
一种结合神经网络和敏感位置语义的轨迹隐私保护方法
2024-04-22 02:41梁阳罡申自浩刘沛骞
小型微型计算机系统 2024年4期
张 俊,梁阳罡,申自浩,王 辉,刘沛骞
1(河南理工大学 计算机科学与技术学院,河南 焦作 454000) 2(河南理工大学 软件学院,河南 焦作 454000)
0 引 言
随着基于位置服务和位置感知设备的广泛发展,产生了大量的轨迹数据.这些数据可以帮助研究人员开展一系列的研究,例如:兴趣点推荐[1]、船舶轨迹预测[2]等.
轨迹数据包含了大量的敏感信息,如果这些数据在没有保护或处理不当的情况下直接发布,会引起严重的隐私泄露问题.恶意的攻击者通过数据分析和挖掘的技术手段获取用户的敏感信息,包含用户的生活习惯、家庭住址和职业信息等.
近年来,为了保护用户的身份信息或敏感位置,Sweeney[3]提出了使用k-anonymity的方法,确保数据库中的每个数据无法与其他k-1条数据区分开来.为了抵抗具有背景知识的攻击者,Dwork[4]提出了差分隐私技术(Differential Privacy,DP)用于保护数据隐私.吴云乘等[5]提出了基于时空关联性的差分隐私保护方法.冀亚丽等[6]提出了基于时空和群体特征的兴趣区域的构建方法,根据访问频率对用户的地方进行处理.
尽管现有的隐私保护方法在保护用户敏感信息方面做出了很大的贡献,但大多数研究人员考虑的是敏感位置或敏感区域等,他们中的大多数没有考虑到位置语义特征所代表的含义,位置语义特征的外在表现是用户的日常行为模式.一般来说,位置语义信息(Location Semantic Information,LSI)是通过停留点来体现的.停留点则是由用户在一定范围内长时间的停留而形成的,因此停留点表示的是用户的日常活动等敏感信息,而这些信息可以用LSI代替.从敏感度的角度来说,使用位置语义敏感度代替位置敏感度.下文将“位置语义敏感度”简称为“语义敏感度”,“位置语义”简称为“语义”.
此外,Yuan等[7]提出了对敏感位置分级的策略,如果某个位置对用户不敏感或敏感度低,但是从全局的角度(轨迹数据库)考虑,假如该位置拥有极高的敏感度,那么该方法对类似这样的位置在处理方面存在一定的局限性.Li等[8]提出了基于语义的敏感等级构建方法,但该方法并不适用于轨迹数据发布的隐私保护场景.
为了保护用户的敏感位置语义,本文提出了一种结合神经网络和敏感位置语义的轨迹隐私保护方法TP-SLS.首先,分别从局部(个人轨迹数据)和全局(所有用户的轨迹数据)的角度考虑,提出了敏感度感知模型(Sensitivity Awareness Model,SAM),用于量化语义敏感度.然后,为了干扰用户的敏感位置,本文构建了基于空间坐标、时间和语义敏感度的用户构建敏感移动场景,并使用差分隐私技术干扰.最后,考虑到预测的轨迹可能存在废数据,提出了基于强化学习和多属性决策的轨迹优化方法.本文使用了一个真实的数据集评估了TP-SLS.实验结果证明,TP-SLS在隐私保护强度和数据可用性两个方面优于现有的方案.
1 相关工作
Xu等[9]提出了一种DP-LTOD的方法.他们使用聚类算法将具有相同兴趣爱好的用户划划分为同一个社区,然后使用启发式轨迹混淆算法从原始轨迹中选择最小差异的轨迹,最后使用DP技术平衡隐私保护和数据效用强度.Chen等[10]提出了一种DP-QIC的数据发布机制.该机制的核心是使用DP混淆相关属性,通过挖掘敏感属性与QI之间的潜在关系抵御攻击.Chen等[11]提出了一种基于循环神经网络和DP的方法.该方法基于原始轨迹,对速度属性添加DP噪声干扰,通过循环神经网络生成新轨迹;最后,对新轨迹进行判别和处理,完成轨迹数据的发布.Qu等[12]提出了一种以GAN为驱动的个性化隐私保护方案.该方案为了解决由GAN引起的不可预知的随机性问题,设计了一个P-GAN的模型.首先,将用户按社区分类,按照社区边缘的密度划分出不同的亲密度;然后,设计一个QoS函数,将亲密度与隐私保护级别相关联;最后,构造一个DP识别器用于扩展GAN,实现数据效用,满足个性化的隐私保护需求.
