
动态数据流驱动的再制造拆解工艺知识图谱构建方法
2024-04-10 12:59江志刚代明仁
计算机集成制造系统 2024年3期
江志刚,谢 彬,朱 硕 ,张 华,鄢 威,代明仁
(1. 武汉科技大学 冶金装备及其控制教育部重点实验室,湖北 武汉 430081;2. 武汉科技大学 机械传动与制造工程湖北省重点实验室,湖北 武汉 430081;3.武汉科技大学 绿色制造工程研究院,湖北 武汉 430081;4. 谷城万利铸造有限公司,湖北 襄阳 441705)
0 引言
再制造拆解作为再制造工艺的首要步骤,是按照一定拆解工艺将废旧产品及其部件分解成全部零部件的过程,是实现大批量废旧产品循环利用的关键手段[1]。不同于新品,再制造拆解针对的是已完成一次服役周期且可能存在某种缺陷或损伤的废旧零部件,而废旧零部件的内部结构、损伤特征等存在较大差异,需要频繁地对拆解工艺进行调整,避免工艺质量波动大而造成零部件损坏,甚至无法进行再制造。拆解工艺数据作为表达工艺知识的载体,能够直观地揭示拆解工艺的动态变化过程,对于提高废旧零部件拆解效率和质量稳定性具有重要作用[2]。然而,由于废旧零部件拆解特征的特殊性,拆解过程中始终伴随着工艺数据的迭代更新,难以从数据中提炼出个性化的知识形式。因此,如何将高度变化的拆解工艺数据转化为有组织的、可重用的且支持更新的知识,是当前实现规模化再制造的关键瓶颈之一。
关于将拆解工艺数据转化为知识,属于工艺知识建模的一种。目前,众多学者针对工艺知识建模相关问题展开了广泛研究,相关技术包括面向对象建模[3-4]、基于图论建模[5-6]、基于Petri网建模[7-8]及基于本体建模[9-10]等。面向对象建模方法具有抽象性、稳定性和可重用性特点,但缺乏结构化的知识描述机制,无法满足多源异构系统间的互操作性要求。基于图论建模方法主要关注于零部件间的接触特征、几何约束及拆解优先级等信息,但未能表述其他拆解知识及其语义关系。基于Petri网建模方法处理大规模复杂系统时存在可读性差等问题,且难以表征知识的动态特征。基于本体建模方法能够表达知识的复杂关系,并利用特定语言进行异构系统间的交互操作,但其并不等同于知识化表征。例如ZHU等[11]针对废旧产品不确定性特征,构建了基于本体的再制造拆解知识系统,以支持拆解序列的生成。CHEN等[12]通过本体语义模型集成相关拆解知识,并结合基于案例(Case-Based Reasoning,CBR)和基于规则(Rule-Based Reasoning,RBR)推理技术实现机电产品拆解过程的自动化决策。上述研究中缺乏对拆解工艺数据之间语义关系的表达及动态时序特征的描述,所表达的信息相对固化且粒度大,进而难以从中提取出个性化的拆解工艺知识。
在再制造拆解过程中获取并利用知识辅助决策,发展认知学习能力,已然成为再制造拆解的核心需求,而知识图谱的诞生为满足这一需求提供了成熟条件。知识图谱作为一种结构化的语义网络,以“实体-关系-实体”或“实体-属性-值”的形式对知识进行组织,具有能够处理复杂语义关系数据的特点[13-14]。HEDBERG等[15]以知识图谱为信息载体,通过集成设计、制造和质量等阶段的制造数据构建了覆盖产品全生命周期的智能制造数字化主线,便于服务产品制造信息追溯和知识复用。段阳等[16]针对金属切削加工过程数据分布离散问题,通过构建金属切削加工知识图谱,为制造型企业信息重用提供了数据支撑。GUO等[17]将知识图谱技术引入到自动化加工工艺决策系统中,建立了基于知识图谱的零件信息、工艺知识和设备资源的三级信息模型。尽管知识图谱在其他领域中发挥了重要作用,但将其直接应用在再制造拆解中仍有不足,主要表现在以下3个方面:
