
基于多源遥感特征融合与卷积神经网络(CNN)的丘陵地区水稻识别
2024-03-20 05:08:20曾学亮
江苏农业学报 2024年1期
曾学亮, 郭 熙, 钟 亮, 吴 俊
(1.江西农业大学国土资源与环境学院,江西 南昌 330045; 2.江西省鄱阳湖流域农业资源与生态重点实验室,江西 南昌 330045)
水稻作为中国重要的粮食作物之一[1],其种植面积和产量是影响中国农业经济的重要因素。南方丘陵地区作为中国水稻种植的主要区域之一,在水稻生产中有重要地位[2],因此,及时、准确地获取丘陵地区水稻种植面积尤为重要。传统作物面积统计方式以抽样调查、实地测量等为主,但是这些方法在调查时不但效率低、成本高,而且准确率也有待提高[3-4]。随着遥感技术的发展,使用遥感信息及时、准确地对水稻种植区域进行识别是重要的做法。然而,丘陵地区地形环境复杂,耕地斑块不规则,水稻空间分布破碎化严重,水稻识别难度较大[5],因此,探究适用于丘陵地区的水稻种植区遥感识别方法具有重要意义。
根据数据源的不同,水稻遥感识别可分为单一遥感数据源、时间序列遥感数据源、多源遥感数据融合等方法[6-7]。根据选用分类特征变量的不同,又可分为基于影像、单一特征变量、多特征变量等的识别[8]。对于大尺度区域水稻的提取,常使用中分辨率成像光谱仪(MODIS)、美国国家海洋大气局第三代实用气象观测卫星(NOAA)等中低分辨率卫星数据;对于中等尺度或小尺度范围水稻的提取,使用较广泛的是Landsat、H-J等中高分辨率卫星数据[9]。但对于南方丘陵地区,基于MODIS等中低分辨率或Landsat等中高分辨率数据的水稻识别精度显然不能满足实际生产要求。目前,Sentinel-2卫星影像数据由于具有较高空间分辨率、重返周期短、具有多个光谱波段信息等优势,已经被广泛用于农作物识别[10],此外,高分辨率卫星遥感影像凭借其高空间分辨率的特点,在近年的研究中得到了广泛运用[11]。
在水稻遥感识别的分类算法中,传统监督分类算法有马氏距离法(Mahalanobis distance,MD)、最大似然法(Maximum likelihood,MLC)等,机器学习算法主要有随机森林(Random forest,RF)法、支持向量机(Support vector machine,SVM)法等。在丘陵地区,水稻田块的破碎化和遥感影像的异质化现象导致分类结果更加复杂[11],传统的分类算法对于水稻种植区的识别存在稳定性和适用性不足[12]、分类精度不能满足实际生产要求等问题。