综上所述,现有的隐私保护机制一定程度上满足了不同的隐私保护需求,但大多数没有考虑到语义信息,并且没有很清晰的描述出语义的敏感度问题.基于此,TP-SLS考虑到了语义敏感度的问题且构造一个SAM模型用于量化语义敏感度权重.与以往工作不同的是,本文没有使用速度或者语义属性构建移动场景.而是基于语义敏感度,构建了敏感移动场景,并且使用差分隐私进行干扰.最后,使用神经网络技术的优势,提出了一种将神经网络和敏感位置语义相结合的轨迹隐私保护方法.
2 预备知识
2.1 Transformer network
Transformer network[13]是一个编码器-解码器结构和仅依赖于自注意力的多层堆栈模型.它的每一层都是一个由点积组成的自回归模型的多头自注意力机制,可以表示为:
(1)
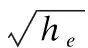
2.2 深度Q网络
在人工智能领域中,强化学习(Reinforcement Learning,RL)是一个重要的分支.RL的核心是智能体与环境的交互,这个过程使用马尔科夫决策过程(Markov Decision Process,MDP)来表示.五元
Q-learning是强化学习的主要算法之一.但如果动作和状态空间的维度复杂性很高时,由于Q-table(一个存储动作和状态的表格)的限制,使得Q-learning无法或难以完成复杂的任务.为了解决复杂任务的应用场景,Mnih等[14]提出了一种基于神经网络的方法用于估计Q函数(期望奖励函数,Q表示一个动作的期望奖励),即深度Q网络(Deep Q Network,DQN).DQN包含了两个神经网络,分别是估计值网络和目标值网络.估计值网络和目标网络的输出分别是Q估计值和Q目标值,DQN的目的是确保这两个值尽可能的接近.这个过程可以用一个损失函数表示.
Loss(θ)=E[(Qtarget-Q(st,at;θ))2]
(2)
其中Q(st,at;θ)表示时刻t的Q估计值,θ表示网络参数,Qtarget是目标值,为:
Qtarget=r+λmaxat+1Q(st+1,at+1;θ)
(3)
其中,r表示奖励值,Q(st+1,at+1;θ)表示时刻t+1的Q估计值.
2.3 相关定义
定义1.(ε-差分隐私)对于两个数据库D1和D2,如果它们之间最多存在一个数据差异,D1是较大的数据库,D2是较小的数据库,那么可以说D1和D2是相邻数据库.如果存在一个随机算法L,使得相邻数据库的输出结果Q满足:
Pr[L(D1)∈Q]≤oε×Pr[L(D2)∈Q]
(4)
那么可以说满足ε-差分隐私,ε是差分隐私参数.其中,Pr表示概率,o表示自然常数.
定义2.(灵敏度)对于任意一个查询函数f,ff∈F(D)属于实数集,f的灵敏度Qf定义为:
(5)
其中‖·‖1表示曼哈顿距离.
定义3.(拉普拉斯机制)拉普拉斯机制是目前最常见的处理机制,通过在查询结果中加入符合拉普拉斯分布的噪声η保护数据的安全,可以表示为:
(6)
其中λ是噪声参数.
定义4.(语义点)语义点p是一个三元组,p=(lat,lon,ls),其中lat和lon表示空间坐标,如WGS84坐标参考系统中的纬度(lat)和经度(lon),ls表示语义(语义是兴趣点(point-of-interest,POI)的描述,可以通过LBS数据库查询).
在本文中,ls表示的是“小语义”,例如一个POI的语义描述是“食品、快餐店、肯德基”,语义描述级别从大到小,表示的是“肯德基”.
