
基于生成对抗网络的女上装图像属性编辑
2024-03-19 09:08:44肖红梅王伟珍房媛
服装学报 2024年1期
肖红梅, 王伟珍*,2, 房媛
(1.大连工业大学 服装学院,辽宁 大连 116034;2.大连工业大学 服装人因与智能设计研究中心,辽宁 大连 116034;3.大连工业大学 工程训练中心,辽宁 大连 116034)
款型设计是服装生产过程中核心内容产出的重要环节。深度学习技术在近年不断成熟,其中生成对抗网络(generated adversarial network, GAN)模型在服装图像生成领域应用广泛。对于服装图像区域属性编辑任务,学界分别通过改进模型和训练方式开展相关研究并取得显著效果。其中时尚生成对抗网络(FashionGAN)[1]模型可以解决深度卷积生成对抗网络(deep convolution generative adversarial networks,DCGAN)[2]所产生的服装图像结构不一致以及图像模糊的问题,其通过语义分割和文本编码对输入的图像和描述进行处理,并对编辑后的形状加以纹理渲染。Fashion-AttGAN[3]对面部属性编辑生成对抗网络(attribute generative adversan networks,AttGAN)[4]模型的损失函数进行改进,使得模型能够编辑服装图像颜色和袖长两个属性。为展现生成模型在产品设计领域的实用性,属性设计生成对抗网络(design attribute GAN,DA-GAN)[5]在AttGAN基础上采用了新的损失函数。属性编辑生成对抗网络(attribute manipulation generative adversarial networks,AMGAN)[6]模型将条件生成对抗网络(condition GAN,CGAN)模型、卷积神经网络(convolution neural network,CNN)和类激活图(class activation maps,CAMs)算法结合,实现了袖子和领型的精细控制。生成器使用CAMs增强注意机制,且在模型中添加属性鉴别器网络,使得模型专注于指定属性的编辑。TailorGAN[7]模型使用自监督训练方式实现服装的属性编辑,使用对抗损失和重建损失实现不同领型和不同袖长之间的转换。虚拟私人裁缝网络(virtual personal tailoring network,VPTNet)[8]模型将可编辑服装图像属性拓展至衣长,整个模型分为形状生成和色彩纹理渲染两个部分,通过使用变分自编码器生成对抗网络(variational autoencoder GAN,VAE-GAN)模型,对输入的语义图和边缘图进行编码,编辑为目标形状后完善细节。
上述模型从不同角度提供了服装款型设计的方法,但对于款型变化的细节之处研究较少,图像的形状编辑效果存在模糊[9]和无关属性(如图案和纹理)被修改的问题[10]。为解决这些编辑不精准的问题(如袖子轮廓不完整、领型多余轮廓等),文中提出一种优化Fashion-AttGAN模型以提高编辑后的图象质量。
1 技术背景
1.1 GAN生成对抗网络
GAN模型在生成真实自然图像任务中展示出了强大能力,它由生成模型Generator和判别模型Discriminator组成,其结构如图1[11]所示。图1中将噪音向量z输入到生成模型G后生成假图像xfake。将真实图像xreal和假图像xfake输入判别模型,通过分类网络D识别出输入图像的真假。生成模型和判别模型交替训练,使生成器学习到真实图像数据分布。GAN的损失函数见式(1),训练目标为求得损失函数的最小值。
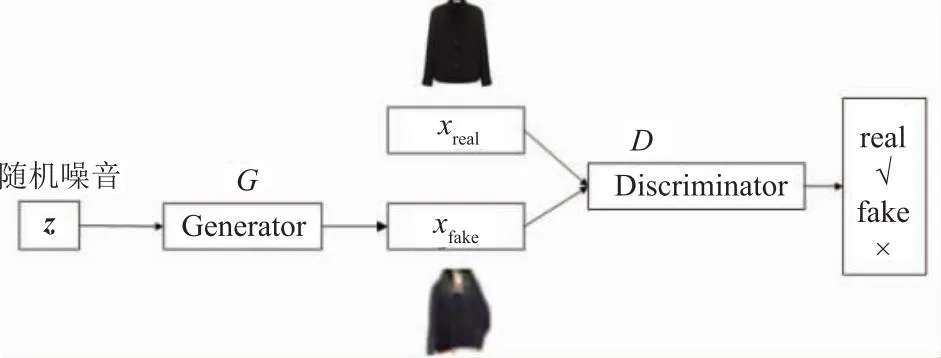
图1 生成对抗网络结构
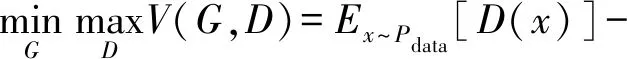
(1)

直接应用该GAN模型容易产生模式崩塌,无法完成服装图像属性编辑。Fashion-AttGAN模型能实现图像属性的精准修改,更适合应用到上装图像属性编辑的研究中。故文中选择Fashion-AttGAN模型作为基准进行改进。
1.2 属性编辑
属性编辑是近年生成式模型关注的热点问题,其可以通过使用特定算法精准控制图像中指定属性的呈现效果,如将女上装图像中的长袖和圆领属性修改为无领和V领。对于此类任务,最终目标是在不影响其他信息的情况下控制颜色、领型和袖长等服装属性。文中以女上装图像的袖长和颜色作为研究变量和载体,通过优化Fashion-AttGAN模型结构,提高编辑效果的细节真实度与完整性。

