
全局通道注意力增强的毫米波图像目标检测*
2024-04-18 05:08:32蒋甜甜叶学义杨梦豪陈华华
电子技术应用 2024年3期
蒋甜甜,叶学义,李 刚,杨梦豪,陈华华
(杭州电子科技大学 通信工程学院,浙江 杭州 310018)
0 引言
人们对自身安全问题的持续关注,促进了在公共场所以及一些重点场所安检技术的发展。传统的安检技术包括X 射线探测器、金属探测器[1]以及人工检测[2],它们在人体健康和隐匿目标检测方面存在一定限制。由于毫米波辐射是非电离辐射[3],对衣物穿透性强[4],能够在不伤害人体情况下进行安全检查,因而毫米波安检技术越发受到关注;且随着成像技术和计算机视觉的飞速发展,毫米波安检技术逐渐与人工智能方法相结合。因为主动毫米波(Active Millimeter Wave,AMMW)[5]图像质量要高于被动毫米波(Passive Millimeter Wave,PMMW)[6],对AMMW 图像(包括阵列和线扫毫米波成像设备)的隐匿目标检测逐渐成为主流。
当前AMMW 图像隐匿目标检测已经进行了较为深入的研究,根据采用的方法不同,毫米波图像隐匿目标检测可以分为传统方法和深度学习方法[7]。用传统方法检测毫米波图像隐匿目标[8-9],虽然可以达到对目标有效检测,但模型泛化能力弱。随着深度学习在目标检测领域取得显著成果,采用深度卷积神经网络对毫米波图像隐匿目标检测逐渐增多。基于深度卷积神经网络目标检测方法主要有两种模型:基于区域提取两步(Regions with CNN features,R-CNN)模型和一步回归(You Only Look Once,YOLO)模型。在基于区域提取两步R-CNN 模型中,对毫米波图像隐匿目标检测算法研究大多采用Faster-RCNN[10],通过改进Faster-RCNN 解决小数据集问题以及提升对于小目标的检测[1,11-12],但实时性与YOLO模型相比具有明显劣势。为了提升检测效率,近年来采用YOLO 模型对毫米波图像隐匿目标检测逐渐增多,致力于在满足安检实时性的前提下,提高检测性能[13-15]。由于注意力机制可以加强与任务相关的信息关注,在增加少量参数情况下达到良好的检测结果,并且YOLO 模型不断改进,YOLOv5 与注意力机制相结合的目标检测方法在其他目标领域已经取得了显著优势[16-17]。
