
多层特征融合与语义增强的盲图像质量评价
2024-04-09 01:41:52赵文清许丽娇陈昊阳李梦伟
智能系统学报 2024年1期
赵文清,许丽娇,陈昊阳,李梦伟
(1.华北电力大学 控制与计算机工程学院, 河北 保定 071003; 2.复杂能源系统智能计算教育部工程研究中心,河北 保定 071003)
图像在采集、存储、传输中可能存在着模糊、噪声等失真问题[1]。图像质量评价(image quality assessment, IQA)旨在为各种失真图像进行质量的评级打分,对多种图像处理算法的评估、改善图像的视觉体验具有重要意义。最直接的图像质量评价方法是根据人类的视觉感知进行评分,但是这种方法会被人的主观因素所影响,且耗时费力。随着计算机技术的不断发展,在没有人工干预的情况下,可自动进行图像的质量评价[2]。全参考图像质量评价算法要求利用高清晰度、无失真图像作为参照,传统的全参考图像质量评价算法有峰值信噪比算法(peak signal to noise ratio,PSNR)[3]和文献[4]提出的结构相似度算法(structural similarity index measure, SSIM) 等。半参考图像质量评价算法仅利用无失真图像的部分特征即可评估图像的质量,如文献[5]实现的综合多尺度几何分析算法。但是,现实中的失真图像很难找出对应的无失真图像。无参考图像质量评价(no reference image quality assessment, NRIQA)算法不需要使用参考图像,通过提取图像的失真特征对图像进行评价,在实际中有着广泛的应用[6]。
盲/无参考图像空间质量评估器(blind/referenceless image spatial quality evaluator, BRISQUE)[7]算法将图像的高斯分布特征作为质量分数的回归特征。基于高阶统计聚合的盲图像质量评估(blind image quality assessment based on high order statistics aggregation, HOSA)算法[8]提取码本中图像的归一化均值、方差和协偏度等特征,通过计算码本中图像和测试图像之间的特征差异来进行质量分数的回归。以上方法需要从失真图像中提取人为设计的图像特征,要求人们具有足够的先验知识,具有一定的局限性且性能提升较慢。
鉴于深度模型具有很强的特征抽取能力,越来越多的学者将其应用到图像质量评价领域[9]。用于无参考的加权平均深度图像质量评估(weighted average deep image quality assessment metric-no refenence, WaDIQaM-NR)[10]通过堆叠多个卷积层和池化层自动提取与畸变有关的特征,并将图像分割成许多图像块,对图像块的分数进行加权操作来得到整幅失真图像的质量分数。分级退化级联卷积神经网络(cascaded convolutional neural network with hierarchical degradation concatenation,CaHDC)[11]考虑了人类视觉系统中分层感知机制,利用卷积神经网络(convolutional neural network, CNN)学习退化特征,实现质量的预测。深度双线性卷积神经网络(deep bilinear convolutional neural network, DB-CNN)[12]分别设计针对合成失真和真实失真的CNN模型来提取失真特征,采用双线性池进行结合,最后利用全连接层进行质量分数的回归。文献[13]利用数据驱动的方式,将大量带有标记的畸变图像映射为质量分数,使无参考图像质量评价(no reference image quality assessment, NR-IQA)算法在合成失真图像数据集上的性能得到了显著提高。然而,以上方法考虑的是图像退化的全局信息,而真实情况下,大多数畸变都是局部畸变,而且人的视觉系统对局部畸变十分敏感,从而导致以上算法在面对真实失真图像时表现不佳。