
基于GRU-SVM 的工业系统态势预测模型
2024-03-11 01:51陈鸿韬
电子设计工程 2024年5期
陈鸿韬,郭 烁,洪 悦
(沈阳化工大学信息工程学院,辽宁沈阳 110142)
随着工业互联网技术不断升级,工业网络开放引入的安全问题不容小觑。2020年,美国天然气供应商为排查被攻击设备停止运营[1]。网络攻击方式不断升级,工控系统传统防御手段[2]难以主动防御。研究者转向入侵检测[3],但只能在发生入侵时预警。态势感知技术[4]是利用历史态势预测未来系统安全态势,对系统安全进行态势感知,主动发现异常并规避。
舒闯提出基于自适应灰色Verhulst 和GRU 的态势预测方法[5],利用Verhulst 构建预测态势序列,利用GRU 网络对预测值残差修正。文献[6]构建基于随机博弈的态势感知模型,通过情报事件相似度比对和博弈论量化安全态势。文献[7]通过GRA 对网络安全指标加权分析,SVM 对加权后的指标预测安全态势。
利用工控系统要素的强时序性建立态势感知模型,由于传统方法在准确性和实时性上表现欠佳,因此提出基于GRU-SVM 的态势预测模型。首先从工控系统中提取安全要素,构造时间序列。通过GRU模型对序列数据预测得到态势要素组,最后由SVM进行态势评估,输出态势值。
1 态势预测模型的相关概念
1.1 支持向量机
SVM 作为二分类模型常用于线性分类问题,其本质是寻找特征空间上间隔最大的分类超平面[8],该超平面作为分类器的决策线,将样本空间中的数据分割成两个类别。将式(1)作为核函数实现非线性分类,将低维数据映射到高维空间,在特征空间中实现内积运算,解决原始空间线性不可分问题:
其中,ϕ(xi)是映射后的特征向量。
1.2 注意力机制层
为解决神经网络结构对输入序列的编码长度要求和复杂输入造成的信息丢失问题,引入注意力机制。其是模拟人脑对事物观察时注意力偏向的过程,当人脑对事物的某部位重点关注时,通常给予更多的注意力,而忽略掉其余部分,注意力机制层[9]通过训练学习输入数据,得到输入与输出间相关性的权重矩阵。权重系数决定了模型对哪些特征进行重点关注。模型融合注意力机制结构如图1 所示。

图1 注意力机制结构图
在图1 中,x1,x2,x3,…,xj是时间序列模型中态势要素组的输入。h1,h2,h3,…,hj表示GRU 网络隐藏层的状态,对相对应的注意力权重值αtj进行求和计算,得到上下文加权向量ci。st是当下时刻的内部隐藏状态。注意力机制中各个权重以及当前输出的状态计算如式(2)所示:
其中,U、W是注意力机制的权重系数,b为偏置项。
1.3 GRU网络
GRU 是为解决长期记忆和反向传播中的梯度问题提出的算法模型[11]。与LSTM 相比较,GRU 主要包括重置门和更新门,在相同数据量下GRU 的运行时间更短。更新门控制上一时刻传到下一时刻的信息量,重置门控制是否遗忘上一步的信息。
GRU 单元结构如图2 所示。
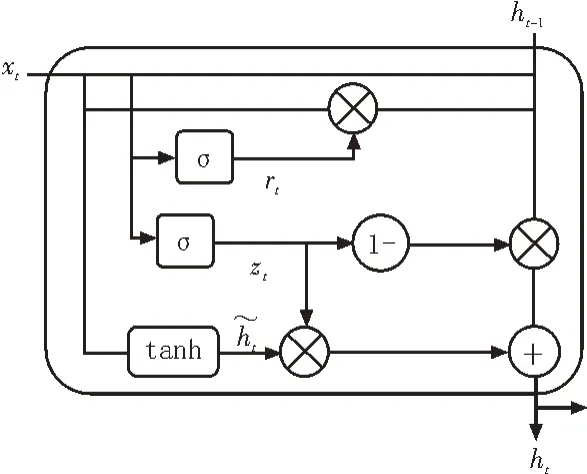
图2 GRU单元结构
