵横团队于2023年8月25日发布了首个民航领域垂直大模型“千穰”。千穰大模型是融合了视觉大模型、语言大模型、多模态大模型和计算大模型的图文计算多智体,以强大的人工智能技术,赋能民航产业数智化建设和民航旅客智慧出行。面向旅客,千穰大模型不仅具备日常闲聊、百科常识等通用大模型的通识能力,还能垂直深入民航,给用户提供专业、实时、准确、全面的民航信息。面向行业,千穰打造了数字机坪全景、保障节点感知、机位违规预警、智能机位分配、区域态势感知、客群行为分析、风险行为识别等面向行业的解决方案,帮助工作人员监测、分析行业运行情况,提高决策能力。如图4所示。

图4 千穰大模型
2.3 汽车行业大模型应用
(1) 吉利汽车“吉利星睿AI大模型”
2024年1月,吉利正式发布汽车行业全栈自研全场景AI大模型——吉利星睿AI大模型。星睿AI大模型包括语言大模型、多模态大模型、数字孪生大模型3大基础模型,并由此衍生出NLP语言大模型、NPDS研发大模型、多模态感知大模型、多模态生成大模型、AI DRIVE大模型、数字生命大模型6大能力模型。不同于科技巨头开发的通用大模型,星睿AI大模型深度聚焦汽车垂直领域,对车辆功能使用、常见车辆问题、交通法规、售后服务等海量知识库进行大规模学习,拥有汽车行业最完备的专业知识储备,仅星睿语言大模型训练过程中就特别补充了汽车领域39类知识库。未来,星睿AI大模型知识结构还将持续更新迭代,成为用户趁手的“汽车百科全书”。
2.4 通信行业大模型应用
(1) 中国电信“星辰系列大模型”
星辰系列大模型是由中国电信完全自主研发的国内领先AI大模型,具备了语义、语音、视觉及多模态大模型的完备基础框架。其中语义大模型于2023年11月份发布千亿参数版本,在大模型知名榜单CSL排名第五、GAOKAO排名第七、AGIEval排名第八。视觉大模型赋能100多个城市治理下游任务,算法日均调用量达3.3亿次。多模态大模型聚焦图文生成和图文理解能力,采集超过12亿的风格数据,文图检索精度达到SOTA,支持20多种风格生成。语音大模型可实现高精度多方言的语音识别以及多语种、多风格、多音色的语音合成。2024年1月,中国电信星辰语义大模型TeleChat-7B版本宣布开源,开放1T高质量清洗数据集。之后,中国电信开源12B版本模型,为国产大模型的发展注入新动能。
(2)中国移动“九天AI大模型”
在2023年世界人工智能大会“大模型与深度行业智能”创新论坛上,中国移动正式发布“九天·海算政务大模型”和“九天·客服大模型”。其中,“九天·海算政务大模型”主要目标是对数字政府的全流程进行深层赋能,助力政府提供更加便捷和智能的政务服务。“九天·客服大模型”基于中国移动几亿用户数据,把人工智能相关能力赋能客服领域多项任务,提升服务质量并降低服务成本。之后,以九天基础模型为基础,中国移动联合通信、能源、航空等行业的骨干企业共建“九天·众擎基座大模型”。目前,“九天·众擎基座大模型”已得到中国远洋、中智集团、中国铁建、中国信科、中国航信、中国航油等多家龙头及骨干企业支持。下一步,中国移动将深化产学研用合作,依托“九天·众擎基座大模型”持续促进数字经济与实体经济深度融合,把人工智能技术的创造力转化为促进经济社会高质量发展的新质生产力,助力实现国家智能化水平整体跃升。
(3)中国联通“鸿湖图文大模型1.0”
2023年6月,中国联通发布了“鸿湖图文大模型1.0”,该模型目前拥有 8 亿训练参数和 20 亿训练参数两个版本,支持以文生图、以图生图、视频剪辑等多样化AI能力,是首个面向运营商增值业务的图文双模态大规模预训练模型。“鸿湖图文大模型1.0”立足文旅产业的真实需求和年轻用户群的增值业务场景,主打国风水墨画生成。该大模型已成功赋能文旅数字人的建设,实现了降本增效。
2.5 金融行业大模型应用
(1) Bloomberg“BloombergGPT”