深度学习可以从要素之间的复杂非线性关系中挖掘特征和进行自动化学习,实现高效率运算,已逐步成为遥感影像分类和图像识别领域研究的新热点[13]。卷积神经网络(Convolutional neural networks,CNN)是遥感分类中最常用的深度学习算法之一,相对其他算法在遥感影像分类中具有较大的优势[14]。
目前,国内外研究者对水稻遥感识别进行了大量研究并取得了不错的成果,但中国南方丘陵地区水稻种植受地形、气候等条件的限制,云雾天气较多,稻田呈现规模小、破碎分散的特点,水稻遥感识别存在困难,因此选择合适的数据源和分类算法进行水稻遥感识别对于获取丘陵区水稻种植信息尤为重要。此外,利用CNN算法结合多源遥感特征数据对中国南方丘陵地区的水稻进行识别的研究较少。因此,本研究拟以地处丘陵区的江西上高县为研究区,基于Sentinel-2与GF-1卫星遥感影像,结合光谱波段特征、指数特征、纹理特征和地形特征等特征变量,筛选与水稻分离度较高的优选特征,利用CNN分类算法,借助Sentinel-2优选特征数据、GF-1优选特征数据、Sentinel-2与GF-1优选特征融合数据进行水稻识别,并与SVM、MLC分类算法进行对比,旨在探究适用于南方丘陵水稻种植区的提取方法,以期为南方丘陵区水稻遥感识别提供参考。
1 材料与方法
1.1 研究区概况
研究区为江西省宜春市上高县(图1),为江西省农业生产大县和重要商品粮生产基地,所处地理位置为114°28′~115°10′E,28°02′~28°25′N,位于中国长江中下游,是典型的南方丘陵区域,县域耕地面积3.47×104hm2,占土地总面积的25.73%,主要粮食作物为水稻,种植方式为双季稻和单季稻混种。
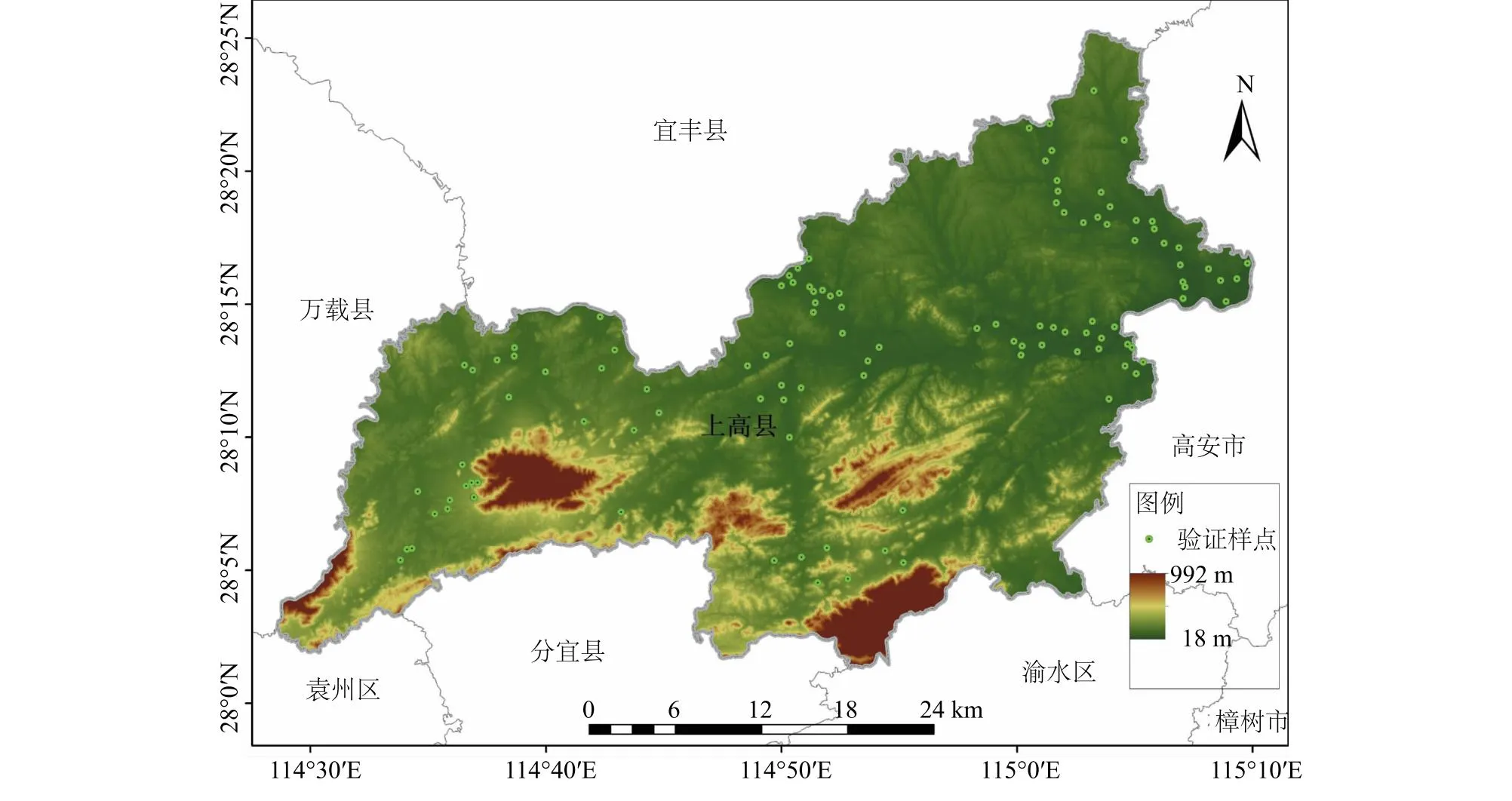
图1 研究区范围示意
1.2 数据来源及处理
Sentinel-2卫星是高空间分辨率、高重访周期的多光谱成像卫星[15]。GF-1卫星是中国高分辨率对地观测系统的首发星,具有高空间分辨率、高时间分辨率的特点。水稻生长期与成熟期的遥感识别精度较发育期的遥感识别精度更高[16]。结合上高县晚稻生长周期与可获取数据情况,确定本研究的遥感影像获取时间为晚稻孕穗期。如表1所示,本研究选取了Sentinel-2卫星影像数据2景、GF-1卫星PMS影像4景,成像时间分别为2021年9月21日、2021年9月26日,均处于晚稻孕穗期,云量均在5%以下[Sentinel-2影像数据来源于美国地质勘探局(USGS),网址http://glovis.usgs.gov/;GF-1影像数据来自江西省遥感中心]。
