
U-Net通道变换网络在腺体图像分割中的应用
2024-03-20 10:32曹伟杰段先华许振伟盛帅
中国图象图形学报 2024年3期
曹伟杰,段先华,许振伟,盛帅
江苏科技大学计算机学院,镇江 212100
0 引言
腺癌是一种来源于腺上皮的恶性肿瘤,对人体健康有极大危害。近年来人们生活作息不规律,导致腺癌成为严重损害人体健康的恶性肿瘤之一(张家宝和肖志勇,2022)。计算机视觉技术快速发展使医学图像成为专家术前诊断的重要手段(赵樱莉等,2023)。在腺癌诊断中,医生通过分析腺体结构大小、形状和其他一些外在表现,来判断腺癌的严重程度并对其进行分级。如何准确高效分割腺体细胞成为临床医学的迫切要求。传统的人工分割方法(任楚岚 等,2022)需要很多先验知识,耗费大量人力和时间,同时存在分割主观性强、分割缺失等问题,限制了分割准确性和效率,降低了临床诊断的可靠性(蒋希 等,2022)。因此开发一种快速、高精度的图像分割机制,对临床腺体病症的判断具有重要意义。
常用医学图像分割方法分为传统的机器视觉方法和基于深度学习的方法。传统方法包括基于阈值的图像分割、基于区域生长的图像分割和基于聚类的图像分割等。这些方法利用图像自身的灰度、色彩和纹理等特征进行分割。孟月波等人(2019)提出一种具有边缘保持的多尺度马尔可夫随机场模型,将分割问题转化为优化问题,有效保持了图像分割结果的边缘,获得了更好的分割结果。但是传统分割方法在面对医学图像分割的复杂情况下,难以满足其高精度要求。随着人工智能视觉技术的迅速发展,深度学习方法在医学图像分割领域得到广泛应用,通过构建多层深度神经网络模型,训练标注好的数据集,实现高精度分割。目前为止,流行的分割框架 有FCN(fully convolutional network)(Shelhamer等,2015)、DeepLab(deep convolutional nets)(Chen等,2014)和U-Net(Ronneberger 等,2015)等,其中U-Net 由于其结构比较简单、所需数据集少、不易出现过拟合现象等备受瞩目。很多学者开始对U-Net进行相关性研究,提出许多基于U-Net 的变体结构,例如U-Net++(Zhou 等,2018)、V-Net(volumetric convcets)(Milletarì 等,2016)、3D U-Net(Çiçek 等,2016)和Attention U-Net(Oktay 等,2018)等。这些研究通过改进U-Net 的结构或针对特定场景加入适用的模块,进一步提升模型性能。但由于U-Net 中的卷积神经网络(convolutional neural network,CNN)存在局部感知性(徐光宪 等,2023),无法准确把握图像全局信息,所构建模型存在一定局限性。
Transformer 的出现给医学图像分割带来新突破,将全局注意力的Transformer 和关注局部性的CNN 结合使用,可以有效提高医学图像分割的精度和效率(Dosovitskiy 等,2021),同时兼顾全局特征和局部细节,是一种具有潜力的研究方向(许聪 等,2023)。许多学者根据这个理论提出两者结合使用的模型,如TransUNet(Transformers make strong encoders)(Chen 等,2021)、Swin-UNet(hybrid vision Transformer with U-Net)(Cao 等,2022)、UCTransNet(U-Net from a channel-wise perspective with Transformer)(Wang 等,2022)、SMESwin UNet(semisupervised with a Swin Transformer-based U-Net)(Wang 等,2022)。Chen 等人(2021)利用多层次的Transformer 来提取图像全局的信息,提高了精度,但是训练时间过长。Cao 等人(2022 )将U-Net 中的CNN 模块替换为Swin Transformer 模块,增强了U-Net 特征提取能力。Wang 等人(2022 )以U-Net 作为网络的主要结构,提出一种Transformer 构成的通道融合变换器(channel cross fusion with Transformer,CCT)来替换U-Net 中的跳跃连接,从通道的角度将编码器多尺度上下文特征信息进行交叉关注融合,产生了更精确的分割性能。
腺体原始图像及其医学图像的分割存在差异,具体如下:1)腺体图像包含大量小目标,易造成分割不足或误分割;2)不同图像中的细胞形态、大小变化差异大(赵宝奇 等,2021),要求模型具有较强的泛化能力;3)腺体图像中分割信息范围广,要求模型能够有效捕获全局信息(霍璐 等,2021)。
为此,本文采用U-Net与Transformer的最新结合模型,即U-Net型通道变换网络U-Net from a channel-wise perspective with Transformer(UCTransNet)作为参考模型,对腺体医学图像的特点进行针对性改进。本文主要从3个方面进行改进:1)改进编码器结构,在编码器开端加入ASPP_SE(atrous spatial pyramid pooling_squeeze and excitation)模块和ConvBatchNorm模块,解决模型提取小目标特征信息不足的问题,同时避免过拟合的问题;2)在编码器和跳跃连接中加入简化后的密集连接,以增强编码器相邻模块特征信息融合;3)在通道融合变换器中引入细化器(Zhou 等,2021),将Transformer的注意力特征图投射到更高维度空间,增强自注意机制能力,解决模型融合速度缓慢问题。密集连接与CCT模块相互结合可以使模型达到更好的效果,改进的算法在腺体医学图像分割上优于现有其他分割算法,可以满足临床腺体图像分割的要求。
1 U-Net型通道变换网络
U-Net 型通道变换网络的结构如图1 所示,模型的基本结构采用U-Net 结构,分为编码器、解码器和跳跃连接模块。编码器捕获低、高级语义特征信息,解码器将捕获到的特征信息上采样到像素级别的分割图,跳跃连接补充编码器在卷积、池化操作中丢失的空间信息到解码器中。

