
不同产区杉木生物量与碳储量模型*
2024-03-12 06:50吕梓晴段爱国
林业科学 2024年2期
吕梓晴 段爱国,2
(1. 林木资源高效生产全国重点实验室 国家林业和草原局林木培育重点实验室 中国林业科学研究院林业研究所 北京 100091; 2. 南京林业大学 南方现代林业协同创新中心 南京 210037)
人类活动导致大气中二氧化碳(CO2)浓度增加,是全球气候变化的主要原因之一(Lawet al., 2011)。森林生态系统是最大的陆地碳汇,固定大气中CO2,在全球碳循环中发挥着重要作用,对减缓气候变化至关重要(FAO,2020)。人工造林是公认的减缓气候变暖最为有效且最具生态效应的碳增汇方法之一(Piaoet al., 2009),人造林面积自1990年到2020年增加了1.23亿hm2,到2020年人工林覆盖面积约为2.9亿hm2,占全球森林面积的7%(FAO,2020)。这些人工林不仅提供了大量的木材,还固定了大量的碳。生物量是评价不同林分类型净初级生产力(NPP)的重要依据,是评估森林固碳能力和碳收支的重要参数(Wanget al., 2002)。碳储量既是评价森林生态系统碳收支的基础,也是评价森林碳汇与碳循环问题的重要指标(王效科等,2000;续珊珊,2014)。因此,准确估计人工林生物量和碳储量对于评估生态系统功能、森林在全球碳循环中的作用和森林生产力至关重要(Xianget al., 2021)。
近年来,国内不同地区开发了主要人工林树种的生物量和碳储量方程。李燕等(2010)基于幂函数形式开发了福建和江西的杉木(Cunninghamia lanceolata)人工林生物量方程;Zeng等(2012)开发了适用于我国南方地区的马尾松(Pinus massoniana)人工林生物量模型;辛士冬等(2020;2022)为东北地区红松(Pinus koraiensis)人工林开发了可加性生物量和碳储量方程。建立生物量模型最常用的方法是异速生长模型法,该方法主要利用易于测量的林木因子来推算林木生物量(董利虎等,2020;Xianget al., 2021)。估算植被碳储量最直接、应用最广泛的方法是生物量法(胡小燕等,2020),通常以植被生物量乘以含碳量来计算植被的碳储量,许多研究者估算立木含碳量时采用目前国际上常用的碳含量0.45或0.50计算立木碳储量(Johnsonet al., 1983;Ngoet al., 2013;魏亚伟等,2014)。在建立生物量模型时要考虑到各分量之间的内在相关性,即可加性,指各组分的生物量预测值之和等于总的立木生物量预测值(Zhaoet al., 2015)。似乎不相关回归(seemingly unrelated regression,SUR)可以拟合具有内在相关性的线性方程组,以确保模型的可加性(Parresol , 1999),在众多可加性模型的参数估计方法中,SUR是应用最广泛、最灵活的参数估计方法(董利虎等,2020)。
