
融合序列局部信息的日期感知序列推荐算法*
2024-04-23 12:46曹浩东汪海涛贺建峰
计算机工程与科学 2024年4期
曹浩东,汪海涛,贺建峰
(昆明理工大学信息工程与自动化学院,云南 昆明 650500)
1 引言
现如今,推荐系统在电子商务、视频音乐和新闻媒体等在线平台扮演着至关重要的角色[1]。序列推荐旨在通过用户的历史交互序列来抽取有意义的用户偏好,从而预测用户未来的行为演化趋势[2]。这些用户偏好通常会随着时间的推移而迅速变化,并且不同的用户之间是异构的,因此在历史交互序列中精准地捕获用户的偏好是很困难的[3]。随着用户、项目和用户-项目交互数量的激增,获取这些用户偏好变得越来越具有挑战性。现有的研究表明[4],基于自注意力机制的序列推荐算法可以较好地捕获这些复杂的、多样化的、不断演化的用户偏好。
但是现有的基于自注意力机制的序列推荐算法都存在3个问题:(1)使用点积计算得到的注意力权重在感知项目上下文信息方面存在局限性[5],将用户的交互序列嵌入矩阵直接输入自注意力结构不能有效地利用各个交互项目在序列中的局部关联信息。(2) 只依赖用户交互序列中最近的交互项目的潜在特征计算目标项目的得分,这种方法显著降低了先前交互项目对推荐结果的影响。(3)依照自然语言处理领域的简单位置嵌入来探索用户交互序列中的顺序行为模式,这对于建模用户行为的序列关系存在一定限制[6]。
基于以上问题,本文提出融合序列局部信息的日期感知序列推荐算法,命名为Flida。该算法首先将当前交互项目及其部分前项作为输入,通过垂直卷积获得与序列局部信息融合的当前交互项目的表示。垂直卷积使用不同的垂直过滤器融合交互项目在交互序列中的多种局部关联信息,随后作为自注意力结构的输入。为了捕获用户所有的历史交互项目和目标项目的关系,Flida没有使用传统的利用用户交互序列中最近的行为表征和目标项目嵌入的点积来计算项目得分的方式,而是利用交叉注意力机制[7],基于所有历史交互项目的行为表征计算目标项目的最终得分,从而进行项目推荐。与此同时,为了更好地建模用户行为的序列关系,Flida充分利用用户交互发生的日期信息。现有研究指出,交互发生的时间戳的值充满了信息[8]。因此,Flida将用户交互行为发生的时间戳转化为日期融入自注意力的运算中。
本文的主要工作有以下几点:
(1)本文提出了序列推荐算法Flida,利用垂直卷积充分融合各个项目在交互序列中的局部关联信息。
(2) Flida利用交叉注意力机制联合用户所有的历史交互项目做出下一项推荐,同时使用各交互行为的时间戳作为绝对时间嵌入。
(3)本文展示了Flida算法在多个公开数据集上的实验结果,并与具有代表性的基线算法进行比较。实验结果表明,该算法在不同的评估指标上较基线算法均有一定程度的提升。本文还进行了全面的消融实验,用以展示算法中各组件对算法预测性能的影响。
2 相关研究
现有推荐算法大致可以分为以下3类:
(1)传统推荐算法。协同过滤CF(Collaborative Filtering)是推荐算法领域的经典算法之一,基于协同过滤的算法从用户的历史交互行为推断用户偏好[9]。矩阵分解MF(Matrix Factorization)是一种成功的协同过滤算法,它使用一个共享空间来表示用户和项目,并通过用户和项目嵌入之间的向量内积来估计交互的可能性[10]。然而,传统的协同过滤方法虽然有结构简单和易于训练的优点,但忽略了用户偏好的多变性,且在数据稀疏的情况下易受影响。
(2)序列推荐算法。序列推荐算法旨在抽取用户交互的项目序列中的项目转换模式,避免了传统推荐算法的弊端。基于马尔科夫链MC (Markov Chain)的序列推荐算法最先开始捕获这种转换模式,这种算法假设用户的下一个行为与之前的一个或几个行为相关[11],因为最后访问的项目通常是影响用户下一个行为的关键因素。但是该算法显然无法捕获用户的长期偏好。Hidasi等人[12]提出的基于循环神经网络RNN (Recurrent Neural Network)的GRU4Rec(Gated Recurrent Unit for Recommender system)在每个时间步将最后一个步骤的隐藏状态和当前的交互项目作为输入,这种依赖关系可以使算法捕获用户的长期偏好,但却导致GRU4Rec无法并行训练,并且难以权衡用户长期偏好和短期偏好。Tang等人[13]提出的基于卷积神经网络CNN(Convolutional Neural Network)的Caser进一步提升了序列推荐的准确性。Caser将最近的交互序列按照时间顺序嵌入到“图像”的潜在表示空间中,分别使用水平过滤器和垂直过滤器学习交互序列中的局部特征,提取项目转换关系,该算法提供了一个统一且灵活的网络结构,可以同时捕获用户的长期偏好和短期偏好,并在二者之间做出权衡。
(3)基于自注意力机制的序列推荐算法。自注意力机制由于其良好的性能和可解释性在许多领域(如机器翻译)得到了广泛的应用。Kang等人[4]提出的SASRec(Self-Attentive Sequential Recommendation)不使用任何循环神经网络或卷积神经网络结构,而是将自注意力机制引入到序列推荐,达到了较好的效果。但是,SASRec只对序列进行从左到右的单向建模,这限制了对用户行为序列进行表示的能力[14]。Sun等人[14]提出的BERT4Rec(sequential Recommendation employing the deep Bidirectional Encoder Representations from Transformer to model user behavior sequences)使用深度的双向自注意力机制建模用户的行为序列,同时为了避免信息泄露使用了填空任务(Cloze Task)来代替单向模型中的预测目标。Gholami等人[15]提出的算法将循环神经网络与SASRec相结合,去除了对交互序列长度的限制,同时由于利用了RNN建立顺序关系,也使其省略了位置嵌入的步骤,相对于SASRec和BERT4Rec,较大幅度地提升了性能。此外,Li等人[6]在SASRec的基础上,将时间间隔纳入自注意力机制,实现了序列推荐算法的时间感知,但后来Cho等人[8]提出的MEANTIME(MixturE of AtteNTIon mechanisms with Multi-temporal Embeddings)指出,其对时间信息的使用受限于单一的时间嵌入方案。