
基于轻量化YOLOv5的交通标志检测
2024-03-09 02:42王晓杰晋志华马继骏
郑州大学学报(工学版) 2024年2期
张 震, 王晓杰, 晋志华, 马继骏
(1.郑州大学 电气与信息工程学院,河南 郑州 450001;2.河南省交通调度指挥中心,河南 郑州 450001)
交通标志蕴含丰富的语义信息,这些信息或提醒或警告或禁令行驶在道路上的司机,保障行人和司机的安全。并且随着自动驾驶技术的快速发展,行驶在道路上的车辆只有快速、准确、高效地识别车道线、交通信号灯、交通标志等关键信息,并综合分析其他来源信息,才能提高自动驾驶的安全性。所以,交通标志检测的研究对于智能驾驶相关技术具有重大意义。
随着算力水平的提高,基于深度学习的目标检测算法已经成为科研人员的主流选择。两阶段目标检测算法和单阶段目标检测算法相继被研究学者提出。Girshick等[1]提出的R-CNN(region convolutional neural networks)被认为是两阶段检测算法的先驱,该算法先提取候选区域,再使用卷积神经网络和SVM分类器进行分类预测。在此基础上,科研人员相继提出Fast R-CNN[2]、Faster R-CNN[3]、Mask R-CNN[4]等更高效的两阶段检测算法,但囿于其特点,两阶段算法很难达到实时检测的要求。另一类目标检测算法为YOLO(you only look once)系列,YOLO算法由Redmon等[5]提出,该算法创新性地将检测视为回归问题,使用预设锚框的方式代替候选区域选取。此后,YOLO9000[6]、YOLOv3[7]、YOLOv4[8]等YOLO的算法以及SSD(single shot multibox detector)[9]算法相继被提出,在精度和速度方面的表现也越来越优秀。
国内外学者针对交通标志的检测探索出不同的研究方案。Sudha等[10]通过使用新的随机梯度动量序列和形状特征提取方法进行检测,然后使用卷积神经网络(CNN)分类器对训练输出标签进行分类,最后在训练与测试阶段将交通标志转换为音频信号,帮助视障人士解决问题。Han等[11]提出一种针对小目标交通标志检测的Faster R-CNN,首先使用小的区域候选网络(region proposal network, RPN)提取建议框,然后将Faster R-CNN与在线硬示例挖掘(online hard example mining, OHEM)算法相结合来提高定位小目标的能力。Wan等[12]使用改进的YOLOv3进行模型剪枝和多尺度预测,在减小模型参数量的同时提高检测速度,但是在实时检测时性能不高。