相较于YOLOv3[18]和YOLOv4[19],YOLOv5[20]具有更好的检测性能和优越的实时性。在YOLOv5 4 种模型中,YOLOv5s 参数量最少、实时性更强、模型更灵活。由于当毫米波图像中隐匿目标与背景纹理区分度较低时容易漏检,以及公共场所对安检实时性要求,选择YOLOv5s 作为毫米波图像隐匿目标检测的基本模型,构建并提出基于全局通道注意增强的毫米波图像目标检测模型,具体创新点如下:
(1)全局通道注意力增强器(Global Channel Attention Booster,GCAB),在坐标注意力(Coordinate Attention,CA)[21]位置方向上引入全局通道注意模块,生成GCAB,并与YOLOv5s 有效结合,提升对与背景纹理区分度较低的隐匿目标检测。
(2)重新聚类生成锚框,利用K-means++聚类算法[22]根据毫米波图像隐匿目标尺寸重新聚类生成新锚框,解决了原有锚框对与人体相对较小隐匿目标检测不适问题。
1 基于全局通道注意力增强检测模型
1.1 模型整体结构
基于全局通道注意增强的检测模型整体框架如图1所示,其中灰色方框为提出的GCAB 模块。模型主要包含3 部分:主干、颈部和头部。主干包含5 级特征层,除第一级特征层外,其余每级特征层皆由CBS 和C3 模块组成。CBS 模块由Conv、BN 和SiLU[23]构成,通过下采样,将语义信息由低级向高级转化;C3 借鉴了跨阶段区域网络(Cross Stage Partial Network,CSPNet)[24],由CBS、BottleNeck 和Contact 组成,主要用于特征的提取。颈部借鉴了聚合路径网络(Path Aggragation Network,PANet)[25],融合了主干网络的第3~5 级特征图,以获得更多的上下文信息。头部采用3 个检测头,分别用来检测大、中、小隐匿目标。模型在主干和颈部C3 模块之后加入GCAB模块,通过对上一级特征层的隐匿目标特征信息加强,有利于下一级特征层对隐匿目标特征提取。在主干和颈部连接处加入GCAB 模块,加强浅层细节。由于原检测部分对所有通道处理看似公平但不合理,因此在头部检测之前,利用GCAB 模块来加强重要通道特征权值。