因此在其基础上,MEANTIME引入了多种绝对时间嵌入和相对时间嵌入来捕获用户行为序列中不同的行为模式[8]。它为每个注意力头注入不同的时间嵌入,利用不同的注意力头分别处理不同的时间嵌入,这使得每个注意力头可以分别专注于特定的用户行为模式,以更好地编码用户交互序列中交互项目的序列模式[8]。
各序列推荐算法利用不同的神经网络和算法结构对用户的交互序列进行建模,同时辅以各种优化策略,并利用时间戳等信息作为辅助,达到了为用户推荐感兴趣的物品这一目的,展现出了优秀的性能。但是,在用户交互序列当中,各交互项目在局部的上下文关联信息也至关重要。与此同时,基于用户所有的历史交互计算目标项目的得分更有利于统筹用户的全局偏好。本文提出的Flida算法针对这2点,首先使用不同的垂直过滤器融合项目在交互序列中的多种局部关联信息;其次利用交叉注意力机制,基于所有历史交互项目的行为表征计算目标项目的偏好得分;最后为了更好地建模用户行为的序列关系,Flida充分利用用户交互发生的时间,将用户交互行为发生的时间戳转化为日期融入到注意力的运算中。
3 Flida算法
在本节,首先描述序列推荐的目标任务,随后介绍Flida的各个组件,包括项目嵌入、垂直卷积、注意力结构以及参数更新方法。Flida算法整体结构如图1所示,其中,B表示自注意力结构的最大层数,Add&Norm表示残差连接和层归一化,FFN(Feed-Forward Network)表示2层前馈神经网络。
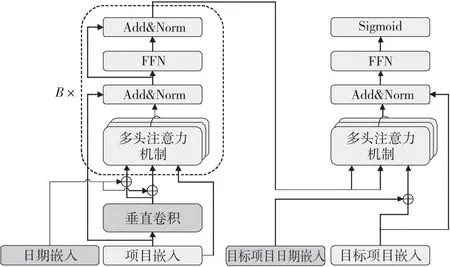
Figure 1 Flida algorithm structure
3.1 问题描述
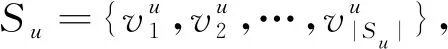
3.2 项目嵌入

3.3 融合序列局部信息
在获得交互序列的嵌入矩阵后,利用垂直卷积为每一个交互项目融合该项目在序列中的局部关联上下文信息。如图2所示,将交互项目的嵌入Ei与其前k-1个项目的嵌入Ei-k+1:i∈Rk×d作为垂直卷积运算的输入,卷积结果即为该项目与序列局部信息融合的项的表示。垂直卷积运算使用垂直过滤器F∈Rk×1融合交互项目在序列中的局部关联信息,如式(1)所示:
(1)
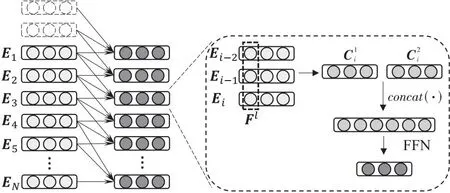
Figure 2 Fusing local information of sequence
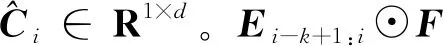
(2)
其中Fj是F中的元素。
为了融合各个交互项目的多种局部关联信息,Flida采用多个不同的过滤器Fl∈Rk×1进行多次卷积,其中,1≤l≤L,L为垂直过滤器的个数。以此获得不同维度之间更丰富的关联信息,如式(3)所示:
(3)
(4)
(5)
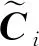
将各个交互项目通过垂直卷积获得的与局部关联信息融合的表示堆叠起来,就得到了一个表示更丰富的新嵌入矩阵,如式(6)所示:
