
Flash 阵列无效块管理
2024-04-18 05:08:38焦新泉朱振麟
电子技术应用 2024年3期
焦新泉,朱振麟
(1.中北大学 仪器科学与动态测试教育部重点实验室,山西 太原 030051;2.中北大学 电子测试技术国家重点实验室,山西 太原 030051)
0 引言
近年来伴随着航空航天领域的不断发展,获取到的空间信息的种类也越来越多,数据量急剧增加,对数据存储装置存储速度和可靠性带来了更大的挑战。NAND Flash 具有体积小、容量大、成本低、可多次擦除等优点,在数据存储领域得到广泛应用。近年来,大多数存储装置采用多片Flash 组成阵列,并采用流水线的存储机制来实现高速大容量的数据存储[1]。其中镁光半导体公司Luca Nubile 等人提出了一种针对Flash 存储阵列的多线程控制算法,该算法对系统的逻辑开销、存储速度和容量等性能就行了优化[2];俄罗斯的Puryga 等人研发的汤姆逊散射诊断数据采集系统同样包含多片存储单元,它允许以5 GHz 采样率采集八通道数据[3];但由于NAND Flash 生产过程中工艺等问题,每片Flash 都不可避免存在无效块,而且无效块数量不定,地址随机[4]。这对Flash 阵列数据存储的可靠性带来了一定的影响。若采用单片Flash 坏块的管理方法,在往Flash 中存储数据之前对每一块进行扫描,并生成坏块信息表,这种方法应用在Flash 阵列的坏块检测中时,会极大地限制存储速度,占用过多的内部资源。
本文对于Flash 固有坏块提出了基于整合块的坏块管理方法和基于EEPROM 查找表的坏块管理方法。对于操作过程中出现的突发坏块,提出一种基于页跳过和页替换的管理方法。
1 Flash 阵列
