
面向存算联调的跨云纠删码自适应数据访问方法
2024-03-23 08:04张凯鑫王意洁阚浚晖
计算机研究与发展 2024年3期
张凯鑫 王意洁 包 涵 阚浚晖
(并行与分布计算全国重点实验室(国防科技大学) 长沙 410073)
(国防科技大学计算机学院 长沙 410073)
随着数字经济生态和云计算技术的蓬勃发展,用户的云计算需求量迅速扩大且需求越发多样化.由于单一云厂商服务能力有限,逐渐难以满足用户的全部需求.跨云调度计算任务可有效缓解单一云厂商服务能力不足以满足用户需求的问题.为此,研究者提出了云际计算技术,以云厂商之间的开放协作为基础,有效破解云厂商锁定问题,方便开发者通过软件定义方式定制云服务,为计算任务跨云调度创造了基础条件.
然而,由于跨云调度的计算任务通常需要跨云访问数据(即跨云存算联调),且在诸如机器学习、气象预报、基因测序、粒子物理等领域的计算任务的数据集往往高达数百TB[1],因而跨云调度后的计算任务的执行效率受到跨云数据访问速度的严重制约.基于数据冗余(纠删码和多副本)技术的跨云数据访问方法是提高数据跨云访问速度的重要技术途径之一.相较于多副本[2-5],纠删码具有更高的数据容错性和更低的数据冗余度[6-7].因此,基于纠删码的跨云数据访问方法成为了当前的研究热点.基于纠删码的跨云数据访问方法的基本思想为:首先,把原始数据对象分为k个数据块;然后,把k个数据块编码为n个编码块(这n个编码块中可能包含k个数据块),使用这n个编码块中的任意n-d+1 个编码块均可重构出k个数据块;接着,把n个编码块存储到多个云上;当某个数据访问节点需要访问数据时,选择若干云请求n-d+1 个编码块,用这些编码块重构出k个数据块,并将这些数据块重组为原始数据对象[8].
由于云间网络带宽通常远低于云内网络带宽,而基于纠删码的跨云数据访问方法需要跨多个云传输编码块.因此,基于纠删码的跨云数据访问方法的编码块传输用时通常较长,使得其数据访问速度较慢.
基于纠删码的跨云数据访问方法主要可从2 个方面来缩短编码块传输用时:
1)合理制定编码数据访问方案[9-13].由于纠删码可使用任意n-d+1 个编码块重构出k个原始数据块,因此基于纠删码的跨云数据访问方法可选择与数据访问节点间延迟较低(或带宽较高)的云上的编码块来重构数据,从而缩短编码块传输用时.
2)合理缓存编码块[14-20].基于纠删码的跨云数据访问方法可通过把常被访问的编码块缓存在相应的数据访问节点附近,以缩短整体的编码块传输用时.
在引入编码块缓存的情况下,基于纠删码的跨云数据访问方法的编码块传输用时显著受到缓存命中量(从数据访问节点对应的缓存中读取的数据总量)、缓存命中增效(缓存命中时编码块传输用时的缩短量)、低传输速度编码块访问量的影响.
然而,现有基于纠删码的跨云数据访问方法存在2 个方面的不足,使得其缓存命中量和缓存命中增效较低且低传输速度编码块访问量有待降低:
1)缓存管理粒度较粗.现有基于纠删码的跨云数据访问方法以编码块为单位管理缓存,缓存编码块只存在命中和未命中2 种状态,无法利用部分命中的缓存编码块,因而其缓存命中量较低.
2)未协同优化缓存管理与编码数据访问方案.现有基于纠删码的跨云数据访问方法在选择加入缓存的编码块时,未综合考虑编码数据访问方案制定算法选择各编码块用于重构数据的概率以及各编码块的实际传输速度,不利于提高缓存命中量和缓存命中增效;或者在制定编码数据访问方案时,未充分考虑缓存对各编码块传输速度的影响,不利于准确评估各编码块传输速度,因而难以有效减少低传输速度编码块访问量.
现有基于纠删码的跨云数据访问方法存在的缓存命中量低、缓存命中增效较低、低传输速度编码块访问量大的问题,导致其编码块传输用时较长,进而使得其数据访问效率仍有待提升.
为此,本文首先提出了一种基于星际文件系统(interplanetary file system,IPFS)的跨云存储系统框架(IPFS-based cross-cloud storage system framework,IBCS).IBCS 基于IPFS 的数据分片管理机制实现细粒度缓存管理,可提高缓存命中量.此外,在引入缓存后,同一编码块的多个副本可能同时存储在多个云上,IBCS 可充分利用这些副本提高编码块的传输并行度,从而减少低传输速度编码块.
然后,在框架IBCS 下,本文提出了一种面向存算联调的跨云纠删码自适应数据访问方法(adaptive erasure-coded data access method for cross-cloud collaborative scheduling of storage and computation,AECAM),可通过协同优化缓存管理与编码数据访问方案提高缓存命中量和缓存命中增效.具体提出2 个关键算法:
1)编码数据访问方案自适应制定算法(adaptive formulating algorithm of erasure-coded data reconstruction scheme,AFERS).AFERS 首先根据IPFS 集群的各个存储节点与数据访问节点间的传输延迟、各编码块在各存储节点里的存储状态(含正常存储、长期缓存、临时缓存等)、数据访问节点的类型(云内计算节点、云外计算节点),综合评估指定节点访问数据的过程中各编码块的传输速度.然后,根据各编码块传输速度的评估值,自适应制定可避免访问传输速度评估值低的编码块的编码数据访问方案.
2)基于数据访问过程感知的缓存管理算法(cache management algorithm based on data access process-aware,CADA).CADA 根据数据访问过程中AFERS 对各编码块传输速度的评估值,以及被传输的编码块的实际传输速度,决定各编码块的缓存优先级.优先在数据访问节点附近缓存易被AFERS 选中(传输速度预估值高)且实际传输速度相对较低的编码块,因而能同时提高缓存命中量及缓存命中增效.
1 相关工作
1.1 纠删码数据访问方案
纠删码数据访问方案可由二元组〈type,blocks〉组成.其中type为数据访问方案的类别,包括直接数据访问方案和降级数据访问方案;blocks为访问数据时需获取的编码块的列表.
1)直接数据访问方案
如图1 所示,直接数据访问方案是指数据访问节点直接获取被访问数据对象的k个数据块,然后将它们重组成被访问数据对象.直接访问方式无需进行解码运算且实现简单,因而大部分分布式存储系统(GFS(Google file system)[3],Lustre[4],Ceph[5]等)均默认采用这种数据访问方式.

图1 直接数据访问方案示意图Fig.1 Illustration of direct data access scheme
对于直接数据访问方案,需获取的编码块固定为k个数据块.因此,直接数据访问方案只有1 套.
2)降级数据访问方案
如图2 所示,降级数据访问方案是指数据访问节点获取被访问数据对象的任意n-d+1 个编码块,并将其解码为k个数据块,然后用解码出的数据块重组出原始数据对象.由于降级访问会带来额外的计算开销,因此在大部分存储系统中,仅当无法正常获取数据块时才会采用降级数据访问方案[6].
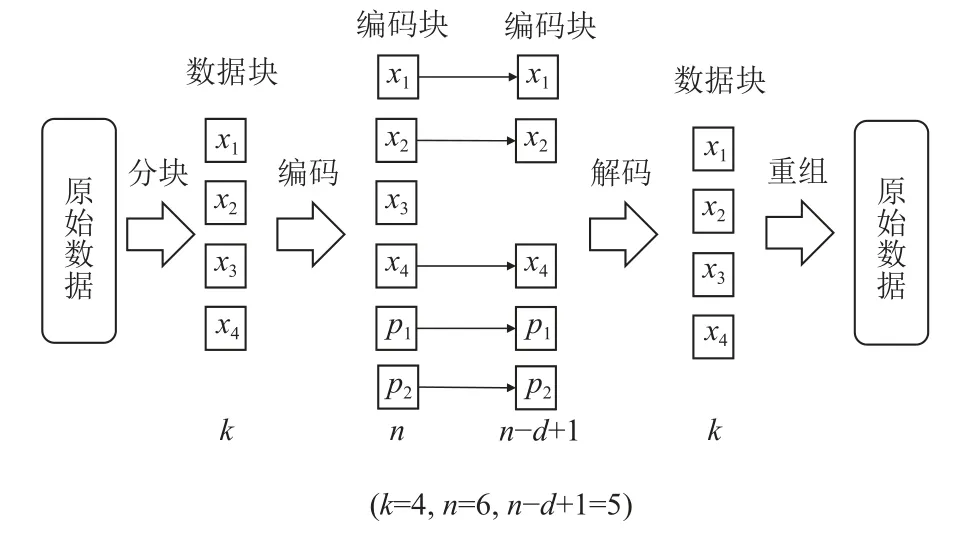
图2 降级数据访问方案示意图Fig.2 Illustration of degraded data access scheme
对于降级数据访问方案,需获取的编码块列表blocks的可能取值有组.因此,降级数据访问方案共有套.
