
Improved multi-scale inverse bottleneck residual network based on triplet parallel attention for apple leaf disease identification
2024-03-12 13:31LeiTangJizhengYiXiaoyaoLi
Lei Tang ,Jizheng Yi, ,Xiaoyao Li
1 College of Computer &Information Engineering, Central South University of Forestry and Technology, Changsha 410004, China
2 Yuelushan Laboratory Carbon Sinks Forests Variety Innovation Center, Changsha 410000, China
Abstract Accurate diagnosis of apple leaf diseases is crucial for improving the quality of apple production and promoting the development of the apple industry. However,apple leaf diseases do not differ significantly from image texture and structural information. The difficulties in disease feature extraction in complex backgrounds slow the related research progress. To address the problems,this paper proposes an improved multi-scale inverse bottleneck residual network model based on a triplet parallel attention mechanism,which is built upon ResNet-50,while improving and combining the inception module and ResNext inverse bottleneck blocks,to recognize seven types of apple leaf (including six diseases of alternaria leaf spot,brown spot,grey spot,mosaic,rust,scab,and one healthy). First,the 3×3 convolutions in some of the residual modules are replaced by multi-scale residual convolutions,the convolution kernels of different sizes contained in each branch of the multi-scale convolution are applied to extract feature maps of different sizes,and the outputs of these branches are multi-scale fused by summing to enrich the output features of the images. Second,the global layer-wise dynamic coordinated inverse bottleneck structure is used to reduce the network feature loss. The inverse bottleneck structure makes the image information less lossy when transforming from different dimensional feature spaces. The fusion of multi-scale and layer-wise dynamic coordinated inverse bottlenecks makes the model effectively balances computational efficiency and feature representation capability,and more robust with a combination of horizontal and vertical features in the fine identification of apple leaf diseases. Finally,after each improved module,a triplet parallel attention module is integrated with cross-dimensional interactions among channels through rotations and residual transformations,which improves the parallel search efficiency of important features and the recognition rate of the network with relatively small computational costs while the dimensional dependencies are improved. To verify the validity of the model in this paper,we uniformly enhance apple leaf disease images screened from the public data sets of Plant Village,Baidu Flying Paddle,and the Internet. The final processed image count is 14,000. The ablation study,pre-processing comparison,and method comparison are conducted on the processed datasets. The experimental results demonstrate that the proposed method reaches 98.73% accuracy on the adopted datasets,which is 1.82% higher than the classical ResNet-50 model,and 0.29% better than the apple leaf disease datasets before preprocessing. It also achieves competitive results in apple leaf disease identification compared to some state-ofthe-art methods.
Keywords: multi-scale module inverse bottleneck structure,triplet parallel attention,apple leaf disease
1.Introduction
The apple has the title of “King of Fruits” in today’s world and is of great value to the agricultural,commercial,and scientific communities,while the frequent occurrence of apple leaf diseases is a major factor behind the instability of apple production. Alternaria leaf spot,brown spot,grey spot,mosaic,rust,and scab are the six most common apple leaf diseases that cause very serious damage to the growth of apples,making the economic market for apples fluctuate and fail to maximize benefits. Therefore,the intelligent and accurate detection of apple leaf diseases is of paramount importance in improving the yield and quality of apples,and it is also a research boom in agricultural information technology.
In the early days,the identification of apple leaf diseases required subjective diagnosis by plant experts(Gigotet al.2017),which is time-consuming and inefficient. Moreover,the disease is hardly distinguished by human eyes,so early diagnosis could not meet the realistic market demand. With the development of machine learning,a series of traditional machine learningbased models for leaf disease identification have emerged gradually,such as the hybrid method of PCA (principal component analysis) and SVM (support vector machine)(El-Bendaryet al.2015),which uses OAO-SVM (one-toone support vector machine) algorithm combined with specific linear kernel functions for feature extraction and classification of plant leaf diseases. K-means clustering algorithm (Sujathaet al.2018) uses clustering scheme for the feature extraction of region of interest and adopts SVM for the classification of leaf disease. The 2DSLDR (twodimensional subspace learning dimensionality reduction)algorithm for apple disease identification (Zhong and Zhao 2020) maps the observed sample points from highdimensional space to low-dimensional subspace,which solves the difficulties related to feature extraction and selection in classical plant disease identification methods.There are also genetic algorithms and correlated feature selection algorithms (Zhanget al.2017),reducing the dimension of the feature space by selecting the most valuable features of the genetic algorithm to improve the accuracy of leaf disease identification. Compared with the early methods,the traditional machine learning methods have the advantages of higher efficiency and intelligence.However,they are easily disturbed by factors such as uneven data distribution and noise,and the recognition rate of traditional machine learning fluctuates in complex and multi-interference environment.
In recent years,deep learning has emerged as an important branch of machine learning. Compared to traditional machine learning,deep learning has a deeper network structure that can extract more abundant learning information and automatically feature extraction. For example,deeply supervised subspace learning approach which use for cross-modal material perception of known and unknown objects (Xionget al.2023),a framework which use deep learning for multiple objects tracking by detection (Ahmedet al.2021),and a hybrid ensemble deep learning approach which effectively combine handcrafted features with domain knowledge and latent features (Xuet al.2023). There are also a deep learningbased model predictive control shows good performance in modeling,tracking,and antidisturbance (Wang G Met al.2021),and a context-aware deep network named PCUNet (point cloud completion network) which allows full consideration of contextual information (Zhaoet al.2022). Therefore,its recognition accuracy is significantly improved upon traditional machine learning. Since the emergence of mainstream architectures of apple leaf disease recognition,e.g.,AlexNet (Krizhevskyet al.2017),GoogLeNet (Szegedyet al.2015),and ResNet(Heet al.2016),deep learning has been a breakthrough in the field of apple leaf disease recognition. AlexNet(Krizhevskyet al.2017) utilizes a network structure with large convolutional layers plus fully connected layers for coarse-grained feature extraction of diseases.GoogLeNet (Szegedyet al.2015) improves recognition results by applying a combined string-parallel network structure to enhance the fine-grained features of leaf diseases extracted by the network of the same order of magnitude of dataset input. ResNet (Heet al.2016)builds some ultra-depth network layers and residual structure for leaf depth feature extraction. Gradually,people realize the limitations of deep learning model in terms of model complexity and parameter size,so there are new optimization and improvement methods for some mainstream model frameworks. For example,a basic classification model of apple leaf disease (Liu Bet al.2018) is proposed by removing part of the full connection layer within CNN (convolutional neural networks). As for the method of combining hierarchical gradient direction histogram with VGG network (visual geometry group network) (Nasiret al.2021),the best feature is selected in the form of correlation between leaf disease classification,and the accuracy is significantly improved. In addition,Yuet al.(2020) propose a ROI (region of interest) based DCNN (diffusion-convolution neural network) for apple disease classification,which first designs a ROI subnetwork for leaf separation and then uses a VGG network to classify apple leaf diseases.