定义5.(语义轨迹数据库)语义轨迹数据库Dls={Tls1,Tls2,…,Tlsu}是特定类型的时空数据库,表示所有用户在一个固定空间内的连续变化.其中,Tls=p1,p2,…,pn,pi表示语义点.
定义6.(个人语义敏感权重)个人语义敏感权重表示用户与语义的亲密程度,记为γ,个人语义敏感权重集合ST表示为:
ST={(ls1,γ1),(ls2,γ2),…,(lsq,γq),Ui}
(7)
其中Ui是用户标识.特别说明的是,如果某个语义不在集合ST中,它的语义敏感度权重等于0.
3 TP-SLS方法
TP-SLS利用DP干扰语义敏感权重,使用神经网络处理时间序列轨迹数据.TP-SLS如图1所示,分为4个步骤:

图1 TP-SLS体系结构Fig.1 TP-SLS architecture
步骤1.基于语义轨迹数据库Dls,提出了一个敏感度感知算法SAM量化语义敏感权重.
步骤2.将添加噪声后的语义敏感度权重引入轨迹数据中,并使用Transformer network训练一个轨迹预测模型.
步骤3.引入DQN优化预测的轨迹数据.
步骤4.修复由于停留点的变更而导致的路径不相连,完成轨迹数据的发布.
3.1 SAM算法
SAM算法的目的是量化语义敏感度权重,为构建用户的语义敏感移动场景和优化轨迹提供数据支撑.SAM由3个算法构成,分别是语义访问频率分级算法(Semantics access frequency classification algorithm,SAFC)、异常值感知算法(Outliers-aware algorithm,OLA)和语义敏感度权重分配算法(semantics sensitivity weight allocation algorithm,SSWA).其中,SAFC算法基于个人轨迹数据库初始化个人语义敏感度公式,OLA算法用于解决SAFC算法无法处理的全局(轨迹数据库)语义敏感度问题,SSWA算法将OLA算法和SAFC算法结合起来,得到一个全新的语义敏感度公式,并计算语义敏感度权重.
3.1.1 SAFC算法
SAFC算法的核心思想是将访问停留点的频率,转换为访问语义的频率.然后,利用聚类算法将频率相近的语义聚类,根据频率分级.最后,初始化语义敏感度公式.处理过程为:
步骤1.从用户轨迹数据中提取停留点的频率,并对语义相同的停留点的访问频率fr做累加计算处理.用户的语义频率如式(8)所示:
LS={(ls1,fr1),(ls2,fr2),…,(lsq,frq),Ui}
(8)
步骤2.令样本z=(ls,fr),样本空间Z=(z1,z2,…,zq).对相似频率的样本数据分割,用光谱聚类算法将Z分为κ个子集,记为C=(c1,c2,…,cκ).
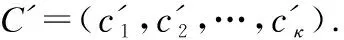
步骤4.基于C′划分语义敏感度级别.存在映射函数f1和f2如式(9)和式(10)所示:
(9)
f2:(δ1,δ2,…,δκ)→(1,2,…,κ)
(10)
令sn表示c′的语义数量.同一个敏感度级别中的语义敏感度权重相同,将敏感度权重记为γ.那么,δ1的权重是γ1,δ2的权重是γ2,δκ的权重是γκ.粗糙语义敏感度权重公式STr表示为:
sn1·γ1+sn2·γ2+…+snκ·γκ
(11)
其中,γ1>γ2>…>γκ.
算法1描述了SAFC算法.
算法1.语义访问频率分级算法(SAFC)
输入:Tls
输出:STr
1.从Tls中提取所有的语义并去重,存储到Fls
2.forlsinFlsdo
3. 初始化Γ=0
4. forpinTlsdo
5. 获取p的语义ls′
6. ifls=ls′ then
7. Γ←Γ+1
8. end if
9. end for
10.将(ls,Γ)保存到LS
11.end for
12.LS转换为Z
13.Z转换为矩阵并使用Spectral Clustering算法得到C
14.计算C中每一个簇的中位数并排序得到C′
15.使用映射函数f1和f2并根据权重映射得到粗糙语义敏感度公式STr
16.returnSTr
3.1.2 OLA算法
一般而言,用户访问一个POI的频率越高,说明用户对这个POI的敏感度越高.但是访问频率低的POI语义,它的敏感度也可能非常高.算法1无法处理上述的POI.具有上述特征的POI属于异常值,OLA算法的目的是为了寻找这些异常值.为了更好的理解OLA算法,下面给出一个例子说明SAFC算法的局限性和OLA算法的应用场景.
