
轻量化改进XYZNet的RGB-D特征提取网络
2024-03-05 02:54于建均刘耕源于乃功龚道雄冯新悦
计算机应用研究 2024年2期
于建均 刘耕源 于乃功 龚道雄 冯新悦
收稿日期:2023-06-01;修回日期:2023-08-02 基金項目:国家自然科学基金资助项目(62076014);北京市教育委员会科技计划重点资助项目(KZ202010005004)
作者简介:于建均(1965—),女(通信作者),北京人,副教授,硕导,主要研究方向为智能机器人的仿生自主控制、智能计算与智能优化控制(yujianjun@bjut.edu.cn);刘耕源(1999—),男,江西吉安人,硕士,主要研究方向为图像处理、位姿估计;于乃功(1966—),男,山东潍坊人,教授,硕导,主要研究方向为计算智能、智能系统;龚道雄(1968—),男,湖南永顺人,教授,硕导,主要研究方向为人形机器人、遥操作机器人;冯新悦(1999—),女,河北唐山人,硕士,主要研究方向为图像处理、机械臂操作.
摘 要:
针对用于位姿估计的RGB-D特征提取网络规模过于庞大的问题,提出一种轻量化改进XYZNet的RGB-D特征提取网络。首先设计一种轻量级子网络BaseNet以替换XYZNet中的ResNet18,使得网络规模显著下降的同时获得更强大的性能;然后基于深度可分离卷积设计一种多尺度卷积注意力子模块Rep-MSCA(re-parameterized multi-scale convolutional attention),加强BaseNet提取不同尺度上下文信息的能力,并约束模型的参数量;最后,为了以较小的参数代价提升XYZNet中PointNet的几何特征提取能力,设计一种残差多层感知器模块Rep-ResP(re-parameterized residual multi-layer perceptron)。改进后的网络浮点计算量与参数量分别降低了60.8%和64.8%,推理速度加快了21.2%,在主流数据集LineMOD与YCB-Video上分别取得了0.5%与0.6%的精度提升。改进后的网络更适宜在硬件资源紧张的场景下部署。
关键词:图像处理;位姿估计;RGB-D;特征提取;轻量级
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)02-045-0616-07doi: 10.19734/j.issn.1001-3695.2023.06.0322
RGB-D feature extraction network based on lightweight improved XYZNet
Yu Jianjun, Liu Gengyuan, Yu Naigong, Gong Daoxiong, Feng Xinyue
(Faculty of Information Technology, Beijing University of Technology, Beijing 100124, China)
Abstract:
According to the problem of the current RGB-D feature extraction network used for pose estimation is too large, this paper proposed a lightweight improved XYZNet RGB-D feature extraction network. Firstly, this paper designed a lightweight sub-network BaseNet to replace ResNet18 in XYZNet, which made the network scale significantly reduced and obtained more powerful performance. Then, this paper proposed a re-parameterized multi-scale convolutional attention (Rep-MSCA) sub-module based on depth separable convolution, which enhanced the ability of BaseNet to extract contextual information of different scales, and constrained the amount of parameters in the model. Finally, in order to improve the geometric feature extraction ability of PointNet in XYZNet with a small parameter cost, this paper designed a re-parameterized residual multi-layer perceptron (Rep-ResP) module. The floating point operations (FLOPs) and parameters of the improved network are 60.8% and 64.8% lower, the inference speed is 21.2% higher, and the accuracy of the mainstream datasets LineMOD and YCB-Video is 0.5% and 0.6% higher. The proposed model is more suitable for deployment in scenarios where hardware resources are tight.