With the development and application of intelligent devices,deep learning models for apple leaf disease recognition are evolving towards low complexity,high efficiency,convenience and many other aspects. For example,MobileNet (Howardet al.2019) uses the stacking of deeply separable modules to improve the computing efficiency of the convolution layer to make the disease identification more efficient. ShuffleNet (Maet al.2018) uses pointwise group evolution and channel shuffle improvement based on each residual unit to reduce the network computing overhead while retaining the original accuracy of the model. Chaoet al.(2020) combines the densely connected blocks of DenseNet with Xception networks for five classifications of apple leaf diseases with low model complexity and higher network recognition rates in complex contexts. DMS-Robust AlexNet model(Lvet al.2020) combines dilated convolution and multiscale convolution to improve the recognition accuracy of the original AlexNet.
Refining feature extraction,reducing information redundancy,and preventing information overload are key to accurate and efficient plant disease identification.On the one hand,refining feature extraction and reducing information redundancy requires refining the dimensionality of input features while retaining key information to improve the speed and efficiency of the model. Methods such as squeeze-and-excitation networks (Huet al.2018),which adaptively recalibrate channel-wise feature responses by explicitly modeling interdependencies between channels,can improve model accuracy by attending to informative features and suppressing irrelevant ones. Another approach is to focus on fine-grained feature learning (Tranget al.2019),using transfer learning and residual networks to extract features from plant disease images and feature selection algorithms to choose the most informative features.There is also a model that proposes a lightweight framework which improves the residual structure and utilizes Depthwise Separable Convolutions to enhance the efficiency of convolution operations (Guet al.2022),and a model which adds residual connections between the feature extractor and the transform network (Caiet al.2020). As for the method that uses the mobile inverted bottleneck,the input resolution,depth,and width of the model are all quantified (Feng and Ren 2021). On the other hand,the emergence of attention mechanism provides a new solution for reducing information overload. Its principle is that visual processing systems tend to focus on important information in images and ignore irrelevant information. For example,the attention mechanism in deep residual networks (Karthiket al.2020) processes plant disease features learned in hierarchical structures to improve model accuracy.DVAN (diverse visual attention network) (Zhaoet al.2017) identifies local information about regions more accurately than the no-attention model in classifying finegrained targets for leaf diseases. There is also a finegrained classification model based on transfer learning to quickly build an attention mechanism (Yanget al.2020). The unsupervised training mode obtains the corresponding computational attention spectrum as the follow-up network input. This model effectively improves the recognition rate of fine-grained classification of crop images. The methods mentioned above can improve the accuracy of network application in classification and recognition from a specific perspective,but they also show some limitations,such as the failure to control the relationship between network depth and model generalization ability,the tendency to learn irrelevant features of leaf disease,and the loss of the combination of spatial and channel information,etc.
Inspired by the above-related research and aimed at the shortcomings of the above research,we improve the ResNet-50 as the initial network and propose a layerwise dynamic coordinated multi-scale inverse bottleneck residual network based on triplet parallel attention(TAMSIB-NET) to identify apple leaf diseases. Our proposed model aims to capture fine-grained features and reduce information redundancy in a more efficient manner,leading to improved performance in plant disease identification. The original 3×3 convolutions in some bottlenecks are replaced by inverse bottleneck multi-scale residual convolution. At the same time,after each bottleneck,triplet parallel attention modules are integrated,and the number of model module stacks is slightly adjusted. The improved model is applied to the diagnosis and identification of apple leaf disease under a mixture of simple and complex backgrounds. The corresponding algorithm framework is shown in Fig.1.
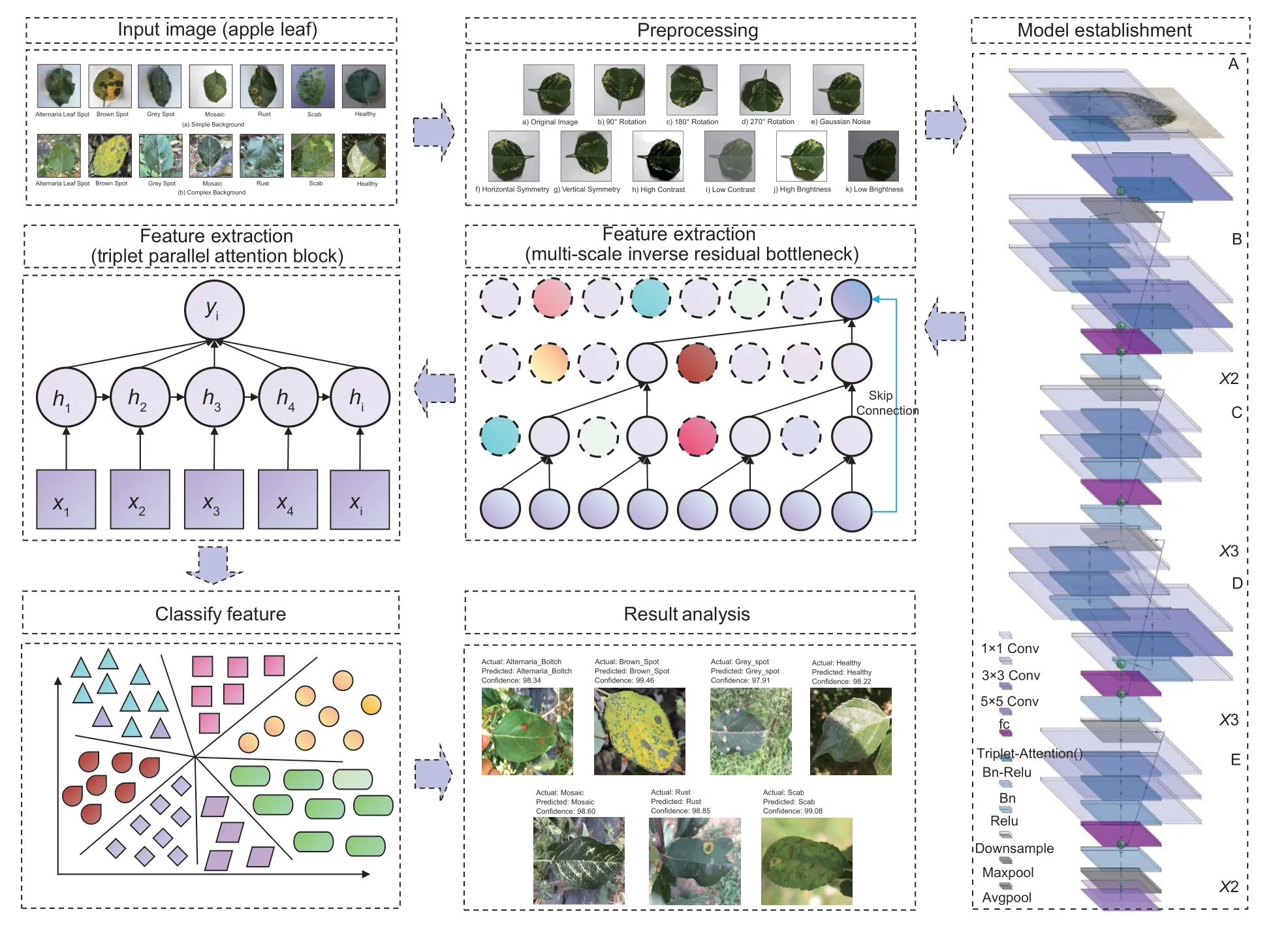
Fig. 1 The framework of the proposed algorithm.
The image is preprocessed and then converted into a three-dimensional tensor form,which is input into the TAMSIB-NET for apple leaf disease classification.
Our main contributions are summarized as follows.
1) An improved multi-scale residual module is proposed to replace the original residual module. The multi-scale convolutions of 3×3 and 5×5 are used to replace the first 7×7 convolution in the original ResNet for feature extraction. Its purpose is to consider the details and background features in image pixels by using multidimensional perception convolutions of different sizes to effectively recognize the characteristics of different features when initially extracting image features. The 3×3 convolution in the specified residual module is also replaced by the multi-scale 3×3 and 5×5 inverse bottleneck convolutions to achieve the comprehensive extraction of high and low dimensional diversity features. By using different multidimensional perception convolution kernels to extract features of different sizes and then fusing them,the network synchronous extraction using single-dimensional and multidimensional convolution modules not only avoids the loss of information caused by compressed dimensions,but also makes the feature extraction more comprehensive and detailed in the complex background,which is conducive to improving the accuracy of network classification.
2) The global layer-wise dynamic coordinated inverse bottleneck structure is designed to extract channel features instead of the original bottleneck structure. We increase the number of convolution channels used for main feature extraction,which makes the extracted information more concentrated and avoids the information redundancy caused by feature extraction. This structure effectively avoids the information loss caused by applying too many ReLu activation functions and reduces the information loss caused by compressing dimensions.The progressive adjustment of the scaling ratio and size of inverse bottleneck channels at different levels of the network effectively balances computational efficiency and feature representation capability,enabling the network to flexibly adapt to different feature selection sizes at various scales,which signifies that our multi-scale inverse bottleneck module flexibly expands and scales elastically with the increasing network depth to capture crucial features at higher levels.
3) A triplet parallel attention is improved with a more suitable convolutional kernel size,activation function,and Z-pool pooling layer,and integrated into the improved ResBlocks. Two of three branches establish the interaction between any two dimensions through rotation,and the other one extracts the spatial attention weight.The three-branch structure captures image information across dimensions and constructs the dependency between dimensions through rotation operation and residual transformation. The convolution cores of different branches share the output channel through aggregation,which greatly improves the parallelism compared with other attention mechanisms and shortens the convergence time of the model.
The model presented in this paper built upon ResNet-50,while improving and combining the Inception module and ResNext inverse bottleneck blocks. It also adopts a multi-scale elastic feature fusion module to enhance the diversity of feature extraction,and layerwise dynamic coordinated inverse bottleneck structure to process information more centrally,combined with triplet parallel attention which focuses on effective information and reduces unnecessary information transmission.The proposed extracts and utilizes information more efficiently,thereby reducing the risk of information overload while improving the efficiency for apple leaf disease identification.
The rest of this paper is arranged as follows. Section 2 introduces the experimental data and the proposed method. Section 3 presents the experimental results and analysis. Section 4 summarizes this paper and discusses the future research plans.
2.Materials and methods
2.1.Datasets and data preprocessing
There are seven types of apple leaf disease image datasets used for identification in this paper. As shown in Fig.2,the datasets come from pathological images of Baidu Flying Paddle apple leaves (https://aistudio.baidu.com/aistudio/datasetdetail/11591/0),New Plant Village(https://www.kaggle.com/datasets/vipoooool/new-plantdiseases-dataset) and a small number of images selected from the Internet,respectively. Among them,alternaria leaf spot,brown spot,grey spot,mosaic,and rust are from the pathological images of Baidu Flying Paddle apple leaves,and scab and healthy leaves are from the new plant village. The image types and corresponding quantity distribution are shown in Table 1.