1.2 广域纠删码数据访问技术
在广域部署的基于纠删码的存储系统(如基于纠删码的跨云存储系统)进行数据访问时,通常需要在低带宽链路上传输大量编码块,导致编码块传输速度成为了数据访问的瓶颈.为此,研究者提出了一系列广域纠删码数据访问技术,主要分为基于数据访问方案优化的广域纠删码数据访问技术和基于缓存的广域纠删码数据访问技术.
1)基于数据访问方案优化的广域纠删码访问技术
基于数据访问方案优化的广域纠删码访问技术的基本思想是:传统分布式存储系统默认采用直接数据访问方案,因为其计算量较小.然而,在广域环境中,不同域的节点间的数据传输速度远低于域内节点间的数据传输速度,且不同域节点的I/O 性能差异较大.如果数据访问节点与大量数据块存储节点属于不同的域或者大量数据块存储节点的I/O 性能较低,则会导致必须访问数据块的直接数据访问方案的传输开销大于某些降级数据访问方案.因此,基于数据访问方案优化的广域纠删码访问技术会综合评估各编码块存储节点和客户端间的带宽、各编码块存储节点的综合性能,求得效率较高的数据访问方案.
例如,Saeed[12]以传输开销和服务延迟优化为目标,提出一种跨地域分布云环境下的纠删码访问方法Sandooq.Sandooq 以编码块请求在各云数据中心的排队时延,以及以数据访问节点与存储各编码块的云数据中心的物理距离为依据建立读取优化函数,按照梯度下降的方法寻找最优数据访问方案.Zhang等人[13]提出基于节点性能感知和精确距离估算的纠删码降级访问方法NADE.NADE 首先收集存储节点的容量、CPU 频率、吞吐量、响应时间、时延等指标的历史数据,并以此为依据构建各节点之间的欧氏距离.然后,根据各节点间欧氏距离估算客户端获取每个编码块的开销,并以此为依据求出最优数据访问方案.此外,Rashmi 等人[14]提出了一种延迟绑定的纠删码访问方法LBA.采用LBA 的数据访问节点会请求多个编码块,并选择先传输到数据访问节点的n-d+1 个编码块重构原始数据对象.
2)基于缓存的广域纠删码数据访问技术
基于缓存的广域纠删码数据访问技术的基本思想是:由于跨域传输编码块的开销较大,因而把部分访问频率高、传输速度低的编码块缓存在数据访问节点附近以提高后续数据访问速度.
例如,Zhang 等人[15]提出了一种基于慢节点感知的编码数据缓存系统POCache,用于提高广域纠删码的数据访问速度.POCache 将校验块缓存到数据访问节点附近,并在访问数据时优先请求数据块.当数据块的传输速度过低时,POCache 将选择从缓存节点获取校验块,并使用缓存校验块与访问效率正常的数据块重构原始数据对象.此外,POCache 可支持用户自行选择缓存引入算法和缓存驱逐算法.然而,POCache需要测出各数据块传输速度后才能确定用于重构原始数据对象的编码块,对其数据访问速度带来不利影响.Halalai 等人[16]提出了一种基于缓存收益评估的编码数据缓存系统Agar,将编码块的全局访问次数与各数据访问节点获取该编码块的开销的乘积作为各数据访问节点缓存该编码块的预期收益,并将预期收益较高的编码块缓存到对应的数据访问节点.
整体而言,现有基于数据访问方案优化的广域纠删码访问技术和基于缓存的广域纠删码数据访问技术均可提高广域环境(含跨云环境)下的纠删码数据访问效率,但存在2 点不足:首先,现有工作中的缓存管理优化与编码数据访问方案优化结合不紧密,未同时做到根据缓存编码块分布情况决定数据访问方案、根据数据访问方案制定策略决定编码块缓存优先级,导致其缓存命中量和缓存命中增效仍有待提高.此外,现有工作为优化缓存管理与编码数据访问方案,通常需要耗费较多额外的计算、网络、存储资源以采集、维护存储节点状态信息及各类节点间的网络信息.
1.3 星际文件系统
星际文件系统是一个去中心化的分布式文件系统[21-23],基于分布式哈希表(distributed Hash table,DHT)、BitTorrent 点对点文件共享协议、Git 分布式版本控制、Merkle DAG 等已有技术,实现了数据的分片存储、内容寻址及点对点(peer-to-peer,P2P)高速传输.
1)数据分片存储
IPFS 将用户数据分为若干个大小不超过256 KB的数据分片,并使用Merkle DAG 来组织各个存储节点上的数据分片.如图3 所示,Merkle DAG 的末端节点的内容为各个数据分片,其他节点的内容为其所有子节点的内容组合的哈希值.
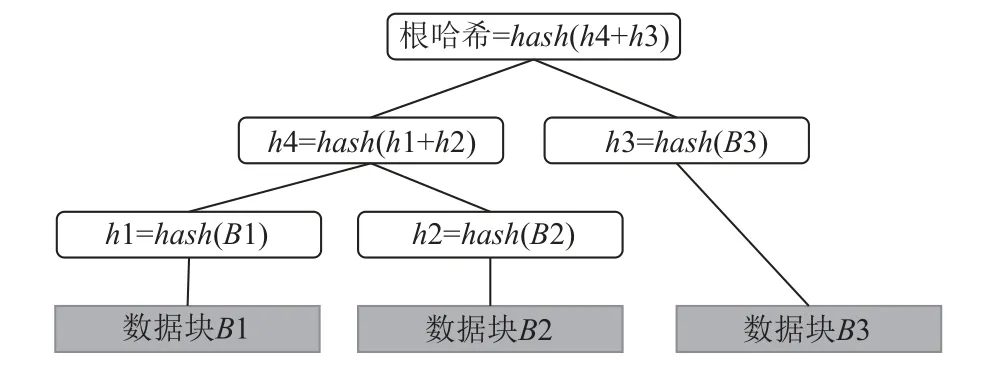
图3 Merkle DAG 示意图Fig.3 Illustration of Merkle DAG
此外,Merkle DAG 的每个顶端节点对应一个数据对象,该数据对象的内容为其子孙节点中末端节点内容(数据分片)的组合.
分片存储数据并使用Merkle DAG 来维护数据对象和数据分片间的关系的主要优点是:在同一IPFS存储节点上,多份用户数据对象均含有的数据分片只需要被实际存储1 份,因而可显著降低存储开销.
2)数据内容寻址
在IPFS 中,每份用户数据对象对应于一个Merkle DAG 的根哈希,且每个数据分片的哈希也由Merkle DAG 维护.此外,IPFS 采用了分布式哈希表,支持任意IPFS 节点通过哈希值定位到维护了指定用户数据对象的Merkle DAG 的节点,以及存储了指定数据分片的节点.
因此,在IPFS 中,访问数据的基本过程有4 个:
①数据访问节点向IPFS 集群发送需访问数据对象的根哈希,IPFS 集群通过查询分布式哈希表定位到维护了被请求数据对象的Merkle DAG 的节点,并将相应的Merkle DAG 传输到数据访问节点.
②数据访问节点根据接收到的Merkle DAG 解析出被访问数据的各数据分片的哈希.
③数据访问节点向IPFS 集群发送需访问数据对象的各数据分片的哈希,IPFS 集群通过查询分布式哈希表定位到存储了这些数据分片的节点,并将这些数据分片传输到数据访问节点.
④数据访问节点根据接收到的Merkle DAG 和数据分片,构造出被访问的数据.
3) P2P 高速传输
在IPFS 中,数据访问节点会同时请求多个数据分片且可能有多个存储节点上拥有部分或全部被请求的数据分片.因此,IPFS 采用以BitSwap[24]数据交换协议为核心的P2P 传输技术,根据节点信用分、性能、负载、网络状况等因素选择各数据分片的提供节点,并从多个提供节点并行地向数据访问节点发送其请求数据的各数据分片,从而显著提高数据传输速度.
此外,IPFS 具有缓存机制,各节点会将请求过的数据分片缓存在本地一段时间.期间,如果其他节点请求这些数据分片,该节点仍能将缓存的数据分片提供出去,以提高其他节点的数据访问速度.
最后,在IPFS 的BitSwap 协议中,引入了信用机制,根据各节点对外提供数据的情况为其评定信用分.对外提供数据越频繁的节点的信用分越高,而信用分越高的节点需要数据时会有更多的节点向其提供数据.在各节点属于不同主体的场景下(如跨云存储场景),这种信用机制可以促进各主体积极对外提供数据,进而提高IPFS 系统的整体数据访问速度.
2 基于IPFS 的跨云存储系统框架(IBCS)
本节提出了框架IBCS,可基于IPFS 的分片存储、内容寻址及P2P 传输等技术,实现细粒度缓存管理和高速编码块传输.
2.1 体系结构
如图4 所示,框架IBCS 由读写控制层、存储传输层和数据服务层组成.