杉木是我国南方重要的乡土树种,具有较高的经济价值(吴中伦,1955)。第九次全国森林资源清查结果表明,杉木人工林面积990万hm2,蓄积7.55亿m3,分别占全国主要优势人工林树种的27.23%和32.57%,均排名第1,杉木已成为我国最重要的人工林用材树种。杉木广泛分布于我国南方16个省,不同产区的杉木生长差异较大,整个杉木的分布区可分为3个带(童书振等,2019),本研究采样地点分别属于杉木分布带的中带东区、中带中区和杉木分布的南部边缘,虽然不能完全代表杉木的广泛分布区,但是这几个地点可以获得杉木生长的大多数环境和生长数据。国内学者已经构建了许多杉木人工林生物量模型(曾伟等,2016;苏瑞兰,2017;曾鸣等,2013;李燕等,2010;Linet al., 2016;Xianget al., 2021;郭泽鑫等,2022),但这些模型仍存在改进空间:首先,已有的杉木生物量模型建模样本数据量较小,或未包含地下部分生物量;其次,主要拟合杉木各器官的独立方程,未考虑各器官之间的可加性;第三,方程未进行通用性检验,建模样本的胸径范围不清楚。
以不同产区杉木资料建立的杉木生物量、碳储量模型存在较大差异,目前缺乏适合不同产区应用的预测模型,因此,本研究利用福建、四川、江西、广西4地的杉木人工林生物量和福建、四川、广西3地的杉木人工林碳含量实测数据,基于异速生长方程联立方程组,采用SUR对生物量、碳储量模型系统中的参数进行联合估计,保证各组分的可加性。本研究旨在建立适用于不同产区的杉木人工成熟林生物量和碳储量模型,以便准确估算我国杉木人工林的生物量和碳储量。
1 材料与方法
1.1 调查样地自然概况
杉木生物量调查样地分别设置于广西凭祥市大青山试验林场、福建邵武市卫闽林场、江西分宜县大岗山林区和四川泸州市纳溪区,分别属于杉木分布带的南带、中带东区、中带东区和中带中区,4个采样地均属于热带季风气候区,具体信息见表1。
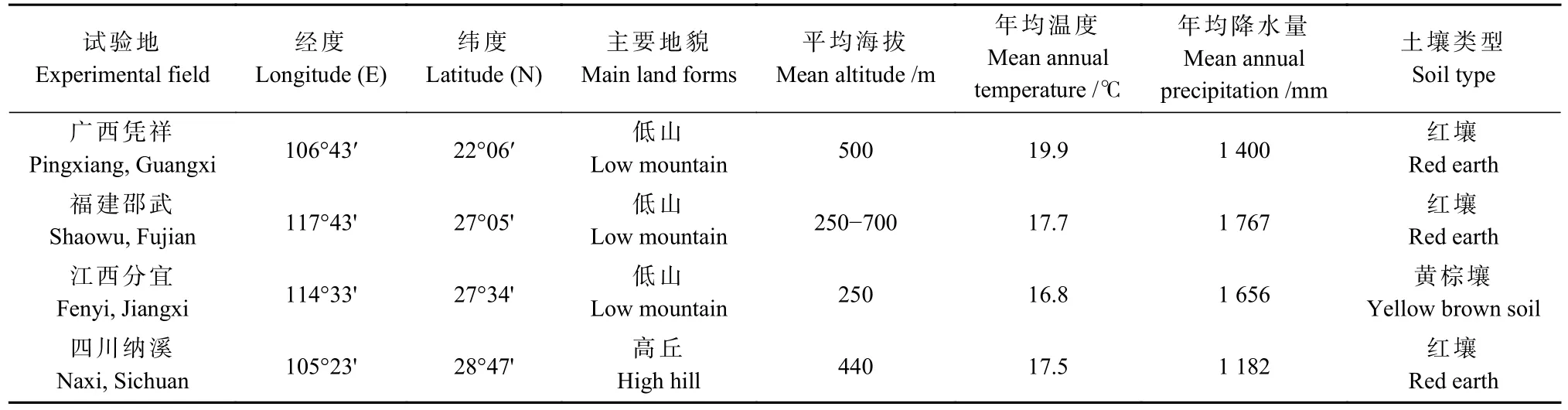
表1 采样地自然概况Tab. 1 Natural conditions of sampling sites
1.2 杉木样木选择
密度试验林均于1981年春采用1年生实生苗营造,均采用随机区组设计,每片试验林均控制5种不同初植密度1 667、3 333、5 000、6 667和10 000株·hm-2,株行距分别为2 m×3 m、2 m×1.5 m、2 m×1 m、1 m×1.5 m和1 m×1 m,每种密度重复3次,共15个小区,每个小区面积为600 m2(20 m×30 m),并在每块小区四周各设有2行同样密度的杉木保护带。