
融合多粒度信息的用户画像生成方法
2024-03-05 08:33邵一博秦玉华崔永军高宝勇赵彪
计算机应用研究 2024年2期
邵一博 秦玉华 崔永军 高宝勇 赵彪

收稿日期:2023-05-14;修回日期:2023-07-01 基金項目:青岛市科技惠民示范项目(23-2-8-smjk-20-nsh)
作者简介:邵一博(1999—),男,山东菏泽人,硕士研究生,CCF会员,主要研究方向为智能信息处理、用户画像;秦玉华(1971—),女(通信作者),山东青岛人,教授,硕导,博士,主要研究方向为智能信息处理(yuu71@163.com);崔永军(1975—),男,山东青岛人,副主任医师,主要研究方向为医疗大数据;高宝勇(1998—),男,山东寿光人,硕士研究生,主要研究方向为智能信息处理;赵彪(2001—),男,山东菏泽人,硕士研究生,主要研究方向为自然语言处理.
摘 要:现有用户画像方法缺乏不同粒度文本信息表示,且特征提取阶段存在噪声,导致构建画像不够准确。针对以上问题,提出一种融合多粒度信息的用户画像生成方法(user profile based on multi-granularity information fusion,UP-MGIF)。首先,该方法在嵌入层融合字粒度、词粒度表示向量以扩充特征内容;其次,在改进双向门控循环单元网络基础上,结合降噪自编码器和注意力机制设计一种特征提取混合模型Bi-GRU-DAE-Attention,实现特征降噪和语义增强;最后,将鲁棒性强的特征向量输入到分类器中实现用户画像生成。实验表明,该用户画像生成方法在医疗和互联网两个画像数据集上的分类准确率高于其他基线方法,并通过消融实验验证了各个模块的有效性。
关键词:用户画像;多粒度信息融合;特征提取;双向控制循环单元
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)02-012-0401-07
doi:10.19734/j.issn.1001-3695.2023.05.0234
User profile generation method by fusing multi-granularity information
Shao Yibo1,Qin Yuhua1,Cui Yongjun2,Gao Baoyong1,Zhao Biao1
(1.College of Information Science & Technology,Qingdao University of Science & Technology,Qingdao Shandong 266061,China;2.Qing-dao Hospital,University of Health & Rehabilitation Sciences(Qingdao Municipal Hospital),Qingdao Shandong 266001,China)
Abstract:Most of the existing user profile methods lack different granularity text information representation,and there is a noise problem in the feature extraction stage,resulting in the inaccurate construction of the profile.To address these issues,this paper proposed a user profile method based on multi-granularity information fusion,called UP-MGIF.Firstly,it integrated the character-level granularity and the word-level granularity representation vectors in the embedding layer to expand feature content.Secondly,based on the improved bi-directional gated recurrent unit network(Bi-GRU),it designed a hybrid feature extraction model called Bi-GRU-DAE-Attention by combining denoising autoencoder(DAE) and attention mechanism to achieve feature denoising and semantic enhancement.Finally,it input the robust feature vectors into the classifier to achieve user profile generation.Experiments show that the user profile generation method achieves higher classification accuracy than other baseline methods on two profile datasets in the medical and Internet domains,and validate the effectiveness of each module through ablation experiments.