自适应超网络引导下的野外图像质量盲评估算法(blindly assess image quality in the wild guided by a self-adaptive hyper network,HyperIQA)[14]首次将不同层次的局部失真特征进行提取聚合。多尺度特征逐层融合的深度神经网络(deep neural network based on multi-scale features fusion layer-by-layer, MsFF-Net)[15]通过逐层融合相邻的尺度特征,获得了更能精确表征图像质量的多尺度失真特征。从补丁到图片的盲图像质量测量算法(from patches to pictures blind image quality measurement, P2P-BM)[16]构建了基于图像区域的深度架构,用于学习生成局部的图像质量分数以及全部的图像质量分数。以上3种方法充分考虑到了图像细粒度的局部畸变在评价过程中的作用,在野生图像质量挑战数据集(live in the wild image quality challenge database, LIVEC)[17]和康斯坦茨真实图像质量数据库(konstanz authentic image quality 10k database,KonIQ-10k)[18]上性能得到了明显的提升。
为了兼顾图像的局部和全局信息,往往对相邻层的特征构建金字塔结构,但是会造成语义跨度较大的问题,而且简单的特征融合不能有效地提取失真图像的细节信息[19]。在面对不同内容时,人们观察图像的感知方式并不相同,IQA任务应与图像的语义信息高度相关。真实失真图像中内容多种多样,存在着各种局部和非局部的失真,质量评价算法需要同时考虑失真图像中的语义信息和局部信息[19]。尽管以上方法中的回归损失对于质量预测任务十分有效,但是没有考虑图像块之间的排序关系[20]。
因此,本文针对以上存在的问题,提出了多层特征融合和语义增强相结合的盲图像质量评价算法(multi-level feature fusion and semantic enhancement for NR, MFFSE-NR),将失真图像块输入到深层特征提取网络,提取出局部和全局特征,利用特征融合模块对各个特征进行分层融合,然后对各个层次的特征进行自适应池化,最后通过全连接层得到每个输入图像块的分数;为了更好地利用图像语义信息,设计语义特征增强模块,捕获长距离的上下文关系,使用语义信息为全连接层生成参数。考虑预测分数和主观分数之间排名的一致性,设计带有相对排名信息的混合损失函数Lmix。
1 相关技术和理论
1.1 Res2Net50网络
本文选取Res2Net50[21]网络作为主干网络,结构如图1所示。Res2Net50将ResNet50[22]的bottleneck中的3×3卷积进行多尺度解耦,以进行多尺度的特征提取。首先是1×1的卷积运算,之后对通道进行分组,图1中组数scale为4,第1组的特征向下传递,第2组的特征经过一个3×3卷积进行特征提取,由此特征提取的感受野随之改变,以此类推,越到后面的组感受野越大,最后将各个组的特征进行拼接还原,再次使用1×1卷积融合通道信息来提取同一层次的多尺度特征。本文中scale取4,每次拆分中通道数width取26。
1.2 特征金字塔网络
为了有效识别目标检测任务中的多尺度目标,特征金字塔网络(feature pyramid networks,FPN)采用自顶向下的结构将上层具有高级语义信息的特征图进行上采样,与低层具有细节信息的特征图逐元素相加,把来自不同卷积层的不同表征信息融合在一起,实现多层特征的融合和增强。
以ResNet作为特征主干网络为例,FPN选取conv2、conv3、conv4、conv5层的最后一个残差块的输出特征组成特征金字塔。每层特征图首先在横向上进行1×1卷积,然后将上一层特征图进行自顶向下的上采样,放大到上一层特征图一样的大小,将二者生成的特征图通过相加的方式进行融合,横向连接之后的特征图再次经过3×3的卷积得出最终的特征金字塔。