(1)数据样本构建 由于废旧零部件内部结构、损伤特征等具有较大差异,使得拆解过程具有很强的不确定性,这种不确定性导致车间内各拆解活动的工艺数据获取、流通和集成困难。
(2)知识表征及抽取 不同拆解活动所涉及的工艺数据类型多,结构复杂,难以进行知识化表征。在此基础上,需要对拆解工艺数据进行处理,以实现工艺知识的自动抽取。
(3)知识更新 在实际拆解过程中,要求知识图谱能够根据拆解工艺调整情况进行自适应更新,从而保证知识的准确性和时效性。
综上所述,针对再制造拆解过程中工艺频繁调整的要求,为进一步提高废旧零部件拆解效率和质量稳定性,本文提出一种动态数据流驱动的再制造拆解工艺知识图谱构建方法。通过分析再制造拆解工艺数据特点,定义以拆解工位为节点的数据流模型,以实现不同工位上拆解工艺数据的组织串联;利用本体建模方法为拆解工艺数据流提供统一的知识表达形式,并采用基于轻量化双向编码器表示转换和双向长短期记忆网络与条件随机场的命名实体识别模型(ALBERT-BiLSTM-CRF)及自然语言处理方法对拆解工艺实体及关系进行抽取;最终基于动态数据流实现图谱实体及关系的更新,有效提高拆解工艺知识质量,满足知识图谱对拆解工艺调整的快速响应。
1 动态数据流驱动的再制造拆解工艺知识图谱构建框架
1.1 再制造拆解工艺数据特性
再制造拆解涉及到加工对象、工艺方法、拆解设备以及操作人员等,是一个复杂的动态过程[18]。拆解工艺路线的随机性及不确定性、零部件失效机理的不可知性、工艺方法的特殊性等特点,使得传统离散手工拆解为主且经验依赖性大的拆解模式难以再适用于废旧产品拆解过程,需要在拆解过程中尽可能掌握一系列拆解工艺数据并辅助工艺人员进行决策,从而保证拆解作业的合理性。
随着拆解作业的持续进行,再制造拆解过程中积累了大量且类型复杂的工艺数据(如工艺路线、技术文档、操作记录、质量检验结果等),这些数据呈现分布离散、关联不明确且价值密度低的特性。此外,由于废旧零部件拆解特征的特殊性以及拆解过程的动态性,使得拆解工艺数据具有显著的时序变化特征,需要保证不同工位上拆解工艺数据“采集-处理”过程的时效性,才能在有效时间内针对特定拆解环节进行工艺调整,从而提高拆解效率。依据拆解工艺层级嵌套关系以及数据流向,构建拆解工艺数据变迁过程如图1所示。通常地,废旧产品拆解结构分为产品整机、装配体和零部件三个层级,从宏观上看,产品是由各装配体的拆解活动(工步)组成,从微观上看,产品是由各装配体内零部件的拆解活动(工序)组成,整个拆解过程是由一系列自上而下的拆解活动累积构成的,产品结构经历了从产品整机、装配体到分解成全部零部件的变化过程。另一方面,从拆解工艺数据流向可以看出,经由不同层级拆解过程得到的拆解工艺数据在车间各工位之间通过不断地迭代更新,可用于映射并指导实际拆解活动的实施,从而确保拆解过程顺利高效的执行。
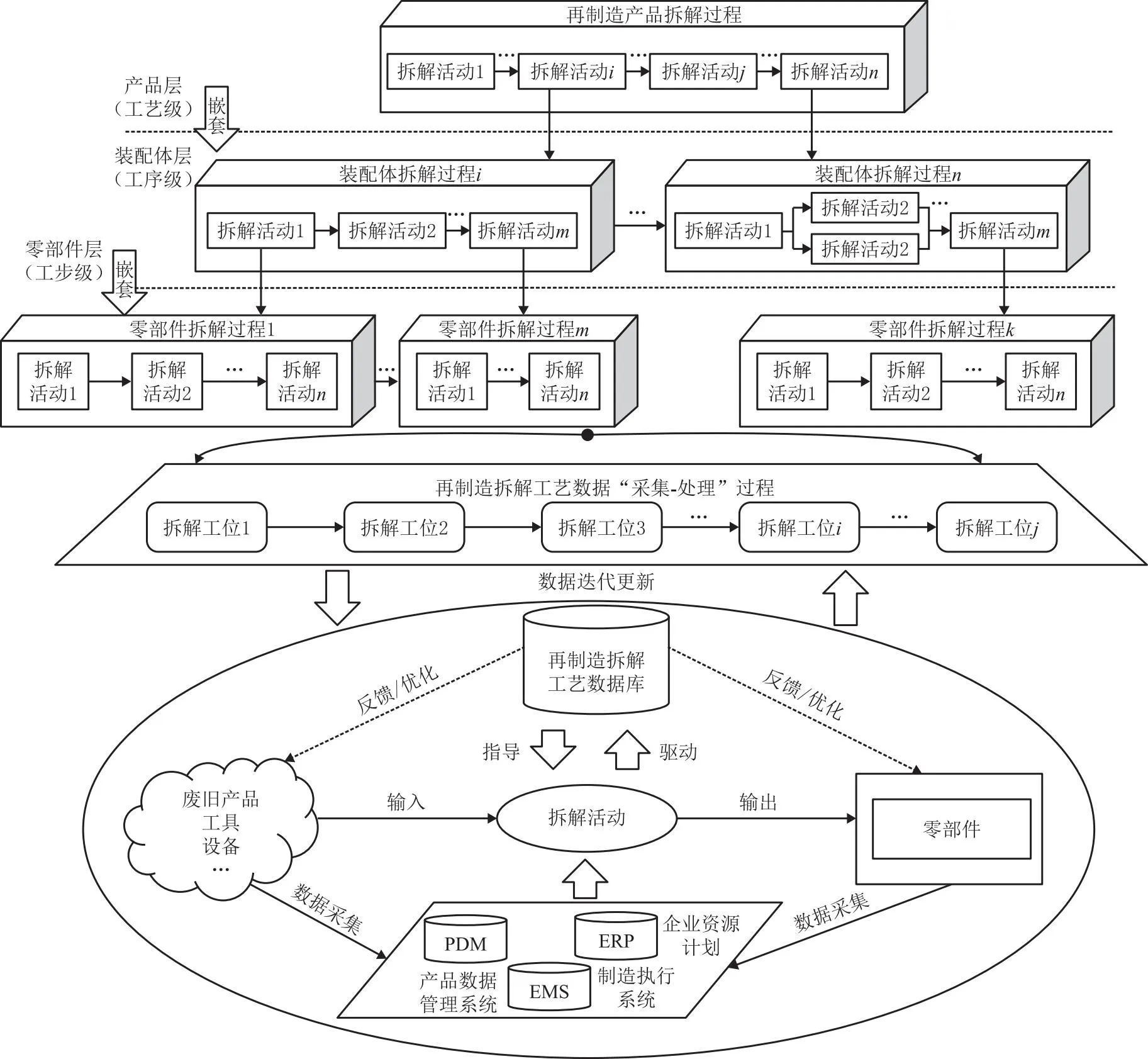
图1 再制造拆解工艺数据变迁过程示意图
1.2 再制造拆解工艺知识图谱构建框架
在分析再制造拆解工艺数据特性的基础上,提出动态数据流驱动的再制造拆解工艺知识图谱构建框架,如图2所示。主要分为再制造拆解工艺数据流模型定义、再制造拆解工艺知识建模、再制造拆解工艺知识图谱生成及更新三部分:
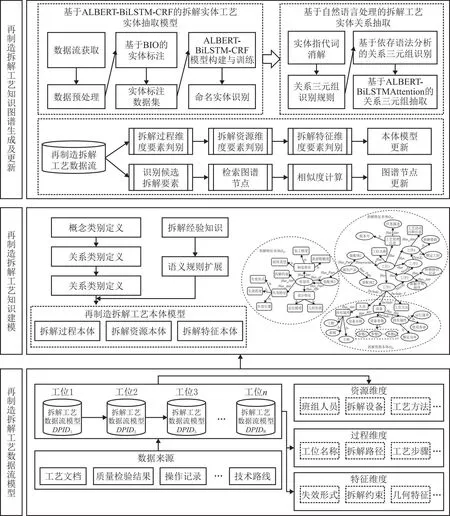
图2 再制造拆解工艺知识图谱构建流程
(1)再制造拆解工艺数据流模型定义 再制造拆解工艺数据作为拆解过程中不可或缺的组成部分,包含丰富的实践经验、加工规律以及操作方法等。然而,这一类数据往往具有离散性强、关联性弱且动态时序性特征,不易在拆解过程中被挖掘、组织和表征。通过将拆解工位作为数据分析节点,构建拆解工艺数据流模型,集成不同工位上涉及的工艺信息资源,为后续知识图谱的构建提供数据支撑。
(2)再制造拆解工艺知识建模 针对不同拆解工艺数据之间的语义差异性,需要为数据流提供统一的知识表达形式。通过本体建模方法对拆解工艺知识进行表示,构建拆解过程、资源和特征三类本体模型;并利用语义规则语言(Semantic Web Rule Language,SWRL)描述拆解经验知识,进一步提高知识图谱的语义表达能力。
(3)再制造拆解工艺知识图谱生成及更新 利用ALBERT-BiLSTM-CRF模型及自然语言处理方法对拆解工艺数据流进行实体抽取、关系抽取等步骤,获得以<实体-关系-实体>表征的知识形式。针对拆解工艺频繁调整的要求,通过本体链接改动与图谱实体更新,实现基于动态数据流的图谱更新。
2 动态数据流驱动的再制造拆解工艺知识图谱构建方法
2.1 动态拆解工艺数据流模型定义
在再制造拆解过程中,每一次工艺执行都会产生一系列流式数据。通过分析拆解工艺数据特点,将其划分为如下三类:
(1)过程维度数据:描述拆解过程中一系列拆解活动信息,其要素包括拆解工艺管理信息、工艺属性信息、工艺执行信息、工艺标注信息等,这一类数据能够清楚表达废旧产品拆解过程状态,便于对零部件或装配体的拆解活动进行监测和管理。
(2)特征维度数据:是对废旧零部件拆解特征的详细描述,主要涉及到失效形式、装配关系、几何特征和材料类型等。拆解特征是拆解活动的执行依据,并为后续拆解工艺的优化和调整提供参考。
(3)资源维度数据:涵盖了参与再制造拆解过程中所有非产品的固有元素,如场地、班组、设备、任务计划及工艺方法等。拆解资源的合理配置能够有效降低拆解活动的成本和能耗。
由于废旧零部件内部结构、损伤特征等具有差异性,不同零部件之间的加工参数、资源配置以及工艺方法等会随时间发生改变,即拆解工艺数据具有动态时序性特征。因此,本文提出以拆解工位为数据分析节点,将不同工位上的拆解工艺数据流封装成一个个具有时间节点的集合,进而实现动态数据流的组织串联。拆解工艺数据流模型DPID是对特征维度、资源维度及过程维度数据进行集成及统一化的描述,该模型表示为
(1)
(2)
(3)
(4)
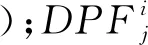
通过该模型可以根据不同工位情况生成与之对应的拆解工艺数据流资源,为后续再制造拆解工艺知识图谱的构建提供数据支撑。其中,如何从拆解工艺数据流中生成个性化的工艺知识是当前亟需解决的问题。
2.2 基于本体的再制造拆解工艺知识建模
(1)再制造拆解工艺本体模型构建
在工程语义层面,本体模型常被用于形式化描述领域知识,是对相关概念的归集以及概念间关联作用的表示[19]。再制造拆解工艺本体(Remanufacturing Disassembly Process ontology,RDP)通过式(5)定义的五元组形式描述为
