
组合光学和微波遥感的耕地土壤含盐量反演
2024-04-08 07:23刘瑞亮贾科利李小雨陈睿华王怡婧张俊华
干旱区地理(汉文版) 2024年3期
刘瑞亮, 贾科利, 李小雨, 陈睿华, 王怡婧, 张俊华
(1.宁夏大学地理科学与规划学院,宁夏 银川 750021;2.宁夏大学生态学院,宁夏 银川 750021)
自然或人为引起的土壤盐渍化是一种重大的环境灾害,广泛发生在内陆干旱、半干旱地区,严重影响农业生产和区域可持续发展。据估计,到2050年全球约50%的耕地会面临盐碱化[1],将成为世界性的生态问题[2]。因此,运用科学手段精准反演和监测耕地土壤盐渍化动态,及时治理和缓解耕地土壤盐渍化,对区域粮食生产和农业可持续发展具有重要意义。
卫星遥感手段能快速、宏观地获取土壤光谱特征,通过构建遥感监测模型,可以实现大范围土壤盐渍化监测和评估[3]。光学遥感可以提供多波段的光谱信息,对土壤盐分具有较强敏感性,研究者通过构建光谱指数实现土壤盐分的反演。陈红艳等[4]基于Landsat 8 OLI,引入第7 波段(2100~2300 nm)对植被指数进行改进,模型反演精度大幅提升。Wang等[5]等用Sentinel-2红边波段代替原来红光波段构建光谱指数,提高了光谱信息对土壤盐分的敏感性。然而单一光学数据易受成像时间、云雨等天气影响,依赖光谱特征提取盐渍化信息具有局限性[6]。微波遥感具有全天候工作能力,不易受气象条件和日照水平影响。同时,由于试验区有植被覆盖,光谱反射率受影响,而微波遥感能穿透植被,具有探测地表下目标的能力[7]。马驰等[8]基于Sentinel-1 雷达影像,分析垂直极化模式(VV)和交叉极化模式(VH)组合的后向散射系数与土壤盐分之间的关系,确定(VV2+VH2)/(VV2-VH2)极化组合的后向散射系数可以较好分离不同含盐量的土壤。张智韬等[9]利用Sentinel-1 雷达数据探究了内蒙古河套灌区不同深度土壤含盐量。尽管上述研究已经取得较好的结果,但多基于单一遥感数据,而组合光学和微波遥感反演土壤含盐量相关研究较少。肖森天等[10]组合光学影像和雷达后向散射特征,验证了光学与雷达数据组合在土壤盐渍化监测方面的可行性。然而该研究仅利用随机森林分类算法对土壤盐渍化进行了等级分类,并没有反演出土壤不同区域具体的盐分值。而本文利用随机森林的回归算法,能够反演得到研究区耕地像元尺度土壤含盐量,在一定程度上可以保留更多的盐分信息。
土壤盐渍化产生原因和土壤盐分组成复杂,在特征变量的选择上,不同区域的研究结果存在差异[11]。因此,需要采用不同方法来筛选特征变量。常用的方法有相关系数法(PCC)、逐步回归(SR)、灰度关联法(GC)和变量投影重要性法(VIP)等。王海峰[12]采用GC、SR 和VIP 3 种方法筛选变量构建模型,发现不同筛选方法下模型精度不同。