Key words:user profile;multi-granularity information fusion;feature extraction;bidirectional gated recurrent unit
0 引言
当今,数字化技术的迅猛发展和互联网的广泛普及使得数据的生成和存储量不断增加,从而导致数据爆炸、信息冗余等一系列问题[1]。如何从数据中提取有价值的信息,帮助企业更好地了解用户的需求、习惯和兴趣等属性特征,避免资源浪费,依旧是当前的研究热点。
用户画像是通过对用户数据进行分析,建立一个代表用户特征的画像表示,进而利用该画像为用户提供更加个性化的服务[2]。用户画像研究广泛应用于电商、医疗、推荐系统等领域,可以帮助企业更好地了解用户需求,提高用户满意度和忠诚度[3]。
用户画像的构建过程是将用户数据信息标签化,完善系统中缺失的用户属性信息。目前主要有基于统计的用户画像和基于模型的用户画像两种生成方式。其中,基于统计的用户画像主要利用数据统计和分析技术对用户的属性、行为和兴趣等特征进行描述和分析,以形成一个关于用户的整体概况。Yan等人[4]通过统计用户在线购物和浏览日志建立基于使用情况的用户画像,从而挖掘用户之间的行为差异。刘海鸥等人[5]对社交媒体用户碎片化信息进行时间统计特征分析,揭示了在线社交活动中的用户行为特点。Chen等人[6]基于企业舆情理论知识,抓取用户特征标签,将数据量化为影响风险程度的指标,构建企业网络舆情用户画像。然而,基于统计方法构建的用户画像较为简单,无法对文本、图片等非结构化数据进行分析,易造成资源浪费。
基于模型的用户画像比基于统计的用户画像更具灵活性和准确性,前者可以通过更深入的分析和更多的数据来预测用户的行为,这种方法通常将深度学习技术应用于自然语言处理领域,建立用户的预测模型,并通过训练数据对模型进行优化。陈泽宁等人[7]通过词向量模型word2vec将文本内容表示成向量,并结合随机森林算法对用户的基本属性进行分类构建用户画像,但针对数据特征的表示较为单一,缺乏对多方面信息的有效利用。于伟杰等人[8]采用集成学习Stacking的方式结合LR、SVM、BERT多个模型,通过投票机制获得最优分类效果,但多个模型的累加容易出现过拟合问题。苗宇等人[9]提出一种多层级特征提取的融合网络用户画像生成方法Multi-Aspect,对用户的搜索词数据进行多角度特征提取融合,使用Bi-GRU(bidirectional gated recurrent unit)和Attention提取文本全文特征和关键词特征来预测用户的匿名属性标签,但在文本编码模块中仅使用word2vec方法,沒有从多粒度的角度出发,特征表示不够全面,文本语义表示能力较差,用户画像属性预测准确率较低。Zhou等人[10]结合RoBERTa-wwm-ext模型完成中文文本的编码嵌入,获得字符粒度的文本表示。辛苗苗等人[11]融合字符粒度、词语粒等特征信息来扩充特征内容,融合多粒度信息比单一粒度准确率更高,但特征提取阶段忽略了文本数据中的随机噪声影响,分类的效果仍有待提升。为了克服序列数据噪声的影响,段闫闫等人[12]在LSTM的基础上引入降噪自编码器(DAE),从而获取鲁棒性更强的特征表示。
综上所述,现有用户画像方法通常只考虑单一粒度信息,忽略了不同粒度组合对用户画像的研究,导致文本向量对文本语义的表示能力较差。另外,简单的特征提取方法容易忽略文本数据特征细节,特征提取阶段存在噪声干扰、过拟合问题,导致用户画像属性预测时准确率较低。针对上述问题,本文提出一种融合多粒度信息的用户画像生成方法(user profile based on multi-granularity information fusion,UP-MGIF)。首先,构建不同粒度的向量嵌入表示,使用word2vec模型获取文本的词粒度向量,并使用RoBERTa模型获取文本的字粒度向量,将两者进行拼接得到融合向量,从而扩充特征内容,获取更加全面的特征信息,增强文本语义表示能力。其次,设计一种特征提取混合模型Bi-GRU-DAE-Attention(Bi-GDA),将向量输入到改进的双向门控循环单元网络(bidirectional gated recurrent unit,Bi-GRU)中进行初步的特征提取,融合降噪自编码器(denoising autoencoder,DAE)解决文本序列随机噪声的干扰问题,增强特征的鲁棒性,并结合Attention机制进一步加强对文本序列中关键因子的关注以及内部相关性的捕捉。最后,在分类层得到用户画像标签的分类结果。
1 相关工作
1.1 word2vec模型