(5)
式中CDP为拆解工艺本体的概念集合,分为三类拆解工艺涉及到的概念元素:拆解过程本体(oDP);拆解资源本体(oRA);拆解特征本体(oDF)。


表1 语义关系定义及其描述
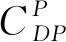
图3所示为再制造拆解工艺本体模型。其中,拆解过程本体代表某一装配体或零部件拆解活动的相关描述,用于确定拆解工艺的执行顺序和步骤。拆解资源本体将分散在不同工位上的拆解资源进行集中管理,为拆解过程提供资源的按需配送。拆解特征本体主要描述拆解对象所具有的特征属性,能够指导拆解工艺的合理实施。其中,对于语义关系中的时间戳“T”,均以工位开工时间tb和完工时间te设置。

图3 再制造拆解工艺本体结构
(2)基于SWRL规则的拆解经验知识表示
SWRL是基于本体的语义规则语言[20]。本体语义实现了对拆解工艺知识的抽象化描述和结构化表达,但却未能表征语义性更强的拆解经验知识。然而,从工程实践角度分析,再制造拆解过程包含了对经验知识的综合应用,但这些知识未能从上述本体模型中清楚描述。
为解决这一问题,本节利用SWRL规则语言将经验知识进行表征,并融入本体模型中。其核心思想:①从已有拆解工艺设计规范及工艺人员中分析、提取拆解经验知识;②将提取的经验知识转为可用IF-THEN条件语句的表示形式;③将IF-THEN的形式转化为SWRL规则,完成对经验知识的语义表示;④利用protégé内的推理模块验证所构建的SWRL规则,核验无误后统一到本体模型中。
构建部分SWRL规则实例如下:
规则1若某一联接件在拆解方向+X上被某一子装配体直接遮盖,则联接件需要在该子装配体之后拆卸。
Fastener(?f),SubassemblyPart(?fp),
isDirectCoveredBy_plusX(?f,?fp)
→has_disassembled_after(?f,?fp)。
规则2若某一子装配体在拆解方向+X上被某一联接件固定,则该子装配体需要在联接件之后拆卸。
SubassemblyPart(?f),Fastener(?fp),
isFixedBy_plusX(?f,?fp)
→has_disassembled_after(?f,?fp)。
2.3 基于ALBERT-BiLSTM-CRF的拆解工艺实体抽取模型
实体抽取又称为命名实体识别,是其他抽取任务的前提,其本质是从语料数据中抽取出实例化实体[21]。ALBERT预训练模型采用词嵌入矩阵分解、跨层参数共享等方法加快模型训练速度并增强语义理解能力,在自然语言处理任务上具有较强的鲁棒性[22-23]。因此,本文基于ALBERT-BiLSTM-CRF命名实体识别模型进行拆解工艺实体抽取,具体流程如下:
(1)数据流获取 将拆解工艺数据流(如工艺文档、加工记录以及质量检测结果等)作为拆解工艺实体抽取任务的原始语料集,并采用十折交叉验证的方式划分模型的训练集和测试集,避免模型存在过拟合风险。
(2)数据预处理 数据流大多以自然语言形式表征,为避免其存在大量噪声导致实体抽取效果差的情况,采用正则表达式或字符串操作等方法对数据进行清洗和筛选,获取可作为ALBERT层的输入语料。
(3)实体标注 本文采用BIO(begin-inside-outside)标注方法对拆解工艺实体进行标注。其中,“B-”表示实体关键词的字首,“I-”表示实体关键词非字首的后缀词,“O-”表示非实体关键词。具体标注策略如表2所示。