用户A是一个普通公司员工,他由于生病访问了医院.用户B是一名医生,他的工作地点在医院.在SAFC算法中,对于“医院”语义,用户A的敏感度等级低,用户B的等级高.相比之下,用户A的“医院”语义敏感度等级应该更高,因为用户A的身份对于“医院”的差异性高.在轨迹数据中,如果其他用户拥有“医院”语义,由于其他用户的混淆,拥有“医院”的用户越多,用户A就越安全.由此,语义的敏感度级别不仅依赖于个人语义数据,还依赖于其他用户的语义数据.那么,OLA算法需要度量语义的信息量,用于判断语义是否属于异常值.OLA算法的核心思想是利用熵权法计算所有语义的权重,并使用标准差筛选出偏离总体趋势的异常值.OLA算法分为两个步骤.
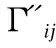
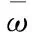
(12)
(13)
算法2描述了OLA算法.
算法2.异常值感知算法(OLA)
输入:Dls
输出:STun:语义异常值的集合
1.从Dls中提取所有的语义并去重,记为LSall
2.基于LSall和用户标识构建语义-频率数据表格
3.forlsinLSalldo
4. forTlsinDlsdo
5. 初始化Γ=0
6. 获取Tls的语义与对应的频率并对频率做累加计算操作,记为Tls′
7. if ∃ls′(ls′∈Tls′),ls=ls′ then
8. Γ←Γ′(Γ′∈ls′)
9. end if
10. 基于用户标识和语义信息,将Γ存储到语义-频率数据表格
11. end for
12.end for
13.基于语义-频率数据表格,使用熵权法计算语义权重
14.使用公式(13)计算ζ
15.基于ζ筛选语义异常值,并保存到STun
16.returnSTun
3.1.3 SSWA算法
SSWA算法的核心思想是将SAFC算法和OLA算法相结合,重置语义敏感度公式,并基于可行域计算语义敏感度权重.算法3描述了SSWA算法.
算法3.语义敏感度权重分配算法(OLA)
输入:C′,STun
输出:ST

2.forlsuninSTundo
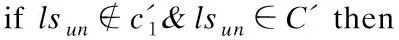
5. end if
6.end for
7.使用SAFC算法中描述的方法,重置语义敏感度权重公式,记为STre
8.基于1>γ1>γ2>…>γκ>0和STre构建语义权重可行域
9.在可行域中随机选择一个点,记为frp

11.forc′ inC′ do
使用映射函数f1和f2获取c′的敏感度等级,将对应的权重γ赋予敏感度等级δ
12. 将c′中的语义与γ保存到ST
13.end for
14.returnST
3.2 轨迹生成模型
在本节中,构建一个用户敏感度移动场景用于训练Transformer network模型,用于预测轨迹.由于轨迹数据的复杂性,对轨迹数据做预处理,处理过程分为3个步骤.
步骤1.基于时间序列,将轨迹数据中的坐标点连接起来.用户的原始轨迹数据如公式(14)所示:
Traw:(lat1,lon1,ts1)→
(lat2,lon2,ts2)→…
→(latn,lonn,tsn)
(14)
其中,ts表示时间序列.
步骤2.将添加噪声后的语义敏感度权重用于扩展Traw.如公式(15)所示:
(15)
但是,由于轨迹数据的复杂性,编码变得非常困难.根据Nguyen等[15]提出的“regularization term”的方法,本文将任意时刻的坐标数据构造为一个高维嵌入向量ei,ei∈he.关系映射如图2所示.
