
一种面向行人跌倒检测的改进YOLOv5算法
2024-04-22 02:30沈国鑫刘力手尹天睿
小型微型计算机系统 2024年4期
沈国鑫,魏 怡,刘力手,尹天睿
(武汉理工大学 自动化学院,武汉 430070)
0 引 言
近年来,随着我国快速发展,城市人口密度迅速增加,这也增加了公共场合发生拥挤跌倒的概率和一些安全隐患,尤其是在地铁站、公交站等等场合,如果发生跌倒现象而没有及时发现就会产生严重后果.因此,亟需提出一种检测精度高、实时性的好的跌倒检测模型.近年来,深度神经网络在目标检测领域取得了巨大的成就,如SSD[1]、R-CNN[2]、Fast RCNN[3]、Faster RCNN[4]、YOLO系列[5-8]等等目标检测模型广泛应用于无人驾驶、自动导航、姿态检测等.至今为止,目标检测算法分为one-stage以及two-stage两种.two-stage算法的典型代表就是R-CNN、Fast RCNN以及Faster RCNN,而one-stage算法典型的代表是YOLO系列以及SSD算法.
对于复杂场景下的跌倒检测,由于工作区范围大,环境差,背景复杂,经常会出现目标互相遮挡难以检测等问题,针对以上问题,许多学者对此进行了很多研究.周大可等[9]人提出一种结合双重注意力机制的遮挡感知行人检测算法,提升了遮挡目标的检测准确性.王立辉[10]等人提出一种基于GhostNet与注意力机制结合的行人检测与跟踪算法,将其引入到YOLOv3中替换主干,来达到精确有效地跟踪复杂场景下的多目标行人的目的.王璐[11]等人提出一种基于语义分割注意力和可见区域预测的行人检测方法用于行人行为预测.钱惠敏[12]等人本文提出基于ResNet34_D的改进YOLOv3模型,对小目标和遮挡目标的误检率更低,速度更快.陈光喜[13]等人设计了一种基于YOLOv2的级联网络,对YOLOv2初步检测出的行人位置进行再分类与回归,以此降低误检,提高召回率.涂媛雅[14]等人提出了基于Lite-YOLOv3的行人与车辆检测方法,采用改进后的深度可分离卷积块,有效降低了网络运算成本,加快网络运算速度.Sweta Panigrahi[15]等人提出了一种改进的轻量级MS-ML-SNYOLOv3网络,它可以提取分层特征表示,在扩展部分还增加了一个更大的感受野来提高检测效果.Jing Wang[16]等人提出一种高质量的特征生成行人检测算法来提高检测表现.人类可以通过考虑图像中所有可用实例的相互线索来更好地预测目标的存在,而多模态特征的融合可以表达这个过程,Yongjie Xue[17]等人提出一种新型多模态注意力融合MAF-YOLO的实时行人检测方法来提高夜间检测的精度,Yanpeng Cao[18]等人提出了一种新的多光谱行人检测器,这是由执行局部引导的跨模态特征聚合和像素级检测融合模型.但是上述网络模型的精度仍然达不到跌倒检测的要求,关键特征融合次数仍然较少,对于多重遮挡问题仍然没有很好的解决.
针对上述问题,本文贡献如下.首先本文提出了一个新的特征增强融合模块FFEM来增强目标的特征表示和解决多重遮挡问题,其次提出一种新的特征金字塔网络(AFEF-FPN)来提高特征自适应融合深度,最后引入Alpha IoU Loss和CARAFE代替CIoU Loss和Nearest Upsample来提高回归精度和上采样的语义信息.实验表明,本文提出的基于AFEF-FPN的YOLOv5s网络能够准确的处理各种复杂的跌倒场景,在数据集上取得了优于其他网络的结果.
1 相关工作
1.1 YOLOv5网络模型简介
YOLOv5的网络结构由Backbone、Neck、Head 3个部分组成,在6.0版本中,Backbone使用的是Darknet53作为特征提取网络,Neck部分使用PAN+FPN的结构,一共有3个Prediction-head,分别用来检测大、中、小目标.YOLOv5算法具有4个版本,具体包括:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 4种,本文重点讲解YOLOv5s,s版本是YOLOv5系列中卷积深度最小、特征图宽度最小的网络.
