
基于递归神经网络(RNN)的情绪分析算法在自然语言处理中的研究
2024-04-23 06:15张世宏赖德刚黄婷婷
中国信息化 2024年3期
张世宏 赖德刚 黄婷婷
一、引言
自然语言处理(NLP)的核心目标是使计算机能够理解和处理人类语言,其中情感分析是NLP领域的重要分支,其主要用于解读和理解文本中的情感趋势,以实现对文本的情感分类或预测。早期采用简单RNN结构的情感分析算法在处理长期依赖关系上常面临梯度消失或梯度爆炸等问题,因此在处理复杂任务时其性能受到了限制。现在,长短时记忆网络(LSTM)在情感分析中展现出了强大的性能,提高了情感分析任务的准确率。双向循环神经网络和注意力机制也获得了成功应用。在实际的情感分析应用中,社交媒体分析、电影评论分析和产品评论分析等方面都具有许多研究价值。本文通过数据预处理技术,将原始文本转换为RNN模型可接受的形式,使用训练数据进行RNN模型的训练和参数优化,并通过测试数据对训练好的模型进行评估,计算F1分数、准确率等性能指标。本研究的目标是探索基于RNN的情感分析算法在电影评论中的应用,利用RNN模型来分析文本情感,为相关领域的应用和研究提供有价值的参考资料。
二、算法设计
本文算法设计思路源于我们处理时间序列数据的方式,可以有效地掌握在序列数据中出现的时间序列信息和上下文关联性。采用递归神经网络(RNN)实现,其实现过程中需要为训练准备好输入数据和相应的标签,并选用合适的循环单元类型,如基础循环单元、长短期记忆单元或门控循环单元。在编译模型之前,需要设定损失函数、优化器和评价指标,常用的损失函数是交叉熵损失函数,优化器可以选择Adam或SGD,评价指标可以选择准确率。在训练阶段,通过反向传播算法更新模型参数,让模型逐渐学习并掌握输入序列的模式和规律,还可以使用验证集来评估模型和预防过拟合。模型训练完成后,可以用测试集对模型进行最后的评估,根据任务需求,预测结果可以进行后续的分析和应用。在实际操作中,还可以根据任务特性和需求进行适当的调整和优化,如添加正则化处理、使用dropout等技术来提升模型的泛化能力和预防过拟合。此外,还可以结合其他的技术和模型进行优化,如注意力机制、双向RNN等。RNN的核心概念包括前向传播公式、输出公式和隐藏状态传递公式,其中隐藏状态可以看作是模型对过去输入序列的记忆或表示。通过隐藏状态的传递或更新,RNN可以在时间序列上循环传递,同时还可以结合反向传播算法,计算损失函数对各个参数的梯度,从而进行参数更新和模型优化。在具体实现中,还需要选择和配置具体的激活函数、损失函数等。RNN实现过程如图1所示。

三、情感分析算法实现
情感分析算法的设计是本文的核心内容之一,本研究采用基于递归神经网络的方法来实现情感分析,算法设计主要包括以下步骤:
数据准备:研究主要集中在IMDB的电影评论数据集上。数据集中的文本数据已经经过标记,标记对应不同的情感类别,例如正面、负面、中立等。通过这些数据准备,可以为情感分析算法提供准备好的数据集,方便后续的模型训练和评估。
特征提取:主要是将电影评论的文本数据转换为适用于RNN处理的特征表示。它包括五个主要部分:读取测试数据,创建和适配分词器,将文本数据转换为序列,序列填充以及标签独热编码和数据划分。通过读取名为电影评论Test.txt的文件获取测试数据。使用分词器Tokenizer将文本转换成数值型数据,并构建词汇表。使用适配过的分词器将训练数据和测试数据的文本转换为数值序列,序列长度被填充到100,以便RNN处理。标签也被转换成独热编码形式。随机划分训练数据成训练集和验证集,确保模型泛化性能。整个程序综合了分词、填充、编码和划分等技术,为情感分析任务提供了良好的数据基础。
构建RNN模型:本文在设计上采用了循环神经网络(RNN)中的长短时记忆网络(LSTM),总共实现分三步完成。第一步,通过Keras的Sequential()方法创建一个空的序贯模型,然后添加一层Embedding层作为词嵌入层,将词的整数表示转换为密集向量。Embedding层的参数确定了输入数据的最大词汇量、词嵌入的维度和输入序列的长度。第二步,添加两个LSTM层,每个LSTM层都有32个隐藏单元,并通过dropout参数设置随机失活的概率。第一个LSTM层设置return_sequences=True,以便将每个时间步的隐藏状态传递给下一个LSTM层。紧接着,添加一个全连接层(Dense层),它有64个神经元,并使用ReLU激活函数。然后添加一个Dropout层,以防止过拟合。第三步,添加输出层,它是一个全连接层,有2个神经元对应两种情感类别,并使用softmax激活函數输出预测概率。这个RNN模型结合了LSTM和dropout等技术,能够在处理文本情感分析任务时更好地解决梯度消失和爆炸问题,提高模型的准确性和泛化性能。
模型训练:使用标记的训练数据对RNN模型进行训练。在训练过程中,将文本序列输入RNN模型,通过优化算法(如随机梯度下降)调整模型参数,提高对情感类别的预测能力。使用model.compile()函数配置模型的训练过程,选择分类交叉熵作为损失函数,优化器选择Adam,并将准确率作为评估指标。通过model.fit()函数进行模型训练,使用训练数据的特征和标签进行训练,并提供验证数据来评估模型性能。进行20轮训练,每轮使用64个样本进行训练。model.fit()函数返回一个History对象,其中包含每个epoch的训练损失、验证损失、训练准确率和验证准确率等信息。这样的训练过程能够使模型逐渐优化参数,提高对情感类别的预测准确性。
模型评估:使用预留的测试数据集对训练好的RNN模型进行评估。常用的评估指标包括准确率、精确率、召回率和F1分数等,用于衡量模型在情感分析任务上的性能。设计了model.evaluate()函数用于评估模型的性能,该函数将模型对测试数据进行预测,并将预测结果与真实的标签进行比较,计算出损失值和指定的评估指标。这个过程不会改变模型的参数,只是用于衡量模型的性能。model.evaluate()函数返回的是一个包含损失值和所有评估指标值的列表。有两个返回值:test_loss和test_ accuracy,分别代表在测试集上的损失值和准确率。最后,将这两个值输出,以便查看模型在测试集上的表现。这两个指标反映了模型在未见过的数据上的预测能力,可以帮助我们判断模型的泛化能力。
四、算法结果分析
(一)初始方案

