
融合注意力与多分支膨胀卷积的音频隐写算法*
2024-03-20 01:16廖浩媛
通信技术 2024年2期
廖浩媛,高 勇
(四川大学 电子信息学院,四川 成都 610065)
0 引言
隐写技术是信息隐藏的一个分支,其核心目标是将秘密信息隐蔽地嵌入到特定的载体中,确保载体在传输过程中不引起怀疑,将其传输给通信接收方,合作接收方利用对应的提取算法从含密载体中得到秘密信息。在此过程中,除了通信双方,第三方不能感知到除载体之外的隐蔽信息传输行为的存在[1]。音频隐写是一种能从源头上保护秘密信息传输的安全技术,最初兴起时隐藏的信息通常为文本。随着传输需求的增大,隐藏音频的隐写算法逐渐发展起来。
有不少国内外学者提出了高效的音频隐写算法,主要分为传统隐写算法和深度学习算法两类。文献[2-4]在音频时域上选择载体音频的最低有效位(Least Significant Bit,LSB)作为秘密信息嵌入位置,算法简单、复杂度低,但在噪声环境中容易丢失信息。文献[5]借助人耳听觉系统(Human Audio System,HAS)对音频相位失真的低灵敏性,通过修改相位值实现秘密信息的隐藏。该方法鲁棒性高,但其透明性受到嵌入率和相位变化程度的影响,表现相对不够稳定。文献[6]提出了基于离散余弦变换(Discrete Cosine Transform,DCT)将载体转换至频域并修改其DCT 系数进行嵌入的隐藏算法。文献[7-8]在基于DCT 的方法的基础上进行改进,采用离散小波变换(Discrete Wavelet Transform,DWT),并通过奇异值分解计算特征值,将秘密信息量化嵌入到特征值中,以实现隐写目的。研究结果表明,该算法具备高透明性和鲁棒性,然而其隐藏容量相对较低。
深度学习卓越的特征学习能力和端到端的传输避免了人工特征选择的一系列烦琐过程,因此以深度学习为基础的自适应隐写算法不断发展起来。Kreuk 等人[9-10]首次提出了使用神经网络进行音频隐写,并表明图像隐写的神经网络模型不适用于音频隐写,极大地提升了隐写算法的隐藏容量;文献[11]提出了一种基于深度神经网络(Deep Neural Network,DNN)的源混合和分离的音频隐写模型,在时域中将音频与其他未知的音频混合,利用源分离的方法提取秘密信息。为了进一步提升音频隐写方案的性能,本文提出一种融合多分支膨胀卷积与注意力机制的音频隐写算法,利用多分支膨胀卷积网络完成原始载体音频的编码,同时在编解码器的不同位置上引入瓶颈注意力(Bottleneck Attention Module,BAM)残差块,以提高网络对音频有效特征的表征能力。这样的设计使得整个系统在网络参数轻量化的情况下能全面地捕捉音频特征,从而完成具有较高透明性、鲁棒性及较大的隐藏容量的端到端的音频隐写任务。
1 多分支膨胀卷积与残差注意力机制
1.1 多分支膨胀卷积
受到文献[12]的启发,本文选用通道式注意力机制来设计多分支膨胀卷积(Multi-Branch Dilated Convolutional,MBDC)网络,实现不同膨胀率的多重卷积的通道选择,在不增加参数量、不失去分辨率的情况下,结合上下文信息增大感受野,融合多尺度特征。MBDC、膨胀卷积和普通卷积的比较结果如表1 所示,其中N为普通卷积的参数量基准。由表1 可知,MBDC 具有比普通膨胀卷积更显著的特征采样率,同时具有比传统卷积低得多的计算复杂性。

表1 MBDC、膨胀卷积与普通卷积的对比
本文提出的MBDC 的结构如图1 所示,主要采用3 个分支来承载不同膨胀率的卷积层,以产生不同大小感受野的特征映射。本文选择的膨胀系数为{1,2,4},这样感受野下利用的区域是连续的,同时3 个扩张卷积层的卷积核大小相同,通过采用并行结构,可以在不显著增加计算成本的情况下获得更广泛的感受野。