C=concat(Ci)i=1:N
(6)
3.4 自注意力结构
通过垂直卷积获得了交互序列融合局部信息的表示,按照图1所示,Flida算法将其作为自注意力结构的输入,通过自注意力机制建模用户动态行为偏好。自注意力机制使用的缩放点积自注意力机制[18]定义为式(7)所示:
(7)
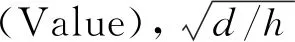
先前的研究已经表明,共同关注来自不同位置的不同表示子空间的信息是有益的[18],因此Flida采用多头注意力机制。具体来说,多头注意力机制首先通过不同的线性投影将项目表示投影到h个子空间中。但是,值得注意的是此处仅将融合局部信息的项目表示线性投影到查询 (Q)和键 (K),而针对值(V)则使用项目嵌入产生的原始项目表示,如式(8)所示:
(8)
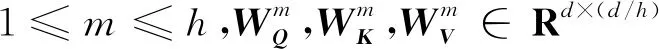
与此同时,Flida还维护一个可学习的时间嵌入表MD∈R|D|×d,其中包含了数据集交互时间跨度内所有的日期嵌入。综合衡量时间嵌入表的大小以及时间嵌入的有效性,选择日期作为时间嵌入的尺度是合理的[8]。如果将时间嵌入精确到小时甚至分钟,将会产生大量没必要的计算。因此,Flida将用户交互序列中交互的时间戳的日期按照时间嵌入表转化为时间嵌入矩阵ED∈RN×d,然后将其线性投影到h个子空间中,如式(9)所示:
(9)
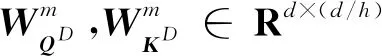
传统的基于自注意力机制的算法采用简单的绝对位置嵌入,即将项目嵌入矩阵和可学习的位置嵌入矩阵相加[4,14,17],而本文算法改为将时间嵌入矩阵投影到查询和键之后再与项目嵌入的对应投影相加,如式(10)所示:
(10)
其中,Sm∈RN×(d/h),表示不同的注意力头计算得出的用户行为表征。随后将不同的注意力头输出拼接起来,如式(11)所示:
S=[S1;S2;…;Sh]
(11)
简要来说,多头注意力首先使用不同的、可学习的线性投影将项目和日期的嵌入投影到h个子空间中,然后并行地应用h个注意力头来产生输出表示,随后将这些输出表示拼接起来[14]。
虽然自注意力机制能够自适应地聚合之前所有的项目嵌入,但它仍然是一个线性算法,为了赋予算法非线性特性,并考虑不同潜在维度之间的相互作用[4],对所有Si输入到参数共享的2层前馈神经网络FFN,如式(12)所示:
Fi=FFN(Si)=
ReLU(SiW1+b1)W2+b2
(12)
其中,W1,W2∈Rd×d为2层前馈神经网络的权重矩阵,b1,b2∈Rd为其相应的偏差向量,Si和Fi分别表示S和F中第i个项目的行为表征。
最终,为了捕获更具表现力的用户行为表征,将堆叠多层自注意力结构[4],定义SA(F)=Attention(FWQ,FWK,FWV),第b(1≤b≤B)层自注意力结构定义如式(13)和式(14)所示:
S(b)=SA(F(b-1))
(13)
(14)