图2 中,rt、zt分别是重置门和更新门在t时刻的输出,结合xt输入到GRU 网络中,利用tanh 函数将输出值映射到[-1,1]上。
2 基于GRU-SVM的态势预测模型
基于GRU-SVM 的态势预测模型主要包括数据预处理层、模型训练层以及实时态势感知层,具体层级架构如图3 所示。
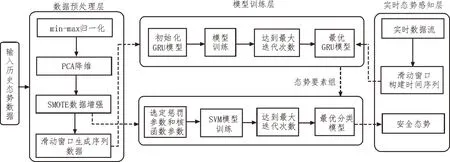
图3 态势预测模型框架
2.1 数据预处理层
数据预处理层是对工控系统数据进行预处理,获得高质量的数据集,以提高预测准确率。对历史态势数据归一化、数据降维、对不平衡的数据进行增强、利用滑动窗口生成时间序列数据。处理步骤如下:
步骤一:采集数据后,对数据进行清洗。
步骤二:归一化处理步骤一的数据,计算过程[12]如式(3)所示,统一态势数据量纲,将特征方差降低至一定范围,避免异常值的过度影响。其中x′、x、xmin、xmax分别输出值、初始值、最小值与最大值:
步骤三:数据降维。因数据维度较高,通过主成分分析法[13]对数据进行降维,消除冗余信息,在保证准确率下提高收敛速度。
步骤四:数据增强。由于正常工况数据比攻击异常多,因此采用SMOTE 方法[14]增强处理不平衡的异常数据,提高SVM 分类模型的性能。
步骤五:滑动窗口构建时间序列数据。通过历史数据训练模型完成对未来工况态势的预测,对降维后的数据通过滑动窗口构建时序数据。设定窗口大小S=M,样本总数N,经过处理后生成N-S+1 个样本。将窗口中包含前M个数值作为GRU 算法的输入样本,将第M+1 的数值作为样本标签,即为输出样本。生成序列数据的形式如表1 所示。

表1 样本构造结果
2.2 模型训练层
模型训练包括对GRU-Attention 预测模型训练和对SVM 分类模型训练。GRU 模型学习中用定长向量来表示复杂的时序信息,在不同特征表达信息量难免不足。因此在GRU 模型中添加注意力机制层,将隐藏层节点的输出作为注意力机制层的输入,使得模型在处理序列时能尽可能地保留特征信息。通过工业控制系统中的历史态势数据预测未来态势,对前M个历史值构建态势要素组作为GRUAttention 模型的输入,寻找其中的非线性关系,来预测第M+N时刻的未来值。其中N表示预测步长。因工况数据特征相互间的影响,单维态势值有强耦合性,故考虑采用对降维后的数据进行单维预测。具体算法步骤如下:
步骤一:将由数据预处理层处理后的数据,按照表1 的方法构造成时序单维态势要素组,作为GRUAttention 网络的训练集。
步骤二:初始化权重值和偏置项、学习率,网络层数包括注意力机制层和神经元个数。
步骤三:训练集按batch_size 划分后送入网络,通过前向传播计算结果,比较模型预测值和真实值得到误差值。采用后向误差传播对偏置项和权重值进行更新。
步骤四:判断模型迭代次数是否达到规定值,若没有则继续按步骤三执行,若达到则输出模型。得到GRU-Attention 预测模型,可对工控系统的实时态势进行单维预测得到态势要素组。
态势评估层是对系统要素评估获得工控系统态势,通过SVM 挖掘出态势要素组与系统态势的相关性,并利用SMOTE 中的上采样方法对不平衡数据增强后输入到SVM 分类模型学习训练,得到最优的态势评估模型。
