
改进YOLOv5-S的交通标志检测算法
2024-03-12 08:58刘海斌张友兵张宇丰
计算机工程与应用 2024年5期
刘海斌,张友兵,周 奎,张宇丰,吕 圣
湖北汽车工业学院汽车工程师学院Sharing-X移动服务技术平台联合实验室,湖北 十堰 442000
在无人驾驶领域,道路交通规则制约着智能汽车的应用与部署,对于智能汽车来说,实时可靠的交通信息是其在道路上安全行驶的首要前提[1-2]。作为智能交通系统(intelligent transportation system,ⅠTS)的一项基础功能,同时也是无人驾驶体系下的一个研究对象,交通标志的感知及其含义的理解有着重要的研究意义。
交通标志检测旨在识别图像或视频序列中交通标志的位置、类别和大小,根据技术种类的不同分为传统的交通标志检测方法和基于深度学习的交通标志检测方法。传统的检测方法更多的是结合交通标志自身的颜色与形状特征[3-4],采用滑动窗口等方式产生候选区域,使用诸如尺度不变特征变换(scale invariant feature transform,SⅠFT)或者方向梯度直方图(histogram of oriented gradient,HOG)等算法提取候选区域的图像特征,再使用诸如支持向量机(support vector machine,SVM)等分类器筛选目标类别。综合来看,传统方法需要结合多个处理步骤,算法的设计更复杂,同时人工设计的特征鲁棒性差、适用性弱,不能满足无人驾驶场景下的可靠性需求。
随着深度学习技术的兴起,卷积神经网络(convolutional neural network,CNN)在模式识别领域取得了重大的技术突破。基于卷积神经网络的目标检测算法可以克服传统方法的诸多缺陷,具有更高的检测精度和鲁棒性。根据是否生成目标的区域建议,基于深度学习技术的目标检测算法分为两类:two-stage 算法和singlestage 检测算法。在two-stage 检测算法中,选择性搜索或区域建议网络(region proposal network,RPN)被用来生成目标的区域建议,在此基础上通过神经网络进行分类处理,在结构上略为复杂,常见的有Fast R-CNN[5]、Faster R-CNN[6]、Mask R-CNN[7]等。张毅等人[8]通过改进Faster R-CNN的基础网络结构,在TT100K数据集上将检测精度提高了13.14%,但是算法的计算量太大,实时表现差。Han 等人[9]提出了一种改进Faster R-CNN的实时小尺寸交通标志检测方法,通过修剪冗余网络层以及采用空洞卷积的方式使得算法在分割小尺寸交通标志候选区域时更加稳健。虽然two-stage 算法具有不错的检测精度,但其整体性能依赖于候选区域选择算法,实时性较差。而single-stage算法不需要生成目标的区域建议,可同时完成不同目标的定位和分类,检测效率更高,常见的有SSD[10]和YOLO[11-18]系列。刘紫燕等人[19]通过改进空间金字塔池化(spatial pyramid pooling,SPP)[20]层以及特征金字塔网络(feature pyramid network,FPN)[21]层产生更大尺度的特征图,提高了YOLOv3 对小尺寸交通标志的检测精度。