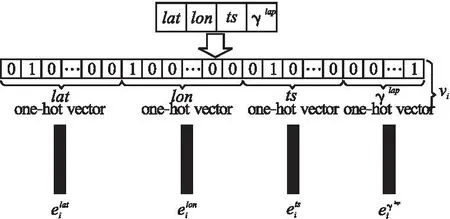
图2 轨迹数据转换方法Fig.2 Trajectory data conversion method
转化后的轨迹数据如公式(16)所示:
(16)
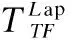
(17)
3.3 轨迹优化
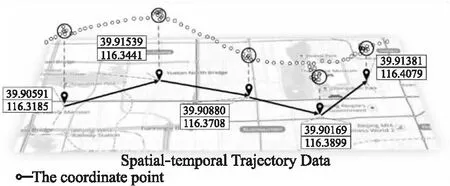
图3 DBSCAN处理坐标点Fig.3 DBSCAN dealing with coordinate points
在优化的过程中,为了尽量贴合预测的轨迹数据,需要考虑相邻POI之间的距离(dis)和方位角(ath)两个属性.另外,考虑到用户的敏感语义问题,还需要另外一个属性:语义敏感度权重γ.
对于上述的3个属性,使用多属性决策模型之加权算法平均算子计算POI的期望值,记为POIr.对于dis和ath两个属性,使用Vincenty公式的逆解计算.计算距离的公式记为Vd,计算方位角的公式记为Va.dis和ath是固定型,固定值如公式(18)所示:
(18)
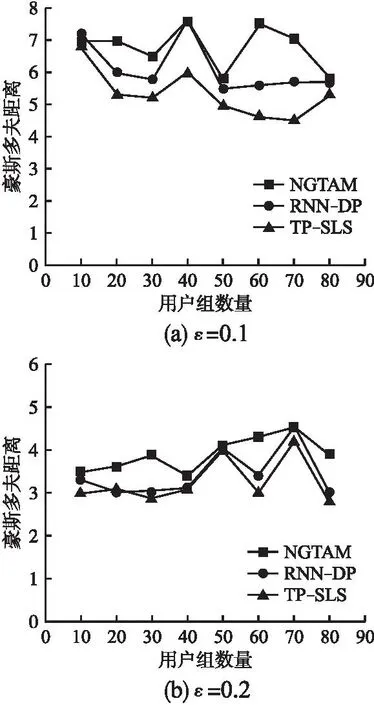
其中,i γ是偏离型,固定值为1.3个属性的归一化如公式(19)所示.其中,σpoi表示当前POI的语义敏感度权重. (19) 由于动作和状态空间的复杂性高,引入了DQN.DQN中,智能体在每个时刻t的状态是st=(latt,lont,lsnt,st∈S,其中latt和lont表示t时刻POI的坐标,lsnt表示位置序列号,同一个查询范围内的所有POI共享lsn.对于奖励值和状态,使用d-状态池算法进行预处理.算法4描述了d-状态池算法. 算法4.d-状态池算法 输入:Ppre,ST 输出:Sset:状态集合,Spoir:POI期望值集合 2.定义一个集合POIall,存储指定聚集点查询范围内的所有POI信息. 3.初始化lsn=0,γpoi=0 4.forppreinPpredo 6.lsn←lsn+1 7. 根据公式(18)计算距离和方位角的固定值 9. end for 10. forpoiinPOIalldo 11.dis=Vd(ppre,poi),ath=Va(ppre,poi) 12. iflspoi∈STthen 13. 将对应的权重赋予γpoi 14. else 15.γpoi←0 16. end if 17. 使用多属性决策计算POIr 18. 将POIr压入Spoir 19. 将(latpoi,lonpoi,lsn)压入Sset/*latpoi和lonpoi是poi的坐标*/ 20. end for 21.end for 22.returnSset,Spoir 此外,奖励值由智能体的“移动方向”确定,使用lsn引导智能体的“移动方向”.如公式(20)所示: (20) 对于优化后的轨迹,可能存在由于停留点的变化而导致相邻停留点之间的路径断开,使用Ye等[17]提出的一种路径补偿方法修复断开的路径.修复完成后,完成轨迹数据发布. 本文使用微软研究院的T-Drive数据集[18]和高德地图API验证TP-SLS方案的有效应.T-Drive数据集收集了10357辆出租车的GPS数据,其中包含超过1500万个GPS点.SMA算法和d-状态池算法需要获取停留点的语义信息和停留点周围的所有POI信息.由于T-Drive数据集只包含位置信息,需要一个LBS服务来完成这项工作.在本节中,将TP-SLS方案与NGTMA[19]和RNN-DP[11]进行了比较.本文选取10-80名用户,分别设置隐私参数ε=0.1和ε=0.2,在隐私保护强度和数据效用两个方面做对比. 