图1 MBDC 结构
在编码器部分采用MBDC 模块,其参数量仅为普通卷积的1/3。具体的计算公式为:
式中:δ表示先进行softmax 操作,再进行批量归一化(Batch Normalize,BN)与ReLU 操作;Md1(x)表示膨胀率为1,卷积核大小为3×3 的膨胀卷积操作;Md2(x)表示膨胀率为2,卷积核大小为3×3 的膨胀卷积操作;Md4(x)表示膨胀率为4,卷积核大小为3×3 的膨胀卷积操作。
音频输入经过MBDC 后,本文引入了一种基于残差网络与瓶颈注意力的模块来增加网络的关键特征学习能力。
1.2 残差注意力机制
在处理复杂的输入数据时,常常面临信息超载的挑战,即输入数据中包含大量冗余和无关信息,这影响了模型从中提取有效特征的能力,从而降低了模型性能。为了应对这一问题,本文引入注意力机制。通过学习权重分配,注意力机制可以自动学习到关键特征,并将更多的注意力集中在与任务相关的重要特征上,有效地解决了信息超载的问题。
本文采用的BAM 是一种简单而有效的注意力模块,可用于任何前馈卷积神经网络。对于输入的特征图,BAM 会生成注意力图来强调重要元素,如图2 所示。生成注意力图的过程分为通道注意力和空间注意力两个分支流程。通道注意力融合每个通道的特征,学习不同通道间的关系,而空间注意力通过学习上下文信息掌握不同空间位置的特征。

图2 BAM 注意力机制流程
本文在BAM 网络的基础上进一步增加残差得到R-BAM 模块。给定输入特征为Fin∈RC×H×W,定义中间特征为F∈RC×H×W,注意力模块按照通道顺序相应计算一维通道注意力特征Mc∈RC×1×1和二维空间注意力特征Ms∈R1×H×W。整个过程如下所示:
式中:f为卷积操作,f1×1为卷积核大小为1×1 的卷积操作,f3×3为卷积核大小为3×3 的卷积操作,W0∈RC/r×C,b0∈RC/r,W1∈RC×C/r,b1∈RC。
2 音频隐写算法
2.1 隐写方案
本文针对音频数据提出一种基于多分支膨胀卷积与残差BAM 注意力机制的端对端的隐写方案。此方案提出的模型隐藏与提取流程将在频域中进行,但为了将音频信号以时域形式进行传输,本文借鉴文献[13]的方法,在传输过程中对音频信号进行短时傅里叶变换和逆短时傅里叶变换,并加入模型中,将其作为一个可微层以约束网络模型的输出。隐写流程如图3 所示。

图3 隐写方案流程
本文研究的方案模型包括3 个关键模块:(1)利用Ec从载体中学习并提取潜在冗余,以嵌入秘密信息完成隐藏;(2)Dc负责对含密音频解码;(3)Dm对解码后的数据进行重建,从中提取出秘密音频。
本文将载体c和秘密音频m作为音频隐写的输入,经过音频隐写网络后输出为含密音频和重构音频。为满足音频隐蔽通信的需求,本文需要对神经网络不断进行训练优化,而神经网络的参数优化是通过最小化载体音频c与含密音频、秘密音频m与重构音频之间的均方误差(Mean Square Error,MSE)函数来实现的。损失函数的表达式为:
式中:参数Lc与Lm分别表示含密音频和重构音频对应的MSE;λc和λm的取值关系到对含密音频和秘密音频重构的平衡。
2.2 网络模型
本文使用膨胀卷积与注意力网络相结合的深度学习网络,其主要分为Ec,Dc,Dm3 个模块,同时每个模块又由几个子模块组成。Ec由MBDC 模块、Gconv 模块与R-BAM 模块组成,Dc模块由Gconv模块与R-BAM 模块组成,Dm由Gconv 模块与R-BAM 模块组成。其中,R-BAM 借鉴经典ResNet网络的残差结构,引入残差可以加速网络模型的收敛速度并且防止出现深层网络梯度爆炸的情况。各个模块的具体结构分别如图4~图8 所示。