图2 Fashion-AttGAN流程示意

(2)

(3)

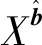
(4)
式中:Xa为真实的具有属性a的图像;Genc为生成器中的编码器部分。
由图2流程示意以及式(1)~式(4)得出Fashion-AttGAN的损失函数包括属性分类损失、重构学习损失和对抗学习损失[3]。
2 女上装图像属性编辑方法
在现有的研究中,由于模型提取特征能力有限,加之数据集分布不均等,生成图像存在袖型、领型的残缺或冗余问题,因此,选取Fashion-AttGAN模型进行改进,通过优化模型结构和损失函数实现服装设计的细节要求。
2.1 特征提取网络优化
原始Fashion-AttGAN中编码器使用5层特征提取网络,从结果来看,并不能满足服装图像的特征提取要求,其生成的袖长存在残缺或冗余,颜色变化受到输入图像自身色彩影响较大。针对这些问题,改进模型增加了生成器和判别器的网络层数,同时使用了U-net结构,U-net通过拼接的方式实现服装图像中颜色以及袖长的特征融合。改进后,生成器的特征提取能力增强。优化后的网络结构如图3所示。由图3可知,分类器和判别器共享前7层网络,卷积层进行卷积操作,反卷积层进行转置卷积操作。

图3 改进Fashion-AttGAN模型结构
2.2 损失函数优化
使用合适的损失函数是最大化GAN生成能力的关键步骤之一。在图3模型训练中,模型的损失函数被分为重构损失、对抗损失和交叉熵损失3部分,分别命名为Lrec,Ladv和Lcls,最终目标是通过训练使得损失函数达到最小值。重构损失保证除指定属性以外的其他属性编辑前后保持一致;对抗损失保证生成图像的真实性;交叉熵损失鉴别生成图像是否满足输入的属性要求。
在Fashion-AttGAN模型结构中,重构损失使用了L1损失函数优化生成器网络,L1损失函数即平均绝对误差。L1损失函数将重构图像与输入图像进行比较,计算平均绝对误差,所得值越小,代表重构图像与输入图像越相似,但这种像素级别的还原会导致图像丢失部分信息,使模型学习到的数据分布存在偏差,生成的图像模糊不清。为优化这一问题,文中研究在重构损失部分加上了(structure similarity index measure,SSIM) 结构相似性[12]损失。SSIM损失函数用来评估生成图像与真实图像之间的相似度,可通过图像的对比度、亮度和结构相关性计算得到。SSIM的取值范围是[0,1],数值越接近1,表示生成图像与输入图像之间的相似度越高,计算公式为
(5)
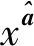
重构损失可表示为
(6)

对抗损失Ladv使用WGAN-GP的方法,由LadvG和LadvD组成,即
(7)

(8)
交叉熵损失也称为属性分类损失,使用交叉熵计算得到,在改进模型中,属性分类损失由LclsC和lclsG组成,分别计算属性a和b的分类损失。属性分类损失表达式分别为
(9)
(10)
式中:LclsC为分类损失函数中分类器的部分;lG为交叉熵函数;a为输入图像中的属性编码;LclsG为分类损失函数中判别器的部分;b为输出图像中目标属性编码。
因此,改进后的Fashion-AttGAN中总损失函数包括LclsG和LclsC组成的判别器损失函数、Lrec和LadvG组成的生成器损失函数和LclsG组成的生成器中解码器额外损失函数。
判别器损失函数表达式为
(11)
式中:Ldis,cls为判别器损失函数;λ2为超参数,需要在训练过程中确定;LadvD为对抗损失函数中判别器部分。
生成器网络损失函数表达式为
(12)
式中:Lenc,dec为生成器中编码器和解码器共同的损失函数;λ1为超参数,需要在训练过程中确定。
生成器中解码器的额外损失函数表达式为
(13)
式中:Ldec为生成解码器的损失函数;λ3为超参数,需要在训练过程中确定。
3 实验及结果
3.1 数据集
实验使用特性保留的虚拟试穿网络(characteristic-preserving virtual try-on network ,CP_VTON)[13]数据集进行训练。数据集中包含14 221张女装上衣图像,每一张图像都有对应的属性向量,分别标注了袖长、衣领和颜色3种粗粒度属性。文中实验选取袖长和颜色2种粗粒度属性作为实验对象,其中袖长有7种细粒度,颜色有6种细粒度,所以实验中总计使用了13种细粒度属性。
3.2 搭建环境
使用PyCharm作为集成开发环境,TensorFlow作为上衣图像属性编辑的学习框架。实验程序运行在NVIDIA GeForce RTX 4080显卡的计算机中,其内存为128G,显卡内存为16G,处理器为i7。
3.3 参数设定
经过反复实验,式(11)~式(13)中超参数λ1设定为100,控制重构损失权重;λ2设定为1,控制输入图像属性a分类损失权重;λ3设定为3,控制目标属性b分类损失权重。迭代次数epoch代表整个数据集被送入到网络完成一轮前向传播和反向传播的次数,batch_size是每次epoch从训练集中随机抽取的部分样本进行一次前向传播和反向传播的样本数。实验中epoch设置为200,batch_size设置为 32。
3.4 结果与分析
将改进模型与Fashion-AttGAN模型进行比较,使用CP-VTON数据集,实现袖长和颜色的编辑。
在袖型编辑效果方面,改进模型的袖型结构连贯性和颜色的编辑效果优于原始Fashion-AttGAN模型。如对“9分袖”这个属性的编辑效果进行改进,改进后的模型相较于Fashion-AttGAN模型残缺部分减少。袖长编辑效果对比如图4所示。