表2 实体标注规则
(4)训练ALBERT-BiLSTM-CRF模型 ①特征转换,使用ALBERT预训练模型将训练集数据转换为词向量形式,为后续模型提供数值型数据的输入。②模型调参,经过模型参数调优后保存最佳模型参数,使得其在训练集上具有良好的泛化能力。
(5)命名实体识别过程 模型工作流程如图4所示,首先将测试集数据转换得到的词向量输入至前向BiLSTM层和后向BiLSTM层,获取数据的语言特征信息,并输出相关向量序列。然后将向量序列输入至CRF层,通过优化转移矩阵得到概率最高的预测实体标签,即为最优实体集合。
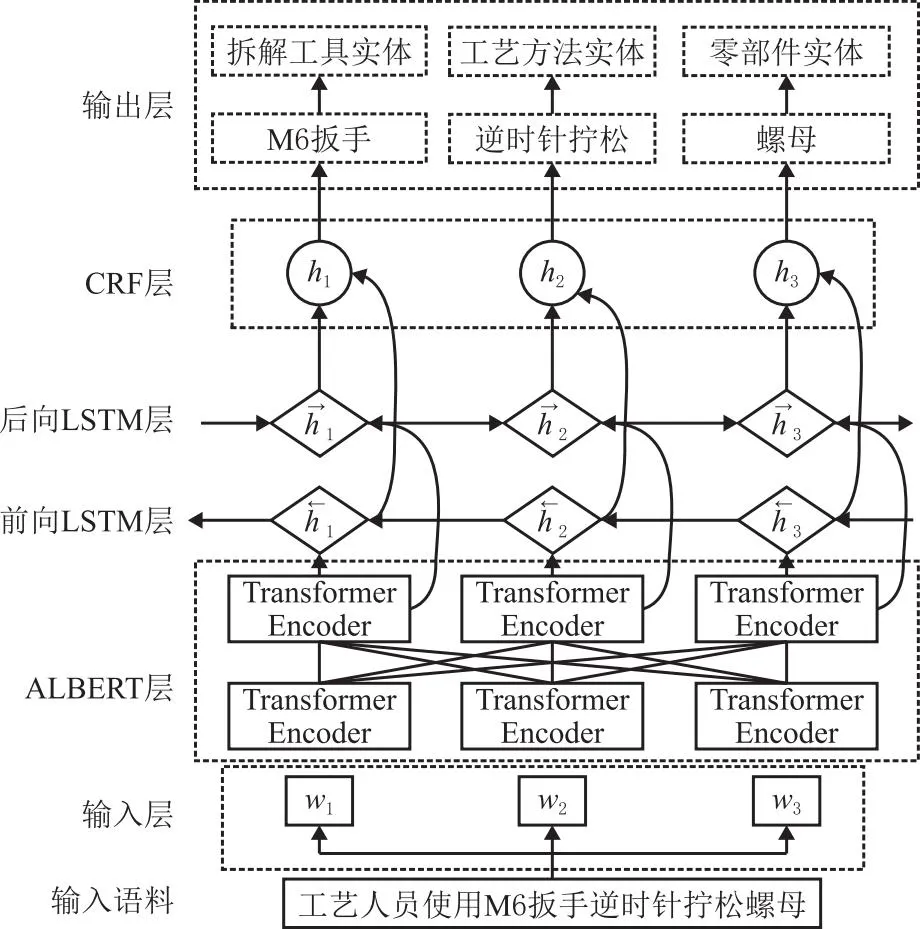
图4 ALBERT-BiLSTM-CRF模型结构图
2.4 基于自然语言处理技术的拆解工艺实体关系抽取
提取实体间关系是生成知识图谱关系边的必要步骤,主要目的是将拆解工艺知识构建为三元组形式,从而清楚地描述知识之间的逻辑关系。针对拆解工艺数据具有多个客体并列存在、客体语句位置分布密集的特征,且存在“指代不明”的问题。本文提出一种基于自然语言处理技术中指代消解和依存语法分析的方法,对拆解工艺数据流进行关系三元组识别和抽取,分为实体指代词消解、基于依存语法分析的关系三元组识别、基于ALBERT-BiLSTM-Attention模型的关系三元组抽取3个步骤。
(1)实体指代词消解
1)指代识别。首先对拆解工艺数据流进行截断、分词和词性标注等预处理操作;其次识别出经处理后语句中的先行词和照应词,并按照“距离优先”准则(距离最近的先行词作为指代对象)以及语句成分对其进行过滤、分类;最后基于命名实体识别过程获得的知识,构建模型输入数据。
2)训练ALBERT模型。通过对输入数据进行特征转换,并训练ALBERT模型得到最佳参数组合,便于对测试集数据进行预测。
3)指代词预测。通过输入测试集数据得到指代词预测结果,然后筛选正确的指代词标签,并对指代词进行替换。
(2)基于依存语法分析的关系三元组识别
1)数据解析。首先对拆解工艺数据流进行分词、词性标注等,然后经由词汇及词性解析得到数据流的依存句法结构。
2)构建关系识别三元组规则。结合再制造拆解领域数据特征、依存句法结构对三元组进行标注,并对每个词进行规则匹配,识别相应的关系三元组知识,具体依存关系规则如表3所示。

表3 依存关系句法表
3)基于ALBERT-BiLSTM-Attention的关系三元组抽取。拆解工艺实体关系抽取同样基于ALBERT预训练模型,并在BiLSTM的基础上引入ATttention注意力机制。该机制通过对BiLSTM预测信息序列进行加权变换,按照信息重要程度赋予不同权重,从而进一步提高模型特征抽取的准确度。其主要原理是计算实体对之间存在指定关系的概率,当具有最高概率值的关系词与实体匹配成三元组,即完成关系三元组的抽取任务。
2.5 基于动态数据流的图谱更新机制
废旧产品的拆解过程是按照一定的工艺流程完成的,呈现出一种结构有序的特征,通过对多个工艺活动进行编排,进而实现整个拆解工艺的规划设计。然而,由于实际拆解过程中工艺持续不断地进行调整,要求知识图谱需要具备能够根据拆解工艺调整情况进行自适应更新的能力,以确保知识的准确性和时效性。因此,本文提出一种基于动态数据流的图谱更新机制,能够基于动态数据流灵活地对图谱实体及其关系进行更新,从而实现知识图谱对拆解工艺调整的快速响应。该机制分为本体链接改动和图谱实体更新两部分,具体描述如下。