使用互信息(Mutual Information,MI)来衡量在不同隐私预算下,TP-SLS的隐私保护强度.MI越低,隐私保护强度越高.如图4所示,MI随着ε的增加而增加.这说明ε与隐私保护强度有关,隐私保护强度随着ε的增加而降低.当ε的值较低时,TP-SLS方法具有优势. 图4 隐私保护强度Fig.4 Privacy protection intensity 为了衡量TP-SLS的数据可用性,使用豪斯多夫距离(Hausdorff Distance,HD).HD是对两组点之间距离的测量,它在评估两组数据的相似性领域有广泛的应用.图5展示了对比结果.当数据大小相同时,ε增加,HD降低,说明隐私保护强度降低,数据可用性提高.表明了ε值较小时,TP-SLS方法具有优势. 图5 数据可用性Fig.5 Data availability 在性能实验分析中,TP-SLS使用真实世界的数据,与其他两个方案在隐私保护强度和数据可用性两个方面进行了比较. 4.3.1 隐私保护强度分析 与NGTMA和RNN-DP相比.TP-SLS在MI的度量上到达最低值.ε=0.1时,最大提升0.00108和0.00044;ε=0.2时,最大提升0.00413和0.00219.TP-SLS量化了语义敏感度权重,每个语义都有属于自己的权重指标,语义敏感度权重和语义是密切相关的.在一定程度上,语义敏感度可以代替语义去构建用户的敏感活动场景.那么,对语义敏感度添加噪声,相当于对敏感语义进行了干扰.同时,使用Transformer network用于处理轨迹数据,它对于序列数据的处理性能远远超过现有的一些神经网络模型,尤其是对于长序列数据的处理. 4.3.2 数据可用性分析 通过对比,TP-SLS的HD最小,这表明TP-SLS在数据可用性方面有更好的表现.ε=0.1时,最大提升2.89059和1.57608;ε=0.2时,最大提升1.2889和0.39621.TP-SLS使用了Q-learning作为优化机制,使用了Transformer network作为预测机制.同时,对于优化轨迹,考虑到了轨迹中相邻POI之间的距离和方位角,这两个属性决定了轨迹的走向,在一定程度上提升了数据的可用性.最后,考虑到了由于POI的改变而导致的路径断开问题. 本文提出了一个基于敏感位置语义的轨迹隐私保护方法,使用Transformer network预测用户的轨迹.此外,本文提出了一个敏感-感知模型量化用户的语义敏感度,并将语义敏感性引入原始轨迹数据,同时使用差分隐私技术干扰语义敏感度,从而干扰用户的敏感位置,建立一个四元组的用户敏感移动场景.为了解决预测的轨迹数据存在废数据的问题,提出了基于DQN的优化轨迹算法.通过理论和实验证明,TP-SLS方案可以更好地保护隐私,提高数据的可用性.在局限性方面,由于TP-SLS方案需要使用LBS数据库来提取停留点的语义信息,如果LBS数据库提供的数据精度不够,可能会影响隐私保护结果和数据可用性.
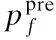
3.4 轨迹数据发布
4 实验与性能分析
4.1 隐私保护强度
4.2 数据可用性
4.3 结果分析
5 结束语
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
开放教育研究(2020年2期)2020-03-31
工程与建设(2019年5期)2020-01-19
新闻传播(2018年10期)2018-08-16
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
海外华文教育(2016年2期)2017-01-20
现代语文(2016年21期)2016-05-25
电子设计工程(2015年15期)2015-02-27