Table 1 Image types and corresponding quantity distribution
The original datasets have problems such as uneven distribution of the number of samples,small infection focus of a single type of image,and complex background occlusion mixture,which increases the corresponding classification difficulty. Therefore,preprocessing of the datasets is necessary (Yanget al.2022a). After filtering and elimination,the datasets is adjusted to ensure the model extracts features from different categories evenly.
The processed datasets contain 14,000 images in total.The datasets are randomly divided into 80% for training,and the other 20% for testing,and the verification set is selected from 20% of the unused testing set. To avoid the impact of different resolutions in the original images on the classification results,this paper adjusts all image resolution to 224×224. At the same time,to enhance the generalization ability of the networks,reduce the impact of noise,and avoid overfitting caused by insufficient image training networks,we performed five image augmentation methods on the original images,including rotation (90 degrees,180 degrees,and 270 degrees),Gaussian blur,flip (horizontal and vertical),contrast enhancement and reduction,and brightness enhancement and reduction (Liuet al.2022). The final model robustness test data set is obtained as shown in Fig.3. Please see subsection 3.6 for the comparison of network accuracy before and after image preprocessing.

Fig. 2 Samples of six diseases and one healthy apple under simple and complex background.
To eliminate the adverse effects caused by the potential singular samples,speed up the network gradient descent to find the optimal solution and improve the network accuracy (Zhanget al.2022),this work has conducted data transformation on the overall data set,normalized the image channel by channel,as shown in formula (1).
wherexiis the eigenvalue of theiimage sample,is the mean value of the channel,δxiis the channel standard deviation. After normalizing the data onto [0,1] through linear transformation,formula (1) is adopted to map each element to [–1,1].
2.2.Apple leaf disease identification model
The proposal of ResNet (Heet al.2016) made the network as deep as possible,and solved the problem of network degradation in the history of CNN images. The main network structure of ResNet refers to the residual mechanism,and residual units are constructed through a shortcut connection. Compared with ordinary networks,the shortcut connection mechanism is added between every two layers of ResNet,which well balances the relationship between the three dimensions of depth,width,and resolution. The principle of a multi-scale convolution layer is to use convolution layers of different sizes to convolution operation the same feature map to obtain a new feature map (Yanget al.2022 b).
Inspired by the Inception network and the extensive application of multi-scale convolution network (Tan and Le 2019),the use of multiple convolution kernels together does not change the size of the original input feature map but performs independent operations through different convolution kernel operations. This enriches the characteristics of the image and uses the image information from the overall perspective to improve the image segmentation and extraction performance.
Concerning the MLP structure of the Transformer(Vaswaniet al.2017),the inverse bottleneck operation is to increase dimensions first and then reduce dimensions,to avoid information loss caused by compressed dimensions when information is converted between feature spaces of different dimensions. The attention mechanism has many applications in natural language processing,statistical learning,voice and computer. By introducing the attention mechanism (Huanget al.2019),when selecting information,we can extract task-related information,calculate its weighted average,and then input it into the neural network for calculation,so that we can focus on the information more critical to the current task,solve the problem of information overload and improve the efficiency and accuracy of the network.

Fig. 3 Examples of dataset augmentation.
Referring to the above research results,based on ResNet-50,this study proposes an improved multi-scale inverse bottleneck residual network based on triplet parallel attention for apple leaf disease identification.The introduction of the model is mainly divided into the following four parts: the introduction of the overall model,the multi-scale residual module for more comprehensive feature extraction,the inverse bottleneck structure for avoiding information loss caused by compressed dimensions,and the triplet attention mechanism for capturing image information across dimensions.
Model structureConsidering that there are similarities between different species of apple leaf diseases,the classification of diseases that tend to be fine classification requires more detailed and deep-level identification. This paper takes ResNet-50 as the basic network architecture for transformation,aiming to balance the three dimensions of depth,width,and resolution.
The overall structure of the model is shown in Fig.4.The 7×7 convolutions in the original Stage 1 of ResNet-50 is replaced with 3×3 and 5×5 multi-scale parallel multidimensional perception convolutions,as shown in Fig.4-A,to effectively capture the details of image pixels and background features when initially extracting image features by using the feature that different size convolutions can extract features of different sizes. The Max Pooling layer is added after the initial image features are extracted in Stage 1 to select the features with better classification recognition in the shallow network and retain the initial texture information. Stages 2 and 4 also apply the 3×3 and 5×5 convolutions in parallel to the multiscale inverse bottleneck residual convolution block,as shown in Fig.4-B and D. Stages 3 and 5 keep the original 3×3 residual convolutions of ResNet-50 to cooperate the inverse bottleneck block,as shown in Fig.4-C and E.
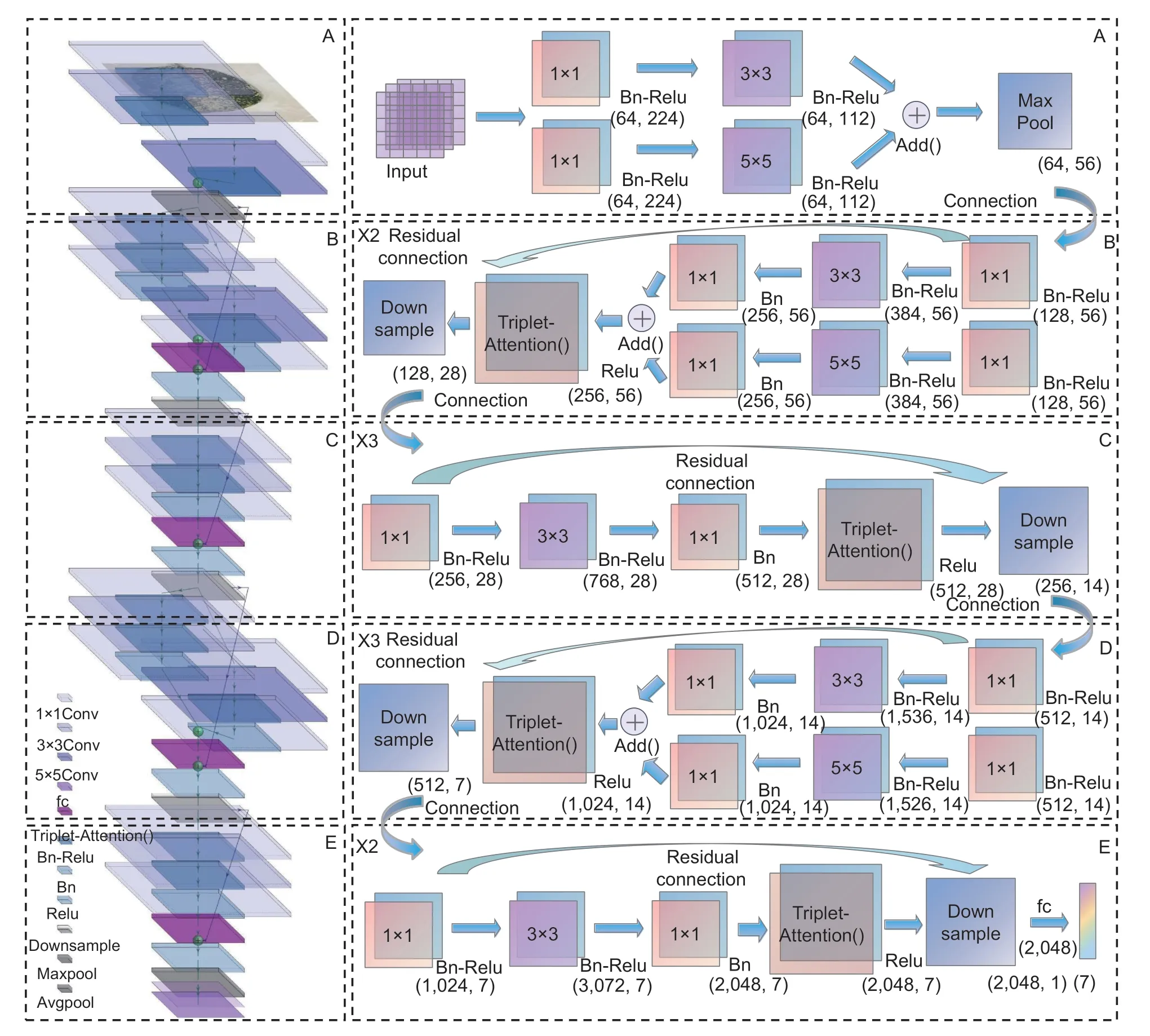
Fig. 4 Improved multi-scale inverse bottleneck residual network structure based on triplet parallel attention.
Considering the comprehensiveness of feature extraction and the moderate depth of the network,we set the stacking number of network modules as the 2–3–3–2 structure of the corresponding cycle,that is,two multi-scale inverse bottleneck modules stacked with three inverse bottleneck modules followed by three multi-scale inverse bottleneck modules stacked with two inverse bottleneck modules. The purpose is to realize the complementarity of feature extraction of lower layer network and higher layer network,where the features of lower layer network are used to refine the extraction results of higher layer network features. Meanwhile,the differences in the fine-grained features of higher layer network affect the features of lower layer network.
After the superposition of each multidimensional perception convolution layer,the BN (batch normalization)operation and ReLu activation function are added,as shown in formulas (2) and (3),to make the distribution of characteristics of each layer of the network as stable as possible,prevent gradient explosion,and make the network converge faster.
whereαis the input data,is the mean of the data,is the standard deviation of the data,γandβare learnable control variables for scaling (ʘ) and panning the normalized data,and the batch normalization operation reducing covariant shifts within the data.
where the parametertis the input vector from the network of the upper layer,andwTt+bis the nonlinear output result of the ReLu function after the linear transformation of this layer. Selecting the ReLu function can maintain the sparsity of feature selection,save useful feature information,and reduce the overfitting of the network.
Algorithm 1 uses pseudo code to explain the batch normalization operation. Considering the network weight,error,and other related factors,the network also adopts the cross-entropy loss function to facilitate faster gradient updates,as shown in formula (4).