Bloomberg依托其四十多年来积累的大量金融数据源,创建了一个包含3 630亿token的金融数据集FinPile,又与公共数据集叠加成为了包含超7 000亿token的大型训练语料库。基于该大型训练语料库,训练了具有500亿个参数的大规模生成式人工智能模型BloombergGPT。BloombergGPT能够针对金融领域的专业术语、行业趋势、经济数据等为用户提供专业的高质量的信息和分析服务。此外,BloombergGPT模型在金融领域取得好效果的同时,并没有牺牲模型通用能力,根据Bloomberg公开的信息,在金融领域任务上,BloombergGPT与GPTNeoX、OPT、BLOOM、GPT-3等模型相比,综合表现最好;在通用任务上,BloombergGPT的综合得分同样优于相同参数量级的其他模型,并且在某些任务上的得分要高于参数量更大的模型。出于行业安全性的考虑,BloogbergGPT模型未被公开。
(2)Broadridge“BondGPT”
2023年6月,Broadridge子公司LTX宣布,通过GPT-4打造了BondGPT,主要用于帮助客户回答各种与债券相关的问题。为了增强ChatGPT的输出准确性并满足金融业务场景需求,LTX将Liquidity Cloud中的实时债券数据,输入到GPT-4大语言模型中,帮助金融机构、对冲基金等简化债券投资流程以及提供投资组合建议。BondGPT能够根据用户输入的问题,回答符合需求的公司名字、利率、价格、发布日期、到期日期、债券评级等信息。同时支持连续、深度对同一个问题进行发问,使用方法与ChatGPT基本相似。目前,BondGPT已经投入使用。如图5所示。
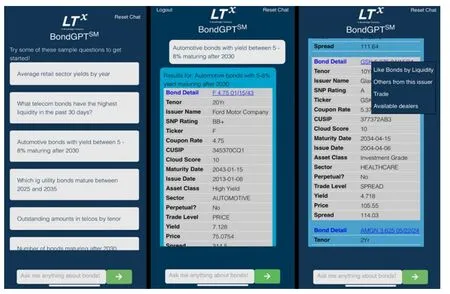
图5 BondGPT产品展示
2.6 医疗行业大模型应用
(1) 谷歌“Med-PaLM 2”以及“Med-PaLM M”
Med-PaLM 2由谷歌DeepMind的医疗健康团队基于谷歌的基础大语言模型PaLM 2微调得到的一款针对医学领域医疗问题问答的医疗聊天机器人。Med-PaLM 2是第一个在美国医师执照考试(USMLE)的MEDQA数据集上达到“专家”考生水平的大模型,其准确率达85分以上,也是第一个在包括印度AIIMS和NEET医学考试问题的MEDMCQA数据集上达到及格分数的人工智能系统,得分为72.3分。此外,在用户隐私方面,谷歌确保测试Med-PaLM 2的客户能够在加密设置中保留对其数据的控制权,科技公司无法访问,并且人工智能程序不会摄取任何数据。
而谷歌的Med-PaLM M 是一个大型多模态生成模型,可以灵活地编码和解释临床语言、医学图像和基因组学等各种类型的生物医学数据,在医学问答、生成放射学报告和识别基因组变异等任务中表现优异。Med-PaLM M是在谷歌的PaLM-E基础大模型上进行微调得到的,为了评估Med-PaLM M在实际临床环境中的效果,放射科医生对由AI生成的不同规模的报告进行了评估。研究结果显示,人工智能的错误率与放射科医生的错误率相当,这表明了Med-PaLM M在临床场景中的应用潜力。
猜你喜欢
青年生活(2019年23期)2019-09-10 12:55:43
商界(2019年12期)2019-01-03 06:59:05
IT经理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
南风窗(2016年19期)2016-09-21 16:51:29
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
中共南宁市委党校学报(2015年4期)2015-02-28 11:48:10
计算物理(2014年2期)2014-03-11 17:01:39
中国音乐教育(2014年7期)2014-02-06 21:46:15