图1 模型整体框架
1.2 全局通道注意力增强
通道数的增加导致通道间相互信息减少,而每个通道被看作是一个特征检测器,因而加强通道信息关注有利于检测目标。同时,位置信息也不可缺失。CA 注意力机制既能生成通道注意力,又能生成与方向相关的位置注意力。但CA 是在位置信息嵌入的基础上进行注意力生成的,减弱了全局通道注意力的生成。因此,提出在CA 与输入特征进行加权之前,加入全局通道特征注意,增强全局通道信息关注,生成GCAB 模块。
GCAB 模块包含CA 和全局通道特征注意两部分。算法流程图如图2 所示,其中,灰色方框表示全局通道特征注意部分,其余方框表示CA 部分。对于CA 部分,输入特征图Fin∈RC×H×W分别在X(X为特征图宽度方向)和Y(Y为特征图高度方向)方向上进行一维全局平均池化,定义池化后高度为h时输出特征图Zh(h)∈RC×1×1和宽度为w时输出特征图Zw(w)∈RC×1×1公式如下:

图2 GCAB 计算流程
其中,C、H和W分别为特征图的通道数、高度和宽度。Fin(h,i)和Fin(j,w)分别为输入Fin在高度为h时和宽度为w时的局部特征。
式(1)和式(2)分别在X和Y方向上生成的聚合特征图为Zw∈RC×1×W和Zh∈RC×H×1,然后Contact 拼接特征图Zw和Zh,经过Conv2d 的1×1 卷积将通道数减少为,从而减少计算量,再经过BN 归一化和非线性性激活,得到在X和Y方向特征图Z∈R(C/r)×1×(W+H):
其中,[,]是级联操作,F1是1×1 卷积操作,δ是非线性激活函数,r是减少率。
随后将Z按空间维度分解成X和Y方向上特征图fw∈R(C/r)×1×W和fh∈R(C/r)×H×1,再由1×1 的卷积恢复通道数为C,最后经过Sigmoid 激活函数分别得到对Y方向和X方向通道加强特征gh∈RC×H×1和gw∈RC×1×W:
其中,Fh和Fw为1×1 卷积操作,σ为Sigmoid 激活函数。