1.3 通道注意力模型
注意力机制可以为网络生成更具有辨别能力的特征,关注更需要关注的信息而忽略无关的信息。
SENet是通道注意力机制的代表模型,可以嵌入在各种网络结构中改善性能。SENet首先利用全局平均池化(global average pooling, GAP)对W×H×C的特征图进行压缩,将每个通道上的空间特征进行编码,得到1×1×C的全局特征图;然后利用2个全连接层先降维再进行升维,实现通道之间的交互,得到1×1×C大小的向量;最后经过非线性激活函数Sigmoid生成每个通道的权重,将其与原始特征图相乘,得到加权后的通道特征。
1.4 扩张卷积
扩张卷积最早出现在DeeplLab系列中,通过在卷积核的各像素点中间加入0值的像素点,增大卷积核的尺寸,可以在不牺牲特征图尺寸的前提下增加感受野,提取更多的语义信息,有效避免池化操作过程中造成的信息丢失。当多次叠加的扩张卷积具有相同的扩张率时,由于卷积核存在间隔,不是所有的输入都参与计算,会出现计算中心向外扩散的情况,为此,将扩张率设置为不同值的组合,可以很好地避免这个问题。
1.5 三元组损失函数
深度度量学习以使同类对象之间的距离比较近而不同类的对象之间的距离比较远作为目标。三元组损失最初由谷歌的研究团队提出,在人脸识别领域被广泛使用,用于实现对非同类极相似样本的区分[23]。三元组损失函数为
式中:A为常量,通过学习,模型会让锚点a和正例p的距离值更小,同时让锚点a和负例n的距离值更大,从而实现模型对细节的区分。
2 基于多层特征融合和语义增强的盲图像质量评价网络
本文提出的多层特征融合和语义增强相结合的盲图像质量评价算法(multi-level feature fusion and semantic enhancement for NR, MFFSE-NR),能够有效地处理真实失真场景中的各种复杂失真,如图2所示,模型包含4个模块,分别为多尺度特征提取模块、多层特征融合模块、语义信息增强模块和语义信息指导的质量分数回归模块。

图2 MFFSE-NR整体架构Fig.2 Overall structure of MFFSE-NR
2.1 多尺度特征提取模块
残差图像含有与图像质量有关的重要信息[24],本文选取Res2Net50作为失真特征提取的主干网络。随着卷积层的不断叠加,输出特征图的感受野越大、语义信息越丰富,最后一层卷积生成的特征包含全局感受野,具有最高级的语义信息[25]。本文利用Res2Net50的conv2_10、conv3_12、conv4_18、conv5_9卷积层提取的特征构建特征金字塔,捕获多尺度的畸变信息。特征提取主干网络提取出不同层次的失真特征,方便后续进行更细粒度的融合。
2.2 多层特征融合模块
由于输入的失真图像存在各种局部的失真,同时为了获取不同退化层次的表征信息,本文在特征金字塔结构的基础上,设计了多层特征融合结构,提出了更细粒度的特征融合模块,其结构如图3所示。

图3 多层特征融合结构Fig.3 Structure of multi level feature fusion
与目标检测任务不同,上采样操作会给失真图像引入不必要的噪声,故本文通过横向连接和自下而上路径构建特征金字塔。首先使用步长为2的3×3卷积对低级语义特征进行下采样。为了减少计算量,利用1×1卷积进行横向的等比例降维,将第1层通道数降低至64,第2层降低至128,第3层降低至256。随后,对第1层和第2层的特征进行拼接,得到一个融合的特征。为了减少特征融合过程中的冗余信息,通过通道注意力块得出每层特征的通道权重分数,将它们分别与低级语义特征和高级语义特征逐元素相乘,得到精细的特征图,再经过1×1大小的卷积核进行等比例升维,拼接生成最终的多尺度融合特征图,用于生成质量感知特征向量,进行质量分数的回归。这一过程为
式中:Fi和Fj为相邻层的特征图,Mc为相邻特征拼接后的特征,Wi和Wj分别为Fi′和Fj′的权重分数,CA为独立的通道注意力模块,Fo为自适应融合后的特征,⊗为拼接操作。