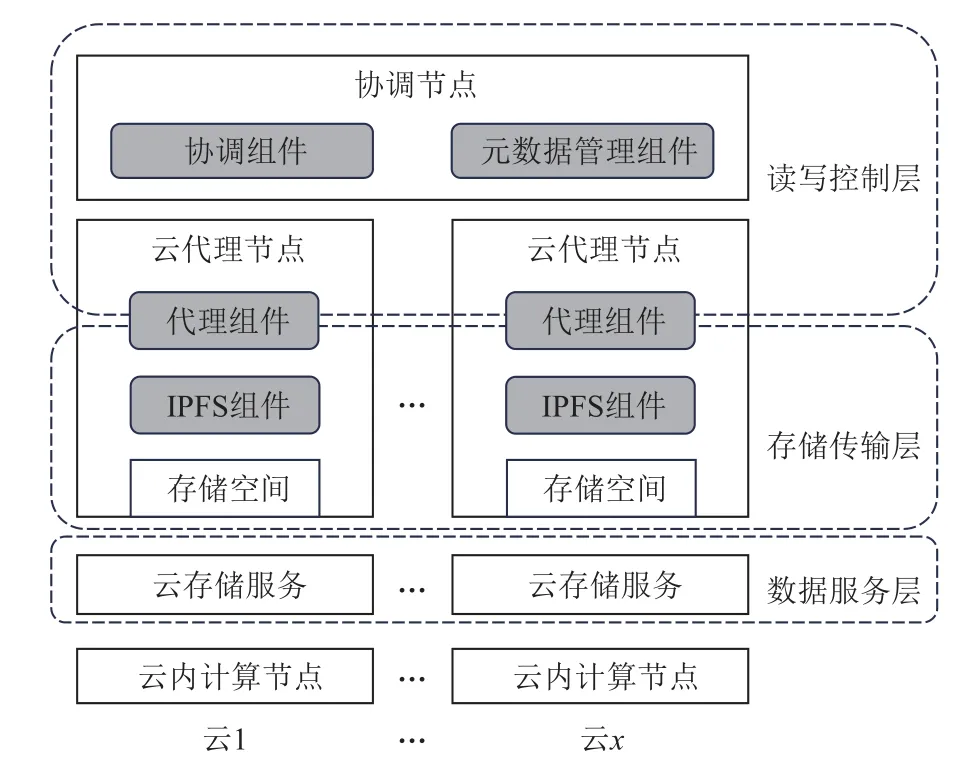
图4 IBCS 示意图Fig.4 Illustration of IBCS
1)读写控制层包含协调节点和多个云代理节点,主要负责响应客户端请求,完成用户数据的写入和访问,具体工作由协调节点上的协调组件、云代理节点上的代理组件和元数据管理组件完成:
①协调组件负责解析用户命令,生成写入、访问过程的控制命令,并发往代理组件;
②代理组件负责执行协调组件发送的命令,包括调用IPFS 组件向IPFS 集群写入编码块或从IPFS集群读取编码块、对编码块进行解码操作、将解码编码块得到的数据上传到各云存储服务或传输到云外计算节点;
③元数据管理组件负责维护用户、数据对象、编码块、云代理、云存储服务等元数据.
2)存储传输层由各云代理节点构成,主要负责在各云代理节点上的存储空间中存储管理用户数据对象的编码块,并在各云代理节点之间传输这些编码块,具体工作由各云代理节点上的代理组件和IPFS组件完成:
①代理组件负责调用IPFS 组件,完成本节点上持久化存储编码块及缓存编码块的读出、写入和状态变更;
②各IPFS 组件及各云代理的存储空间构成了IPFS集群,负责持久化存储或缓存编码块、执行代理组件命令、从IPFS 集群中读取编码块、向IPFS 集群写入编码块、利用P2P 技术在不同云的代理节点间高效传输编码块.
3)数据服务层为各个云的云存储服务(可被各云代理节点访问),将用户数据对象存储到云存储服务后,同一云上的计算节点才能正常访问该数据对象.
2.2 工作原理
框架IBCS 的核心工作原理包括数据写入原理、数据访问原理、存储状态管理原理和缓存实现原理.
1)数据写入
如图5 所示,客户端首先向协调节点发起数据写入请求后,协调节点为用户数据分配云代理节点;然后,客户端会将原用户数据分割为k个数据块,并对这k个数据块进行编码计算后得到n个编码块;最后,客户端将n个编码块传输至协调节点分配的云代理节点,各云代理节点的代理组件会接收这些编码块,并调用IPFS 组件将编码块按照IPFS 的数据组织格式(分片后以Merkle DAG 组织)存储到本节点的存储空间.
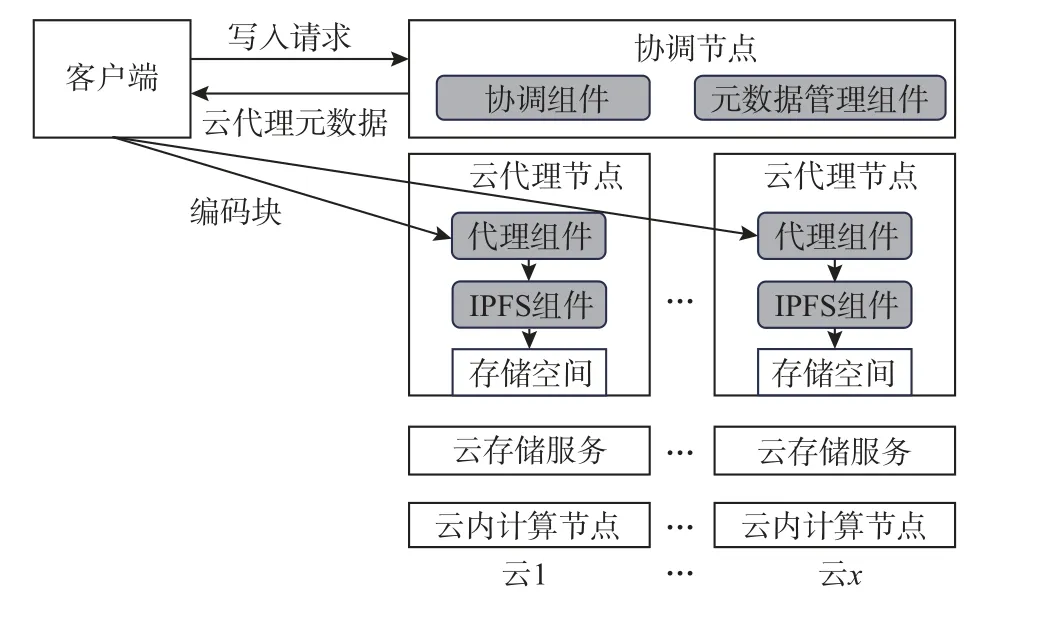
图5 IBCS 数据写入方案Fig.5 IBCS data write scheme
2)数据访问
在框架IBCS 中,有2 种节点可能需要访问数据:云内计算节点和云外计算节点.
如图6 所示,云内计算节点可高效访问其所在云的云存储服务中的数据.云内计算节点需要访问数据的过程为:首先,客户端向协调节点发送数据访问请求;然后,协调节点根据客户端请求,拟制数据访问方案并生成控制命令发送云内计算节点对应的云代理节点;随后,接收到命令的云代理节点从IPFS 集群读出待访问数据对象的编码块,解码出原始数据,并上传到对应的云存储服务.

图6 IBCS 数据访问方案(云内计算节点)Fig.6 IBCS data access scheme(in-cloud nodes)
云外计算节点无权限访问或不可高效访问云存储服务.如图7 所示,云外计算节点访问数据的过程为:首先,云外计算节点(运行着客户端)向协调节点发送请求,获取其所需数据的编码块的云代理节点信息;然后,云外计算节点拟制数据访问方案并向各代理节点请求编码块;随后,各代理节点将编码块从IPFS 集群中读出后,发送给云外计算节点;最后,云外计算节点将收到的编码块解码为所需数据.
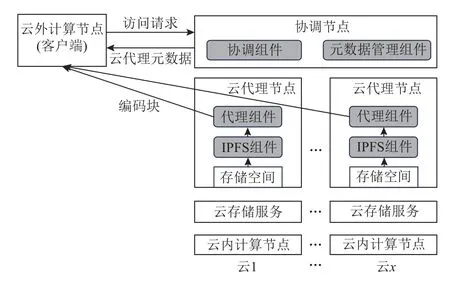
图7 IBCS 数据访问方案(云外计算节点)Fig.7 IBCS data access scheme(nodes outside the cloud)
3)存储状态管理
在框架IBCS 中,各云代理节点上由IPFS 组件维护的存储空间既是编码块的持久化存储空间,又是编码块的缓存空间.
IPFS 组件维护的存储空间中的编码块有长期存储(pinned)和临时存储(tmp)两种状态.处于tmp 状态的编码块会被IPFS 组件的垃圾回收程序定时清理,处于pinned 状态的编码块则不被垃圾回收程序清理.
代理组件向IPFS 集群写入编码块时,为了最大化数据容错度,通常避免将一个条带上的编码块及其副本分配至同一个云代理节点上,以确保单一节点失效时同一数据对象的编码块中最多一个编码块受到影响.图8 说明了IBCS 编码块存储状态的变化,写入的编码块会默认以pinned 的状态存储在代理组件所在云代理节点的存储空间中,直到维护该存储空间的IPFS 组件接收到改变该编码块状态的unpin命令.代理节点从IPFS 集群读取的编码块,会以tmp的状态存储在代理组件所在代理节点的存储空间中,直到维护该存储空间的IPFS 组件启动垃圾回收策略.此外,如果某云代理节点上的IPFS 组件接收到请求某个编码块的pin 命令,IPFS 集群使用P2P 传输技术将该编码块传输到该云代理节点上的存储空间中并设置为pinned 状态.