Key words:image processing; pose estimation; RGB-D; feature extraction; lightweight
0 引言
6D位姿估计是指识别目标物体的三维旋转姿态与三维空间位置,是机械臂抓取、增强现实以及自动驾驶等应用的重要前提[1]。作为位姿估计算法中的关键部分,特征提取网络捕获位姿特征的能力往往直接决定了整个位姿估计算法的性能[2]。
特征提取网络根据所处理数据的类型可分为基于RGB、基于点云与基于RGB-D三种。基于RGB的特征提取网络主要提取物体的纹理特征等局部信息,包括VGG[3]、GoogLeNet[4]与ResNet[5]等,该类网络在面对弱纹理物体时往往精度较差。基于点云的特征提取网络则提取物体的几何形状特征等全局信息,包括PointNet[6]与PointNet++[7]等,该类网络在处理受遮挡严重的物体时难以取得较好的表现。基于RGB-D的特征提取网络由于能够捕捉到相较于前两者更加丰富的特征信息,所以在面对弱纹理与遮挡严重的物体时更具鲁棒性。
DenseFusion[8]中将处理RGB图像的卷积神经网络CNN与处理点云信息的PointNet并行排列,组成能够同时提取RGB与深度信息的异构特征提取网络。PVN3D[9]中将CNN与PointNet++[7]并联形成异构结构,并在结尾设计一个特征融合模块,根据索引来获得每个点的融合特征。FFB6D[10]中采用一种全流双向融合网络,将融合应用于编码器与解码器的每一层。然而,这些网络为了能同时处理RGB与点云信息两种不同的数据,往往构建了复杂的并行异构网络。这种设计虽然能够取得较高的精度,但也造成了庞大的模型计算量与参数量。对于算力与存储资源较为紧张的工业设备而言,这样的缺陷一定程度上降低了其算法的实用性。ES6D[2]将点云信息以XYZ map的形式与RGB图像进行前向融合,并输入到由改进后的ResNet与PointNet串联而成的纯卷积特征提取网络XYZNet。尽管该算法采用更高效的串联方法,从而避免了并行网络的复杂性,但其参数量与计算量仍然有优化的空间。因此,迫切需要一种轻量级的RGB-D特征提取网络。
为了解决上述问题,本文从降低模型参数量与计算量的角度出发,提出一种轻量化改进XYZNet的RGB-D特征提取网络。首先设计了轻量级子网络BaseNet,在显著降低模型规模的同时,构建了包含丰富形状与语义信息的表征;然后基于深度可分离卷积设计一种可重参数化的多尺度卷积注意力子模块,以加强BaseNet提取多尺度上下文的能力;最后提出一种可重参数化的残差多层感知器模块,并加入到XYZNet的PointNet中,以极小的参数代价加强其提取几何特征的能力。实验结果表明,该网络在具有低运算成本的同时,保持了较高的估计精度,为硬件资源受限的工业设备进行位姿估计提供了新的解决方案。
1 相关工作
1.1 大尺寸卷积核
近年来,大尺寸卷积核开始被广泛应用于CNN中。研究表明,相较于3×3卷积核而言,大尺寸卷积核对形状特征的提取能力更加优秀,并且能获取更大的感受野[11]。例如ConvNeXt[12]将7×7的卷积核转换为深度可分离卷积的形式,并添加到CNN中,在获得比肩基于视觉Transformer[13]架构性能的同时,又缓解了大尺寸卷积核所带来的参数量增长。visual attention network [14]通过将21×21的卷积核分解成深度卷积、深度扩张卷积与逐点卷积的方式,建立了一种捕获长距离依赖的注意力机制。SLaK[15]则将两个条形卷积核进行并联,从而等效成一个51×51的超大尺寸卷积核,同样取得了较高的精度。然而,由于以上算法仅采用了单一尺寸的大卷积核,忽略了对多尺度上下文信息的提取与融合,而这在视觉算法中十分重要[16]。
1.2 结构重参数化
重参数化是指利用卷积核的线性可加性等概念,将训练完毕后较为复杂的网络结构等价转换为另一组更简洁的结构,从而在保证检测精度不变的条件下降低网络推理时的运算代价[17]。Arora等人[18]通过研究证明,随着网络深度的不断增加,重参数化可加速全连接层的训练。DiracNet[19]利用重参数化技术训练一个普通的卷积神经网络,其性能与残差网络ResNet相当。RepVGG[20]将由3×3卷积核、1×1卷积核与恒等映射组成的多分支结构重参数化为仅有3×3卷积核的直筒型结构,从而实现了一种兼顾低计算成本、高速度与高精度的骨干网络。但是,目前主流的重参数化结构仅针对处理RGB图像等单模态信息,缺乏能够处理RGB-D多模态信息的重参数化结构。