Wang等[5]基于PCC、VIP、GC、随机森林(RF)筛选变量,并利用偏最小二乘回归(PLSR)建立模型,结果显示GCPLSR模型决定系数(R2)高于VIP-PLSR模型。不同建模方法反演效果不同,刘恩等[13]等采用多元线性回归和反向传播神经网络(BPNN)反演小开河引黄灌区土壤盐渍化,发现BPNN 的精度优于传统的多元线性回归。而陈红艳等[4]以Landsat 8 OLI建立的土壤含盐量反演模型中,支持向量机(SVM)精度优于BPNN。此外,RF 具有可处理非线性数据、抗拟合能力强的特点,在土壤盐分及主要离子定量估测方面已显示出较好效果[14]。变量筛选方法结合机器学习算法进行土壤盐分反演是近几年的研究热点,而比较不同变量筛选方法,并结合不同机器学习算法反演土壤含盐量相关研究较少。
本文以宁夏平罗县为研究区,基于光学和微波遥感影像,提取光谱指数和雷达极化组合指数,使用VIP 和GC 筛选特征变量,然后利用BPNN、SVM和RF 机器学习算法构建耕地土壤含盐量反演模型,评定不同变量输入和不同建模方法下土壤含盐量反演精度,并反演研究区耕地土壤盐分分布,为银川平原耕地土壤盐渍化的潜在识别和防治提供理论依据和技术支持。
1 数据与方法
1.1 研究区概况
研究区位于宁夏石嘴山市平罗县(38°26′60″~39°14′09″N,105°57′40″~106°52′52″E),地处贺兰山东麓洪积扇和黄河冲积之间、宁夏平原北部,是重要的灌溉农业区。年平均降水量150~203 mm,年蒸发量超过1825 mm,蒸降比达到10:1。主要土地利用类型为耕地、林地、草地和盐碱荒地,耕地总面积约9.5×104hm2,主要分为水田和旱地。试验区(图1)选择平罗县耕地区域进行布设,分别位于平罗县山前洪积扇区、西大滩碟形洼地、冲积平原区、灵盐台地和河滩区五大地貌单元。同时,采样时间处于春耕农忙之前,人为扰动较少。
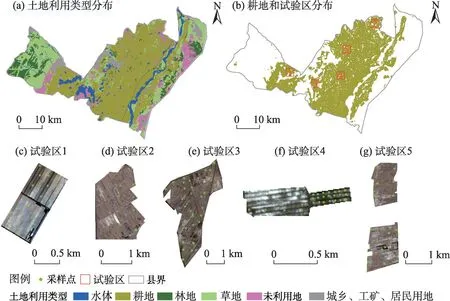
图1 研究区土地利用类型及试验区分布Fig.1 Land use types of the study area and distribution of the test areas
1.2 数据来源与预处理
1.2.1 土壤样本采集与盐分测定样本采集于2022年3 月20 日—4 月8 日,采样时利用五点法采集0~20 cm 土壤,编号装入采样袋带回实验室。土样经过自然风干、研磨,并用2 mm孔径筛过滤后,以水土5:1配置提取液[15],运用电导率法[16]计算样本的含盐量,每个样本重复3 次,取平均值作为该点的盐分值。
按含盐量大小划分样本盐渍化程度[17]。样本总体变异系数为79.154%(表1),呈中等强度变异,表明样本分布离散,具有普适性。将样本按含盐量大小进行排序,每隔2 个样本取出1 个用于模型验证,剩余样本用于建模,共选取70 个样本作为建模数据,34个样本作为验证数据。建模集与验证集样本分布趋势与总样本分布趋势一致(图2),说明样本划分合理,可用于模型构建和验证。