为了更加精确地识别真实失真中不同类型的复杂失真,减少特征融合过程中的冗余信息,本文在特征融合部分加入通道注意力模型,其结构如图4所示。

图4 通道注意力模块Fig.4 Channel attention module
为了将每个通道的有利信息进行聚合,首先在特征图上进行全局平均池化处理,生成通道向量。然后利用一个全连接层把通道数缩小为原来的1/16,再通过一个全连接层,实现跨通道之间的交互,最后经过非线性激活函数Sigmoid生成每个通道的权重。
2.3 语义信息增强模块
为了解决高层语义信息不足、感受野较小的问题,首次将多层扩张卷积应用于图像质量评价任务中,使模型拥有更强的语义表达能力。语义信息增强的过程如图5所示。

图5 语义增强过程Fig.5 Process diagram of semantic enhancement
将扩张率设置为不同值的组合,可以很好地避免计算中心向外扩散的问题。本文探究了不同扩张率对野生图像质量挑战数据集(live in the wild image quality challenge database, LIVEC)测试集指标的影响,如表1所示。

表1 扩张率对LIVEC测试集指标的影响Table 1 Influence of expansion rate on LIVEC test set
表1显示了不同扩张率组合对应的感受野大小及对各项指标的影响。由表1可以看出,当扩张率设置为{1,2}时,测试集上各指标均达到最高。在加入了多层扩张卷积的情况下,2项指标均有提升,说明堆叠扩张卷积能在不缩小特征图的情况下,对模型性能的提升具有明显帮助。
2.4 语义信息指导的质量分数回归模块
人类视觉系统往往在理解图像内容的基础上对图像进行评分,因此本文引入超网络架构,利用全局语义特征作为质量分数回归模块的参数生成器,参数生成过程如图6所示。

图6 参数生成过程Fig.6 Parameter generation process
卷积和变形操作用于生成全连接层的权重系数W;平均池化和全连接操作用于生成全连接层的偏置系数b。卷积层和全连接层的输出通道数由回归网络中层的尺寸进行自适应的匹配。其中,为了提高网络的拟合能力,回归网络中的全连接层的节点数分别设为112、56、28、14和1,用于生成最终单幅图像的质量分数。
2.5 损失函数
为了提高主观质量分数和预测质量分数之间的等级相关性,本文充分利用了每批图像块之间的相对距离信息,融合了L1损失函数和三元组损失函数Ltriple,构建了混合损失函数Lmix。
L1损失函数有稳定的梯度,不会出现梯度爆炸的问题,常常被用于回归任务。
三元组损失函数Ltriple可以对差异性较小的输入向量学习到更细微的特征。已知使用三元组损失函数的模型会让锚点a和正例p的距离值更小,同时让锚点a和负例n的距离值更大,即|a,p|≤|a,n|,为了不让两边同时为0,增加了超参数A,得|a,p|≤|a,n|-A。
设smax、、、分别表示4张图像块的主观质量得分,按最高、次高、次低、最低分数的顺序排列,即smax<<<smin。pmax、、、pmin为它们对应的预测得分,如果预测得分pmax<<<pmin,则称模型预测分数和主观分数之间的相对排名信息保持一致。
为使模型预测分数和主观分数之间的相对排名信息保持一致,可视为让pmax和pmin的距离更大,pmax和的距离更小,故可将pmax当做锚点,将pmin当做负例,将当做正例,即为Ltriple(pmax,,pmin)。并且,让pmin和pmax的距离更大,pmin和的距离更小,故可将pmin当做锚点,将pmax看当负例,将当做正例,即为Ltriple(pmin,,pmax)。
故本文的混合损失函数为
式中λ为常量,经实验验证,λ取0.2。
由于|pmax,|≤|pmax,pmin|-A1,即A1≤-pmin,同时希望模型预测的质量分数和主观分数是一致的,所以,将-smin作为训练过程中A1的上界,设A1=s′max-smin;同理,设A2=smax-s′max。
3 实验结果
3.1 数据集和评估指标