where input[xi] is the true vector value of theioutput sample of the network,and target[xi] is the target predictive value of the corresponding model. The cross-entropy loss function is used to measure the difference between the network output vector and the model predictive value,and it is used to adjust and update the network parameters.The specific algorithm application pseudo code of the cross-entropy loss function is shown in Algorithm 2.

Secondly,the layer-wise dynamic coordinated inverse bottleneck block is applied to every module except the Stage 1. The number of hidden layer channels is expanded to 6 times the input and the output is restored.Then,in high-dimensional modules,the channel features are balanced through down sampling operation,which can be more abstracted layer by layer in the convolution of high-dimensional space and expand the receptive field to extract more refined feature information. Furthermore,the triplet attention module is also connected to the residual structure of each layer except the Stage 1. Each channel interacts in dimension to form three interactive tensor branches (channel,height),(channel,width) and (height,width). Under the premise of being lightweight,it can provide rich cross-dimensional interaction,to extract broad feature information.
After the network stacking is completed,the average pooling layer is connected,so that the information can be completely transferred to the final classifier. Finally,2,048 fine feature maps are converted into 2,048 dimensional vectors,which are output to the final full connection layer for the final seven classifications of apple leaf diseases.
Multi-scale residual moduleTo extract the input image features more comprehensively,we replace the 3×3 convolution in the original residual module with multiscale convolution. Stacking among multiple layers of multidimensional perception convolution blocks can lead to the network’s learning parameters behaving similarly,resulting in a large amount of information redundancy(Lianget al.2021). To make the feature extraction of multi-layer stacked models more comprehensive and diverse,and prevent the similarity of feature performance,this paper inspired by the multi-scale diversity measurement network (Gonget al.2019),and through the comparison of the efficiency of different convolution cores in identifying the training set of this paper,see experiment 3.3 for details. 3×3 convolutions and 5×5 convolutions can make the model have the highest recognition efficiency within the same count of iterations(Guanet al.2022). Therefore,this paper adopts the 3×3 convolution combine with 5×5 convolutions to replace Stages 1,2,and 4 in the original ResNet-50 network in parallel,and keep the original Stages 3 and 5 unchanged,to achieve the complementarity of feature extraction between the lower and upper layers of the model and the high efficiency of network recognition.
The original residual module in Fig.5-A is a smallsized 3×3 residual convolution structure,which can ensure the efficiency of local feature extraction through data accumulation and constitutes a network with good capability and low complexity. The improved multi-scale residual module is shown in Fig.5-B. While ensuring the comprehensive performance of the network,the parallel combination of 3×3 convolutions and 5×5 convolutions can improve the recognition efficiency of our model compared to the original single-row network within the same count of iterations,which enables the network to obtain smoother features while improving the receptive field. At the same time,the extracted features are added together for fusion,so that the feature information can be extracted in a centralized manner without adding redundant parameters.
The detailed structure of the multi-scale module and the details of the layer-by-layer feature extraction are shown in Algorithm 3. And after the multi-scale combination,a triplet attention module is connected to capture the extracted rich features interactively across latitudes,and then filter more useful and detailed information.


Fig. 5 Multi-scale structure.
Inverse bottleneck structureInspired by MobileNetV2(Sandleret al.2018),smaller networks use smaller channel expansion rates for higher efficiency,while larger networks use larger channel expansion rates for better performance. In this paper,considering the balance between network depth and width,the traditional bottleneck structure in ResNet is replaced by an inverse bottleneck structure. The inverse bottleneck structure is a structure with a large middle and small end. It increases the number of channels in the hidden layer,while keeping the number of channels at both ends small. Because the number of 1×1 convolution channels used for down sampling is relatively reduced,while the number of convolution channels used for main feature extraction is increased,making the information for feature extraction more concentrated. This structure can effectively avoid the waste of information caused by using too many ReLu activation functions and reduce the loss of important information caused by compressing dimensions.
This paper uses the method of layer-wise dynamic coordinated inverse bottleneck convolution to replace the original bottleneck structure of ResNet-50,as shown in Fig.6-A and B,to prevent information loss when the network depth is deepened. To prevent information loss when the depth of the network deepens,we use a six-fold elastic expansion factor to expand the number of hidden layer channels and then recover it. Assuming that the number of input channels of the current module is 64,it is changed to 128 by the two-fold expansion after the first layer of convolution,and 384 in the middle-hidden layer after six-fold expansion,and is back to 256 channels after the third convolution. After the channel features are selected and refined through the down sampling operation,the information is fused with the input channel through the identity residual connection,which can be more abstracted layer-by-layer in the convolution of highdimensional space and expanded the receptive field to extract more refined feature information. The channel transformation details of the inverse bottleneck structure are shown in Algorithm 4.


Fig. 6 Bottleneck structure in the different blocks.
Cross-dimensional triplet parallel attention moduleThe CBAM (convolutional block attention module) attention mechanism (Wooet al.2018) is a vertical stacking of spatial attention and channel attention. The spatial attention uses the spatial dimension of the compressed input image feature mapping to identify meaningful feature information,while the channel attention generates feature descriptors to focus the position of the key feature information on the input images. The dual attention mechanism (Chenet al.2018) collects the features of the whole space into a compact set through the secondorder attention pool,and then selects the features through another adaptive attention module and distributes them to each position. There is also a triplet attention mechanism(Misraet al.2021).
After synthesizing the above two research methods,a three-dimensional interactive attention with parallel space and channel functions is proposed. Two dimensions are responsible for capturing the interaction between channel and space,and the remaining branch is similar to CBAM,which is used to establish separate spatial attention,and finally integrate the three branches.
Inspired by the above research,this paper improved the cross-dimension triplet attention module. After comparing the recognition efficiency of the convolution kernel in subsection 3.3,we use 3×3 convolution to replace the original 7×7 convolution for feature extraction.In addition,considering that the Sigmoid function is prone to lose network information due to the problem of gradient disappearance when the network computation is heavy(Liet al.2022),we adopt the Relu function (Sunet al.2021),which can reasonably control the network sparsity and calculate the derivative value more quickly,to reduce the interdependence between network parameters and stabilize the update of effective network information,as shown in Fig.7. The specific placement position of the attention module is verified in Section 3.4 and added to the rear of each multi-scale inverse bottleneck residual connection layer.
After the incoming tensor χC×H×Wenters the module,rotate the tensor along the three directions of channel,height,and weight respectively,and keep the other two directions unchanged to obtain the vectorsϵ[C´×(H,W),H´×(C,W),W´×(C,H)] of the three branches. Each branch then obtains (1×M×N) through the corresponding pool layer and convolution layer of the Z-pool,where M,NMϵ(C,H,W). The definition of the pooling layer of Z-pool is shown in formula (5).
where 0d represents the 0th dimension of the Z-pool operation.
The average pooling and maximum pooling are simultaneously applied to the 0th dimension of the 3D vector,reducing it to two,that is,the tensor after passing through the Z-pool alone becoming*ϵ(2×M×N),where M,Nϵ(C,H,W),which can reduce the depth while retaining the tensor information to reduce the calculation cost.