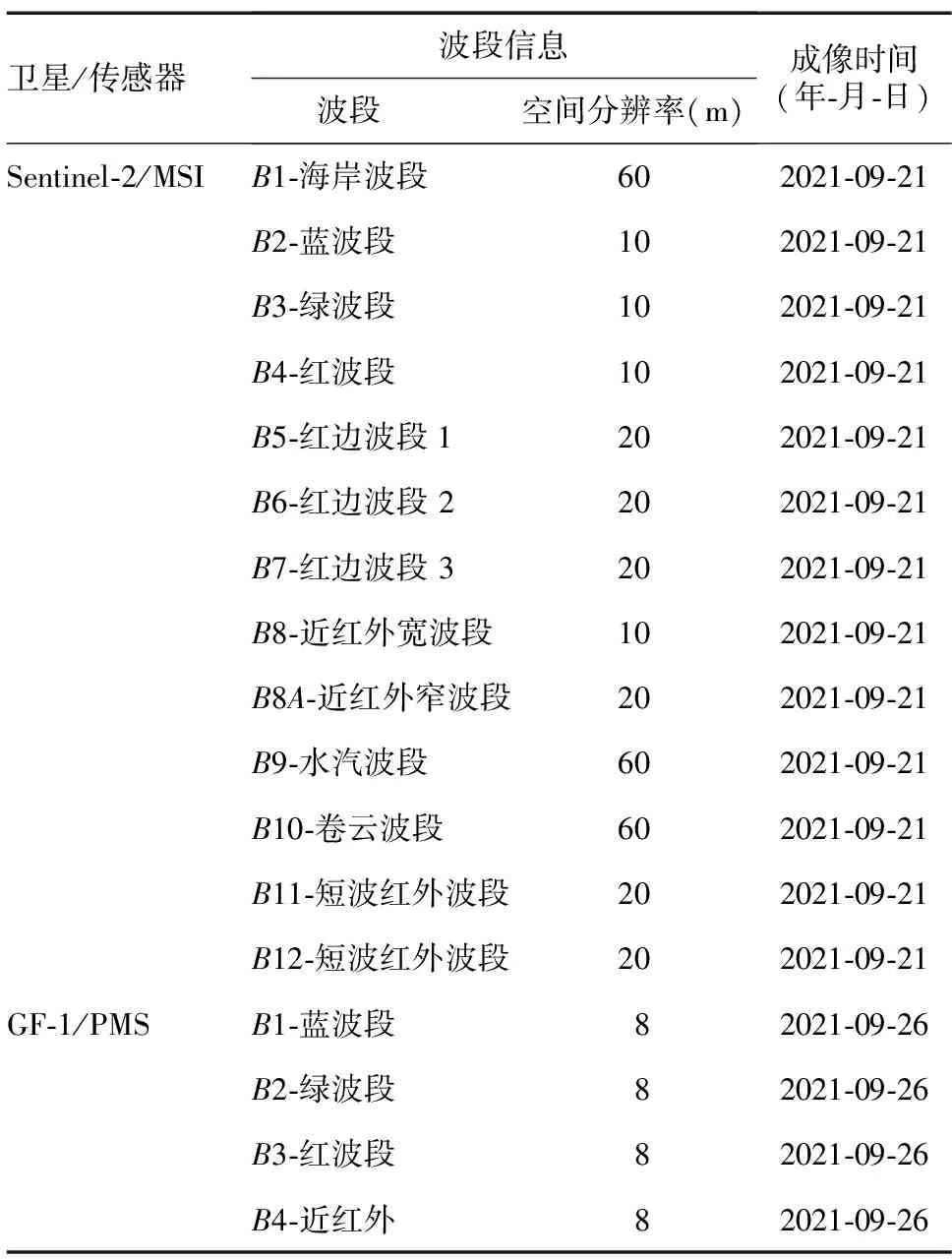
表1 多源遥感影像数据
对获取的遥感影像数据进行辐射定标、大气校正、几何精校正等预处理,同时对Sentinel-2影像的各波段运用三次卷积法将其空间分辨率重采样为8 m,使之与GF-1影像的空间分辨率一致[17],之后对其进行影像拼接与裁剪,得到研究区内的影像(图2)。

图2 预处理后的遥感影像
为方便训练样本的选取、野外实际数据的验证和精度计算,于2021年10月到实地进行调查,共获取113个研究区内晚稻样本点,采样借助全球定位系统(GPS)定位仪进行坐标的确定,结合GF-1全色影像(2 m分辨率)对样本点进行定位。其他数据还包括30 m数字高程模型(DEM)数据(数据来源:USGS;网址:http://glovis.usgs.gov/)等。
1.3 研究方法
在本研究中,首先对Sentinel-2、GF-1及DEM数据提取光谱波段、植被指数、水体指数及地形与纹理特征等特征变量,组成特征变量集,再利用分离阈值法(SEaTH)从特征变量集中筛选出对各类别分离度较大的特征变量,即为优选特征。然后用卷积神经网络算法对Sentinel-2优选特征数据、GF-1优选特征数据及Sentinel-2与GF-1优选特征融合数据进行研究区晚稻的识别,并用支持向量机与最大似然分类法进行分类得到晚稻识别结果。最后对不同数据情况下各分类方法得到的结果进行识别精度与效果的对比分析。
1.3.1 分类特征的选取 识别过程中使用的分类特征集基于不同数据源的光谱波段、植被指数、水体指数及地形与纹理特征[18]进行选取。考虑到水稻具有植物特征及需水生长的特性,本研究选取了基于Sentinel-2的植被指数与水体指数等变量,基于GF-1的植被指数与水体指数共14个(表2)。此外,本研究选取了8个基于二阶矩阵的纹理滤波,包括均值、方差、协同性、对比度、相异性、信息熵、二阶矩和相关性。考虑到南方丘陵区地形复杂的特征,利用DEM数据提取坡度、坡向、地形起伏度。加上遥感影像原始波段,分别得到基于Sentinel-2影像的42个分类特征和基于GF-1影像的29个分类特征。