福建省杉木幼龄林和中龄林分别于2001年和1993年春采用1年生实生苗营造,林分密度为2 500株·hm-2。 对小区进行每木检尺,测量并记录胸径大于5 cm的杉木,根据每木检尺结果划分径阶范围(采用2 cm径阶距,上限排外法),福建幼龄林径阶范围是6~16 cm,福建中龄林径阶范围是6~22 cm,不同产区成熟林径阶范围是8~36 cm,按照径阶范围在小区中选取样木,每个径阶选取1~2株样木。为保护密度试验林的完整性,样木均在密度试验林保护行中进行破坏性采样,因为保护行与试验林有相同的试验设计,最具代表性。样木信息见表2。
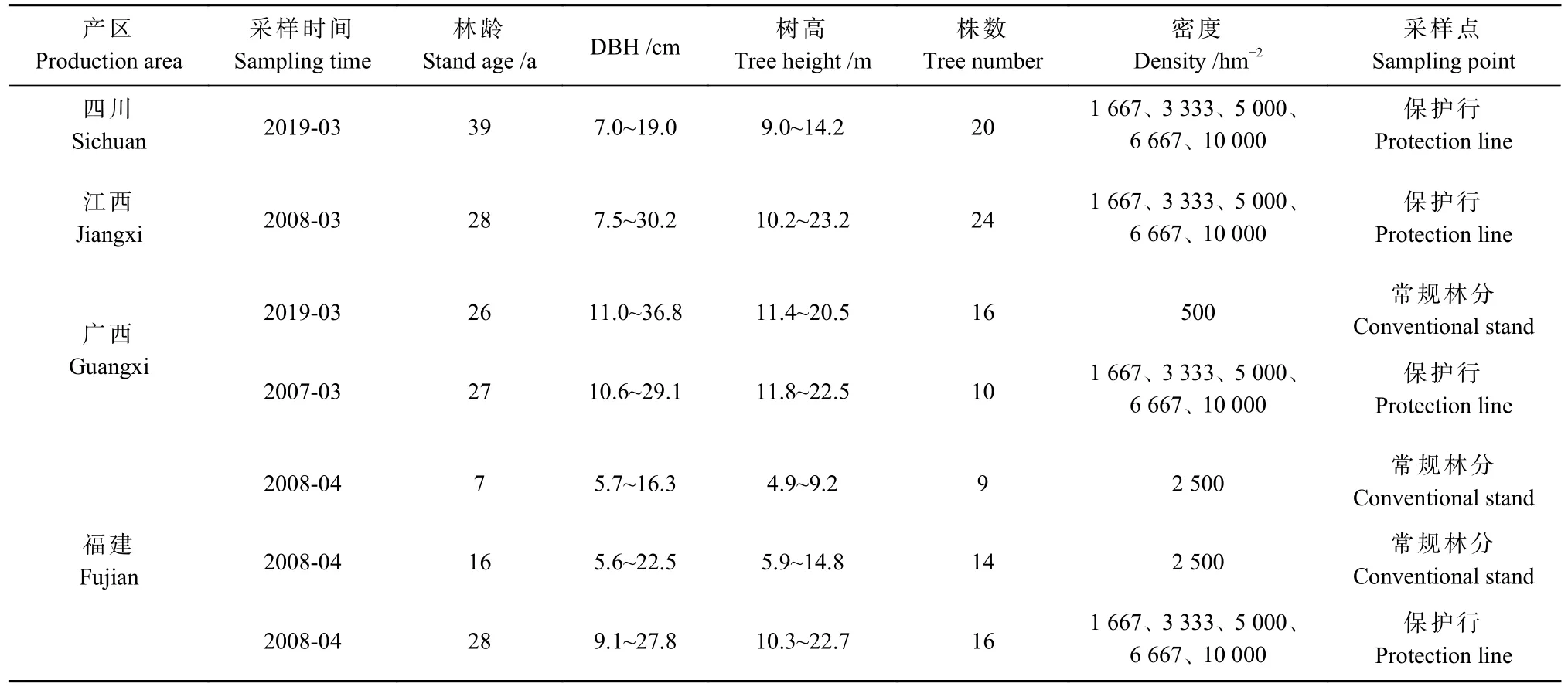
表2 杉木样木基本信息Tab. 2 Statistical table of basic information of Chinese fir samples
1.3 采样方法
4个地区共选取样木109株。将样木伐倒,采用“分层切割法”(林生明,1991),7年生样木按1 m区分段,其他树龄样木按2 m区分段,称量各区分段树干的鲜质量,在每个区分段的基部,切下一个5 cm厚的圆盘,分别称取圆盘干材部分和树皮部分鲜质量,求得圆盘的树皮与干材质量比,根据二者的比值计算该区分段干材和树皮鲜质量。树冠分为3层,每层选取鲜树叶样品共0.5~1.0 kg,准确称量并记录鲜树叶样品质量,树枝取样方法与树叶相同。采用“全挖法”采集树根,分别称量并记录根(粗根和细根)和根兜的总鲜质量;选取广西8株样木,对其根系生物量进行分级测定,大而明显的初生根为根兜,从主根上发生的根称为Ⅰ级侧根,由Ⅰ级侧根上发生的根为Ⅱ级侧根,由Ⅱ级侧根上发生的根为Ⅲ级侧根,按根兜、Ⅰ级侧根、Ⅱ级侧根、Ⅲ级侧根分别称量并记录其总鲜质量;然后分别取代表性的样品0.5~1.0 kg,准确称量并分别记录样品质量。将树叶、树枝、圆盘、根兜和不同侧根的鲜样品分别装入密封袋中,做好标记,带回实验室烘干后称其干质量。
1.4 生物量和碳储量测定
将野外采集的各样品在烘箱中105 ℃烘至恒质量,称其干质量,求得各器官的干鲜质量比,然后将各器官鲜质量换算成干质量,即可得到单木各器官的生物量,单木的全株生物量为各器官生物量之和。在福建、四川和广西3地共选取40株样木测定碳含量(福建28年生杉木成熟林样本中每个径阶选取1株,共10株;四川杉木成熟林样木20株;广西37年生杉木成熟林样木10株),分别测定其带皮干、树枝、树叶和树根的碳含量。分析方法:将烘干的各器官样品研磨,过0.25 mm目筛。所有样品均采用重铬酸钾外加热法测定碳含量(鲍士旦等,2000)。各分项碳储量等于其生物量与碳含量的乘积,汇总得到全株碳储量。
1.5 模型选择和参数估计
在拟合相关方程时,有多项式函数、幂函数和指数函数3种方法,李燕等(2010)研究表明幂函数曲线模拟效果最佳。本研究以不同产区杉木生物量、碳储量实测数据为因变量,以D、DH和D2H(D为立木胸径,H为立木树高)为自变量,采用幂函数形式拟合杉木各器官独立模型(表3)。