Fig. 7 Improved triplet parallel attention module.
Finally,the vector is normalized and the sigmoid activation layer is used to obtain the attention weight,and the attention weight is re-applied to*. Then it is rotated back along the rotation axis to maintain the same output shape as the initial tensor. The output tensor y after attention refinement is expressed as formula (6),and formula (7) can be obtained through simplification.Algorithm 5 shows the pseudo-code of the crossdimension triplet attention module.
where σ is the algebraic symbol of the activation function,is the simplified vector after passing the Z-pool layer,χ is the initial vectors,and,is the vector obtained after the initial vector is rotated by three dimensions,ψ1,ψ2,ψ3is the convolution layer with the kernel size K defined in the structure.ω1,ω2,ω3are the three cross-dimension attention weights generated by formula (7),y3are three cross-dimensional final output tensors.

3.Experiment and analysis
3.1.Experimental environment and preparation
The method proposed in this research is implemented on the Python 1.10.1 deep learning framework,and all experiments are conducted on Intel®Core™ I9-11900K@ 3.50 GHz CPU and NVIDIA GeForce RTX 3090 GPU. The operating system uses Windows 11. The number of Epochs in the experiment is set to 100. To maintain stable training while obtaining appropriate model convergence acceleration,the dynamic attenuation of the learning rate is set. Adam optimizer is used. The initial learning rate is set to 0.01. The learning rate update strategy of piecewise exponential attenuation is adopted.The learning rate is reduced to 10% of the original after every 25 Epochs.
3.2.Ablation experiment
To verify the impact of the basic components of the module added in the experiment on the overall model efficiency,the ablation experiment is conducted in this paper. The variables are controlled into eight parts,namely,1) Part A+B+C,2) ResNet-50,3) Part A,4) Part B,5) Part C,6) Part A+B,7) Part A+C,8) Part B+C. Part A is the initial network single plus cross-dimension triplet parallel attention module. Part B is the initial network single plus multi-scale residual module. Part C is the initial network single plus inverse bottleneck structure.Part A+B is ResNet-50 plus cross-dimension triple parallel attention module and multi-scale residual module. Part A+C is ResNet-50 plus triplet attention module and inverse bottleneck structure. Part B+C is ResNet-50 plus multi-scale inverse bottleneck residual module and inverse bottleneck structure. Part A+B+C is the complete module of this paper.
The training loss and validation accuracy of the ablation experiment are shown in Figs.8 and 9 and Table 2. The accuracy of the improved complete model in the validation set can reach 98.73%. Next is the ablation comparison model with two modules. The accuracy rates of Part A+B,Part A+C,and Part B+C are 97.92,97.84,and 97.61%,respectively,which are higher than those of networks with only one module. Moreover,network with Part A+B or Part A+C converge faster than those without triplet attention modules,and network with only Part A converge faster than network with only Part B or C. It can also observe that the computational cost of Part A is relatively small compared to the overall computational cost of the model. This means that it can improve the parallel search efficiency and achieve a certain level of accuracy while incurring only a small computational cost. In addition,the Part C part with only the inverse bottleneck module added has a lower accuracy of 97.02% compared to the other individual modules,but it is still an improvement compared to the original ResNet-50 network,and the inverse bottleneck module can reduce a certain amount of computation while slightly improving the network accuracy (Liuet al.2020). After the above comparison of ablation experiments,the complete model of our research,namely Part A+B+C,achieved the highest accuracy and lowest loss compared with other experimental modules,and the experiment verified the effectiveness of the model.
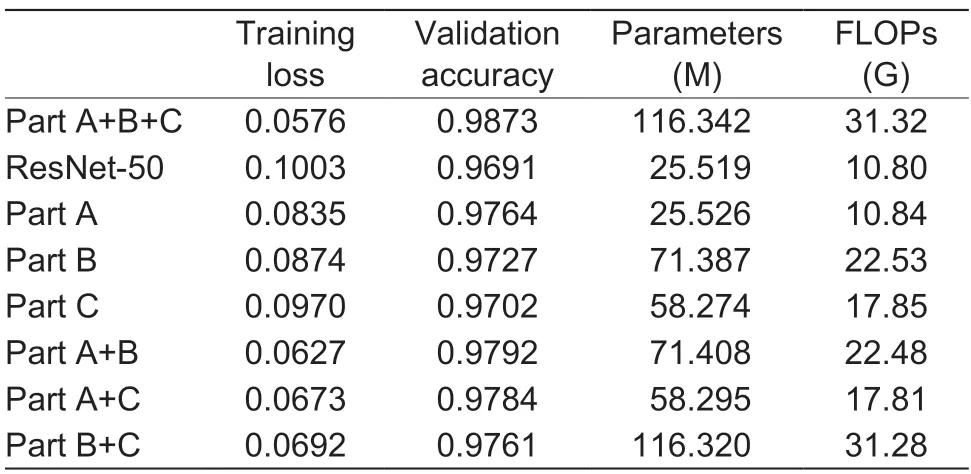
Table 2 Comparison of ablation experiment results

Fig. 8 Comparison of training loss.

Fig. 9 Comparison of validation accuracy.
3.3.Recognition efficiency among different convolution kernels
In theory,the larger the convolution kernel is,the larger its receptive field will be. The larger the convolution kernel is,the better to retain more information in the down sampling process,and extract more comprehensive discriminant feature from deeper networks. However,the smaller the convolution kernel,the better the convolution kernel can be used alone and can minimize the network parameter data and recognition complexity (Aiet al.2022). After synthesizing the different advantages of the different sizes convolution,using different types and sizesof convolution cores in the research network,especially in the parallel structure,helps the network achieve better results (Wanget al.2022).
To make the best combination pairing of convolutions for the multi-scale network in this paper,as shown in Table 3,the recognition efficiency among different kernel convolution comparison experiment is performed for 3×3 convolution,5×5 convolution,and 7×7 convolution in a simple single convolution network. In 100 cycles of training,5×5 convolution is far superior to 7×7 convolution in improving network speed and accuracy,and it requires the least number of iterations while achieving a high recognition rate in the effective range,while 3×3 convolution can achieve the maximum recognition rate while ensuring a relatively excellent rising speed.
Therefore,this study decides to use a multi-scale network with a parallel combination of 3×3 convolution and 5×5 convolution,which can significantly improve the recognition efficiency of the model within the same number of iterations compared with the original single-row network,and obtain smoother features while improving the receptive field.
3.4.Influence of the different placement of attention modules
The location and number of attention modules have a great impact on the efficiency of the whole model (Wang Y Xet al.2021). We test the placement of modules in turn,as shown in Fig.10. UP means placing the attention module in the convolution module,MID means placing the attention module in the residual connection,and DOWN means placing the attention module after the residual module. It can be seen that after the attention module is connected to the residual module,the overall training effect of the model is the best,and when placed in the other two positions,the global feature vector cannot be extracted well,and there are always be omissions in the acquisition of the attention feature vector. Adding the triplet attention module at the end of each residual module can better focus on the key feature information comprehensively,thus improving the generalization ability and recognition efficiency of the network. Therefore,we choose to add the attention module to each improved module.