图1 U-Net型通道变换网络Fig.1 UCTransNet
U-Net型通道变换网络模型采用通道融合变换器来替换跳跃连接,将不同分辨率的编码器模块提取的特征信息分割为不同批次大小的图像块,将其重塑为二维批次序列Ti(i=1,2,3,4)输入到通道融合变换器,利用Transformer 的自相关性融合不同层次的编码器模块特征。从通道的角度将编码器多尺度上下文特性信息与交叉注意力融合在一起,捕捉局部跨通道交互,通过协作学习,有效融合尺度语义间隙的多尺度通道特征。U-Net 型通道变换网络有效解决了编码器不同分辨率模块之间以及编码器和解码器之间的语义缺口,实现了更高精度的图像分割。
2 改进的U-Net型通道变换网络
2.1 改进编码器结构
腺体医学图像中存在许多小目标信息,对腺体医学图像高精度分割具有重要作用。U-Net 型通道变换网络的编码器部分仅采用简单的卷积、池化操作,无法充分提取这些小目标特征信息。为了解决这个问题,本文在编码器的开端加入ASPP_SE 模块。ASPP_SE 模块融合了ASPP 模块和通道注意力机制,ASPP 模块利用多尺度空洞卷积,通过不同尺度的膨胀率来获得更大的感受野、更密集的数据特征,可促进编码器小目标特征信息的提取。通道注意力可对图像中的通道信息进行动态选择,在之后CCT模块融合起到重要作用。在ASPP_SE模块充分提取图像特征之后加入ConvBatchNorm 模块,防止出现过拟合现象。
本文具体的改进方法如图2 所示,输入图像会先经过ASPP_SE 与ConvBatchNorm 模块进行不同膨胀率信息的提取,提取出原编码器模块无法提取的小目标信息,再通过原编码器进一步提取特征。

图2 改进编码器结构图Fig.2 Improved encoder structure diagram
ASPP 模块由3 个不同膨胀率的空洞卷积、1 个1 × 1 卷积、1 个ASPP Pooling 组成,模块结构如图3所示。空洞卷积是在标准卷积的基础上注入空洞来扩大感受野,获得更密集的数据特征,同时不改变图像输出特征图的尺寸。ASPP Pooling 是一个自适应均值池化,可以提取各个通道的特征,进而提取全局的特征。ASPP利用不同膨胀率的空洞卷积,从不同的尺度提取输入特征,再将所获取的特征与ASPP Pooling 得到的全局特征进行特征融合,得到比原有特征更密集的语义信息。本文修改空洞卷积的膨胀率进行实验对比,得出在膨胀率为3,6,9 的时候,模型的精度是最高的。

