
基于语义和结构增强的时序知识图谱问答方法
2024-04-29 02:43:36黄政霖董宝良
计算机与现代化 2024年3期
黄政霖,董宝良
(中国电子科技集团公司第十五研究所系统四部,北京 100083)
0 引 言
基于知识图谱的问答推理(Knowledge Graph based Question Answering,KGQA)作为自然语言处理中的重要研究方向,主要将自然语言问题转换为计算机能够理解的语言,结合知识图谱中的信息,自发地给出答案。而在现实生活中,许多自然语言问题的出现往往伴随着对时间的限定,例如“2022 年是谁当选美国总统?”“谁在2019 年获得了诺贝尔生物学奖?”针对这些问题,传统的知识图谱并不能给出准确答案,因为其缺乏时间信息。[1]
因此,近年来,时序知识图谱成为学者们热衷研究的对象。为了深入研究基于时序知识图谱的问答技术,本文根据时序知识图谱的问题集所表现时间的形式和时间粒度,将问题集划分如表1所示的类型。
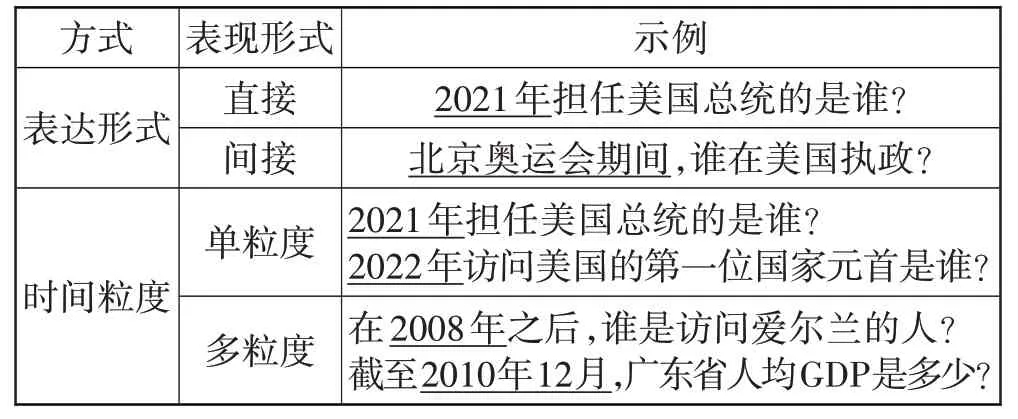
表1 问题类型
本文主要从表达形式和时间粒度2 个方面来区分问题类型。在表达形式上,分为直接表现时间的问题和间接表现时间的问题。直接表现时间的问题,指问题中带有精准时间词,如“2021 年”“2008 年1 月”“2023 年9 月12 日”等,这些时间词可直接表示问题的具体时间。间接表示时间的问题,指用某一具体事件的发生时间来限定问题的时间,如“北京奥运会期间”“二战期间”等。在时间粒度上,分为单粒度时间问题和多粒度时间问题。单粒度时间问题集是指在问题集中,只包含单个时间跨度来描述时间的问题,如:“在2008年之后……?”“在2020年之前……?”等,这些问题都是以“年”粒度来描述问题的时间。多粒度时间问题集则是指在问题集中,包含多个不同的时间跨度的问题,如“在2008 年之后……?”“在2020 年10 月前……?”等,这些问题中不仅存在以“年”粒度来描述时间的问题,还存在以“月”粒度、“日”粒度来描述时间的问题。
在目前的研究中,研究者们局限于研究表达方式直接且时间粒度单一的问题,忽视了对形式复杂、表达方式多样,且时间粒度多维的问题的研究。显然,探索形势复杂的问题更具有现实意义和研究价值。
2021 年,Saxena 等人[1]提出了CronKGQA 模型,它通过利用时序知识图谱中的嵌入方法计算语义相似性来确定答案。该模型并不依赖于人工构建的规则,且在回答简单问题方面取得了良好的效果,但是,该项研究对于一些复杂问题处理的效果较差。譬如对于“在《教父》之后,2020 年之前,哪部电影获得了最佳影片奖?”和“在2022年10月之后,第一个访问英格兰的国家元首是谁?”这2 个问题,该模型无法给出正确答案。这主要由于问题中存在的隐式时间语义(“在《教父》之后”)无法被原模型提取,且在时间粒度单一的时序知识图谱中,“月”粒度的时间语义(“在2022 年10 月之后”)无法被完全解析,从而出现与实际答案存在误差的回答。
2023 年,Chen 等人[2]提出了模型MultiQA,该方法基于MultiTQ 数据集,对时序知识图谱中的时间信息进行聚合。具体来说,它通过分析数据集中的时间粒度,使用嵌入模型对时序知识图谱中的时间信息按照不同时间粒度进行聚合,从而获得问题所对应粒度的时间信息。但是,该项研究忽略了图结构中的时间信息对于同一实体的影响会因为问题的不同而不同。譬如图1 展示的美国总统相关的时序知识图谱中,针对“二战后,美国的第一任总统是谁?”这个问题,Hoover、Roosevelt 和Truman 这3 实体所连接的时间边对President 主实体的影响是不同的。如果忽略图结构信息,或者粗略地将3 条时间边对主实体的影响程度设定为一致,则会导致推理错误。