Fan等人[22]使用DenseNet作为YOLOv3的骨干网络,使得模型具有更少的参数量和更快的检测速度。冯爱棋等人[23]通过融合注意力机制以及视觉Transformer 来增强对交通标志的关注程度,改善了对小尺寸交通标志的漏检情况。俞林森等人[24]提出YOLOT 算法,采用注意力机制以及改进损失函数的方法改善算法对交通标志的检测效果,但是实时性不够好,检测速度不够快。
长期以来,交通标志的检测是计算机视觉领域当中具有挑战性的一项任务。交通标志通常是小尺寸目标,缺乏足够的视觉特征,因此有时很难将其与背景或类似的物体区分开来,这也使得交通标志更容易受到自然因素如复杂光照或遮挡问题的影响。为了能够更好地识别道路场景中的交通标志,需要定制一种能够抑制背景噪声干扰、具有高精度和高计算效率的交通标志检测算法。YOLOv5作为当前流行的深度学习目标检测算法,其已经整合了大量的优化策略,但是在检测交通标志时还是容易出现错检或漏检的问题。基于此,本文提出一种改进YOLOv5-S的交通标志检测算法,在保证实时检测的同时有着更高的检测精度及鲁棒性。本文的主要工作如下:(1)提出一种融合了坐标注意力(coordinate attention,CA)[25]机制的C3 模块并将其应用到YOLOv5的主干网络当中,在减少网络层数占用的同时获得更好的注意力关注效果。(2)在边界框回归阶段引入定位损失计算函数Focal-EⅠoU[26],使得算法更加关注高质量的分类样本,提高对难分类样本的学习能力。(3)在颈部网络当中采用轻量级卷积结构GSConv[27]来替换普通降维卷积,在降低网络参数量的同时提高特征的丰富程度。(4)本文改进了YOLOv5 的特征金字塔结构,通过更大尺度的特征图来检测小尺寸物体,在不增加过多计算量的前提下获得更好的交通标志检测效果。
1 相关工作
1.1 YOLOv5整体结构
YOLOv5 是一种single-stage 的目标检测算法,它结合了以往YOLO 系列的诸多优点,有着不错的精准度以及实时性表现。YOLOv5 包含多种版本,包括YOLOv5-N、YOLOv5-S、YOLOv5-M、YOLOv5-L 和YOLOv5-X等,通过调整配置文件可以自由的改变网络的深度和宽度。YOLOv5有着出色的可扩展性,在生产环境当中有着广泛的应用部署。YOLOv5 的网络结构如图1所示。
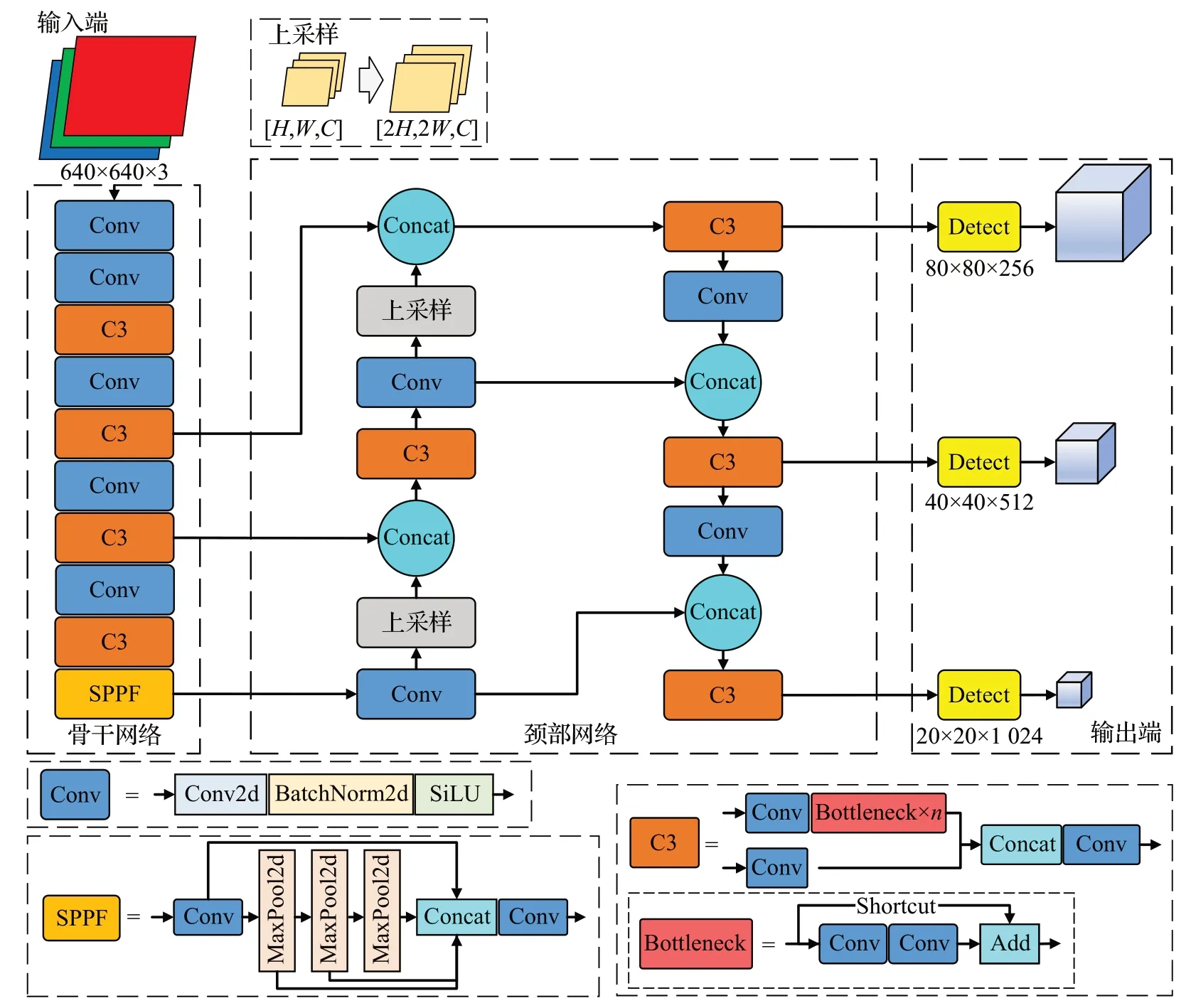
图1 YOLOv5网络结构Fig.1 Network structure of YOLOv5
1.2 损失函数
YOLOv5 采用了分类损失、定位损失以及置信度损失三种损失函数来评估算法的预测性能。交并比(intersection over union,ⅠoU)是一个计算定位损失的简单函数,通过计算交并比来评估两个边界框的重叠程度。然而,ⅠoU 有着诸多的缺陷,无法应用于实际情况。如今,定位损失的计算方法有着许多不同的改进版本,常见的如GⅠoU[28]、DⅠoU 和CⅠoU[29]等,其中CⅠoU 是一种考虑了更多优化策略的损失函数,有着比较好的评价准确度。最新的YOLOv5算法使用了CⅠoU函数来计算定位损失。ⅠoU 以及CⅠoU 的表达式如式(1)和式(2)所示:
其中,b和分别表示预测框和真实框,ρ表示两者之间的欧式距离,C表示两者的最小闭包区域内的对角线距离。v和α分别为长宽比评价参数和平衡因子,其公式如式(3)、式(4)所示:
2 YOLOv5网络改进
作为当前流行的目标检测算法,YOLOv5已经整合了大量的优化策略,但其提取到的特征易受噪声的影响、特征信息的丰富程度不足等问题使得YOLOv5 容易出现错检或漏检的问题。对此,本文设计了改进的YOLOv5检测算法,能够更加有效地检测交通标志。
2.1 融合坐标注意力机制
注意力机制可以降低背景噪声带来的干扰,使得神经网络更关注于目标物体的显著特征区域,生成质量更优的特征图。常见的注意力机制从特征通道[30]或者特征空间域[31]的角度出发,获取目标信息在不同通道和空间维度上的重要性权值。但是这种方法仅可以捕获到物体的局部信息,缺乏对长范围依赖特征的捕获能力。坐标注意力CA是一种能够产生精确位置感知的注意力机制,能够在空间方向进行位置感知,使得网络能够在更大的区域上进行注意力关注。坐标注意力同时考虑了特征通道间的关系以及位置信息,能够更好的定位敏感区域。坐标注意力机制主要由坐标信息嵌入和坐标注意力生成两个部分来构建对目标的长范围依赖,图2为坐标注意力机制的结构组成图。
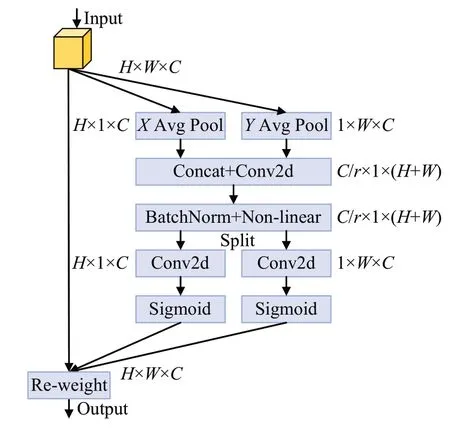
图2 坐标注意力机制的结构Fig.2 Structure of coordinate attention mechanism
2.1.1 坐标信息嵌入
不同于采用二维全局池化来计算通道注意力,坐标注意力机制将二维全局池化拆分为两个一维的编码过程,分别从水平和垂直两个方向获取位置信息。具体而言采用一对尺寸为(H,1)和(1,W)的池化核对输入特征的每个通道进行水平和垂直方向的特征编码,得到两个方向的感知特征,计算过程如式(5)、式(6)所示:
其中,表示垂直方向上的感知特征,表示水平方向上的感知特征,Pc表示来自上层网络的输入特征,下标c为特征向量的所属通道。
2.1.2 坐标注意力生成
在得到感知特征之后,就可以对通道信息进行编码。编码时首先将两个方向的感知特征进行拼接,再使用一个卷积核为1×1 的卷积对通道进行压缩。随后使用批标准化和非线性回归来编码两个不同方向的空间信息,得到注意力关系图fc,如式(7)所示:
在得到注意力关系图后,将其先后经过切分、1×1卷积变换和激活函数激活得到最终的区域权重和,将其作用于输入特征Pc,就可以得到注意力增强后的特征图。其中垂直区域权重的表达式如式(8)所示,水平区域权重的表达式如式(9)所示,调整后的特征如式(10)所示:
其中,和为切分之后的两个独立的张量,σ表示sigmoid激活函数,Dc为经过注意力调整后的特征图。
本文在C3 模块的输出端连接坐标注意力机制,形成新的C3CA模块。相较于在网络当中单独插入CA模块,这种方法可以减少网络层数的占用,计算效率更高。新的C3CA 模块融合在主干网络当中有着最大感受野的位置,可以充分地捕获全局特征信息,有效地发挥注意机制的作用。
