
基于大数据分析的电子商务推荐系统
2024-05-03 05:41张艳
信息记录材料 2024年3期
张 艳
(苏州旅游与财经高等职业技术学校 江苏 苏州 215104)
0 引言
随着电子商务的蓬勃发展,商品信息的急速增长导致用户在面对庞大的选择时面临困难。电子商务推荐系统应运而生,成为缓解信息过载问题、提升用户体验的核心技术之一[1-2]。本文专注于基于大数据分析的电子商务推荐系统,旨在提出创新的商品推荐系统框架,深入研究其中基于协同过滤的推荐方法[3-4]。通过深入理解协同过滤方法在推荐系统中的应用,本研究对该方法做了优化以满足大数据环境的需求,提高推荐的准确性和个性化水平。
1 商品推荐系统框架
本研究提出的商品推荐系统构建了一个包含5 个关键层级的框架以实现全面而高效的推荐功能,包括应用层、服务层、算法层、缓存层和存储层,如图1 所示。
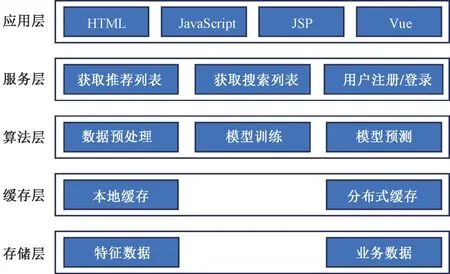
图1 商品推荐系统框架设计
在应用层方面,系统采用了超文本标记语言(hypertext markup language, HTML)、JavaScript、Java 服务器页面(Java server pages, JSP)和Vue 等技术,以构建用户友好且具有响应性的前端界面。这一层级负责与用户进行交互,提供直观的推荐系统界面,以确保用户体验的优越性。服务层是推荐系统的核心,包含了获取推荐列表、获取搜索列表以及用户登录/注册等服务。这一层级通过有效的服务接口与应用层进行通信,从而实现用户请求的响应和处理。在算法层,推荐系统经过了数据预处理、模型训练和模型预测3 个关键步骤。首先,对原始数据进行预处理,以清理和转换数据,为后续的模型训练做好准备;接着,在模型训练阶段,系统利用丰富的数据集进行算法学习,以建立高效的推荐模型;最后,在模型预测阶段,系统根据用户的历史行为和个性化特征,实时地生成推荐结果。缓存层采用了本地缓存和分布式缓存Redis,以提高系统的响应速度和性能。本地缓存用于存储频繁访问的数据,减少数据读取时间;而分布式缓存Redis 则通过将数据存储在内存中,加速了数据的检索和传输,从而提升了系统的整体效率。最后,存储层包含特征数据和业务数据。特征数据用于存储商品和用户的相关特征,为算法提供丰富的信息。业务数据则包含了系统的运行日志、用户行为记录等关键信息,为系统的优化和改进提供数据支持。
2 基于协同过滤方法的商品推荐方法
2.1 基于用户的协同过滤方法
基于用户的协同过滤方法是一种推荐系统中常用的策略,其基本思想是通过分析用户与产品之间的相似性,从具有相似喜好的用户中推荐未被目标用户评价过的产品[5-6]。具体而言,该方法以用户的历史行为为依据,计算用户之间的相似度,并基于相似用户的评价历史为目标用户推荐未曾接触过的产品。如图2 所示,假设存在用户1、2 和3,以及产品1、2、3 和4。通过分析用户1 和用户3与4 种产品的联系,系统可以计算这两位用户之间的相似性。若相似性较高,即两者在产品偏好上存在一致性,系统将基于用户1 的历史行为向用户3 推荐用户1 喜欢但用户3 尚未关注的产品,如产品1 和4。
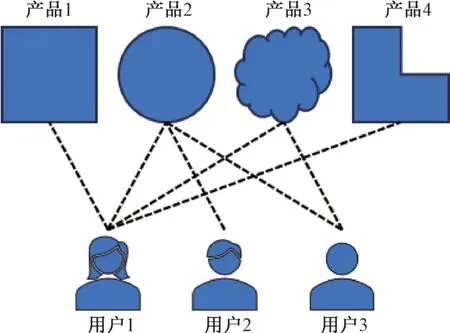
图2 基于用户的协同过滤方法
在大数据环境下,基于用户的协同过滤方法的推荐存在一些问题:
(1)计算复杂度高。大规模用户和产品数据集导致相似度计算的复杂度大幅增加,占用大量计算资源,影响系统的实时性和效率。
(2)稀疏性问题。随着数据规模的增加,用户与产品之间的评价数据呈现稀疏性,导致相似用户的准确度下降,降低了推荐的精准性。
(3)数据隐私和安全性。在大数据环境中,用户的个人信息可能涉及大量敏感数据。基于用户的协同过滤方法在计算相似度时需要比对用户行为,可能存在潜在的隐私泄露和安全性问题。
(4)个性化不足。随着数据量的增大,基于用户的协同过滤方法可能更倾向于推荐热门产品,而忽略了个体用户的特殊偏好,降低了推荐的个性化水平。
这些缺陷使得在大数据环境下基于用户的协同过滤方法在应对复杂实际场景时面临一系列挑战,需要进一步优化和改进。
2.2 针对大数据分析的方法优化
本研究聚焦于大数据环境下基于用户的协同过滤推荐方法,特别关注计算复杂度高的稀疏性问题。为应对这一挑战,研究提出了3 种关键方法,包括基于奇异值分解的降维处理、引入正则化项以解决稀疏性问题以及采用随机梯度下降的优化方法进行用户和产品特征矩阵的迭代更新。
在面对大规模数据集的情境下,为降低计算复杂度,研究采用奇异值分解(singular value decomposition, SVD)来进行降维处理[7-8]。通过对用户-产品评分矩阵进行SVD 分解,得到低秩的近似矩阵,从而减少数据的维度,简化了相似度计算的过程。具体而言,对于一个用户-产品评分矩阵R,其奇异值分解表示为:
式(1)中,U为用户特征矩阵,∑为包含奇异值的对角矩阵,VT为产品特征矩阵。通过仅保留前k个最大的奇异值及其对应的特征向量,实现了对原始矩阵的降维处理,进而降低了计算的复杂度。
为应对稀疏性问题,研究引入正则化项,通过在目标函数中添加正则化项对用户和产品的特征进行约束[9-10]。设P为用户特征矩阵,Q为产品特征矩阵,则目标函数为:
式(2)中,λ为正则化参数,表示Frobenius 范数。通过在目标函数中引入正则化项,研究在优化的过程中对用户和产品的特征进行了有效的约束,缓解了稀疏性问题。
为进一步提高计算效率,研究采用了随机梯度下降(stochastic gradient descent, SGD)优化方法[11-12]。通过使用随机梯度下降,研究能够在每次迭代中随机选择部分样本进行更新,避免了对整个数据集的完全遍历。具体而言,对于用户i和产品j的评分Ri,j,采用以下更新规则:
式(3)、式(4)中,ei,j为实际评分与模型预测之间的误差,α为学习率。通过随机梯度下降的迭代更新,研究有效地提升了模型的收敛速度和计算效率,适应了大数据环境的需求。
3 实验与系统测试
3.1 系统构建
本实验的一部分核心硬件和软件环境配置分别如表1、表2 所示。