表2 分类特征指数信息

续表2 Continued 2
如果将上述选取的42个Sentinel-2分类特征与29个GF-1分类特征全部用于分类,不仅会使分类时间加长,还会因数据冗余而影响分类精度。为减少数据冗余,利用分离阈值法进行筛选。用SEaTH[37]的J-M(Jeffries-Matusita)距离判断类别间的可分离性,其值范围为[0,2],其值接近0,代表2个类别在某一特征上几乎无差异;其值为2,代表2个类别在某一特征上能够完全区分开。根据公式(1)和公式(2)计算不同类型特征值的分离度(J):
J=2(1-e-B)
(1)
(2)
式中:J为分离度;B为巴氏距离,用于计算因子之间的距离;m1、m2为2种不同样本的某一特征分布的均值;σ1、σ2为2种不同样本的某一特征分布的标准差。
结合野外调查数据与GF-1全色遥感影像辅助进行目视解译,在研究区内选取训练样本且样本图斑不覆盖野外采样实际验证点所在田块,其中水稻、林地、水域、建设用地和其他地类样本图斑数量分别为504个、557个、193个、458个和337个。计算各类样本中各分类特征的均值、标准差,根据公式(1)计算J值,选取前8个水稻类别参与计算且J>1的分类特征,保留涉及其他类型的J值最大的2个分类特征,包括重复分类特征,即为优选分类特征集。
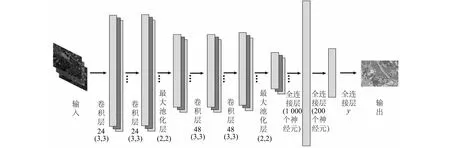
1.3.2 分类方法 CNN能够对神经元进行局部连接、权重共享、池化,在处理二维结构数据时具有快速、高效等优势[38]。将不同分类特征集与特征样本添加到CNN模型中进行训练、验证及分类,能够将输入的特征层层变换,把原先的空间特征转换到新的特征空间,实现特征的分层抽象,方便分类和特征的可视化。在本研究中,CNN算法模型框架包括7层(由于池化层无需更新权值参数,因而未算在层数里面),模型框架如图3所示。在卷积层中,卷积核数量分别为24个、24个、48个、48个,采用最大池化层,卷积核大小为(3,3),池化范围为(2,2),全连接层神经元数量分别为1 000个、200个。
SVM是机器学习中较为常见的遥感影像分类方法,其算法简单,具有较好的鲁棒性[39];MLC是传统遥感图像监督分类中运用得比较广泛的方法,该方法由各个类别的均值和方差等确定分类函数,从而对每个待分类对象进行类别归属。以上算法模型均在Python 3.7软件中实现,其中CNN利用Keras深度学习库搭建,其他算法利用Sklearn库中相应的机器学习模块实现。