2 改进的轻量级特征提取网络
2.1 XYZNet的基本结构
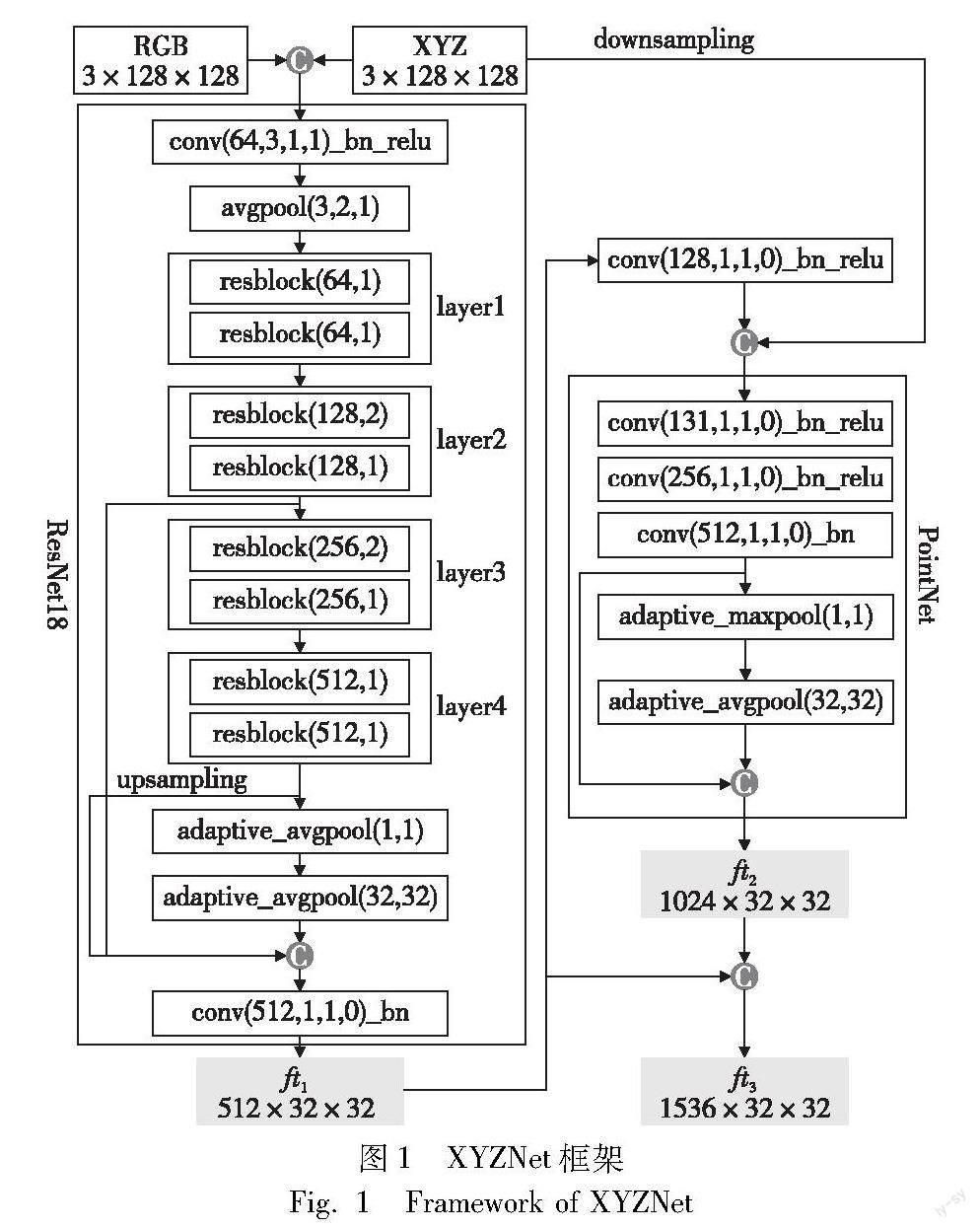
XYZNet的框架如图1所示[2],该网络主要由改进的ResNet18[5]与PointNet两部分构成。其中,ResNet18用于学习局部特征,通过不同的卷积核与下采样率来扩大感受野,并在输出部分将不同感受野的特征串联;PointNet的主要功能是提取融合了颜色信息的几何特征,通过将ResNet18输出的局部特征和由点云信息轉换而成的XYZ-map连接起来,以恢复局部特征的空间结构,并利用1×1的卷积核对局部特征与每个点的坐标进行编码,最后通过池化操作获得全局特征[2]。在网络的最后,将局部特征与全局特征拼接起来,作为逐点特征输出到下游网络。
尽管该网络在精度与模型大小之间取得了较好的平衡,但由于ResNet18本身的网络规模较大,使得XYZNet的参数量与计算量距离轻量级网络仍有一定的差距。所以,当面对存储与算力资源紧张的嵌入式平台等工业设备时,该算法会难以应用。另外,PointNet提取几何特征的能力较弱,需要对其进行改进,以加强其对几何信息的学习能力。
2.2 轻量级子网络BaseNet
为了降低XYZNet的参数量,本文设计了一种轻量级子网络BaseNet,替换掉XYZNet中参数庞大的ResNet18,其由基于CSP(cross stage partial)结构改进的多尺寸卷积注意力网络MSCAN(multi-scale convolutional attention network)与高效层聚合网络ELAN(efficient layer aggregation networks)两种轻量级模块组成,如图2所示。SegNeXt[16]中的MSCAN模块在具有良好特征提取能力的同时保持了较低的参数量。为了进一步压缩MSCAN模块的参数规模,本文采用CSP结构对MSCAN模块进行轻量化处理,设计了一种CSP-MSCAN模块。本文还在该模块中设计了一个基于深度可分离卷积的多尺度卷积注意力子模块Rep-MSCA,通过捕获多尺度上下文信息来提升网络的性能。另外,本文还引入了轻量级网络YOLOv7[21]中的ELAN模块,该模块在拥有轻量化特点的同时具有良好的特征提取能力。
网络的深层特征中具有高度抽象的语义信息,但分辨率较低,对位置与形状的感知能力较差,而浅层特征的分辨率更高,包含更丰富的形状、细节、位置信息。在对目标物体的空间位置与旋转姿态进行估计时,形状与位置信息具有十分关键的作用。本文将CSP-MSCAN模块设置到位于BaseNet子网络浅层的stage1與stage2上,因为该模块中的大尺寸卷积核能够捕获较大感受野,这有利于模块学习到更丰富的形状与位置信息。将ELAN模块设置到位于BaseNet子网络深层的stage3与stage4上,以利用其中的小卷积核提取网络深层中高度抽象的语义信息。在子网络末端,通过Concat级联操作使CSP-MSCAN模块的浅层特征与ELAN模块的深层特征相互融合,从而构建具有丰富语义信息的特征表示,更有利于对物体位姿的估计[22,23]。
2.2.1 CSP-MSCAN模块
本文基于CSP结构对MSCAN模块进行轻量化改进后的CSP-MSCAN如图3所示。CSP-MSCAN模块一边通过包含1×1卷积核、归一化层BN(batchnorm)与激活层的子模块CBS(conv batchnorm Silu)进行通道收缩,然后由MSCAN模块进行多尺度注意力特征计算,接着与另一边经由通道收缩的输入数据进行级联,从而获取更加丰富的特征信息,最后再由CBS子模块扩张至原先输入数据的通道数并对特征进行拟合。这种轻量化改进使MSCAN模块的通道数下降至原先的一半,从而显著降低了MSCAN模块自身的参数量。尽管改进后的CSP-MSCAN模块增加了3个CBS子模块,但该参数增量的规模远小于MSCAN模块,因此本文的改进仍能明显压缩网络参数量。
在MSCAN模块中,首先采用1×1卷积核学习输入通道的线性组合,其次将Rep-MSCA子模块捕获到的多尺度上下文信息送入1×1卷积核进行拟合,然后对特征信息进行通道扩张,并利用3×3大小的卷积核进行局部特征的编码,最后将其降维至原通道数。为了避免网络退化,MSCAN中增加了两条残差连接。另外,本文仅通过堆叠MSCAN模块中的核心结构Rep-MSCA来加深网络,从而获取更深层次的语义信息。与主流算法通过堆叠整个模块来加深网络的方法相比[12~16],本文方法避免了网络参数量成倍数地增长,因而使网络实现轻量化。
1)基于深度可分离卷积的Rep-MSCA子模块
由于一个场景中可能有多个不同大小的目标物体需要进行位姿估计,对于体积较小的目标仅需要用小尺寸卷积核所提取到的局部特征便可估计它的位姿;而对于体积较大的目标,就需要利用能捕获更大感受野的大卷积核所提取到的全局特征来对它进行位姿估计。所以,对于复杂场景下的位姿估计需要多尺寸的卷积核来获取不同尺度的上下文信息。
作为一种可分解的卷积结构,深度可分离卷积能将标准卷积分解成深度卷积与逐点卷积。在计算时首先通过深度卷积分别对每个输入特征的通道进行卷积计算,接着利用逐点卷积对深度卷积的输出进行拟合。