word2vec是一种基于神经网络的模型[13],可以将单词转换为固定维度的向量,向量的每个维度表示不同单词的语义特征。word2vec包括CBOW和skip-gram两种词嵌入模型。CBOW模型通过输入窗口内目标词的前后词语来预测目标词语。skip-gram模型通过输入目标单词来预测该词前后单词的概率分布,其训练时间短且效果较好,所以本文采用skip-gram模型。假设文本由一组词序列w1,w2,w3,…,wn组成,在输入层将每个词进行编码,skip-gram算法的目标是计算最大化平均对数条件概率pn。
pn=1T∑Tn=1∑-m≤j≤mln p(wn+j|wn)(1)
其中:m为训练文本窗口的大小;wn+j为中心单词wn的前j个;T为文本中的单词总数。
在给定输入单词wn+1的情况下,输出单词wn+j出现的概率为
p(wn+j|wn)=exp(uTwn+jvn)∑Ww=1exp (uTwvn)(2)
其中:vn表示中心词向量;uTw表示窗口内上下文词向量的转置;W表示单词的总数。
通过对语料库进行训练,skip-gram模型为语料库中的每个单词生成一个词向量。将文本中每个单词的词向量相加取平均值,可以得到文本的词粒度向量表示。在词粒度信息表示方面,word2vec具有更快的计算速度以及更好的单词含义捕捉能力。
1.2 RoBERTa-wwm-ext模型
RoBERTa的核心架构同BERT模型[14]一样,采用多层双向Transformer编码器作为模型的主要框架,这种架构能够更好地处理文本序列输入,同时充分利用上下文信息,提高模型对文本的理解能力。RoBERTa模型在预训练阶段去除NSP任务,并采用更加灵活的动态掩码策略(dynamic masking),每次在输入文本中随机选取一部分token进行掩码,而不是像BERT模型固定地选取15%的token进行掩码,这种随机的方式有助于提高模型的鲁棒性和泛化能力,但是原始的RoBERTa模型并不能很好地适用于中文语料库。因此,RoBERTa-wwm-ext模型在RoBERTa模型的基础上将动态掩码策略变为全词掩码策略(WWM),并增大训练数据集的规模,使用max_len=512的训练模式。基于RoBERTa字粒度的编码方式相对于基于词粒度的编码方式在一些中文语言处理的场景下具有优势,能够更好地处理未登录词、复杂结构和纯口语化的文本,从而提高模型的表征能力。
1.3 降噪自编码器
文本数据常常受到拼写错误、语法错误、噪声字符等干扰,影响用户画像模型的准确性。通过使用降噪自编码器,可以学习到文本数据特征的鲁棒表示,减少噪声的影响,提高文本质量。降噪自编码器是基于自编码器(autoencoder,AE)的改进。AE[15]是神经网络的一种,由编码器、解码器和隐含层组成,可以从原始数据中学习具有代表性的特征。但原始的自编码器容易出现对原始数据的简单复制,无法学习数据之间的潜在关系,导致模型提取的特征无效。为了学习深层的特征表示,降噪自编码器引入了一种随机噪声的策略,用于减少原始数据噪声的影响,结构如图1所示。
DAE在编码器阶段通过对原始数据添加一定程度的随机噪声[16],使得数据的表达更加复杂。在解码的过程中学习去除噪声并重构原始数据,从而增强特征学习的能力,使得提取的特征更具有鲁棒性。对输入数据hv添加随机噪声,v为加噪后的特征向量表示,然后通过编码器对v进行编码操作,获得隐层特征向量y。最后通过解码器对其进行解码重构操作,z为重构后的特征表示,Loss(hv,z)是对应的重构误差的损失函数。
2 融合多粒度信息的用户画像生成模型
用户画像生成模型主要由嵌入融合层、特征提取层和用户画像层构成。如图2所示,首先对用户的文本数据进行预处理,包括清洗、分词、去停用词等操作;其次,在嵌入层对文本数据进行训练,获取字粒度和词粒度的向量表示;然后将两种粒度向量表示按顺序拼接,获得融合向量,并将其输入到本文提出的Bi-GRU-DAE-Attention模块中提取噪声小、鲁棒性强的深层次语义特征;最后,将其输入到softmax进行分类,从而完成用户画像标签的预测。
2.1 嵌入层
为了扩充用户文本数据的特征信息,对预处理后的文本数据进行字粒度和词粒度的向量化表示,然后将字粒度和词粒度的向量表示进行拼接得到丰富语义的融合向量,嵌入层融合过程如图3所示。
2.1.1 字粒度向量
给定一条文本数据X,按照字为单位进行分词,得到序列X={x1,x2,x3,…,xm},将其输入到RoBERTa-wwm-ext模型中。此模型可以在大规模中文文本数据上进行自监督学习,从而学习到字粒度的表征向量。具体地,通过非线性函数将每个字符xi转换为对应d维向量表示。然后,将这些向量传入Transformer模型[17]进行编码。本文采用12层Transformer编码模块学习序列的上下文关系和语义信息,经过第l层Transformer编码后的输出如下:
Hl=transformer_block(Hl-1)(3)
其中:Hl-1是第l-1层的输出;transformer_block表示Transformer块,由自注意力子层和前向传播子层组成。
最终,经过12层Transformer编码后,得到文本X字粒度的向量表示:
CRoBERTa=[c1,c2,c3,…,cm]T∈Euclid Math TwoRApm×d(4)
其中:m表示文本中字的数量;d表示字向量的维度;cm表示第m个字的向量;Euclid Math TwoRApm×d表示m行、d列的文本矩阵。
2.1.2 词粒度向量
本文使用word2vec中的skip-gram模型训练文本语料库,获得词粒度向量编码。首先利用Jieba分词工具对文本数据进行切分得到X={x1,x2,x3,…,xn},xi表示第i個词,n表示总共的词数。将其放入skip-gram模型中进行训练,模型选取一个中心词xi。然后在xi的上下文窗口中选取一个词xi-1,将xi和xi-1分别表示成向量uxi-1和vxi,在当前中心词xi下,计算所有上下文词出现的条件概率,公式为
p(xi-1|xi)=exp (uxi-1vxi)∑Vw=1 exp (uwvxi)(5)
其中:V表示词汇表中的所有词;uw表示词w在上下文出现的向量表示。在训练过程中,skip-gram模型通过反向传播算法来更新词向量,使得目标函数最大化。在训练完成后,每个词都会被表示成一个固定维度的向量,最终得到词粒度的向量表示:
Wword2vec=[w1,w2,w3…,wi…,wm]T∈Euclid Math TwoRApm×d(6)
其中:m表示文本中词的数量;d表示词向量的维度;wi表示第i个词的词向量。
2.1.3 多粒度信息融合
字粒度向量考虑文本中每个字的语义信息,而词粒度向量则考虑整个词的语义信息。获取文本字粒度和词粒度向量表示后,将两者进行拼接得到最后的文本表示向量[18],增加向量的维度和蕴涵的信息量,提高模型的特征表达能力。两种粒度向量的拼接公式为
V=Wword2vec⊕CRoBERTa(7)
其中:⊕为拼接运算符,得到融合字粒度和词粒度的向量V后,将其输入到特征提取模型中,提取更深层次的特征。
2.2 特征提取层
文本数据中包含丰富的特征信息,只使用Bi-GRU网络提取的特征数据不仅存在许多噪声,而且无法突出不同位置语义特征的贡献程度,模型分类效果不佳。为此,本文提出一种基于Bi-GRU-DAE-Attention(Bi-GDA)的特征提取模型,该模型首先改进GRU特征提取单元,并将其与注意力机制结合改进DAE模块,使得提取的特征噪声小、鲁棒性强,其网络结构如图4所示。
2.2.1 基于改进Bi-GRU的初步特征提取
Bi-GRU是基于门控循环单元网络(gated recurrent unit,GRU)[19]的改进模型,核心思想是在GRU网络的基础上再增加一层GRU网络来反向处理数据。在每个时刻,GRU网络的状态计算包括更新门、重置门、候选值和隐藏状态,其中,更新门和重置门控制信息的流动,候选值和隐藏状态控制节点的输出。相较于传统的长短期记忆网络(long short-term memory,LSTM)[20],GRU网络具有更简单的网络结构和高效的计算效率。但原始的GRU单元的参数较多,模型容易出现过拟合现象,使模型的泛化能力较差。因此,本文在GRU网络结构中添加dropout层[21]减少过拟合现象。将dropout层设置在更新门和隐藏状态之间的通道上,可以随机地将隐藏状态的一部分元素置为0,以防止过拟合,添加dropout层的GRU单元结构如图5所示。
将嵌入层的融合向量V输入到Bi-GRU中,从正向和反向两个方向学习深层次的隐含强依赖关系特征。具体地,在第t个时间步的隐层表示计算过程如下:
首先,计算更新门zt和重置门rt,其作用是控制GRU单元输入、遗忘和输出的比例:
zt=σ(Wzxt+Uzht-1+bz)(8)
rt=σ(Wrxt+Urht-1+br)(9)
然后,计算候选值t,以更好地捕捉当前时刻输入信息xt和前一时刻的状态ht-1。
t=tanh(Whxt+Uh(rt·ht-1)+bh)(10)
最后,计算隐藏状态时,增加dropout层对部分神经元进行失活处理,增加模型的泛化性。丢弃率p一般控制在[0.2,0.5]效果最佳[22],在第t步隐层的输出ht公式变为
ht=(1-zt)·ht-1+dropout(t,p)·zt(11)
其中:σ(x)=11+e-x即sigmoid函数,将信息流控制在(0,1); tanh(x)=ex-e-xex+e-x即双曲正切函数;Wz、Wr 、Wh、Uz、Ur、Uh为门控参数矩阵;bz、br、bh为偏置参数。
向量V经过Bi-GRU网络处理后,得到正向特征信息序列v=[1,2,…,m]和反向特征信息序列v=[m,m-1,…,1],将两者进行拼接得到输出向量hv。
hv=[v⊕v](12)
2.2.2 基于改进DAE的特征降噪
传统的DAE结构,其编码层为全连接网络,节点之间处于无连接状态。虽然该结构能够降低文本数据噪声问题,但无法有效处理包含上下文信息的序列数据,也无法突出不同位置的语义重要性。针对此问题,本文将DAE模型编码器部分的全连接层编码网络更改为Bi-GRU网络,在提取融合向量特征的同时可以降低噪声干扰,以保证语义信息的连贯性和鲁棒性。在解码器部分结合注意力机制,加强不同位置的语义重要性。