全局通道特征注意模块如图3 所示。将CA 在X和Y方向上生成的通道加强特征作为此模块输入。由于在X和Y方向上处理相同,选择只对其中一个方向作详细描述。以X方向上的处理为例,首先对在X方向上通道加强特征gw进行一维全局平均池化,得到特征图g∈RC×1×1:

图3 全局通道特征注意模块计算流程
再经过两个1×1 的卷积,先压缩通道数为原通道数的1/r,再恢复成原通道数,最后经过Sigmoid 激活函数得到以X方向为基础的全局通道加强特征权重xw∈RC×1×1:
其中,F1为改变通道数为C/r的卷积操作,F2为恢复通道数为C的卷积操作,r与CA 中减少率相同。
最后将在X方向上通道加强特征gw和以X方向为基础的全局通道加强特征权重xw相乘,得到在X方向上加强的全局通道特征权重X∈RC×1×W:
同理,得到在Y方向上加强的全局通道特征权重Y∈RC×H×1,最后将在X和Y方向上加强的全局通道特征权重X、Y和输入特征图Fin相乘,得到全局通道增强后特征图Fout∈RC×H×W:
1.3 锚框改进
在YOLOv5s 中,采用锚框拟合真值标签框,并根据锚框偏移量计算得到预测框,所以锚框尺寸选择是影响目标检测结果的一个因素。YOLOv5s 原始锚框是根据COCO 数据集[26]由K-means 算法[27]得到的,COCO 数据集中目标可以分成小尺寸(分辨率小于32×32)、中尺寸(分辨率大于32×32 且小于96×96)和大尺寸(分辨率大于96×96)3 种。而毫米波数据集中隐匿目标相对于人体较小,通常在COCO 数据集小中尺寸目标范围内。因此,采用YOLOv5s 原锚框不适合对毫米波隐匿目标检测。
为了提高YOLOv5s 回归盒的能力,采用K-means++聚类算法分别对阵列图像数据集和线扫图像数据集重新聚类生成新锚框,结果如表1 第一行和第二行所示,表1 第三行表示YOLOv5s 原始锚框。将表1 中前两行与第三行对比可以看出,用K-means++聚类算法对毫米波图像数据集聚类出新锚框尺寸在原始锚框检测小中目标范围内,进一步验证了毫米波数据集中隐匿目标尺寸处于COCO 数据集小中尺寸目标范围以及原始锚框不适合对毫米波数据集隐匿目标检测。

表1 K-means++聚类新锚框尺寸与原锚框尺寸对比结果 (px)
2 相关实验
2.1 数据集准备