Flash 在存储过程中要完成页编程,这对持续高速存储有很大的影响。通道内流水线循环操作,避开了Flash 页编程对存储速度的约束,可以实现持续存储的目的。Flash 阵列通常为m×n架构。即m个通道并行存储,每个通道内有n片Flash 进行流水线循环操作,理论上存储速度是单片Flash 的m倍。如图1 所示,本文基于该理念设计一种满足设计要求的6×2 Flash 阵列架构。
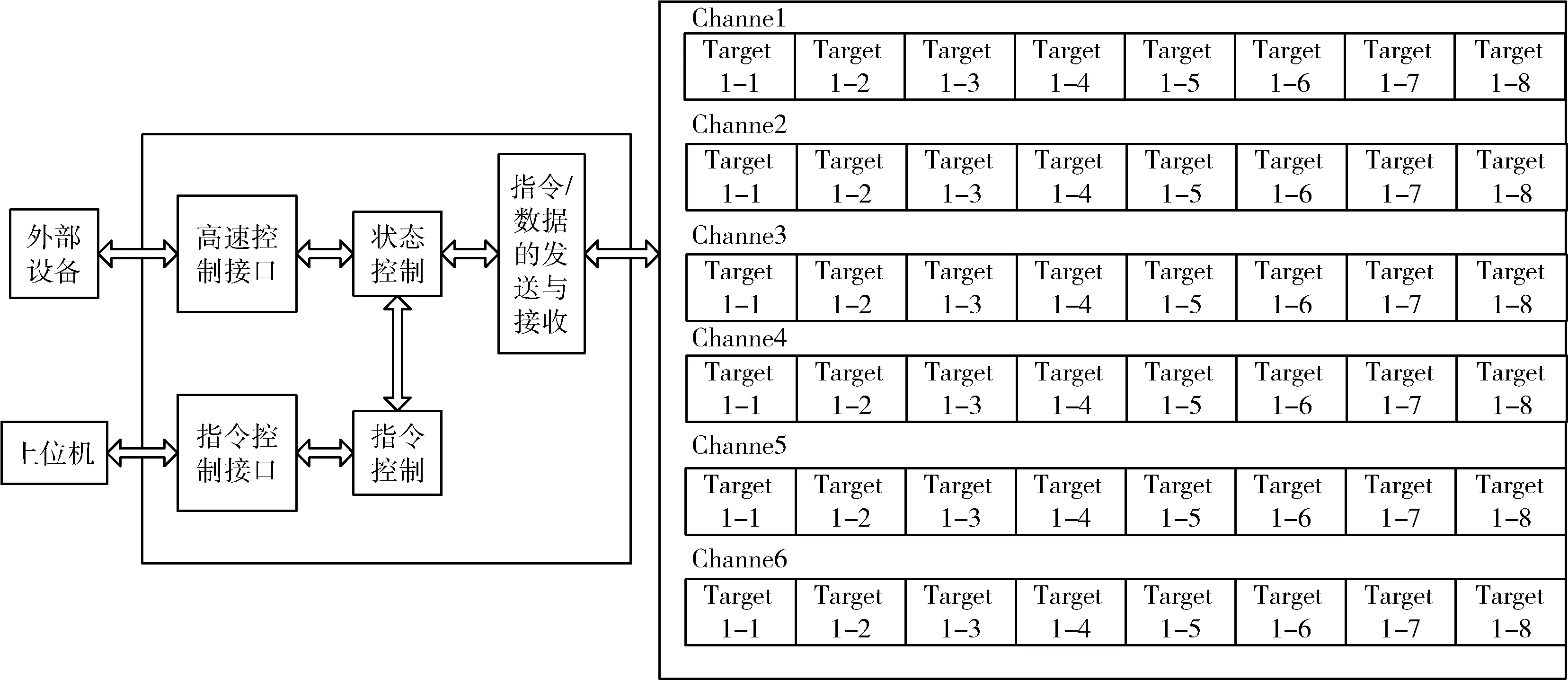
图1 Flash 阵列
本文选用的Flash 是镁光MT29F256G08A,存储容量为32 GB。每个通道内有2 片Flash,每片Flash 内部有4个Target,因此每个通道内有8 个Target,也可以认为每个通道内有8 个Flash。NAND Flash 芯片与FPGA 主控芯片之间通过高性能的异步I/O 口进行通信,通道内的8个Flash 共用命令锁存使能、地址锁存使能、写使能、读使能4 个控制使能端口,并通过CE、R/B 端口对通道内的8 个Flash 进行区分。其中WP 为写保护端口,当端口输入有效时,存储的内容被写保护,只能进行读取。当端口输入为无效或者悬空时,NAND Flash 允许进行正常的读/写操作,单通道Flash 控制接口如图2 所示。

图2 单通道Flash 控制接口示意图
2 固有坏块管理
Flash 存储数据的单元为胞元,每个胞元内存储1 bit数据[5]。该Flash 芯片内部有4 个Target,每个Target 内部有2 个LUN,每个LUN 由2 个Plane 组成,一个Plane 又由2 048 个块组成,每个块由128 页组成,每个页的存储容量为8 KB+448 B。由于芯片工艺等问题,芯片在生产出来时,就有块中存在不能进行擦除和修复的位错误,这些块就被称为固有坏块。这些固有坏块的信息在芯片出厂时厂商就会标注出来,在对芯片进行使用之前,对所有的存储块进行遍历扫描并建立坏块表。但是对Flash 阵列仍采用单片Flash 遍历扫描的方式,这势必对存储速度带来影响,因此需要提出新的坏块管理方法。
