
基于机器视觉的电力运维数据提取与分析方法研究
2024-05-06 08:11:42高峰杨莹马玮娜
电子设计工程 2024年9期
高峰,杨莹,马玮娜
(1.国网河南省电力公司信息通信公司,河南郑州 450052;2.河南九域腾龙信息工程有限公司,河南郑州 450000)
随着信息技术的快速发展,智能电网成为我国相关建设的重点内容及方向,同时也为进一步推动电力信息通信系统的建设提供了契机[1]。当前各地电网企业已初步建立了电力运营监控与信息管理平台,通过对运维数据的采集、分析来优化电力通信运维体系,从而提升智能电网的水平[2]。但由于信息系统的检修存在管理流程、网络环境、涉及人员及远程操作均较为复杂的特点,因此对相关操作进行审计仍是检修管理中的难点[3-5]。人工智能(Artificial Intelligence,AI)的崛起,使得计算机视觉技术被广泛应用于医疗、工业、教育等领域[6-8],实现了对视频图像数据进行分类、检测、识别和分割等任务。而应用该技术对机房的视频监控数据进行实时采集与分析,可获取现场检修时间、人员和位置等信息;再将其与远程检修审计信息进行对比分析,可以找出不符合检修计划、无票检修等一系列问题,从而及时发现并审计违规行为。其中的关键技术是实现对监控视频图像中检修人员的检测,即人员目标检测。通过利用目标检测模型对机房视频帧图片进行计算识别,以此判断各个信息机房中人员出现的时间及位置信息。文中基于深度学习(Deep Learning,DL)算法,设计了一种针对机房检修人员的检测模型。
1 理论分析
1.1 目标检测
目前主流的目标检测方法主要采用深度学习算法[9-11],通常可分为两种:两阶段检测与单阶段检测。两阶段检测使用多个固定的滑动窗口对整个图像进行扫描,以产生多个候选框,再从中筛选出正样本并进行二次修正后得到最终效果[13]。而单阶段检测提前划分单元格,再将实例对象放入其中,最后不断对锚框进行分类与位置修正并得到最终的效果。
1.2 YOLOv4算法
YOLO 系列算法是单阶段检测模型,其优点是能显著提升计算速度,故可满足实时性要求较高的场景。该模型的核心思想是将目标检测看作一个回归问题,并把输入图片划分成若干网格;再用卷积神经网络(Convolutional Neural Networks,CNN)对图片进行特征提取;当检测到目标时,根据当前网格的先验框得出预测框,进而实现对图像类别及位置的判别。
YOLOv4 模型[14]相比于传统的YOLO 系列算法,可大幅提高检测速度和准确性。该模型从数据预处理、主干网络、激活函数与损失函数多个部分进行优化。改进模型主要有三个贡献:1)构建一个低门槛、高性能的目标检测模型,即使用较低的GPU 就能训练出一个快速且准确的目标检测器;2)验证了两种先进Bag-of-Freebies 和Bag-of-Specials 方法对于模型训练的影响;3)引入了交叉迭代归一化(Cross Iteration Batch Normalization,CBN)、特征融合PAN、空间注意力机制SAM 等技术。
2 基于改进YOLOv4的运维人员检测模型
2.1 总体架构设计
由于对机房监控视频处理的实时性要求较高,且还需保证能够准确识别和定位人员信息,所以文中以YOLOv4 作为基础模型。整个模型包含输入端、主干网络、颈部网络及输出端四部分。首先,将机房运维监控的视频帧图像作为网络的输入;然后,使用主干网络对图像特征加以提取;再利用颈部网络将获得的特征做进一步提取,并对不同尺度特征图的信息进行融合;最终输出检测结果。改进YOLOv4 框架结构如图1 所示。