图4 R-BAM 模块

图5 Gconv 模块

图6 Dc 模型

图7 Ec 模型
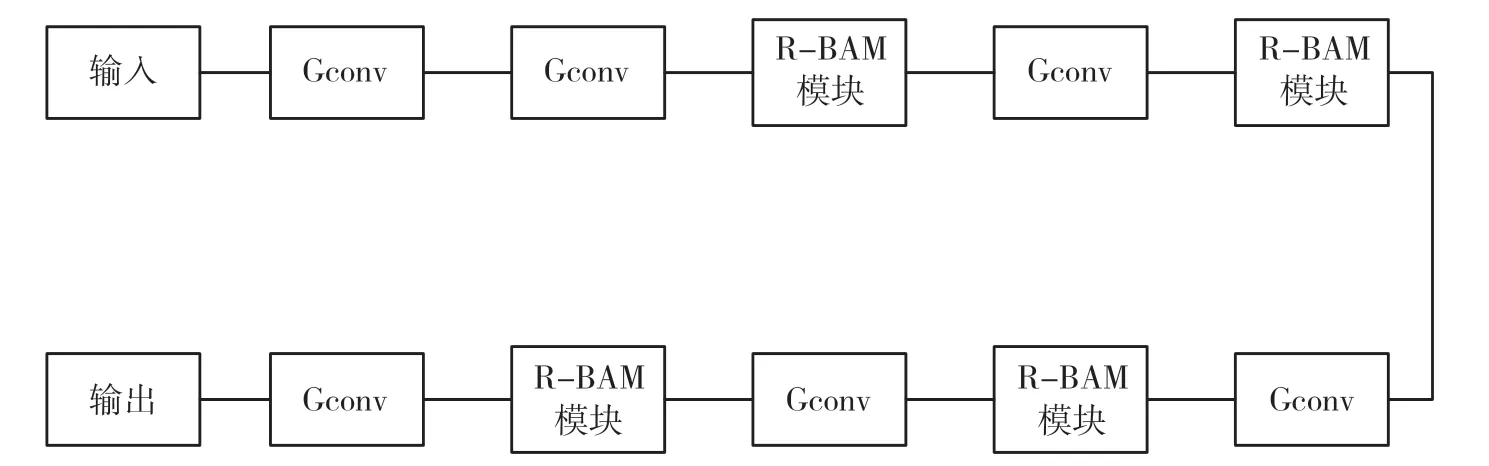
图8 Dm 模型
3 实验结果及讨论
本次实验分别在DiDiSpeech[14]和TIMIT[15]两类语言(中、英文)的数据集上对采用的网络模型进行评测,数据集按照7 ∶2 ∶1 的标准比例分割为训练、验证和测试集。两种音频信号数据的采样率均为16 kHz。为了提升模型效率,短时傅里叶变换(Short-Time Fourier Transform,STFT)中傅里叶采样点数设置为512,各段间重叠采样点数设置为256。通过随机选择数据集中的一条音频作为载体信息,与任意一条其他音频作为秘密信息形成一组训练数据,以1 ∶1 的形式完成嵌入操作,实验中对载体音频与秘密音频的选择是完全随机的。所有模型均采用经典的Adam 优化器进行参数优化,初始学习率设置为0.001,并采用每隔15 个epoch 学习率下降50%的策略进行训练,网络以目标损失函数连续3 个epoch 不下降作为停止训练的条件,最后给出模型在通用数据集上的临界值。在损失函数的设计中,λc设置为3.2,λm设置为0.8,以此来权衡载体音频与含密音频、秘密音频与重构音频之间的损失。
3.1 透明性测试
本节用于评价音频隐写算法透明性的含密音频信噪比SNRs'、重构音频信噪比SNRc'、含密音频的均方误差MSEs'、重构音频的均方误差MSEc'的计算公式为:
式中:符号s(t)和s'(t)分别为时域中的原始载体音频和含密音频,c(t)和c'(t)分别为时域中的原始秘密音频和重构音频,'(t)和(t)分别为模型预测的含密音频与重构音频。
为了能够更加客观地评价含密音频与重构音频的听觉质量,本文采用了客观的语音质量评估(Perceptual Evluation of Speech Quality,PESQ)方法。
表2 分别给出了本文提出的网络模型在中、英文数据集上进行音频隐写实验后的透明性测试结果。根据国际唱片业联合会标准,当含密音频信噪比SNR>20 dB 时,隐藏的秘密音频不可察觉,拥有较好的透明性。在TIMIT 英文数据集下实验,含密音频的信噪比最高可达25.82 dB,重构音频的信噪比最高可达12.92 dB;在DiDiSpeech 数据集下,含密音频的信噪比最高可达25.78 dB,重构音频的信噪比最高可达13.99 dB。