Fig. 10 Influence of the different placement of attention modules.
3.5.Model classification performance experiment
The improved model in this paper shows high precision,recall,and specificity in six diseases and one health classification as shown in Table 4. Precision,Recall,and Specificity can be expressed by the following formulas:
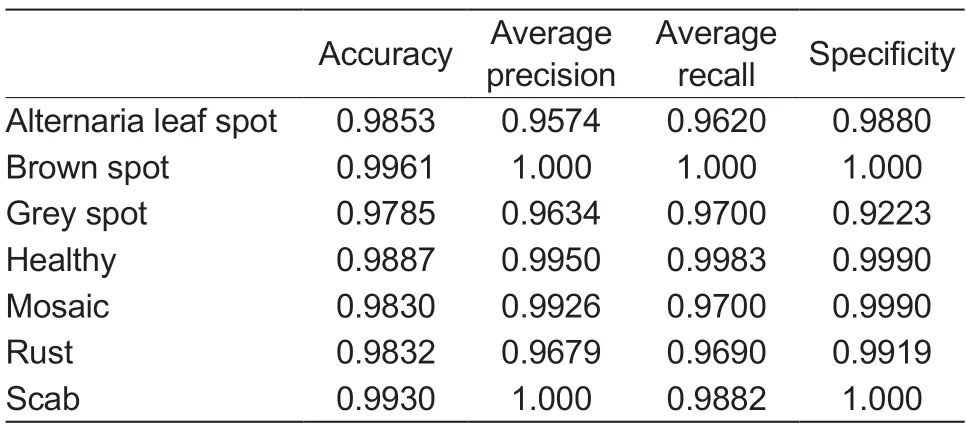
Table 4 Classification performance of the proposed model
Among them,TP is true positive,FP is false positive,TN is true negative,FN is false negative.
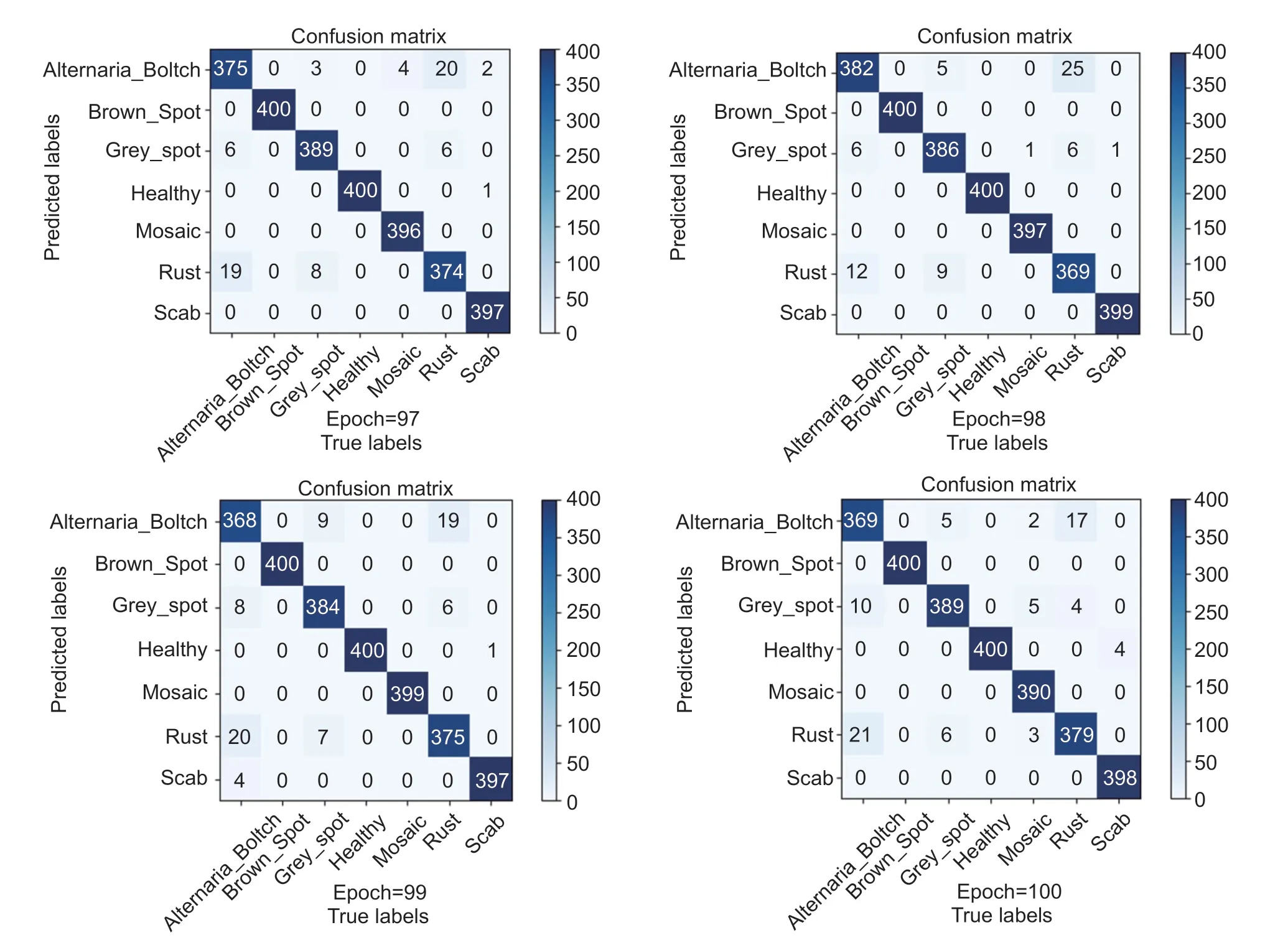
Fig. 11 Confusion matrix for different epochs.
The confusion matrix intuitively shows the classification performance of the proposed model. As shown in Fig.11,theYaxis is a predictive label,and theXaxis is a real label. Meanwhile,we have also included graphical results of the final predictions for various types of diseases,as shown in Fig.12. By displaying the graphical results,it shows that the model performed with high accuracy in predicting each type of disease. These graphical results also better demonstrate the predictive capability of the proposed model.
The test set used for testing contains a total of 2,800 pictures,and the final accuracy rate can reach 98.57%.The average accuracy rate of the proposed model can reach 98.23% or more. It can be seen from the confusion matrix that there are also subtle errors in the classification of the model,mainly between Rust and Alternaria Leaf Spot. The characteristics of Rust and Alternaria Leaf Spot are both composed of Yellow-brown rounded spots,which are very similar in color and shape. It is easy to observe that these two characteristics have certain similarities,so it is easy to lead to misjudgment of the network model.In addition,the training efficiency of the network will also be affected by the complex mixed background. A few healthy leaves in the background are also easy to be confused into features. Therefore,the classification of apple leaf diseases under complex background is a very challenging work. However,both the confusion matrix and the graphical prediction results show that the misclassification rate of the proposed model is relatively low. In a moderate range,it shows excellent recognition effect and has strong generalization ability and robustness for the classification of apple leaf diseases.
3.6.Data preprocessing and enhancement experiment
In the training process of the original apple leaf disease datasets,because there is no control of independent variables and the basic processing of datasets is not sufficient,the distribution range of feature values always varies greatly,and fewer data often leads to uneven samples,which is easy to cause overfitting of the network(Zhanget al.2023). Therefore,data preprocessing and data enhancement are very necessary. Only by normalizing the features of each dimension to the same value interval and eliminating the correlation between different features,can we obtain ideal results. In this paper,the images are uniformly cropped to 224×224 pixels,and the original datasets images are enhanced with five data enhancement operations (90-degree,180-degree,and 270-degree clockwise rotation,gaussian blur,horizontal and vertical flip,contrast enhancement and reduction,brightness enhancement and reduction) are performed on the original dataset images. The images are normalized to make the network avoid overfitting and obtain better performance.