尹靖涵等[13]使用改进YOLOv5对雾霾场景下的交通标志进行识别,运用削减特征金字塔深度、限制最高下采样倍数、调整残差模块的特征传递深度等方法提升检测精度。张毅等[14]在Faster R-CNN算法的基础上进行改进,提出了一种多尺度卷积核的ResNeXt模型,使用多维特征融合的方法,在TT100K数据集上取得了90.83%的平均精度,但是算法的实时性无法保证。李宇琼等[15]基于YOLOv5算法,增加卷积块注意力机制,使用DIoU损失函数提升模型检测性能,改进后模型精度更高,但同时检测速度下降。郭继峰等[16]将深度可分离卷积应用于YOLOv4-tiny的特征提取网络中,使用BiFPN融合多尺度特征,在TT100K数据集上获得87.5%的准确率,但模型参数量依然较大。
综上所述,由于交通标志检测的实时性要求较高,而目前模型无法同时满足检测速度快并且检测精度高的要求,因此,为了在提高模型检测速度的同时不损失检测精度,并降低模型的参数量和计算量,本文提出一种轻量化的YOLOv5算法用于交通标志检测。使用本文构建的GhostBottleneck替换主干网络中的Bottleneck,并融合到主干网络(Backbone)和颈部网络(Neck)中,利用Ghost卷积减少计算量和参数量;为了维持模型检测精度,本文使用双向加权特征金字塔网络(bidirectional feature pyramid network, BiFPN)替换PANet结构,提升网络特征学习能力;将CIoU损失函数替换为SIoU损失函数,优化定位损失,提高算法精度。
1 YOLOv5模型
YOLOv5是首款使用Pytorch框架编写的YOLO系列算法,适合在生产环境中使用,更容易部署,模型参数更少。目前YOLOv5系列仍在继续优化改进,不断更新迭代新的版本,本文以6.1版本的YOLOv5s为基础进行实验和改进。
该版本的YOLOv5模型可以分为输入端、主干网络、颈部网络及检测端4个部分。数据首先在输入端经过马赛克数据增强,丰富了数据的多样性,提高训练效率。主干网络使用C3模块,即简化版的BottleneckCSP,大幅减少参数量。颈部网络借鉴PANet网络[17],采用FPN+PAN结构,FPN结构通过将深层的语义特征传到浅层,增强多个尺度上的语义信息。PAN结构则相反把浅层的定位信息传导到深层,增强多个尺度上的定位能力。Neck部分还增加了快速空间金字塔池化(spatial pyramid pooling fast, SPPF)模块,SPPF使用3个5×5的最大池化代替SPP的5×5、9×9、13×13最大池化操作,为此达到使用小卷积核大幅提升计算速度的目的。检测端含有3个并行的卷积层,当输入图片大小为640×640×3时,3个卷积层的输出分别为80×80×255,40×40×255,20×20×255。YOLOv5的网络结构如图1所示。