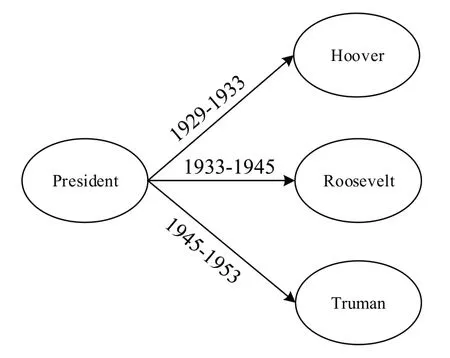
图1 时序知识图
基于以上问题,本文提出一种基于语义和结构增强的时序知识图谱问答模型(Semantic and Structural Enhancement based Temporal Graph Question Answering,SSE-TGQA)。
针对语义信息缺乏问题,本文构建语义解析模块和语义增强模块来解析问题中的实体语义和时间语义,并通过特征融合增强问题语义。具体来说,语义解析模块主要基于已有的时序知识图谱,对问题中表示的隐式时间进行改写。同时,将问题中的时间表示按照语法标准划分时间粒度,并查询时序知识图谱,构建不同时间粒度的时间嵌入,以加深对于问题中时间语义的解析。语义增强模块主要利用嵌入模型对问题本身进行编码,利用预训练后的时序知识图谱,对实体语义进行解析,并结合语义解析模块中解析出的时间语义进行融合,以增强实体语义和时间语义对于问题语义的表达。
针对结构信息缺乏问题,本文构建结构增强模块。具体来说,结构增强模块主要通过提取问题中主实体所涉及的子图结构,利用图卷积神经网络,对子图进行迭代更新。随着网络层数的加深,使其充分学习到子图的结构信息,提高模型的推理能力。
综上,本文的主要工作如下:
1)针对文献[2]推理中的语义信息缺乏问题,设计语义解析模块和语义增强模块。在问答中有效捕捉到实体信息和时间信息,丰富对于问题语义的表示,提升模型推理的准确性。
2)针对推理中的结构信息缺乏问题,设计结构增强模块。结合子图的结构信息,进行迭代更新,使嵌入向量中包含丰富的子图结构信息,增强对于子图结构的表示,提升模型推理能力。
3)基于文献[3]公开的多粒度时间数据集MultiTQ[4](https://github.com/czy1999/MultiTQ),与其他基线模型进行对比实验。实验结果表明,SSE-TGQA模型在最优基线模型的基础上绝对提升了约4%,进一步验证了SSE-TGQA模型的有效性。
1 相关工作
1.1 时序知识图谱补全
时序知识图谱指将时间维度融入到实体关系表示中的有向知识图谱。针对时序知识图谱中的补全问题,不少学者给出了解决方案[3-15]。2016 年,Jiang等人[16]首次提出了将现有事实的时间信息整合入传统知识图谱中,以预测知识图谱中的关系链接。2020年,Xu 等人[17]将时序知识图谱表示映射到多维高斯分布的空间中,以减少在时间演变过程中,实体和关系所产生的不确定性。2023 年,Hu 等人[18]提出了Transbe-TuckERTT 模型,其通过组合实体、关系和时间构建嵌入序列,并利用Transformer的自注意力机制和位置前馈网络来捕获信息之间的依赖关系,最终完成了时序知识图谱中的关系预测。
但是,现有的时序知识图谱往往存在时间粒度单一的问题。当用户给出的时间信息与时序知识图谱中的时间粒度不一致时,即使模型完成了对信息的解析,在最终关系预测时也无法匹配用户所给出的信息,从而无法完成时序知识图谱补全问题。
1.2 时序知识图谱问答