首先对编码层Bi-GRU提取的特征向量hv采用添加随机噪声的方式进行局部破坏;然后通过线性变换和激活函数等过程到达隐层;最终通过解码器得到重构映射向量z。编码器和解码器的表示函数分别为e(v)和d(y)。
y=e(v)=Se(Wv+by+bn)(13)
z=d(y)=Sd(WTy+bz)(14)
其中:Se为编码器的激活函数;Sd为解码器的激活函数;W为权值;by、bz为偏置,bn为高斯随机噪声。
重构向量的误差最小取决于损失函数,将其添加到整个网络的损失中,并通过反向传播算法不断优化参数,使得重构的误差达到最小。具体而言,在重构向量部分,本文采用均方误差损失函数,如下所示。
Loss(hv,z)=1N∑Ni=1(zi-hvi)2(15)
为避免编解码过程重要信息的缺失,进一步融合编码特征hv和z得到融合向量Z,以減小噪声因子对原始数据的影响,避免重要特征信息遗漏,提高特征的鲁棒性。在解码器之后将融合向量Z进一步传入Attention模块中计算特征不同位置之间的权重[23],降低模型对外部信息的依赖,提高模型的性能。通过权重矩阵将输入向量Z分别映射为查询向量Q、键向量K和数值向量V,经过注意力加权得到最终的特征向量H,其计算方式如下:
Z=[hv⊕z](16)
H=attention(ZWQi,ZWKi,ZWVi)(17)
attention(Q,K,V)=softmax(QKTd)V(18)
其中:WQi、WKi、WVi为权重矩阵;d是键向量K和查询向量Q的维度。
2.3 用户画像层
用户画像层是神经网络模型的一个分类层,其主要作用是将经过注意力计算后的向量H转换为每个用户画像类别的概率。该层由一个全连接神经网络和一个softmax函数组成。具体而言,将向量H传入全连接神经网络进行线性变换,然后再通过激活函数ReLU进行非线性变换,学习更加复杂的特征表示,从而得到输出向量F。其中,Fi表示属于第i个用户画像类别的得分。最后,通过softmax函数将F转换为每个用户画像类别的概率,选择概率最高的用户画像类别作为预测结果。
F=f(WH+b)(19)
pl=exp(Fi)∑nj=1exp(Fj)(20)
其中:n为画像类别数;W为权重;b为偏置;exp为自然指数函数;f为激活函数ReLU;pl为用户属于第l个画像类别的概率。
3 实验及结果分析
3.1 实验环境及参数设置
本文实验的硬件环境包括Intel Core i7-12700KF CPU、32 GB内存和NVIDIA GeForce GTX 4090显卡,软件环境包括CUDA 11.3、Python 3.7、PyTorch深度学习框架和PyCharm集成开发环境。在整体网络的训练过程中,本文模型的参数设置主要包括word2vec、RoBERTa以及Bi-GDA模块,模型参数如表1所示。
3.2 实验数据集及评价指标
本文實验通过两个数据集对模型画像的效果进行验证,具体的数据集信息如下:
a)慢病患者画像数据集。该数据集爬取于某知名的在线医疗咨询网站慢病患者在线咨询数据,数据量共计3 294条样本,根据慢病患者咨询内容设计三类画像标签(年龄、性别、科室)。其中,gender属性分为2种类别,age和departments为7种类别。选择2 636条咨询文本数据作为训练数据,658条作为测试数据。
b)搜狗用户画像数据集。该数据集来自第七届中国计算机学会(CCF)组织的关于搜狗用户画像比赛的数据,包含用户一个月内在搜索引擎中的搜索记录和对应的用户画像属性标签(年龄、性别、学历)共10万条。其中,gender属性分为2种类别,age和education属性分别为7种类别。对数据集的缺失或重复部分进行清洗操作,采用随机采样的方式选取80%为训练集,余下20%为测试集。
以慢病患者画像数据集为例,各字段详细说明如表2所示。
用户画像技术根据用户数据信息将用户划分到对应的属性类别,属于分类任务。准确率是模型预测正确结果的占比,是评估分类模型的重要指标。因此,本文采用准确率(accuracy)作为评价指标,其计算公式为
accuracy=TP+TNTP+FP+TN+FN×100%(21)
其中:TP、FP、FN和TN的含义如表3所示。
3.3 实验结果对比分析
3.3.1 不同参数选择对比
1)隐含层节点数 Bi-GRU的隐含层节点数会影响分类的结果,隐含层的节点数决定模型的表达能力。如果隐含层节点数较少,则模型不足以很好地捕捉输入序列中的信息,导致模型欠拟合,预测准确率较低。相反,如果隐含层节点数过多,则模型可能过度拟合,对训练数据过于敏感,导致对未见过的数据学习能力较差。因此,选择适当的隐含层节点数可以获得更好的分类结果。本文实验隐含层节点初始数目设置为32,间隔大小为32,在两个数据集上的实验结果如图6所示。
可知,当节点数为128时,分类准确率最高。节点数过高容易增加模型的复杂度,导致准确率下降。经实验验证,本文模型最佳的隐含层节点数为128。
2)噪声比 在模型的训练阶段,加噪程度会影响模型的性能。加噪程度过低,重构数据与原始特征差距较小,准确率提升不明显。加噪程度适中,可以强制模型学习数据的关键特征,从而提高模型的泛化能力。然而,当加噪程度过高时,重构误差也会增高,导致特征提取能力下降。图7显示加噪比例对实验结果的影响。由图可以看出,加噪比例为0.3时,分类准确率有明显提升,说明模型学习到更加鲁棒性的特征,随着噪声比例的增加,分类的准确率也越来越低。