为了验证本文方法对不同成像设备的毫米波数据集中隐匿目标的检测能力,实验采用两种主动毫米波数据集:阵列图像数据集和线扫图像数据集(分别来自目前仅有的两种实际应用的主动毫米波图像采集设备)。为了得到更好的模型性能,选择训练集、验证集和测试集比例为8:1:1(即整个数据集中训练集占80%、验证集占10%、测试集占10%)。
阵列图像数据集中每个模特通过阵列设备扫描产生正面和背面各一张图像,图像分辨率为1 024×2 048,如图4 所示,实验选取24 700 张图像,以正面或背面单张图像划分训练集、验证集和测试集。

图4 阵列图像数据集
线扫图像数据集中每个模特由线扫设备旋转扫描产生正面和背面各9 张不同角度的图像,图像分辨率为400×762,如图5 所示,图中方框为目标真值框,其中(a)为模特正面的顺时针成像9 张图,(b)为模特背面的逆时针成像9 张图。实验选取38 240 张图像并将正面9 张图像和背面9 张图像各合为一组,然后再划分训练集、验证集和测试集。
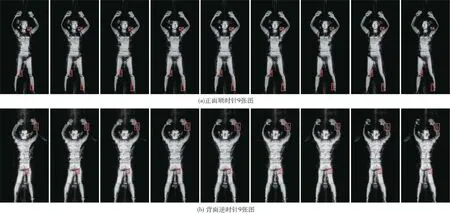
图5 线扫图像数据集
2.2 实验设置
实验采用训练轮次为180,输入图片大小在训练中调整为640 px×640 px,批次大小为32,优化器采用随机梯度下降法。在实验中所用评估参数为精度(P)、召回率(R)和平均精度(mAP)。P表示在所有预测为真的时候,正确预测标签所占的比例。R表示预测为真当中的正确预测占所有真实标签的比例。AP 表示在不同置信度阈值下精度和召回率围成的面积,mAP 表示所有类别平均的平均精度,用来判断模型优劣。由于对毫米波图像隐匿目标检测时,不需要更精确的轮廓位置,当预测框和目标框面积的交并比(Intersection over Union,IOU)为0.5 时便判定检测到目标,因而评价标准采用IOU=0.5 时指标。
2.3 阵列图像数据集相关实验
2.3.1 对比实验
为了验证本文方法有效性,将其与主流检测模型在阵列毫米波图像数据集上做对比实验,包括Faster RCNN、YOLOv3、YOLOv4、YOLOV5s、YOLOv5m、YOLOv6[28]、YOLOv7[29]、YOLOv8[30]。对比的性能指标有P、R、mAP@.5、模型参数量和平均单张图像推理时间(表示图像归一化后输入模型到得到输出结果的时间,不包括非最大抑制比处理时间),实验结果如表2 所示。