假设输入与输出特征通道数为Cin与Cout,特征图大小均为Df×Df,卷积核尺寸为Dk×Dk,则深度可分离卷积与普通卷积的计算量l1、l2为
l1=Cin(∑ni=1Df×Df×Dkt×Dkt+n×Df×Df×Cout)(1)
l2=Df×Df×Cin×Cout×Dk×Dk(2)
其中:Dkt为第t个卷积核的尺寸;n为卷积核的个数。
深度可分离卷积与普通卷积的计算量之比为
l1l2=Cin(∑ni=1Df×Df×Dkt×Dkt+n×Df×Df×Cout)Df×Df×Cin×Cout×Dk×Dk=
∑ni=1Dkt×DktCout×Dk×Dk+nDk×Dk(3)
本文基于多尺寸的深度可分离卷积设计了一种可重参数化的多尺度卷积注意力子模块。如图4所示,本文利用3×3、5×5、7×7与9×9的卷积核进行互相组合,其中小尺寸卷积核对局部特征更敏感,大尺寸卷积核能通过长距离建模捕获更大的感受野。由式(3)可知,当使用5×5、7×7与9×9的多尺寸深度可分离卷积时,假设输入输出通道为64,则计算量仅为一个5×5普通卷积的0.217倍。因此相较于采用单一尺寸的普通卷积,本文的多尺寸深度可分离卷积不仅可以大幅压缩模型规模,还能使网络捕获到多尺度的上下文信息,从而强化模型的特征提取能力[24]。
Rep-MSCA首先使用大小为3的深度卷积来提取局部特征,然后通过由大小为5、7和9的卷积核以及恒等映射所组成的多尺寸深度可分离卷积来提取多尺度上下文,并使用相加操作融合四个分支的特征信息,接着采用大小为1的普通卷积核拟合多尺度信息,最后将其输出作为多尺度注意力权重,对Rep-MSCA进行重新加权。Rep-MSCA对输入数据的计算过程如下:
Fout=DWConv3×3(Fin)(4)
Att=Conv1×1[∑i=5,7,9DWConvi×i(Fout)+Fout](5)
Mout=AttFin(6)
其中:Fin为输入特征;Fout、Att、Mout分别为3×3深度可分离卷积、多尺度深度可分离卷积以及Rep-MSCA子模块的输出特征;DWConv分别为3×3、5×5、7×7以及9×9的多尺寸深度可分离卷积;Conv1×1表示大小為1的普通卷积。
2)Rep-MSCA子模块的结构重参数化
本文通过对Rep-MSCA中的多尺寸深度可分离卷积进行重参数化,可将其多分支结构等价转换为直筒结构。这种方法通过简化结构,显著降低了模型在推理阶段的参数量,使得Rep-MSCA更加轻量化。由于只有尺寸相同的卷积才能进行重参数化的融合,所以本文的重参数化分为两个步骤进行,如图5所示。
第一步为统一多尺寸卷积大小,即通过Padding填充操作将不同大小的卷积核以及恒等映射转换成统一尺寸的卷积核。本文将5×5卷积核转换成Padding为2的9×9卷积核,同理7×7卷积核转换为Padding为1的9×9卷积核,9×9卷积核则保持尺寸不变。对于恒等映射,将其转换为左对角线卷积核中心为1,其余位置卷积核均为0的9×9卷积核[20]。
第二步为卷积融合,即通过加法操作将尺寸一致的多个卷积核融合为单一卷积核。本文将四个分支上卷积核的权重ki×i(i=5,7,9)和kidentity与偏差bi×i(i=5,7,9)和bidentity(恒等映射分支的偏差bidentity视为0)分别进行相加操作,并将权重和ksum与偏差和bsum作为9×9等效卷积核的系数。该9×9卷积核即为重参数化后的卷积,其在推理阶段等效于原网络的多分支卷积。第二步的计算过程如下:
ksum=∑3i=0kScale i=k5×5+k7×7+k9×9+kidentity(7)
bsum=∑3i=0bScale i=b5×5+b7×7+b9×9+bidentity(8)
其中:kScale i、bScale i分别为四个分支卷积核的权重与偏差。
2.2.2 ELAN模块
ELAN的结构如图6所示。该模块一边通过包含1×1卷积核的CBS子模块M2对输入数据Fin进行通道收缩为F2;然后由4个包含3×3卷积核的CBS子模块M3~M6采集局部特征,并采用多个短路连接来输出不同尺度的信息,包括F2、F3以及F4;接着将多尺度信息与另一边经由通道收缩的F1进行级联,并由CBS子模块M7来拟合多尺度特征,输出Fout为最终的特征信息[21]。ELAN模块一方面通过收缩通道数来降低参数量,另一方面通过多个残差连接提取丰富的特征信息,从而达到良好的性能。
2.3 基于Rep-ResP模块的PointNet改进
XYZNet中的PointNet仅由两层1×1卷积与两个池化层组合而成,其较浅的网络层数使得PointNet无法提取更深层次的特征信息,从而限制了网络性能。不同于主流算法为了提升精度,设计复杂且精细的特征提取模块[25,26],本文基于Residual Point模块[27]设计了一种结构简单的可重参数化残差多层感知器Rep-ResP模块,如图7所示。一方面,该模块通过加深XYZNet中PointNet的网络深度以强化其特征提取能力;另一方面,该模块结构简单的特性使得其参数量较低,从而保持了整个改进XYZNet的轻量化特点[28]。
2.3.1 Rep-ResP模块