图3 ASPP_SE+ConvBatchNorm 模块结构图Fig.3 ASPP_SE+ConvBatchNorm module structure diagram
在ASPP 后端加入SE 通道注意力机制,可以让模型更加关注图像中的重要通道区域,对图像中的信息进行动态选择,在CCT 模块进行通道融合中信息权重大的模块会得到更好的融合。SE 模块由一个全局平均层和两个全连接层组成。全局平均池化层用来进行空间压缩,对输入为W×C×H的特征图实现全局平均池化,得到1 × 1 ×C的特征图,然后通过两个全连接层,将这些特征映射到一个可训练的参数上,用于学习通道注意力。最后将得到的通道权重与特征图对应通道进行二维矩阵相乘,以加强重要信息的权重,得到更好的模型结果,SE 模块结构如图4所示。

图4 SE模块结构图Fig.4 SE module structure diagram
由于腺体图像数据集的稀少,为防止模型训练过程中出现过拟合现象,在提取完特征之后加入ConvBatchNorm 模块,该模块由一个3 × 3卷积层,一个BatchNorm 层和ReLU(rectified linear unit)激活函数组成,其中,卷积层进行特征的提取,BatchNorm层可以将数据归一化,减少不同batch之间数据抖动的情况发生,防止过拟合,加快网络收敛的速度。ReLU激活函数可以有效地防止梯度消失。
2.2 编码器和跳跃连接间加入密集连接
U-Net 型通道变换网络模型利用通道融合变换器来替换跳跃连接,通道融合变换器可以从通道的角度对编码器提取的特征进行全局特征信息的融合。虽然通道融合变换器全局关注能力很强,但存在局部关注能力过弱的问题,相邻编码器模块之间的歧义性并未得到良好的解决。为解决此问题,本文在模型编码器和跳跃连接的连接处,嵌入密集连接,以U-Net++中跳跃连接的密集结构为参考。但实验时发现加入密集连接后,精度反而下降,可能是过拟合现象导致。通过进行不同层数和不同加入位置的实验对比,发现采用1 层密集连接时,密集连接块在CCT 模块之前,模型的精度是最高的。密集连接的结构图如图5所示。

图5 密集连接结构图Fig.5 Structure diagram of dense connections
上层编码器模块经过卷积池化得到下层编码器模块,对下层编码器进行上采样操作,使其与上层编码器模块分辨率一致,将这两层编码器进行通道上的拼接,拼接后分辨率不发生改变,但是通道数为两者通道数之和,对拼接后的模块进行ConvBatch-Norm 模块处理,修正通道数。经过拼接后,上层编码器模块得到了下层编码器模块的特征信息补充,增强了相邻模块之间的语义融合,减少了编码器相邻模块之间的语义差距,再将融合后的模块拆分为小图像块,作为线性序列输入到通道融合变换器。
2.3 自注意力优化
在通道融合变换器融合编码器各个分辨率序列块信息与全局特征信息时,注意力机制起到了关键作用,自注意力机制的强弱代表其融合特征信息的能力。通过增强自注意力能力,可进一步提高模型的分割精度,CCT 模块结构如图6 所示。图中Qi(i=1,2,3,4)为由U-Net 通道变换网络编码器部分中不同分辨率大小的序列块线性转化得到,K、V为编码器不同分辨率大小序列块拼接得到的全局信息,d为序列块的长度,CΣ为不同分辨率序列块的维度之和,ψ()为实例归一化,σ()为softmax 函数。Oi(i=1,2,3,4)为Qi、K、V经过自注意力计算得到的不同分辨率序列块与全局特征信息融合的结果。