1.3.3 精度验证 晚稻提取精度从2个方面进行验证,一是结合GF-1全色影像进行目视解译后在研究区内随机选取测试集样本,其中水稻类型样本图斑1 329个,林地、水域等非水稻类型样本图斑共1 864个,基于所选测试集样本的像元构建混淆矩阵,计算水稻分类用户精度(UA)、制图精度(PA)、总体精度(OA)及Kappa系数对分类精度进行评价,其计算方法如公式(3)~公式(6)所示:
(3)
(4)
(5)
(6)
式中:mi为第i类分类正确的验证样本像元数量;Ci为第i类真实的验证样本像元总数;Gi为第i类分类的验证样本像元总数;n为分类数;N为验证样本像元总数。
y:输出的结果。
验证晚稻提取精度的另一个方法是利用野外调查数据计算实际验证精度,由于实地验证点的地物均为水稻,非随机选取且未在研究区域均匀分布,因此仅计算其实际验证精度(VA)用于评估研究区晚稻分布图的准确性[40],计算方法如公式(7)所示:
(7)
式中:m为正确分类的调查点数量;M为调查点总数。
2 结果与分析
2.1 分类特征筛选
基于Sentinel-2遥感数据筛选的特征为波段特征B2、B4、B7、B8、B8A、B11与CIgreen(绿叶绿素指数)、NDVIre2(归一化植被指数红边2)、EVI(增强植被指数)、EVI2(增强植被指数2)、MTCI[中分辨率光谱成像仪(MERIS)陆地叶绿素指数]、RVI(比值植被指数)、MNDWI(修正归一化水体指数)、NDVI(归一化植被指数)、OSAVI(优化的土壤调节植被指数),其中6个为波段特征,6个为植被指数,1个为水体指数,2个为红边指数。基于GF-1遥感数据筛选的特征为B1、B2、B3、B4、CIgreen、NDVI、RVI、EVI、MSR(优化简单比值指数)、NDWI(归一化水体指数)、OSAVI,其中4个为波段特征,6个为植被指数,1个为水体指数。
筛选结果表明,植被指数、波段特征在水稻与其他地类的分类中分离度较高,纹理、地形特征在水稻与其他地类的分类中分离度较低,对分类效果无明显影响。此外,在特征融合数据集中,对于不同数据源计算得到的同一指数特征(如NDVI、EVI等),在训练模型中发现,如果全部将其加入融合数据集中,与只保留对水稻类别J值较大的融合数据集进行对比,训练精度略有下降,故本研究中的融合数据集只保留J值较大者。