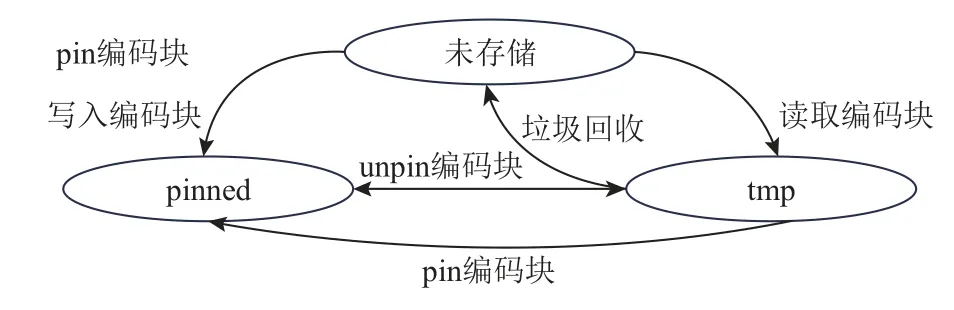
图8 IBCS 编码块存储状态管理原理Fig.8 Principle of coding blocks storage state management in IBCS
因此,通过对各IPFS 组件发送pin 命令和unpin命令,可以实现编码块存储状态的灵活管理.
4)缓存实现
在框架IBCS 中,持久化存储的编码块和缓存编码块均存储在各云代理节点的存储空间,如表1 所示.其中,持久化存储的编码块一直处于pinned 状态;缓存编码块可能处于pinned 状态,也可能处于tmp 状态,二者间的转换由运行的代理组件控制.
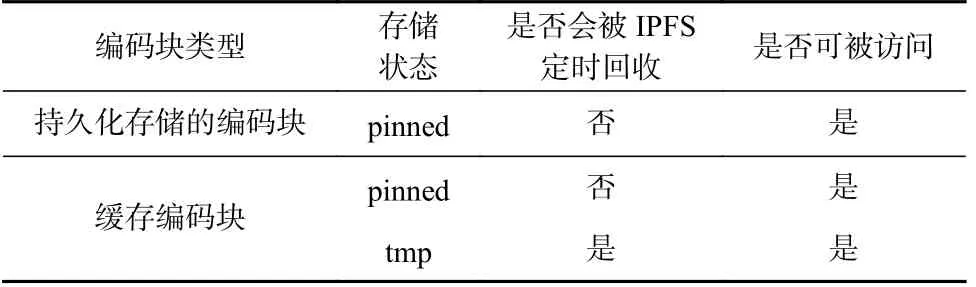
Table 1 Classification of Coding Blocks in IBCS表1 IBCS 中编码块的分类
2.3 框架分析
框架IBCS 的主要特点有4 个方面:
1)利用IPFS 的数据分片管理机制实现了缓存数据的细粒度管理,可从2 个方面提高缓存命中量.一方面,利用IPFS 的数据分片管理机制避免在同一云代理节点上存储重复的数据分片,因而能降低存储开销,进而增加了各云代理节点可缓存的编码块数;另一方面,数据分片管理机制使得未命中缓存编码块中的命中数据分片可以被利用起来,如图9 所示.
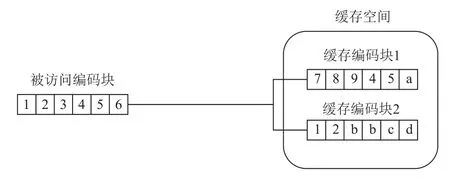
图9 IBCS 的细粒度缓存管理示意图Fig.9 Illustration of fine-grained cache management in IBCS
2)基于IPFS 的P2P 传输技术,可充分利用系统中持久化数据和缓存数据来提高编码块的传输并行度,通过减少低传输速度编码块从而有效提高编码块传输速度.此外,IPFS 的P2P 传输技术引入了信用机制,可以促进各云主体提升自身对外提供数据的能力,有助于不断提高跨云存储系统的编码块传输速度.
3)得益于IPFS 的内容寻址机制,读写控制层只需要管理各个编码块的根哈希即可,无需管理各个数据分片信息,因而数据分片管理机制、P2P 传输过程对读写控制层而言是透明的,这大大降低了元数据管理开销和系统实现难度.
4)针对云内计算节点和云外计算节点,分别设计了不同的数据访问流程,适用范围较广.
3 面向存算联调的跨云纠删码自适应数据访问方法(AECAM)
第2 节提出了一种基于IPFS 的跨云存储系统框架(IBCS).基于IBCS,本节提出一种面向存算联调的跨云纠删码自适应数据访问方法(AECAM),可通过协同优化缓存管理与数据访问方案减少数据访问过程中的编码块传输用时.
具体而言,首先提出一种编码数据访问方案自适应制定算法(AFERS),可根据IPFS 集群的各个存储节点与数据访问节点的传输延迟、各编码块在各存储节点里的存储情况、数据访问节点的类型,综合评估数据访问过程中各编码块的传输速度,并以此为依据自适应制定可避免访问传输速度评估值低的编码块的编码数据访问方案,从而缩短数据访问过程中的编码块传输用时.
然后,提出了一种基于数据访问过程感知的缓存管理算法(CADA),可优先在数据访问节点缓存易被编码数据访问方案自适应制定算法AFERS 选中(传输速度预估值高)且实际传输速度相对较低的编码块,以同时提高缓存命中量及缓存命中增效,进而缩短数据访问过程中的编码块传输用时.
3.1 编码数据访问方案自适应制定算法(AFERS)
1)核心思想
算法AFERS 首先针对云内计算节点访问数据和云外计算节点访问数据2 种场景,分别建模评估编码块传输速度.然后,AFERS 可根据各编码块传输速度的评估值制定编码数据访问方案.
①编码块传输速度评估
算法AFERS 将数据访问节点区分为云内计算节点和云外计算节点2 种,并根据框架IBCS 中将数据传输到2 类数据访问节点的具体过程,使用不同的模型来评估这2 类数据访问节点访问数据时的编码块传输速度.
(i)云内计算节点访问数据时的编码块传输速度评估
在框架IBCS 中,云内计算节点需要访问数据时,编码块通过P2P 传输技术被传输到数据访问节点所对应的云代理节点,然后该云代理节点会用接收到的编码块解码出原始数据对象,并将原始数据对象上传到需访问数据的云内计算节点(数据访问节点)可访问的云存储服务.
上述过程中,影响编码块传输速度的主要因素包括P2P 网络中存储了各编码块的云代理节点数,以及这些云代理节点与数据访问节点对应云代理节点间的实时带宽.P2P 网络中实际存储待传输编码块的云代理节点数越多,编码块传输速度越快;这些云代理节点与数据访问节点对应云代理节点间的实时带宽越高,编码块传输速度越快.
因此,若令b为待传输编码块,c为数据访问节点对应的云代理节点(编码块的传输目的地节点),Eb,c为将编码块b传输到目的地节点c的速度,qb为存储编码块b的云代理节点数,xb,i(i∈[1,qb])为第i个存储了编码块b的云代理节点的序号,Bc,xb,i为序号为xb,i的云代理节点与传输目的地节点c间的实时带宽,则有
此外,由于框架IBCS 中各云代理节点上的编码块的状态包括2 类pinned 和tmp,且处于tmp 状态的编码块有一定概率已经被回收(状态为pinned 的编码块没被回收的概率为1),所以,若令Qb为可能存储编码块b的云代理节点数(存储了处于pinned 状态或tmp 状态的编码块b的云代理节点数),yb,i(i∈[1,Qb])为第i个可能存储编码块b的云代理节点Nodeyb,i的序号,Bc,yb,i为Nodeyb,i与传输目的地节点c间的实时带宽,pyb,i为Nodeyb,i实际存储了编码块b的概率,则有
由于IPFS 会定时触发垃圾回收任务删除处于tmp 状态的编码块,因此,若令IPFS 触发垃圾回收任务的周期为T,节点Nodeyb,i上的编码块b处于tmp 状态的时长为tb,yb,i,则该节点上编码块b未被回收(实际存在)的概率为
因此,Nodeyb,i中编码块b未被回收的概率为
最后,由于测量节点间实时带宽的开销较大,算法AFERS 使用节点间延迟来估算带宽,具体估算方法为:
其中Dc,yb,i为Nodeyb,i与传输目的地节点c间的传输延迟.通常情况下,2 个节点间的传输延迟越大意味着在2 个节点间传输数据时的数据转发的次数越多,而数据转发次数的增加将导致数据传输途经低带宽链路的概率增加、丢包率提升,进而导致传输带宽降低,因此延迟通常与带宽呈负相关.此外,实际测试中发现,传输延迟少于1ms 时(如2 个节点处于同一云中)节点间带宽将大幅度提高(同云内节点间带宽远高于不同云节点间带宽).式(5)符合上述2 项规律.综上,可得
因此,算法AFERS 在访问数据前,用式(7)为各编码块评分,当传输目的地云代理节点为c时,编码块b的传输速度评分为Sb,c:
通常而言,评分越高,编码块相对传输速度越高.