2.1 基于整合块的坏块管理方法
通道内8 个Flash 中每一个都由8 192 个块组成,块地址从0000h 到1FFFh。基于每个Flash 中相同位置块的块地址相同,因此可以把相同位置的块看做一个整合块,整合块划分方式如图3 所示。只有当整合块内的8个子块全部为好块时,该整合块才被视为有效整合块。只要整合块内有一个子块为坏块,那么这个整合块将被视为无效整合块。

图3 整合块划分方式
在FPGA 内部开辟RAM 空间用来存放无效整合块的地址,通过查阅Flash 的芯片手册,每个Flash 内部最多有80 个无效块,无效整合块最大数量就是当每个Flash 内80 个无效块地址都不一样,这时最大无效整合块数量就是640 个。介于每个Flash 内部的块地址是从0000h 到1FFFh,为了节省FPGA 内部资源,选取地址位宽为13。因此需要在FPGA 内开辟的RAM 空间为最大无效块数量×地址位宽×通道数量=(640×13×6)/8=6.1 KB。
将无效整合块的块地址存储在RAM 空间内,每一次读写操作前都要将操作的整合块地址与RAM 空间内无效整合块地址进行预匹配,预匹配流程如图4 所示。如果要操作地址小于RAM 空间内第一个无效整合块的地址,那么就可以对该整合块内的所有子块进行读写操作,操作整合块地址加1。当要操作的整合块地址和RAM 空间内存储的无效整合块地址相同时,表示该操作整合块为无效整合块,不能对其进行读写操作,操作整合块地址加1,并从RAM 空间中读取下一个无效整合块的地址。重复上述的操作,直至对所有的整合块操作完成。