将时序信息融入到知识图谱问答[5]任务中是近几年的主流研究方向[19-20]。通过捕获问题中的时间信息和实体信息,结合时序知识图谱中的信息,构建备选答案集合,并制定评分规则,最后将评分最高的答案作为输出。
2021 年,Saxena 等人[1]基于BERT 模型构建了问题嵌入,并使用TComplex 函数对备选答案进行评分,来完成问答。同年,Mavromatis 等人[21]提出了一种TempoQR 模型,通过结合问题嵌入、时间嵌入和实体嵌入来提升模型预测准确性。2022 年,Otte 等人[22]提出了一种贝叶斯模型平均集成方法(BMA),通过结合多个时序知识图谱嵌入上的链路预测结果来提升问答性能。2023年,Chen等人[2]提出了MultiQA 模型解决多粒度时间问题,通过对时序知识图谱中的时间粒度进行分割和时间信息进行聚合,实现了对多粒度时间的解析。
但是,现有的时序知识图谱问答研究缺乏对于时序知识图谱中图结构的解析。由于在回答复杂时间构建的问题时,时序知识图谱中会捕捉到与答案相关的多条时间边,但不同的时间边对复杂时间问题的作用应该是不同的。如果忽略掉子图中的结构信息,则无法正确解析问题的时间信息,导致推理错误。
2 方法与模型
2.1 模型概览
本文提出的基于语义和结构增强的时序知识图谱问答模型的总体框架如图2所示,主要包含4个模块:
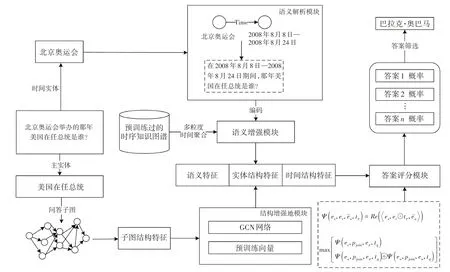
图2 总体框图
1)语义解析模块。首先,该模块抽取问题中的隐藏时间信息,并基于时序知识图谱中的信息,对问题进行重构。其次,利用Transformer模块对时序知识图谱中的时间信息按照不同的时间粒度进行聚合,得到不同粒度的时间嵌入表示,使模型能够有效提取到时序知识图谱中的时间信息。
2)语义增强模块。该模块利用预训练模型对问题进行编码。结合时序知识图谱中的信息,得到问题语义、实体语义和时间语义。将3 种语义进行融合,得到语义增强向量。
3)结构增强模块。从时序知识图谱中抽取主实体相关的k阶子图,利用图神经网络对抽取到的子图信息进行训练。同时,通过分析子图中实体的时间信息与问题的相关性,为对应边的权重进行加权处理,并更新下一层网络的状态。最终,得到编码后的时间结构特征。以此类推,可得到实体结构特征。最后将2种结构特征进行拼接,得到问题结构特征。
4)问题评分模块。将问题语义特征和问题结构特征进行拼接,并对融合向量进行打分排序,输出最后的预测结果。
2.2 准备工作
本文将时序知识图谱问答的任务定义为:给定问题文本ptext和时序知识图谱G,通过充分利用G中的信息进行查询和推理,最终得到答案集atext作为ptext的答案。
在时序知识图谱G中,每一个事件F可以表示为{s,r,o,τ},其中,s和o分别表示事件发生的头实体和尾实体,r表示2 个实体之间的关系,τ表示与该关系相关的时间戳。
本文使用文献[23]中的预训练模型对其进行编码,计算过程如下:
其中,es、er、eo、tτ分别表示实体s、实体o、关系r和时间τ所对应的m维向量,Re(·)表示实部,· 表示嵌入向量的复共轭,⊙表示对应元素相乘。
2.3 语义解析模块
由于问题中带有隐式表达的时间信息,如“北京奥运会那年”“中国建国那年”等,因此,本文首先基于时序知识图谱,改写带有隐式表达时间的问题,如图3所示。
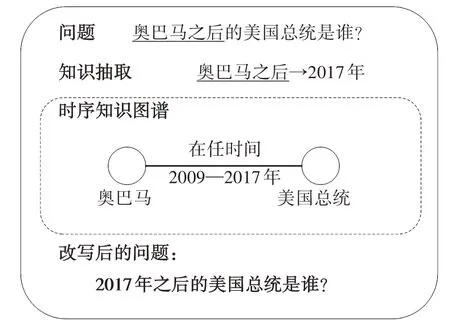
图3 隐式时间转换框图