图1 YOLOv5结构
2 改进的YOLOv5模型
2.1 骨干网络GhostBottleneck
Ghost模块是Han等[18]在2020年提出的一种轻量级特征提取模块,使用更少的参数量生成特征图。Ghost模块的基本结构是Ghost卷积,普通卷积与Ghost卷积结构如图2所示。
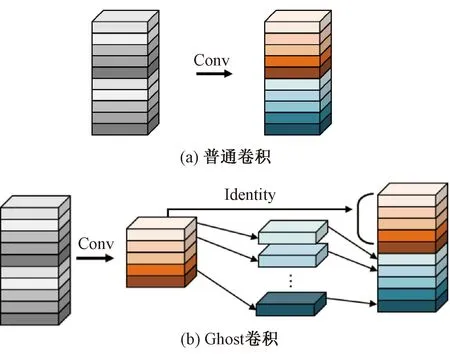
图2 普通卷积与Ghost卷积
由图2可以看出,Ghost卷积首先对原始图片经过一次小计算量的普通卷积操作,得到本征特征图;然后对本征图中的m个通道的基础特征使用低成本的线性运算,即卷积核大小为d×d的深度卷积,得到m个新的相似特征图;最后将本征特征图和m个相似特征拼接,得到最终的特征图。
普通卷积的计算量可表示为
n×h′×w′×c×k×k。
(1)
式中:n表示特征图个数;h′和w′分别表示输出图片的高度和宽度;c表示输入图片通道数;k表示标准卷积核大小。
Ghost卷积操作的计算量可以表示为
(2)
式中:s表示本征图参与线性变换的数量;d表示深度可分离卷积的卷积核大小。
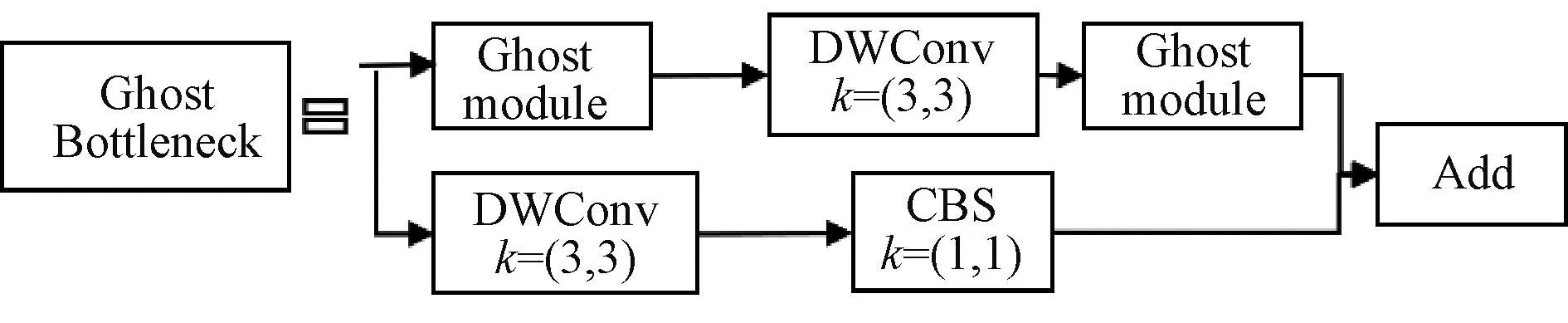
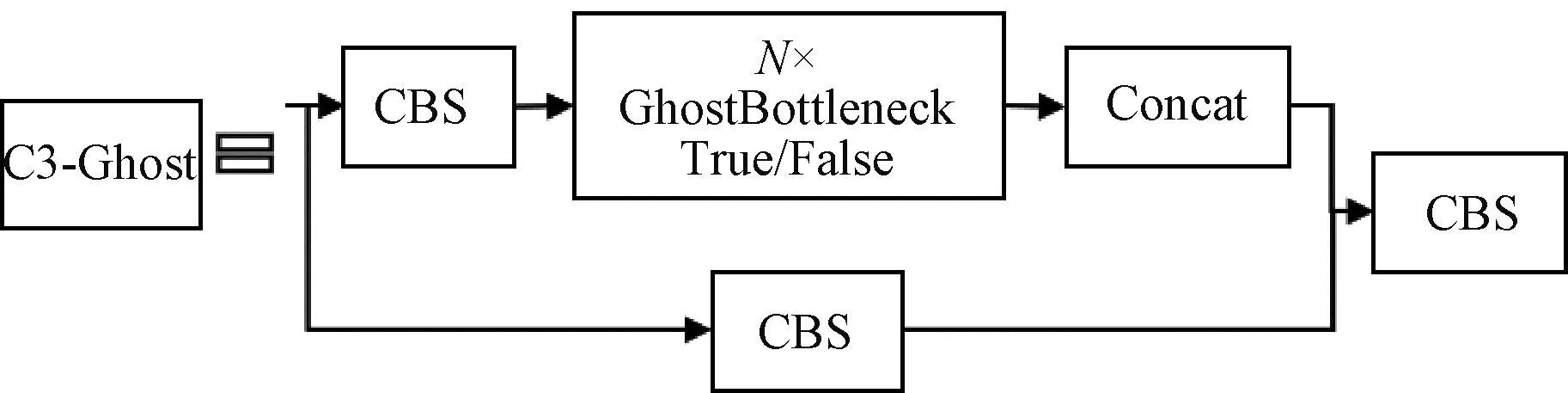
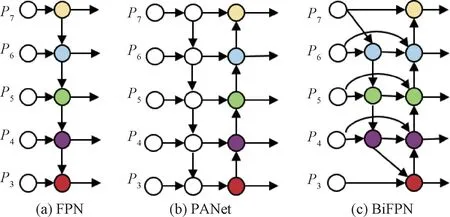
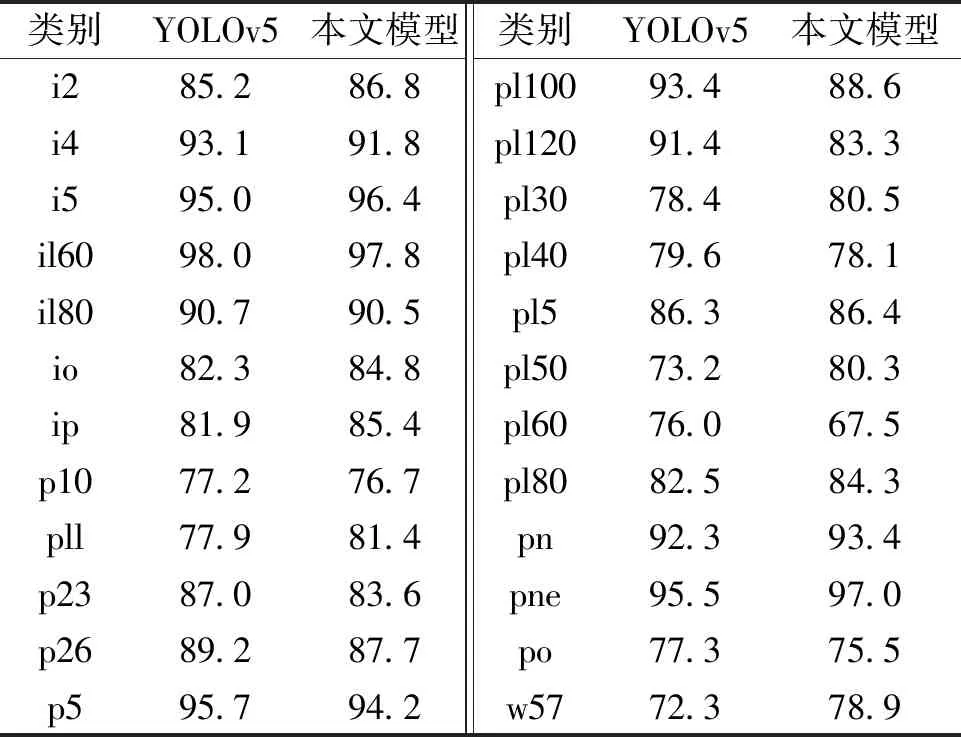
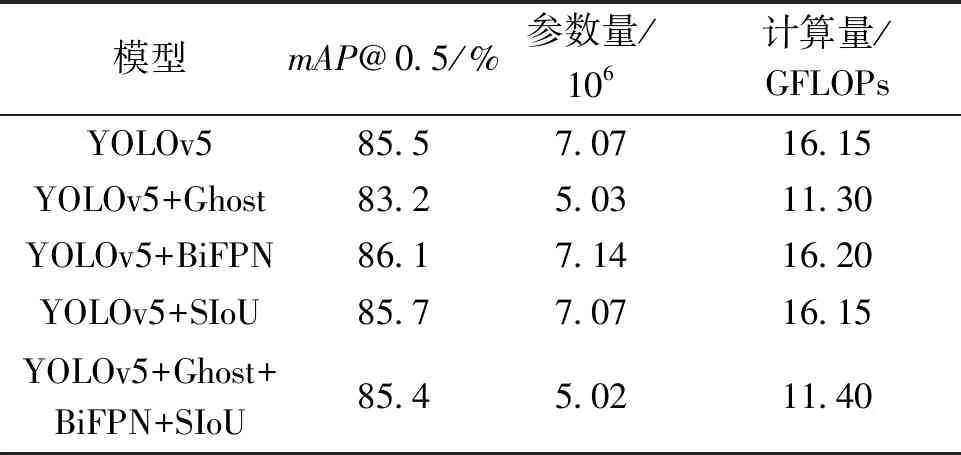
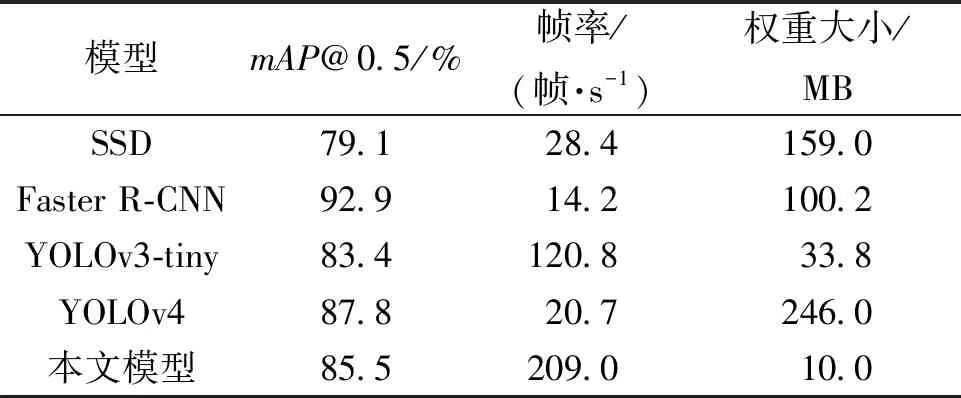
因为d×d的卷积核与k×k的卷积核大小相似,且s< 普通卷积的参数量可以表示为 n×c×k×k。 (3) Ghost卷积的参数量可以表示为 (4) 同理,普通卷积与Ghost卷积的比值rc≈c,证明Ghost卷积比普通卷积也能在参数量上得到削减。 GhostBottleneck模块就是以Ghost模块为基础构建的一款骨干网络,Han等[18]给出了2种骨干网络,如图3所示。步长为1(图3(a))与步长为2(图3(b))都采用残差结构,且图3(b)在Ghost模块中间多了1个深度卷积,并且残差路径由1个下采样层和1个步长为2的深度卷积实现。 图3 GhostBottleneck模块 本文中采用步长为2的GhostBottleneck结构替换YOLOv5主干网络中的C3结构的Bottleneck,从而达到进一步降低计算量和参数量的目的,如图4所示,图4中的CBS模块指的是卷积+批量归一化+SiLU激活函数。 