2.2 损失函数的改进
虽然CⅠoU 考虑了边界框的相交面积、中心点距离以及边界框的长宽比,但是长宽比的衡量参数v计算比较复杂,降低了模型的收敛速度。当v满足条件{(w=kwgt,h=khgt)|k∈R+}时参数v就会失效,无法反映边界框的差距。进一步地对v求偏导数,可以得知w和v不能同步增减,阻碍了算法评估边界框相似度的准确性。
交通标志有着众多的类别,常见种类如警告标志、强制标志和禁止标志,而多数类别的标志特征不够明显,识别起来存在困难;同时,处在室外场景下的交通标志会受到多种因素的影响,使得算法在样本分类时会产生大量的负例,进一步降低了难分样本的识别。基于此,本文采用Focal-EⅠoU 损失函数取代默认函数,提升算法对多分类的识别精确度和鲁棒性。Focal-EⅠoU 由两部分组成,分别是Focal Loss[32]和EⅠoU 损失函数。EⅠoU 取消了对边界框长宽比的计算,改为边界框长宽值的回归,解决了w和v不能同步增减的问题。而引入Focal Loss 是因为Single-Stage 算法在训练时更容易受到难易样本以及正负样本不均衡问题的影响,导致模型泛化能力的降低,而Focal Loss通过平衡不同类别和不同质量样本的权重,减少对易分类样本的依赖,更加关注高质量样本,提高对难分类样本的学习能力。Focal-EⅠoU的公式如式(11)、式(12)和式(13)所示:
式中,LIoU为ⅠoU损失,Ldis为距离损失,Lasp为方位损失,wc和hc为包含两个边界框的最小闭包区域的宽度和高度,参数α、β和γ为控制抑制程度的超参数,用来平衡有益梯度和抑制有害梯度对模型的影响,C为保持函数连续的常数值。
2.3 融合GSConv卷积
深度可分离卷积(depth-wise separable convolution,DSC)是一种轻量级的卷积结构,通常情况下,在网络当中部署DSC 能够有效地缓解计算成本带来的压力,但随之而来的问题就是检测精度的大幅度下降。由于DSC在计算过程中拆分处理每个通道的信息,丢失了大量的隐藏连接,其特征提取能力不如普通卷积。因此,本文参考了一种更优秀的DSC 结构GSConv。相对于标准卷积,GSConv参数量更少,更适合于构建轻量级的检测模型。
如图3所示,GSConv是由标准卷积、DSC和随机排序所组成的混合卷积结构,通过随机排序混合标准卷积和DSC 所产生的特征图,使得标准卷积所保留的特征信息渗透到DSC内部,保持通道间的隐藏连接,提高特征的丰富程度。考虑到主干网络的优势是特征提取,本文将GSConv模块部署到网络的颈部,在保证特征图质量的同时降低对模型推理时间的影响。
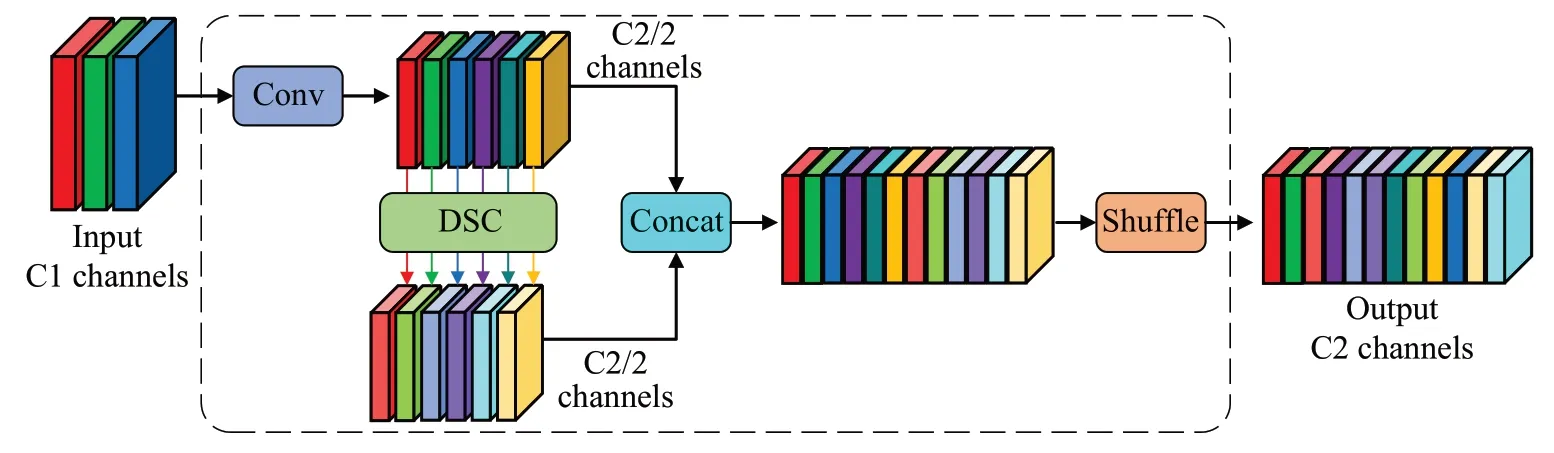
图3 GSConv模块结构Fig.3 GSConv module structure
2.4 增加小尺寸检测层