3)学习率 学习率对模型的效果有重要影响,通过对比实验调整以获得最佳模型性能。学习率是梯度下降算法中一个重要的超参数,控制着网络权重更新的幅度。本文选取1E-7、1E-6、1E-5、1E-4、1E-3、1E-2和1E-1共7个学习率进行实验,结果如图8所示。可以看到,当学习率为1E-5时模型的效果最佳,所以本文网络采用该学习率。
3.3.2 单一粒度与多粒度融合对比
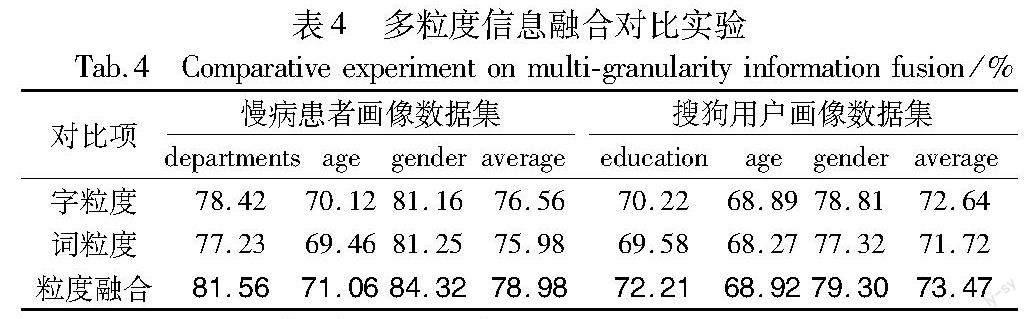
目前用户画像的研究大多数基于数据的单一粒度,为验证融合不同粒度信息对用户画像的影响,分别对字粒度、词粒度和融合粒度进行实验,实验结果如表4所示,加粗内容为最优值。综合分析两个数据集上的实验结果可以看出,嵌入层使用字粒度表示或词粒度表示时对整体的平均分类结果相差不大,但融合两者之后再作分类,分类效果得到较为明显的提升。因为仅使用单粒度表示时,数据特征表示得不够充分,分类效果相对较差。使用融合粒度可以扩充文本特征实现数据增强,从而改善这种弊端。因此,本文后续实验采用融合粒度进行后续的特征提取。
3.3.3 不同画像模型效果对比
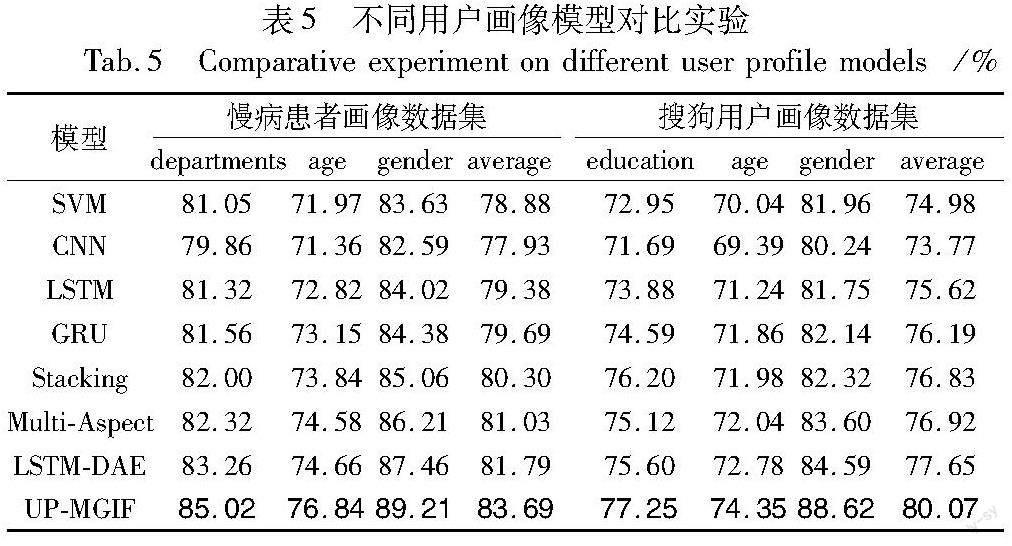
为验证本文在用户画像生成模型中提出的Bi-GDA方法的有效性,将其与SVM[24]、CNN[25]、LSTM[19]、GRU[20]、Stacking[8]、Multi-Aspect[9]和DAE-LSTM[12]七个模型进行对比实验,表5为本文方法UP-MGIF与其他算法的对比结果,加粗内容为最优值。
由实验结果可以看出,UP-MGIF在用户画像的分类性能均优于所有基线模型。支持向量机SVM只能对文本特征进行简单提取,无法获取深层次的语义信息,导致分类效果较差。使用卷积神经网络进行局部特征提取,虽然能获得局部细粒度特征信息,但是会丢失部分全局的样本特征,不能很好地适用于文本数据,分类准确率相对较低。文本数据属于序列数据,LSTM和GRU模型可以很好地提取上下文信息,分类准确率有所提升,但缺乏对特征质量的进一步加强,提取的特征存在噪声问题,导致模型鲁棒性较差。集成学习Stacking的方式通过多分类器投票的方式获得最优分类结果,其分类效果略优于LSTM和GRU,但过于依赖某一分类器的性能,分类结果不稳定。多层级特征提取方法Multi-Aspect忽略了特征提取阶段的噪声问题,准确率有待进一步提升。LSTM-DAE结合降噪模块后在两个数据集的准确率比LSTM提高4.31%和4.45%,证明了对数据特征进行噪声处理可以进一步提高分类准确率。本文提出的特征提取模块Bi-GDA使用Bi-GRU作为基础特征提取模块,将其作为编码器改进DAE网络,并结合Attention机制突出不同位置语义特征的重要性,充分发挥各模块的优势,提取噪声更少、质量更高的数据特征,尤其是在分类类别较少时准确率获得明显提升。由两个数据集上的实验结果可知,在文本内容较短的慢病患者画像数据集上,本文构建的UP-MGIF模型相较于其他模型平均准确率分别提升4.81%、5.76%、4.31%、4.00%、3.39%、2.66%和1.90%。在文本内容较长的搜狗用户画像数据集上,相较于其他模型平均准确率分别提升5.09%、6.30%、4.45%、3.88%、3.24%、3.15%和2.42%。在age属性分类中准确率略低于其他属性画像,原因在于age属性类别较多,文本信息关联性差,导致分类误差率较高。总体而言,UP-MGIF的分类效果提高较为明显,适用于不同领域的画像生成。
3.3.4 消融實验
为验证本文特征提取层Bi-GDA模型各个模块在画像任务上的有效性,分别在两个数据集上进行消融实验,结果如表6所示,加粗内容为最优值。从表6可知,若去除DAE和Attention模块,平均准确率都有所下降。因此,本文设计的特征提取方法中的每个模块对用户画像标签的预测均有贡献,Bi-GRU可以从正反两个方向提取融合粒度的上下文信息,然后输入到降噪自编码器中进行降噪,获取更稳健的特征表示,加入Attention机制可以进一步给不同位置的特征分配不同的权重来突出关键信息,使得总体分类效果得到明显提升。
3.3.5 案例分析
为了更为直观地展示本文方法的有效性,选取慢病患者画像数据集进行案例分析,并与其他算法进行对比。本文对比了主流方法Stacking、Multi-Aspect、LSTM-DAE和本文方法在慢病患者画像数据集的表现,观察不同算法预测正误情况,选取数据集中的两个样本分类结果为例进行说明,如表7所示。
从表7中可以看出,在第一个测试样本中,实际的画像标签为“25~30岁、女、妇科”,Stacking、Multi-Aspect两种方法均存在错误预测,这两种算法的编码阶段采用的是word2vec,仅基于词粒度信息,没有充分考虑上下文信息,因此在出现“宝宝”“男孩”时便直接将其预测为年龄为0~18岁、男、所属科室为儿科的类别中。LSTM-DAE和本文方法在编码阶段采用了RoBERTa的方式,不仅获取字粒度信息,且融合了上下文语境信息,因此预测正确。在第二个测试样本中,实际画像标签类别为“19~24岁、男、内科”,Stacking、Multi-Aspect、LSTM-DAE三种方法均在年龄属性预测错误,因为文本中的数字信息和符号干扰,导致模型无法挖掘更深层信息。本文模型加入了噪声消除模块,可以降低文本中的符号噪声的影响,并通过注意力机制增强不同位置的语义信息,从而得到正确的分类。