针对较为简单的隐式时间表达问题,本文抽取问题文本中的每一个事件实体,在时序知识图谱中进行搜索查询,以检索事件实体的开始时间和结束时间,并将问题文本ptext中的事件文本pevent替换为对应的时间表达。
针对较为复杂的隐式时间表达问题,需要联合多个表达隐式时间的实体来确定时间信息。譬如“奥巴马之后的美国总统是谁?”,对于这类问题,可通过这句话中的2个实体“奥巴马”和“美国总统”来查询时序知识图谱,锁定其在任时间“2009 年—2017 年”,并将问题改写为“2017年之后的美国总统是谁?”。
基于此,本文遍历问题中所有实体在时序知识图谱的时间信息,构建不同实体对应的时间序列T=其中,n表示具有时间信息的实体或联合实体个数,并计算问题的时间表示T1,计算过程如下:
其次,由于问题和时序知识图谱中的时间粒度会存在差异。因此,假设经过隐式表达时间转换后,问题中的时间信息表示为T1,粒度为“月”,而时序知识图谱中的时间粒度为“日”,则提取时序知识图谱中的所有时间信息d1,d2,…,dn,其所对应的时间嵌入表示为Ed1,Ed2,…,Edn并将相同月份的,粒度为日的时间信息进行聚合,得到时间嵌入集合Td:
考虑到时间嵌入集合中的位置信息和文本中的位置信息一样重要,为保证不同位置的时间的正交性,本文采用正交编码对每一个时间嵌入集合中的时间嵌入进行位置编码:
式中,x表示时间嵌入集合Td中的位置,y表示在D维向量中的嵌入位置。最后,将时间嵌入集合Td中的时间嵌入与对应的位置编码进行拼接,得到融合时间嵌入集合再次,本文利用文献[24]中所提出的Transformer编码器对融合时间嵌入集合T′d进行编码,得到月粒度的融合时间嵌入集合Tm:
2.4 语义增强模块
本文利用ALBERT 预训练模型对问题进行编码,提取出其中的语义信息,计算过程如下:
为了增强问题中的实体语义,将PM矩阵中的问题标注替换为预训练的时序知识图谱嵌入,计算过程如下:
式中,WE表示C×C的投影矩阵,eα表示实体α经过时序知识图谱预训练的嵌入,tβ表示时间β经过时序知识图谱预训练的嵌入。
为了增强问题中的时间语义,本文利用语义解析模块提取的不同实体所对应的时间序列T,计算过程如下:
为了融合问题中的上下文、实体和时间信息,本文使用Transformer模块进行特征融合,最终的嵌入矩阵P的计算过程如下:
2.5 结构增强模块
为了将子图结构上的信息融入问答推理中,本文采用图卷积神经网络对子图中的结构信息进行增强处理。
考虑到在问答推理中,子图所涉及的实体的不同时间边对推理的影响权重应不同,因此,本文定义问题时间边权重来描述不同时间边对推理的影响程度,其中它表示节点vi通过关系r与节点vj相连。图中其所对应的时间戳表示为其计算过程如下:
式中,pM表示问题经过ALBERT 编码后的语义嵌入向量。可以发现,如果问题的时间落在边所在的时间范围内,则图中对应的时间边可以获得比较高的权重。
在图卷积网络的初始化阶段,对于图中的每个节点vi在第0层初始化为,根据文献[25],更新第k+1层的节点嵌入表示。计算过程如下:
式中,R代表时序知识图谱中关系集合的数量,表示与节点通过关系连接的邻居节点的集合,表示与第k层和关系r相关联的权重矩阵。
基于此,本文根据式(11)和问题时间边权重对k+1 层的节点vi的隐藏状态进行更新,计算过程如下:
式中,表示k层的节点vi的时间隐藏状态。在多次迭代更新后,节点向量中充分融合了子图中的结构信息,将最后1 层的隐藏节点的状态进行合并,得到时间结构向量信息ts。