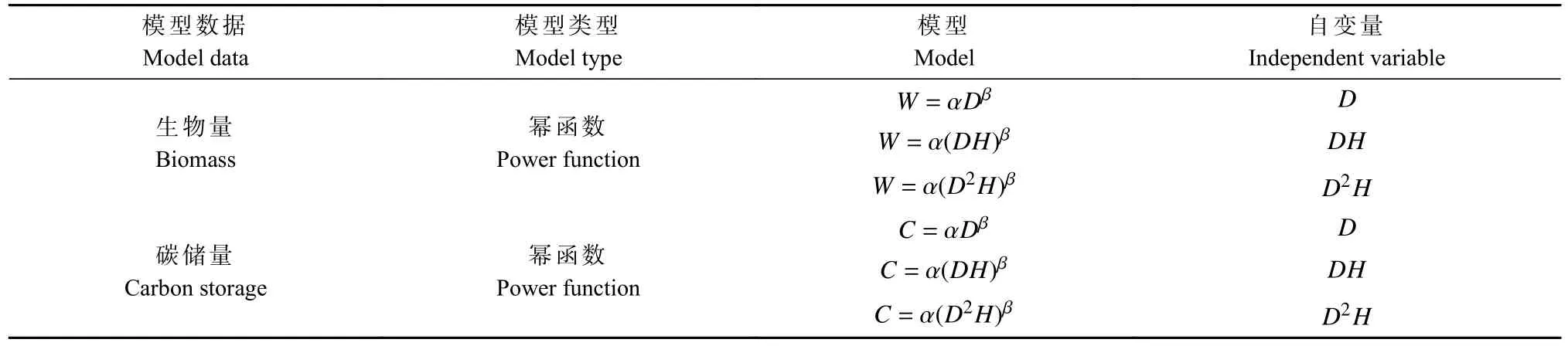
表3 生物量和碳储量独立模型形式①Tab. 3 Independent model form of biomass and carbon storage
本研究以异速生长方程为基础,采取SUR保证可加性,构建不同产区杉木人工林生物量和碳储量的可加性模型系统。基于SUR的生物量模型表达式如下(式1):
式中:Ws、Wb、Wl、Wr、Wp和Wt分别为树干、树枝、树叶、树根、树皮和全株生物量;X为自变量D、DH、D2H;αs、αb、αl、αr、αp、βs、βb、βl、βr和βp为模型参数;εs、εb、εl、εr、εp和εt为各项随机误差。
碳储量模型表达式如下(式2):
式中:Cs、Cb、Cl、Cr、Cp和Ct分别为树干、树枝、树叶、树根、树皮和全株碳储量。
按径阶分布随机分离2/3的数据来拟合模型,然后使用剩余的1/3用来测试模型的预测能力。本研究用 SAS 9.4中的PROC MODEL模块以及SUR对杉木单木各器官和全株生物量、碳储量模型参数进行联合估计。通过使用总相对误差(total relative error,简称TRE)和调整后确定系数(adjustedR-square,简称R2a)来评估模型性能,见公式3和4。TRE越接近0说明拟合效果越好,本研究以-25%<TRE<25%作为模型符合实际的标准。
式中:yi为 实际观测值;为模型预估值;为样本平均值;k为自变量的个数;n为样本单元数。
2 结果与分析
2.1 杉木可加性生物量模型拟合与评价
由表4、5、6可知,本研究所构建的生物量模型R2a为0.552 0~0.995 8,TRE为-17.88%~21.39%,t检验达到极显著水平(P<0. 01),表示模型可用于估算生物量。4个产区成熟林总体模型的R2a为0.739 4~0.966 9,TRE为-5.43%~21.39%。广西除I级侧根(0.552 0)外,各器官模型的R2a均在0.8以上,TRE为-5.42%~7.21%(表6)。本研究所构建的生物量模型均表现为带皮干、去皮干、树皮和全株模型的R2a较高,TRE的绝对值较小;枝、叶和根生物量模型的R2a较小,TRE的绝对值较大。
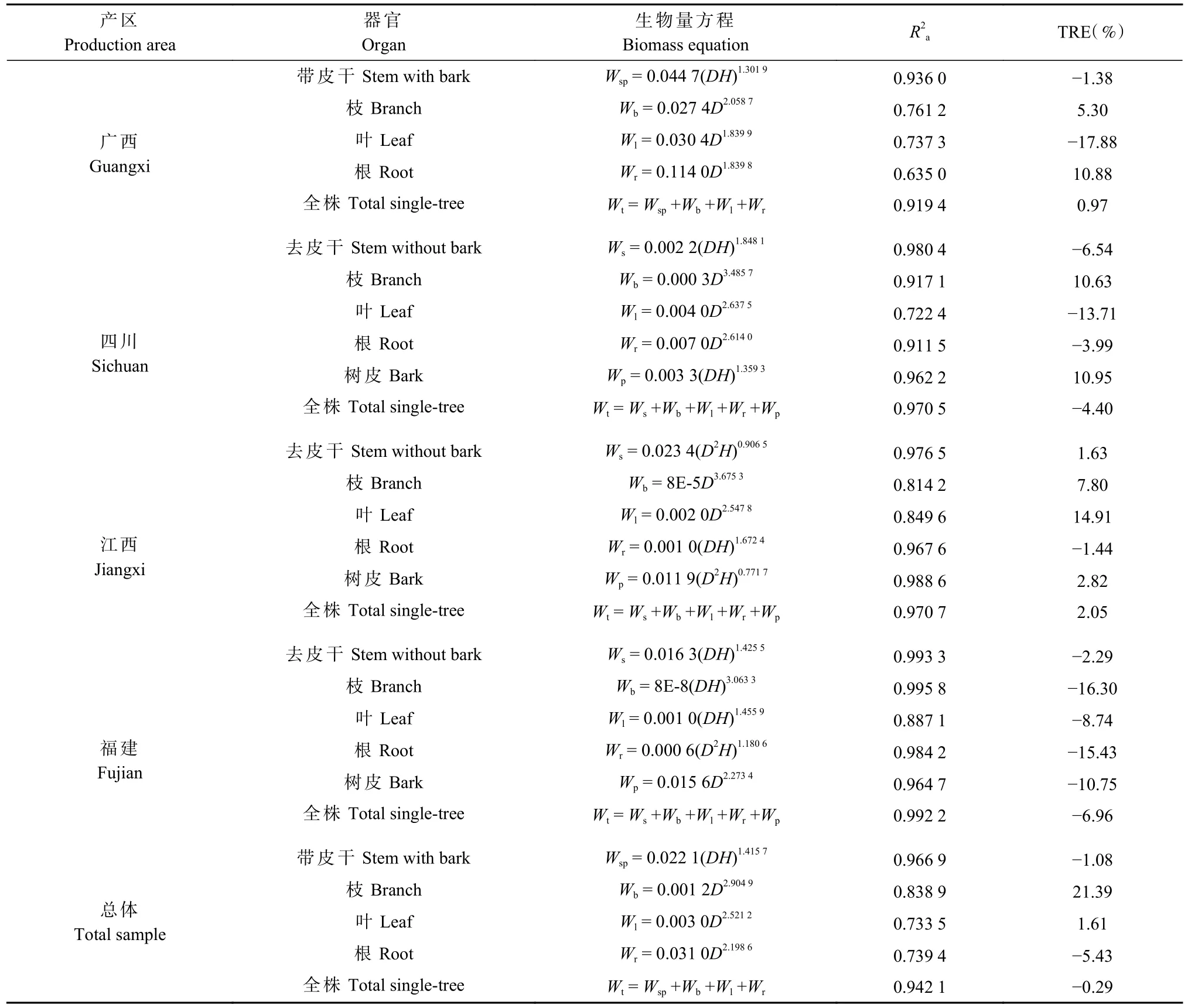
表4 各产区和总体杉木人工林生物量模型及模型评价指标①Tab. 4 Biomass model and model evaluation index of Chinese fir plantations in each production area and total sample