2.2 水稻识别精度分析
分别对Sentinel-2优选特征数据集、GF-1优选特征数据集及Sentinel-2与GF-1优选特征融合数据集在不同分类方法下得到的结果进行精度的对比与分析。表3为3种数据集利用CNN、SVM、MLC算法得到的识别结果,包括用户精度、制图精度、总体精度、Kappa系数及实际验证精度。Sentinel-2优选特征数据集识别结果显示,CNN算法所得识别结果的各精度指标皆高于SVM、MLC算法识别精度指标,其中总体精度、实际验证精度分别为92.59%、92.04%。GF-1优选特征数据集识别结果显示,CNN算法识别结果的用户精度为95.13%,高于SVM、MLC算法识别结果,但在制图精度上,CNN算法识别结果低于SVM、MLC算法识别结果,说明在用CNN算法对GF-1优选特征数据集进行水稻识别的过程中,有部分水稻地类被错位划分为其他地类,实际验证精度仅为86.73%,低于SVM、MLC算法识别结果的实际验证精度,进一步说明有部分水稻区域未被识别。Sentinel-2与GF-1优选特征融合数据集识别结果显示,CNN算法所得识别结果的各精度指标皆高于SVM、MLC算法识别精度,总体精度为96.19%,分别比SVM与MLC识别结果总体精度高6.26个百分点、8.13个百分点,其Kappa系数与实际验证精度分别为0.93、94.69%,高于SVM、MLC识别结果的Kappa系数与实际验证精度,与总体精度呈现出相同的变化趋势,表明基于野外调查点验证得出的实际验证精度与总体精度接近,总体一致性较好。
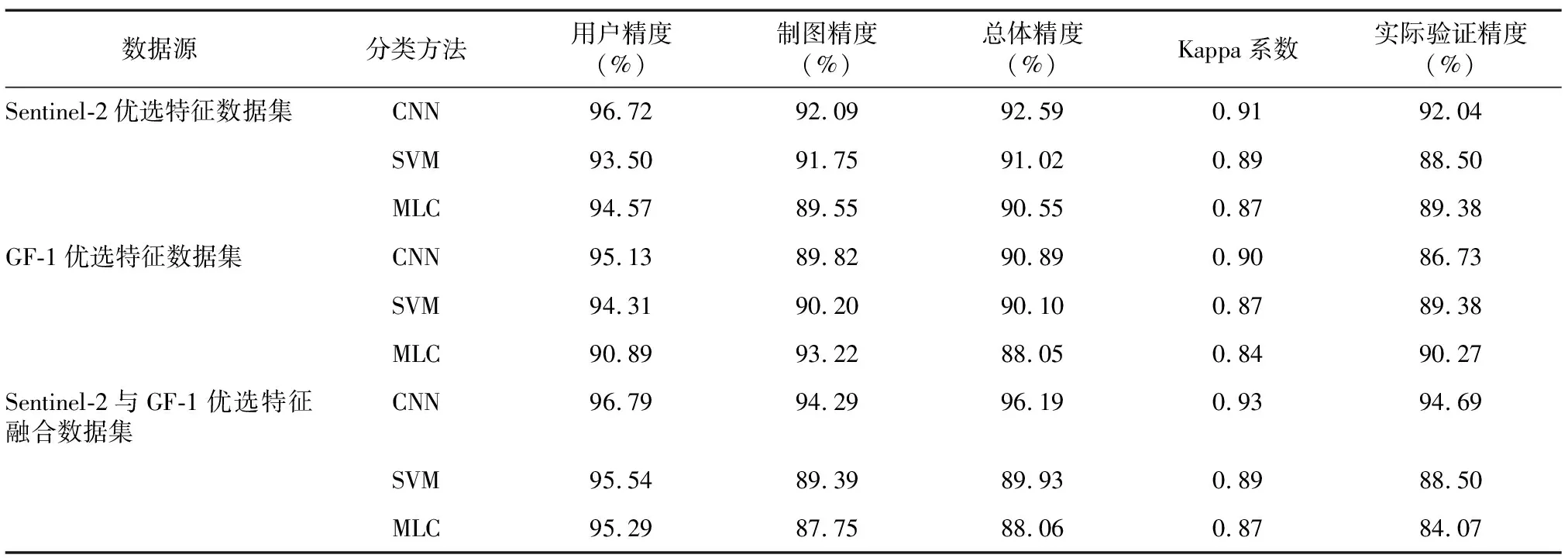
表3 优选特征水稻遥感识别精度
识别结果显示,水稻制图精度总体低于用户精度,说明有部分水稻区域被错误划分为非水稻区域,这也表明在这3种数据集条件下,依然无法排除混合像元对水稻识别的影响。其中利用CNN算法对Sentinel-2与GF-1优选特征融合数据集进行识别所得结果的制图精度与用户精度之间的差异最小,说明在此方案下,水稻的识别精度最好,各项精度评价指标皆高于其他方案,在整个研究区范围内用CNN算法对Sentinel-2与GF-1优选特征融合数据集进行识别有最佳效果。
2.3 识别结果对比与分析