YOLOv5 采用了特征金字塔网络FPN 以及路径聚合网络(path aggregation network,PANet)[33]相结合的结构来融合不同尺度的特征。然而,默认融合路径产生的特征图尺度最大为80×80,按照等比缩放的原则,原图像相应区域的物体在特征图当中占比只会更小,这不利于小尺寸物体的检测。因此,本文将颈部网络进行加深,产生尺度更大的特征图。具体来说就是在FPN结构当中添加一个上采样层,产生160×160 大小的特征图,再与骨干网络的P2 输出端进行拼接。同时充分利用大尺寸特征图的优势,在PAN结构中将特征进行一次下采样,增强小尺寸特征图的表达能力。最后得到4种不同尺度的特征图(160×160,80×80,40×40,20×20)分别用来检测小尺寸、中尺寸、大尺寸和最大尺寸的物体,在不增加过多计算量、不损失检测精度的前提下获得更好的小尺寸物体检测效果。调整后的网络结构如图4所示。
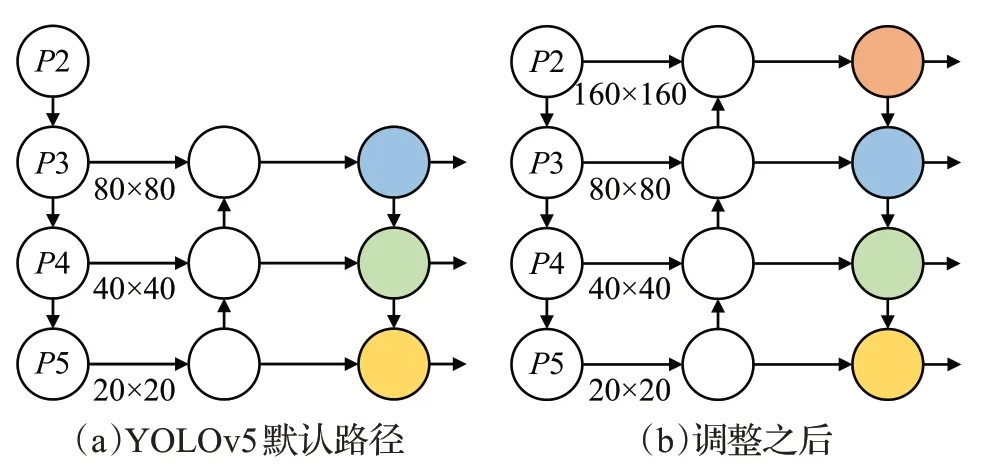
图4 调整后的特征融合网络结构Fig.4 Structure of adapted feature fusion network
由于更改了特征融合网络,原有的锚框不再适用,因此本文基于TT100K 数据集使用K-means 聚类算法来重新计算新的锚框,聚类结果如表1 所示。对比默认锚框,新的锚框尺寸更小,更符合交通标志检测的实际情况。
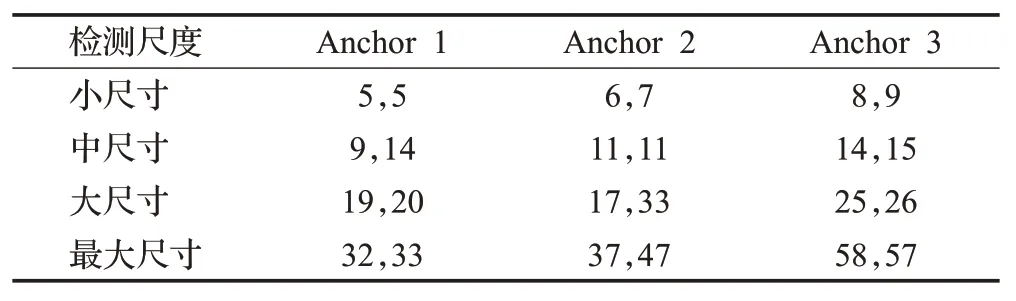
表1 K-means算法聚类结果Table 1 Cluster results of K-means algorithm
2.5 改进后的整体结构
改进后的网络整体结构如图5所示。
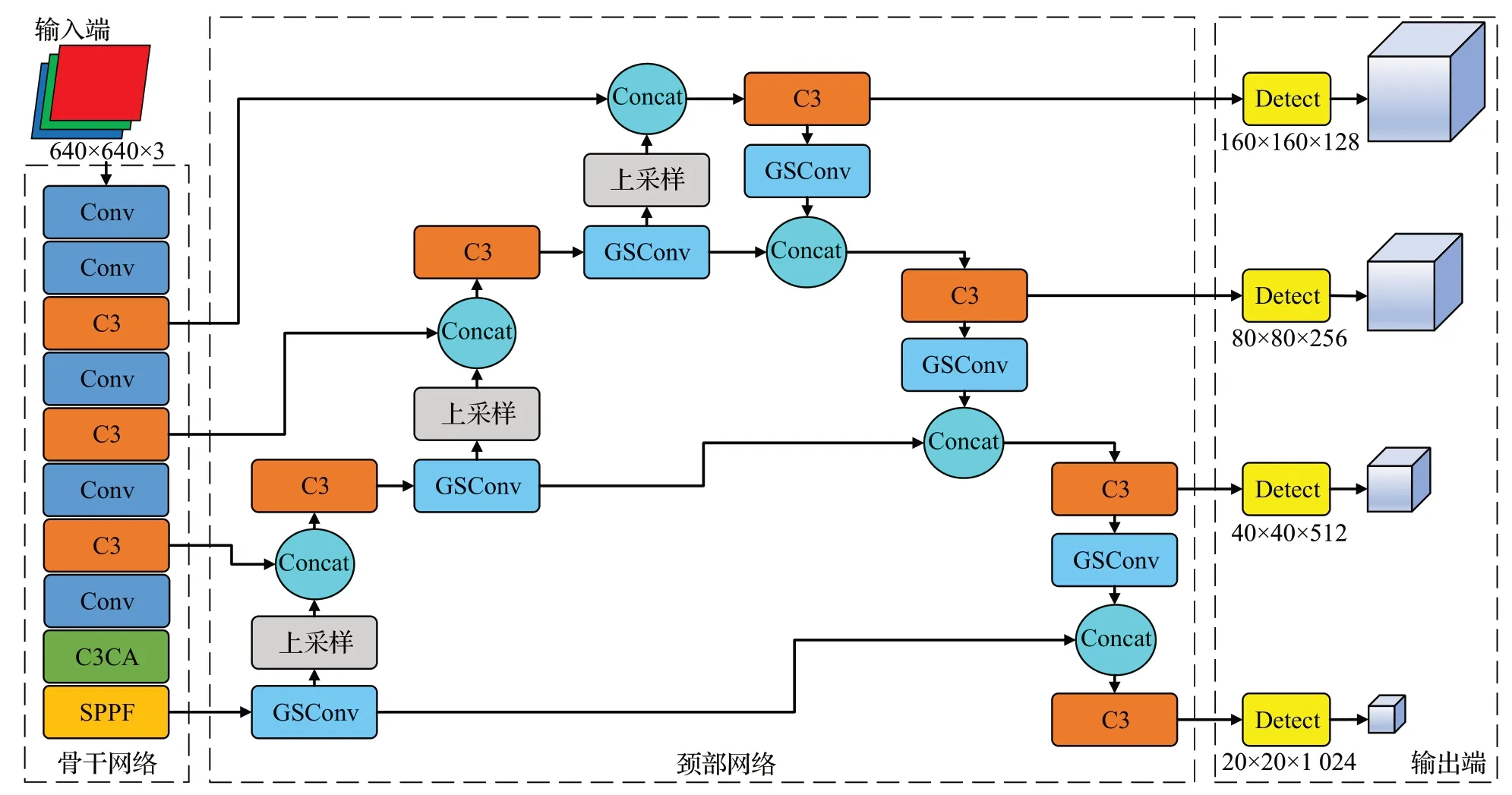
图5 改进算法的网络结构Fig.5 Network structure of improved algorithm
3 实验结果与分析
3.1 实验环境
实验所采用的硬件与软件环境,如表2所示。

表2 实验环境Table 2 Experimental environment
除此之外,网络输入的大小为640×640,启用MOSAⅠC图像增强;模型训练时的batch size 为自动确定,训练周期设置为200;权重参数优化器使用随机梯度下降(SGD)算法,初始学习率为0.01,使用余弦周期退火调整学习率。
本文采用TT100K[34]数据集来训练和验证改进后的算法。TT100K是一个大型的中国交通标志检测基准数据集,单张图像的分辨率为2 048×2 048,在标志尺寸、角度和遮挡程度等方面都有很大的变化。由于该数据集标注了数百种检测类别,而多数类别样本量不足,会影响模型的训练效果。本实验从中筛选出了样本数大于100的45个类别,总共8 293张图片,按照8∶1∶1的比例划分训练集、验证集与测试集。由于不同类别的训练样本数量有较大差异,使用copy-paste 功能对训练样本进行扩充。
3.2 评价指标
本实验选择了一些常见指标来评价检测算法的性能,包括精准率(precision)、召回率(recall)、F1 分数、mAP@0.5、mAP@0.5:0.95、参数量、FLOPs 和每秒帧速率FPS。F1分数是一个综合指标,同时考虑了精准率和召回率来评价算法在正负样本上的性能表现。均值平均精度(mAP)用于衡量多类别目标检测的准确性,是所有类别平均精度(AP)的均值。mAP@0.5表示ⅠoU阈值为0.5时所有类别的均值平均精度;mAP@0.5:0.95表示ⅠoU阈值为0.5到0.95时的均值平均精度,其步长取0.05。