同样,基于式(11)对实体嵌入进行迭代更新,得到实体结构向量信息es。将实体结构向量es和时间结构向量ts进行拼接,得到融合结构向量sq,计算过程如下:
2.6 问题评分模块
通过以上模块,获得了问题语义向量pq和融合结构向量sq。为了充分利用向量中隐藏的信息,将其进行拼接,计算过程如下:
最后,本文得到候选答案的分数,计算过程如下:
式中,s、o和τ分别表示标记的头实体、尾实体和时间戳,ε表示候选答案,ψ表示文献[23]中的评分方法。通过计算候选答案的得分高低,最终选择得分最高的推理答案作为问题的回答。
3 实验与结果分析
3.1 实验设定
3.1.1 实验数据集
本文使用文献[2]中的MULTITQ 公开数据集,其时间粒度分布情况如表2 所示,关系分布情况如图4所示。
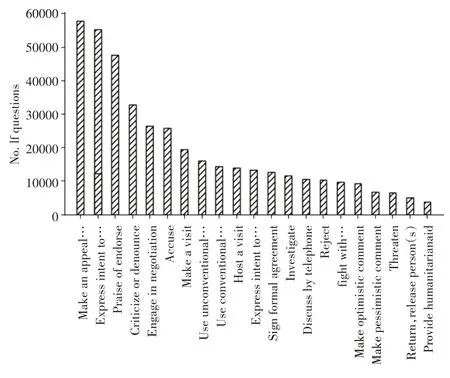
图4 关系分布情况
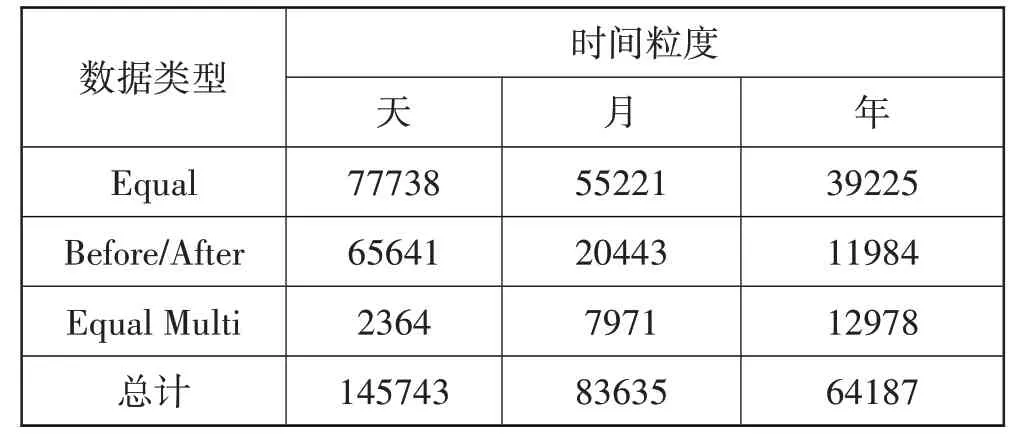
表2 时间粒度分布情况
3.1.2 参数设定
本文所采用的环境参数如表3所示。
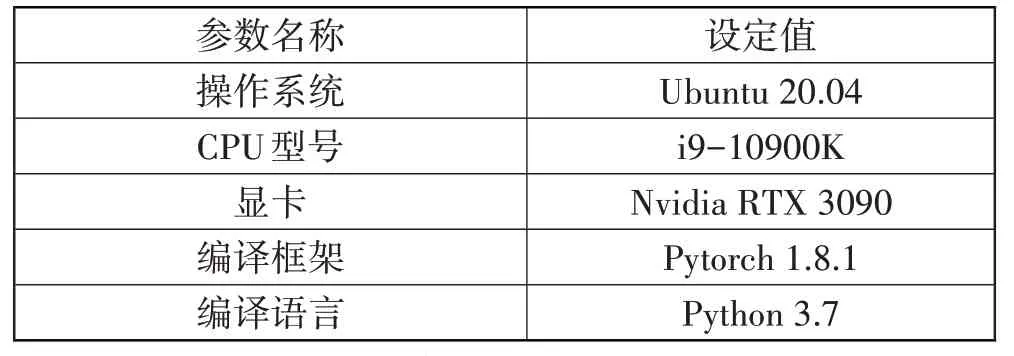
表3 环境参数
本文涉及的模型参数列表如表4所示。
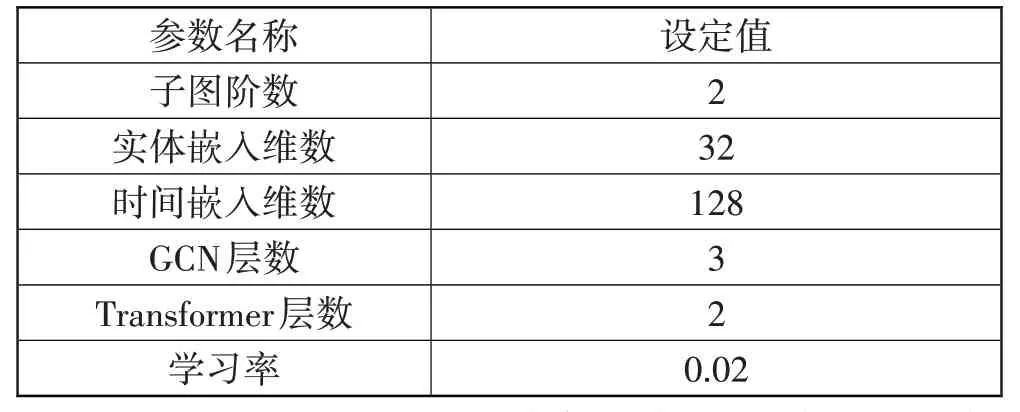
表4 模型参数列表
考虑到实验过程中训练复杂度会随着子图阶数的增加而增加,因此,将子图阶数设定为2。实体嵌入维数e_emb 编码为一个长度为32 的特征向量,时间嵌入维数t_emb 编码为一个长度为128 的特征向量。为了充分学习子图中的结构信息,将GCN 层数设置为3。在本次实验中,选用ALBERT 模型作为嵌入模型,训练的学习率设为0.01。
为衡量模型的有效性,本文选取Hits@1和Hits@10作为性能评价指标,其中,Hits@1 表示输出答案的第一个为正确答案的概率,Hits@10 表示输出答案前10个中包含正确答案的概率。其计算过程如下:
其中,|Q|表示问题的数量,ranki表示正确答案在输出答案中的排名,f为指示函数,若条件真则函数值为1,否则为0。
3.2 对比实验
为了验证本文模型和基准方法的效果差异,以及本文模型的有效性,使用4 类基线模型进行对比测试分析[7]。关于基线模型的相关设定具体如下:
1)预训练模型:本文选用应用广泛,且在自然语言处理语言领域取得不错结果的3 种预训练模型作为基线模型,即BERT[26]、ALBERT[27]、Distill-BERT[28]。通过将问题进行编码后,利用线性层对向量的预测结果进行评分。
2)EmbedKGQA 模型[29]:该模型主要针对静态知识图谱进行设计。因此,在预训练时忽略时间信息,采用随机时间嵌入。
3)CronKGQA 模型[1]:该模型主要应用于单粒度时间处理,因此,为了使该模型能够在多粒度时间数据上进行有效的对比实验,本文对于年、月粒度的时间嵌入表示主要是从日粒度的时间嵌入中进行随机抽取。
4)MultiQA 模型[2]:该模型主要应用于多粒度时间处理。因此,可直接将该模型用于MultiTQ 数据集进行对比实验。