2.3.1 典型区域识别结果分析 对上述3种分类优选特征数据集在不同分类方法下的各方案进行晚稻识别结果制图,选择典型区域对不同方案下的识别结果进行对比。由图4可以看出,3种分类算法得出的结果中,SVM、MLC算法分类结果存在不同程度的“椒盐”噪声现象,而CNN算法分类结果中此现象较少,说明与SVM、MLC算法相比,CNN算法可以在一定程度上克服“椒盐”噪声现象。图4b1、图4b3和图4c1中“椒盐”噪声现象较为明显,地块内部比较粗糙,水稻区域与其他地物之间的边界比较模糊,3个结果均是由Sentinel-2优选特征数据参与的SVM、MLC分类,而在GF-1优选特征数据分类得到的结果(图4a2、图4b2、图4c2)中此现象不明显。在水稻区域的边缘,CNN算法较SVM、MLC算法识别得到的水稻种植区域边缘更加平滑。对比CNN算法下的分类结果可以看出,与图4a1、图4a2相比,图4a3在细小水稻区域的识别过程中,既能识别细碎的水稻区域,又能够在一定程度上保证其田块的完整性。综合对比9种识别结果,不难发现CNN算法分类结果在水稻识别细节上优于SVM、MLC算法分类结果,且通过对Sentinel-2与GF-1优选特征数据的融合,其识别效果能够得到一定提升,与精度的变化趋势相符。

CNN、SVM、MLC见表3注。RGB:红、绿、蓝。
2.3.2 研究区晚稻空间分布 对比上述水稻识别方法,用CNN分类算法、Sentinel-2与GF-1优选特征融合数据集对研究区晚稻种植区域进行识别,获得2021年上高县晚稻种植分布结果(图5)。从晚稻种植空间分布上看,主要分布在上高县东北部的泗溪镇、新界埠镇及中部的锦江镇等地,集中分布在锦江及其支流两侧。2021年上高县晚稻种植总面积为10 761.80 hm2,其中泗溪镇、新界埠镇晚稻种植面积分别为3 678.80 hm2、1 801.36 hm2,分别占全县总种植面积的34.18%、16.74%。利用晚稻野外调查样本点对分类结果进行验证,有107个样本点落在分类的水稻区域中,实际验证精度达94.69%,有6个样本点出现分类错误,经实地调查发现有4个样本点由于晚稻田中存在较多杂草,抑制了水稻的生长,有2个样本点为早稻收割后生长的晚稻,属再生稻,长势不如正常栽种的晚稻。
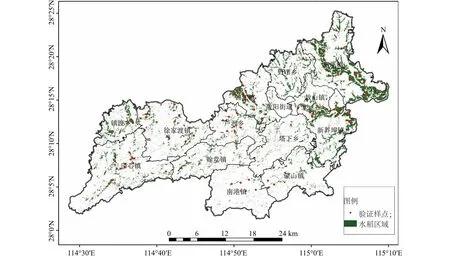
图5 研究区晚稻种植分布
3 讨 论