表2 透明性分析
PESQ 是ITU-T P.862 建议书中提供的客观语音质量感知评估方法,它能将客观的语音质量评估映射到主观平均意见分(Mean Opinion Score,MOS)刻度范围。评估得分在1.0 和4.5 之间,得分越高,音频质量越好。表3 给出了中英文样本分别通过隐写网络后得到的PESQ 值,含密音频的PESQ 在3.8以上,人耳主观听觉不能发现异样;重构音频的PESQ 都大于2.6,可以清楚理解提取得到的重构秘密音频的语义。表4 给出了本文提出的隐写方案与其他一些研究的含密音频信噪比的比较结果。可以看出,本文的隐写方案生成的含密音频信噪比更高,透明性更好。

表3 含密音频与重构音频的PESQ

表4 本文方案与其他隐写方案的信噪比对比
3.2 鲁棒性测试
本节对隐写网络模型进行抗干扰能力的测试,主要在训练过程中对样本分别添加Gaussion 和Speckle 两种噪声,定义σ为噪声强度,其计算公式如下:
表5 给出网络模型对中、英文数据集在对应噪声类型和噪声强度下的含密音频信噪比和重构音频信噪比。通过结果可以看出,本文提出的隐写模型在带噪环境下,其含密音频信噪比没有较大的变化,其重构音频信噪比也和无噪条件的结果相差不大,结果仍然呈现含密音频的高透明性与重构音频的高度可理解性。结果表明,本文提出的音频隐写方案具有良好的鲁棒性。

表5 鲁棒性分析
3.3 隐藏容量
对于隐写方案来说,除了透明性、鲁棒性,还需要衡量其隐藏容量。音频隐写中的隐藏容量Cap是指在一定时间内可以隐藏的秘密信息比特数,用每秒比特数(bit/s)来衡量。计算公式为:
式中:T为含密音频的时间长度,B为隐藏到含密音频中总的秘密信息比特数。
本文采取的深度神经网络隐写方案的隐藏容量为4 001.833 bit/s,与文献[9]和文献[16]的容量大小相同,是传统隐写方法[15,17-19]的20 倍左右。由此可以看出,深度神经网络采用的音频隐写方案拥有更好的冗余提取能力与自适应隐藏秘密信息的能力,极大地提高了音频隐写方法的隐藏容量,弥补了传统隐写方法隐藏容量小的缺点。
4 结语
本文提出了一种结合多分支膨胀卷积网络和残差瓶颈注意力模块的音频隐写算法。该方法选择使用多膨胀率卷积网络来学习音频特征,并使用残差的瓶颈注意力提高模型对音频隐藏位置的学习能力,实现音频完全的自适应编解码及秘密音频的提取。实验结果表明,经过该隐写算法处理的音频具有良好的听觉质量,保持了良好的透明性。此外,该算法对不同程度的加噪干扰具有较好的抵抗力,展现出了高度的鲁棒性,同时该算法拥有高隐藏容量,可以在保持音频质量的同时存储较多的隐藏信息。综合来看,该算法在透明性、鲁棒性和隐藏容量这3 个评价指标上取得了良好平衡。
猜你喜欢
设计(2022年8期)2022-05-25
建材发展导向(2021年9期)2021-07-16
北京航空航天大学学报(2019年9期)2019-10-26
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
电子测试(2018年11期)2018-06-26
通信技术(2018年4期)2018-05-05
雷达学报(2017年3期)2018-01-19
电子制作(2017年9期)2017-04-17
人间(2015年8期)2016-01-09
