
基于人工智能的视频监控异常行为检测方法
2024-05-03 05:41程铭瑾
信息记录材料 2024年3期
程铭瑾
(福建开放大学职业学院 福建 福州 350001)
0 引言
在当今社会,随着城市化的不断推进和科技的飞速发展,视频监控系统已经成为维护个人和社会安全的重要工具之一[1]。然而,传统的视频监控系统往往仅仅能够提供对静态场景的观测,对于动态场景下的异常行为检测却面临着巨大的挑战。因此,为了更加高效地应对复杂多变的安全威胁,本研究提出了一种基于深度学习的视频监控异常行为检测方法。
本研究通过构建一个完整的视频智能监控系统总体框架,致力于实现对多样化场景的全面监测。该框架以实时性和准确性为核心目标,通过整合先进的技术,为后续的异常行为检测奠定了坚实的基础。为了更加精准地捕捉监控画面中的关键信息,本研究在目标检测与跟踪阶段采用了深度学习的YOLO(you only look once)[2]目标检测算法。该算法以其高效的实时性和精确的目标定位为视频监控系统提供了可靠的目标识别能力,从而为后续的异常行为分析提供了有力的支持。本研究的关键创新点在于,在动作识别阶段采用了三维卷积神经网络(3-dimensional convolutional neural network, 3D-CNN)[3],以更加全面地捕捉目标在时空上的演变规律。通过对视频序列进行立体感知,该方法能够更准确地捕捉人体动作的细微变化,为异常行为的早期识别提供了可靠的数据支撑。最后,为了验证所提出方法的有效性,本研究进行了一系列实验,并对实验结果进行了分析。实验结果充分证明了本方法在异常行为检测方面的卓越性能,为未来智能视频监控系统的发展提供了有益的借鉴。
1 视频智能监控总体框架
本研究所提出的视频监控异常行为检测方法的总体框架如图1 所示,包括了视频采集、目标检测跟踪、动作识别以及异常行为判断等,以实现对监测场景的全面而高效的分析。

图1 视频智能监控的总体框架
首先,系统通过视频采集模块实时获取监测区域的画面信息。其次,系统采用YOLO 算法对监测画面中的目标进行迅速而准确的识别与定位,该模块不仅能够有效检测场景中的多个目标,而且能够跟踪它们在画面中的运动轨迹,为后续的动作识别提供了可靠的基础。最后,在目标检测跟踪的基础上采用3D-CNN 实现动作识别,该模块以视频序列为输入通过对时空信息的深度学习分析,能够捕捉到目标在不同时间段内的动作演变规律,实现对人体行为的高度敏感识别。在动作识别的基础上,系统进一步判断是否为特定的异常动作。若检测到特定异常动作,则系统会立即产生预警信号;反之,如果未检测到异常动作,则系统将继续进行视频采集,保持对监测区域的全面监视。
2 基于人工智能的异常行为检测
2.1 基于YOLO 的目标检测跟踪方法
定义监测区域为R,视频帧序列为{It},其中t表示时间。在YOLO 模型中,目标检测和跟踪是分开进行的。
YOLO 使用一个单一的神经网络,将目标检测问题转化为回归问题。设D表示每个目标的边界框坐标,C表示目标的类别,那么对于一个目标i, 其在图像中的得分Pi可以表示为:
式(1)中,Pr(Ci) 是目标属于某一类别的概率,IoU(Di,) 是目标框Di与真实框的交并比。模型的最终输出是所有目标的得分矩阵P:
式(2)中,N是目标的数量。
在目标检测的基础上,本研究使用卡尔曼滤波器[4]实现目标跟踪。设目标在时间t的状态为St=[xt,yt,wt,ht],其中(xt,yt) 是目标中心的坐标,wt和ht分别是目标的宽和高,则卡尔曼滤波器的预测方法为:
式(3)、式(4)中,A是状态转移矩阵,Pt-1是时间t -1 时刻的状态协方差矩阵,Q是过程噪声的协方差矩阵。接着,可以通过观测得到的目标位置更新状态:
式(5)~式(7)中,H是观测矩阵,R是观测噪声的协方差矩阵,O是在时间t时刻通过目标检测得到的位置。
通过以上方法,YOLO 模型能够在视频监控中实现对目标的准确检测和鲁棒跟踪,为后续的行为分析提供了可靠的基础。
2.2 基于三维卷积神经网络的动作识别
3D-CNN 是一种在时空域对数据进行卷积操作的深度学习模型,其结构如图2 所示。该结构输入层接收来自视频的三维数据,卷积层使用卷积运算来提取特征,池化层用于减少输出特征图的大小同时保留重要的特征,全连接层将输出特征图转换为一个标量值。
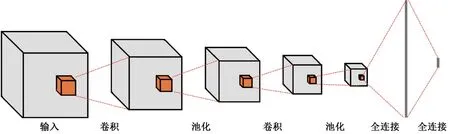
图2 3D-CNN 的模型结构
假设有一个视频序列V, 其中每一帧图片为Ft, 表示为:
式(8)中,T是视频的帧数。为了进行动作识别引入了3D 卷积操作来考虑时序上邻近帧之间的关系。设3D卷积核的大小为C×H×W,其中C为通道数,H和W分别为高度和宽度。在时序上,卷积核将沿时间轴滑动,从而捕捉到视频中目标的时序特征。
动作识别的过程可以表示为在每个时间步t上,使用3D 卷积核对当前帧Ft及其相邻的若干帧进行卷积操作。假设输出的特征图为Mt,则该操作可以表达为:
式(9)中,∗表示3D 卷积操作,σ是激活函数,W和b分别是卷积核的权重和偏置,Tk是卷积核的时间跨度,决定了网络在时序上捕捉的信息量。通过3D 卷积的逐帧滑动,可以得到一系列时序上的特征图{M1,M2,…,MT},这些特征图已经融合了视频序列中目标的时空信息。接下来,为了全局理解目标动作,可以使用全局平均池化(global average pooling,GAP)[5]对时序维度进行池化操作,得到整体的时序特征表示:
式(10)中,GAP 表示全局平均池化操作。通过这一过程,得到了对整个视频序列进行时空建模的时序特征表示Mglobal,最后,将该时序特征表示输入到全连接层进行分类,得到视频中目标的动作类别预测P:
式(11)中,Softmax 是用于产生概率分布的激活函数,Wfc和bfc分别是全连接层的权重和偏置。通过上述过程,3D-CNN 能够从时空维度上学习到视频中目标的动作信息,实现了对目标在视频序列中的动作识别。
3 实验与分析
3.1 数据集和开发环境
本研究采用A2D 数据集对所提方法进行测试,该数据集A2D 是用于视频中的目标识别跟踪与行为检测的一个大型数据集,包含多种类型的动作、场景和运动模式,并且数据集的标注质量较高,标注准确、完整。本研究采用的硬件和软件配置如表1 所示。