(ii)云外计算节点访问数据时的编码块传输速度评估
在框架IBCS 中,云外计算节点需要访问数据时,编码块通过TCP 协议直接从特定云代理节点传输到需要访问数据的云外计算节点(数据访问节点),并由数据访问节点将编码块解码为原始数据对象.
上述过程中,影响编码块的传输速度的主要因素为存储了编码块的云代理节点与需访问数据的计算节点间的实时带宽的最大值.因此,若令o为数据访问节点(编码块传输目的地节点),Eb,o为将编码块b传输到计算节点o的速度,Wb为以pinned 状态存储编码块b的云代理节点数,zb,i(i∈[1,wb])为第i个存储编码块b的云代理节点Nodezb,i的序号,Bo,zb,i为Nodezb,i与数据访问节点o间的实时带宽,则有
此外,算法AFERS 使用节点间延迟来估算带宽,具体估算方法为:
其中Do,zb,i为Nodezb,i与计算节点o间的传输延迟.综上可得
因此,算法AFERS 在访问数据前,用式(11)为各编码块评分,当传输目的地计算节点为o时,编码块b的传输速度评分为Sb,o:
通常而言,评分越高,编码块相对传输速度越高.
②编码数据访问方案制定
在跨云环境下,数据访问过程中最耗时的步骤通常为传输编码块.因此,编码数据访问方案制定的主要思想是根据编码块的传输速度评分,为不同编码数据访问方案〈type,blocks〉的编码块传输速度评分,其中type为编码数据访问方案类型,blocks为访问数据时需获取的编码块的列表,并以〈type,blocks〉为主要依据确定编码数据访问方案以及编码访问方案中各编码块的提供节点.
(i)编码数据访问方案的编码块传输速度评分
通常而言,各节点的数据接收能力远高于跨云节点间的数据传输能力,且同一节点可并行接收不同节点发来的编码块.因此,编码数据访问方案〈type,blocks〉的编码块传输速度为blocks中各编码块的传输速度的最小值.
由于直接数据访问方案需要传输k个数据块,因此该类方案编码块传输速度评分Edir为k个数据块的传输速度评分的最小值;由于降级数据访问方案需要传输任意n-d+1 个编码块,因此该类方案的编码块传输速度评分Eun为传输速度评分第n-d+1 高的编码块的传输速度评分.
(ii)编码数据访问方案选择
算法AFERS 结合各类数据访问方案的编码块传输速度评分及计算开销确定数据访问方案类型type.由于直接数据访问方案的计算开销较小,所以将其编码块传输速度评分Edir乘上一个权值s后与降级数据访问方案的编码块传输速度评分Eun比较.若sEdir>Eun,则采用直接数据访问方案,反之采用降级数据访问方案.假设Ddir为直接访问方案中k个数据块的传输速度评分的最小值所对应的代理节点与云外计算节点间的延迟,Dun为降级访问方案中传输速度评分第n-d+1 高的编码块所对应的代理节点与云外计算节点间的延迟,将式(10)带入选择直接数据访问的条件sEdir>Eun,可得Ddir<.换言之,当且仅当Ddir<时,选择直接数据访问方案,反之选择降级数据访问方案.因此,当s≤1 时,满足Ddir≥Dun即选择降级数据访问方案,此时忽略了降级数据访问方案带来的额外计算开销,因而s≤1 不合理;当s≥2 时,至少满足Ddir≥才选择降级数据访问方案,由于满足不等式Ddir≥的Dun通常远小于Ddir,这将造成数据传输开销远低于直接访问方案的降级数据访问方案被放弃,因而s≥2 不合理.因此s的合理取值范围为1<s<2,本文实验中取s=1.5.
若采用直接数据访问方案,需要传输的编码块blocks为k个数据块.若采用降级数据访问方案,为了尽可能提高整体编码块传输速度,需要传输的编码块blocks为传输速度评分最高的n-d+1 个编码块.
(iii)提供编码块的云代理节点选择
当数据访问节点为云内计算节点时,该计算节点对应的云代理节点只需要提供各需传输编码块的根哈希,相应的编码块即可通过P2P 传输技术传输到该云代理节点上,因而此时无需选择提供各编码块的云代理节点.
当数据访问节点为云外计算节点时,则需要从存储了需传输编码块的各云代理节点中,选择与计算节点间的网络延迟最小的云代理节点作为提供该编码块的节点.
2)算法描述
算法AFERS 的具体工作流程如算法1 所示.
算法1.算法AFERS.
输入:数据访问节点accessNode,访问数据IDdataID;
输出:编码数据访问方案〈type,blocks〉,提供各编码块的云代理节点列表nodes.
若数据访问节点为云内计算节点(算法1 的行①),则算法AFERS 运行于协调节点上的协调组件.首先,AFERS 从协调节点上的元数据管理组件获取数据访问节点对应云代理节点与存储被访问数据的编码块的云代理节点间的延迟(各云代理节点定时检测其与其他云代理节点间的延迟,并将检测结果发往协调节点存储),以及被访问数据的编码块的信息,具体包括:存储各编码块的节点、编码块在各节点上的存储状态tmp 或pinned、处于tmp 状态的编码块的存入时间等(算法1 的行②③).然后,AFERS 根据从元数据管理组件获取的信息,计算各编码块的传输速度评分(如式(7)),并根据评分选择编码数据访问方案的类型和用于重构数据的编码块(算法1 的行④~⑥).
若数据访问节点为云外计算节点(算法1 的行⑧),则算法AFERS 运行于数据访问节点.首先,AFERS 从协调节点的元数据管理组件获取被访问数据对应编码块的信息,主要包括:存储了被访问数据对应pinned 状态编码块的节点ID(算法1 的行⑨).然后,如果数据访问节点未初始化,则数据访问节点先测试其与被访问数据对应pinned 状态编码块所在云代理节点间的延迟,并存于本地内存;如果数据访问节点已初始化,则直接从本地内存获得其与各pinned 状态编码块所在节点间的延迟(算法1 的行⑩~⑬).接着,AFERS 计算各编码块的传输速度评分(如式(11)),并根据评分选择编码数据访问方案的类型type和用于重构数据的编码块blocks(算法1 的行⑯~⑱).最后,AFERS 依据数据访问节点与被访问数据对应pinned 状态编码块所在云代理节点间的延迟,选择提供blocks中编码块的云代理节点(算法1的行⑲).
3)算法分析
①算法AFERS 针对2 种不同类型数据访问节点访问数据的过程,分别设计了编码块传输速度评估模型,且评估各编码块传输速度时考虑了各缓存编码块的分布情况,能较为准确地评估框架IBCS 下不同类型数据访问节点访问数据时各编码块的速度.同时,AFERS 能以编码块传输速度评估值为依据制定编码块传输速度较高的编码数据访问方案,从而能提高不同访问节点访问数据的速度.
②算法AFERS 只需要测试各云代理节点和云外计算节点间的延迟,相较于现有的需要测试节点间实时带宽、各节点实时性能的算法,AFERS 对各云代理节点的影响较低.
3.2 基于数据访问过程感知的缓存管理算法(CADA)
1)主要思想
算法CADA 首先以数据对象为单位进行缓存管理,当决定缓存或驱逐某个数据对象后,再对该数据对象的各编码块进行差异化的操作, 各缓存编码块被切分为若干数据分片进行管理,可节省缓存空间.
①数据对象级缓存管理
当某个云代理节点对应的云内计算节点访问数据时,算法CADA 会将该数据对象的部分编码块加入缓存,加入缓存的编码块的初始存储状态均为pinned.
此外,CADA 可适配任意用户自定义的数据对象级缓存驱逐算法.当触发缓存驱逐操作后,CADA将使用用户自定义的缓存驱逐算法初步决定驱逐哪些数据对象的编码块.缓存驱逐操作一方面会定时触发,另一方面会在剩余缓存空间不足以缓存待缓存编码块时触发.
②编码块级缓存管理
缓存编码块在云代理节点的存储空间内有pinned 和tmp 这2 种状态.编码块状态为pinned 时,存在缓存优先级(取值包括0 或1);编码块为tmp 状态时,没有缓存优先级,且会被IPFS 组件的垃圾回收程序定时清理.tmp 状态的编码块被回收之前仍保留在云代理节点上,可以作为缓存读取.
当某个云代理节点对应的云内计算节点访问数据时,CADA 会选择该数据对象的部分编码块加入缓存,并为这些编码块设置缓存优先级.缓存驱逐时,首先由用户自定义的数据对象级缓存驱逐算法决定待驱逐的数据对象,CADA 会根据缓存优先级更改pinned 缓存编码块的状态.其中缓存优先级为1 的编码块将被设为0,仍保留pinned 状态;缓存优先级为0 的编码块将被设为tmp 状态,如图10 所示.