表1 硬件环境配置

表2 软件环境配置
系统构建的过程需要经过多个步骤,本研究按照如图1 所示的商品推荐系统框架构建了推荐系统:
(1)应用层构建。基于Visual Studio 开发工具使用HTML、JavaScript 等前端技术进行用户界面设计,利用Vue.js 等框架编写前端交互逻辑,确保用户友好的界面和流畅的交互。
(2)服务层构建。使用RESTful API 等标准设计服务接口,确保各个服务之间能够进行有效的通信;使用Spring 框架等技术实现服务层逻辑,包括获取推荐列表、获取搜索列表、用户登录/注册等服务。
(3)算法层构建。利用Python、Pandas 等工具进行原始数据的清理、转换和标准化,并用TensorFlow 库进行推荐算法的模型训练。
(4)缓存层构建。利用Ehcache 设置本地缓存,提高对于频繁访问数据的读取速度;使用Redis 分布式缓存工具,配置集群模式以及合适的缓存策略以提升系统整体的性能。
(5)存储层构建。使用非关系型数据库存储用户和产品的特征数据。设计合适的表结构或文档模型,确保数据的存储和检索效率。
3.2 系统测试
用户登录和操作的实验流程如图3 所示。首先,判断用户是否登录,如果未登录则直接抽取热门商品推荐;然后,判断该用户是否有历史记录或标签,如果是则进行推荐,否则直接抽取热门商品进行展示。

图3 系统推荐流程
该系统测试的搜索结果界面如图4 所示,包含搜索框、搜索结果、实时推荐、热门推荐等。通过搜索框,用户能够方便快捷地输入关键词,提高了系统的用户友好性,搜索结果展示在页面上,确保了信息的直观呈现。实时推荐的即时性是用户体验的关键,通过所提优化方法系统能够在用户输入关键词时,迅速返回相关的实时推荐结果。热门推荐可以吸引用户点击,增加用户在网站上的停留时间,提高用户的参与度;并且热门推荐可以有效推广网站上的热门商品或服务,增加其曝光度。

图4 用户搜索后的系统推荐界面
用户通过搜索框找到期望的产品,实时推荐符合其兴趣,热门推荐引导用户发现热门商品,这些方面的综合表现将直接影响用户满意度。通过对搜索、实时推荐和热门推荐等功能的综合分析,可以初步证明所采用的商品推荐系统方法是可行的,进一步的用户反馈和系统性能测试将有助于更全面、深入地评估方法的效果。
4 结语
综上所述,本文提出的电子商务推荐系统框架在大数据环境下展现了可行性。通过细致设计的层级结构,系统能够高效地整合多种推荐算法,同时通过优化协同过滤方法,解决了计算复杂度高和稀疏性问题。在系统构建过程中,采用了现代化的硬件和软件配置,通过综合测试验证了系统的性能和用户体验。通过实际系统构建和测试,展示了所提框架的实际应用潜力,为电子商务领域的推荐系统设计和应用提供了有益参考。未来,可在个性化推荐和系统扩展性方面进一步拓展研究,以不断提升系统的性能和用户满意度。
猜你喜欢
科学大众(2020年23期)2021-01-18
汽车观察(2019年2期)2019-03-15
中国惯性技术学报(2019年6期)2019-03-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
海外星云(2016年7期)2016-12-01
中国卫生(2016年5期)2016-11-12
家庭百事通(2016年5期)2016-05-06
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
生物进化(2014年2期)2014-04-16