男生,22/岁,长期慢性腹泻怎么回事?出现这样的情况该做什么呢?
Stacking
Multi-Aspect
LSTM-DAE
UP-MGIF
31~40岁、男、内科
31~40岁、男、内科
25~30岁、男、内科
19~24岁、男、内科19~24岁、男、内科
4 结束语
现有用户画像技术通常缺乏对非结构化数据信息的充分利用,存在数据利用率低、特征表示鲁棒性差等问题,导致构建的用户画像不够准确。因此,针对用户的非结构文本数据,本文提出一种融合多粒度信息的用户画像生成方法。该方法首先从字粒度、词粒度两方面进行向量融合,提高文本数据的利用率,扩充文本数据的特征表示;然后通过Bi-GRU-DAE-Attention特征提取层获取深层次、高质量的特征向量;最后将提取的融合向量输入分类器中完成用户画像,通过消融实验证明各个模块的重要性。不同主体的用户画像之间存在一定的关联性,用户画像的生成应该充分结合主体间各种关联数据。因此,下一步尝试从多主体的角度出发,结合不同主体信息,更加充分地描述用户属性,并构建合适的模型进一步提高准确性。
参考文献:
[1]Luan Hui,Geczy P,Lai H,et al.Challenges and future directions of big data and artificial intelligence in education[J].Frontiers in Psychology,2020,11:580820.
[2]Chen Xusong,Liu Dong,Xiong Zhiwei,et al.Learning and fusing multiple user interest representations for micro-video and movie recommendations[J].IEEE Trans on Multimedia,2020,23:484-496.
[3]徐芳,应洁茹.国内外用户画像研究综述[J].图书馆学研究,2020(12):7-16.(Xu Fang,Ying Jieru.Literature review of persona at home and abroad[J].Research on Library Science,2020(12):7-16.)
[4]Yan Huan,Wang Zifeng,Li Yong,et al.Profiling users by online shopping behaviors[J].Multimedia Tools and Applications,2018,77:21935-21945.
[5]刘海鸥,孙晶晶,张亚明,等.在线社交活动中的用户画像及其信息传播行为研究[J].情报科学,2018,36(12):17-21.(Liu Haiou,Sun Jingjing,Zhang Yaming,et al.Research on user portrayal and information dissemination behavior in online social activities[J].Information Science,2018,36(12):17-21.)
[6]Chen Tinggui,Yin Xiaohua,Peng Lijuan,et al.Monitoring and recognizing enterprise public opinion from high-risk users based on user portrait and random forest algorithm[J].Axioms,2021,10(2):106.
[7]陳泽宇,黄勃.改进词向量模型的用户画像研究[J].计算机工程与应用,2020,56(1):180-184.(Chen Zeyu,Huang Bo.Research on user portrait of improved word vector model[J].Computer Engineering and Applications,2020,56(1):180-184.)
[8]于伟杰,杨文忠,任秋如.基于全词BERT的集成用户画像方法[J].东北师大学报:自然科学版,2022,54(4):87-92.(Yu Weijie,Yang Wenzhong,Ren Qiuru.User profile method based on improved integration algorithm[J].Journal of Northeast Normal University:Natural Science Edition,2022,54(4):87-92.)