2.3 实时态势感知层
经过上两层处理后,可获得GRU-Attention 预测模型和SVM 态势评估模型,便能通过以往态势要素数据来预测获得未来态势。利用非线性映射关系,按表1 的构造方法对当前M个态势值构造获得态势序列,输入到GRU-Attention 中,获得单维态势要素组。对多维要素进行单维预测,获得多维预测要素组,将其输入到SVM 评估模型,即可评估未来系统态势。图4 展示了利用单维预测方法获取多维要素组的过程。
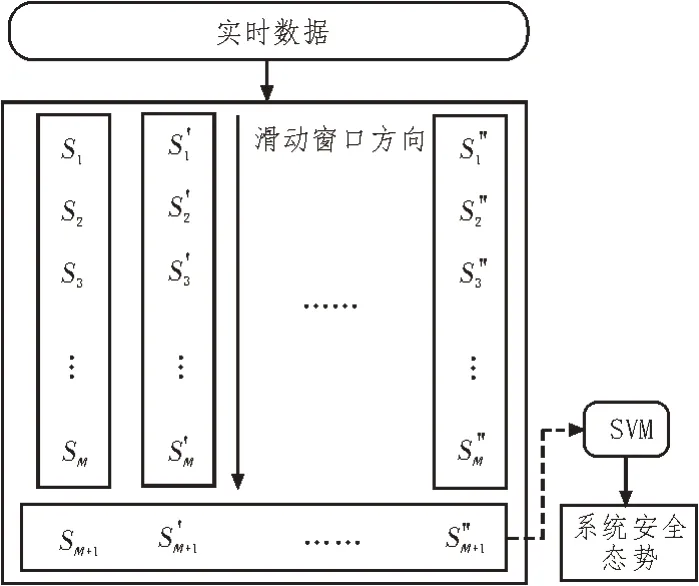
图4 构建要素组
3 实验仿真
为验证所提出的态势预测模型和评估模型的有效性,实验在Windows64 平台上进行。实验环境包括Intel(R) Core(TM) i5-3350P CPU(3.10 GHz)和基于CUDA 的Nvidia GeForce GTX 1070ti GPU(8 GB)。使用TensorFlow 的Keras 框架编写模型。
3.1 实验数据处理
实验仿真数据是SWaT 数据集[15],SWaT 是现代化水处理工业控制系统,对SWaT 系统进行攻击测试并采集工况数据,通过图3 中的数据预处理层,将数据维度降低至16 维,并按7∶3 的比例划分为训练集和测试集,对16 维数据构造预测序列,获得多维度态势要素组,进行态势评估。
3.2 模型预测以及评价指标
GRU-Attention 模型采用手动试值法调整,试值对比预测性能,最后确定模型层数为两层,神经元为130 个,dropout 值为0.3,在第二GRU 层后添加注意力机制层。输出值为单维态势要素,dense 层为1。GRU 的损失函数选择均方误差函数,优化器选择在SGD 基础上修正后的Adam 函数。通过每轮次训练的验证预测误差,滑动窗口大小为100,按表1 的构造方法,获得前100 个时刻的要素的相关性,预测第101 个数值。
在对SVM 评估模型训练之前,考虑到数据存在小样本的异常工况数据,通过SMOTE 的上采样技术增加异常工况数据,再输入到SVM 模型中。试值测试态势评估模型的影响,选定高斯径向基为核函数,惩罚因子为11,核函数参数为2。
为检验态势预测模型效果,采用平均绝对误差(Mean Absolute Error,MAE)和均方误差(Mean Square Error,MSE)作为实验过程的评价指标。评价函数如式(4)、式(5):
其中,yi是某样本的真实值,是预测值,N是预测样本总个数。
态势评估模型的输出值是工控系统传感器的工作状态,共有两类八种标签,其中包括正常情况和七种攻击异常情况。在态势评估过程中,若原有数据为真实正常工况,却被模型评估为预测攻击工况,则该数值被判定为FP,相反则为FN。而TP 和TN 是被模型正确识别的工况数据。SVM 态势评估模型以precision(准确率)、recall(召回率)、F1 作为评价指标。召回率=TP/(TP+FN),F1=2×准确率×召回率/(准确率+召回率),准确率=TP+TN/(TP+TN+FP+FN)。