本研究基于GF-1遥感影像数据与Sentinel-2遥感影像数据,通过构建优选特征分类特征集的组合方案,用CNN、SVM及MLC分类算法对南方丘陵地区晚稻进行识别,研究结果表明:(1)在所有分类方案中,Sentinel-2与GF-1优选特征融合数据在CNN分类算法下对水稻的识别效果最好,其总体精度、Kappa系数分别为96.19%、0.93,结合野外调查数据得到的实际验证精度达94.69%。与CNN分类算法下的Sentinel-2、GF-1单一数据源优选特征识别结果的总体精度相比,CNN算法下Sentinel-2与GF-1优选特征融合数据识别结果的总体精度分别提高了3.60个百分点、5.30个百分点,实际验证精度分别提高了2.65个百分点、7.96个百分点,说明Sentinel-2与GF-1优选特征融合数据较单一数据源在丘陵区水稻识别上有一定的优势。(2)3种分类算法中,与SVM、MLC算法相比,CNN算法在对丘陵地区水稻识别上在精度与识别效果方面有明显优势。CNN能够分析水稻的特征信息,进而对特征变量中的不同地物特征信息进行提取,在一定程度上克服丘陵地区水稻识别过程中出现的“椒盐”噪声现象,对丘陵地区水稻种植区有较好的识别能力。同时在CNN算法下,Sentinel-2与GF-1优选特征融合数据集较单一数据源(Sentinel-2或GF-1)优选特征数据集对水稻的识别效果更好;而在SVM、MLC算法下,随着数据源的增加,即分类特征数量的增加,分类精度总体会有所降低。
尽管本研究利用Sentinel-2与GF-1优选特征融合数据、CNN分类算法在南方丘陵地区取得了较好的水稻识别效果,但是在实际应用时仍然有一定的局限性,在南方地区,由于云雨天气较多,往往难以获取质量较好的遥感影像数据,对水稻遥感识别工作开展有较大的影响,因此可结合雷达遥感数据协同识别[41]。
猜你喜欢
青少年科技博览(中学版)(2022年6期)2022-12-27 19:44:27
军事文摘(2021年22期)2021-11-26 00:43:51
文苑(2020年6期)2020-06-22 08:41:52
文苑(2019年22期)2019-12-07 05:29:00
电子制作(2018年11期)2018-08-04 03:25:38
湖南农业(2017年1期)2017-03-20 14:04:41
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
福建农业科技(2015年3期)2015-02-27 10:20:47
作物研究(2014年6期)2014-03-01 03:39:13