图4 袖长编辑效果对比
颜色花纹编辑效果对比如图5所示。由图5可知,改进后模型生成的颜色更深,而原始模型受输入图像颜色影响较大。由图5可以看出,改进后模型的花纹保留得更加完整。在图5第2行中,输入的服装图像带有花纹,原始Fashion-AttGAN模型在进行属性编辑时,花纹信息有很大损失;在改进模型中添加SSIM损失能最大程度保留与目标属性无关的其他属性,因此在改进模型结果中花纹信息最大程度得以保留。

图5 颜色花纹编辑效果对比
重构图像效果对比如图6所示。相较于原始Fashion-AttGAN模型,改进后模型生成的重建图像清晰度更优。对于服装内轮廓的阴影部分还原得更加真实,如图6第1行输入图像服装内轮廓中有白色标签,在原始Fashion-AttGAN模型重构图像中,此标签相对模糊,在改进模型中更加真实地还原了内轮廓以及标签。

图6 重构图像效果对比
Fashion-AttGAN重构损失趋势和改进模型的重构损失趋势如图7所示。由图7可知,改进模型的网络训练收敛趋势更加平稳,而原始模型出现了大幅度的震荡。
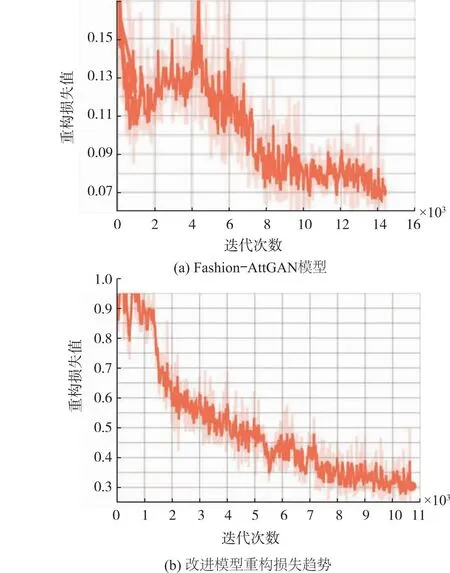
图7 改进模型重构损失趋势
为了证明使用SSIM损失的有效性,对改进后的模型和Fashion-AttGAN模型生成的重构图像的结构相似性指标SSIM和峰值信噪比PSNR (peak signal-to-noise ratio)进行了数据对比。SSIM是衡量两幅图像相似度的指标,其取值范围为[0,1],数值越大代表重构图像越接近输入图像。PSNR是信号最大功率与信号噪声功率之比,用于量化经过影像压缩后图像或视频的重建质量,值越大代表生成图像质量越好。
将改进前后的各20张重构图像以及原始图像输入程序,并测量生成图像的SSIM和PSNR,比较其均值。具体结果见表1。

表1 重构图像质量对比
由表1可以看出,相较于原始Fashion-AttGAN模型,改进后模型SSIM从0.475 6变化为0.606 0,上升27.4%,SSIM值越大代表重构图像越接近输入图像,由此验证了添加SSIM损失函数的有效性;改进后模型的PSNR评分相较于原始Fashion-AttGAN提升2.8%,PSNR值越大代表生成图像质量越好。
4 结语
文中以女上装的袖长和颜色作为研究变量和载体,通过优化Fashion-AttGAN模型结构,增强特征提取能力,增加SSIM损失提高图像的清晰度以提升生成指定属性的能力,从而提高编辑效果的细节真实性与完整性。最终实验表明,改进后的Fashion-AttGAN模型在袖长和颜色的编辑效果以及图像的清晰度上优于Fashion-AttGAN模型,重构图像的SSIM提升27.4%,PSNR值提高2.8%,为服装图像细节变化研究提供技术参考。后续将继续进行参数简化和模型优化,减少训练时长。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
摄影世界(2022年1期)2022-01-21 10:50:14
趣味(作文与阅读)(2021年9期)2022-01-19 01:25:56
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
今日农业(2019年15期)2019-01-03 12:11:33
知识经济·中国直销(2018年12期)2018-12-29 12:22:14
商周刊(2017年6期)2017-08-22 03:42:36
米娜·女性大世界(2016年9期)2016-12-02 19:05:42
山东大学法律评论(2016年0期)2016-08-16 03:24:12
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