表5 福建不同林龄杉木人工林生物量模型及模型评价指标Tab. 5 Biomass model and model evaluation index of Chinese fir plantations of different forest ages in Fujian

表6 广西包括不同级别侧根的杉木人工林生物量模型及模型评价指标Tab. 6 Biomass modeling and model evaluation indexes including lateral roots of different grades of Chinese fir plantation forests in Guangxi
2.2 碳储量可加性模型拟合与评价
由表7可知,所构建的碳储量模型R2a为0.805 0~0.994 0,TRE为-19.34%~19.84%,t检验达到极显著水平(P<0. 01),表示模型可以准确估算杉木的碳储量。各产区碳储量模型可以准确预测本产区杉木碳储量,通用碳储量模型可用于估算不同产区杉木碳储量;带皮干和全株碳储量模型拟合皮干和全株碳储量模型拟合精度更好,R2a为0.970 4~0.989 8,TRE为-6.12%~8.96%,而枝、叶和根碳储量模型的拟合精度较差,TRE的绝对值较大。

表7 杉木人工林碳储量模型及模型评价指标①Tab. 7 Carbon stock modeling of Chinese fir plantation forests and model evaluation indexes
2.3 模型通用性检验
2.3.1 生物量模型通用性检验 以TRE为模型检验指标,在R studio中用已构建的生物量模型进行交互检验,检验样本为各模型建模时的检验样本,结果见表8。用广西带皮干和全株生物量模型对除四川外的其他检验样本预测时TRE为-24.56%~0.97%。用江西和福建的去皮干和全株生物量模型对其他检验样本预测时TRE为-14.23%~21.79%;江西和福建的成熟林生物量模型可以相互预测(除枝外)。四川的生物量模型通用性最差,仅适用于本产区。用综合模型对所有检验样本的带皮干和全株生物量预测时TRE为-10.47%~19.88%;还可对江西和福建中、成熟龄林除枝外的生物量进行准确预测。由表9可知,福建7年生杉木全株生物量模型低估了其他林龄的生物量,通用性差;福建16、28年生杉木去皮干生物量模型可对福建不同林龄的杉木生物量进行预测,TRE为-2.30%~15.88%。

表8 生物量模型通用性检验结果(TRE)①Tab. 8 Results of biomass model generalizability test (TRE) %