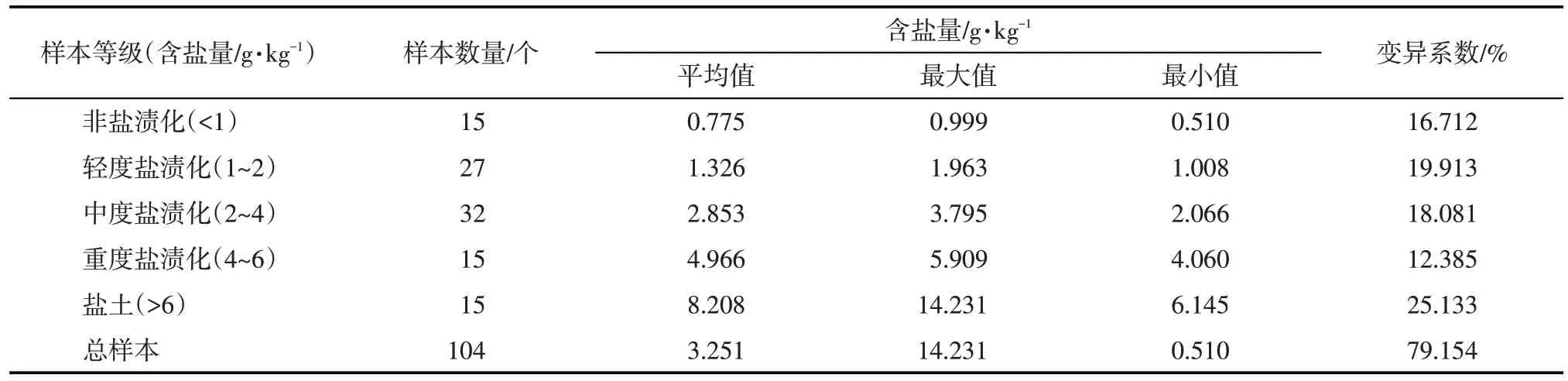
表1 土壤样本描述性统计Tab.1 Descriptive statistics of soil samples
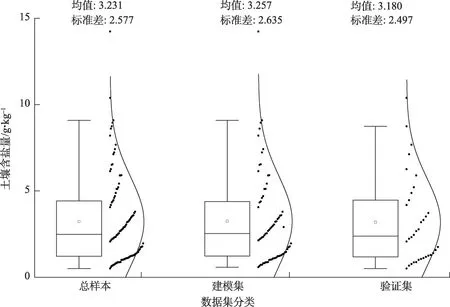
图2 不同数据集土壤样本分布Fig.2 Distributions of soil samples in different datasets
1.2.2 遥感影像数据获取与处理Landsat 9 OLI 遥感影像来源于美国地质勘探局(https://earthexplorer.usgs.gov),行列号为129/33,成像时间为2022年4月5 日,云量为4.7%。在ENVI 5.3 中对影像进行辐射校正、裁剪等预处理,计算盐分指数和植被指数,如表2所示。
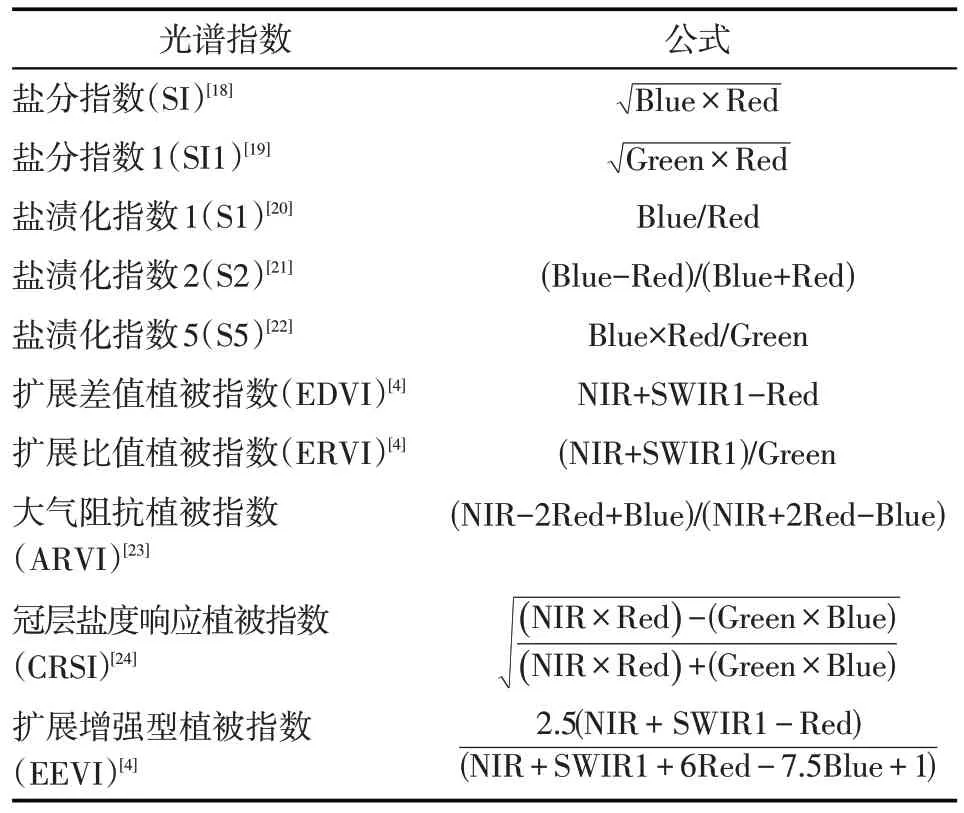
表2 光谱指数计算公式Tab.2 Calculation formulas of spectral indices
Sentinel-1 数据来源于欧洲航空航天局数据网站(https://scihub.copernicus.eu),成像时间为2022年4 月1 日,数据级别为Level 1,包括垂直极化模式和交叉极化模式。利用SNAP软件对数据进行热噪声去除、轨道文件校正、辐射定标等处理。已有研究指出[25],对于单极化雷达数据,如提取的土壤信息量相对较少,研究结果会受到一定影响。因此,将雷达影像的极化方式进行组合,以提高土壤含盐量反演精度[26-27]。本文所用指数如表3所示。

表3 雷达极化组合指数计算公式Tab.3 Calculation formulas of radar polarization combination indices
1.2.3 土地利用数据获取及处理土地利用数据从中国科学院资源环境科学与数据中心(http://www.resdc.cn)获取,根据分类标准将研究区土地利用分为6类(图1):耕地、林地、草地、水域、未利用地以及城乡、工矿、居民用地,提取耕地作为研究对象。
1.3 研究方法
首先进行数据获取和处理,包括光谱指数、雷达极化组合指数的计算,土壤含盐量的测定;然后采用变量投影重要性法和灰度关联法进行土壤含盐量特征变量筛选;最后利用筛选的变量,采用3种不同机器学习算法分别构建光谱指数模型、雷达极化组合指数模型、光谱指数和雷达极化组合指数协同模型,并进行精度验证,选择最优模型进行研究区耕地土壤含盐量反演。具体研究思路如图3所示。

图3 研究路线Fig.3 Research route