[9]苗宇,金醒男,杜永萍.基于Multi-Aspect的融合网络用户画像生成方法[J].计算机技术与发展,2022,32(8):20-25.(Miao Yu,Jin Xingnan,Du Yongping.A user profile generation method based on multi-aspect converged network[J].Computer Technology and Development,2022,32(8):20-25.)
[10]Zhou Faguo,Wang Chao,Sun Dongxue,et al.Joint big data extraction method for coal mine safety with characters and words fusion[J].Journal of Signal Processing Systems,2022,94(11):1213-1225.
[11]辛苗苗,马丽,胡博发.融合多粒度信息的文本分类研究[J].计算机工程与应用,2023,59(9):104-111.(Xin Miaomiao,Ma Li,Hu Bofa.Research on text classification by fusing multi-granularity information[J].Computer Engineering and Applications,2023,59(9):104-111.)
[12]段闫闫,徐凌伟.融合DAE-LSTM的认知物联网智能频谱感知算法[J/OL].计算机工程与应用.(2023-03-01).http://kns.cnki.net/kcms/detail/11.2127.TP.20230228.1551.030.html.(Duan Yanyan,Xu Lingwei.DAE-LSTM-fused intelligent spectrum sensing algorithm for cognitive Internet of Things[J/OL].Computer Engineering and Applications.(2023-03-01).http://kns.cnki.net/kcms/detail/11.2127.TP.20230228.1551.030.html.)
[13]Jatnika D,Bijaksana M A,Suryani A A.word2vec model analysis for semantic similarities in English words[J].Procedia Computer Science,2019,157:160-167.
[14]Liu Yinhan,Ott M,Goyal N,et al.RoBERTa:a robustly optimized BERT pretraining approach[EB/OL].(2019-07-26).https://arxiv.org/abs/1907.11692.
[15]Zhang Guijuan,Liu Yang,Jin Xiaoning.A survey of autoencoder-based recommender systems[J].Frontiers of Computer Science,2020,14:430-450.
[16]张敬川,田慧欣.基于 LSTM-DAE 的化工故障诊断方法研究[J].北京化工大学学报:自然科学版,2021,48(2):108-116.(Zhang Jingchuan,Tian Huixin.Fault diagnosis of chemical process based on long short-term memory(LSTM) -denoising auto-encoder(DAE)[J].Journal of Beijing University of Chemical Technology:Natural Science,2021,48(2):108-116.)
[17]Vaswani A,Shazeer N,Parmar N,et al.Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems.Red Hook,NY :Curran Associates Inc.,2017:6000-6010.
[18]聂维民,陈永洲,马静.融合多粒度信息的文本向量表示模型[J].数据分析与知识发现,2019,3(9):45-52.(Nie Weimin,Chen Yongzhou,Ma Jing.A text vector representation model merging multi-granularity information[J].Data Analysis and Knowledge Discovery,2019,3(9):45-52.)
[19]Zhang Yonggang,Tang Jun,He Zhengying,et al.A novel displacement prediction method using gated recurrent unit model with time series analysis in the Erdaohe landslide[J].Natural Hazards,2021,105:783-813.
[20]Jang B,Kim M,Harerimana G,et al.Bi-LSTM model to increase accuracy in text classification:combining word2vec CNN and attention mechanism[J].Applied Sciences,2020,10(17):5841.
[21]吳晓建,危一华,王爱春,等.基于融合Dropout与注意力机制的LSTM-GRU车辆轨迹预测[J].湖南大学学报:自然科学版,2023,50(4):65-75.(Wu Xiaojian,Wei Yihua,Wang Aichun,et al.Vehicle trajectory prediction based on LSTM-GRU integrating dropout and attention mechanism[J].Journal of Hunan University:Natural Sciences,2023,50(4):65-75.)
[22]Cheng Gaofeng,Peddinti V,Povey D,et al.An exploration of dropout with LSTMs[EB/OL].92017-08-20).https://api.semanticscholar.org/CorpusID:3836066.
[23]Suman C,Saha S,Bhattacharyya P.An attention-based multimodal Siamese architecture for tweet-user verification[J].IEEE Trans on Computational Social Systems,2023,10(5):2764-2772.
[24]Sueno H T,Gerardo B D,Medina R P.Multi-class document classification using support vector machine(SVM) based on improved Nave Bayes vectorization technique[J].International Journal of Advanced Trends in Computer Science and Engineering,2020,9(3):3937.
[25]Wan Changxuan,Li Bo.Financial causal sentence recognition based on BERT-CNN text classification[J].The Journal of Supercompu-ting,2022,78:6503-6527.
猜你喜欢
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
移动通信(2016年22期)2017-03-07
中国广播(2017年1期)2017-02-21
中国生物医学工程学报(2017年6期)2017-02-10
现代情报(2016年10期)2016-12-15
现代经济信息(2016年24期)2016-11-09
广西科技大学学报(2016年1期)2016-06-22
电脑知识与技术(2016年7期)2016-05-19
噪声与振动控制(2015年4期)2015-01-01