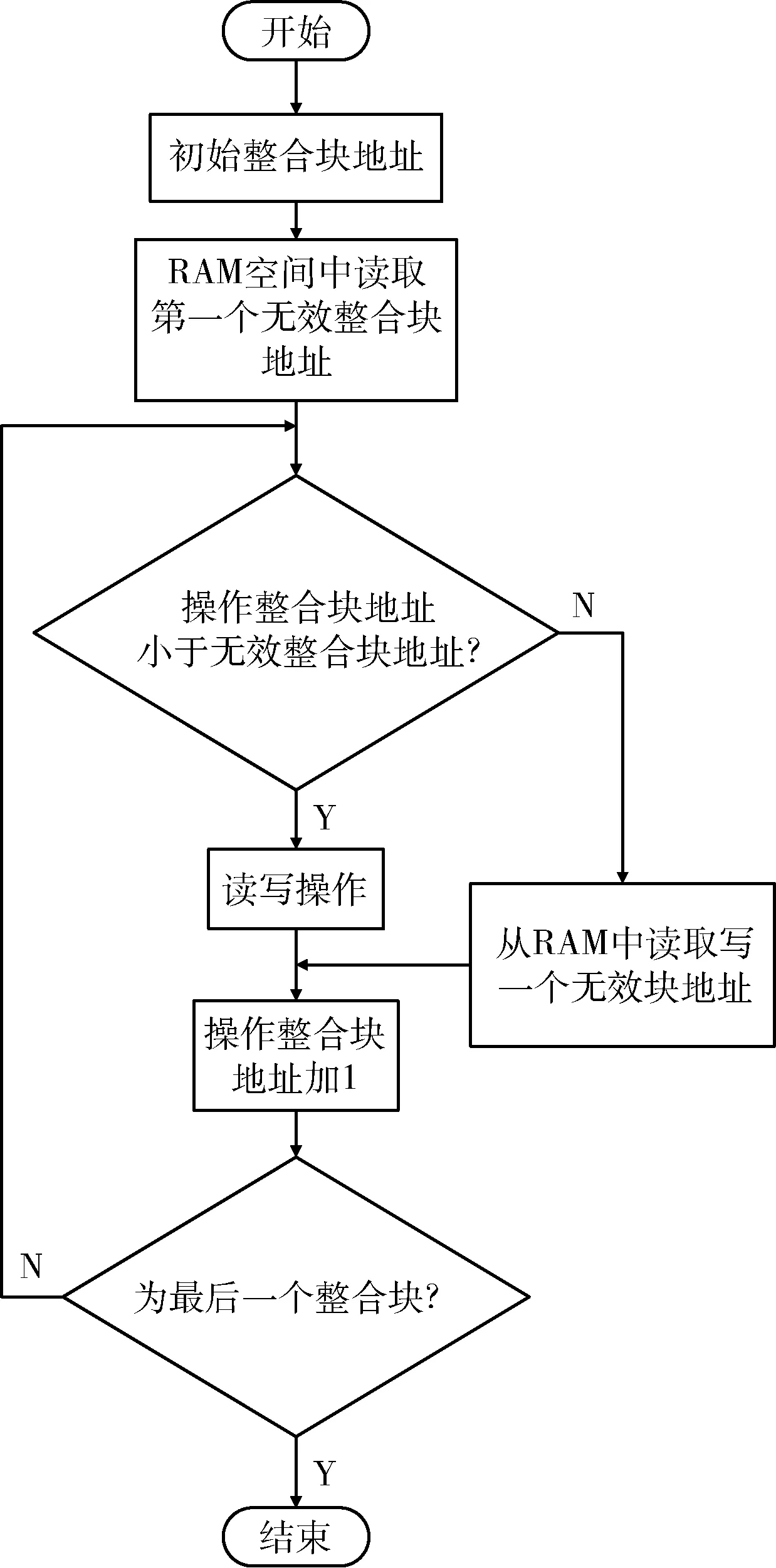
图4 无效整合块预匹配流程图
该方法是建立在对单个通道的无效块管理基础上,便于对Flash 阵列的并行扩展。一个整合块上的8 个子块进行流水线循环操作,通过通道内的片选端口对8 个子块进行区分,在程序上实现简单。但是该方法不足之处就在于当一个无效整合块中只有一个坏块时,其余7个好块也不能进行正常的读写操作,降低了存储空间的利用率。
2.2 基于EEPROM 查找表的坏块管理方法
上述方法对Flash 内部存储空间的利用率不高,为了减少空间的浪费,本文提出在每一通道后加一片EEPROM 芯片。在上述整合块的基础上,以整合块的地址作为EEPROM 查找表的地址,存储每个子块的具体信息。对通道内的每个子块进行遍历扫描,并将相应块的状态信息写入对应EEPROM 表中,每一子块用8 位二进制对其进行编码,FFh 表示该块为好块,80h 表示该块为坏块。如图5 所示,Flash 逻辑块的地址一一对应在EEPROM 地址中,这样就可以确保EEPROM 中存放的信息就是相应地址块的信息。

图5 子块状态映射表
无效块检测以单个通道为单位,检测流程如图6 所示。在EEPROM 内开辟一个容量大小为(8K×8×8)/8=64 KB 的空间。在第一次编程时,通过对每一子块第一页和第二页的最后一个字节进行读取,若读取到的数据为00h,则在该块对应的EEPROM 表中写入80h,否则就在EEPROM 对应表中写入FFh,子块地址加1。重复上述操作,将整合块内所有的子块检测完毕后,整合块地址加1,进行下一个整合块的检测,直至最后一个整合块。在EEPROM 表创建完成之后,需要设计读写操作与坏块地址的预匹配机制。