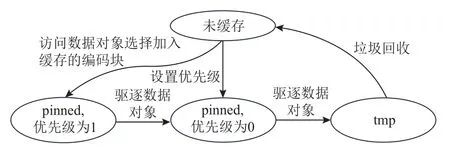
图10 CADA 编码块缓存状态管理原理Fig.10 Principle of coding blocks cache state management in CADA
设置编码块缓存优先级的主要策略为:优先缓存易被算法AFERS 选中的编码块(本次访问数据时已被AFERS 选中的编码块)以提高缓存的命中量;优先缓存实际传输速度远低于所有被访问编码块实际传输速度平均值的编码块,使得缓存命中时可通过大幅度提高各编码块传输速度的下限而大幅度缩短编码块传输用时(即缓存命中增效较大).
因此,具体的缓存优先级设置过程为:首先,获取被AFERS 选中的各编码块的实际传输用时,并计算出各编码块的实际传输用时的平均值和标准差 σ.然后,得到实际传输用时大于的编码块(j为经验常量,即使用j-sigma 原则进行缓存决策),并将这些编码块加入缓存,其中,传输用时最长的编码块的缓存优先级将被设为1,其他编码块的优先级将被设为0.
③数据分片级缓存管理
加入缓存的编码块被划分为若干个大小不超过256 KB 的数据分片并以Merkle DAG 组织存储在云代理节点上,由IPFS 组件维护.缓存编码块(以哈希值标识)对应Merkle DAG 的一个根节点,内容为其叶节点所对应数据分片的组合.
算法CADA 通过IPFS 获取待缓存编码块哈希在Merkle DAG 上末端节点的各数据分片哈希值,与本地已有分片的哈希进行比对,以判断数据分片的命中情况.利用IPFS 的数据分片管理机制,在缓存空间中内容完全相同的数据分片仅存储1 份,该数据分片在Merkle DAG 中指向多个包含该数据分片的顶端节点,对应不同的缓存编码块.数据分片级缓存管理可节省缓存空间,增加云代理节点上可缓存的编码块数.
2)算法描述
算法CADA 的工作流程如算法2 所示.
算法2.算法CADA.
输入:缓存量阈值Rthreshold,用户选择的数据对象级缓存驱逐算法F.
算法CADA 运行于云内计算节点对应的云代理节点上,会不停阻塞读取事件队列中的事件(算法2的行①②),其中包括数据访问事件和定时缓存回收事件等.
若读取到数据访问事件,则从事件中获取被算法AFERS 选中的编码块信息,以及各编码块的实际传输用时(算法2 的行③~⑤).然后,根据获得的信息得到被AFERS 选中的编码块中传输用时较长的编码块列表slowBlocks,传输用时较长的编码块指实际传输用时大于的编码块,其中t¯, σ分别为各编码块传输用时的平均值和标准差(算法2 的行⑥),j为经验常量.接着,将slowBlocks中的编码块加入缓存,并将其中传输用时最长的编码块的缓存优先级设为1,其他编码块的缓存优先级设为0(算法2 的行⑦).随后,如果当前缓存的总数据量超过阈值,则调用用户选择的数据对象级缓存驱逐算法F确定拟驱逐的数据对象(算法2 的行⑧~⑩).最后,调整拟驱逐数据对象的编码块的缓存优先级(将缓存优先级为1 的编码块的缓存优先级调为0)并将缓存优先级为0 的编码块设为tmp 状态(算法2 的行⑪).
若读取到定时缓存回收事件,则调用用户选择的数据对象级缓存驱逐算法F确定拟驱逐的数据对象,并调整拟驱逐数据对象的编码块的缓存优先级(将缓存优先级为1 的编码块的缓存优先级调为0)并将缓存优先级为0 的编码块设为tmp 状态(算法2的行⑭~⑯).
3)算法分析
①算法CADA 选择缓存被算法AFERS 选中且实际传输用时较长的编码块,可以提高缓存命中量和缓存命中增效,从而缩短编码块传输用时,进而提高数据访问速度.
②算法CADA 对实际传输用时相对较长的编码块(缓存优先级为1)进行了保护,使其需要经历2 次缓存驱逐操作且期间未被命中才会被清理,有利于提高缓存命中增效.
③不同数据对象级缓存驱逐算法适用于不同的场景,由于算法CADA 可适配用户自定义的数据对象级缓存驱逐算法,故其适用场景较为丰富.
4 实验与结果
4.1 原型实现
为评估方法AECAM 的性能,我们实现了一个面向跨云存算联调的存储系统(cross-cloud storage system for collaborative scheduling of storage and computation,C2S2),并在该系统中实现了AECAM.
C2S2 遵循基于IPFS 的跨云存储系统框架IBCS,该框架由协调组件、元数据组件、代理组件、IPFS 组件、客户端组成,如图11 所示.
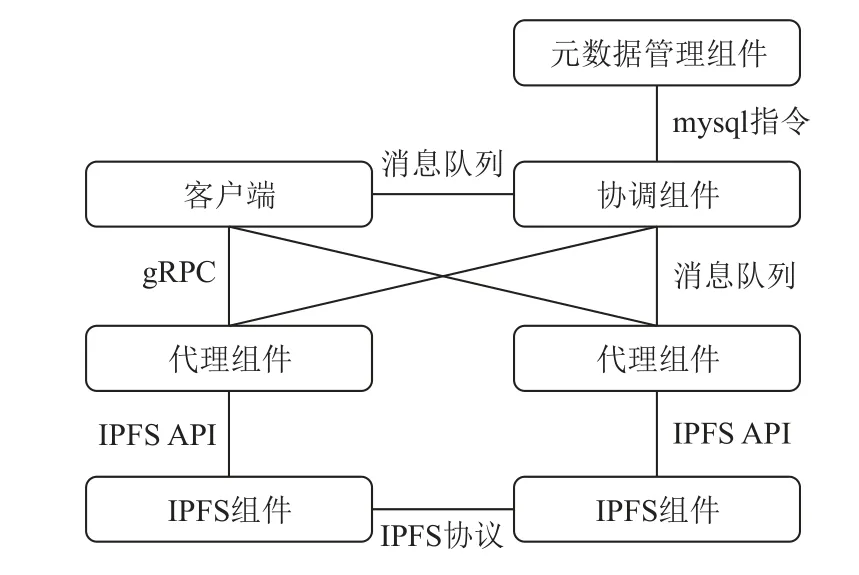
图11 C2S2 各组件间消息交互示意图Fig.11 Illustration of communications between C2S2 modules
为避免单点故障,协调组件有多个,运行于多个协调节点上.各协调组件不断阻塞读取竞争消息队列中的消息,并在成功读取消息后将其解析执行.其中,消息由客户端写入,包括文件写入请求、访问请求等.
每个云代理节点上运行一个代理组件.代理组件不断阻塞读取其专有消息队列中的消息,并在成功读取消息后将其解析执行.其中,消息由协调组件写入,包括具体的编码块操作指令.此外,代理组件上运行着gRPC(Google remote procedure call)服务,负责与客户端进行数据传输.
各协调节点元数据组件共同构成mysql 集群,负责存储系统中的各类元数据:存储服务元数据、数据对象元数据、代理节点元数据、代理节点编码块元数据、云内计算节点数据对象元数据、编码块元数据.为保证元数据安全,该mysql 集群只能被协调组件通过mysql 指令访问.
每个云代理节点上运行一个IPFS 组件,各IPFS组件组成IPFS 集群.各IPFS 组件可被其所在云代理节点上的代理组件通过IPFS API 访问,也可与IPFS集群中的其他IPFS 组件通过IPFS 协议共同完成编码块的P2P 传输.
4.2 实验设置
实验环境包括阿里云和华为云在北京和上海的3 个云数据中心的6 个节点(云主机),各云数据中心间的带宽如图12 所示.华为云主机配备2 核第3 代Intel 至强3.0 GHz 处理器、4 GiB 内存和40 GB 云硬盘;阿里云主机配备2 核第3 代Intel Xeon2.7 GHz 处理器,4 GiB 内存和40 GB 云硬盘.其中,节点1~5 为云代理节点,同时充当云内计算节点;节点6 为协调节点,同时充当云外计算节点.其中,华为云主机对应的云存储服务为MinIO 对象存储服务,阿里云主机对应的云存储服务为OSS 对象存储服务.
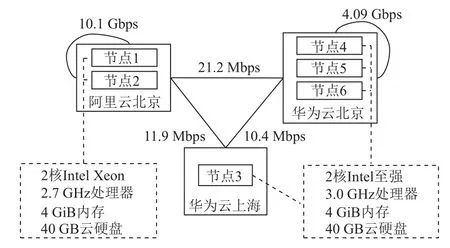
图12 跨云实验环境示意图Fig.12 Illustration of cross-cloud experimental environment
为评估C2S2 的性能,我们将其与2 个引入缓存的基于纠删码的存储系统Agar 和POCache 进行了对比测试.
Agar[16]默认采取直接数据访问方案,将编码块的全局访问次数与各数据访问节点获取该编码块开销的乘积作为各数据访问节点缓存该编码块的预期收益,并将预期收益较高的编码块缓存到对应的数据访问节点.
POCache[15]将校验块缓存到数据访问节点附近,在访问数据时请求所有的数据块.当访问的数据对象存在校验块缓存时,POCache 同时从缓存节点请求校验块,等待k个编码块到达后采取直接或降级数据访问方案解码计算重构原始数据对象.