其中,S(1)=S,F(1)=F,且各自注意力结构的投影参数是不跨层共享的[14]。同时本文为了简单起见,在此处省略了多头注意力的表达式。与此同时,如图1所示,Flida依照SASRec的操作,使用残差连接[19]、层归一化[20]和Dropout[21]来缓解算法过拟合和不稳定的问题。
3.5 交叉注意力结构
受到自然语言处理领域Transformer[18]和图像领域CrossViT[7]的启发,不同于以往只通过用户交互序列中最近的行为表征和目标项目的点积计算相关性得分的方法,Flida使用一个单独的交叉注意力结构来预测目标项目的偏好得分(如图1所示),旨在捕获用户所有历史交互项目的行为表征和目标项目之间的项目相关性。
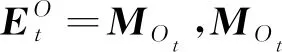
(15)
其中,Om∈R|O|×(d/h)。该操作允许算法为目标项目生成不同的潜在表示,以捕获用户所有历史交互项目的行为表征与目标项目嵌入之间的相互作用。随后按照式(11)的方式将不同的注意力头输出拼接起来得到O∈R|O|×d。
交叉注意力结构仍使用多头注意力机制,是因为不同的注意力头可以从不同的表示子空间中学习相关信息,实现不同的注意力分配,增加算法表达目标项目和用户历史行为之间相关性的能力,避免了单一注意力可能存在的局限性。
最后将交叉注意力机制为各目标项目生成的潜在表示输入一个前馈神经网络,并通过激活函数计算它们的项目相关性得分,如式(16)所示:
(16)
其中,权重矩阵WO∈Rd×1,如式(16)所示偏差向量bO∈R1,σ(·)表示Sigmoid激活函数。
3.6 参数更新
Flida的参数更新策略依照SASRec和RETR(REcommender TRansformer)[17]的参数更新方法,但与之不同的是,Flida的目标项目集由真值项和负值项2个等长的集合组成,真值项为输入序列的右移位版本,负值项由随机抽选的用户从未交互的项目组成。值得注意的是,负值项的时间嵌入与其对应真值项的时间嵌入相同。
最终,Flida使用二元交叉熵损失函数来进行参数更新,如式(17)所示:
(17)
3.7 算法描述
Flida算法如算法1所示。

算法1 融合序列局部信息的日期感知序列推荐算法Flida输入:用户交互序列Su,目标项目集O,交互时间戳。输出:Top-N推荐列表。步骤1 将用户交互序列转换为固定长度为N的序列,并生成嵌入维度为d的项目嵌入矩阵;步骤2 使用垂直过滤器F∈Rk×1获得交互项目的嵌入Ei与其前k-1个项目的嵌入融合后的嵌入矩阵C;步骤3 对步骤2得到的嵌入矩阵C和原始嵌入矩阵E使用不同的线性投影矩阵得到Qm,Km和Vm,并将交互时间戳的日期转化为时间嵌入矩阵,并投影为QmD,KmD;步骤4 将项目嵌入及其时间嵌入投影得到的查询和键对应相加,并进行缩放点积自注意力机制计算,然后将h个注意力头输出拼接后进行前馈神经网络计算;步骤5 在步骤4的基础上堆叠多个注意力结构;步骤6 将目标项目嵌入及其时间嵌入投影为QmO和QmDO,相加后作为交叉注意力的查询,将步骤5的输出进行不同的投影后分别作为键和值,进行多头注意力计算后拼接;步骤7 将步骤6所得结果输入前馈神经网络,然后调用Sigmoid激活函数对其结果进行激活,最终得到目标项目的得分,生成Top-N推荐列表。