表9 福建不同林龄杉木人工林生物量模型通用性检验结果(TRE)Tab. 9 Results of the generalization test of biomass model for fir plantation forests of different stand ages in Fujian, China (TRE)%
2.3.2 碳储量模型通用性检验 用已构建的碳储量模型进行交互检验,结果见表10。四川枝和根碳储量模型可用于其他检验样本碳储量预测,TRE为-19.84%~22.95%。广西带皮干、枝、根和全株碳储量模型的通用性较好,TRE在-25%~25%范围内。福建全株碳储量模型通用性较好,TRE为4.68%~22.36%。通用碳储量模型除对广西杉枝碳储量的预测误差较大,用于其他检验样本时TRE为-9.57%~15.70%,说明模型的通用性好,可以用于不同产区杉木人工林的碳储量预测。

表10 碳储量模型通用性检验结果(TRE)Tab. 10 Results of carbon storage model generalizability test (TRE) %
3 讨论
3.1 建立可加性模型的必要性
异速生长关系经常被用于生物量和碳储量模型的拟合中,因其变量易于测量,在对生物量、碳储量的预估中可大大节省工作量和成本,且预测精度较高(Sierraet al., 2007;Biet al., 2015)。建立立木生物量、碳储量模型时,要充分考虑立木整体与各个组分之间的数学关系和内在相关性(Zhaoet al., 2015),即要求各组分之间要具有相加性。过去有许多文献报道的生物量方程都不具有相加性,而是针对每个组分建立的独立方程,有学者比较了可加性碳储量模型与不可加性碳储量模型的拟合精度,发现用不可加性方法构建模型会导致各组分碳储量预测值之和与全株碳储量有较大偏差(Linet al., 2016),如果将这些模型应用于实际,可能会出现错误。可加性模型的拟合精度相对较好,基于SUR的可加性模型系统在总体上可以提供相对准确的预测,因此建立可加性生物量和碳储量模型是最优的选择。
3.2 生物量、碳储量模型拟合精度影响因素
本研究比较了基于不同变量的独立模型拟合精度,以找到最优的模型形式进行可加性模型的拟合,树干(去皮干、带皮干)的自变量大都是DH或D2H,枝和叶最优模型的自变量大多是D,与Xiang等(2021)的研究结果一致。带皮干碳储量模型的自变量均为DH,枝碳储量模型的自变量均为D,根碳储量模型的自变量均为DH和D2H,与Lin等(2016)的研究结果不同,可能是自变量以及样本选取的差异导致的。在生物量模型系统中,枝、叶和根的生物量模型拟合精度较树干、树皮和全株低,这与前人的研究结果一致(王冬至等,2018;董利虎等,2018;Xianget al.,2021);在碳储量模型系统中,枝和叶碳储量模型的拟合精度相对较低,与前人的研究结果一致(Linet al., 2016)。分析其原因,可能是因为枝、叶和根在生长过程中受环境因素和竞争的影响较大,不确定性高,故拟合精度相对较低。