Rep-ResP由大小为1的卷积核,BN层与激活层依次串行两次而成。为了解决网络加深后的梯度消失与网络退化问题,本文设置了跨层残差连接[10]。另外,本文在第一个激活层前添加了短路连接,通过连接不同卷积层的特征,将高层次与低层次的特征进行融合,进一步提升了特征信息的丰富度。为了降低推理时的代价,该短路连接可通过重参数化并入卷积所在的分支。
Rep-ResP对输入信息的计算过程如下:
Fout_1=ReLU{BN2(Fin)+BN1[Conv1(Fin)]}(9)
Fout_2=ReLU{BN3{Conv2[ReLU(Fout_1)]}+Fin}(10)
其中:Fin为输入信息;BNi(i=1,2,3)为BatchNorm层;Convi(i=1,2)为1×1卷积核;ReLU为非线性激活函数;Fout_1为第一个激活层的输出;Fout_2为Rep-ResP的输出。
本文将4个Rep-ResP模块加入XYZNet中的PointNet,如图7所示。该网络将经由 Rep-ResP模块处理的信息通过1×1卷积核依次进行两次通道扩张后,使其与自身池化的结果进行级联后作为PointNet的输出。
2.3.2 Rep-ResP模块的结构重参数化
图8显示了本文Rep-ResP中短路连接的重参数化过程,共分为三个步骤:
a)将短路连接分支等效为左对角线卷积核为1,其余位置卷积核均为0的1×1卷积核Conv2。
b)分别将BN1与BN2融入卷积核Conv1与Conv2中[19]。
卷积与BN层融合后的等效卷积为
Convf_i(x)=Wf_i(x)+Bf_i=BNi[Convi(x)]=
γi×Wi(x)-μivi+βi=
γi×Wi(x)vi-γi×μivi+βi i=1,2
(11)
其中:Wi(x)为原卷积的权重;μi、vi、γi、βi分别为BN层的平均值、方差、学习率因子与偏差;Wf_i(x)为等效卷积的权重;Bf_i为等效卷积的偏差。通过将γi×Wi(x)vi等效为融合卷积的权重,而-γi×μivi+β等效为融合卷积的偏差,从而完成BN层与卷积的融合。
c)由于两个分支上的卷积尺寸大小相同,将两者进行相加操作,合并为单一卷积。
Convsum(x)=∑2i=1Convf_i(x)(12)
所求出的Convsum(x)即为推理阶段的卷积。
3 实验结果及其分析
3.1 基准数据集
本文在公开的主流位姿估计数据集LineMOD和YCB-Video上进行实验。
a)LineMOD数据集:该数据集广泛应用于6D目标位姿估计的评估中。该数据集包含13个纹理缺乏的物体[29]。本文采用与DenseFusion[8]相同的实验设置来分割训练集与测试集,即将每种物体15%的RGB-D图像划分为训练集,其余为测试集。另外,本文不使用任何额外的合成数据。
b)YCB-Video数据集:该数据集共包含21个对象,92个RGB-D视频,其中每个视频显示21个对象的室内场景。本文采用与DenseFusion相同的方式,将80个视频分为训练集,并选取剩余的12个视频中的2 949个关键帧作为测试集。同时,本文还使用了DenseFusion发布的80 000张合成图像作为训练数据集,以及groud truth分割掩模作为输入[2,30]。
3.2 实验细节
本文采用PyTorch 1.10作为深度学习框架,CUDA版本为11.3,配置为Intel酷睿 i5-12600KF CPU,NVIDIA RTX 3080-12 GB GPU,所有实验均在同一电脑下进行。本文将RGB图像与XYZ map均统一调整为128×128的大小[2]。
在LineMOD数据集上,批处理大小设置为8,共训练100轮。初始学习率设置为1.65×10-4,并采用余弦退火的衰减方式,然后在第90轮时保持6.65×10-6的值不变,直至训练结束。另外在第一轮时,采用学习率线性预热策略,将学习率从1.65×10-6线性提升至1.65×10-4。
在YCB-Video数据集上,模型训练的批处理大小设置为64,共训练30轮。初始学习率设置为3.3×10-4,并采用余弦退火的衰减方式,然后在第20轮时保持1.65×10-5的值不变,直至训练结束。另外在第一轮时,将学习率从3.3×10-6线性提升至3.3×10-4。
3.3 评价指标
本文使用ADD(S)来评估6D位姿估计算法的精度。ADD(S)包含两个评价指标,分别为ADD与ADD-S。在评价非对称物体时采用ADD,在评价对称物体时则采用ADD-S。ADD指标通过计算物体真实位姿(R*,T*)與估计位姿(R,T)两种状态下,目标点云间的点对平均距离来衡量两个位姿的差距[9]。ADD的计算公式如下:
ADD=1m∑x∈O‖(R*x+t)-(Rx+t)‖(13)
其中:x为点云O的每一个点;m为点云中点的个数。然而ADD指标只能应用于具有唯一真值的非对称物体,当面对存在多个关联位姿真值的对称物体时,需要采用ADD-S这种具有对称不变性的指标来进行度量。ADD-S的计算公式为
ADD-S=1M∑X1∈Omin‖(R*x+t*)-(Rx1+t)‖(14)
为了进行综合评估,对于LineMOD数据集,本文以ADD(S)小于目标直径的10%作为判断正确估计的标准,并统计百分比精度作为算法在LineMOD上的性能指标。对于YCB-Video数据集,本文采用ADD-S与ADD(S)的AUC曲线,即在评估时通过改变距离阈值(0~10 cm)得到精度阈值曲线,并计算其与XY轴所围成的面积[2]。