对比实验最终结果如表5 和表6 所示,通过分析实验结果,可以发现:对于3 种预训练模型,从整体效果来看,在Hits@1 上,ALBERT 相对于BERT 和DistillBERT 模型绝对提升了约0.025,而在Hits@10 上,ALBERT 相对于BERT 绝对提升了0.003,相对于DistillBERT 提升了0.002。同时,ALBERT 模型无论是对于单粒度的时间分析,还是多粒度的时间分析,其问题推理效果相对于BERT 和DistillBERT 模型都更好。这主要是因为ALBERT 通过参数共享和跨层连接等技术,有效提升了模型的表示能力和学习能力。同时,由于其在训练过程中表现出更快的收敛速度,进一步提升了模型的性能。
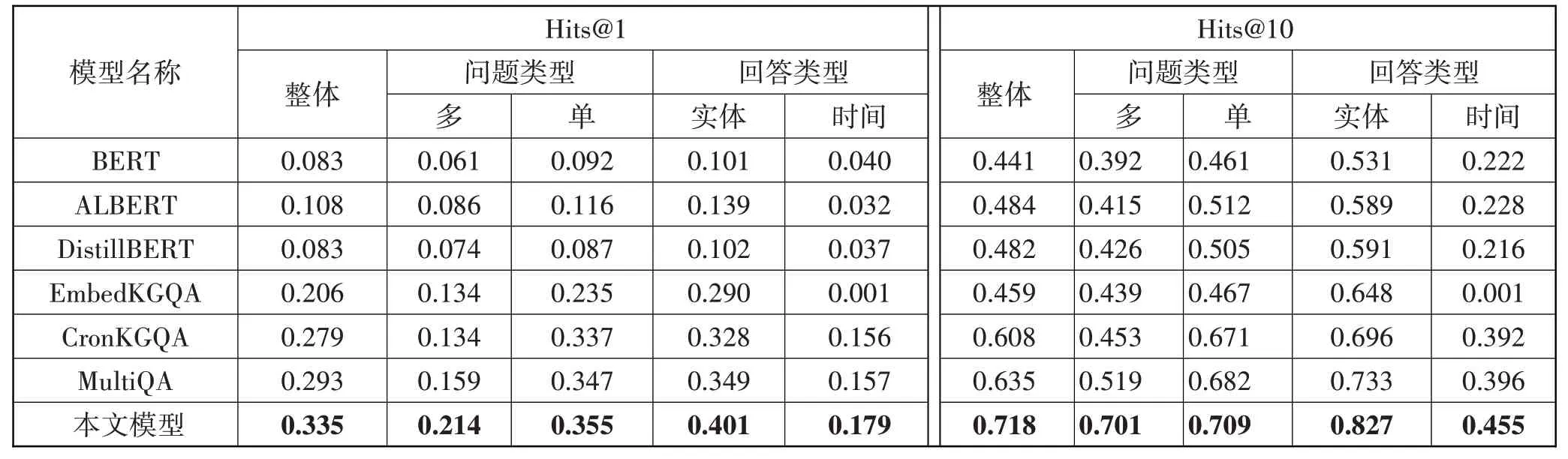
表5 整体实验
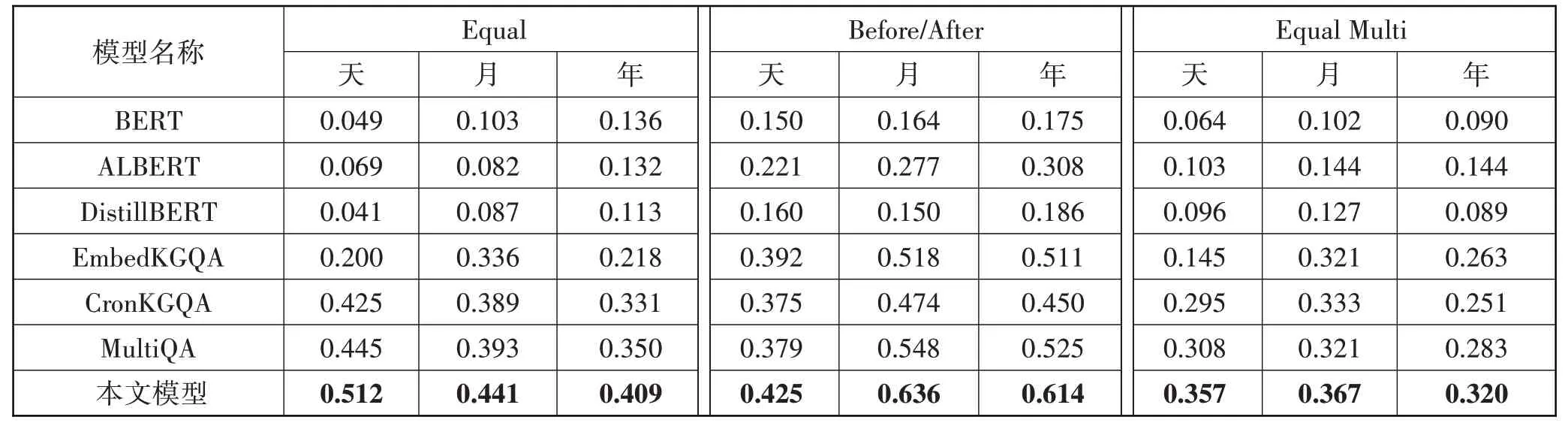
表6 在Hits@1上多粒度对比实验
对于EmbedKGQA 和CronKGQA 模型,从整体上看,CronKGQA 模型在Hits@1 和Hits@10 中相对于EmbedKGQA 模型,绝对提升了0.073 和0.149。这说明引入时间嵌入有助于提升其对于时序问答推理的正确率。在单粒度时间情况下,CronKGQA 模型预测情况相对于EmbedKGQA 模型预测情况更好,而在多粒度时间下两者模型的预测情况较差,且CronKGQA模型在多粒度时间情况下的预测准确率下降更为明显。可以推断,传统模型缺乏对多粒度时间问题的推理能力,且CronKGQA模型相对于EmbedKGQA模型,受到时间粒度的影响较大,推理能力更不稳定。
对于多粒度时间推理模型MultiQA 和本文所提出的SSE-TGQA 而言,从整体效果来看,SSE-TGQA模型相较于MultiQA 模型在Hits@1 和Hits@10 上的整体分别提升了0.042 和0.043。且无论是在单粒度时间还是多粒度时间,本文所提出的SSE-TGQA 模型都优于MultiQA 模型。这主要是由于本文模型不仅对语义信息进行深度分析,同时融入了子图结构信息。通过深层分析问题中的语义信息、子图中时间结构信息和实体结构信息,有助于提高问题推理的准确率。
为详细描述SSE-TGQA 模型与MultiQA 模型在不同类型的问题上的差异性,本文绘制了如图5 所示的实验结果。
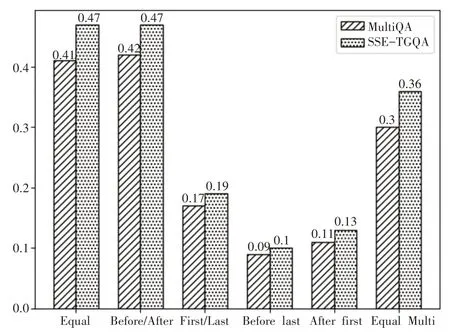
图5 MultiQA和SSE-TGQA差异性
由图5 可知,本文所提出的SSE-TGQA 模型在所有问题中均优于多粒度模型MultiQA。
3.3 消融实验
为验证SSE-TGQA 模型中各个模块的作用,本文采用消融实验的方法,通过在原模型中删除或者修改某个模块进行测试,以检验不同模块在SSE-TGQA 模型中处理问题的作用。
变种1删除语义解析模块。由于SSE-TGQA模型中的语义解析模块主要基于时序知识图谱解析问题中存在的隐式时间表达,同时将时序知识图谱中的多粒度时间信息根据问题的时间粒度进行聚合和编码,因此,在消融实验中剔除该模块对于隐式时间解析和多粒度时间信息增强的功能。实验结果如表7所示。观察表7可以发现剔除该模块在测试集上的效果弱于原模型,说明隐式的时间表达和多粒度的时间信息增强对于模型有一定影响,检验了语义解析模块的有效性。
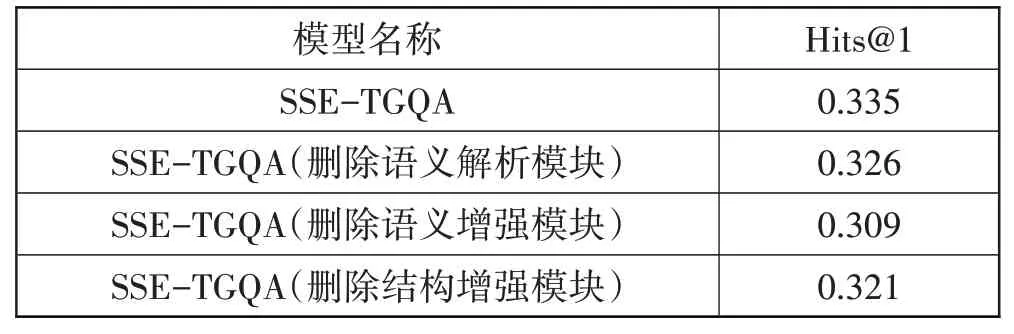
表7 消融实验结果