(1)本体链接改动 本体链接改动是根据不同工位上拆解工艺数据流中拆解要素的变化情况(如工艺方法调整、拆解设备增删等),通过在拆解工艺本体模型中改动相应的实例,并重新建立本体实例之间的链接关系,然后更新本体模型,即可提高本体模型对拆解过程的适应性,而不需要再对本体模型进行重新设计,有效降低拆解工艺重构的代价。如图5所示,首先,扫描第i个工位上的拆解工艺数据流DPIDi,判断拆解过程维度要素类别,依据变化情况调整拆解过程本体相应实例,建立拆解工位、拆解对象等要素之间的“NextTo”、“FlowTo”等顺序关系;然后判断拆解资源维度要素类别,依据变化情况调整拆解资源本体相应实例,建立班组人员、拆解设备及工具等要素之间“Include:T”、“Hasproperty:T”等时序关系;再判断拆解特征维度要素类别,依据变化情况调整拆解特征本体相应实例,建立装配关系、失效特征及几何特征等要素之间的“Has_part”、“Has”或“Is”等特征关系;最后更新拆解工艺本体模型。如此递归扫描所有工位上的拆解工艺数据流。
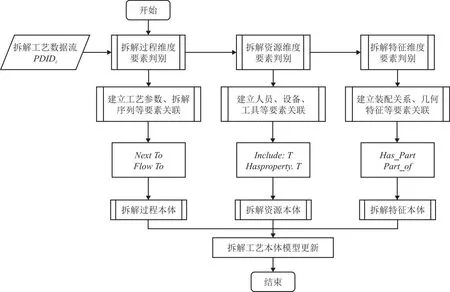
图5 本体链接改动流程
(2)图谱实体更新 图谱实体更新是在工位时间戳[tb,te]内将拆解工艺数据流与图谱实体进行匹配链接,具体流程如表4所示,主要包括拆解要素候选模块和实体链接模块。其中,拆解要素候选模块的功能是识别拆解工艺数据流中已变化的所有候选拆解要素。实体链接模块则是把数据流中的候选拆解要素与图谱实体映射至向量空间,计算其欧氏距离来判断两者之间的相似程度[24],并链接到正确的图谱实体上。对于图谱更新的输出项DREN,经由专家评估后在图数据库中自动转换为相应实体结构,从而实现图谱中拆解工艺实体的更新。
3 案例分析
某型号废旧动力电池包拆解过程共涉及预处理(检测外观及绝缘性)、吊装上线、切割模组侧板、OCV测试分选等28个拆解工位。相关拆解设备、人员数量以及操作类型等数据如表5所示。
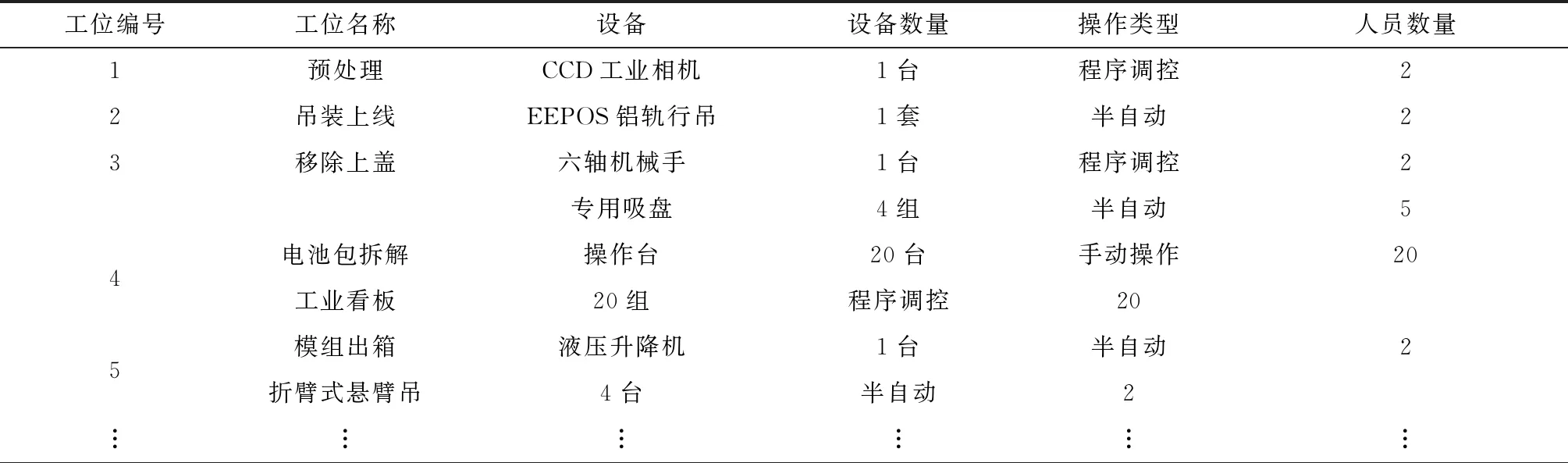
表5 拆解设备及工位人员配置
对于拆解工艺数据流,利用所提出的3种维度进行收集和处理,形成以资源描述框架(RDF)描述的数据流形式,并采用MongoDB数据库进行存储。以某一吊装上线工位时间戳为例,其数据流如表6所示。
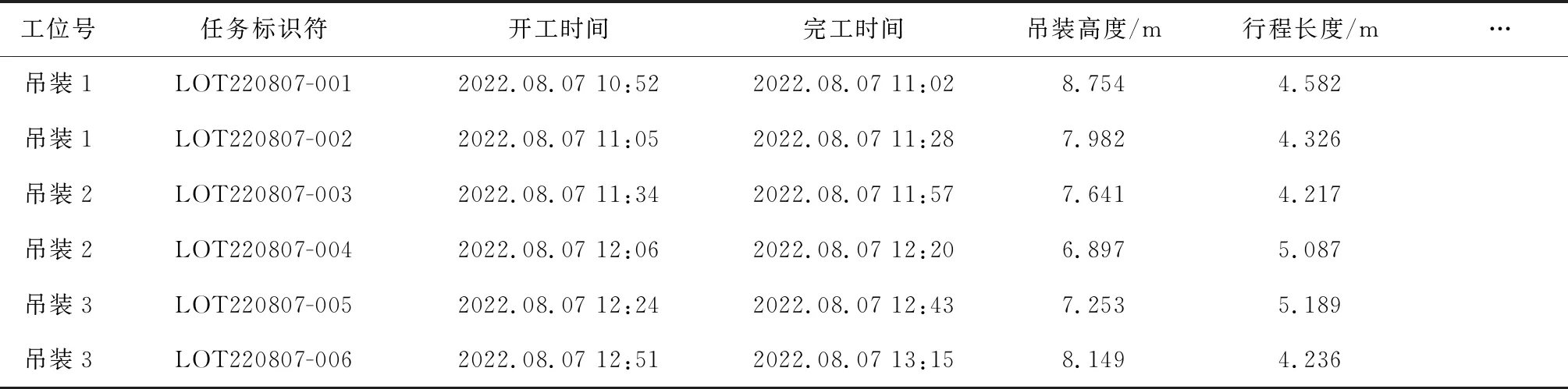
表6 时间戳内吊装上线工位的数据流(部分)
3.1 拆解工艺知识图谱构建示例
首先,在图谱构建过程中,需要将拆解工艺数据转化为易于理解的知识形式。根据本文所提的基于本体的拆解工艺知识建模方法,利用protégé工具分别建立了该动力电池包拆解过程、资源和特征的本体模型,领域专家可通过该工具对这三类本体进行编译。图6所示为动力电池包拆解过程本体,包含预处理、模组出箱、OCV测试分选等步骤。图7所示为动力电池包拆解资源本体,通过添加相应的工艺方法、班组人员、拆解设备及工具,实现拆解过程中资源要素的合理配置。图8所示为动力电池包拆解特征本体,可以清楚表达某一装配体或零部件所具有的拆解优先级、连接数量等属性。
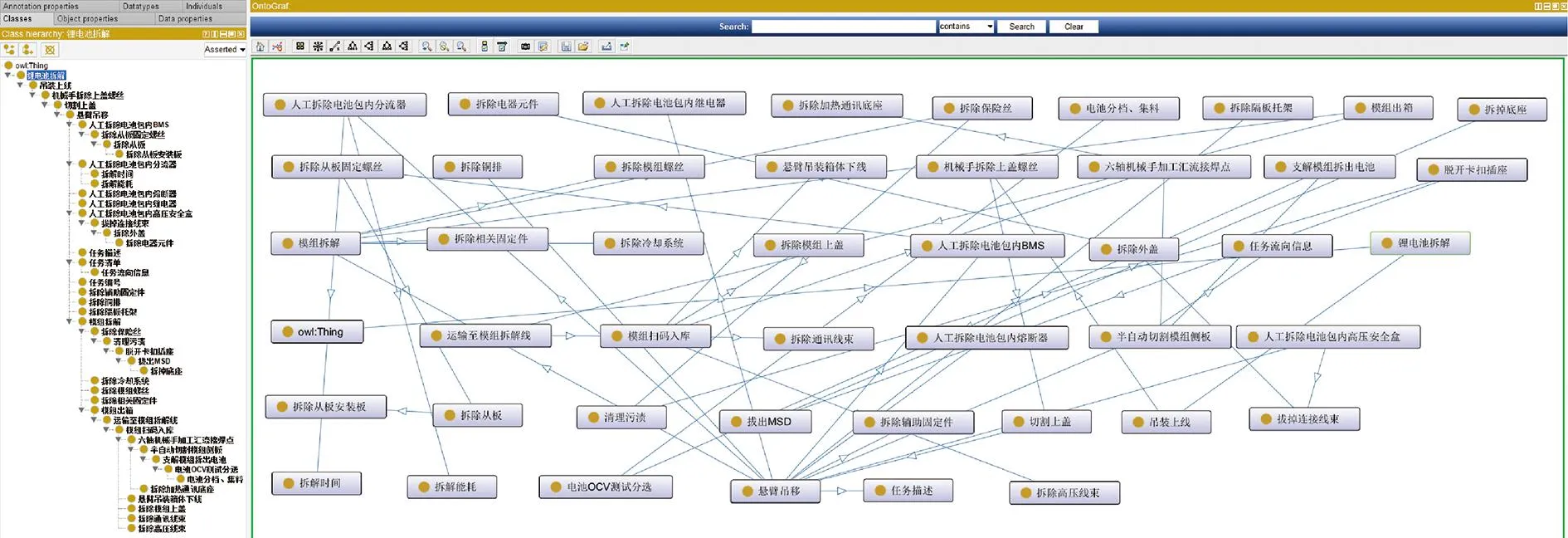
图6 动力电池包拆解过程本体