对于一组图片输入,先是进行自适应的锚框的计算和数据增强,然后Backbone会对提取输入图片各个尺度下的特征,提取到的多尺度特征会在Neck部分进行融合,融合采用的是PAN+FPN的结构,最后分别在网络的18层、21层、24层作为网络的输出端进行预测,在预测的过程中会随机产生大量的预测框,通过非极大值抑制(Non-Maximum Supression,NMS)[19]来筛选目标框,最后预测筛选得到的目标框的类别.
PAN-FPN[20]是在原始FPN自上而下的特征融合通道的基础上增加了一条自下而上的特征融合通道.除此之外,还有Mingxing Tan[21]等人提出的Bi-FPN、Golnaz Ghaisi[22]等人提出NAS-FPN.经过对多种基于YOLOv5的网络模型的实验发现,这些特征融合网络在跌倒检测数据集上并不能取得很好的效果,仍然会出现许多漏检和错检的情况,尤其在多个跌倒的人高度重叠的场合,非常容易发生漏检.Yiqi Jiang[23]等人提出GiraffeDet特征融合网络,他们提出了一种目标检测新范式:Heavy-Neck,Light-Backbone.他们指出Backbone已经提取到了丰富的信息,增加Neck层的融合次数比增加Backbone的卷积层数量得到的结果更好,本文受到此启发提出了一种新的特征融合网络.
1.2 注意力机制
近年来,注意力机制被广泛应用于计算机视觉领域,常见的注意力机制有通道注意力和空间注意力两种.Hu J[24]等人提出了一种通道注意力机制Sequee-and-excitation(SE),SE的出现是为了解决在池化过程中的特征图不同通道的重要性不同的问题.Woo S等人将通道注意力和空间注意力进行级联整合提出了Convolution block attention module[25](CABM),进一步加强了注意力感知.Qilong Wang等人为了进一步加强通道注意力而提出了ECA-Net[26].Qibin Hou等人提出了Coordinate Attention(CA)[27],该机制将位置信息嵌入到通道注意力中,它可以沿着一个空间方向捕捉长程的依赖,而另一个空间方向则可以保留精确的位置信息,从而捕捉特征图上感兴趣的区域.受到CA的启发,本文设计了一个特征增强融合模块,增强融合后得到的结果用CA捕捉感兴趣的目标,以此来建模多尺度特征之间的长距离依赖关系.
2 本文工作
2.1 网络模型的整体结构
本文网络由Backbone、AFEF-FPN(Neck)、Head 3个部分组成,输入一组图片,输出这组图片中的检测目标的类别、预测框、置信度等信息.首先本文提出一种新的特征增强融合模块(FFEM),它是由一个Concat模块、一个CA模块、一个Receptive Field Block(RFB)[28]模块、一个1*1的卷积层组合而成,FFEM可以解决感知域受限的问题,增强输入特征的特征表示,同时在原始特征融合的基础上将特征进一步融合,提高 Backbone特征信息的复用率.使用Adaptively Spatial Feature Fusion(ASFF)[29]模块作为本文网络的Neck的最后一部分,其作用是为了让特征图自适应的进行融合,FFEM输出的特征图用于Adaptively Spatial Feature Fusion(ASFF)融合,加权融合后会产生3个主成分,对这3个主成分分别进行回归预测,其中FPN在加入FFEM和ASFF改进后称其为Adaptivity Feature Enhance Fusion-FPN(AFEF-FPN).其次使用CARAFE[30]上采样模块代替Nearest Upsample,CARAFE 分为两个部分,分别是上采样核预测和特征重组,它是一种基于输入特征图信息并且引入参数量较小的上采样模块.然后使用Alpha IoU Loss代替CIoU Loss,Alpha IoU Loss可以根据IoU大小来自适应的加权目标损失和梯度,有利于提高bbox的回归精度.为了检测的实时性,本文删除了FPN部分的CSP模块的最后一层卷积层来减小模型参数,具体结构如图1所示.