对于数据写入来说,首先从EEPROM 表中读取整合块地址对应的8 个子块状态信息,如果为80h 则跳过该块,将数据写入下一个好块。通过这种方法可以实现对Flash 存储空间的最大化利用,基于EEPROM 掉电非易失性,在第一次编程操作时,就将所有块的状态信息存储在EEPROM 表中,避免了每次上电后对整合块中子块的遍历扫描。但是由于每一个Flash 内部的坏块数量和位置不同,实现一个整合块内8 个子块流水线写入操作就变得复杂,且由于EEPROM 的操作速度不如FPGA 内部RAM 资源操作速度快,对存储速度有一定的影响。

图6 检测流程
3 突发坏块管理方法
Flash 的擦除次数也是有限的,NAND Flash 在编程和操作过程中也会出现一些坏块,这种坏块被称为突发坏块。对于突发坏块,传统方法是将已经写入坏块的数据重新读出来存储在缓存区,然后再写入下一个好块中。然而当遇到突发坏块时,只有最后一页数据写入失败,之前页写入的数据也会被舍弃掉。这种方法会降低数据的写入速度,且对Flash 存储资源造成浪费,传统方法流程如图7 所示。
本文提出在EEPROM 表基础上设计基于页跳过和页替换的管理方法,在擦除过程中出现坏块时,FPGA 就将该块对应EEPROM 位置写入80h。在写入数据过程中出现坏块,就将坏掉页的页地址(00h~7Fh)写入该页所属块对应EEPROM 位置,并将坏掉页的数据重新写入下一好块中,保留了已经成功写入的数据。基于页跳过和页替换管理方法写入数据流程如图8 所示。
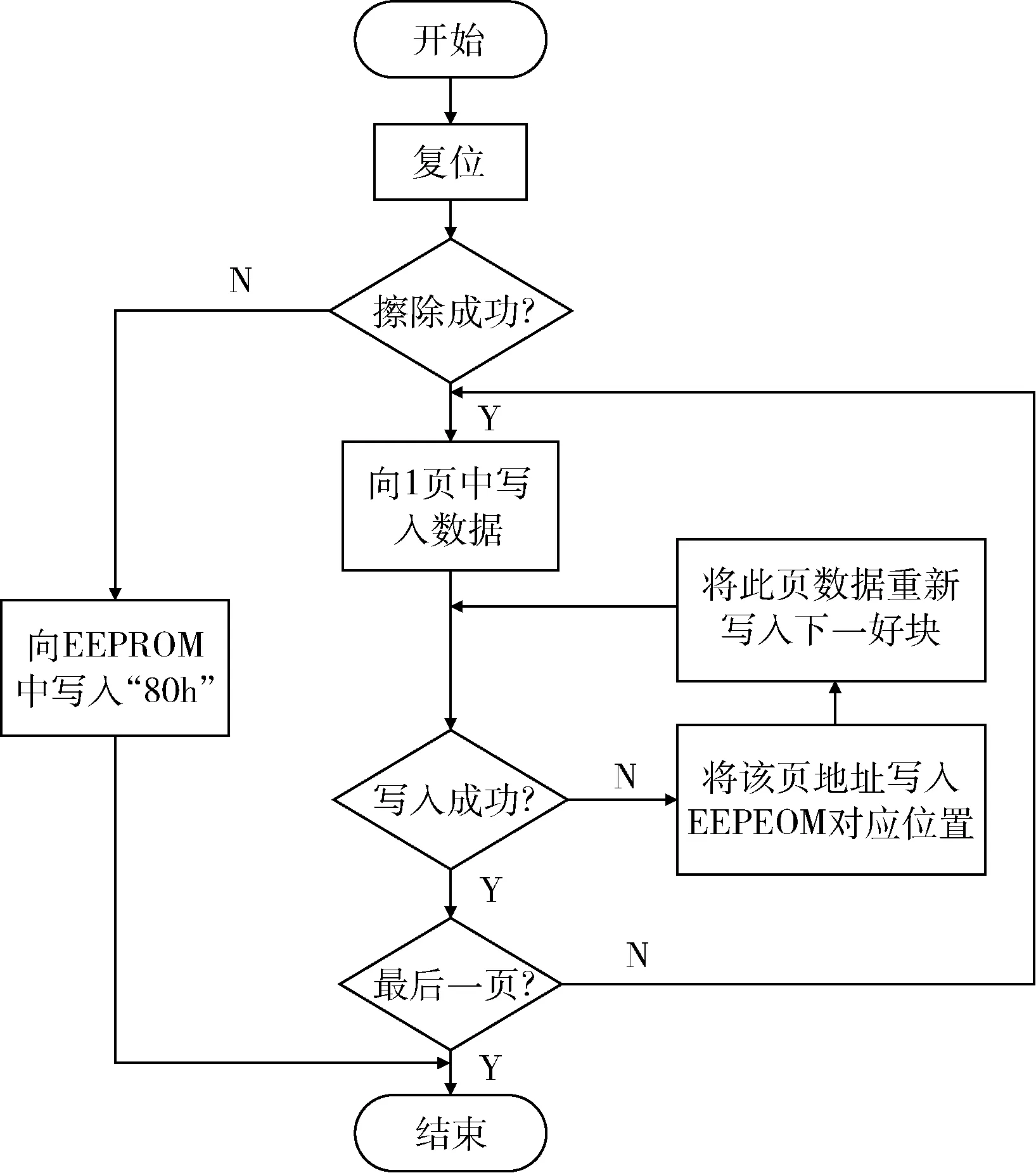
图8 写入数据流程
在读取数据时,FPGA 首先读取EEPROM 表中对应块的状态信息。如果为FFh,则表示该块已成功写入数据,可以将数据读出;如果为80h,则表示该块为全部坏块,不能对该块进行读取操作;如果为页地址(00h~7Fh),则读取该页地址之前的所有数据。读取数据流程如图9 所示。