为了精确预测立木的碳储量,建立碳储量模型是较好的方法,许多研究者估算立木碳储量时采用目前国际上常用的含碳量0.50计算立木碳储量(Johnsonet al., 1983;Ngoet al., 2013;魏亚伟等,2014)。董利虎等(2020)比较了5个立木碳储量预测方法的预测精度,结果表明,立木含碳量模型法预测精度最好,而利用通用含碳量0.45和0.50估算立木碳储量会产生较大误差。曾伟生等(2018)也得出类似的研究结果,使用固定含碳系数法估算杉木林碳储量低于实际值0.6%~5.4%,误差较大。本研究中,广西各组分平均含碳量为53.22%~55.42%,福建各组分含碳量为50.42%~53.44%,四川各组分含碳量为52.82%~54.51%,使用通用含碳量0.50对不同产区杉木碳储量进行计算,3个产区各组分和全株碳储量均较实际值低1.8%~10.0%。这些误差源于不同树种、器官碳含量的差异(梅莉等,2009),以固定含碳系数法计算森林碳储量会掩盖这种差异,存在很大的估计误差。Widagdo等(2020)对东北地区兴安落叶松(Larix gmelinii)的研究结果表明,含碳量在不同组分、乔木大小和起源之间存在显著差异。这表明使用特定地区和特定组分的含碳量来估算森林碳库比通用含碳量(0.5)更合适,因此,有必要分别树种及器官测量其生物量及含碳量,以便更精确地估计林分的碳储量。
3.3 模型通用性及其影响因素
本研究杉木幼龄林生物量模型显著低估了杉木中龄林和成熟林的生物量,福建16、28年生杉木仅去皮干生物量模型可用于预测其他林龄的去皮干生物量,说明分林龄生物量模型通用性较差,与李燕等(2010)的研究结果一致。江西省和福建省属于中亚热带东区,广西省属于南亚热带,四川省属于中亚热带西区,广西、江西和福建成熟林树干和全株生物量模型通用性较好;江西和福建成熟林生物量模型可相互预测各组分及单株生物量;四川生物量模型的通用性较差。造成以上结果的原因是,杉木人工林在我国的分布区域极为广阔,我国幅员辽阔,各地环境、气候条件各不相同,因而不同地区杉木林生物量和碳储量也会有所不同(王姣娇等,2018)。碳储量模型通用性检验结果与生物量有所不同,可能是因为不同产区各器官含碳率差异较大。
到目前为止,适用于不同产区的杉木人工林生物量、碳储量通用模型的报道还比较少。曾伟生(2013)建立了适合杉木不同生长区域可加性地上生物量模型及根茎比函数,其总体涉及区域很广,平均到某一地区样本数量较少,本研究4个产区共109株样木,样本数量较大;其次,曾伟生(2013)的研究结果不包含地下部分生物量模型的拟合,本研究详细测定了树干、枝、叶、树皮和根的生物量,研究结果的指导性更强。