图6 CCT模块结构图Fig.6 CCT module structure diagram
自注意力机制计算为
目前,自注意力增强的大多数研究都是通过设计更复杂的结构或者训练方法,这种方式存在问题,随着训练的加深,会导致自注意力内的不同模块之间越来越相似,大大降低自注意力的性能。为了解决这个问题,进一步提升模型精度,本文在通道融合变换器的自注意力机制中加入细化器DLA(distributed local attention),用于细化注意力的关注图,将多头注意力投射到更高维度空间用于促进多样性的扩展,再利用头部卷积来增强注意力图的空间上下文和局部模式,有效地结合自我注意力和卷积的优点,最后再用一个线性投影,将注意力图恢复到初始的分辨率。细化器由一个线性扩展层、一个线性回溯层和3 × 3的卷积层组成,其具体结构如图7所示。

图7 细化器模块结构图Fig.7 Structure diagram of the refiner module
具体而言,细化器主要对CCT 的自注意机制中注意力图A进行进一步优化,其步骤如图8 所示。注意力图A为Qi与K进行相关性计算得到的结果,计算为
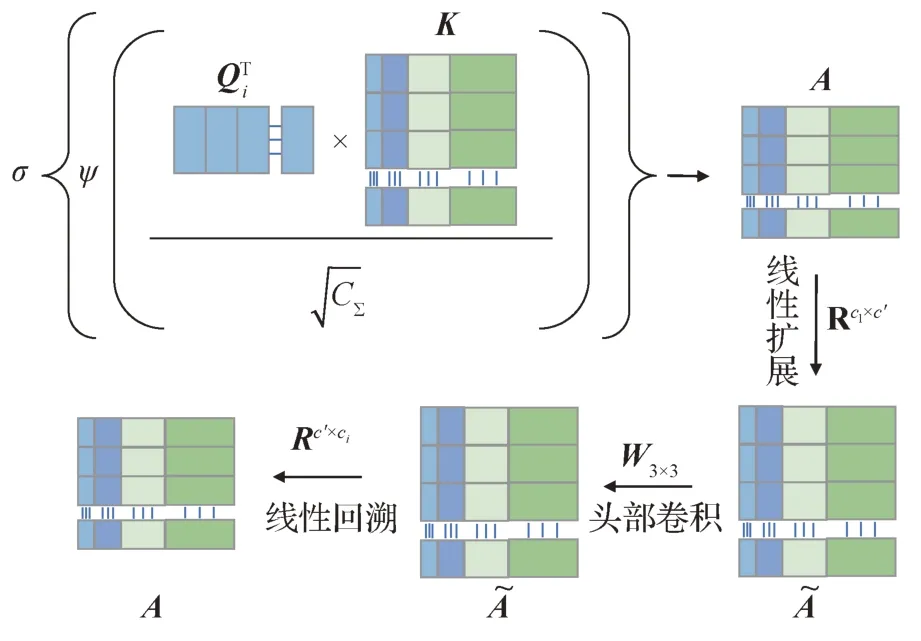
图8 细化器运算步骤图Fig.8 Refiner operation steps diagram
式中,A∈。在得到注意力图A后,使用一个线性投影Wd∈将注意力图A=[A1,A2,…,ACi]投影到一 个新的 注意力 图其 中C'>Ci,通过线性扩展可以使得注意力图A的长度增加,所存储的信息量增多,具体计算为
经过线性扩展后,本文使用新的注意力图来聚合特征,注意力扩展隐含的增加了注意力机制的头部数量,摆脱了特征划分。重新使用可学习的标量对Qi进行权重划分,有效的提高注意力的多样性。之后,本文利用卷积对扩展后的注意力矩阵进行卷积操作,对特定位置进行重新加权,再对局部聚集的特征进行求和,该方法在全局上下文聚合(自我关注)和局部上下文建模(卷积)之间建立很好的协同关系其计算为
3 实验分析
3.1 实验数据集
本实验采用MoNuSeg(multi-organ nuclei segmentation challenge)数据集和Glas(gland segmentation)数据集,如图9 所示。二者均为公共数据集,MoNuSeg数据集是通过仔细注释几名患有不同器官肿瘤并在多家医院被诊断的患者的组织图像获得的,该数据集将能够训练细胞分割模型实现高精度的细胞核分割技术。Glas 数据集由来自T165 期或T16 期结直肠腺癌的3 个H&E(hematoxylin and eosin stains )染色组织学切片的42 幅图像组成。在染色分布和组织结构方面都表现出很高的受试者间变异性。
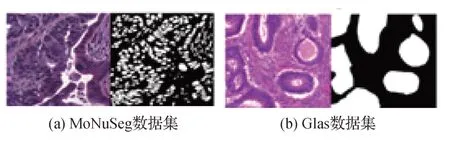
图9 医学数据集Fig.9 Medical datasets((a)MoNuSeg;(b)Glas)
3.2 实验平台
网络优化实验基于python3.7环境,采用pytorch作为深度学习的框架,利用CUDA11.0 和CUDNN,加快GPU 运算。设置Adam 作为模型的优化器,初始学习率设定为0.000 1,每个批次训练4 幅图像,输入图像的分辨率为244 × 244 像素,序列块的分辨率为16 × 16像素。在硬件方面,本文基于Unbutu系统的计算机上进行实验,该计算机配备NVIDIA GeForce RTX 2080,12 GB 显存,足够运行本文所有的网络优化实验。
3.3 模型评估方法
本文采用医学图像分割算法中的常用性能指标平均:索伦森—骰子系数(Dice)和交并比(intersection over union,IoU)系数对改进后的模型进行评估。实验结果采用3次5折交叉验证法,将原始数据分成5 组,将每个子数据集分别做一次验证集,结果加和平均得到最后的结果。
Dice 是一种集合相似度度量函数,用来表示两个样本的相似度,是医学图像分割中使用频率最高的指标。Dice系数越高,表示二者之间的相似性越高。
IoU 是一种用来衡量结果位置信息准确度的一个标准。IoU的值越大,推测的物体区域就越准确。
3.4 实验结果与分析
3.4.1 消融实验
为准确论证所阐述改进点的有效性,本文以参考模型在两个数据集上的实验结果为基准,逐一进行对比参照实验,除改进点不同其余实验环境均相同,在MoNuSeg数据集上的实验结果如表1所示。