3.3 实验结果分析
3.3.1 消融实验结果与分析
本文采用了多种方法来改进YOLOv5-S算法,本小节设计了几组消融实验来对比分析改进的效果,实验结果汇总如表3所示。

表3 消融实验Table 3 Ablation experiment单位:%
从表中可以看出,对比前两种方法的实验数据,整合了小尺寸检测层后的模型在精准率、召回率和F1 分数上均提升了5.1 个百分点,同时mAP@0.5 提升了5.5个百分点、mAP@0.5:0.95 提升了5.6 个百分点,这说明新的小尺寸检测层能够显著改善算法对交通标志的检测效果,提升整体的性能表现;第3 种方法在此基础上融合了坐标注意力机制,能够辅助网络在特征提取过程中捕获目标信息,获得更多有效的特征细节,训练结果显示各项指标均得到了一定程度的提升,对比上一种方法精准率提高了0.7个百分点,召回率提升了0.3个百分点,F1分数提升了0.5个百分点,mAP@0.5提升了0.6个百分点,mAP@0.5:0.95 提升了0.2 个百分点;第4 种方法采用了GSConv卷积模块来取代网络颈部的普通1×1卷积,实验结果显示整合了GSConv之后模型的精准率和召回率出现了一定的波动,F1分数有所下降,而mAP指标有着0.1个百分点左右的小幅提升,这说明GSConv在构建轻量化模型的同时也能够有效地辅助网络提取特征;第5种方法采用了Focal EⅠoU作为边界框回归的损失函数,Focal EⅠoU通过平衡不同类别和不同质量的样本来提高模型的泛化能力,而EⅠoU 损失函数则克服了CⅠoU 的缺陷,提升多分类模型的鲁棒性。通过分析实验结果,在引入Focal EⅠoU损失函数之后模型的精准率和召回率维持在89.7%和82.8%,而mAP@0.5 和mAP@0.5:0.95继续提升,达到了88.1%和68.5%。总的来说,这些改进方法显著提升了模型检测交通标志的能力,所带来的效果是显而易见的。
为了验证不同的注意力机制对算法性能的影响,分别选取几种不同种类的注意力机制进行对比分析,实验结果如表4所示。
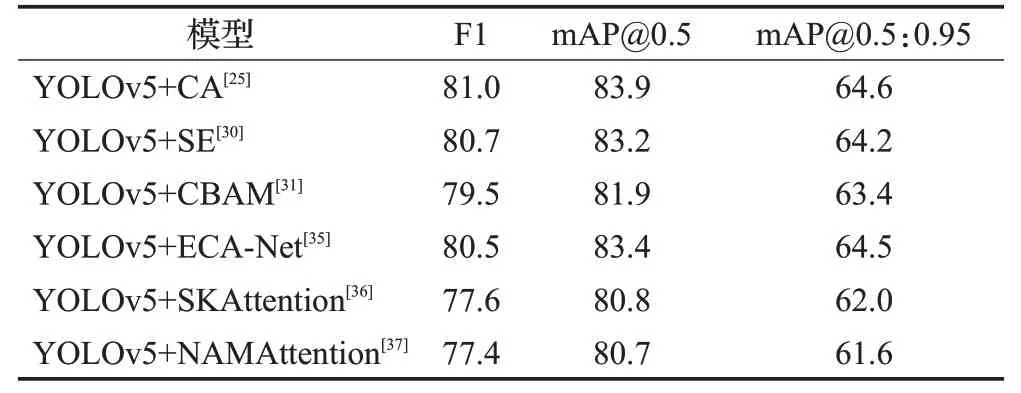
表4 不同的注意力模块对算法的影响Table 4 Effect of different attention modules on algorithm单位:%
从表4 中可以看出,坐标注意机制CA 有着最好的F1 分数和mAP 精度表现,这说明坐标注意机制可以有效地构建物体的位置感知,实际效果优于常见的几种注意力机制,更适合于交通标志的检测。
改进模型在所有类别上的precision-recall曲线如图6所示。得益于各种改进方法,综合了所有改进策略的模型曲线有着最大的横纵轴覆盖面积,说明其在所有的检测类别上有着最高的查准率和查全率。

图6 所有类别的precision-recall曲线Fig.6 Precision-recall curves for all categories