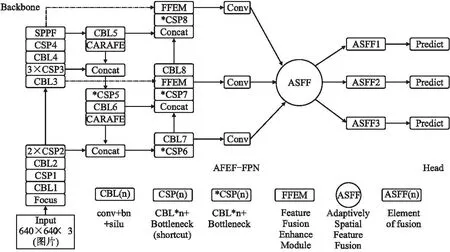
图1 本文网络结构图Fig.1 Network structure diagram of this paper
2.2 特征融合增强模块(FFEM)
在本小节中,主要介绍FFEM的具体结构,如图2(a)所示.整体结构如下:Concat模块将上一层的特征图与Backbone主干中对应特征图大小相同且未被FPN使用的特征图进行通道上的叠加融合,图1中的虚线为Backbone上特征的融合通道.融合之后的特征输入到RFB模块,RFB模块对于输入进来的特征图进行特征增强后传入1*1的卷积层来压缩输出通道数,最后传入CA模块来增加感兴趣目标的特征表示.
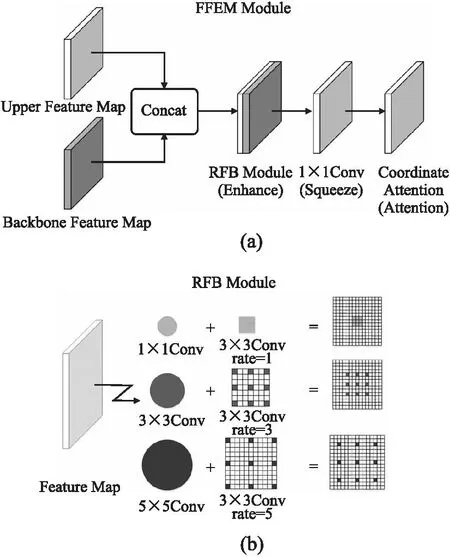
图2 FFEM(a)和RFB模块(b)结构图Fig.2 Structure diagram of FFEM(a)and RFB module(b)
RFB主要是由不同膨胀率的膨胀卷积组成,膨胀率表示每个相邻的卷积像素点之间非卷积像素点的个数.具体来说,普通的卷积核大小为3、步长为1的卷积覆盖的空间范围是3*3,即在一个3*3大小的特征图上进行卷积操作,而一个卷积核大小为3*3、步长为1、膨胀率为1的膨胀卷积覆盖的空间范围是5*5,在卷积核大小相同、步长相同的条件下,一次膨胀卷积比一次普通卷积覆盖的空间范围更大,即感受野更大,具体示意图如图2(b)所示.
本文使用了3种膨胀卷积,它们的膨胀率分别为1、3、5,输入RFB模块的特征图在进行3次膨胀卷积后再加入一条边直接连接输入输出来构成残差结构,有了这个残差结构就能够在一定程度上解决膨胀卷积核不连续的问题,并且能够实现多层膨胀卷积的叠加而不损失信息的连续性,此模块在本文中用于增大感知空间,提取更多的跌倒特征.
其次是CA模块,CA是一种轻量型注意力机制,不会给网络带来巨大的计算量.普通的通道注意力通常会忽略对生成空间选择注意力图非常重要的信息,图3为CA 模块的结构图.