图4 本文使用的GhostBottleneck 基于GhostBottleneck构建的C3-Ghost结构如图5所示,用该结构替换YOLOv5网络中除第1个C3外的其他C3模块。 图5 基于C3构建的C3-Ghost模块 由于使用Ghost卷积降低参数量和计算量的同时也造成了检测精度下降,因此选择将BiFPN引入YOLOv5的Neck网络部分,构建Concat操作替换普通Concat层,通过可学习权重进一步增强网络特征融合能力。 BiFPN[19]是谷歌大脑提出的一种加权双向特征金字塔网络,由于特征金字塔网络(feature pyramid network, FPN)仅通过一条自顶向下的路径传递特征,可能会遇到特征信息丢失的情况,精度不高,结构如图6(a)所示。PANet是在上述网络的基础上增加一条相反的路径,用于传达丢失的位置信息,如图6(b)所示。BiFPN则是在PANet的基础上删除只有一个输入的节点,在不丢失重要信息的前提下简化网络,同时若输入节点和输出节点位于同一层则添加一条额外的边,以融合更多特征,其结构如图6(c)所示。更重要的是,BiFPN提出使用带权重的特征融合机制,给每条路径分配一个可学习的权重,通过对数据特征的学习不断更新权重,从而获取更重要的信息。以中间层P6层为例,其最终输出可以表示为 (5) 图6 FPN、PANet与BiFPN结构 (6) YOLOv5的损失函数包含3个部分,分别为定位损失box_loss、置信度损失obj_loss及分类损失cls_loss。定位损失用于计算预测框与真实框的误差;置信度损失用于计算网络的置信度;分类损失用于计算锚框与对应的标定分类是否正确。 针对定位损失,Gevorgyan[20]认为应该进一步考虑预测框与真实框的角度信息,从而提出了新的损失函数SIoU损失函数,该损失函数由预测框与真实框的角度、距离和形状以及传统IoU 4部分损失组成,其中角度损失可以表示为 (7) (8) (9) 距离损失可以表示为 (10) 形状损失可以表示为 (11) 最后一项为传统的交并比损失,因此SIoU损失函数的最终损失可以表示为 (12) 因此,为了提高因Ghost卷积丢失的检测精度,本文选择将用SIoU损失代替CIoU损失,更加关注真实框与预测框之间的角度位置信息,提高锚框精度。 改进后的轻量化YOLOv5模型如图7所示,使用C3-Ghost替换原始YOLOv5中的C3模块,在颈部网络引入BiFPN结构,以及使用SIoU损失函数。 图7 轻量化YOLOv5结构 改进后模型的算法流程如下。 