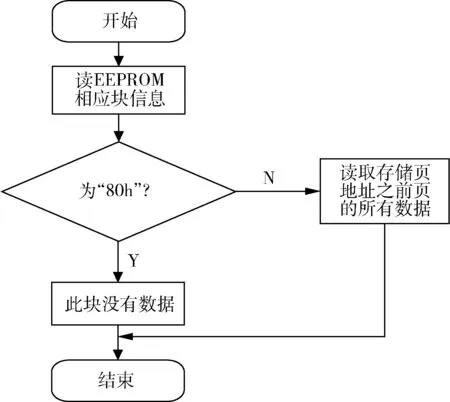
图9 读取数据流程
4 验证与分析
4.1 固有坏块存储空间利用率分析
基于整合块的坏块管理方法对Flash 存储空间的利用率取决于单片Flash 内部最大无效块数量和通道内Flash 的数量。每个Flash 内部有8 192 个块,每个Flash最大无效块数量为80。整合块内由8 个Flash 构成,则通道内最大无效整合块数量为640 块。浪费的存储空间为640 MB×7=4.375 GB,本设计单通的存储容量为4 GB×8=32 GB,最大损失容量比例为13.67%。
基于EEPROM 表的坏块管理方法由于是对通道内Flash 中每一块状态信息的存储,因此对Flash 存储空间的利用率最大可以达到100%。
4.2 突发坏块管理测试
本次测试选用的主控芯片是由Xilinx 公司生产的XC7K325T-2FFG900I,基于NAND Flash 阵列存储,通过上位机不断地写入32 GB的递增数。控制频率为125 MHz,为了验证突发坏块的管理机制,通过修改EEPROM 表中存储块的状态信息,人为在块中加入不同位置的坏掉页。通过比较传统方法和改进方法写入一块数据的时间和平均写入速度,来验证改进方法是否可行,经过多次测试后的结果如表1、表2 所示。
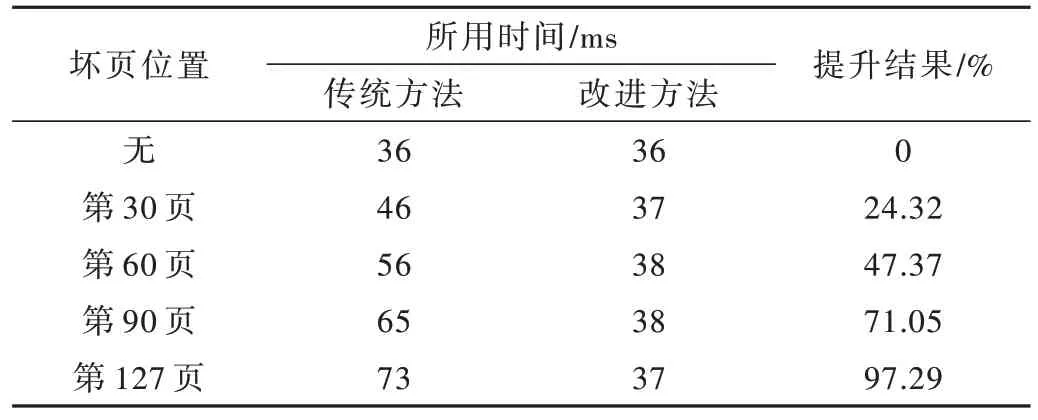
表1 写入1 块数据所用时间
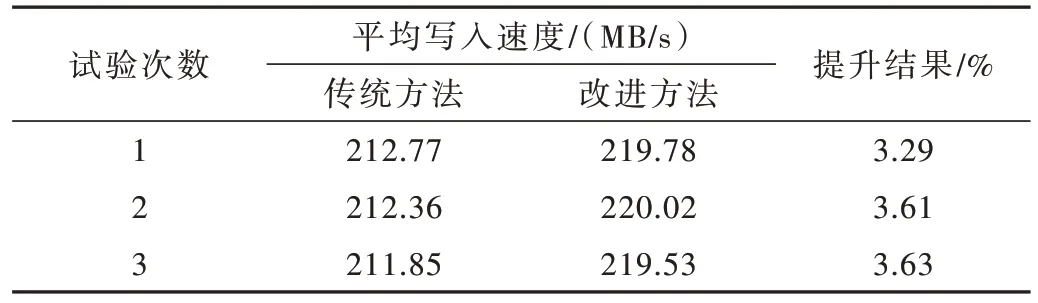
表2 平均写入速度测试结果