3.3 实验结果分析
3.3.1 态势要素组的预测结果
通过GRU-Attention 和LSTM 进行态势要素预测,部分单维要素态势值如图5-6 所示,可看出所提模型的预测值和真实态势基本拟合,比LSTM 效果更好。为了更直观地体现GRU-Attention、LSTM 和GRU 的预测性能,利用MSE、MAE 进行误差对比。从表2 中可看出,GRU-Attention 和LSTM、GRU 相比,MSE 分别降低了58.8%、36.4%;MAE 分别降低了54.5%、37.5%。结果表明,GRU-Attention 的误差更小,预测精度更高。
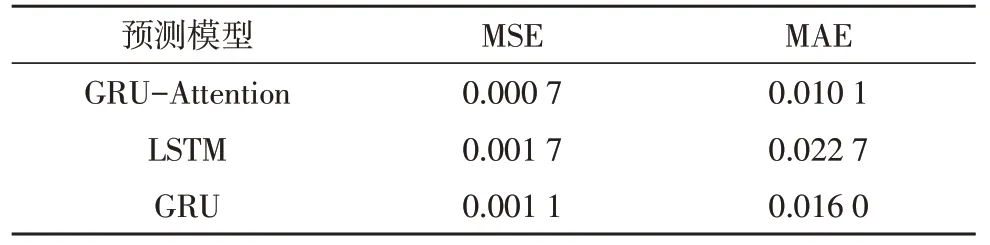
表2 不同预测模型的误差对比

图5 GRU-Attention态势要素组预测结果
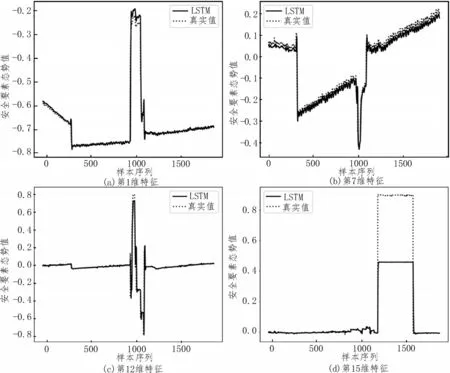
图6 LSTM态势要素组预测结果
3.3.2 态势评估效果
为检验模型的有效性,设计横向对比实验,对比算法有LSTM-SVM、RNN[16]-SVM、GRU-Attention-DNN、GRU-KNN[17],测试结果如表3 所示。

表3 各算法的态势评估结果
相比较于LSTM-SVM 算法,GRU-Attention-SVM 模型在准确率更优;RNN-SVM 和GRU-KNN 在召回率和F1 上偏低,说明KNN 易将攻击类别误判正常类别;而RNN-SVM 训练中耗时更多,预测精度不高。综上,GRU-Attention-SVM模型整体性能更佳。
通过实验检验GRU-Attention-SVM 对未来时间段预测性能,预测步长划分为四个时间段,间隔为5 s。从表4 可知,间隔为1~5 s 的预测评估效果最好,6~10 s 的准确率保持在96%以上,但是召回率偏低,不利于感知攻击工况态势。综上,应用第一组时间段进行态势预测。
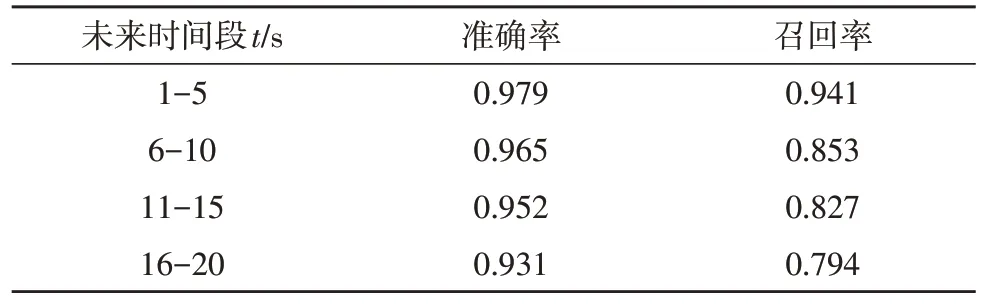
表4 未来时间段的态势评估对比
4 结束语
针对工业系统数据的时序性,提出基于GRUSVM 的工业系统态势预测模型,对多维数据进行单维逐一预测,利用GRU 和注意力机制对长序列处理优势训练预测模型,形成态势要素组输送到SVM 态势评估模型获得未来态势。经横向对比实验,结果表明GRU-SVM 模型性能更佳,预测精度更优。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
当代水产(2020年4期)2020-06-16
汽车与安全(2020年1期)2020-05-14
中国外汇(2019年19期)2019-11-26
中国化肥信息(2019年5期)2019-06-25
现代园艺(2017年22期)2018-01-19
河北书画研究(2017年1期)2017-08-22
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
山东青年(2016年2期)2016-02-28