4 实验
4.1 数据集
本文实验分别在3个公开数据集上进行。Yelp是一个商业推荐数据集,由于它过于庞大,本文只使用2019年1月1日及其之后的交易记录。Beauty和Sports都属于亚马逊评论数据集[22],是其中的2个子类。
对于全部的数据集,本文按照用户将交易记录进行分组,并根据时间戳按照先后顺序进行排序[4]。同时遵循其他研究中的操作,过滤掉不流行的项目和交互项目小于5个的用户[23],并采用留一策略(leave-one-out),将每个用户最近的2个交互项目分别作为测试集和验证集,将之前的交互项目作为训练集[24]。表1概括了各个数据集的统计数据,值得注意的是,这3个数据集都有较高的稀疏性。

Table 1 Dataset statistics
4.2 对比算法
将本文所提出的算法与以下算法进行对比:
(1)GRU4Rec[12]:使用循环神经网络捕获交互项目的顺序依赖关系,并预测用户的下一次交互。
(2)Caser[13]:同时使用水平卷积和垂直卷积建模用户的动态偏好。
(3)HGN(Hierarchical Gating Network)[25]:采用分层的门控神经网络来获取用户的长期偏好和短期偏好。
(4)SASRec[4]:使用单向的基于Transformer的结构建模用户交互序列,进行下一项推荐。
(5)BERT4Rec[14]:使用双向的基于Transformer的结构并使用Cloze任务建模用户交互序列,完成序列推荐任务。
(6)FMLP-Rec(all-MLP model with learnable Filters for sequential Recommendation task)[23]:借鉴信号处理领域中的过滤算法来减少序列中的噪声,缓解算法的过拟合问题。
4.3 实现细节
为了公平对比,所有的对比算法都使用对应作者提供的源代码,各超参数和初始化策略均采纳作者的建议,以便获得最佳的结果。对于本文提出的算法,使用PyTorch来实现,令最大序列长度N=50,嵌入维度d=64,在融合序列局部信息时令k=3,L=4,并且堆叠2层自注意力结构,同时令每层的注意力头数h=4。每个数据集的随机失活率都设置为0.5,使用Adam优化器并令学习率为0.001,批大小设置为256。
4.4 评估指标
参照以往的研究方法,本文采用在该领域被广泛使用的命中率HR@k(top-kHit Ratio)和归一化累积增益NDCG@k(top-kNormalized Discounted Cumulative Gain)进行算法性能评估[24]。HR@k统计真值项目出现在前k个排序项目中的比例,而NDCG@k在HR@k的基础上增加了位置感知的特性,真值项目在前k个项目中位置越靠前得分就越高。由于HR@1和NDCG@1是等价的[23],因此本文只给出HR@{1,10}和NDCG@10下的实验结果。为了避免产生过大的计算量,针对每个用户u∈U,此次实验将真值项和随机采样的99个用户没有交互过的负值项一起排序,然后根据这100个项目的排序计算所有的评估指标[24]。
4.5 实验结果
不同的算法在各数据集上的结果如表2所示。基于这些实验数据,可以发现:
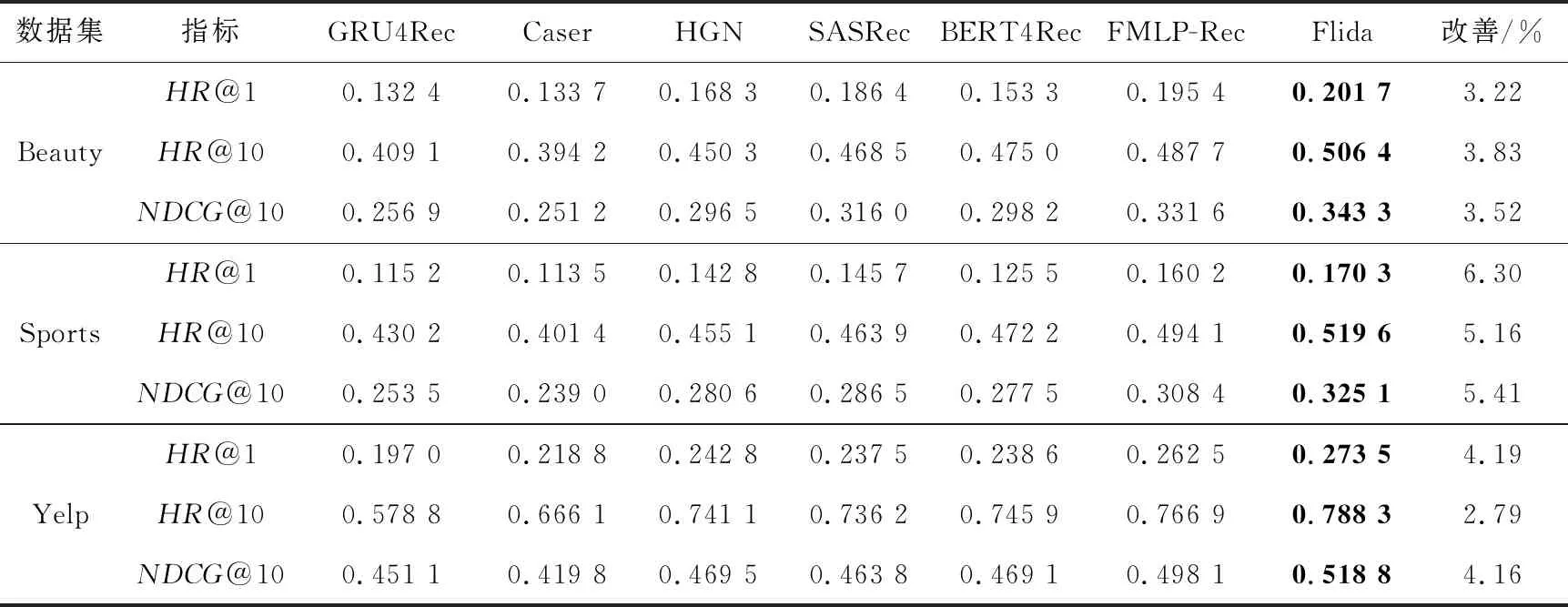
Table 2 Experimental results
首先,SASRec和BERT4Rec利用自注意力机制,大幅提高了推荐准确度(通过评估指标HR@{1,10}和NDCG@10体现)。相比基于循环神经网络的算法GRU4Rec、基于卷积神经网络的算法Caser和基于门控的算法HGN,无论是在归一化HR和NDCG上性能均得到提升。一个广泛认同的原因是,基于自注意力的算法能够自适应捕获不同用户的行为演化模式,具有更强的序列特征建模能力[4]。
其次,FMLP-Rec相比于SASRec和BERT4Rec,在一定程度上提升了推荐准确度。不同于SASRec和BERT4Rec,FMLP-Rec使用了全感知机结构编码用户交互序列,可以缓解噪声信息对最终推荐结果的影响[23],在各个评估指标上均有较大幅度的提升。
最后,通过将本文提出的Flida与对比算法进行比较,可以很明显地观察到,在各个数据集上,Flida的各个评估指标均优于其他对比算法的。不同于其他算法,Flida使用不同的垂直过滤器融合交互项目的局部关联信息,并使用交叉注意力机制基于用户所有历史交互的行为表征得到目标项目的得分,同时使用日期作为绝对时间嵌入。实验结果表明,本文提出的算法Flida是有效的,可以在一定程度上提高序列推荐的准确度。
4.6 消融实验
本节通过消融实验对本文算法的各个模块进行有效性验证。
首先构造Flida-1,移除垂直卷积,将序列嵌入直接输入自注意力结构,同时保持其他设置不变。然后构造Flida-2,移除交叉注意力结构,通过计算目标项目与最近行为表征之间点积的方式计算项目得分,并保持其它设置不变。最后构造Flida-3,移除本文使用的基于日期的嵌入方式,改为使用普通的可学习的位置嵌入,并保持其它设置不变。
将以上方式构造得到的算法变体分别在数据集Yelp上进行实验,分别得到评估指标HR@10和HDCG@10的实验结果。如表3所示,在移除垂直卷积模块之后,Flida-1的2个评估指标均大幅下降,验证了序列中每个项目融合局部信息对提升推荐准确度的有效性。Flida-2的实验结果显示,用户先前的交互行为对当前的交互行为仍然有影响,利用用户所有的历史交互行为进行推荐是合理的。Flida-3只是利用了交互序列的顺序性,并假设各交互序列之间的时间间隔是相等的,导致算法性能出现了轻度的下降。这说明在缺少时间戳信息的时候,可以使用位置嵌入作为替代方案。

Table 3 Ablation experimental results表3 消融实验结果
4.7 算法细节分析
为了研究超参数对算法的影响,本文将其中较重要的超参数设置为不同的值后进行一系列实验。
4.7.1 嵌入维度分析
本节保持其它最优超参数不变,将嵌入维度d的取值设置为16,32,64,128,256,在数据集Yelp上进行嵌入维度分析,给出在不同嵌入维度下各算法评估指标HR@10的变化趋势图,探索嵌入维度d对算法性能的影响,实验结果如图3所示。由于本文提出的算法是基于注意力机制和卷积神经网络的,所以此处只给出基于注意力机制和卷积神经网络的算法的实验结果。