从表1、表2 的数据对比中可以看出,当块中无坏掉页时,改进方法与传统方法写入速度没有提升。当坏掉页的位置越靠后时,改进方法与传统方法相比提升就越大。原因是对于传统方法来说,当出现坏掉页时,就要将该页之前所有页重新写入下一块,坏掉页位置越靠后,需要重新写入的数据就越多。而对于改进方法只需要将坏掉页的数据重新写入下一块,保留了之前成功写入的数据,因此对写入速度无明显影响。
通过上位机对存储的数据进行回读,回读的数据经过校验后无误码、无丢帧,数据校验结果如图10 所示,经过多次测试表明数据的可靠性得到了保证。

图10 回读数据校验结果
5 结论
本文提出两种固有坏块检测和识别的方法,在实际的工程应用中有一定的参考价值。两种方法在存储速度和存储空间利用方面各有考量。基于整合块的坏块管理方法适合于对存储速度要求较高,FPGA 内部资源丰富的场合。而对于基于EEPROM 表的坏块管理方法适用于对存储速度要求不高、内部资源紧缺的场合。针对突发坏块提出的基于页跳过和页替换的管理方法,保证了在出现坏页时写入速度不会大幅度下降,且成功应用在具体实践中。
猜你喜欢
电脑知识与技术(2024年12期)2024-06-16 05:03:12
电脑知识与技术(2024年10期)2024-06-01 05:59:06
智能计算机与应用(2021年6期)2021-12-17 00:56:36
现代计算机(2021年36期)2021-03-14 00:50:40
综艺报(2020年21期)2020-11-30 08:36:49
电脑爱好者(2019年17期)2019-10-30 03:34:48
计算机应用(2018年12期)2019-01-07 12:16:36
发明与创新(2016年23期)2016-10-13 02:16:14
湖北工业大学学报(2016年5期)2016-02-27 13:14:51
河南科技(2014年10期)2014-02-27 14:09:18