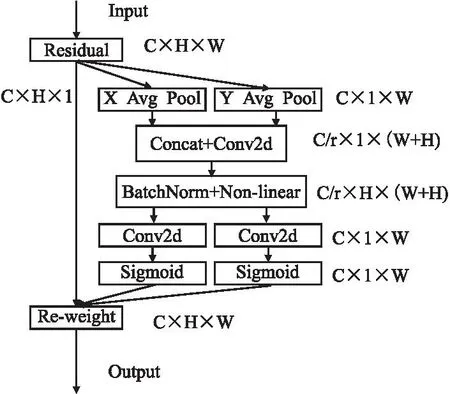
图3 CA模块结构图Fig.3 Structure diagram of CA module
CA把位置上的信息嵌入到通道中,这种做法大大减少了计算量的同时有了感知位置的能力.对于一个给定的输入x,每个通道分别在水平和垂直方向进行编码,在深度为h的第c个通道的输出可以表示为:
(1)
同理,宽度为w的第c个通道可以表示为:
(2)
上述的两种方法分别在不同的方向进行特征的聚合,这样做可以沿着一个空间方向捕捉长程的依赖,而另一个空间方向则可以保留精确的位置信息.为了利用捕捉到的信息表征同时降低模型的开销,CA首先将两个方向上的信息进行Concat操作后接一个1*1卷积来压缩通道数,压缩倍数为r,然后沿着空间维度将上述输出切分为两个单独的张量:fh∈C/r×H和fw∈C/r×H,再使用两个1*1卷积来变换成与输入x同样的大小,最后用Sigmoid激活输出,这样做可以显著减小CA模块参数量.其输出可以表示为:
gh∈σ(Fh(fh)),gw∈σ(Fw(fw))
(3)
其中,σ为Sigmoid激活函数,Fh和Fw是这两个1*1 卷积变换,gh和gw为两个不同空间维度上的输出.这时,整个CA的输出y可以表示为:
(4)
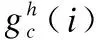
2.3 上采样改进与ASFF
2.3.1 上采样改进
常见的Nearest Upsample和Linear Upsample仅仅是根据像素的空间位置来确定上采样内核,这些方法不能利用特征图的语义信息,并且它们的感知域都非常的小.另一种自适应上采样的方法是反卷积,它有两个主要缺点,首先是反卷积算子在整个图像中应用相同的核,而不考虑底层的内容,这限制了它响应局部变化的能力;其次,它配有一个大的参数量.对于一个理想的上采样模块,希望感知域越大越好、计算量越小越好、和语义信息的关联性越大越好,为了解决模型的上采样语义关联性不高的问题,本文使用CARAFE代替Nearest Upsample.CARAFE的上采样过程主要由上采样核预测和特征重组两个步骤组成,第1步主要是利用特征图上的语义信息来预测上采样核的形状,第2步是将输出特征图中的每个位置映射回输入特征图,取出以之为中心的区域,和第一步得到的上采样核作点积,得到输出值.
2.3.2 ASFF
金字塔特征表示是解决目标检测中目标尺度变化的常用手段.然而不同特征图的大小不一致,通常的做法是将相同尺度的特征图融合检测,或者使用上采样和下采样来压缩特征图尺度保持一致后融合检测.Adaptively Spatial Feature Fusion(ASFF)是一种新的特征融合策略,它通过学习空间滤波冲突信息来抑制特征图的不一致性,对于输入X个的特征图,ASFF对它们进行加权处理,然后输出X个自适应融合特征图,其中每输出一个特征图都是输入特征图的加权,并且几乎没有引入推理开销.
(5)

(6)
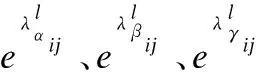
2.4 IoU Loss改进
2.4.1 IoU、GIoU、CIoU和DIou Loss
传统的损失回归都是基于可以表征一个矩形的4个顶点变量,但是这种做法过于简单,不能完整的表示出4个顶点变量之间的内部关系,并且会导致模型在训练过程中更加倾向于尺寸更大的目标.为了解决这个问题,Jiahui Yu[31]等人提出IoU Loss将4个点构成的bbox看成一个整体做回归,这样做的好处是统一了4个变量之间的关联性.其中IoU和IoU Loss定义如下.
(7)
IoU Loss=1-IoU
(8)
其中,A和B分别表示真实框和预测框,A∩B和A∪B分别表示为真实框与预测框并集的部分和交集的部分.并且IoU满足非负性和归一性,所以能够较好的反映预测框与真实框的检测效果.