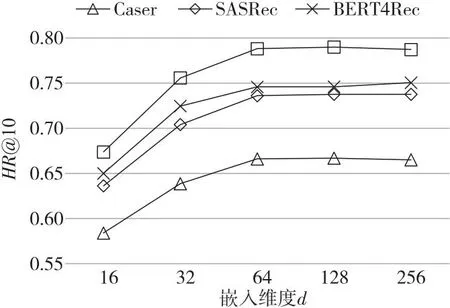
Figure 3 Embedded dimension analysis
观察图3可以发现,随着嵌入维度d的增加,算法的性能指标呈整体上升的趋势。当嵌入维度d增加到一定程度后,算法的性能指标整体趋于收敛。由于存在过拟合现象,部分算法的实验结果甚至出现了略微的下降。Flida在嵌入维度大于64之后命中率便不再出现明显的增加,因此本文在4.3节采用64作为嵌入维度的大小。
4.7.2 注意力头数分析
本节探索Flida中注意力头数对推荐准确度的影响。保持其他超参数不变,将注意力头数h的取值设为1,2,4,分别在各个数据集上依次进行实验,获取评估指标HR@10的值,实验结果如表4所示。
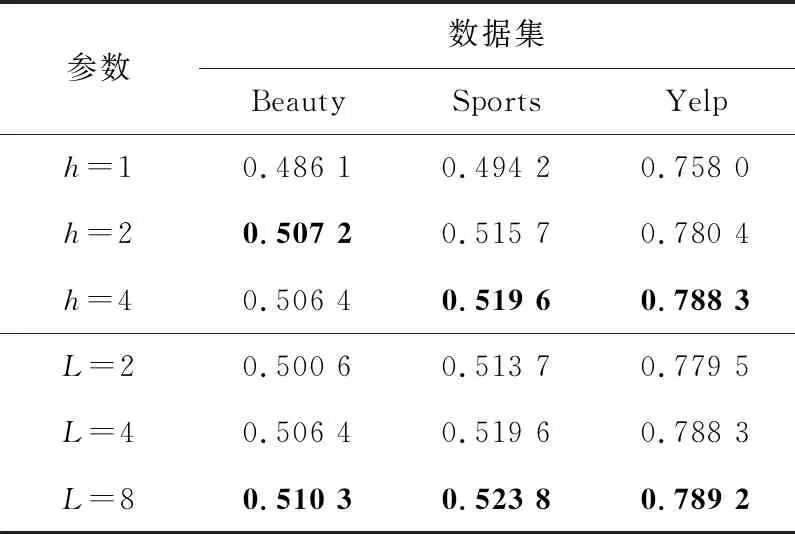
Table 4 HR@10 of Flida with different number of attention heads and filters
从表4中可以看出,在数据集Sports和Yelp上,算法的推荐准确度随着注意力头数的增加而增加,在h=4时达到最高;但是在数据集Beauty上,则是在h=3时达到了最高,继续增加反而造成了推荐准确度的略微下降。即除了数据集Beauty以外,其余的数据集均在h=4时达到最高性能,这也许是由于数据集的稀疏性造成的,因为数据集Beauty的数据稀疏性要略低于其余2个数据集。本文将算法的h默认值设置为4。
4.7.3 垂直过滤器个数分析
本节研究Flida中融合序列多种局部信息的垂直过滤器个数对推荐准确度的影响。保持其他超参数不变,将垂直过滤器的个数L分别设置为2,4,8,在各数据集上进行实验,获取评估指标HR@10的值,实验结果如表4所示。
从表4中可以看出,算法的推荐准确度随着过滤器个数的增加而增加。但是,当过滤器的个数达到8 时,算法的性能并没有大幅增长,但是却造成了训练时长的大幅增加。这是因为随着过滤器个数增加,融合各个过滤器卷积结果的前馈神经网络中的权重矩阵维度也大幅增加,因此本文算法中L的默认值设置为4。
5 结束语
本文充分考虑用户交互序列中的局部关联信息,利用垂直卷积融合各个交互项目在交互序列中的局部关联信息,并利用交叉注意力机制基于用户所有历史交互的行为表征做出下一项推荐,同时使用各交互行为发生的日期作为绝对时间嵌入,充分挖掘用户交互序列中隐藏的用户偏好,使推荐结果更加准确,提升推荐系统的用户体验。本文最后的实验结果验证了本文算法的有效性。在未来的工作中,针对用户的不同行为(例如点赞、添加购物车、收藏等行为)进行建模也是一个有价值的研究方向。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子测试(2018年9期)2018-06-26
趣味(语文)(2018年2期)2018-05-26
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
自动化博览(2014年6期)2014-02-28