3.4 对比实验
为了验证本文提出的RGB-D特征提取网络的优越性与有效性,以ES6D的6D位姿回归框架为基础,用本文网络替换ES6D原本的特征提取XYZNet,并与原始ES6D以及其他主流算法在LineMOD与YCB-Video数据集上进行对比实验。
3.4.1 LineMOD数据集实验结果
图9为ES6D与本文经过改进后的算法在LineMOD数据集上的可视化结果。LineMOD数据集仅对位于标记板中心位置的物体进行位姿估计,含颜色的点为物体3D模型上的采样点。算法进行位姿估计并将采样点投影到图像上,投影点与目标物体越契合,表明位姿估计越准确[31]。从可视化结果可以看出,本文算法的性能优于ES6D。表1列出了不同算法在LineMOD数据集上的性能对比,其中DenseFusion与PVN3D[9]是目前主流的位姿估计网络。实验结果表明,本文算法13种物体的平均精度相比ES6D提高了0.5%。另外,相较于DenseFusion(iterative)与PVN3D等其他主流算法,本文算法的平均精度分别提高了3.7%与2.9%。其中,DenseFusion(iterative)包括了迭代微调的后处理过程,而本文算法未使用任何后处理与微调。这证明了本文提取多尺度上下文信息,并充分捕获几何特征信息的方法,能够提升对弱纹理目标的估计精度。
3.4.2 YCB-Video数据集实验结果
图10为ES6D与本文算法在YCB-Video上的可视化结果。YCB-Video对场景中所有目标进行位姿估计,不同颜色的点为每个物体上的采样点,所框选的目标表示两种算法结果差异较大的物体。从可视化结果可以看出,本文算法的性能明显优于ES6D。表2列出了不同算法在YCB-Video数据集上21个物体(对称物体的名称被加粗显示)的ADD-S与ADD(S)指标的AUC值以及其平均值。可以看出,与ES6D相比,本文算法在ADD(S)上的平均精度提高了0.6%,在ADD-S上提高了0.3%。另外,与DenseFusion和PVN3D相比,本文算法在ADD(S)上分别提升了3.5%和0.9%,在ADD-S上分别提升了1.4%和0.9%。这证明了本文提取多尺度上下文信息,并充分捕获几何特征信息的方法,能够提升对受遮挡目标的估计精度。
3.5 消融实验
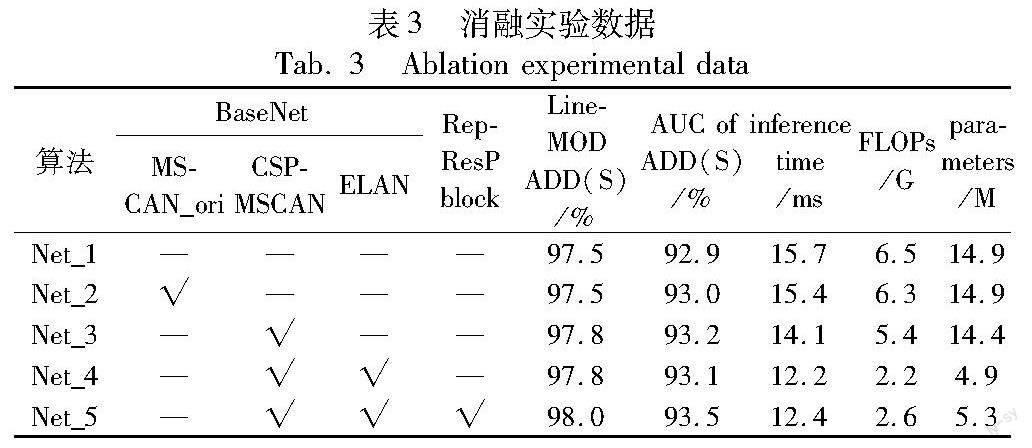
本文通过消融实验,进一步研究特征提取网络中每部分所起到的作用。本文对比了三种网络结构:a)原XYZNet网络;b)将XYZNet中ResNet18的layer1与layer2替换为原始MSCAN模块[16];c)将Net_2的原始MSCAN模块替换为本文的CSP-MSCAN;d)将XYZNet中ResNet18全部替换为BaseNet;e)加入Rep-ResP模块后的本文最终网络模型。除了LineMOD与YCB-Video数据集上的ADD(S)指标之外,本文还列出了不同网络在YCB-Video的推理时间、浮点计算量(FLOPs)与参数量,实验结果如表3所示。
表3的结果表明:相较于原始MSCAN,本文经过轻量化改进后的CSP-MSCAN可在降低网络计算量的同时提升网络的性能;同时,引入的ELAN模块既可显著压缩网络规模,又能保证网络精度不出现明显下降;在向PoinNet添加堆叠的Rep-ResP结构后,估计精度获得了进一步提升,这表明该结构对提升点云网络性能有显著的效果。由于该结构十分简单,所以网络的参数量增长较为有限。相较于XYZNet原网络Net_1,本文最终网络Net_5的浮点计算量与参数量分别降低了60.8%和64.8%,在推理速度上提升了21.2%,在LineMOD与YCB-Video数据集上分别取得了0.5%与0.6%的平均精度提升。
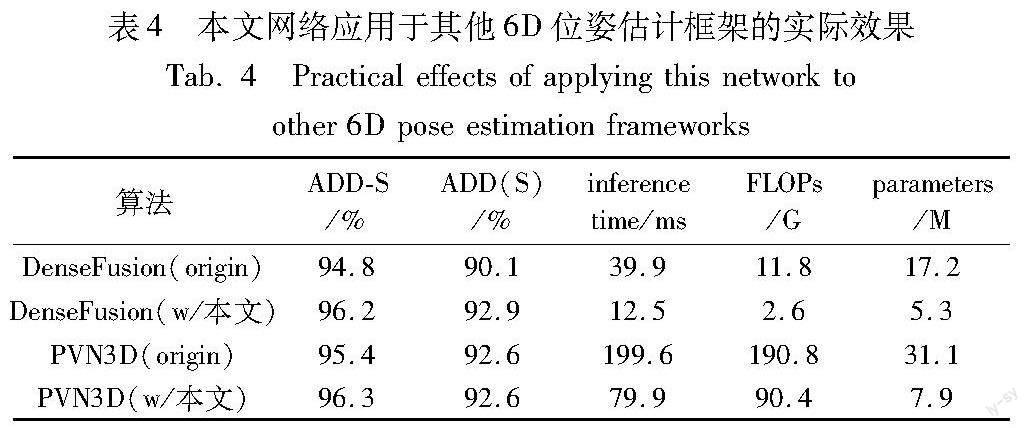
为了进一步验证本文网络的普适性,将主流的两种算法DenseFusion与PVN3D中的原特征提取网络替换为本文网络,并在YCB-Video数据集上进行实验,结果如表4所示。除了所有物体ADD-S与ADD(S)指标的平均值之外,表4还分别列出了不同算法的原特征提取网络与本文网络应用于该算法框架时的推理时间、浮点计算量FLOPs及参数量。实验结果表明,在DenseFusion和PVN3D框架下,本文网络可使推理速度分别提升68.7%与60.0%,浮点计算量分别降低78.0%与52.6%,参数量分别降低69.2%与74.6%。另外,在准确率方面,使用本文网络的DenseFusion的ADD(S)指标提高了2.8%,使用本文网络的PVN3D在ADD-S上实现了0.9%的提升。
综上所述,本文网络在保持较低网络规模的同时仍具有强劲的性能,更加高效地实现了对RGB-D多模态信息的提取。另外,本文网络在多种6D位姿估计框架下均能取得显著的改进效果,这表明其还具有良好的泛用性。
4 结束语