1.3.1 土壤含盐量特征变量筛选采用变量投影重要性法和灰度关联法进行特征变量筛选。变量投影重要性法是一种基于偏最小二乘回归的变量筛选方法[28]。对于给定的自变量,变量投影重要性不仅表示自变量对因变量的影响,还考虑了其他自变量对因变量的间接影响。计算公式为:
式中:VIPj为j变量的重要性;p为自变量个数;F为主成分总数;f为主成分;SSYf为f主成分解释的方差平方和;SSYtotal为因变量平方和;Wjf2 为j变量在f主成分中的重要性。VIPj越大,自变量对因变量的解释力越强。当自变量的VIPj大于1时,独立变量被判断为重要的自变量[29]。
灰色关联度分析是一种多因素统计方法,其目的是通过一定的方法原理确定系统中各因素的主要关系,用灰色关联度刻画因素间关系的强弱和次序,找出影响最大的因素[30]。计算公式为:
式中:GCD为灰色关联度;t为变量;n为变量个数;γ为关联系数;x0(t)为参考序列;xi(t)为比较序列,其中:
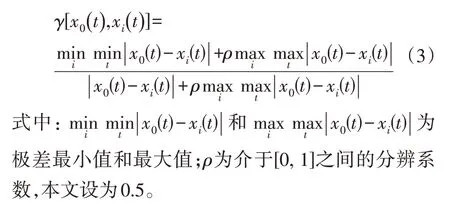
1.3.2 机器学习模型
(1)反向传播神经网络(BPNN)
BPNN基于反向传播误差方式对数据集进行训练,达到误差最小化的目的[31]。该模型是对非线性映射的全局逼近,拥有较强的自适应和自学习能力[32]。本文模型训练目标最小误差设置为0.00001,迭代次数设置为1000次,学习率设置为0.01。
(2)支持向量机(SVM)
SVM 基于结构风险最小原理,依靠有限的样本来检索全局最优解,对未知点有较好的泛化效果[33]。本文选用RBF(Radial basis function)为SVM核函数类型,惩罚因子(c)与核函数(g)由样本训练得到,分别为13和5。
(3)随机森林(RF)
RF是基于多棵回归树的集成学习方法,通过结合多个决策树,并平均其结果使得决策树泛化误差收敛从而产生更好的预测结果[34]。RF 善于处理变量间的非线性关系,预测性能受回归树棵数、最大深度、最小叶子数等参数影响[35]。本文回归树棵树为200,最小叶子数为4。
1.3.3 模型评价为定量比较不同算法反演土壤含盐量的精度,本文选择2 个常用指标决定系数(R2)和均方根误差(RMSE)来进行量化。R2越大,RMSE越小,说明模型拟合效果越好。
2 结果与分析
2.1 土壤含盐量的特征变量筛选
利用式(1)、式(2)计算指数的变量投影重要性(图4)和灰色关联度(图5),筛选出特征变量参与建模。结果表明,光谱指数S1、S2、ARVI、CRSI、EEVI(图4a)和雷达极化组合指数VV、VH、VV+VH、VV2+VH2、VH2-VV(图4b)重要性大于1,说明这些变量是指示土壤盐分的重要变量,可作为特征变量参与建模。
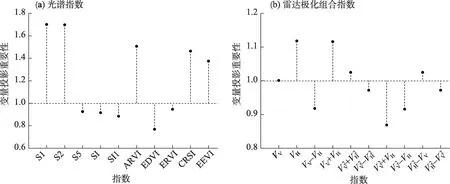
图4 特征变量与土壤含盐量的投影重要性Fig.4 Projection importance between soil salt content and characteristic variables