步骤1 图片经过输入层的处理,计算预设锚框与真实锚框的差值并聚类得到新的一组预设锚框。 步骤2 将图片送入新的主干网络,利用加入Ghost卷积的模块和卷积层提取特征。 步骤3 图片经过在颈部网络设计的BiFPN结构增加短接和跳跃连接,加强特征融合能力。 步骤4 图片到达输出层,通过使用SIoU计算真实框与预测框之间的误差,降低定位损失。 目前开源的和针对中国实际道路的交通标志数据集有CCTSDB,以及腾讯和清华大学使用街景图像构建的TT100K[21]数据集等。CCTSDB数据集仅仅将数据分为指示、警告和禁止标志3类,没有详细内容的区分。而TT100K数据集对实地采集且有详细分类,因此选择TT100K数据集作为本次实验的数据集。 TT100K数据集一共包括了上百个交通标志类别,但大多数标志实例个数较少。数据集分布不均衡,有些实例的个数在3 000以上,有些实例数量仅为个位数,并且包含上百个种类,因此需要先对数据集进行筛选,将得到的交通标志实例个数在200个以上的类别进行实验,避免由于数据集的缺陷无法得到最优模型。以下为预处理步骤。 步骤1 读取json标注文件,遍历标注信息,保存实例个数大于等于200的标签。 步骤2 对原始json标注文件中的标注信息按照训练集与验证集为8比2的比例划分为2个json文件。 步骤3 将划分好的json格式标注信息转换成YOLOv5训练需要的TXT格式进行保存。 步骤4 根据划分好的标注文件将原始图片分开存放。 经过上述步骤后得到24个常见交通标志类别,共8 521张图片,其中训练集6 801张,验证集1 720张,具体类别如图8所示。 图8 24个交通标志类别 准确率P指预测正确的正样本数量占所有预测为正样本数量的百分比;召回率R指预测正确的正样本占所有正样本的比值;平均精确率AP表示PR曲线与坐标轴所围成的图形面积;mAP@0.5表示在IoU阈值为0.5时所有类别AP的平均值;mAP@0.5∶0.95表示不同IoU阈值(从0.5到0.95,步长0.05)上的平均mAP;参数量用来衡量模型大小,参数量和计算量越小说明模型越轻量;帧率表示每秒刷新的图片数,可以用来评估模型在检测时的效率。 本次实验使用的硬件平台GPU为NVIDIA RTX3090,显存24 GB,CPU为Intel(R) Xeon(R) Platinum 8350C@2.60 GHz,内存45 GB。系统环境为Linux,CUDA版本11.1,Pytorch版本1.8.1,Python版本3.8,batch-size设置为16,进行200个epoch迭代。超参设置为系统默认,即初始学习率设置为0.01,使用SGD优化器,初始动量设置为0.937,权重衰减系数设置为0.000 5。 