为了解决当IoU Loss恒等于0时梯度恒为0无法反向传播的问题,Hamid Rezatofighi[32]等人提出了GIoU Loss.Zhaohui Zheng[33]等人提出衡量一个预测框好坏,应该从预测框与真实框的中心点距离以及长宽比之间的差异这3个方面考虑,于是他们提出了DIoU和CIoU,在GIoU的基础上引入中心点距离作为DIoU,在DIoU的基础上再引入长宽比之间的差异作为CIoU.
(9)
ρ2(b,bGT)表示真实框与预测框中心点距离的平方,c2是两个框的最小包络的对角线长度.
DIoU Loss=1-DIoU
(10)
CIoU Loss=DIoU Loss+η×υ
(11)
(12)
(13)
υ表征长宽比的一致性,η是调节因子,wGT、hGT和w、h分别表示为真实框的宽、高和预测框的宽、高,DIoU可以精细的指导预测框的中心,CIoU不仅可以指导预测框中心而且还能使得预测框长宽比更加接近真实框.
2.4.2 Alpha IoU Loss
但是CIoU和DIoU对于每个IoU目标都是平等对待的,因此对于High IoU的目标无法做到高精度回归.于是本文用Alpha IoU Loss[34]代替CIoU Loss,Alpha IoU Loss可以根据IoU大小来自适应的加权目标损失和梯度,有利于提CIoU Loss目标的回归精度.Alpha IoU Loss定义为:
(14)
其中,α是一个可调节参数,当α→0时,lα-IoU=-log(IoU),当α→/0时,lα-IoU=1-IoUα.
在上述公式中加入惩罚项,可以扩展到更加一般的形式:
lα-IoU=1-IoUα1+pα2(B,Bgt)
(15)
这时,α-IoU 可以通过压缩表示出GIoU、DIoU、CIoU.它还有一个重要的性质,由于α是一个可调节的指数参数,那么当α大于1的时候,就会对High IoU目标的损失权重有放大的作用,有利于检测器更加关注High IoU的目标,对High IoU损失的目标更加敏感.为了提高High IoU目标的回归精度,本文使用Alpha IoU Loss代替CIoU Loss,经过实验测试,α参数为3可以取得最好的效果.
3 实 验
3.1 实验环境和数据集
本实验的深度学习环境和使用的框架如表1所示,并以相同的配置应用于Faster RCNN、未改进的YOLOv5、Mobilenet-YOLOv5等网络.

表1 实验环境配置表Table 1 Experimental environment configuration table
本文实验中使用的数据集标签属于独立制做,总共有8000张图片.其中,6875张图片来自于公共跌倒检测数据集[35],1125张图像来自于跌倒视频截帧.本文选取5600张图片用作训练集和验证集,2400张图片用于测试集,训练开始前使用了马赛克的数据增强方法.
3.2 网络参数设置
首先将网络输入的图片大小统一resize为640×640,bacthsize设置为16,使用随机梯度下降法作为本文网络的优化器.为了获取适合本文网络的最优超参数,本文使用基于遗传算法的超参数进化算法对网络超参数进行优化.为了减少进化时间,仅挑选800张图片作为进化过程中的数据集,evolve设置为50,epoch设置为50,每一代的进化都取最大值的点表示为本代超参数下的输出的mAP值.训练过程中的mAP的变化曲线如图4(a)所示,从第2次迭代开始逐渐收敛,在第25代之后收敛于最大值,而后仅仅在小范围内波动.最终得到的mAP值最大值为98.24%,并选择这组超参数设置为本文网络超参数,具体超参数设置如下:初始学习率设置为0.01282,学习率动量设置为0.97676,权重衰减系数设置为0.002,IoU训练时的阈值设置为0.40,图像Mosaic的概率设置为1.0.