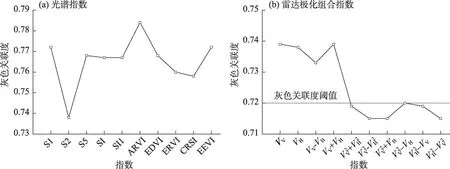
图5 特征变量与土壤含盐量的灰色关联度Fig.5 Grey relativity between soil salt content and characteristic variables
由图5a可知,光谱指数与土壤含盐量灰色关联度均大于0.73,其中ARVI 灰色关联度最高,达到了0.784;S2灰色关联度最低,为0.738。雷达极化组合指数与土壤含盐量灰色关联度(图5b)介于0.71~0.75,最高为VV+VH的0.739。为实现特征变量筛选,本文设光谱指数和雷达极化组合指数灰色关联度阈值为0.720,统计基于灰度关联分析的土壤含盐量敏感指数情况。结果发现,利用灰度关联法筛选的光谱特征变量较雷达特征变量多,其中,10 个光谱指数都为特征变量,雷达极化组合指数中筛选出VV、VH、VV-VH、VV+VH和VV2-VH共计5 个特征变量参与建模。
2.2 模型构建与验证
光谱指数模型中,以土壤含盐量作为因变量,选取VIP筛选的S1、S2、ARVI、CRSI、EEVI作为自变量构建VIP-BPNN、VIP-SVM、VIP-RF 模型;选取GC筛选的S1、S2、S5、SI、SI1、ARVI、EDVI、ERVI、CRSI、EEVI 作为自变量构建GC-BPNN、GC-SVM、GC-RF模型。
雷达极化组合指数模型中,选取VIP筛选的VV、VH、VV+VH、VV2+VH2、VH2-VV作为自变量构建VIP-BPNN、VIP-SVM、VIP-RF 模型;选取GC 筛选的VV、VH、VV-VH、VV+VH、VV2-VH作为自变量构建GC-BPNN、GCSVM、GC-RF模型。
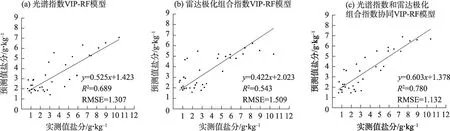
结果发现(表4),光谱指数模型中,利用VIP 筛选变量构建的3个模型验证集R2均大于0.46,RMSE均小于1.93,其中VIP-RF 模型精度最高,建模集和验证集R2分别为0.726 和0.689,RMSE 分别为1.163和1.307,模型具有较强的稳定性。利用GC 筛选变量构建的3 个模型验证集R2整体较低,其中GCSVM 模型验证效果较好,GC-BPNN 模型次之,GCRF 模型验证集误差最大。雷达极化组合指数模型中(表4),VIP筛选变量建立的模型建模集和验证集R2呈现VIP-RF>VIP-SVM>VIP-BPNN 的规律;GC 筛选变量建立的模型建模集和验证集R2呈现同样的规律,表明随机森林机器学习算法在雷达极化组合指数模型中具有较好的反演能力。比较光谱指数模型和雷达极化组合指数模型发现,光谱指数模型精度普遍高于雷达极化组合指数模型,这可能与本文盐分采样为0~20 cm 表层土壤有关,雷达数据更适合于探测地表下目标,而光学数据具有丰富的地表反射率信息。