Fig. 12 Graphical prediction results display.
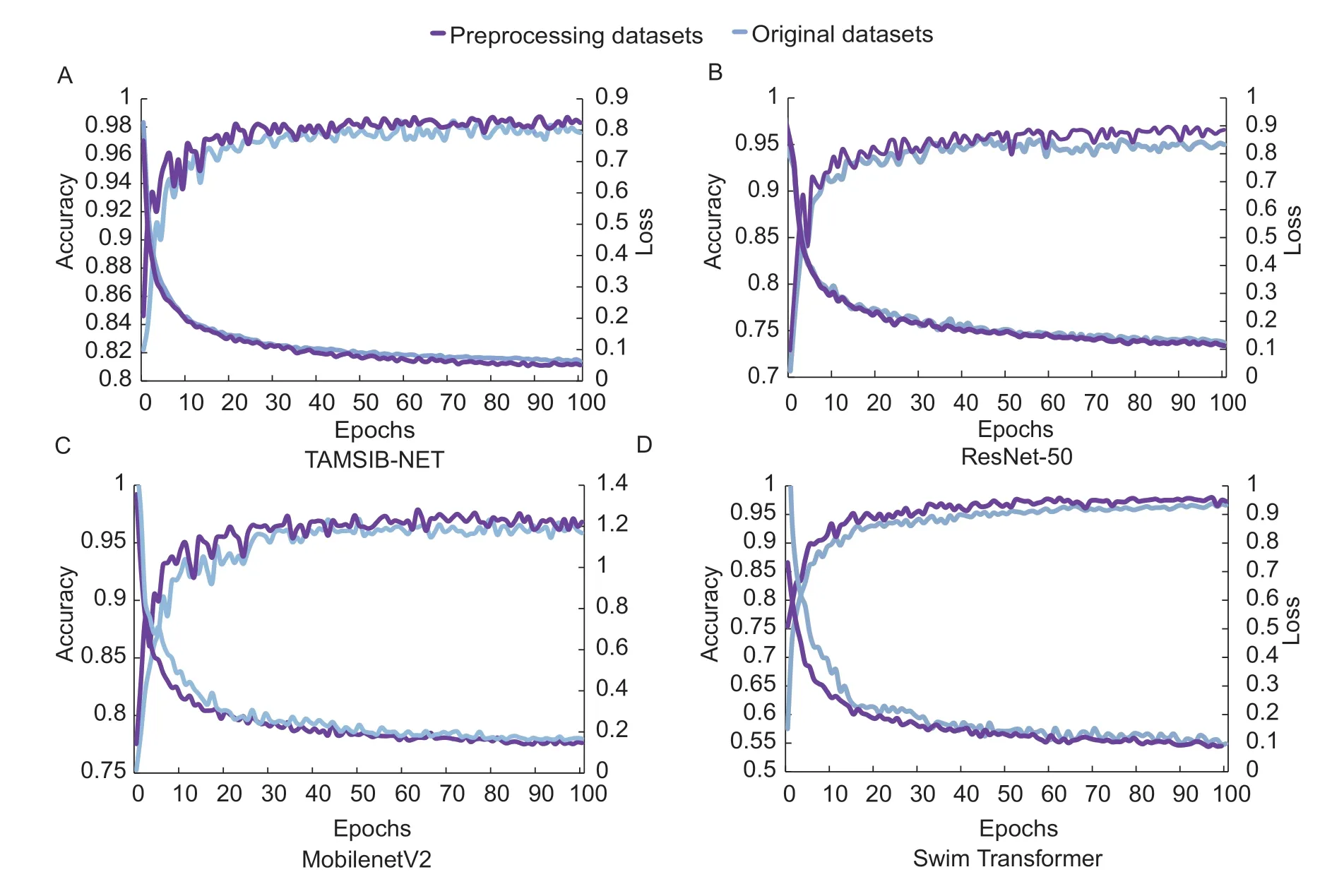
Fig. 13 Result comparison before and after data preprocessing on four networks.
Fig.13 and Table 5 respectively illustrate the training loss and validation accuracy comparison results before and after data preprocessing on the original ResNet50 network (Yuet al.2022),MobilenetV2 network (Pradhanet al.2022),Swim Transformer network (Li and Li 2022) and the proposed network. Among them,the proposed TAMSIB-NET is the ResNet-50 network variant,MobilenetV2 is the representative of the light-weight network model,and the Swim Transformer network is a typical network model using stacking modules and deep feature extraction.

Table 5 Comparison of networks accuracy and convergence time before and after data preprocessing
This comparison experiment shows that,in the case of limited data volume,through data preprocessing and data enhancement to increase the diversity and stability of data set samples and guide the model gradient,the model can be more robust (Chenet al.2023). After dataset preprocessing and enhancement,the proposed model and the other three verification networks improve the model efficiency and accuracy and speed up the network convergence. Furthermore,in networks with more complex parameters and longer training time,the difference in convergence time of the model is more pronounced. In other words,the datasets of apple leaf disease used in this paper has significantly improved the generalization ability and recognition effect of the proposed network model through data preprocessing and data enhancement.
3.7.Datasets ratio and size sensitivity analysis experiment
Compared to datasets that are more suitable for model training,the diversity and complexity of real-world datasets pose more significant challenges to model performance.In real-world datasets,the amount of data for different categories may be imbalanced,the overall size of the dataset may also vary,and there may be unknown variations and factors that affect model performance. To demonstrate that our algorithm trained on our datasets can performs well in the real-world applications,we conduct some experiments about dataset size and ratio sensitivity analysis. By comparing the performance of the proposed system on the real-world dataset with different image ratios and sizes,we aim to prove the applicability of our algorithm in the real-world scenarios.
In the experiments,we keep the total count of the original dataset and maintained an 8:2 ratio for the overall dataset,create datasets with image proportions similar to the real-world scenarios for each category. Additionally,we create a smaller dataset with imbalanced class proportions to perform as a negative example. Then,we keep the same training and testing settings to train and test our algorithm on these datasets. The comparison with our original experimental result is shown in Fig.14. Meanwhile,the obtained confusion matrices are shown in Fig.15.

Fig. 14 Result of datasets ratio and size sensitivity analysis experiment.
The experiment results in Figs.14 and 15 show that even in the case of imbalanced datasets in the real-world scenarios,our algorithm trained on the same proportion of datasets still achieves good results. Indeed,our algorithm also produces fluctuations and overfitting when facing very small and imbalanced datasets. This extreme situation is sometimes also a reality,which may result in inaccurate and unstable model performance evaluation results,but it is obvious that the average accuracy of our model did not change significantly. This indicates that ouralgorithm not only performs well when the proportion of the data set is balanced,but also has good generalization ability to cope with the problem of imbalanced datasets in the real-world scenarios.

Fig. 15 Confusion matrix results for datasets ratio and size sensitivity analysis experiment. A,datasets with the same proportions of each image type (original). B,datasets with the proportions that match the real-world scenario. C,smaller validation set with imbalanced proportion of image type(negative example).
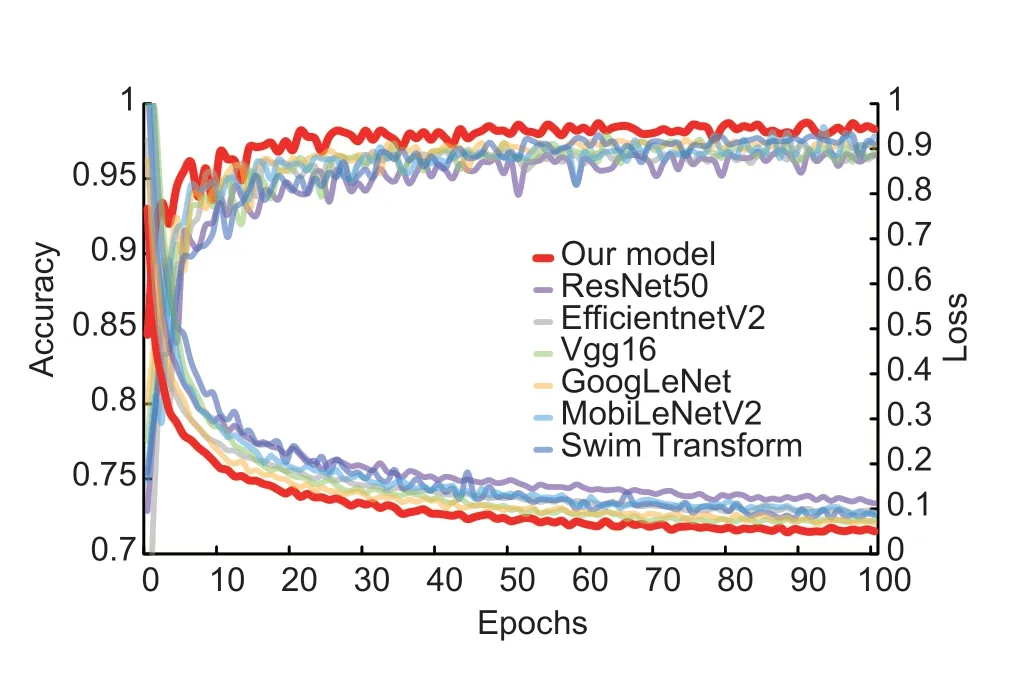
Fig. 16 Comparison of accuracy and loss of seven network methods.
3.8.ldentification efficiency of different networks
To verify the classification performance of the improved model on the preprocessed datasets,the final optimized improved model in this paper is compared with the conventional ResNet-50 model method (Yuet al.2022),GoogLeNet network (Songet al.2021),Vgg16 network model (Yanet al.2020),MobilenetV2 method (Pradhanet al.2022),EfficientnetV2 model (Wang Pet al.2021),Swim Transformer method (Li and Li 2022) for apple leaf disease recognition experiments. The corresponding experimental results are shown in Fig.16. Meanwhile,the structure of the main modules of each network can be found in Fig.17. In a single variable environment where NVIDIA GeForce RTX 3090 GPU and batch size are uniformly set to 32,the validation accuracy and training loss of the above seven networks,as well as the overall convergence speed of the network,are displayed. Fig.18 shows the maximum,average,and minimum accuracy ratios of each network. See Table 6 for detailed values. It is easy to see that our model is more stable and accurate than other models.