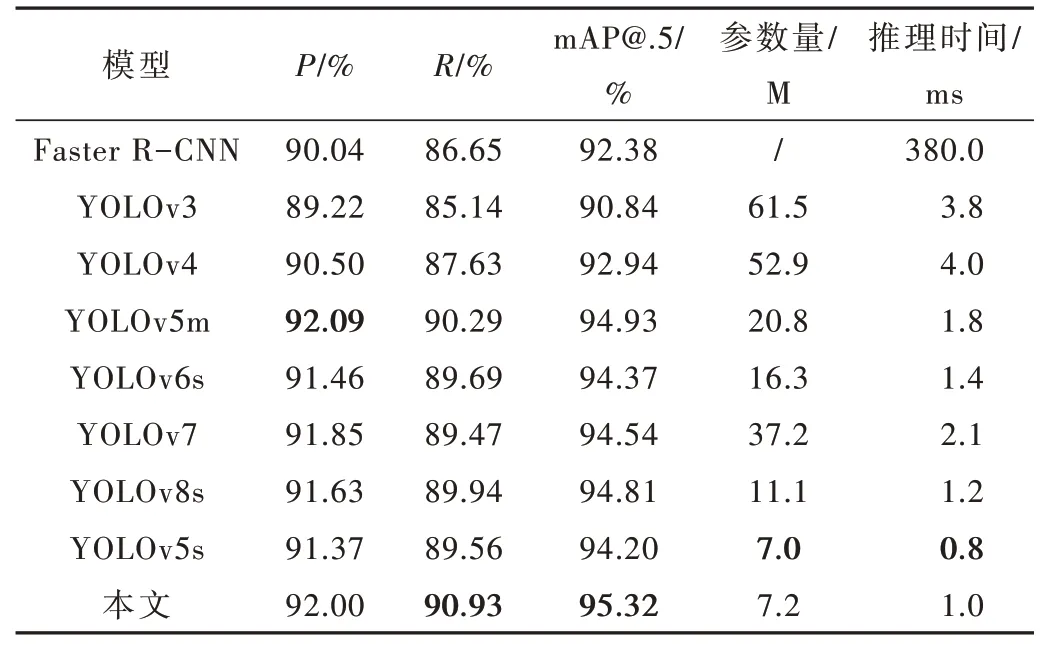
表2 不同检测模型实验对比结果
由表2 可得,本文方法与其他主流检测模型相比,R和mAP@.5 均为最优,比最差的YOLOv3 分别增加了5.79% 和4.48%,比YOLOv5m 分别增加了0.64% 和0.39%。在参数量和单张图像推理时间上比YOLOv3 分别少54.3 M(M 表示百万)和2.8 ms,比YOLOv5m 少13.6 M 和0.8 ms。与后续的YOLOv6s、YOLOv7 和YOLOv8s 相比,本文方法在P、R和mAP@.5 上仍优异。相比于原YOLOv5s,本文方法在增加0.2 M 参数量和0.2 ms的单张图像推理时间基础上,P、R和mAP@.5 分别增加了0.63%、1.37%和1.12%。上述结果表明,本文方法比原YOLOv5s 增加了隐匿目标检测数量,减少了误检数量且模型性能最好;在单张图像推理时间上与现有主流检测模型相比,实时性依然出色。
实验结果在毫米波图像上表现如图6 所示,其中行表示不同样本,列分别表示标签图、YOLOv5s 检测结果图、K-mean++聚类生成新锚框后检测结果图以及采用本文方法所得检测结果图。在标签图上的方框表示隐匿目标的真值框,在其余图上方框表示隐匿目标检测框。从样本1 到样本4 检测结果可以看出,本文方法在原YOLOv5s 检测基础上增加了隐匿目标检测,其中包含了与背景纹理区分较低的隐匿目标。
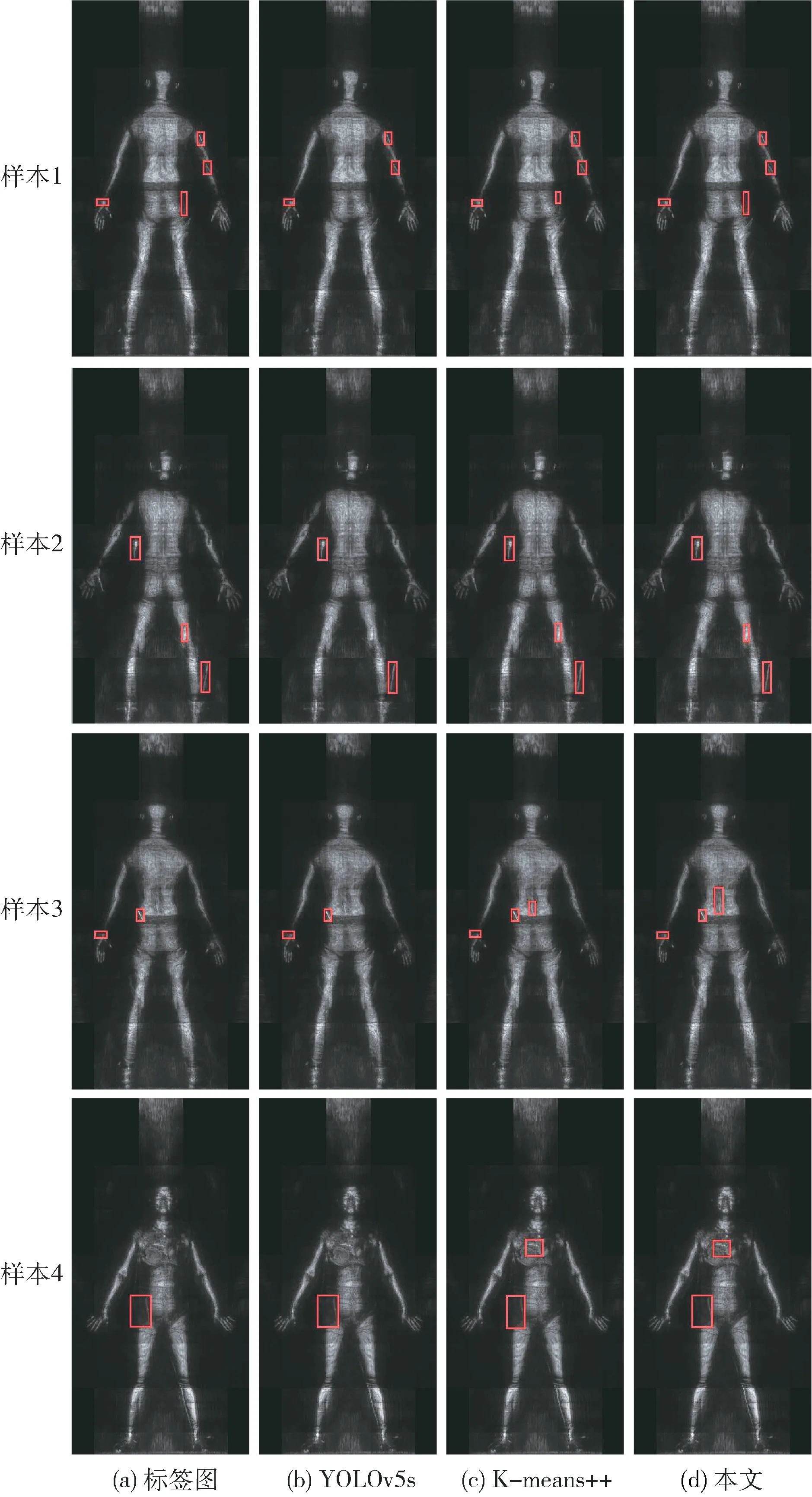
图6 阵列图像数据集检测结果
2.3.2 消融实验
为了验证K-means++聚类算法和GCAB 模块有效性,在YOLOv5s 中融合CA 模块、改进后GCAB 模块、Kmeans++聚类算法以及GCAB模块+K-means++聚类算法进行消融实验,实验结果如表3所示(加粗字体为每列最优值)。
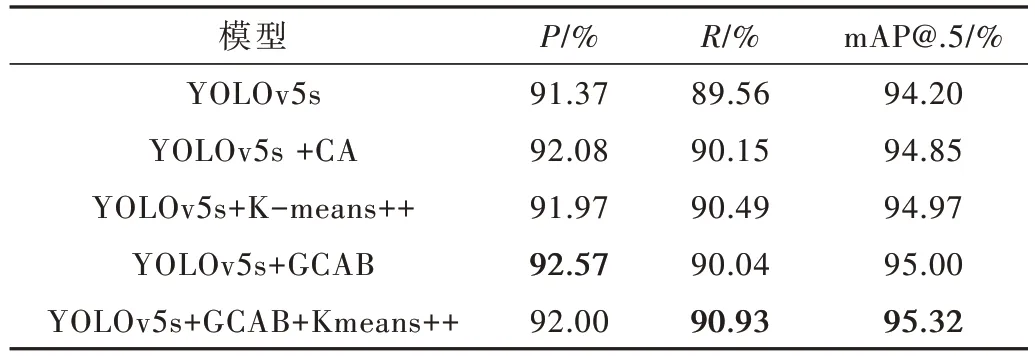