与传统的YOLOv4 相比,文中进行了如下改进:首先,用DenseNet 替换传统模型主干网络中的Cspdarketnet53,原因是DenseNet 网络可增强层与层之间的密度,并提高特征的传播及融合,从而减少梯度消失的问题且降低了参数的数量与计算负荷;其次,提出人员特征提取模块PM 来改进空间金字塔池化,该模块能够对不同尺度的机房运维人员特征进行有效提取;此外,CBL 模块则是由卷积Conv、批量归一化BN 以及Leaky ReLU 激活函数组成。
2.2 DenseNet模块
由于文中将损失函数变为Leaky ReLU,促进了特征的重用和融合,因此,改进模型通过使用DenseNet模块来提高层间的密度,使网络结构变得更为复杂,从而更有效地对人员信息进行检测。
DenseNet[15]主要思想是通过特征重用和旁路设置来解决梯度消失与模型退化的问题,同时还大幅减少了参数的数量。其网络结构也是基于ResNet 网络[16],不同之处在于DenseNet 中建立了所有前层及后层间的密集连接,并同时重用了该特性。密集网模型由密集块与中间区间模块过渡层组成。在同一个密集块中,特征层的宽度和高度并未改变,而通道的数量则会发生相应变化。过渡层是一个连接不同密集块的模块,其结合了密集块的特性以减少前一个密集块的宽度及高度。在模块被堆叠后,功能也会连续堆叠,由此使得各层间的连接更为紧密。DenseNet 网络结构如图2 所示。
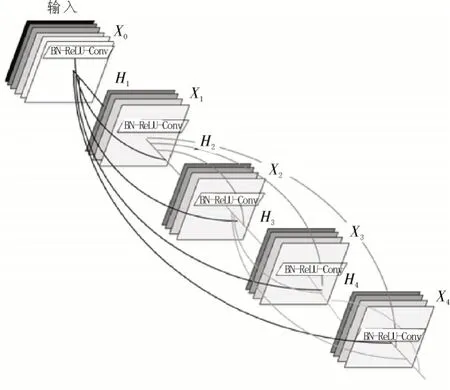
图2 DenseNet网络结构
传统的网络经过第n层后的输出结果为:
而在DenseNet 中,其会连接前面所有层作为输入,由此得到的结果为:
式中,Hn(·) 表示非线性转化函数,包括归一化、激活函数、池化和卷积操作;n层与n-1 层之间实际包含多个卷积层。
2.3 人员特征提取模块PM
由于室内检修人员的目标尺度大小不同,使用单一尺度的特征提取效果通常并不理想。而提取多尺度特征信息的关键,是对目标的每种尺度均进行充分利用,因此文中利用先验的人员长宽比信息加入SPP 结构进行改进,以获取不同尺度的人员感受野,进而有效对检修人员的多尺度特征加以提取。
SPP 网络使用的感受野均为正方形,但这样会覆盖诸多除人员以外的无效背景,导致图像噪声较多,进而干扰人员多尺度信息的提取。因此文中采用更宽的网络加入人员的长宽比先验信息,形成了一个新的人员特征提取模块PM,其结构如图3所示。
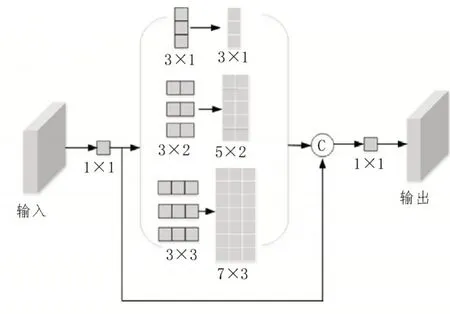
图3 PM结构图
人员特征提取模块采用3×1、3×2 和3×3 共3 种大小不同的感受野来进行特征提取。为了能够拟合人员的宽高比,对3×2 与3×3 的卷积核在高度上使用扩张率为1、2 的空洞卷积;同时借助1×1 的卷积对输入通道进行压缩,以减少计算量;最后,再使用1×1的卷积进行通道变换。
2.4 GIoU损失函数
在目标检测中,仅基于距离的损失函数无法进行准确度量,因此文中采用GIoU 作为损失函数,其能够对预测边框与实际标注边框进行对比,从而计算损失。
GIoU 损失函数可用公式表示为:
其中,LGIoU表示GIoU 的损失值;LIoU代表实际真实框与预测框的交并比;d表示两个框中心点之间的欧式距离;c表示两个框最小闭包区域的对角线长度;v表示两个框宽高比一致性的参数;wgt和hgt、w及h分别表示真实框、预测框的宽度及高度;α表示长宽比一致的权衡函数。
3 实验与数据分析
3.1 样本数据集
由于设备检修工作人员均在室内工作,故摄像头在采集数据时易受到多种因素的影响。为了提高模型的检测效果,选用旷视科技的CrowdHuman 数据集为基础数据集来进行实验,该数据集内包含有各种人员在不同背景环境下的24 370 张图片。实验将其中15 000 张作为训练集,另外的5 000 张作为测试集,剩余的4 370 张则为验证集。
3.2 实验环境和模型训练