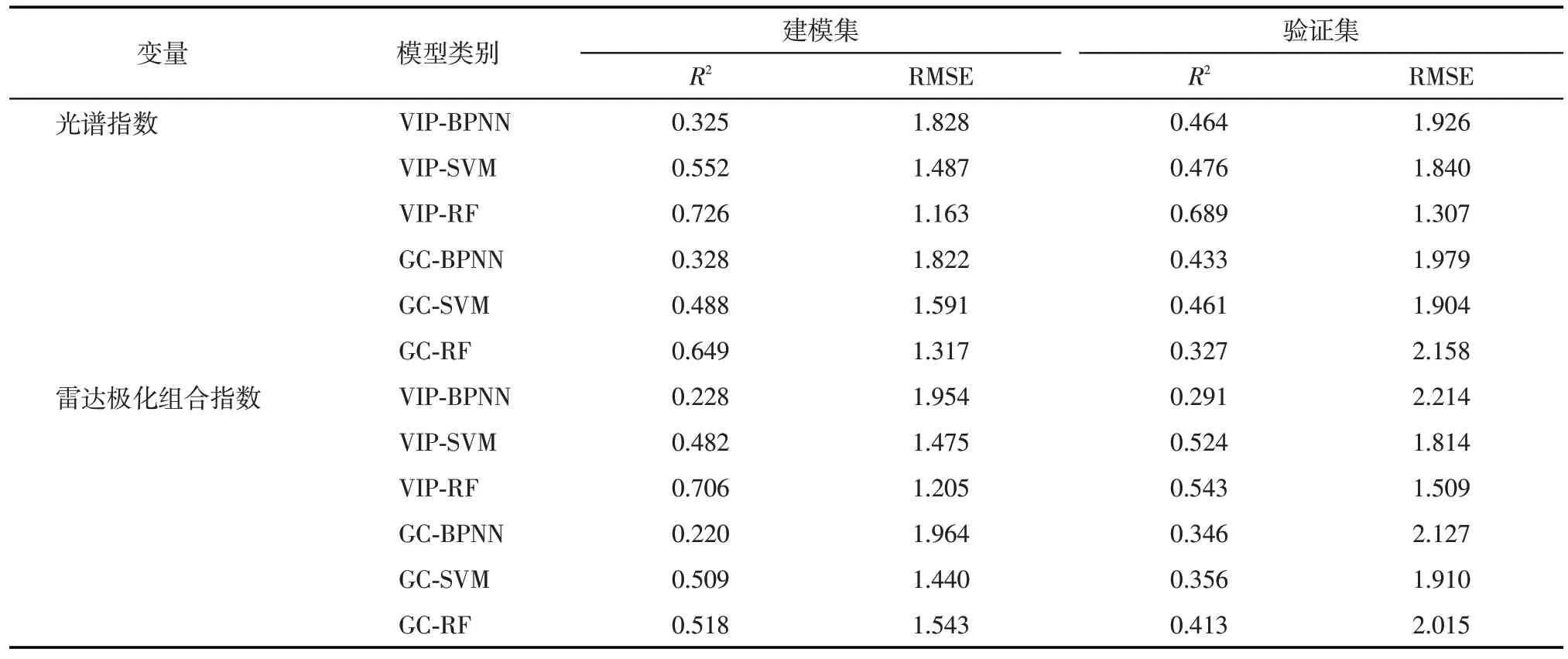
表4 基于单一遥感数据的机器学习模型Tab.4 Machine learning models based on single remote sensing data
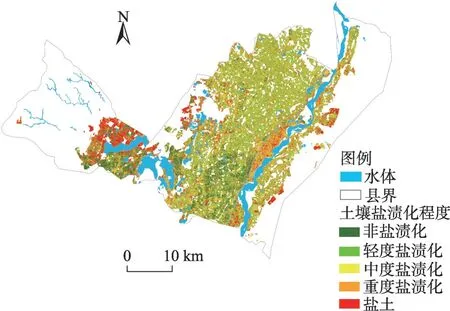
对比2 种变量筛选方法建立的模型精度(表4)发现,光谱指数模型中,验证集精度VIP-RF>GCRF,VIP-BPNN>GC-BPNN,VIP-SVM>GC-SVM。雷达极化组合指数模型中,除VIP-BPNN 表5 基于多源遥感数据的机器学习模型Tab.5 Machine learning models based on multi-source remote sensing data 组合光谱指数和雷达极化组合指数模型反演精度较单一光谱指数和雷达极化组合指数模型大幅提高。其中,VIP-BPNN 模型验证集R2分别提高0.124和0.297,RMSE 分别降低0.237和0.525。VIPSVM 和VIP-RF 模型建模集和验证集R2均大于0.6,RMSE均小于1.6,模型准确度和学习性能更强。其中,VIP-RF建模集R2较单一光谱指数和雷达极化组合指数模型分别提高0.065和0.085,R2达到了0.791,RMSE 分别降低0.147 和0.189;验证集R2分别提高0.091和0.237,R2达到了0.780,RMSE分别降低0.175和0.377,表明光谱指数和雷达极化组合指数协同反演模型效果优于单一数据源模型,说明多源遥感数据参与建模能够有效提高土壤含盐量预测精度。 图6为基于VIP-RF构建的光谱指数模型,雷达极化组合指数模型以及协同模型验证集的实测值与预测值的散点图。结果表明,组合光谱指数和雷达极化组合指数共同建立的VIP-RF 模型拟合效果最好,故选择此模型对研究区耕地土壤含盐量进行反演。 图6 不同数据源变量的VIP-RF模型Fig.6 VIP-RF models of different data source variables 选择精度最佳的光谱指数和雷达极化组合指数VIP-RF 协同反演模型对平罗县耕地进行土壤盐分反演,得到平罗县耕地土壤盐分反演等级图(图7),利用ArcGIS 统计不同盐渍化等级土壤面积(表6)。由结果可知,平罗县耕地盐渍化情况较为严重,盐渍化土壤占比达到了耕地总面积的86.81%,中度盐渍化高达33.54%,重度盐渍化和盐土主要分布在中西部和东部引黄灌溉区。盐渍化反演结果与实地采样情况较为一致,表明组合多源遥感数据构建反演模型在研究区耕地土壤盐分反演中具有可行性。 