其次,将拆解工艺数据流按照8∶2的比例划分训练集和测试集,根据BIO标注法对训练集进行标注,用标注后的数据训练ALBERT-BiLSTM-CRF模型,再用模型自动完成剩余测试集的实体抽取任务,获得6 472个图谱实体。通过对拆解工艺数据流进行指代消解和依存关系分析,并基于ALBERT-BiLSTM-Attention模型抽取出2 781个实体关系。最后,在 neo4j图数据库中构建废旧动力电池包拆解工艺知识图谱(图9),共包含5 478个节点,8种关系类型。其中,ALBERT-BiLSTM-CRF模型中Learning rate为0.0001,Batch size为64,Epochs为20,Max length为256,Hidden size为192;ALBERT-BiLSTM-Attention模型中Learning rate为0.000 03,Batch size为32,Epochs为40,Max length为256,Hidden size为128。
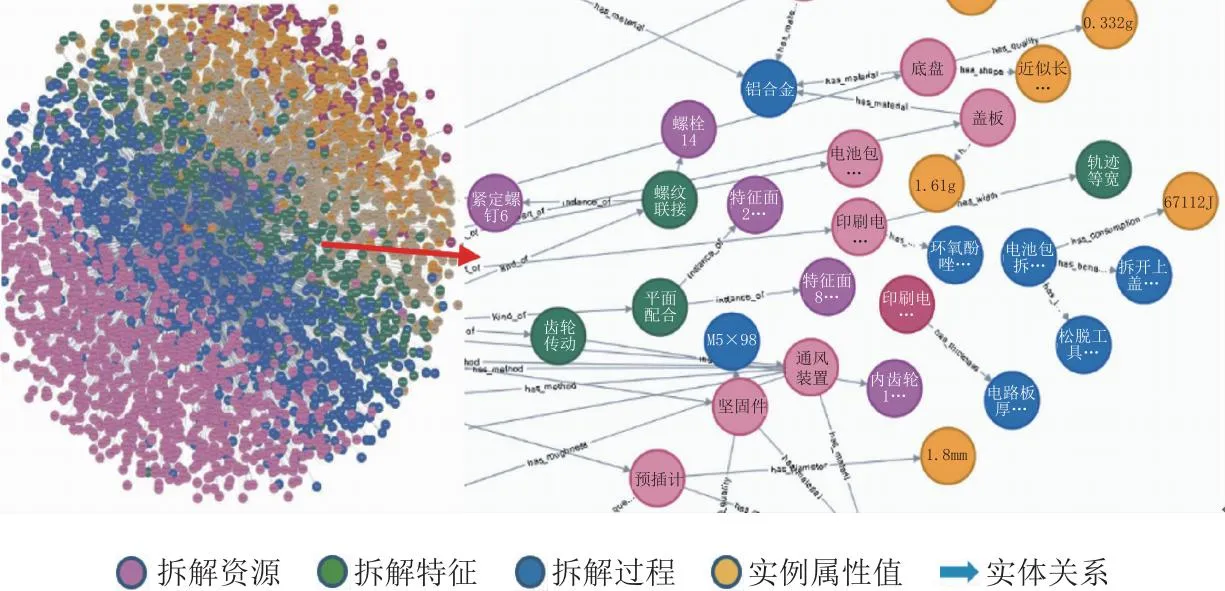
图9 动力电池包拆解工艺知识图谱局部示意图
为了验证所提模型的优越性,本文采用准确率P、召回率R和F1值对拆解工艺实体及关系抽取的性能进定量化评价。实体抽取结果如表7所示,相较于BiLSTM和BiLSTM-CRF模型,由于ALBERT预训练模型可以获取上下文信息的词级特征,并且能够基于上下文生成动态词向量,F1值可达90.8%,表明模型在拆解工艺实体抽取任务中的查准率和查全率具有显著优势。关系抽取结果如表8所示,相较于BiLSTM-Attention和ALBERT-BiGRU-Attention模型,通过在BiLSTM的基础上引入ATttention注意力机制,对于文本关键信息赋予权重值,从而进一步提高特征抽取的准确性,F1值可达93.4%。其中,由于拆解工艺数据流存在训练集未包含语料,使得拆解工艺实体及关系抽取过程中易出现漏识别或误识别,一定程度上影响图谱的准确性。
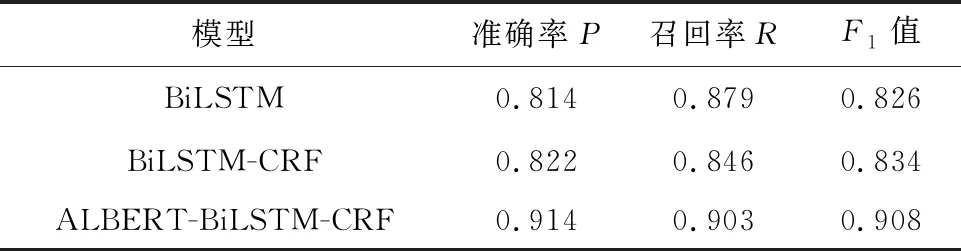
表7 拆解工艺实体抽取结果
3.2 图谱更新效率
基于动态数据流的图谱更新机制对拆解工艺实体及其关系进行更新,可将拆解工艺知识的查询与更新效率提升至秒级。为了更好地评估拆解工艺知识图谱更新与知识查询效率,将每个工位下拆解工艺数据流的更新耗时记为Tts,拆解工艺实体查询耗时记为Teq,拆解工艺实体关系查询耗时记为Trq,拆解工艺实体更新耗时记为Teu,拆解工艺实体关系更新耗时记为Tru。拆解工艺实体及关系的总查询和更新耗时分别表示为:
TRN=Tts+Teu+Tru;
(6)
TQ1=Teq+Teu;
(7)
TQ2=Trq+Tru;
(8)
TQ3=Tts+Teu;
(9)
TQ4=Tts+Tru。
(10)
式中,TRN为图谱更新总耗时;TQ1为拆解工艺实体查询总耗时;TQ2为拆解工艺实体关系查询总耗时;TQ3为拆解工艺实体更新总耗时;TQ4为拆解工艺实体关系更新总耗时。其中,Tts为工位完工时间te与开工时间tb差值。
取某一工位上拆解工艺数据流进行验证,图谱中拆解工艺实体及其关系的查询速率和更新速率相较于全面式更新方法提高1倍以上(见图10和图11)。由此可见,拆解工艺知识图谱的更新耗时基本满足拆解工艺数据流的间隔变化需求,能够根据拆解工艺调整情况进行快速响应。