变种2删除语义增强模块。SSE-TGQA 模型中的语义增强模块主要基于时序知识图谱中的实体嵌入信息和时间嵌入信息,融入到经过预训练的问题语义信息中,以丰富问题语义。为了验证语义增强模块对于该模型的作用,本文直接删除该语义增强模块进行测试。实验结果如表7 所示,可以发现,删除该模块后的模型效果要明显弱于原模型,突出了语义增强对于模型的重要作用。
变种3删除结构增强模块。SSE-TGQA 模型的结构增强模块主要基于图卷积神经网络,对子图中的节点进行迭代更新,随着层数的不断增加,使更新后的节点能够带有相邻节点的信息,为最后的问题推理提供了信息支持。为验证结构增强模块的效果,直接删除该模块进行测试,实验结果如表7 所示。可以发现,删除该模块后的模型效果在测试集上弱于原模型,验证了子图结构信息对于问答推理的有效性。
3.4 案例分析
为了进一步阐述模型产生不同答案的原因,在案例分析中[8],本文针对3种问题类型,选取了3个MultiQA 回答错误、SSE-TGQA 回答正确的问题,以及3个CronKGQA 回答错误、SSE-TGQA 回答正确的问题。据此分析出现的原因,具体如表8和表9所示。

表8 典型案例1

表9 典型案例2
由表8 可知,由于CronKGQA 模型中并没有融入时间信息,因此,它不能确定在2011 年11 月22 日之后毛里塔尼亚向谁提起了上诉。在模型训练过程中,由于时间信息的缺失,导致其错误地将英国判断为毛里塔尼亚提起上诉的国家。而SSE-TGQA 模型能够有效利用问题中存在的时间约束,通过基于时间信息和实体信息进行有效推理和评分,直接过滤掉英国,得到了尼格尔这个正确答案。
由表9可知,对于MultiQA 而言,虽然其能够根据时间语义信息得到最基本的判断,但是,面对实体结构和时间结构相对复杂的问题,MultiQA 无法给出正确判断。比如“在厄瓜多尔政府之前,谁最后代表玻利维亚上诉”。由于该问题中不仅涉及较为复杂的时间信息,还存在较为复杂的实体关系信息,即“代表玻利维亚上诉”。因此,MultiQA 只能从时间上判断答案,导致推理错误。而SSE-TGQA 在对时间推理的基础上,结合子图结构信息对问题进一步进行推理,最终得到了正确答案。
3.5 参数分析
在参数分析中,本文选用了3 类参数进行分析,包括:GCN层数、Tranformer层数和预训练模型。
针对GCN层数,本文选取了4种不同层数的GCN来研究其对于SSE-TGQA 预测结果的影响程度,具体如表10所示。
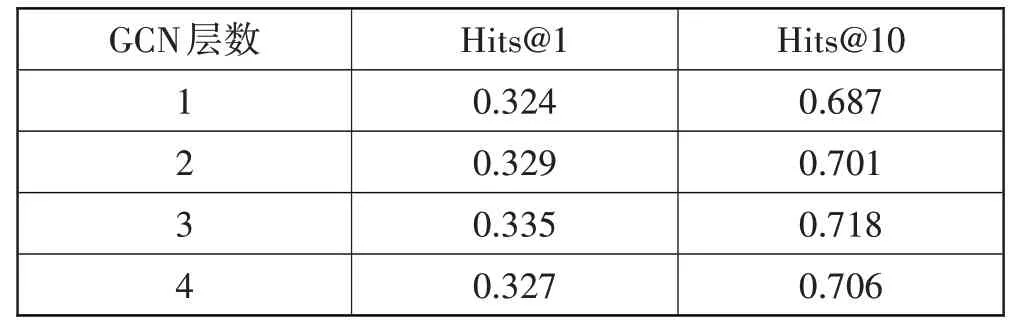
表10 不同GCN层数对SSE-TGQA的影响
由表10可知,随着GCN层数的不断增加,模型的准确率出现先增加后降低的状态,且在层数为3 的时候提升幅度达到峰值。这说明子图结构信息对于提升问答推理过程有一定作用,但是随着子图结构信息的不断增加,会导致过拟合问题,这会导致最终预测结果出现偏差,从而导致准确率下降。
针对Transformer 层数,本文选取了3 种不同层数的Transformer 模型来研究其对于模型预测结果的影响程度,如表11所示。
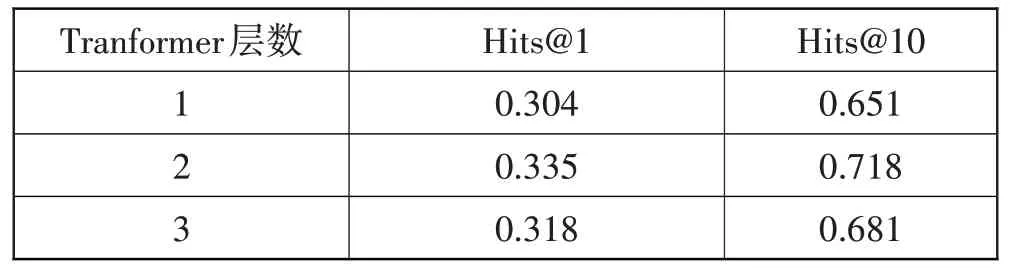
表11 不同Tranformer层数对SSE-TGQA的影响
由表11 可知,随着Transformer 层数的增加,模型预测结果的准确性呈现先增加后减少的现象。这是因为随着模型深度的增加,会导致出现梯度爆炸问题,使得最终预测结果变得不稳定,进而导致预测能力下降。