Table 6 Comparison of accuracy and loss for some network models

Table 7 Performance comparison of network models

Table 8 Comparison of accuracy and loss with some other advanced methods in the same field

Table 9 Performance comparison of some other advanced methods in the same field
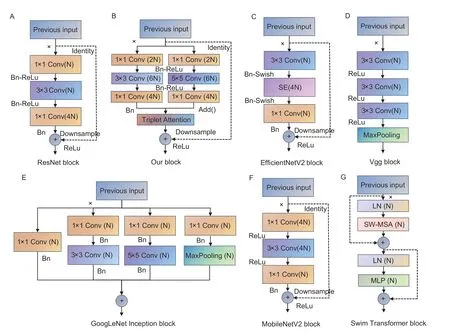
Fig. 17 The structure of the main modules of each network.

Fig. 18 Comparison of seven network precision.
It is easy to see from Fig.16 that in comparison with the other six models,our model can be more stable and relatively convergent in the first 10 epochs,and can obtain more prominent model convergence effect and accurate identification effect at the same time. In the case of training 100 epochs at the same time,the model proposed in this paper is shown in Tables 6 and 7. Comparing with the other network structures in Fig.17,our networkdoes not generate a large number of accumulations,which is in contrast to VGG16’s large number of repeated convolutional layers and Transformer’s MLP multifull connected layers,making our network relatively faster in recognition speed. Compared with EfficientV2,MobileNetV2,and the basic model ResNet50,the multiscale inverse bottleneck improvement of our model more finely extracts feature information and achieves relatively higher recognition efficiency. Moreover,compared with GoogLeNet which also adopts a multi-scale module,the introduction of attention makes it easier for our model to focus on important information in the image and reduce redundant information. The above points can also be verified in the experiments,comparing with other networks,the proposed model achieves the fastest convergence speed,the highest model accuracy of 98.73%,the average accuracy and recall rate,and the highest F1score. The parameters of the proposed model are slightly larger than those of the lightweight network but less than those of the original Vgg16 model and Swim Transformer network,with shorter training time and more obvious advantages. Compared with previous studies,the proposed model has better advantages in terms of recognition accuracy,extraction ability,and robustness and stability,etc.,and is suitable for applications in scenarios that require relatively higher computing resources but place greater emphasis on accuracy and performance.
3.9.Comparison of methods in the same field
In order to demonstrate the superiority of the improved model proposed in this paper compared to other methods in the same field,we compared our method with DBNet,SE_Xception,AFD-Net,MSP-Net,and LDS-Net,which are also applied in the field of apple leaf disease recognition. Among them,DB-Net is a method based on a unique dual-branch apple leaf disease diagnosis system,consisting of a multi-dimensional attention branch (DA)and a multi-scale joint branch (MS) to form a dual-branch network topology (Perveenet al.2023),SE_Xception combine squeeze and excitation (SE) modules with theXception network (Chaoet al.2021),and AFD-Net is a migration learning model based on the Efficient Network,applied to the apple foliar disease neural networks (Yadavet al.2022),MSP-Net is a multi-scale feature fusion apple disease classification model,which introduces pyramid convolution for feature extraction(Luoet al.2021). We also compared the ultra-lightweight LDSNet for leaf disease recognition (Zenget al.2022).
The results of the comparison are shown in Tables 8 and 9,It can be seen from the tables that our model is significantly superior to other models in terms of precision,recall,and other aspects. In addition,our model has a clear advantage in recognition rate compared to models with the same level of parameters (e.g.,MSP-Net,etc.),and it also has better recognition performance than other lightweight models (e.g.,LDS-Net and SE_Xception,etc.). It can be found that our algorithm has equally better cost-effectiveness and competitive advantages in terms of recognition accuracy and overall model performance compared to other methods in the same field. Considering the value of various aspects of the model,although our model still has shortcomings in terms of parameter quantity,it still has greater competitive advantages in terms of recognition accuracy and comprehensive performance,providing a more efficient and accurate solution for practical applications.
4.Conclusion and expectation
In this paper,we proposed an improved layer-wise dynamic coordinated multi-scale inverse bottleneck residual network based on triplet parallel attention(TAMSIB-NET) for apple leaf disease identification. The model is trained on the processed joint datasets of Baidu Flying Paddle and New Botanical Village. The datasets contain 14,000 apple leaf images with six disease types and the healthy type under a mixture of simple and complex backgrounds. The TAMSIB-NET network achieved an accuracy level of 98.73% in the classification of this datasets,which is 1.82% higher than the classical ResNet-50 model,and 0.29% better than the apple leaf disease datasets before preprocessing,and it alsoshowed excellent classification capability in the test set and achieves competitive results in apple leaf disease identification compared to some state-of-the-art methods.
Three improvements of our model are as below: 1) The overlapping use of multi-scale residual modules realizes the complementarity of feature extraction of lower layer network and upper layer network,improving the network recognition accuracy and feature extraction of disease images. 2) Layer-wise dynamic coordinated Inverse bottleneck structure,with a large middle and small end,increases the number of channels in the hidden layer for processing more abundant features,and decreases the number of channels at both ends so that the refined features can be easily transmitted,which flexibly expands and scales elastically with the increasing network depth to capture crucial features at higher levels. 3) Crossdimensional triplet parallel attention module combines tensors two-by-two for cross-latitude interaction from channel,height,and weight directions,and refines tensors by improving the matching convolution kernel size,activation function and Z-pool pooling layer. Combining the dual advantages of spatial attention and channel attention,it retains tensor information while reducing the depth to make computing lighter.
The proposed model shows good performance in apple leaf disease identification and classification,with advantages of fast convergence speed,strong generalization ability,and robustness. Besides,there is also some room for improvement: 1) Our model can identify a leaf with one disease,but it is not applied to a leaf with multiple diseases. 2) The model can be furtherspeeded up while ensuring high classification accuracy by eliminating redundant functions,refining the amount of model’s parameters,and finding more suitable module stacking values. 3) The datasets contain only apple leaves with one disease while ignoring the simultaneous existence of multiple diseases.
Future work will focus on the following aspects: 1) The overall size and recognition speeds of the model is closely related to the applicability of the model. our model will be built as a more lightweight network and can be applied to devices with limited resources. 2) The efficiency of the model can be further improved by starting with the underlying function algorithm and weight change. Further research and explore how to optimize the parameters of the model to improve the performance and practicality of the model. 3) The datasets can be enriched by covering apple leaf images with multiple diseases on each leaf. In summary,the model in this paper shows a good comprehensive recognition ability,which provided a theoretical basis for the subsequent research inputs of apple leaf disease recognition.
Acknowledgements
This work was supported in part by the General Program Hunan Provincial Natural Science Foundation of 2022,China (2022JJ31022),the Undergraduate Education Reform Project of Hunan Province,China (HNJG-2021-0532),and the National Natural Science Foundation of China (62276276).
Declaration of competing interest
The authors declare that they have no conflict of interest.
 Journal of Integrative Agriculture2024年3期
Journal of Integrative Agriculture2024年3期
- Journal of Integrative Agriculture的其它文章
- Molecular mechanisms of stress resistance in sorghum: lmplications for crop improvement strategies
- Artificial selection of the Green Revolution gene Semidwarf 1 is implicated in upland rice breeding
- Dynamics and genetic regulation of macronutrient concentrations during grain development in maize
- The NAC transcription factor LuNAC61 negatively regulates fiber development in flax (Linum usitatissimum L.)
- The underlying mechanism of variety–water–nitrogen–stubble damage interactions on yield formation in ratoon rice with low stubble height under mechanized harvesting
- Rice canopy temperature is affected by nitrogen fertilizer