表1 在MoNuSeg数据集上的消融实验结果Table 1 Ablation experiments on MoNuSeg dataset
本文采用同样的方式对Glas数据集进行改进点测试,实验结果如表2所示。

表2 在Glas数据集上的消融实验结果Table 2 Ablation experiments on Glas dataset
根据表1与表2所展示的数据可以得到,本文提出的改进方法在提高腺体图像分割精度上具有一定有效性,模型加入创新点后,在两个数据集上的分割精度显著提升,不同改进点之间相互结合,可产生更好的实验效果。在观察结果时,可看到加入密集连接后,精度提升幅度最明显,说明跳跃连接中将局部融合与全局融合搭配使用具有一定参考性。
3.4.2 密集连接层数对比
本实验第2 个创新点以U-Net++网络结构中的多层密集连接为参考,密集连接层融合相邻模块特征信息,CCT 模块负责融合全局模块特征信息。但简单地将两个结构拼接在一起,并未起到很好的作用,甚至精确度发生了下降。研究发现,可能产生了过拟合现象。本文在加入其他模块的情况下,进行多次实验对比,发现在减少密集连接层数后,精确度得到了大幅提升,选用1 层密集连接的时候实验效果最好,本文以Glas数据集为例,将不同层数的实验结果进行展示,如图10所示。

图10 不同层数对比图Fig.10 Comparison chart of the number of different layers
根据实验所展示的结果可以看到,当层数为1的时候,模型的准确度是最高的,任意增加密集连接的层数后,模型的精度大幅度降低,产生了过拟合现象,层数2、3、4 的结果接近。为了进一步验证密集连接的效果,本文采用包含不同层数密集连接的分割网络对腺体图像进行分割预测,得出分割结果图,并将其与原网络的分割结果图进行对比。
不同层数的分割结果如图11 所示。从图11 可以看出,层数为1 层时,模型对凹陷区域和缝隙的关注更加明显。例如红色方块标注的地方为一块凹陷区域,当层数为2、3和4层的时候,此处凹陷被填充,原网络此处的效果没有加入层数为1 的密集连接的分割效果好;蓝色方块标记的缝隙,原网络此处缝隙被忽略,添加1 层密集连接后,模型对腺体医学图像的局部特征把握能力增强,此处的缝隙分割效果变好,随着层数增加,模型细节关注能力减少,分割的缝隙变得细小,模型分割效果也变得越来越差。