实验采用的深度学习框架为PyTorch1.0 版本,使用的编程语言为Python,操作系统为Linux,处理器为Intel Core i7-5960,内存为32 GB,显卡为RTX2080。
在训练时将最小批次大小设置为128 张,并采用随机梯度下降法作为模型训练的优化策略。初始学习速率设置为0.001,动量设置为0.9,其余参数设置与YOLOv4 模型相同且保持不变。
3.3 评价指标
在目标检测时,通常使用评价指标来判别模型的优劣。文中采用的指标除了常见的准确率、召回率、F1 值外,还需增加检测速度。每秒帧率(FPS)是最常用的平均指标,即在硬件环境相同的情况下,模型1 s 内处理图片的帧数,FPS 值越大,说明模型的检测速度越快,且性能越优。
根据人员目标检测的真实情况和预测情况可以分为四类:1)TP,人员检测框的真实情况是正类,预测也为正类;2)TN,人员检测框的真实情况为负类,预测也为负类;3)FP,人员检测框的真实情况是负类,预测是正类;4)FN,人员检测框的真实情况是正类,预测是负类。
准确率、召回率以及F1 值的计算方式如下:
3.4 结果与分析
将数据集输入训练模型,经过800 次的迭代训练后,整个模型取得了良好的结果,图4 显示了准确率与迭代次数的关系曲线。从图中可以看到,迭代800 次后的训练集、测试集和验证集准确率基本不变,且模型趋于稳定,精度逐渐达峰。表1 是模型不同评价指标的最终结果,可看到模型的准确率为87.9%,召回率为80.1%,F1 值为88.7%,FPS 为73,总体取得了较好的结果。

表1 改进YOLOv4模型评价指标
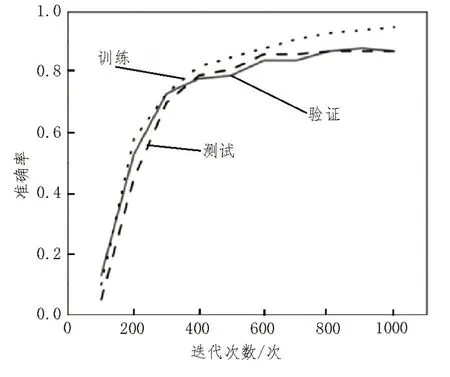
图4 准确率与迭代次数关系图
为了验证文中所提出模型的性能,将检测结果与主流的目标检测模型进行对比,结果如表2 所示。从表中可以看出,该文模型的准确率相比SSD、YOLO 以及YOLOv4 模型分别提高了25.8%、19.2%和7.3%;召回率比SSD 模型提高了21.4%,但相比于YOLOv4 模型略低;F1 值则比YOLOv4 模型提高了9.2%;同时FPS 也达到了73,较其他模型能够更快处理视频图像数据。

表2 不同算法模型的评价指标对比结果
4 结束语
在电力运维的过程中,传统信息系统检修操作过程需要依靠人工监护及审计,监护人员需要全程跟踪操作过程,事后审计也需要耗费大量精力进行数据回溯,审计效率低,且在多操作同时开展时,难以兼顾所有的操作细节。为了解决上述问题,文中提出了基于YOLOv4 的改进模型来对检修人员进行定位检测。该模型用DenseNet 网络替换原有YOLOv4 中的主干网络,从而减少了梯度消失,且使参数的数量和计算负荷均有所降低。同时还提出了人员特征提取模块PM,对不同尺度的机房运维人员特征进行有效提取。在公开数据集上进行的实验验证结果表明,所提出的模型准确率达到了87.9%,召回率为80.1%,F1 值则达到88.7%,FPS 为73,优于目前大部分主流模型的效果。因此该模型可以有效处理电力运维视频图像数据,实现对电力运维检修人员的智能化审计。然而模型仍存在一定的不足,后续可以进一步对模型加以改进,从而提高模型的准确率,同时优化模型计算效率。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2019年5期)2019-08-30 03:49:14
电子制作(2018年19期)2018-11-14 02:37:08
能源(2018年8期)2018-09-21 07:57:24
中国交通信息化(2018年5期)2018-08-21 03:37:40
能源(2017年11期)2017-12-13 08:12:25
自动化学报(2017年11期)2017-04-04 02:52:58
现代工业经济和信息化(2016年8期)2016-05-17 05:37:41