实验采用的参数及默认值如表2 所示.
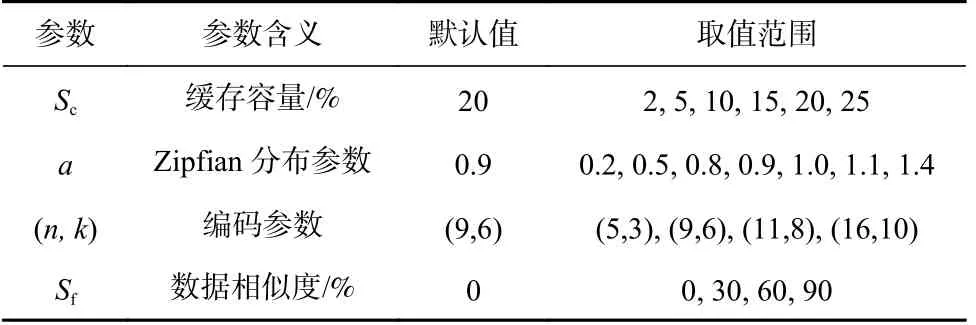
Table 2 Parameters in Experiments表2 实验参数
缓存容量Sc是指缓存空间大小与待读取数据对象总大小之比.
实验中,数据对象的访问服从Zipfian 分布[25],少数热点数据的访问次数占总数据访问次数的比例越大,Zipfian 分布的参数a越大.
数据相似度Sf是指2 个数据对象在内容上的相似程度.在本次实验中,按照数据相似度将每2 个数据对象划分为一个小组,小组内的2 个数据对象在内容上相似,相似度为Sf;任意小组之间的数据对象数据相似度为0.
4.3 评价指标
我们使用3 个指标来评价面向跨云存算联调的存储系统C2S2 的性能.
1)缓存命中量
若存储系统以编码块为粒度进行缓存管理,则该存储系统的缓存命中量HS为经过多轮数据访问操作后被命中的缓存编码块的总大小HSblock;若存储系统以数据分片为粒度进行缓存管理,则该存储系统的缓存命中量HS为经过多轮数据访问操作后被命中的缓存数据分片的总大小HSslice.
2)跨云传输量
若存储系统以编码块为粒度进行缓存管理,则该存储系统的跨云传输量CT为经过多轮数据访问操作后被跨云传输的编码块的总大小CTblock;若存储系统以数据分片为粒度进行缓存管理,则该存储系统的跨云传输量CT为经过多轮数据访问操作后被跨云传输的数据分片的总大小CTslice.
3)数据访问速度
若被访问数据大小为M,且从用户发起数据访问命令到云内计算节点对应的云代理节点将数据重构出来并上传到对应的云存储服务上所消耗的时间为t1,则云内计算节点访问该数据的速度为M/t1;若被访问数据大小为M,且从用户发起数据访问命令,到云外计算节点对应的云代理节点上将数据重构出来所消耗的时间为t2,则云外计算节点访问该数据的速度为M/t2.
实验中的缓存命中量、跨云传输量由仿真实验测得,数据访问用时由真实跨云环境下的实验测得.
4.4 缓存命中量
图13 显示了缓存命中量随编码块缓存决策所采取的j-sigma 原则中经验常量j的变化而变化.随着j的增加,缓存命中量逐渐上升.当j增加到3 后,缓存命中量基本上不再随j的增加而显著增加.因此,本文实验中取j=3.

图13 缓存命中量随缓存决策j-sigma 原则的参数j 的变化Fig.13 Variation of cache hit volume with parameter j of the j-sigma caching decision principle
图14 显示了不同Zipfian 分布参数a下Agar,POCache,C2S2 的缓存命中量.Agar,POCache,C2S2的缓存命中量随a的增大而增加.这是由于a越大,热点数据访问次数占总数据访问次数的比例越大,因而存储系统缓存的热点数据的编码块被命中的次数越多.

图14 不同Zipfian 分布参数a 下缓存命中量对比Fig.14 Comparison of cache hit volume under different Zipfian distribution parameter a
图15 显示了不同缓存容量下Agar,POCache,C2S2的缓存命中量.Agar,POCache,C2S2 的缓存命中量均随着缓存容量的增加而增加,这是由于缓存容量越大,可缓存的编码块越多.
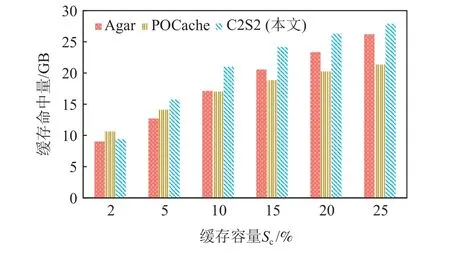
图15 不同缓存容量下缓存命中量对比Fig.15 Comparison of cache hit volume under different cache sizes
图16 显示了不同编码参数下Agar,POCache,C2S2的缓存命中量.Agar 和C2S2 的缓存命中量对编码参数的变化不敏感,而POCache 的缓存命中量对编码参数的变化较为敏感且其缓存命中量除编码参数(5,3)外均低于Agar 和C2S2.这是因为POCache 仅缓存校验块,使得其对编码块中校验块的占比较为敏感.校验块占比越少,可缓存的编码块越少,进而可命中的编码块越少.
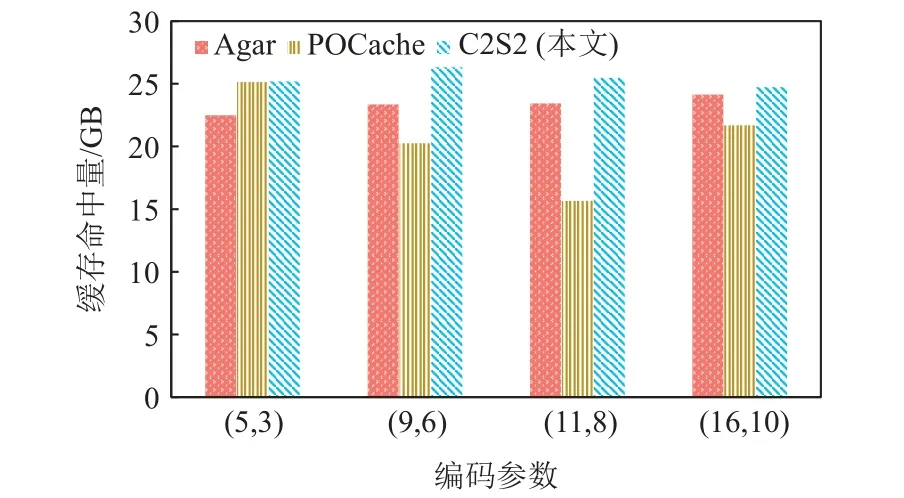
图16 不同编码参数下缓存命中量对比Fig.16 Comparison of cache hit volume under different encoding parameters
图17 显示了不同数据相似度下Agar,POCache,C2S2 的缓存命中量.C2S2 的缓存命中量随着数据相似度的增加而增加,而Agar 和POCache 的缓存命中量几乎不受数据相似度影响.这是由于C2S2 实现了数据分片级的缓存管理,相似数据的编码块中的相同数据分片仅被存储了1 次,因而数据相似度越大,缓存空间中能存储的编码块越多,使得缓存命中量越大.
总体而言,C2S2 的平均缓存命中量比Agar 和POCache 高了10.05% 和65.4%,主要原因为:1)C2S2实现了细粒度的缓存管理;2)C2S2 为各已缓存的编码块设置了优先级,可以更持久地保留数据访问方案中传输效率低的编码块,有利于减少缓存抖动,提高缓存命中量;3)C2S2 可以根据实际情况缓存各类编码块,而POCache 只能缓存校验块且Agar 只能缓存数据块.
4.5 跨云传输量
图18 显示了不同Zipfian 分布参数a下Agar,POCache,C2S2 的跨云传输量.Agar 和C2S2 的跨云传输量随a的增大而显著减少.这是因为参数a越大,热点数据访问次数占总数据访问次数的比例越大,因而存储系统缓存的热点数据的编码块被命中的次数越多,进而从缓存中直接获取的数据的总量越大.然而,POCache 的跨云传输量受a的影响较小.这是由于POCache 在访问数据时首先访问所有的数据块,然后舍弃最后到达的数据块,使得其跨云传输量与缓存是否命中几乎无关.

图18 不同Zipfian 分布参数a 下跨云传输量对比Fig.18 Comparison of cross-cloud transfer volume under different Zipfian distribution parameter a
图19 显示了不同缓存容量Sc下Agar,POCache,C2S2 的跨云传输量.随着缓存容量的增大,C2S2 的跨云传输量有明显下降,这是由于缓存容量越大,可缓存的编码块越多,缓存命中量越大.然而,POCache和Agar 的跨云传输量并没有随着缓存容量的增加而明显下降.这是因为Agar 需要定期进行预缓存和缓存调整,带来了额外的跨云传输量,而POCache 在每次访问数据时都会请求所有的数据块.