图11 不同层数预测图Fig.11 Prediction charts for different layers
3.4.3 密集连接层添加位置对比
加入密集连接层后,本文对密集连接与CCT 之间组合进行研究,设置了3 种结构进行训练,具体展示如图12所示,并对其实验结果进行分析。

图12 密集连接与CCT结构图Fig.12 Dense connection with CCT structure diagram

图13 密集连接与CCT不同结构对比Fig.13 Comparison of dense connections and CCT structures
第1 种搭配结构是将密集连接层加在CCT 模块的前面,先局部信息融合再全局信息融合;第2 种是将密集连接层添加在CCT 模块的后面,先全局信息融合再进行局部信息融合;第3 种是将密集连接层与CCT模块并联,局部融合与全局融合同时进行,将所得到的结果通过卷积进行融合。
3.4.4 其他检测算法对比
为了验证本文中的改进方法对腺体图像的分割性能,本文将改进后的算法与U-Net 及其他的一些变体,如U-Net++、TransUNet、Swin-UNet、UCTransNet、DoubleUNet(DCA)(Ates 等,2023)和HistoSeg(quick attention with multi-loss function for multi-structure segmentation)(Wazir和Fraz,2022)模型进行对比,以Dice 系数和IoU 系数作为对比指标,采用early stop操作,训练50 次,观察验证集的数值是否存在上升趋势,若50 次后数值没有上升,模型训练终止。为了防止过拟合,采用3 次5 折交叉实验,将训练数据分成5 个子集,依次将每个子集作为验证集,其余子集作为训练集,可以保证模型在不同的数据子集上进行训练和验证,对3 次的结果求取平均值作为最后的效果。
实验结果如表3 所示,通过表3 可以看到,本文所使用的模型在腺体医学分割的精确度上优于其他UNet 和Transformer 结合的分割算法,对比最新的工作DoubleUNet(DCA)和HistoSeg,在Glas 数据集上优于HistoSeg,在MoNuSeg 上略低于该网络,后续本文将对其进行研究,对本文网络进一步优化。各个网络分割效果如图14所示。

表3 不同算法的对比Table 3 Comparison of different algorithms

图14 分割结果对比图Fig.14 Comparison of the segmentation results
4 结论
腺体医学图像分割的难点在于分割目标多,分割目标小,存在分割不准确、漏分割等问题。针对这些问题,本文对U-Net 型通道变换网络进行了一系列改进,首先在编码器开端加入融合ASPP_SE 模块与ConvBatchNorm 模块的组合,利用多尺度空洞卷积来获取更多小目标信息,提升模型提取小目标信息的能力,同时避免模型训练出现过拟合现象;其次在编码器与跳跃连接中引入简化后的密集连接,补充局部信息的融合;最后在通道融合变换器(CCT)中加入细化器,增强CCT的自注意力能力,增强模型对编码器全局信息的融合,密集连接与增强后的CCT模块结合使用,可增强模型整体语义融合能力。本文提出的改进方法可以更有效地注意到腺体医学图像中的微小信息,同时更加注重图像全局信息,在分割精度上有了很大的提高。但是本实验只针对腺体进行了研究,对于其他的医学图像未进行太多的训练与实验。未来将会对更加复杂和多样的医学图像进行研究,使模型可以更好地应用于更多的医学分割任务。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
今日农业(2021年9期)2021-11-26
英语文摘(2021年2期)2021-07-22
成都信息工程大学学报(2018年3期)2018-08-29
电子测试(2018年4期)2018-05-09
传媒评论(2017年3期)2017-06-13
电子设计工程(2017年20期)2017-02-10
第二课堂(课外活动版)(2016年2期)2016-10-21
电子器件(2015年5期)2015-12-29
中国质量与标准导报(2015年2期)2015-02-28