表3 消融实验对比结果
由表3 可知,改进后GCAB 模块的检测性能优于CA 模块,P和mAP@.5 分别增加了0.49%和0.15%;且YOLOv5s 单独融合K-means++聚类算法或GCAB 模块后检测性能得到提升,与之相比,同时融合GCAB 模块和K-means++聚类算法后检测性能得到进一步提升,P、R和mAP@.5 比原YOLOv5s 分别增加了0.63%、1.37% 和1.12%。结合图6 和表3 结果可知,融合Kmeans++聚类算法后,样本1 和样本2 增加了臀部和大腿处隐匿目标检测;在此基础上融合GCAB 模块后,在样本1 和样本2 上的检测结果和融合K-means++聚类算法时检测结果相同,同时增加了样本3 和样本4 在后腰和胸前与背景纹理区分较低的隐匿目标检测。说明GCAB 模块增加了对与背景区分度较低的隐匿目标检测,K-means++聚类算法生成新锚框后增加了对隐匿目标检测,与YOLOv5s 原锚框相比更适合对与人体相对较小的隐匿目标检测。
2.4 线扫图像数据集相关实验
在线扫图像数据集上,分别采用本文方法与现有主流检测模型作对比,包括YOLOv3、YOLOv4、YOLOv5s、YOLOv5m、YOLOv6s、YOLOv7、YOLOv8s。对比性能指标有P、R、mAP@.5、模型参数量和平均单张图像推理时间,实验结果如表4 所示(加粗字体为每列最优值)。
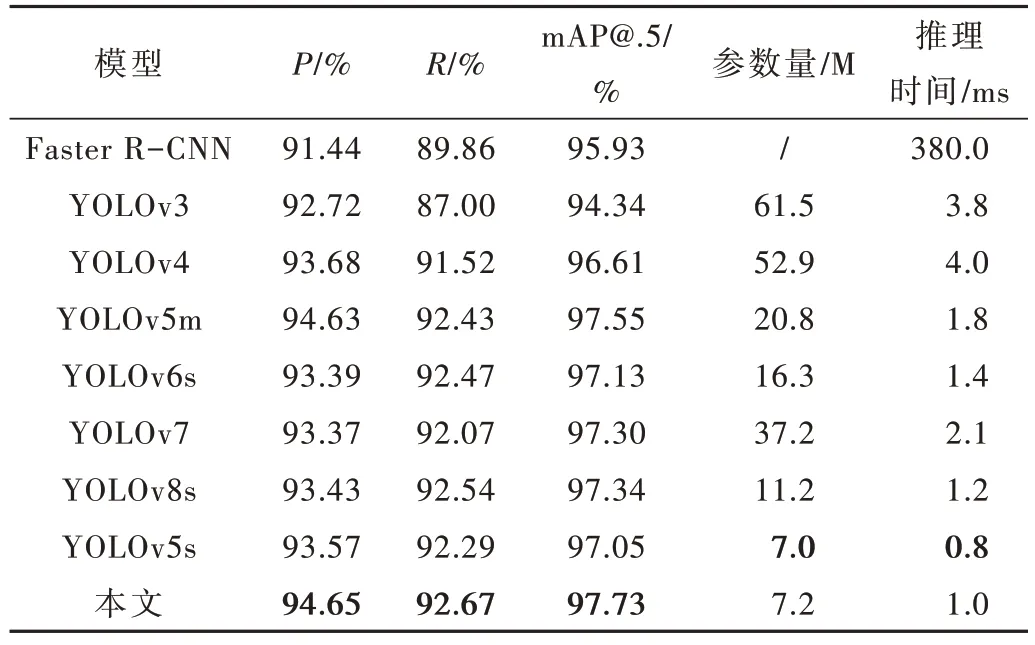
表4 不同模型实验对比结果
由表4 可得,本文方法在P、R和mAP@.5 均优于其他主流检测模型,比最差的YOLOv3 分别增加了1.93%、5.67%和3.39%,比YOLOv5m 分别增加了0.02%、0.24% 和0.18%。在参数量和单张图像推理时间上比YOLOv3 分别少54.3 M 和2.8 ms,比YOLOv5m 少13.6 M 和0.8 ms。与后续YOLOv6s、YOLOv7 以及YOLOv8s 相比,本文方法所得结果仍优异。相比于原YOLOv5s,本文方法在增加0.2 M 参数量和0.2 ms 的单张图像推理时间基础上,P、R和mAP@.5 分别增加了1.08%、0.38%和0.68%。上述结果表明,本文方法比原YOLOv5s 增加了隐匿目标检测数量,减少了误检数量且模型性能最好;在单张图像推理时间上与现有主流检测模型相比,实时性依然出色。