为了直观对比YOLOv5-S 和改进后的模型在每个类别上的精度,本文计算了每个类别的平均精度并制作柱状图,结果如图7 所示。总的来说,改进后的模型对各个种类的交通标志都有着更好的检测精度,对于某些类别如p12、ph4和ph5则有着显著的改善。

图7 YOLOv5-S和改进模型在所有标志类别上的平均精度Fig.7 Average accuracy of YOLOv5-S and improved models on various sign categories
图8 为各个模型在训练时的mAP 变化曲线。可以看到在引入小尺寸检测层后mAP保持着较快的增长速度,在100 轮左右达到了拟合状态。而在引入Focal EⅠoU 损失函数后mAP 的增长速度开始放缓,直至训练后期才逐渐超越其他模型,达到拟合状态。
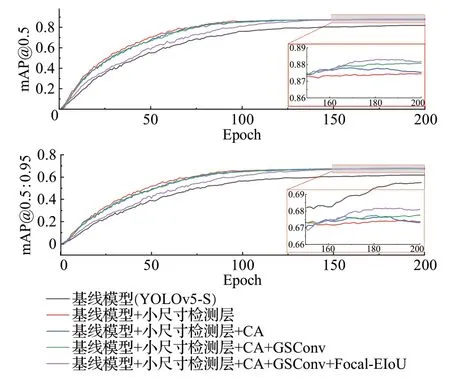
图8 mAP曲线Fig.8 mAP curves
提升算法计算效率的一种途径是使用TensorRT 推理引擎来优化深度学习模型的网络结构和推理过程,减少模型的计算量和资源消耗。为了使用TensorRT 推理引擎需要把权重文件从.pt 格式文件转换为.onnx 中间文件,再由其构建.engine 引擎文件。表5 为YOLOv5-S和本文模型在使用TensorRT 加速前后所耗费的推理时间。

表5 TensorRT加速对推理时间的影响Table 5 Ⅰmpact of TensorRT acceleration on inference time
从表5中可以看出,本文所提出的模型略微增加了推理时间,而在使用TensorRT 引擎加速后推理时间平均降低了约3 倍,有效地降低了计算延迟,节省计算资源,使得模型具有更好的实时性。
3.3.2 与其他算法的对比实验结果与分析
本小节在相同的实验环境下训练了多种流行的检测算法,包括YOLO系列、RetinaNet以及Faster R-CNN,实验数据汇总见表6。其中YOLOv6、YOLOv7 以及DAMO-YOLO属于较新的检测算法,在网络架构、优化策略以及复杂度等方面有着很大的不同,因此在网络输入端采取统一的输入大小。
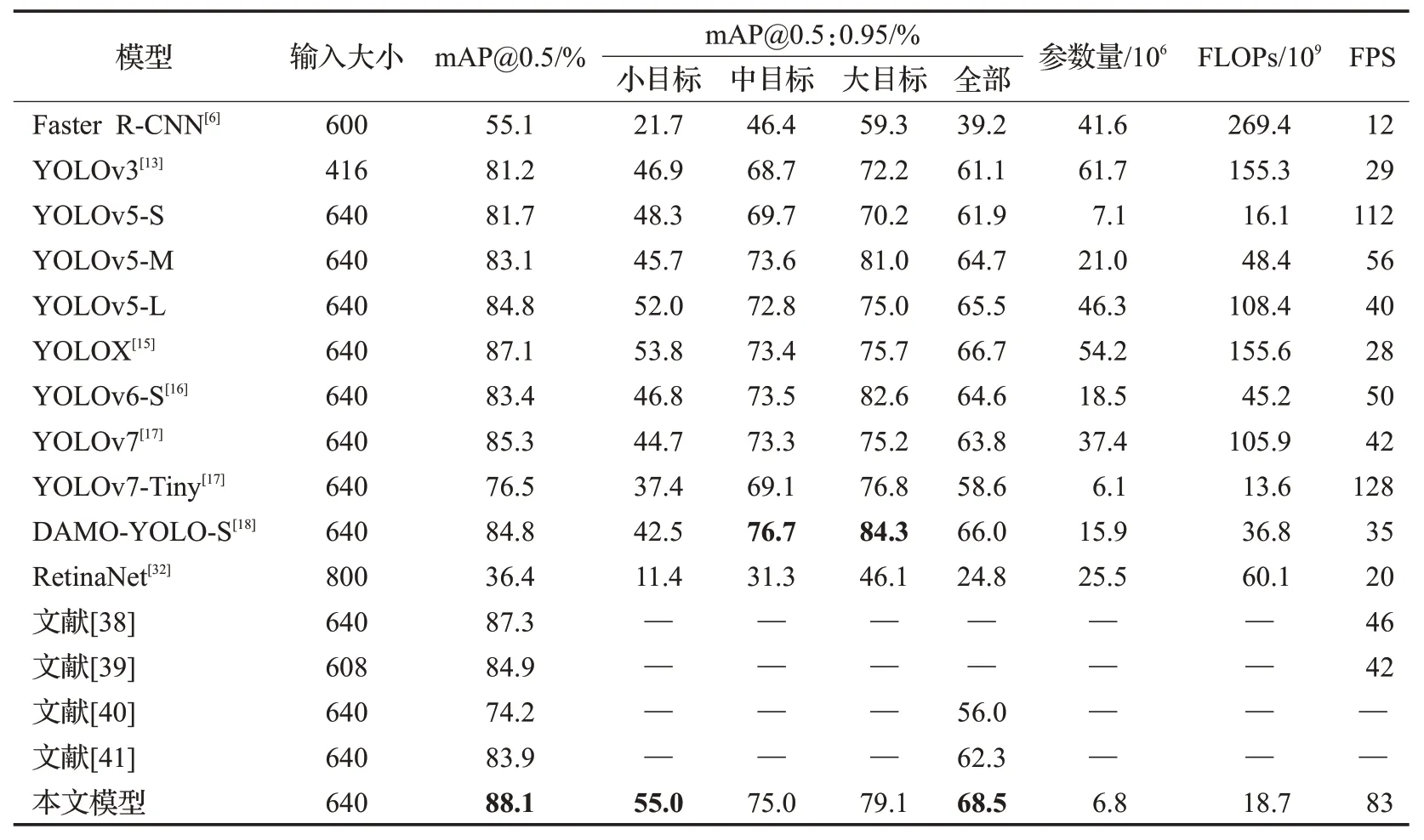
表6 与其他算法的性能对比Table 6 Performance comparisons with other algorithms
从表6当中可以看出,对比YOLOv3、YOLOv5-L以及YOLOX等参数量和FLOPs规模更大的检测模型,本文模型有着最高的mAP@0.5和平均mAP@0.5:0.95,在检测速度上处于领先。对比较新的模型如YOLOv6-S、YOLOv7以及DAMO-YOLO-S,本文模型的总体检测精度更高,参数量及FLOPs 更少,检测速度更快。对于小目标的检测,本文模型的mAP@0.5:0.95 比YOLOv3 高出了8.1 个百分点,比YOLOv5-L 高出了3.0 个百分点,比YOLOX 高出了2.2 个百分点,这说明改进后的模型对小尺寸目标的检测效果更加显著。