本文提出了一种轻量化改进XYZNet的RGB-D特征提取网络模型,在获得较好位姿估计准确率的同时,保持了较低的参数量。本文首先基于CSP-MSCAN与ELAN设计了一种轻量级子网络BaseNet來替换XYZNet中的ResNet18,大幅压缩模型规模的同时更加全面地提取多尺度特征信息;然后基于深度可分离卷积设计了一种可重参数化的多尺度卷积注意力Rep-MSCA子模块,以减小模型的复杂度并构建了丰富的上下文信息表示;最后提出了一种可重参数化的残差多层感知器Rep-ResP模块,以较低的参数代价强化了PointNet提取几何特征的能力。实验结果表明,相较于原始XYZNet模型,改进后的XYZNet模型可在参数量显著下降的情况下有效提升对目标位姿的估计精度与推理速度,实现对RGB-D多模态信息的高效提取。与DenseFusion和PVN3D等主流算法中的特征提取网络相比,本文模型在估计精度、推理速度以及参数量等指标上均为最优,为位姿估计模型在硬件受限的情况下进行部署提供了有效的技术手段。未来将进一步探索如何削减网络中残差连接的数量,以对模型在实际应用中的推理速度作更大的提升。
参考文献:
[1]王太勇,孙浩文. 基于关键点特征融合的六自由度位姿估计方法 [J]. 天津大学学报: 自然科学与工程技术版,2022,55(5): 543-551. (Wang Taiyong,Sun Haowen. Six degrees of freedom pose estimation based on keypoints feature fusion [J]. Journal of Tianjin University: Science and Technology,2022,55(5): 543-551.)
[2]Mo Ningkai,Gan Wanshui,Yokoya N,et al. ES6D: a computation efficient and symmetry-aware 6D pose regression framework [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2022: 6707-6717.
[3]Simonyan K,Zisserman A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2014-09-04)[2023-06-01]. https://arxiv. org/abs/1409. 1556v5.
[4]Szegedy C,Liu Wei,Jia Yangqing,et al. Going deeper with convolutions [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2015: 1-9.
[5]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al. Deep residual learning for image recognition [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2016: 770-778.
[6]Qi C R,Su Hao,Mo Kaichun,et al. PointNet: deep learning on point sets for 3D classification and segmentation [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2017: 652-660.
[7]Qi C R,Yi Li,Su Hao,et al. PointNet++: deep hierarchical feature learning on point sets in a metric space [C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY:Curran Associates Inc.,2017:5105-5114.
[8]Wang Chen,Xu Danfei,Zhu Yuke,et al. DenseFusion: 6D object pose estimation by iterative dense fusion [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2019: 3338-3347.
[9]He Yisheng,Sun Wei,Huang Haibin,et al. PVN3D: a deep point-wise 3D keypoints voting network for 6DoF pose estimation [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2020: 11629-11638.
[10]He Yisheng,Huang Haibin,Fan Haoqiang,et al. FFB6D: a full flow bidirectional fusion network for 6D pose estimation [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2021: 3002-3012.