表6 耕地土壤含盐量反演等级统计Tab.6 Grade statistics of soil salinity inversion in cultivated land 图7 耕地土壤含盐量反演等级分布Fig.7 Grade distribution of soil salinity inversion in cultivated land 组合多源遥感数据反演土壤含盐量已成为近年来研究热点,但如何高效组合不同数据源,减少影像数据处理过程中存在的部分光谱特征、雷达信息丢失和失真等问题,还有待继续研究。余祥伟等[36]利用乘积变换、G-S变换、PC 变换、小波变换等算法将星载SAR 和Landsat 8 OLI 进行融合,发现G-S 变换和PC变换能够较好实现星载SAR 和光学影像的融合,但仍然存在信息量、空间分辨率增加的同时,光谱特征丢失的问题。姜红等[37]研究发现,以雷达后向散射系数和改进型温度植被干旱指数共同作为SVM模型输入参数时,土壤水分监测精度显著提高。因此,本文组合VIP 筛选得到的光谱指数和雷达极化组合指数共同参与建模,充分结合光学遥感和微波遥感优势,较好地保留了土壤的光谱特征和雷达信息。 最优变量筛选方法结合最优机器学习算法可以有效提高反演精度。本文比较VIP 和GC 筛选变量优劣,发现VIP的结果更为可靠,与王海峰等[12]的研究结果相同。这是因为VIP通过判断特征对模型准确率的影响和加入噪声干扰前后模型准确率的变换来实现对模型精度的优化构建,但李明亮[38]指出GC筛选变量建模同样能够有效提高模型拟合精度。有研究[39]指出,土壤成分对反演模型的性能有很大的影响,因此本文所选变量筛选方法是否适用于其他研究区有待商榷。本文选择BPNN、SVM 和RF 3 种传统机器学习算法反演土壤盐分,发现BPNN 和SVM 精度较低,RF 精度最高,能够满足研究区土壤含盐量的反演,这与张智韬等[40]所得结论基本一致。可见,将RF应用于土壤含盐量反演,能够在一定程度上提升模型反演精度。而近年来,诸多学者尝试引入网格搜索、随机搜索和贝叶斯等算法对机器学习进行超参数优化,Chen等[41]提出了一种基于树结构Parzen估计器(TPE)优化算法的极端梯度提升(XGBoost)模型,结果表明TPE 联合优化算法显著提高了XGBoost 模型的性能,具有较强的泛化能力。Wang等[42]同样在贝叶斯优化框架下,将超参数和特征选择相结合,对光梯度增强机(Light-GBM)模型进行自适应联合优化。Xu等[43]提出了一种自适应遗传算法(AGA)的支持向量机输入特征和超参数同时识别的新方法,并使用网格搜索优化超参数。这些优化算法的引入表明学者们开始关注特征选择和超参数调整对机器学习模型性能的影响,以及输入特征和超参数之间的复杂依赖性和相互作用,进而从模型层面提高预测精度。因此,之后的研究可以考虑引入不同优化算法,并结合特征变量筛选方法,以期进一步提高模型的反演精度和普适性。 