训练过程如图9所示,由图9可以看出,改进后的YOLOv5大概在130个轮次之后达到峰值并趋于稳定,而原始YOLOv5则在160个轮次之后才趋于稳定状态,并且改进后的YOLOv5训练过程更平稳,极少出现大幅度变化过程,说明改进后的YOLOv5具有更良好的性能。 图9 训练过程曲线 经过实验分析,原始YOLOv5模型与改进后的YOLOv5模型在TT100K数据集上的结果对比如表1所示。 表1 改进后的YOLOv5模型与原始YOLOv5模型在TT100K数据集上的结果对比 由表1可以看出,改进后的YOLOv5模型的P下降了0.8百分点,R提高了2.8百分点,在参数量减少29%、计算量减少29.4%的情况下,mAP@0.5仅减少了0.1百分点,mAP@0.5∶0.95仅减少了1.0百分点,但检测的速率提升了34帧。达到了几乎不损失精确率的前提下,简化YOLOv5网络的目的。 其中每个类别的AP值如表2所示,由表2可以看出,有50%的标签在改进后网络中的平均精确率高于原始网络,说明尽管参数量和计算量有所下降,但是由于BiFPN结构和SIoU损失的加入,也使得某些特征的学习能力得到加强。 表2 每个类别AP值 为了进一步研究各个模块对网络的影响,本文设置了消融实验证明改进后网络的各模块带来的影响,具体数据如表3所示。 表3 消融实验 由表3可以看出,单独增加Ghost模块后,整体参数量和计算量都会大幅减少,但同时也会导致mAP@0.5降低2.3百分点;单独增加BiFPN结构会在稍微提高参数量和计算量的同时提高0.6百分点的mAP@0.5;单独增加SIoU损失函数则不会对参数量和计算量有所影响,却能带来0.2百分点的mAP@0.5提升。当3种改进同时添加到YOLOv5模型之后,在参数量降低29.0%、计算量降低29.4%的同时仅仅牺牲0.1百分点mAP@0.5。所以该改进方法是可行的。 本文使用SSD模型、Faster R-CNN模型、YOLOv3-tiny模型、YOLOv4模型以及本文提出的模型进行对比,实验结果如表4所示。 表4 5种算法性能对比 由表4可知,相比其他几项传统的目标检测算法,本文提出的轻量化模型在保持较高的检测精度的基础上,检测速度最快、权重最小。 为了验证轻量化模型在推理过程中的优势,本文设计了推理过程实验,考虑到现实使用时很少拥有高性能GPU资源,因此推理过程使用中等偏下配置的平台。推理所使用的GPU为GeForce 1660super,CPU为Intel I5-10400,软件环境与训练一致。使用原始YOLOv5与轻量化模型进行对比,以模型大小和推理时间作为评价指标,实验结果如表5所示。 