本研究建立的生物量和碳储量综合模型的通用性较好,可以对不同产区的杉木人工林立木生物量、碳储量进行准确预测,为估算不同产区杉木人工林生物量、碳储量提供了一种可行的方法。在预测林分乔木层生物量和碳储量时,对大径阶立木的估计尤为关键,因为大径阶立木在林分乔木层中所占的比例较大(王佳慧等,2018)。本研究中,杉木生物量建模样本最大胸径为 36.8 cm,碳储量建模样本最大为27.8 cm。若用本研究中模型去预测更大径阶杉木立木生物量或碳储量时,可能产生较大的预测误差。研究结果对准确测算区域杉木人工成熟林生物量与碳储量具有重要意义,对森林经营管理具有参考价值。
4 结论
1)4个产区和不同林龄杉木生物量模型的R2a为0.635 0~0.995 8,TRE为-17.88%~21.39%,树干、树皮和全株生物量模型的R2a均在0.91以上,适用于建模地的杉木人工林生物量预测。广西分侧根拟合的生物量模型除一级侧根外,R2a均在0.80以上,TRE为-5.42%~7.21%,可用于预测广西杉木人工林侧根生物量。枝、叶、各根的生物量模型拟合精度较干、树皮低。
2)四川、广西和福建3个产区碳储量模型R2a为0.805 0~0.994 0,TRE为-19.34%~19.84%,树干、根和全株模型R2a在0.93以上,适用于本地区杉木人工林碳储量预测。枝、叶的碳储量模型拟合精度较干和根低。
3)不同产区生物量、碳储量模型通用性存在地域差异。位于中亚热带西区的四川生物量模型通用性最差,位于南亚热带的广西带皮干和全株生物量模型通用性较好,位于中亚热带东区的福建和江西生物量模型可相互预测杉木各器官和单株生物量;南亚热带广西的碳储量模型通用性最好,而四川和福建的碳储量模型仅适用于本地碳储量预测。
4)综合生物量模型R2a为0.733 5~0.966 9,根据交互检验结果,综合模型可对不同产区成熟林和福建幼龄林、中龄林的带皮干和全株生物量进行准确预测,TRE为-10.47%~19.88%;还可对江西和福建成熟林及福建中龄林除枝外各器官和全株生物量进行准确预测。综合碳储量模型R2a为0.802 9~0.982 6,除对广西杉木人工林枝碳储量的预测误差相对较大,其他检验样本TRE为-9.57%~15.70%,说明模型的通用性好,可对不同产区的杉木人工林各器官和全株碳储量进行准确预测。
猜你喜欢
疯狂英语·初中版(2023年5期)2023-06-01
故事作文·高年级(2023年3期)2023-05-30
卫星应用(2022年3期)2022-05-23
收藏界(2019年2期)2019-10-12
收藏界(2019年3期)2019-10-10
收藏界(2018年1期)2018-10-10
森林工程(2018年3期)2018-06-26
铁道学报(2018年5期)2018-06-21
中国铸造装备与技术(2017年3期)2017-06-21