[11]Ding Xiaohan,Zhang Xiangyu,Han Jugong,et al. Scaling up your kernels to 31×31: revisiting large kernel design in CNNs [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2022: 11953-11965.
[12]Liu Zhuang,Mao Hanzi,Wu Chaoyuan,et al. A ConvNet for the 2020s [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2022: 11966-11976.
[13]Liu Ze,Lin Yutong,Cao Yue,et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ:IEEE Press,2021: 9992-10002.
[14]Guo Menghao,Lu Chengze,Liu Zhengning,et al. Visual attention network [EB/OL]. (2022-01-20) [2023-06-01]. https://arxiv. org/abs/2202. 09741.
[15]Liu Shiwei,Chen Tianlong,Chen Xiaohan,et al. More ConvNets in the 2020s: scaling up kernels beyond 51×51 using sparsity [EB/OL]. (2022-07-07)[2023-06-01]. https://arxiv.org/abs/2207.03620.
[16]Guo Menghao,Lu Chengze,Hou qibing,et al. SegNeXt: rethinking convolutional attention design for semantic segmentation [EB/OL]. (2022-11-18)[2023-06-01]. https://arxiv.org/abs/2209.08575.
[17]魏愷轩,付莹. 基于重参数化多尺度融合网络的高效极暗光原始图像降噪 [J]. 计算机科学,2022,49(8): 120-126. (Wei Kai-xuan,Fu Ying. Re-parameterized multi-scale fusion network for efficient extreme low-light raw denoising [J]. Computer Science,2022,49(8): 120-126.)
[18]Arora S,Cohen N,Hazan E. On the optimization of deep networks: implicit acceleration by overparameterization [C]//Proc of International Conference on Machine Learning. 2018: 244-253.
[19]Zagoruyko S,Komodakis N. DiracNets:training very deep neural networks without skip-connections [EB/OL]. (2017-02-01) [2023-06-01]. https://arxiv.org/abs/1706.00388.
[20]Ding Xiaohan,Zhang Xiangyu,Ma Ningning,et al. RepVGG: making VGG-style convnets great again [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2021: 13728-13737.
[21]Wang C Y,Bochkovskiy A,Liao H Y M. YOLOv7:trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [EB/OL].(2022-07-06). https://arxiv.org/abs/2207.02696.
[22]张寅,朱桂熠,施天俊,等. 基于特征融合与注意力的遥感图像小目标检测 [J]. 光学学报,2022,42(24): 140-150. (Zhang Yin,Zhu Guiyi,Shi Tianjun,et al. Small object detection in remote sensing images based on feature fusion and attention [J]. Acta Optica Sinica,2022,42(24): 140-150.)
[23]Wang C Y,Liao H Y M,Yeh I H,et al. CSPNet: a new backbone that can enhance learning capability of CNN [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway,NJ:IEEE Press,2020: 1571-1580.
[24]王等准,李飞,严春雨,等. 基于多尺度特征融合的轻量化苹果叶部病理识别 [J]. 激光与光电子学进展,2023,60(2): 99-107. (Wang Dengzhun,Li Fei,Yan Chunyu,et al. Lightweight apple-leaf pathological recognition based on multiscale fusion [J]. Laser & Optoelectrinics Progress,2023,60(2): 99-107.)
[25]Li Guohao,Mueller M,Qian Guocheng,et al. DeepGCNs: making GCNs go as deep as CNNs [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2023,45(6): 6923-6939.
[26]Guo Menghao,Cai Junxiong,Liu Zhengning,et al. PCT: point cloud transformer [J]. Computational Visual Media,2021,7(2): 187-199.
[27]Ma Xu,Qin Can,You Haoxuan,et al. Rethinking network design and local geometry in point cloud: a simple residual MLP framework [EB/OL]. (2022-01-15) [2023-06-01]. https://arxiv. org/abs/2202. 07123.
[28]沙浩,刘越,王涌天,等. 基于二维图像和三维几何约束神经网络的单目室内深度估计方法 [J]. 光学学报,2022,42(19): 47-57. (Sha Hao,Liu Yue,Wang Yongtian,et al. Monocular indoor depth estimation method based on neural networks with constraints on two-dimensional images and three-dimensional geometry [J]. Acta Optica Sinica,2022,42(19): 47-57.)
[29]Hinterstoisser S,Holzer S,Cagniart C,et al. Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes [C]// Proc of International Conference on Computer Vision. Piscata-way,NJ:IEEE Press,2011: 858-865.
[30]Xiang Yu,Schmidt T,Narayanan V,et al. PoseCNN: a convolutional neural network for 6D object pose estimation in cluttered scenes [EB/OL]. (2017-09-01) [2023-06-01]. https://arxiv.org/abs/1711.00199.
[31]馬天,蒙鑫,牟琦,等. 基于特征融合的6D目标位姿估计算法 [J]. 计算机工程与设计,2023,44(2): 563-569. (Ma Tian,Meng Xin,Mou Qi,et al. 6D object pose estimation algorithm based on fea-ture fusion [J]. Computer Engineering and Design,2023,44(2): 563-569.)
猜你喜欢
电子制作(2019年15期)2019-08-27
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年19期)2018-11-14
电子制作(2018年18期)2018-11-14
电子测试(2018年6期)2018-05-09
电子测试(2017年11期)2017-12-15
中国生物医学工程学报(2017年6期)2017-02-10
广西科技大学学报(2016年1期)2016-06-22
电气化铁道(2016年4期)2016-04-16
噪声与振动控制(2015年4期)2015-01-01