表5 推理实验 由表5可知,在推理实验中,本文提出的轻量化模型在使用GPU推理时间相比原始模型减少了7.7 ms,使用CPU推理时间减少了57.1 ms。实验证明改进后的轻量化模型在GPU和CPU上的推理时间均有所降低。 图10为使用改进前后模型检测不同图片的结果。图10(a)、10(b)是有多个目标的图片检测结果对比,可以看出除了“限低速60”的检测精度下降之外,其标志的检测结果均有不同幅度的提升;而“限低速100”两次都没被检测出来是因为本次训练集中未包含该标签。图10(c)、10(d)则是只包含单个检测目标的图片检测结果对比,图10(c)发现有误检结果,将远处一个医院的红十字错误检测成“限速50”的标志,经改进后的网络检测结果如图10(d)所示,并没有误检现象出现,且“禁止掉头”的检测精度有略微提升。 图10 改进前后检测结果 改进后的YOLOv5在参数量降低29.0%、计算量降低29.4%的情况下,mAP@0.5仅下降了0.1百分点,同时检测帧率提升了34帧/s,取得较好的效果。 (1)使用参数量大幅减少的Ghost卷积和深度可分离卷积构建GhostBottleneck,替换主干网络和颈部中的部分Bottleneck,简化网络参数和计算量。 (2)使用BiFPN替换原始的PANet结构,增强特征融合能力,提高检测准确率。 (3)将原始CIoU损失替换成更关注预测框与真实框角度位置的SIoU损失,优化损失函数,提升检测精度。 下一步将考虑在进一步降低参数量和计算量的基础上提高检测精度,加入注意力机制等改进方案,使模型能够部署到移动设备进行实际运用。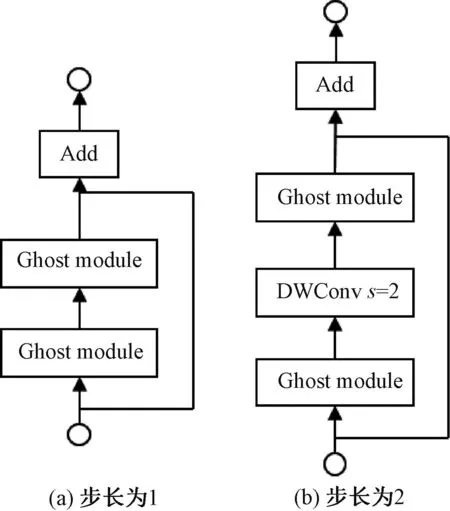
2.2 加权特征融合网络BiFPN


2.3 SIoU损失函数
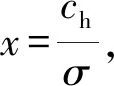
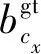

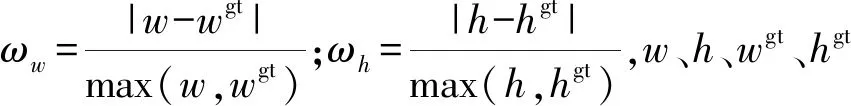
2.4 改进后模型

3 实验与结果分析
3.1 数据集预处理

3.2 评价指标
3.3 实验平台
3.4 实验结果及分析




4 结论
猜你喜欢
东方少年·布老虎画刊(2023年12期)2024-01-01
汽车实用技术(2022年9期)2022-05-20
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2016年8期)2016-05-14
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