本文选择光谱指数和雷达极化组合指数协同VIP-RF 模型反演研究区耕地土壤含盐量,结果表明,研究区耕地盐渍化已较为严重,盐渍化土壤占耕地总面积的86.81%,中度盐渍化土壤分布范围最广,达到了耕地总面积的33.54%,这与前人研究[44]所得结论相符。平罗县地处内陆干旱区,气候干燥,土壤透气、透水性差,易产生盐渍化。中西部为山前洪积扇区和西大滩碟形洼地,排水条件差。东部引黄灌溉区灌溉方式不合理,常出现过量引水和引黄河大水漫灌现象,灌溉水的渗漏引起地下水位升高和强烈蒸发,造成盐渍化愈演愈烈,进而严重影响农业生产。因此,利用遥感监测,结合盐渍土改良与治理的主要机制,如物理调控、化学调理、灌排管理和生物改良[45],因地制宜,提出可行性的治理措施,以减少盐渍化给当地农业发展和自然环境造成的危害。 本文土壤样本采样与影像获取时间不一致,而土壤含盐量存在短期变化情况,影像数据难以真实反应地表情况,数据存在不确定性。后续研究可以考虑利用无人机技术,在同一时间段采集土壤样本和遥感数据,且无人机数据分辨率高达厘米级,模型反演精度会更高。 本文采用VIP和GC筛选特征变量,利用光谱指数、雷达极化组合指数、光谱和雷达指数组合的3种不同数据源构建基于不同机器学习算法的土壤盐分反演模型,得到以下结论: (1)基于GC 方法确定的光谱指数和雷达极化组合指数数量差异较大,筛选变量所构建的模型反演效果较差;基于VIP 方法确定的光谱指数和雷达极化组合指数数量相同,筛选变量所构建的模型精度相对较高。 (2)RF模型反演效果最优,SVM次之,BPNN效果最差,说明RF较其他2种机器学习算法更适于该研究区耕地土壤含盐量反演。 (3)组合多源遥感数据构建的VIP-RF 模型验证集R2=0.780,较单一光谱指数模型和雷达极化组合指数模型分别提高0.091 和0.237,说明组合多源遥感数据能够有效提高土壤含盐量反演精度,有助于更加精确地研究区域土壤盐分分布情况,提升土壤盐渍化监测水平。 (4)根据反演结果可知,平罗县耕地盐渍化较为严重,非盐渍化土壤仅占耕地总面积的13.19%,轻度盐渍化和中度盐渍化土壤较多,占比分别为23.77%和33.54%,29.5%的耕地恶化为重度盐渍化和盐土。
2.3 模型应用

3 讨论
4 结论
猜你喜欢
农业知识(2022年9期)2022-10-13
现代财经-天津财经大学学报(2022年5期)2022-06-01
甘肃科技纵横(2022年11期)2022-03-21
资源信息与工程(2021年5期)2022-01-15
中国生态农业学报(中英文)(2021年8期)2021-07-28
矿产勘查(2020年11期)2020-12-25
工业水处理(2020年10期)2020-03-08
电子测试(2017年15期)2017-12-18
水土保持研究(2016年1期)2016-10-26
文物保护与考古科学(2016年4期)2016-05-17