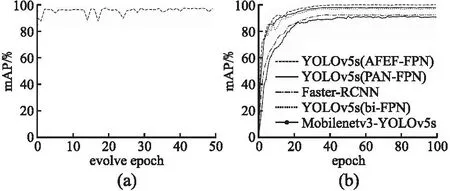
图4 超参数进化曲线(a)和mAP上升曲线(b)Fig.4 Hyperparameter evolution curve(a)and mAP rising curve(b)
3.3 实验结果对比和可视化
首先将本文提出的算法与现有算法在数据集上进行比较,为了客观评价本文网络模型的性能,使用精确率(Precision,P)、召回率(Recall,R)、平均精度(Average Precision,AP)、平均精度均值(mAP0.5)以及平均精度均值(mAP0.5-0.95)指标衡量,计算公式如下.
(16)
(17)
其中,TP(True positives)为正样本被正确识别为正样本的数量,FP(False positives)为负样本被错误识别为正样本的数量,FN(False negatives)为正样本被错误识别为负样本的数量,N为目标的类别数.AP的意义是P-R曲线所包络的面积,mAP越大网络性能越好.保持数据集、运行环境一致,在超参数为最优的前提下,本文使用了Mobilenetv3-YOLOv5、Faster-RCNN、YOLOv5(PA-FPN)、YOLOv5(bi-FPN)以及本文的YOLOv5(AFEF-FPN)分别进行训练.
如图4(b)所示,可以看出本文的网络模型在训练初期就可以快速稳定的收敛,曲线于40次迭代时达到最大值附近,而后在小范围内波动,并且本文网络的mAP 包络线包围了其 他网络的 mAP 曲线.YOLOv5s(AFEF-FPN)最高mAP达到了98.62%,而Faster-RCNN、Mobilenetv3-YOLOv5、YOLOv5s(bi-FPN)、YOLOv5s(PAN-FPN)的最高mAP分别是90.12%、89.85%、96.67%、96.98%,比YOLOv5s(bi-FPN)提升了1.95%,比YOLOv5s(PAN-FPN)提升了1.64%,比Faster-RCNN、Mobilenetv3-YOLOv5提升了8%以上.为了更加深刻的体现本文网络的优越性,本文分别用mAP0.5、mAP0.55、mAP0.6、mAP0.65、mAP0.7、mAP0.75这些数值较大的指标评价网络.
如表2所示,YOLOv5s(AFEF-FPN)在mAP0.5~0.75所有的指标都高于其他网络模型.不仅如此,本文在2400张图片的测试集上进行测试,YOLOv5s(AFEF-FPN)的mAP0.5的值达到了96.21%,而其他网络分别是YOLOv5s(PAN-FPN)93.35%,YOLOv5s(bi-FPN)93.12%,Mobilenetv3-YOLOv5 78.89%,Faster-RCNN 79.37%,其中YOLOv5s(AFEF-FPN)相比于原始YOLOv5s网络在测试集上提高了2.86%的mAP.由此可以得出,YOLOv5s(AFEF-FPN)在训练集和训练集上都取得了优于其他网络的结果,这也体现出它的强大的泛化能力.

表2 不同模型mAP(0.5-0.75)的对比Table 2 Comparison of mAP(0.5-0.75)of different models
为了体现出FFEM的优势,本文对特征图可视化分析.如图5所示,左边的3张图片为输入原图,中间的3张图片为YOLOv5(PAN-FPN)提取的深度图片,右边3张图片是在FFEM作用之后的深度图片,通过对比可以发现,FFEM模块不仅可以注意到有人跌倒的区域.相比起其他YOLOv5网络,注意区域不仅更加准确,还可以增强对感兴趣区域表征.在第1组的3张图片中,FFEM注意到了跌倒特征区域,而YOLOv5(PAN-FPN)没有捕捉到跌倒特征区域.在第2组的3张图片中,FFEM增强了跌倒特征区域的表征.在第3组图片中,YOLOv5(PAN-FPN)没有将注意力覆盖跌倒区域,而FFEM成功感知到了跌倒区域.