表1 实验配置
3.2 实验方案设计
本实验的实验方案为:
(1)数据准备:下载A2D 数据集,并将数据集划分为70%训练集和30%测试集。
(2)搭建深度学习环境,安装Python、TensorFlow、Keras 等深度学习框架。
(3)目标检测与跟踪:使用YOLO 模型对训练集进行目标检测与跟踪,调整参数以适应特定数据集。
(4)动作识别模型建立:设计并搭建3D-CNN 模型,用于视频中目标的动作识别。
(5)使用训练集对3D-CNN 模型进行训练,调整参数以提高模型性能。
(6)模型融合与预测:将训练好的YOLO 模型与3DCNN 模型进行融合,形成完整的异常行为检测系统。
(7)使用测试集进行综合测试。
3.3 结果与分析
本实验的部分检测结果如图3 所示,图3(a)是室内场景中,一个宝宝正在奔跑,目标检测结果准确并正确识别出其动作为“running”。图3(b)和图3(c)的目标检测和动作识别也基本正确。图3(d)是一个宝宝跌倒,目标检测结果准确并正确识别出其动作为“rolling”。从上述实验结果可以看出,该方法在正常情况下的目标检测和动作识别方面表现良好,能够准确检测出目标和动作。在危险动作情况下,该方法也能够正确识别出动作,即“宝宝摔倒了”。总体而言,该方法在目标检测和动作识别方面取得了良好的效果,具有一定的应用价值。

图3 实验结果
4 结语
本研究旨在解决视频监控系统中异常行为检测的挑战,通过融合YOLO 目标检测与跟踪以及3D-CNN 的方法,实现了对监控场景中目标行为的全面感知。在实验中,充分考虑了目标位置变化和动作时序的时空信息,构建了一套完整的异常行为检测系统。通过详细的实验设计与分析,验证了所提方法的有效性和性能优越性,为视频监控系统的智能化提供了有益的参考。未来的研究方向可包括引入更复杂的模型结构、多模态信息的融合,以进一步提升系统性能。
猜你喜欢
中国农业信息(2023年3期)2023-03-18
疯狂英语·新读写(2021年10期)2021-12-07
中国农业信息(2021年3期)2021-11-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
新世纪智能(英语备考)(2019年4期)2019-06-26
铁道通信信号(2019年11期)2019-05-21
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2016年15期)2017-01-15
中国当代医药(2015年17期)2015-03-01