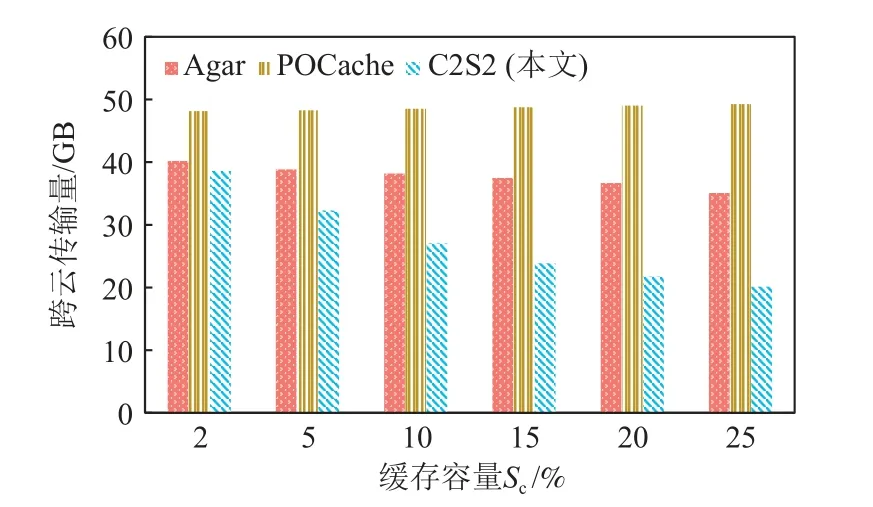
图19 不同缓存容量下跨云传输量Fig.19 Comparison of cross-cloud transfer volume under different cache sizes
图20 显示了不同编码参数下Agar,POCache,C2S2 的跨云传输量.三者跨云传输量基本上不受编码参数的影响.这是由于C2S2,Agar 的缓存命中量对编码参数不敏感,且POCache 在任何编码参数下访问数据时都会请求所有的数据块.

图20 不同编码参数下跨云传输量对比Fig.20 Comparison of cross-cloud transfer volume under different encoding parameters
图21 显示了不同数据相似度Sf下Agar,POCache,C2S2 的跨云传输量.C2S2 的跨云传输量随着数据相似度的增加而减少;Agar,POCache 的跨云传输量几乎不受数据相似度影响.这是由于C2S2 实现了细粒度的缓存管理,在访问数据时可以利用相似数据的编码块缓存来减少跨云传输量.
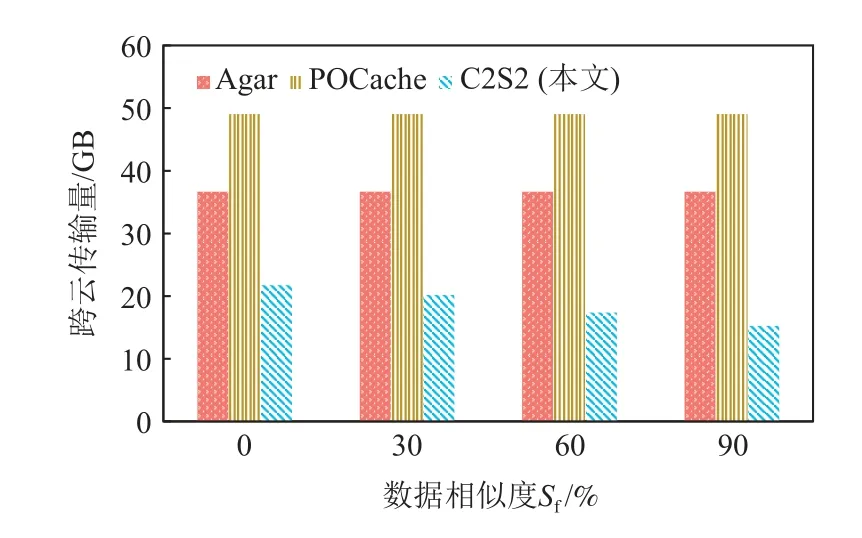
图21 不同数据相似度下跨云传输量对比Fig.21 Comparison of cross-cloud transfer volume under different data similarity
总体而言,C2S2 的平均跨云传输量比Agar 和POCache 分别低了30.13% 和53.69%,主要原因为:1)C2S2 只针对读取到的数据进行缓存,不产生额外的跨云传输量.2)C2S2 利用数据内容寻址机制,可以让相似数据对象从缓存中读取一致的数据分片,减少跨云传输量.
4.6 数据访问速度
图22 显示了不同数据相似度下Agar,POCache,C2S2 的数据访问速度.当数据相似度为0 时,C2S2 与POCache 和Agar 相比,可将数据访问速度提升28.58%~33.04%.这是由于C2S2 的缓存命中量更高、缓存命中增效高,可有效降低低带宽云间的数据传输量.
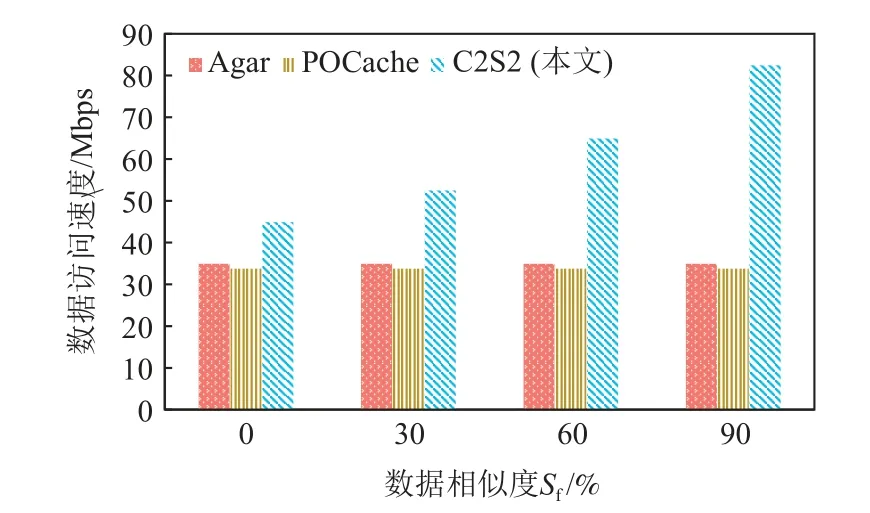
图22 不同数据相似度下平均数据访问速度Fig.22 Comparison of average data access speed under different data similarity
此外,当数据相似度为30%,60%,90%时,C2S2的数据访问速度逐渐升高.这是由于C2S2 支持细粒度的缓存管理,在访问数据时可以利用相似数据的编码块缓存来减少跨云传输量.
整体而言,C2S2 的数据访问速度平均比POCache和Agar 高75.22%~81.29%.主要原因为:
1) C2S2 使用IPFS 集群从多个云代理节点以数据分片为单位并发传输编码块,能够有效提高编码块传输速度;
2) C2S2 可以评估各编码块的传输速度,并自适应制定编码数据访问方案以规避传输速度慢的编码块;
3) C2S2 的缓存管理算法可对数据访问过程进行感知,并通过设置优先级,更为持久地保留数据访问方案中传输效率最低的瓶颈编码块,提高缓存命中增效.
5 总 结
在框架创新方面,本文提出了一种基于IPFS 的跨云存储系统框架(IBCS),使用IPFS 集群存储和缓存数据,并有效利用IPFS 的数据分片管理机制实现细粒度的缓存管理,因而能提高缓存命中率.
在技术创新方面,本文提出了一种面向存算联调的跨云纠删码自适应数据访问方法(AECAM),实现了纠删码编码数据缓存管理策略与编码数据访问方案选择策略深度协同优化,在选择编码数据访问方案时以各编码块的存储和缓存情况为依据,在设置编码数据缓存优先级时以编码数据访问方案对各编码块的评估结果和实际传输时间为依据,可同时提高缓存命中量和命中增效.
在软件实现方面,本文基于IPFS 的跨云存储系统框架(IBCS)和面向存算联调的跨云纠删码自适应数据访问方法(AECAM),设计实现了一种面向跨云存算联调的存储系统(C2S2).与现有引入缓存的基于纠删码的存储系统POCache 和Agar 相比,可将数据访问速度提高75.22%~81.29%.
未来,我们计划进一步研究框架IBCS 的数据修复和数据更新性能优化问题.具体研究如何通过合理管理缓存编码块来缩短数据修复用时,以及如何利用框架IBCS 的数据分片管理机制降低数据更新开销.
作者贡献声明:张凯鑫提出主要研究思路,完成实验并撰写论文;王意洁提出指导意见,修改和审核论文;包涵提出实验方案,参与修改论文;阚浚晖协助完成实验.
猜你喜欢
词学(2022年1期)2022-10-27
数学物理学报(2020年5期)2020-11-26
广东通信技术(2020年10期)2020-10-26
电脑报(2019年11期)2019-09-10
火控雷达技术(2018年4期)2019-01-15
趣味(数学)(2018年12期)2018-12-29
现代营销(创富信息版)(2018年8期)2018-09-08
学生天地(2016年23期)2016-05-17
科技与创新(2014年4期)2014-05-19
城市建设理论研究(2014年5期)2014-02-18