随机选择10个样本,输入初始化RNN模型进行训练,得到在训练过程中准确率和损失值。从图2、图3可见测试集上的损失值为0.6893,准确率为0.5122,以上数据可以看出损失值较高且准确率较低。模型的损失值较高表示模型对于某些样本的预测存在较大的误差,准确率较低表示模型在预测时存在一定程度的误分类。效果并不理想,需要对模型进行进一步优化。
(二)优化方案
本文提出了一种优化方案,该方案采用本文情感分析算法,在模型的最后添加了一个具有64个神经元的全连接层,并使用ReLU激活函数。全连接层可以进一步提取抽象的特征表示,并增加模型的非线性能力。更多的神经元可以提供更丰富的特征表达能力,有助于提高模型的性能。


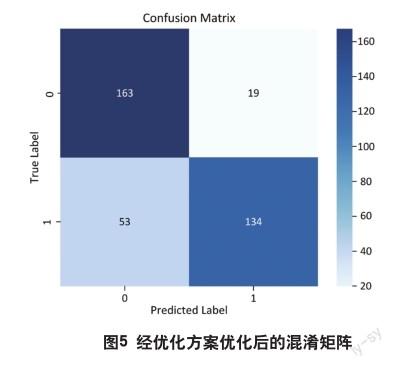
從图4可以看出,输入与初始方案相同的样本,优化后模型的测试损失为0.4652,表示模型在测试集上的平均损失较低。较低的损失值意味着模型能够更准确地预测样本的标签。模型的测试准确率为80.49%,表示在测试集上能够正确预测80.49%的样本标签。结果表明,经过优化的模型在测试集上取得了较好的性能。然而,准确率和损失值并不能完全描述模型的性能,因此还需要综合考虑其他指标和评估方法,如精确率、召回率、F1值等,以全面评估模型的性能和可靠性。从图5可以看出,混淆矩阵的每个方块提供了关于模型预测结果的信息,从而可以计算出多个评估指标。本模型精确率为89.56%,表示有约89.56%是真正的正类样本。模型召回率为75.47%,意味着模型能够正确地识别出约75.47%的正类样本。模型F1值为81.98%,F1值越高,说明模型在预测和识别上的综合表现越好。经过优化后的结果要远高于初始模型。
五、结论
本研究基于递归神经网络(RNN)实现了情感分析算法,并在IMDB电影评论数据集上进行了实验和优化。经过多次迭代和参数调整,得到了优化后的RNN模型,并通过评估指标对其性能进行了评估。本文在初始模型的基础上增加了一个具有64个神经元的全连接层,并使用了ReLU激活函数。经过优化后,模型的测试准确率提高到80.49%,损失值下降到0.4652。通过混淆矩阵的分析,发现模型对于负面评论的预测准确性较低。总之,通过持续改进算法和模型,我们可以更好地理解和分析人类的情感倾向,为社会舆情分析、市场调研、用户反馈分析等领域提供有价值的信息和洞察。
作者单位:张世宏、赖德刚 中国电子科技集团公司第三十研究所
黄婷婷 成都工百利自动化设备有限公司
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
今日农业(2019年15期)2019-01-03
中国交通信息化(2018年5期)2018-08-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
质量与标准化(2015年9期)2015-07-10
读者·校园版(2015年19期)2015-05-14
浙江人大(2014年5期)2014-03-20