而YOLOv6-S、YOLOv7 以及DAMO-YOLO-S 更倾向于检测中型和大型目标,对小目标的检测不够好。对比YOLOv5-S 模型,本文模型对于小目标的mAP@0.5:0.95 提高了6.7个百分点,对于全部目标则有着6.6个百分点的提升,参数量则减少了约4.2个百分点。虽然检测精度得到了提升,但FLOPs也从16.1×109增加到18.7×109,对FPS也产生了一定的影响,但这没有过多的影响到算法的实时性,改进后的模型依然有着83 FPS 的实时检测速度。对比参数量以及FLOPs更少的YOLOv7-Tiny模型,本文模型在检测精度上更优。其他模型当中文献[38]的mAP@0.5 较本文模型低了0.8 个百分点,文献[39]低了3.2个百分点,同时本文模型的检测速度优势更加明显。对比RetinaNet和Faster R-CNN,两者则达不到可靠检测和实时检测的需求,它们的性能表现均逊色于采用了更多优化策略的算法。
如图9 为YOLOv5-S 和改进模型的检测效果。图中每个子图的左上角为标志区域的放大图,右下角是在160×160 的检测层上绘制的热力图。从图中可以看出YOLOv5-S 在检测场景当中的小尺寸标志时给出的分数偏低,同时还存在漏检的问题,而改进后的模型有着更高的检测分数,漏检问题得到了缓解。通过热力图可以看到YOLOv5-S的输出有着更多的不均匀热点,说明其受到了背景噪声的干扰。而改进模型由于采用了坐标注意力机制,可以抑制噪声带来的干扰,热点的分布也更多的集中在标志区域。
4 结束语
针对现有的目标检测方法在检测交通标志时出现的错检、漏检和低精度问题,本文提出了一种改进YOLOv5-S的实时交通标志检测算法。为了增强神经网络对目标关键特征的关注度,提出了一种融合坐标注意机制的C3CA模块,将其部署在网络当中来感知物体的位置信息;使用Focal-EⅠoU损失函数使得算法更加关注高质量的分类样本,提高对难分类样本的学习能力;在网络颈部融合GSConv卷积,减少模型参数,提升计算效率;最后改进颈部的特征融合路径,将特征图大小扩大一倍,同时使用K-means聚类算法更新锚框。实验结果表明,改进后模型的mAP@0.5 和mAP@0.5:0.95 分别提升了6.4个百分点和6.6个百分点,其中对于小目标的mAP@0.5:0.95 提高了6.7 个百分点,模型的参数量减少了约4.2%。与其他的一些目标检测算法相比,改进后的算法在交通标志检测任务中更有优势。未来的工作将在移动计算设备上开展实验分析,实现实时可靠的道路交通标志检测。
猜你喜欢
东方少年·布老虎画刊(2023年12期)2024-01-01
汽车实用技术(2022年9期)2022-05-20
小雪花·成长指南(2022年1期)2022-04-09
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
小天使·一年级语数英综合(2016年8期)2016-05-14
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
小天使·一年级语数英综合(2014年7期)2014-06-26
中国中医药现代远程教育(2014年16期)2014-03-01