为了验证本文所提模型MFFSE-NR的有效性,本文在2个真实失真图像数据集上进行了实验,这2个数据集分别是 LIVEC和康斯坦茨真实图像质量数据集(konstanz authentic image quality 10k database,KonIQ-10k)。
LIVEC数据集包含1 162张图像,每张图像由各种类型的移动相机在高度多样化的条件下拍摄。KonIQ-10k数据集包含10 073张图像,每张图像从大型通用多媒体数据集YFCC100M中采样而来,采样过程确保了图像内容的多样性和图像失真的真实性。
在测试阶段使用2个评估指标:斯皮尔曼等级相关系数(spearman rank-order correlation coefficient, SROCC)、皮尔逊线性相关系数(pearson linear correlation coefficient, PLCC),2个指标越接近1说明模型性能越好,公式为
式中:di2为第i个测试图像主观分数和预测分数的等级差异,si和pi分别为第i个图像的主观分数和预测分数,和为它们的平均值,N为测试图像数量。
3.2 参数设置
为了增强训练性能,同时尽可能保留更多的上下文信息,将数据集中的每幅图像都分割成若干个224×224的图像块。为了简单起见,直接将图像块所在图像的主观分数赋给图像块。训练集、验证集、测试集根据失真图像按8∶1∶1划分。采用混合损失函数Lmix进行训练,初始学习率为10-6,使用Adam优化器,权重衰减率为0.000 5,模型训练40个epoch,16个图像块为一个batch。
3.3 消融实验
为了验证多层特征融合、语义信息增强、混合损失函数Lmix的正确性,本文选取LIVEC数据集进行了消融实验,并使用FPS来评价各模型的计算效率,实验结果如表2所示。其中,基础模型由Res2Net50作为特征提取网络,每层的失真特征直接经过平均池化、全连接层后进行聚合,并利用最后一层的语义特征直接指导质量分数回归模块。

表2 消融实验Table 2 Ablation experiment
由表2可知,本文提出的改进方法中,在基础模型中分别加入特征融合方法、语义增强方法、混合损失函数后,LIVEC数据集上的SROCC和PLCC均有一定的提升;同时加入3个模块后,SROCC提高了2.7%,PLCC提高了3.3%,充分说明本文所提出方法能同时提高模型预测分数与人类评分之间的准确性及等级相关性。同时,由表2可知,本文提出的改进方法在实现较高图像质量评价指标的同时,检测速度达到了27 f/s。
3.4 单一数据集上的对比实验
为了评估本文所提算法MFFSE-NR的有效性,将MFFSE-NR与8种性能较高的盲图像质量评价算法进行比较。其中,选取6种与MFFSENR相近的基于深度学习的经典算法:用于无参考的加权平均深度图像质量评估(weighted average deep image quality assessment metric-no refenence, WaDIQaM-NR)、分级退化级联卷积神经网络(cascaded convolutional neural network with hierarchical degradation concatenation, CaHDC)、深度双线性卷积神经网络(deep bilinear convolutional neural network, DB-CNN)、从补丁到图片的盲图像质量测量算法(from patches to pictures blind image quality measurement, P2P-BM)、多尺度特征逐层融合的深度神经网络(deep neural network based on multi-scale features fusion layer-by-layer, MsFF-Net)和自适应超网络引导下的野外图像质量盲评估算法(blindly assess image quality in the wild guided by a self-adaptive hyper network, HyperIQA);同时,为了保证对比范围的完整性,选取2种基于手工特征的算法:盲/无参考图像空间质量评估器(blind/referenceless image spatial quality evaluator, BRISQUE)和基于高阶统计聚合的盲图像质量评估算法(blind image quality assessment based on high order statistics aggregation, HOSA)。实验结果如表3所示。