针对预训练模型,本文选取了3 种不同的预训练模型来研究其对于SSE-TGQA 模型预测结果的影响程度,如表12所示。
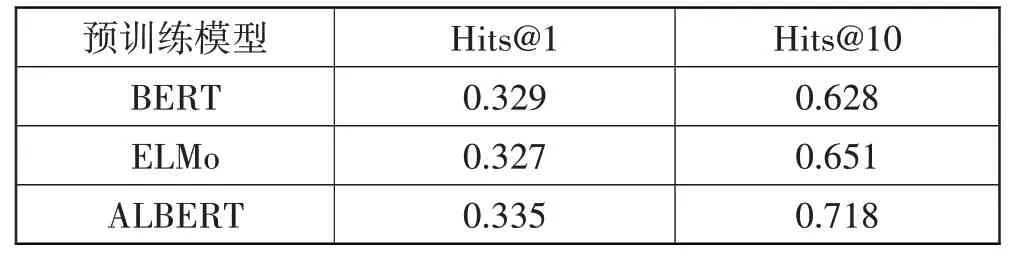
表12 不同预训练模型对SSE-TGQA的影响
由表12 可知,ALBERT 在3 种预训练模型中取得了最佳的成果。这主要是因为相对于BERT 模型和ELMo 模型而言,ALBERT 使用了参数共享的方式,这使得模型的表示能力和学习能力得到了提升,更容易捕捉到问题中的语义特征。同时由于使用了Transformer 结构,使得其具有更好的并行化能力,进一步提升了模型的性能。
3.6 误差分析
在误差分析中,本文随机抽取了100 个错误样例进行分析,错误示例如表13所示。

表13 错误样例分析
对表13的误差分析可知:
1)实体抽取错误。尽管本文模型对于问题的语义和结构处理较为丰富,但是模型存在时序知识图谱中抽取到错误实体的情况。显然,选取错误的实体会导致推理过程无法顺利进行,进而产生错误的答案。
2)知识不完备。由于时序知识图谱中存在未记录的时间和事件关系,而问题中需要基于这些时间和事件进行推理。因此,尽管本文对问题语义进行了加强,但仍会存在推理错误的情况。
3)高复杂问题错误推理。尽管本文模型尽可能结合时序知识图谱的语义信息、问题中的语义信息以及子图中的结构信息来进行问答推理,但存在设计多个时间点、时间序列、条件逻辑的高复杂问题。对于这些高复杂问题,本文模型可能无法准确推理出相应的结果。
4 结束语
本文提出了一种基于语义和结构增强的时序知识图谱推理方法,构建了SSE-TGQA 模型,并采用MultiTQ 数据集进行实验。本文通过对时间、实体和问题语义进行解析,从语义和结构2 个角度,分别利用嵌入模型和图卷积神经网络对问题特征进行了增强。通过对比实验,验证了本文模型相对于基线模型而言,在多粒度时间问题推理上的有效性。通过消融实验,检验了本文模型中的各个模块对于多粒度时间问题推理的影响程度。通过案例分析,进一步解释了SSE-TGQA 模型相较于CronKGQA 模型和MultiQA 模型在具体案例上的分析情况,说明了SSE-TGQA 模型的优越性。通过参数分析,检验了本文模型中核心参数的有效性。通过误差分析,明确了本文模型在推理过程中的错误方向,这为后期对模型进行进一步改进提供了丰富的参考性。
未来,本文将继续围绕基于多粒度时间,利用时序知识图谱对问题进行推理。将针对误差分析中的实体抽取错误进行进一步优化,对时序知识图谱的知识补全方面进一步研究,对高复杂问题进一步细分,以提升模型对于更广泛、更复杂问题的推理准确率。
猜你喜欢
中国农业信息(2023年3期)2023-03-18 08:19:04
中国农业信息(2021年3期)2021-11-22 06:44:48
粉末冶金技术(2021年3期)2021-07-28 06:26:16
南京大学学报(自然科学版)(2021年1期)2021-01-30 14:01:04
少先队活动(2020年12期)2021-01-14 01:47:40
中成药(2017年3期)2017-05-17 06:09:01
电子制作(2016年15期)2017-01-15 13:39:08
系统工程与电子技术(2016年12期)2016-12-24 07:19:14
领导科学论坛(2016年9期)2016-06-05 14:59:58
河南科技(2014年15期)2014-02-27 14:12:36