实验结果在毫米波图像上表现如图7 所示,其中行表示不同样本,列分别表示标签图、YOLOv5s 检测结果图以及采用本文方法所得检测结果图。在标签图上的方框表示隐匿目标的真值框,其余图上方框表示隐匿目标检测框。从样本1 到样本3 检测结果可以看出,本文方法在原YOLOv5s 检测基础上,增加了在人体手腕、胳膊肘和腋下部位与背景纹理区分度较低的隐匿目标检测。
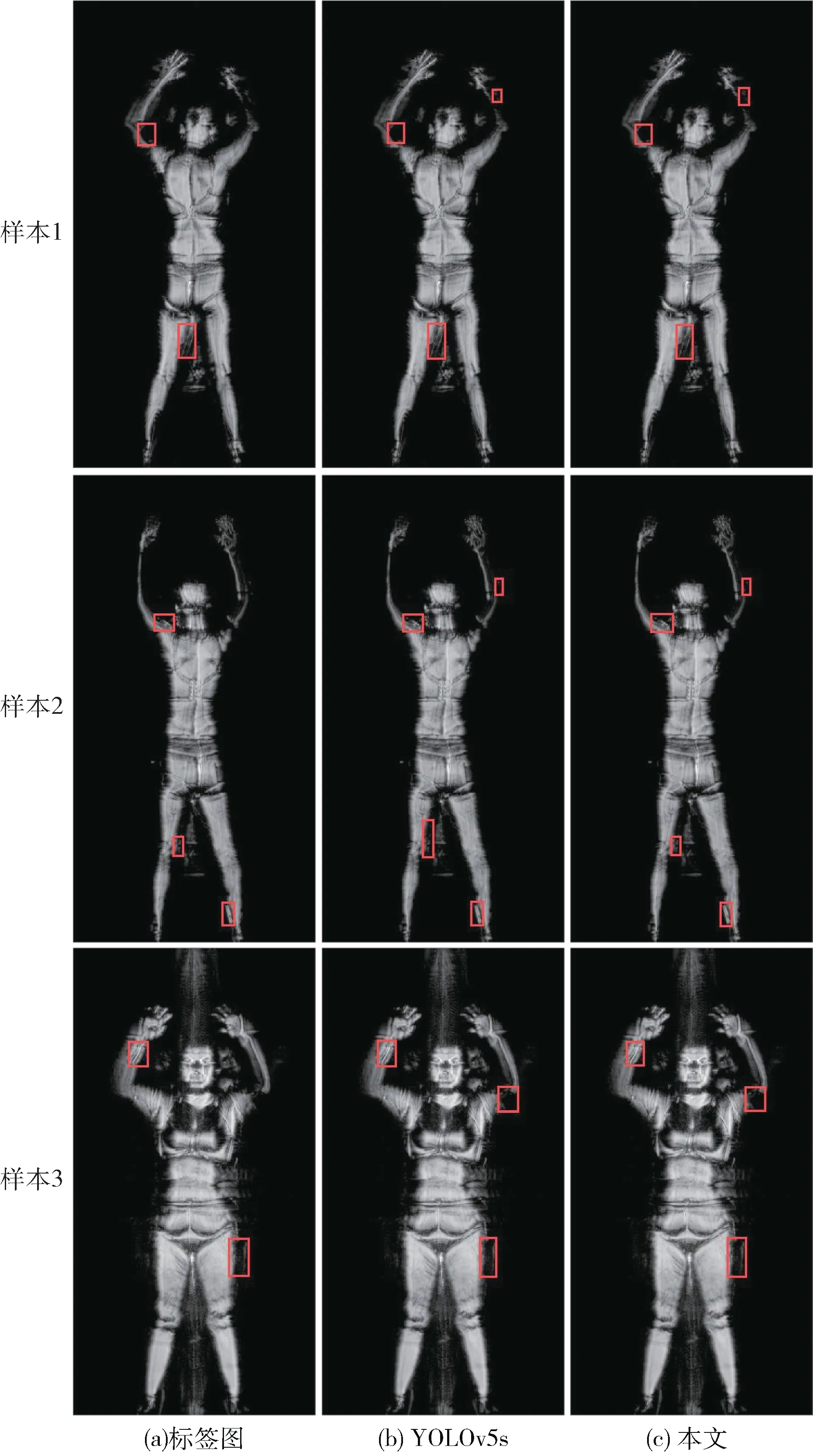
图7 线扫图像数据集检测结果
3 结论
本文将YOLOv5s 模型与GCAB 和K-means++聚类算法相结合,提出了基于全局通道注意力增强毫米波图像目标检测方法。其中,通过GCAB 提升与背景纹理区分度较小时隐匿目标的检测能力,并利用K-means++聚类算法根据毫米波图像数据集重新聚类生成更适合对与人体相对较小隐匿目标检测的新锚框。实验在阵列图像数据集和线扫图像数据集上的结果表明,与现有主流检测模型相比较,本文方法在增加少量参数的基础上,精度和召回率上表现较好且mAP@.5 最高,模型性能最好。平均单张图像推理时间达到1 ms,与现有主流方法相比,实时性仍然优异。由上述结果可知,本文方法在满足实时性的情况下,提升了检测性能。
猜你喜欢
信号处理(2022年11期)2022-12-26 13:22:06
计算机与生活(2022年11期)2022-11-15 16:17:48
数学物理学报(2022年4期)2022-08-22 04:07:12
计算机工程与科学(2022年8期)2022-08-20 01:39:22
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
数学物理学报(2022年2期)2022-04-26 14:08:04
金桥(2018年4期)2018-09-26 02:24:54
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