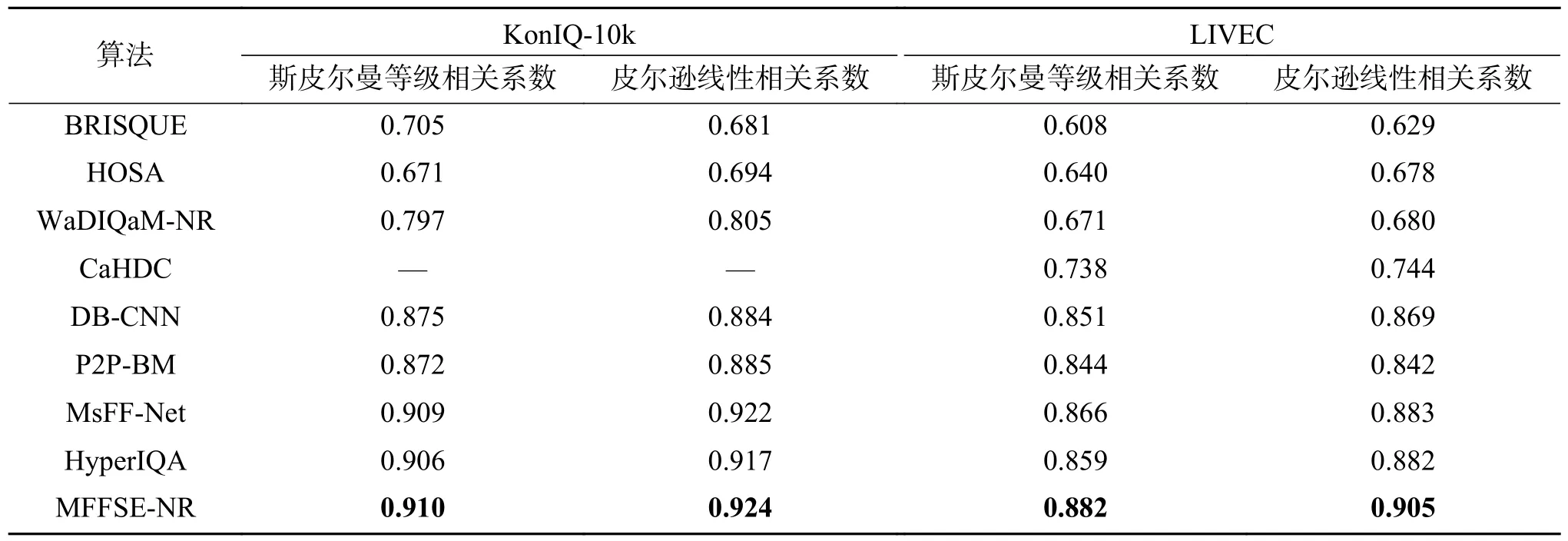
表3 不同方法的比较Table 3 Comparison of different methods
由表3可知,MFFSE-NR在KonIQ-10k和LIVEC 2个真实失真图像数据集上2项指标均优于基于手工特征的方法,与其他6种基于深度学习的方法相比,同样实现了更好的性能,充分说明了在面对真实失真图像时MFFSE-NR能有效提高模型预测的准确性和等级相关性,有效识别各种场景的失真。
3.5 跨数据集上的对比实验
为了验证本文所提算法MFFSE-NR的泛化能力,选取6种先进的基于深度学习的算法进行模型泛化能力的对比实验,实验结果如表4所示。

表4 跨数据集测试的SROCCTable 4 SROCC for cross dataset testing
由表4可知,在2组跨数据集实验中,针对真实失真图像测试的SROCC和PLCC指标均达到了最高,说明MFFSE-NR在面对现实生活中的失真时,泛化性能具有一定的先进性。针对不同失真程度的特征进行了融合,对语义信息进行了增强,并利用了带有排名信息的损失函数,在一定程度上能提升模型预测分数和主观质量分数之间的等级相关性和准确性,提高模型的泛化能力。
3.6 预测结果散点图
本文对KonIQ-10k数据集和LIVEC数据集上的测试结果进行了可视化展示,如图7所示。
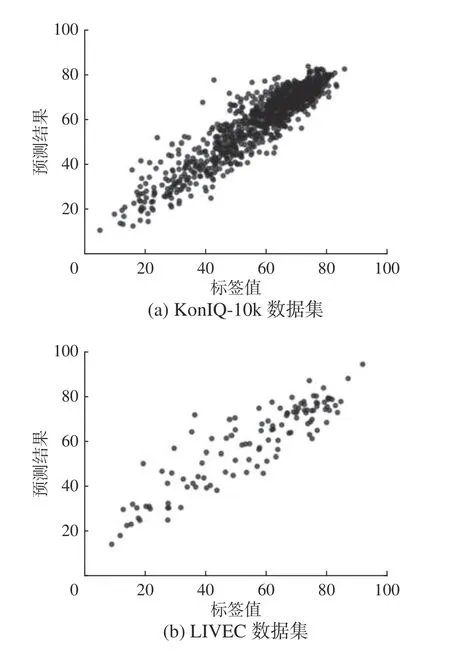
图7 KonIQ-10k和 LIVEC 数据集上测试结果的可视化展示Fig.7 Visualization of test results on the KonIQ-10k and LIVEC datasets
从可视化结果可看出,MFFSE-NR的预测分数与人类评分标签之间呈现出高度的一致性,说明本算法能对各类真实失真进行有效的识别,在一定程度上能模拟人类视觉系统对真实失真图像进行评分的过程,进而提升了真实失真图像质量评价的准确度。
4 结束语
为解决现有的无参考图像质量评价算法在面临真实失真图像时存在的各种问题,本文提出了多层特征融合和语义增强的盲图像质量评价算法,通过Res2Net50网络构建特征金字塔,提出了细粒度的基于注意力的多层特征融合模块,以应对真实失真图像中的局部和非均匀失真;探究了不同扩张率叠加的扩张卷积对语义信息的增强效果,提出了语义信息增强模块,并利用增强的高级语义特征生成质量分数回归模块的参数;最后考虑图像块质量分数之间的相对排名关系,引入了三元组损失,构建了混合损失函数Lmix,提高了模型对真实失真特征的学习能力。
但是,本方法将图像分割成图像块,并将图像的质量分数赋给图像块,在一定程度上引入了标签噪声,如何利用整幅图像进行质量分数的预测是本文未来的研究内容之一。此外,随着各种大规模数据集的出现,如何在复杂场景下对各种真实失真进行评价也是本文后续工作的研究重点。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:14
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
趣味(数学)(2019年12期)2019-04-13 00:29:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
小学生导刊(2017年16期)2017-06-15 20:29:38
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