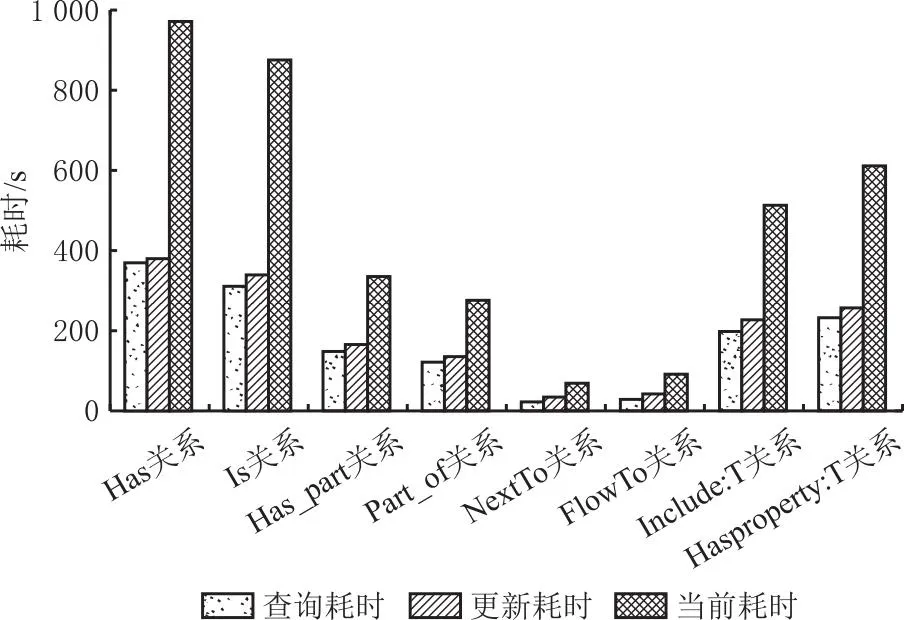
图11 拆解工艺实体关系查询与更新耗时
4 图谱应用实例
依据上述方法,本文设计并开发了基于知识图谱的废旧动力电池包拆解工艺知识管理系统,采用Javascript和Echart来完成图谱展示,前后台采用flask框架接收前端请求并生成数据返回前端,使用neo4j图数据库存储实体与关系。该系统主要用于辅助工艺人员进行拆解工艺规划决策,使得传统的以经验为主的人工决策转变为“数据-知识”联合驱动的智能决策模式,有效提高拆解工艺规划过程的可解释性。图12所示为系统界面展示图,通过解析输入的拆解工艺数据流,实现动力电池包拆解工艺方法、拆解设备及工具、拆解路径等工艺信息的提取。工艺人员在进行拆解工艺设计时,通过输入查询语句,并对其关键词进行解析,向工艺人员返回相关拆解工艺信息,从而综合考量现阶段装配体或零部件拆解工艺的制定。
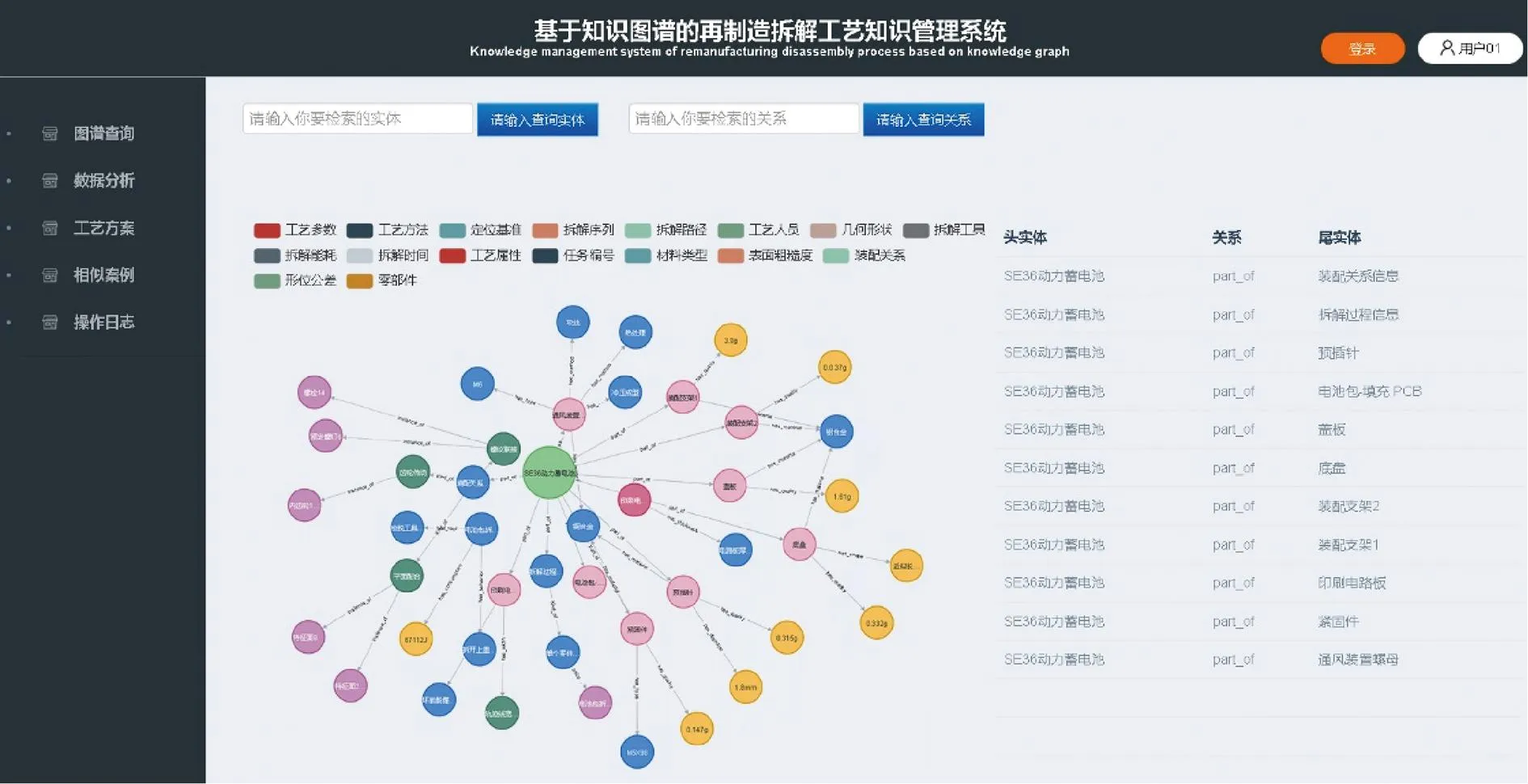
图12 系统界面展示图
图13展示了废旧动力电池包模型,按照产品整机-装配体-零部件的层次关系表示模型的结构信息,且知识图谱相关实体与关系的数据统计以表格形式展示。例如,在拆解电池模组11-24过程中螺栓GB_T_5783_M8与螺母GB_T_889_M8拆解特征面为圆柱面-圆柱面,装配关系为孔轴配合,且螺母拆解优先级高于螺栓。通过在工位时间戳内输入拆解工艺数据流,生成不同工位对应的拆解工艺知识图谱,从而针对特定拆解环节提供拆解工艺知识,辅助工艺人员进行决策。
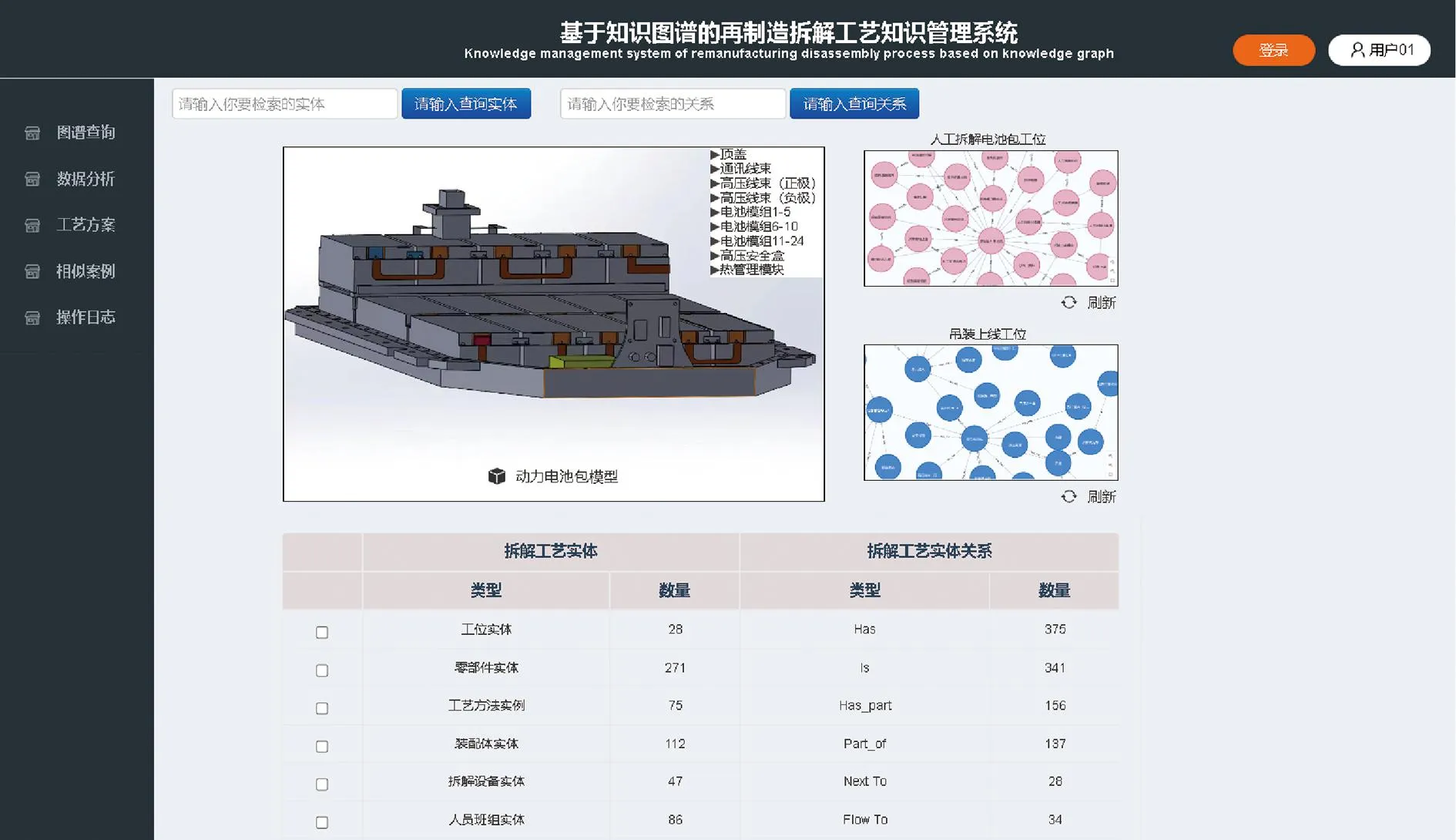
图13 模型展示及工位图谱界面
5 结束语
由于废旧零部件的内部结构、损失特征等存在差异性,使得拆解工艺需要频繁地进行调整,进而导致再制造拆解效率低、质量稳定性差。为此,本文提出一种动态数据流驱动的再制造拆解工艺知识图谱构建方法,利用知识的高效更新与重用指导废旧零部件的拆解过程,从而提高拆解效率与质量,主要工作包括:
(1)分析再制造拆解工艺数据的动态时序特性,定义以拆解工位为单元的数据流模型,对不同工位上的数据流进行集成,实现动态拆解工艺数据流的组织串联。
(2)构建拆解过程、资源和特征三类本体模型,为拆解工艺数据流提供统一的知识表达形式,并利用SWRL规则语言拓展本体模型,进一步拓展图谱的语义表达能力。
(3)结合ALBERT-BiLSTM-CRF模型和自然语言处理技术识别数据流中的拆解工艺实体及关系,完成再制造拆解工艺知识图谱的构建。同时,基于动态数据流实现图谱实体及关系的自适应更新,进而满足拆解过程中工艺调整的要求。
本文后续重点是针对再制造产品拆解工艺要求,采用相关知识推理技术进一步研究基于知识图谱的再制造拆解工艺规划方法,提高再制造拆解的智能化水平。
猜你喜欢
哲学分析(2023年4期)2023-12-21
中国新闻周刊(2023年42期)2023-12-03
中国音乐学(2020年4期)2020-12-25
物流技术与应用(2020年5期)2020-06-25
汽车维修与保养(2020年11期)2020-06-09
意林(2020年10期)2020-06-01
电脑与电信(2018年12期)2018-03-23
文学教育(2016年27期)2016-02-28
杭州(2015年9期)2015-12-21
西北工业大学学报(2015年3期)2015-12-14