图5 特征图可视化分析Fig.5 Feature map visualization analysis
为了更加有说服力的体现AFEF-FPN的有效性,本文设计消融实验对影响因素进行分析,第1组实验是单独使用AFEF-FPN与原始网络的对比实验,第2组实验是在网络中单独使用CARAFE与原始上采样的对比实验,第3组实验是单独使用Alpha IoU Loss与原始的CIoU Loss进行对比实验,第4组实验是在模型中使用AFEF-FPN和CARAFE与单独使用CARAFE进行对比实验,第五组实验是使用AFEF-FPN和Alpha IoU Loss与单独使用Alpha IoU Loss进行对比实验,以mAP0.5、mAP0.5~0.95、Params(参数量)、Precision(准确率)作为评价指标,实验时保持参数一致,环境一致.具体实验结果如表3所示.

表3 消融实验结果表Table 3 Ablation experiment result table
通过1、6实验进行对比,可知AFEF-FPN给网络带来了1.27%的mAP指标提升,通过2、6实验进行对比,可知CARAFE给网络带来了0.17%的mAP指标提升.通过3、6实验进行对比,可知Alpha IoU Loss给网络带来了0.2%的mAP指标提升.通过2、4实验进行对比,可知AFEF-FPN给都使用CARAFE算子的网络带来了1.12%的mAP指标提升,通过3、5实验进行对比,可知AFEF-FPN给都使用Alpha IoU Loss的网络带来了1.14%的mAP指标提升.综上分析可知,AFEF-FPN是给网络带来提升的主要影响因素.在AFEF-FPN中,FFEM是最为主要且关键的模块,AFEF-FPN能够提高网络性能得益于FFEM,它可以提高网络的感受野并且能够捕捉到特征图上的跌倒区域的信息.其中,FFEM模块中的RFB模块,它是一由多个不同膨胀率的膨胀卷积组合而成.在多个摔倒人物重叠的场景下,它能通过间隔取卷积点的方式来减小人物互相遮挡的问题,尽量使每个卷积点都能够捕捉到同一个人的特征,因此在互相遮挡的场景下可以更加准确的捕捉摔倒人物的特征.而FFEM中的CA模块是一种轻量级注意力机制,它可以使模型能够关注到跌倒区域并且捕捉到跌倒特征.RFB与CA的结合可以让模型实现多重遮挡的跌倒检测,提高边界框回归的精度.
本文网络YOLOv5s(AFEF-FPN)取得了优于其它网络的效果,不仅仅体现在mAP的涨点上,如图6所示,上图为YOLOv5s(PAN-FPN),下图为本文网络,可以看出,在多个目标互相遮挡的场景下,本文网络的检测框定位相比于YOLOv5s(PAN-FPN)更加精准.特别在第2组图中,本文网络的每个检测框都精准检测到了目标,而YOLOv5s(PAN-FPN)出现了检测框不准确的情况.

图6 YOLOv5(PAN-FPN)和YOLOv5s(AFEF-FPN)效果对比(上图为PAN-FPN,下图为AFEF-FPN)Fig.6 YOLOv5(PAN-FPN)and YOLOv5s(AFEF-FPN)effect comparison(the picture above is PAN-FPN,the picture below is AFEF-FPN)
4 结束语
本文提出了一个新的特征增强融合模块FFEM,其中包含了RFB模块,1*1卷积和CA注意力模块.本文将ASFF算法引入YOLOv5网络模型中,同时将FFEM加入网络的FPN中,提出了一种新的网络YOLOv5s(AFEF-FPN);其中CA注意力模块提高了感兴趣区域的特征表示,RFB模块增大了感知空间,同时提高了在多个跌倒人物重叠时的特征提取能力,ASFF模块则进一步加强了多尺度的特征融合,提高了网络检测能力;然后本文使用基于全局语义信息的上采样算子CARAFE代替Nearest Upsample来建模全局上采样信息,使用Alpha IoU Loss代替CIoU Loss,有效的提高了遮挡场景下跌倒检测的精度.但是本文网络检测速度仍然低于一些轻量级检测模型,因此,接下来对于检测速度以及检测实时性还有待提升.后续的研究将从以下两个方面展开:一是采集更多场景下的跌倒图片,从而扩充数据集,使得训练出来的模型具备更强的泛化能力;二是进一步改进网络结构,减小模型参数,提高检测速度.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
